Docker实战避坑指南:从入门到精通
摘要:文人结合自身微服务实践,系统梳理从安装适配、镜像拉取,到运行配置、构建优化、多容器编排、数据持久化、监控运维等 Docker 全流程高频踩坑点,给出可落地的解决方案,帮助读者快速规避同类问题并提升容器化效率。
目录
1.引言
2.Docker 初体验:基础搭建那些坑
2.1 安装困境:不同系统的适配难题
2.2 镜像拉取:速度与连接的双重考验
3.深入容器:运行与配置的挑战
3.1 资源限制:容器间的 “资源战争”
3.2 端口映射:容器与外界的 “沟通障碍”
4.镜像构建:细节决定成败
4.1 镜像臃肿:不必要的 “负担”
4.2 安全隐患:秘密的 “泄露危机”
4.3 如何批量删除没有意义的镜像【good】
5.多容器协作:docker - compose 的陷阱
5.1 配置语法:隐藏的语法 “地雷”
5.2 服务依赖:启动顺序的 “迷局”
6.数据管理:持久化与共享的难题
6.1 数据丢失:容器中的 “数据黑洞”
6.2 共享冲突:多容器数据共享的 “矛盾”
7.监控与维护:保障容器稳定运行
7.1 日志管理:信息获取的 “困境”
1.Docker日志文件可以删除吗?
推荐做法(运行中容器)
小结
2.已经定位到 2 GB 的大日志文件
✅ 先确认容器状态
✅ 容器在运行 → 用 truncate(推荐,亲测有效)
⚠️ 容器已停止 → 可安全删除
一键脚本(通用)
7.2 容器清理:空间占用的 “烦恼”
8.总结与展望
1.引言

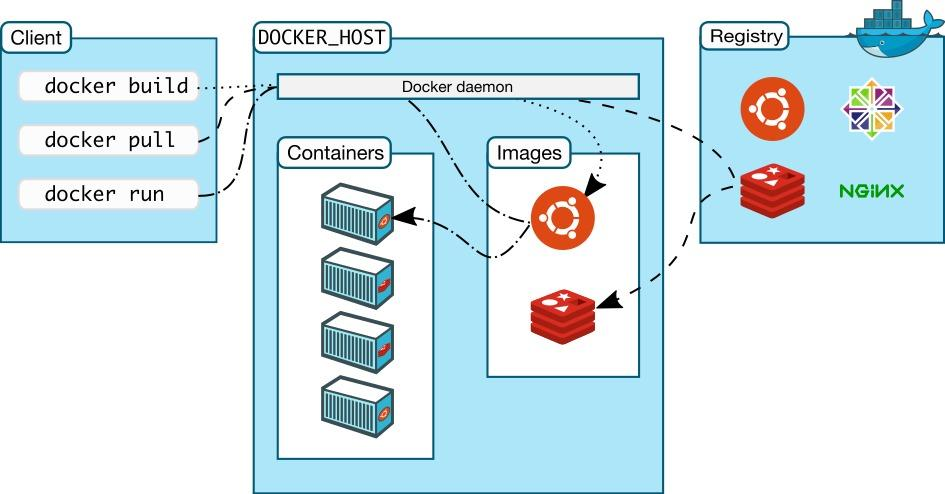
在当今云计算和容器化技术盛行的时代,Docker 无疑是其中的中流砥柱。它以 “一次构建,到处运行” 的理念,彻底改变了软件交付和部署的方式,极大地提升了开发、测试和运维的效率,实现了应用程序及其依赖环境的高效打包和分发,在不同环境中保持一致性,让开发者从繁琐的环境配置中解脱出来。无论是初创公司还是大型企业,Docker 都成为了实现高效开发和部署的必备工具 ,在微服务架构、持续集成与持续部署(CI/CD)等场景中广泛应用。
我在日常工作中,主要负责后端服务的开发与维护,项目采用微服务架构,各个服务都通过 Docker 进行容器化部署。在这个过程中,我深刻体会到了 Docker 带来的便捷性,但也不可避免地遇到了各种各样的 “坑”。这些问题有的耗费了我大量的时间去排查和解决,有的甚至影响到了项目的进度。我深知在技术探索的道路上,每一次遇到的问题都是宝贵的经验积累。所以,我决定将这些在使用 Docker 过程中遇到的典型问题及解决方法分享出来,希望能帮助到正在使用或者即将使用 Docker 的朋友们,让大家在容器化的道路上少走一些弯路。
Docker官网:https://www.docker.com/
Docker概念:Docker是一组平台即服务(PaaS)的产品。它基于操作系统层级的虚拟化技术,将软件与其依赖项打包为容器。托管容器的软件称为Docker引擎。Docker能够帮助开发者在轻量级容器中自动部署应用程序,并使得不同容器中的应用程序彼此隔离,高效工作。该服务有免费和高级版本。它于2013年首次发布,由Docker, Inc. 开发。
2.Docker 初体验:基础搭建那些坑
2.1 安装困境:不同系统的适配难题
Docker 的安装过程虽然在官方文档中有详细说明,但在不同操作系统上实践时,还是会遇到各种意想不到的问题。
在 Linux 系统中,以 Ubuntu 为例,安装过程依赖于系统软件包的更新和一系列依赖包的安装。曾经在一次项目中,我在一台全新的 Ubuntu 服务器上安装 Docker,按照官方步骤,首先执行了系统软件包更新命令sudo apt update和sudo apt upgrade -y ,一切看似顺利。然而,在安装依赖包时,却出现了unable to locate package的错误,提示找不到某些依赖包。经过一番排查,发现是软件源配置的问题,默认的软件源在某些地区可能无法稳定访问,导致依赖包下载失败。解决办法是更换为国内稳定的软件源,如阿里云的软件源,修改/etc/apt/sources.list文件,将软件源地址替换为阿里云的地址,然后再次执行更新和安装命令,问题得以解决。
对于 Windows 系统,安装 Docker Desktop 时,需要满足一定的系统要求,如 Windows 10 Pro 及以上版本,并且要开启虚拟化功能。有一次,一位同事在 Windows 10 Home 版本的电脑上尝试安装 Docker,尽管按照网上的教程开启了 WSL 2(Windows Subsystem for Linux 2),但在安装过程中仍然报错,提示虚拟化功能未启用。后来发现,Windows 10 Home 版本的虚拟化功能需要通过特定的方式开启,即通过管理员身份运行 PowerShell,执行wsl --install命令来安装和启用 WSL 2,并确保在 BIOS 设置中开启虚拟化技术(VT-x/AMD-V)选项 ,之后重新安装 Docker Desktop 才成功。
