智能数据建设与治理 Dataphin-数仓分层
https://help.aliyun.com/zh/dataphin/several-positions-layered?spm=a2c4g.11186623.help-menu-87584.d_1_1_3_1.3a901128r3Mpf1&scm=20140722.H_126215._.OR_help-T_cn~zh-V_1
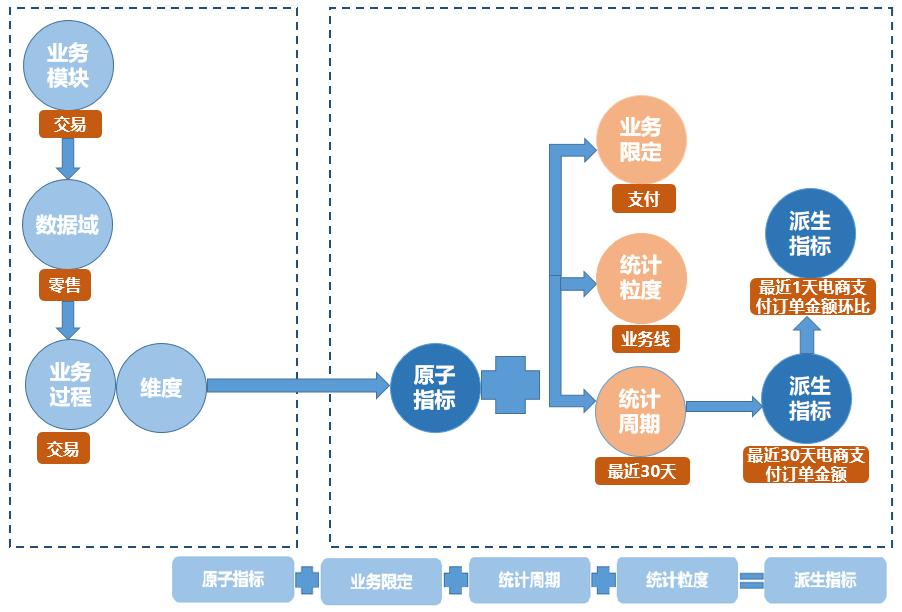
基于阿里巴巴OneData方法论最佳实践,在阿里巴巴的数据体系中,建议将数据仓库分为三层:数据引入层(ODS,Operational Data Store)、数据公共层(CDM,Common Dimensions Model)和数据应用层(ADS,Application Data Store)。
数据仓库自顶向下的分层和各层用途如下图所示。

-
数据引入层(ODS,Operational Data Store,又称数据基础层):将原始数据几乎无处理地存放在数据仓库系统中,结构上与源系统基本保持一致,是数据仓库的数据准备区。这一层的主要职责是将基础数据同步、存储到MaxCompute。
-
数据公共层(CDM,Common Dimensions Model):存放明细事实数据、维表数据及公共指标汇总数据。其中,明细事实数据、维表数据一般根据ODS层数据加工生成。公共指标汇总数据一般根据维表数据和明细事实数据加工生成。
CDM层又细分为维度层(DIM)、明细数据层(DWD)和汇总数据层(DWS),采用维度模型方法作为理论基础, 可以定义维度模型主键与事实模型中外键关系,减少数据冗余,也提高明细数据表的易用性。在汇总数据层同样可以关联复用统计粒度中的维度,采取更多的宽表化手段构建公共指标数据层,提升公共指标的复用性,减少重复加工。
维度层(DIM,Dimension):以维度作为建模驱动,基于每个维度的业务含义,通过添加维度属性、关联维度等定义计算逻辑,完成属性定义的过程并建立一致的数据分析维表。为了避免在维度模型中冗余关联维度的属性,基于雪花模型构建维度表。
在Dataphin中,维度层的表通常也被称为维度逻辑表。-
明细数据层(DWD,Data Warehouse Detail):以业务过程作为建模驱动,基于每个具体的业务过程特点,构建最细粒度的明细事实表。可以结合企业的数据使用特点,将明细事实表的某些重要属性字段做适当冗余,也即宽表化处理。
在Dataphin中,明细数据层的表通常也被称为事实逻辑表。 -
汇总数据层(DWS,Data Warehouse Summary):以分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标表。以宽表化手段物理化模型,构建命名规范、口径一致的统计指标,为上层提供公共指标,建立汇总宽表、明细事实表。
在Dataphin中,汇总数据层的表通常也被称为汇总逻辑表,用于存放派生指标数据。
-
-
数据应用层(ADS,Application Data Store):存放数据产品个性化的统计指标数据,根据CDM层与ODS层加工生成。
数据引入层(ODS)