而在 MacOS 系统中,安装 Docker Desktop 可能会遇到与系统兼容性或已安装软件冲突的问题。比如,当 MacOS 版本过低时,不满足 Docker 的运行要求,会导致安装失败。另外,如果系统中已经安装了如 VirtualBox 等虚拟化软件,可能会与 Docker 产生冲突。我曾在一台 MacBook 上安装 Docker,当时系统中安装了 VirtualBox,在安装 Docker Desktop 时,一直出现启动失败的情况。通过卸载 VirtualBox,并清理相关残留文件后,重新安装 Docker Desktop,才成功解决了问题。
个人推荐Docker安装三个方式:
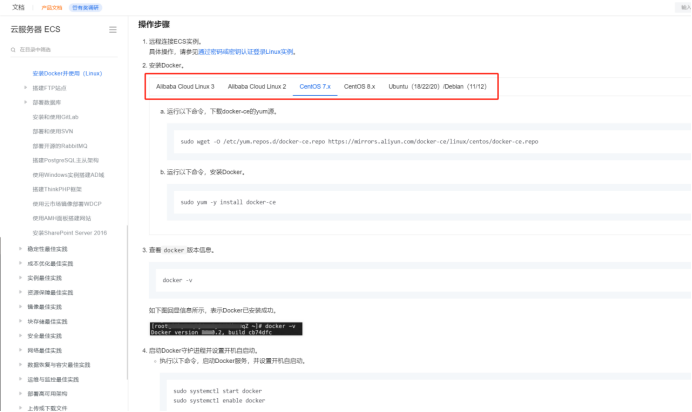
方式一(推荐):阿里云安装docker,根据服务器类型选择安装,地址如下:
安装Docker并使用镜像仓库ACR_云服务器 ECS(ECS)-阿里云帮助中心
方式二:
Windows10安装Docker Desktop(大妈看了都会)_win10 docker desktop-CSDN博客
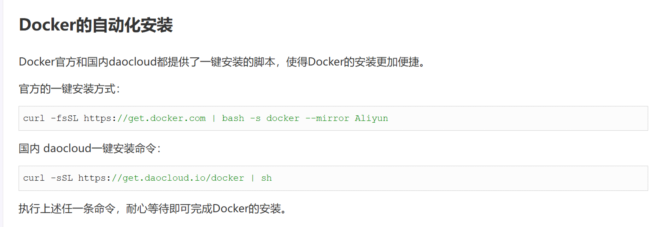
方式三:执行下面的命令。
2.2 镜像拉取:速度与连接的双重考验
在完成 Docker 的安装后,拉取镜像成为了使用 Docker 的第一步,但这一步也常常会遇到各种问题。
网络连接问题是导致镜像拉取失败的常见原因之一。由于 Docker 镜像仓库默认位于国外,在国内访问时,网络速度可能会非常慢,甚至出现连接超时的情况。在一次项目的测试环境搭建中,需要拉取一个较大的 MySQL 镜像,使用默认的镜像源拉取时,速度极慢,并且多次出现拉取中断的情况。通过抓包分析,发现是网络延迟过高导致的。为了解决这个问题,更换为国内的镜像源,如阿里云镜像源、网易云镜像源等。具体操作是在 Docker 配置文件/etc/docker/daemon.json中添加镜像源地址,例如:
{"registry-mirrors": ["https://docker.registry.cyou","https://docker-cf.registry.cyou","https://dockercf.jsdelivr.fyi","https://docker.jsdelivr.fyi","https://dockertest.jsdelivr.fyi","https://mirror.aliyuncs.com","https://dockerproxy.com","https://mirror.baidubce.com","https://docker.m.daocloud.io","https://docker.nju.edu.cn","https://docker.mirrors.sjtug.sjtu.edu.cn","https://docker.mirrors.ustc.edu.cn","https://mirror.iscas.ac.cn","https://docker.rainbond.cc","https://do.nark.eu.org","https://dc.j8.work","https://dockerproxy.com","https://gst6rzl9.mirror.aliyuncs.com","https://registry.docker-cn.com","http://hub-mirror.c.163.com","http://mirrors.ustc.edu.cn/","https://mirrors.tuna.tsinghua.edu.cn/","http://mirrors.sohu.com/"]
}
添加完成后,重启 Docker 服务sudo systemctl daemon-reload && sudo systemctl restart docker ,再次拉取镜像,速度得到了显著提升。
另外,镜像源不可用也是一个常见问题。有时候,某些镜像源可能会因为维护、政策等原因无法正常使用。有一次,我使用的一个镜像源突然无法拉取镜像,报错提示无法连接到镜像源。经过查询相关论坛和官方公告,发现该镜像源由于违规被封禁。此时,只能及时更换其他可用的镜像源,重新拉取镜像。
还有一种情况是镜像名称或标签错误,导致无法找到对应的镜像。在一次部署新服务时,我误将镜像名称中的字母写错,执行docker pull命令后,一直提示镜像不存在。仔细检查镜像名称后,修正错误,才成功拉取到镜像。因此,在拉取镜像时,一定要仔细核对镜像名称和标签,确保准确无误。
3.深入容器:运行与配置的挑战
3.1 资源限制:容器间的 “资源战争”
在容器化的环境中,资源限制是一个至关重要的环节,但也是一个容易被忽视的 “坑”。如果不对容器的资源使用进行合理限制,当多个容器同时运行在同一台宿主机上时,就可能会引发激烈的 “资源战争”。
我曾经遇到过这样一个案例,在一个测试环境中,有多个微服务容器同时运行,其中一个数据分析服务的容器在处理大量数据时,由于没有限制其 CPU 和内存的使用,它疯狂地占用了宿主机几乎所有的 CPU 资源和大量内存 。这导致其他容器中的服务因为资源不足而响应缓慢,甚至出现了服务崩溃的情况,整个测试环境陷入了瘫痪。从监控数据中可以看到,该数据分析服务容器的 CPU 使用率长时间保持在 99% 以上,内存使用率也远远超出了正常水平,而其他容器的资源使用率则急剧下降。
为了避免这种情况的发生,Docker 提供了--cpus和-m(或--memory)等参数来限制容器的资源使用。--cpus参数用于限制容器可以使用的 CPU 核心数,例如--cpus="1"表示容器最多只能使用 1 个 CPU 核心;-m参数用于限制容器的内存使用量,如-m 512m表示容器最多只能使用 512MB 的内存。在重新部署数据分析服务容器时,我添加了这些资源限制参数,将其 CPU 限制为 2 个核心,内存限制为 1GB,即docker run -d --cpus="2" -m 1g --name data-analysis-service data-analysis-image 。重新运行后,通过监控工具可以看到,各个容器的资源使用都处于合理范围内,不再出现资源争抢导致的服务异常情况。
3.2 端口映射:容器与外界的 “沟通障碍”
端口映射是实现容器与外界通信的关键,但在实际操作中,也常常会遇到各种问题,导致容器与外界之间出现 “沟通障碍”。
端口映射错误的一个常见表现就是无法访问容器内的服务。有一次,我在部署一个 Web 应用容器时,按照常规操作使用docker run -d -p 8080:80 --name web-app web-app-image命令将容器的 80 端口映射到宿主机的 8080 端口 ,但在浏览器中访问http://localhost:8080时,却一直显示连接超时。经过仔细排查,发现是端口冲突导致的问题。原来,宿主机上已经有另一个服务占用了 8080 端口,通过使用netstat -ano | findstr 8080命令(在 Windows 系统中)或netstat -anp | grep 8080命令(在 Linux 系统中),找到了占用该端口的进程,并将其停止后,再次启动 Web 应用容器,才成功访问到了容器内的 Web 服务。
除了端口冲突,映射配置错误也是一个常见原因。比如,在映射端口时,将宿主机端口和容器端口的顺序写错,写成了docker run -d -p 80:8080 --name web-app web-app-image ,这样就会导致实际映射关系错误,外界无法通过正确的端口访问到容器内的服务。解决办法就是仔细检查映射配置,确保端口顺序正确。
另外,在一些复杂的网络环境中,如在云服务器上使用 Docker,还需要注意安全组规则的配置。如果安全组没有开放相应的端口,即使端口映射配置正确,也无法从外部访问容器服务。例如,在使用阿里云服务器时,需要在阿里云控制台的安全组配置中,添加允许外部访问映射端口的规则,如添加一条入方向规则,允许来自任意 IP 地址的 TCP 协议访问 8080 端口 ,这样才能确保外部可以正常访问容器内的 Web 服务。
4.镜像构建:细节决定成败
4.1 镜像臃肿:不必要的 “负担”
在镜像构建过程中,一个常见且容易被忽视的问题就是镜像臃肿。臃肿的镜像就像是一个背负着沉重包袱的行者,在分发、部署和运行过程中,都会带来诸多不便和性能损耗。
大镜像的分发往往面临着困难。在网络传输过程中,较大的镜像文件需要更长的时间来完成下载和上传,这对于带宽有限的环境来说,无疑是一个巨大的挑战。曾经在一次项目的生产环境部署中,由于使用了一个体积较大的 Java 应用镜像,在从镜像仓库拉取到服务器的过程中,花费了将近 30 分钟的时间,严重影响了部署的效率。而且,大镜像占用的存储空间也更大,无论是在本地开发环境还是在生产服务器上,都需要更多的磁盘空间来存储这些镜像。随着项目中镜像数量的增加,磁盘空间很快就会被占满,导致服务器运行缓慢甚至出现故障。
为了优化镜像大小,我们可以采取一系列有效的措施。选择合适的基础镜像是关键的第一步。许多常用的基础镜像,如 Alpine,是轻量级的 Linux 发行版,其体积相比传统的 Ubuntu、CentOS 等镜像要小得多。以一个 Python 项目为例,使用python:3.9-slim作为基础镜像,相比使用python:3.9,镜像体积可以减少约 100MB。在构建镜像时,要注意排除不必要的文件和目录。可以使用.dockerignore文件,类似于.gitignore,来指定哪些文件和目录不需要被包含在镜像构建的上下文中。例如,在一个 Node.js 项目中,node_modules目录在部署时可以通过npm install重新安装,因此可以将其添加到.dockerignore文件中,避免将其打包进镜像,从而减小镜像体积。
另外,合理合并RUN指令也能有效减少镜像层数,进而减小镜像大小。每个RUN指令都会在镜像中创建一个新的层,如果指令过多且不合理,就会导致镜像层数过多,体积增大。例如,在安装多个软件包时,将多个RUN指令合并为一个,如RUN apk add --no-cache git curl,而不是写成RUN apk add --no-cache git和RUN apk add --no-cache curl两条指令 ,这样可以减少一层镜像,使镜像更加紧凑。