基于阿里巴巴OneData方法论最佳实践,ODS层存放您从业务系统获取的最原始的数据,是其他上层数据的源数据。业务数据系统中的数据通常为长期累积的、非常细节的数据,且访问频率很高,是面向应用的数据。
数据同步加载与处理
ODS的数据需要由各数据源系统同步、存储到MaxCompute,才能用于进一步的数据开发。本教程建议您使用Dataphin的数据集成功能完成数据同步。在使用数据引入功能的过程中,建议您遵循以下规范:
-
一个系统的源表只允许同步一次到MaxCompute,保持表结构的一致性。
-
数据引入支持全量数据同步、实时增量数据同步(分钟或小时调度实现)两种同步方式。
-
ODS层的表建议以统计日期及时间分区表的方式存储,便于管理数据的存储成本和策略控制,Dataphin中默认时间分区的名字为ds。
-
数据引入支持手动调整源表和目标表的同步字段。
-
如果源表字段在目标表中不存在,用户需手动添加目标字段,或删除源表字段。
-
如果源表字段与目标表字段不匹配,用户需先删除目标字段,然后重新添加与之匹配的字段。
-
维度层(DIM)
本文为您介绍维度层的设计原则、维度表的规范、创建维度及查询维度逻辑表。
维度层简介
建立一致数据分析维表,可以降低数据计算口径和算法不统一风险。以维度作为建模驱动,基于每个维度的业务含义,通过定义维度及维度主键,添加维度属性、关联维度等定义计算逻辑和雪花模型,完成属性定义的过程并建立一致的数据分析维表。同时您可以定义维度主子关系,子维度的属性将合并至主维度使用,进一步保证维度的一致性和便捷使用性。
尽可能生成丰富的维度属性。
例如,电商公司的商品维度可能有近百个维度属性,为下游的数据统计、分析、探查提供了良好的基础。
尽可能多的给出包含一些富有意义的文字性描述。
属性不应该是编码,而应该是真正的文字。在阿里巴巴维度建模中,通常是编码和文字同时存在,例如商品维度中的商品ID和商品标题、类目ID和类目名称等。ID通常用于不同表之间的关联,而名称通常用于报表标签。
区分数值型属性和事实。
数值型字段是作为事实还是维度属性,可以根据字段的常用用途区分。例如,若用于查询约束条件或分组统计,则是作为维度属性;若用于参与度量的计算,则是作为事实。
尽量沉淀出通用的维度属性。
-
通过逻辑处理得到维度属性。
-
通过多表关联得到维度属性。
-
通过单表的不同字段混合处理得到维度属性。
-
通过对单表的某个字段进行解析得到维度属性。
维度表规范
提交普通维度或层级维度时,会自动生成对应的维度逻辑表,不支持用户自定义新建维度逻辑表。此外,Dataphin还支持定义枚举维度和虚拟维度。提交枚举维度和虚拟维度不会生成维度逻辑表。
说明
枚举维度指的是维度表的值可枚举,以便规范统一枚举的维度值,维度作为派生指标统计粒度时,实现数据归一汇总计算。
虚拟维度与某个字段关联后,以维度的形式作为统计粒度,定义派生指标。例如URL。
明细数据层(DWD)
基于阿里巴巴方法论最佳实践,事实表(事实模型,又称事实逻辑表)作为数据仓库维度建模的核心,紧紧围绕着业务过程进行设计。业务过程是通过事实表的度量、引用的维度与业务过程有关属性的方式获取。
Dataphin支持两种类型的事实表:
-
事务型事实表:用于描述业务过程,跟踪空间或时间上某点的度量事件,保存的是最原子的数据,也称为原子事实表,表名后缀一般为di。
-
周期快照型事实表:以具有规律性的、可预见的时间间隔(例如每天、每月、每年等)记录事实,表名后缀一般为df。