4.2 安全隐患:秘密的 “泄露危机”
在镜像构建过程中,安全问题不容忽视,其中一个常见的风险就是在镜像中嵌入密钥等机密信息,这就像是在自家门口埋下了一颗随时可能引爆的炸弹,一旦镜像被泄露或恶意利用,机密信息就会面临 “泄露危机”。
许多开发者在构建镜像时,为了方便,可能会将一些敏感信息,如数据库连接密码、API 密钥、SSH 密钥等,直接硬编码在 Dockerfile 中或复制到镜像中。这种做法看似简单快捷,但却存在着巨大的安全风险。如果镜像被上传到公共镜像仓库或被未经授权的人员获取,这些机密信息就会完全暴露在他人面前。曾经有一个开源项目,开发者在镜像中嵌入了 AWS 的访问密钥,后来该镜像被恶意下载,攻击者利用这些密钥在 AWS 上创建了大量资源,导致该项目遭受了严重的经济损失。
为了避免这种风险,我们应该采用更加安全的方式来处理机密信息。依赖环境变量是一种常用且有效的方法。在容器运行时,可以通过-e参数或在 Kubernetes 的Deployment配置中设置环境变量,将机密信息传递给容器内的应用程序。例如,在运行容器时,可以使用docker run -d -e DB_PASSWORD=your_password --name my-db my-db-image命令将数据库密码以环境变量的形式传递给容器 。在应用程序中,可以通过读取环境变量来获取这些机密信息,如在 Python 中,可以使用os.getenv('DB_PASSWORD')来获取数据库密码。
另外,使用秘密管理器也是一种更高级、更安全的解决方案。像 HashiCorp Vault、AWS Secrets Manager、Google Cloud Secret Manager 等秘密管理器,提供了安全的密钥存储和管理功能。这些工具可以生成、存储和管理密钥,并通过安全的接口将密钥传递给需要的容器或应用程序。以 HashiCorp Vault 为例,首先需要在 Vault 中创建一个密钥存储路径,并将机密信息存储在其中。然后,在容器启动时,通过 Vault 的客户端库或 API,在运行时动态地获取所需的机密信息,并将其注入到容器的环境变量中,从而实现机密信息的安全管理,避免在镜像构建过程中直接嵌入密钥带来的安全风险。
4.3 如何批量删除没有意义的镜像【good】
要批量删除Docker中没有意义或无用的镜像,您可以采用以下几种方法:
- 删除所有未使用的镜像(悬空镜像):
您可以使用docker images -q --filter "dangling=true"命令列出所有未使用的镜像ID,然后通过管道操作符|和xargs命令来批量删除这些镜像:【亲测有效】bash
docker images -q --filter "dangling=true" | xargs docker rmi这将删除所有未使用的镜像,也就是那些没有被任何容器引用的镜像。
- 删除特定前缀的镜像: 如果您想要删除所有以某个特定前缀开头的镜像,可以使用
grep命令来过滤这些镜像,然后使用docker rmi命令删除:bash
docker rmi $(docker images | grep '特定前缀' | awk '{print $3}')其中
特定前缀是您要删除的镜像的共同前缀。
- 使用脚本自动化删除过程: 您可以创建一个shell脚本来自动化删除过程,例如:
bash
#!/bin/bash # 设置镜像前缀 PREFIX="test" # 删除所有以指定前缀开头的镜像 docker rmi $(docker images | grep "$PREFIX" | awk '{print $3}') echo "删除镜像完成。"保存这个脚本为
delete_images.sh,然后通过chmod +x delete_images.sh命令给予执行权限,并执行./delete_images.sh来运行脚本。
- 使用
docker image prune命令: Docker提供了docker image prune命令,可以用来删除未使用的镜像。这个命令非常简便,但需要注意的是,它会删除所有未被使用的镜像,如果不加筛选条件,可能会删除掉一些您并不想删除的镜像:bash
docker image prune -a在此命令中,
-a选项表示删除所有未使用的镜像,而不仅仅是悬空的镜像(dangling images)。请在执行删除操作之前确保您没有正在运行的容器依赖于这些镜像,以避免意外删除正在使用的镜像导致服务中断。同时,定期清理镜像库是保持Docker系统健康和高效运行的重要部分。
5.多容器协作:docker - compose 的陷阱
5.1 配置语法:隐藏的语法 “地雷”
在使用 Docker 进行多容器协作时,docker-compose无疑是一个强大的工具,它通过一个docker-compose.yml配置文件,就能轻松定义和管理多个相关的 Docker 容器。然而,这个配置文件的语法却隐藏着不少 “地雷”,稍有不慎就会引发各种问题。
docker-compose.yml文件采用 YAML 格式,而 YAML 对缩进、空格和大小写都非常敏感。比如,在定义服务时,缩进必须保持一致,通常建议使用两个或四个空格,绝对不能使用制表符。像下面这个错误示例:
services:
web:image: nginx:latest由于web服务的缩进错误,就会导致配置解析失败。正确的格式应该是:
services:web:image: nginx:latest另外,键值对的格式也必须正确,冒号后面一定要有一个空格。例如:
# 错误示例,冒号后缺少空格
environment:KEY:value
# 正确示例
environment:KEY: value如果不注意这些细节,在执行docker-compose up等命令时,就会报错提示语法错误,让容器无法正常启动。而且,这种语法错误往往很难排查,因为错误信息可能并不会直接指出具体是哪个缩进或键值对格式有问题,需要我们仔细检查整个配置文件。
除了缩进和键值对格式,docker-compose.yml文件中的指令也必须准确无误。不同的docker-compose版本支持的功能和指令有所差异,所以在编写配置文件时,一定要根据使用的docker-compose版本来选择合适的指令,并了解其特性和限制。比如,在version: '3'的配置文件中,deploy部分用于定义服务的部署相关配置,像资源限制、副本数量等。如果在低版本中使用了deploy指令,就会导致配置文件无法解析。在使用一些自定义的扩展指令时,也要确保其在当前版本中是被支持的,否则也会引发语法错误。
5.2 服务依赖:启动顺序的 “迷局”
在多容器应用中,服务之间往往存在着复杂的依赖关系,而docker-compose中的depends_on参数用于定义服务之间的依赖关系,确保依赖的服务先启动。然而,depends_on只能保证服务的启动顺序,却不能保证依赖的服务已经完全就绪并可以正常提供服务。
以一个典型的 Web 应用架构为例,Web 服务通常依赖于数据库服务。在docker-compose.yml文件中,可能会这样定义:
version: '3'
services:web:image: mywebapp:1.0depends_on:- dbdb:image: mysql:8.0.26当执行docker-compose up时,docker-compose会先启动db服务,然后再启动web服务。但是,如果db服务启动后,还需要一些时间来初始化数据库、加载数据等操作,而此时web服务已经开始尝试连接db服务,就可能会因为db服务尚未完全就绪而导致连接失败,最终使web服务启动失败。从web服务的日志中,我们可能会看到类似 “Connection refused to mysql” 的错误信息,提示无法连接到数据库。
为了解决这个问题,可以结合使用healthcheck和depends_on中的condition参数。healthcheck用于定义容器的健康检查规则,通过定期执行检查命令,判断容器是否正常运行。例如,对于上述的db服务,可以添加如下健康检查配置:
version: '3'
services:web:image: mywebapp:1.0depends_on:- db:condition: service_healthydb:image: mysql:8.0.26healthcheck:test: ["CMD", "mysqladmin", "ping", "-h", "localhost"]interval: 10stimeout: 5sretries: 5在这个配置中,db服务会每隔 10 秒执行一次mysqladmin ping -h localhost命令来检查数据库是否正常运行。如果在 5 次重试内,每次检查都能成功(即命令返回值为 0),则认为db服务是健康的。web服务的depends_on中设置了condition: service_healthy,表示只有当db服务健康时,web服务才会启动,从而避免了因依赖服务未就绪而导致的启动失败问题。
另外,还可以通过编写自定义的启动脚本来处理服务依赖。在容器启动时,先执行一个脚本,该脚本会不断尝试连接依赖的服务,直到连接成功后,再启动容器内的实际服务。比如,在web服务的容器中,可以编写一个start.sh脚本:
#!/bin/bash
while! nc -z db 3306; dosleep 1
done
echo "Database is ready"
# 启动Web服务的命令
python app.py然后在docker-compose.yml文件中,将web服务的command指定为这个脚本:
version: '3'
services:web:image: mywebapp:1.0depends_on:- dbcommand: /start.shdb:image: mysql:8.0.26这样,web服务在启动时,会先等待数据库服务就绪,然后再启动自身的应用程序,有效解决了服务依赖导致的启动顺序问题。
6.数据管理:持久化与共享的难题