事实表设计原则
- 尽可能包含所有与业务过程相关的事实。
设计事实表的目的是度量业务过程,所以分析哪些事实与业务过程有关,是事实表设计中至关重要的。在事实表中应该尽量包含所有与业务过程相关的事实,即使存在冗余,但是因为事实通常为数字型,带来的存储开销不会很大。
- 只选择与业务过程相关的事实。
在选择事实时应该注意,只选择与业务过程有关的事实。例如,A公司的订单交易业务流程中,在设计下单这个业务过程的事实表时,不能包含支付金额这个表示支付业务过程的事实。
- 在选择维度和事实之前,必须先声明粒度。
粒度(数据行数的最小单位,非统计粒度)的声明是事实表设计中不可忽视的重要一步。粒度用于确定事实表中一行所表示业务的细节层次,决定了维度模型的扩展性。在选择维度和事实之前,必须先声明粒度,且每个维度和事实必须与所定义的粒度保持一致。在事实表中,通常通过业务描述来表述粒度并定义事实表主键,但对于聚集性事实表的粒度描述(例如存在下单、支付等多个事务),可以基于多个字段拼接,形成新的字段作为事实表主键,也可以不定义主键,这样一行记录即最小粒度。
- 在同一个事实表中,不能包含多种不同粒度的事实。
事实表中所有事实的粒度需要与表声明的粒度保持一致,在同一个事实表中不能有多种不同粒度的事实。
- 事实的单位要保持一致。
在同一个事实表中,事实的单位应该保持一致。例如,原订单金额、 订单优惠金额、订单运费金额这三个事实,应该采用一致的计量单位,例如统一为元,以方便使用。
事实表设计方法
任何类型的事件都可以被理解为一种事务。例如,交易过程中的创建订单、买家付款,物流过程中的揽货、发货、签收,退款过程中的申请退款、申请客服介入等,都可以被理解为一种事务。事务型事实表,即针对这些过程构建的一类事实表,用以跟踪定义业务过程的个体行为,提供丰富的分析能力,作为数据仓库CDM层的明细数据。
汇总数据层(DWS)
汇总数据层以分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求构建公共粒度的汇总表。汇总数据层的一个表通常会对应一个统计粒度(维度或维度组合)及该粒度下若干派生指标。
汇总表设计原则
聚集是指针对原始明细粒度的数据进行汇总。DWS汇总数据层是面向分析对象的主题聚集建模。在本教程中,最终的分析目标为:最近一天某个类目(例如,厨具)商品在各省的销售总额、该类目销售额Top10的商品名称、各省用户购买力分布。因此,我们可以以最终交易成功的商品、类目、买家等角度对最近一天的数据进行汇总。数据聚集的注意事项如下:
- 聚集是不跨越事实的。聚集是针对原始星形模型进行的汇总。为获取和查询与原始模型一致的结果,聚集的维度和度量必须与原始模型保持一致,因此聚集是不跨越事实的,所以原子指标只能基于一张事实表定义,但是支持原子指标组合为衍生原子指标。
- 聚集会带来查询性能的提升,但聚集也会增加ETL维护的难度。当子类目对应的一级类目发生变更时,先前存在的、已经被汇总到聚集表中的数据需要被重新调整。
此外,进行DWS层设计时还需遵循数据公用性原则。数据公用性需要考虑汇总的聚集是否可以提供给第三方使用。您可以思考,基于某个维度的聚集是否经常用于数据分析中。如果答案是肯定的,就有必要把明细数据经过汇总沉淀到聚集表中。