6.1 数据丢失:容器中的 “数据黑洞”
在 Docker 的世界里,容器的设计初衷是具有临时性和可重复性的,这使得容器在运行过程中产生的数据面临着丢失的风险。如果将数据直接存储在容器的可写层中,一旦容器被删除,这些数据就会像掉进了 “数据黑洞” 一样,永远消失不见。
我曾经参与过一个数据处理项目,其中有一个数据清洗的容器,它会从外部数据源读取数据,经过一系列的清洗和转换后,将处理后的数据存储在容器内的一个目录中。在一次测试过程中,由于需要重新配置容器的一些参数,我停止并删除了这个数据清洗容器,准备重新启动一个新的容器。然而,当我重新启动容器后,却发现之前处理好的数据全部丢失了。这是因为在删除容器时,容器内的可写层也被一并删除,存储在其中的数据自然也就不复存在了。
为了避免这种数据丢失的情况,我们需要使用数据卷(Volumes)和数据容器(Data Volume Containers)来实现数据的持久化存储。数据卷是一个可供一个或多个容器使用的特殊目录,它绕过了 Union File System,能够提供一些用于持久化或共享数据的特性。我们可以在创建容器时,使用-v参数将数据卷挂载到容器内的指定目录。例如,要将一个名为my-volume的数据卷挂载到nginx容器的/usr/share/nginx/html目录,可以使用以下命令:
docker run -d
-p 80:80
--name my-nginx
-v my-volume:/usr/share/nginx/html nginx这样,即使my-nginx容器被删除,my-volume数据卷中的数据依然会保留在宿主机上,当重新创建容器并挂载相同的数据卷时,容器就可以访问到之前存储的数据。
另外,数据卷容器是一种特殊的容器,它的主要作用是专门用来提供数据卷供其他容器挂载。通过使用--volumes-from参数,一个容器可以挂载另一个数据卷容器中的数据卷。例如,先创建一个数据卷容器dbdata:
docker run -it -v /dbdata --name dbdata centos然后创建另一个容器db1,并使用--volumes-from参数挂载dbdata容器的数据卷:
docker run -it --volumes-from dbdata --name db1 centos这样,db1容器就可以共享dbdata容器的数据卷,实现数据的持久化和共享。而且,即使db1容器被删除,dbdata容器中的数据卷依然存在,其他容器还可以继续挂载使用 。
6.2 共享冲突:多容器数据共享的 “矛盾”
在多容器协作的场景中,多个容器同时读写同一个数据卷是很常见的需求,但这也容易引发数据冲突的问题,就像多个人同时修改同一个文件,很容易导致数据的不一致和混乱。
以一个电商系统为例,其中订单服务和库存服务都需要访问同一个数据库的数据卷。当订单服务接收到一个新订单时,它会读取库存数据卷中的商品库存信息,判断库存是否足够,如果足够则更新库存并生成订单。同时,库存服务可能也在对库存数据进行统计分析,或者进行库存的补充操作。如果这两个服务同时对数据卷进行写入操作,就可能会出现数据冲突。比如,订单服务在更新库存时,库存服务也在更新库存,可能会导致其中一个更新操作被覆盖,从而使库存数据出现错误。
为了预防和解决这种数据冲突问题,我们可以采取以下策略:
- 使用分布式锁:在应用程序层面引入分布式锁机制,如 Redis 的分布式锁。当一个容器需要对共享数据进行写入操作时,先获取分布式锁,只有获取到锁的容器才能进行写入操作,其他容器需要等待锁的释放。例如,在 Python 中使用redis-py库实现分布式锁:
import redis from redis.lock import Lockr = redis.Redis(host='redis-server', port=6379, db=0) lock = Lock(r, "data-volume-lock")try:if lock.acquire(blocking=True, timeout=10):# 进行数据写入操作pass finally:lock.release() - 优化读写操作:尽量减少多容器同时写入的情况,将一些读写操作进行优化。例如,对于一些只读操作,可以使用缓存来减少对数据卷的直接读取;对于写入操作,可以采用异步写入的方式,将写入请求先放入消息队列中,然后由一个专门的服务按照顺序从消息队列中读取请求并写入数据卷,这样可以避免多个容器同时写入导致的冲突。
- 数据版本控制:在数据卷中引入版本控制机制,每次对数据进行写入操作时,更新数据的版本号。当其他容器读取数据时,同时读取数据的版本号,在进行写入操作前,先比较版本号,如果版本号不一致,则说明数据已经被其他容器修改过,需要重新读取最新的数据,然后再进行写入操作,以此来保证数据的一致性。
7.监控与维护:保障容器稳定运行
7.1 日志管理:信息获取的 “困境”
在容器化的应用环境中,日志管理是确保系统稳定运行和故障排查的关键环节,但也面临着诸多挑战,就像在一个庞大的信息迷宫中寻找关键线索,充满了困难和复杂性。
容器日志分散是一个常见的问题。在一个由多个容器组成的分布式系统中,每个容器都产生自己的日志,这些日志分散在不同的容器实例中。例如,一个电商系统可能包含用户服务、订单服务、支付服务等多个微服务容器,每个容器都会记录各自的业务操作日志、错误日志等。当出现问题时,要从这些分散的日志中快速定位问题根源,就如同大海捞针一般困难。曾经在一次线上故障中,用户反馈无法完成支付操作,为了排查问题,我需要查看支付服务容器、订单服务容器以及相关数据库容器的日志。然而,由于这些容器分布在不同的服务器上,且日志格式和存储位置各不相同,我花费了大量的时间在各个服务器和容器之间切换,才收集到了相关的日志信息。
而且,容器日志难以检索也是一个突出的问题。传统的日志管理方式在容器环境下往往显得力不从心。Docker 默认的日志驱动是json-file,它将日志以 JSON 格式写入文件,虽然这种格式便于机器解析,但对于人工检索来说并不友好。当日志量较大时,使用普通的文本搜索工具很难快速找到关键信息。比如,在一个高并发的 Web 应用中,每天产生的日志量可能达到几十 GB 甚至更多,在这些海量的日志中查找某个特定时间点的错误信息,使用简单的grep命令往往效率低下,需要耗费大量的时间和计算资源。
为了解决这些问题,我们可以采用挂载日志卷的方式,将容器内的日志文件挂载到宿主机的指定目录,这样就可以在宿主机上集中管理和查看日志。例如,在运行容器时,可以使用-v参数进行日志卷挂载:
docker run -d -v /host/logs:/container/logs --name my-container my-image这样,容器内/container/logs目录下的日志文件就会被同步到宿主机的/host/logs目录,方便我们直接在宿主机上查看和处理日志。
此外,使用专业的日志管理工具也是一个有效的解决方案。像 ELK Stack(Elasticsearch、Logstash、Kibana)和 Fluentd 等工具,可以实现日志的集中收集、存储、索引和可视化。以 ELK Stack 为例,Logstash 负责从各个容器收集日志数据,然后将其发送到 Elasticsearch 进行存储和索引,Kibana 则提供了一个友好的用户界面,用于搜索和可视化日志数据。通过配置 ELK Stack,我们可以在 Kibana 的界面上根据时间范围、关键字、容器名称等条件进行灵活的日志查询和分析,大大提高了日志检索的效率和准确性 。
1.Docker日志文件可以删除吗?
可以,但要分“场景”和“时机”:
场景
能否直接
rm删除后果/注意点
容器正在运行
❌ 不要直接
rm日志文件被 dockerd 打开,删除后磁盘空间不会立即释放(文件句柄仍在),还可能触发
device busy或容器写日志报错。容器已停止
✅ 可以
rm无风险,空间立即释放。
所有容器已停止或已删除
✅ 可以整目录
rm -rf /var/lib/docker/containers/*/*-json.log彻底清空。
推荐做法(运行中容器)
- 先截断(立即释放空间,容器不停)
sudo truncate -s 0 /var/lib/docker/containers/<容器ID>/<容器ID>-json.log
- 或者 轮转(长期根治)
docker run --log-opt max-size=100m --log-opt max-file=3 ...
小结
- 容器在跑 ⇒ 用
truncate或 配置 log-opts。- 容器停了 ⇒
rm随便删,安全。2.已经定位到 2 GB 的大日志文件
你已经定位到 2 GB 的大日志文件,对应容器目录是:
/var/lib/docker/containers/f826db7c9ef6d3258283de7c6f46fd87e467f4a3febd9474763d31d967b9bb2c/
✅ 先确认容器状态
docker ps -a --filter "id=f826db7c9ef6" --format "table {{.Names}}\t{{.Status}}"
- 如果容器是
Exited→ 直接删日志安全- 如果容器是
Up xxx→ 不要rm,用truncate清空间,不影响运行
✅ 容器在运行 → 用 truncate(推荐,亲测有效)
sudo truncate -s 0 /var/lib/docker/containers/f826db7c9ef6d3258283de7c6f46fd87e467f4a3febd9474763d31d967b9bb2c/*-json.log
- 秒级释放 2 GB 空间
- 容器不停、日志继续写,无风险
⚠️ 容器已停止 → 可安全删除
sudo rm /var/lib/docker/containers/f826db7c9ef6d3258283de7c6f46fd87e467f4a3febd9474763d31d967b9bb2c/*-json.log
- 删除后磁盘空间立即回收
- 重启容器时 Docker 会自动重新创建空日志文件
一键脚本(通用)
CID=f826db7c9ef6 LOG=/var/lib/docker/containers/$CID/*-json.log docker ps -q --filter id=$CID | grep -q $CID \&& sudo truncate -s 0 $LOG \|| sudo rm $LOG执行完再用
df -h看一眼磁盘即可确认空间已释放。
7.2 容器清理:空间占用的 “烦恼”
在 Docker 的日常使用中,如果不及时清理无用的容器、镜像和卷,就会导致磁盘空间被大量占用,就像一个杂乱无章的仓库,堆满了无用的杂物,不仅浪费空间,还会影响系统的性能。
无用容器占用空间是一个常见的问题。当我们停止并退出一个容器后,如果不及时删除它,这个容器仍然会占用一定的磁盘空间。随着时间的推移,大量停止的容器会逐渐积累,占用越来越多的磁盘空间。例如,在开发和测试过程中,我们可能会频繁地创建和运行容器进行各种实验,这些容器在使用完毕后,如果没有及时清理,就会在系统中留下大量的 “垃圾”。曾经在一个开发环境中,由于长时间没有清理容器,磁盘空间被大量占用,导致新的容器无法正常运行,系统提示磁盘空间不足。通过使用docker ps -a命令查看所有容器,发现有数百个已经停止的容器,这些容器占用了数十 GB 的磁盘空间。
未使用的镜像也是磁盘空间的 “吞噬者”。每次拉取或构建新的镜像时,如果不清理旧的未使用的镜像,镜像文件会不断累积,占用大量的磁盘空间。而且,一些大的镜像文件本身就占用较大的存储空间,如果不及时清理,会对系统的磁盘空间造成很大的压力。比如,在一个项目中,我们需要频繁更新 Java 应用的镜像,由于没有及时清理旧的镜像,导致镜像仓库中积累了大量不同版本的 Java 应用镜像,这些镜像占用了数百 GB 的磁盘空间,严重影响了系统的正常运行。
另外,未清理的卷也会占用磁盘空间。数据卷是用于持久化存储数据的,但当与之关联的容器被删除后,如果不及时清理无用的卷,这些卷仍然会占用磁盘空间。特别是在一些数据量较大的应用中,如数据库应用,数据卷占用的空间可能会非常大。例如,一个 MySQL 数据库容器使用的数据卷,在容器被删除后,如果没有清理该数据卷,其中存储的数据库文件仍然会占用大量的磁盘空间。
为了清理这些无用的资源,我们可以使用一系列的 Docker 命令。使用docker container prune命令可以删除所有停止的容器;使用docker image prune命令可以删除所有未被使用的镜像;使用docker volume prune命令可以删除所有未被使用的卷 。例如:
# 删除所有停止的容器
docker container prune
# 删除所有未被使用的镜像
docker image prune -a
# 删除所有未被使用的卷
docker volume prune此外,还可以使用docker system prune命令来一次性清理所有未使用的容器、镜像和卷,加上-a参数可以清理所有未使用的资源,包括有标签但未被引用的镜像和容器卷 ,如docker system prune -a。通过定期执行这些清理命令,可以有效地释放磁盘空间,保持系统的整洁和高效运行。
8.总结与展望

在使用 Docker 的过程中,我们从基础搭建时的安装适配和镜像拉取问题,到深入容器运行时的资源限制、端口映射难题,再到镜像构建的臃肿与安全隐患,多容器协作的配置语法和服务依赖困境,数据管理的数据丢失与共享冲突,以及监控维护的日志管理和容器清理烦恼,可谓是 “一路坎坷”。但正是这些问题,让我们更加深入地理解了 Docker 的工作原理和机制,也积累了宝贵的实践经验。
Docker 作为容器化技术的佼佼者,未来的发展趋势十分令人期待。随着云计算的不断普及和微服务架构的广泛应用,Docker 将在更多的场景中发挥重要作用。它将与 Kubernetes 等容器编排工具更加紧密地结合,实现容器化应用的自动化部署、扩展和管理 ,为企业提供更加高效、可靠的解决方案。
希望我的这些经验分享能够帮助大家在使用 Docker 的过程中少走弯路。也欢迎各位读者在评论区分享自己在使用 Docker 时遇到的问题和解决方法,让我们共同学习,共同进步,一起在容器化的技术浪潮中乘风破浪。
15个关键字解说
Docker:开源容器引擎,把应用与依赖打包成轻量镜像,实现一次构建、到处运行。
镜像:只读模板,含文件系统与元数据,容器启动时以此为蓝本。
容器:镜像的运行实例,彼此隔离,秒级启停,生命周期短暂。
Dockerfile:声明式脚本,用指令逐层构建镜像,决定体积与安全。
镜像加速:国内源替换 Docker Hub,解决拉取慢、超时、断流问题。
资源限制:利用--cpus、-m等参数给容器设上限,防止资源战争拖垮宿主机。
端口映射:-p 宿主机端口:容器端口,打通外部访问,需避冲突与防火墙。
数据卷:独立于容器的持久化目录,删容器不丢数据,支持多容器共享。
docker-compose:单机编排工具,用 YAML 描述多服务依赖、网络与卷。
健康检查:定义探针命令,确保依赖服务就绪后再启动下游容器。
镜像瘦身:选 Alpine、多阶段构建、.dockerignore、合并 RUN 减少层。
密钥泄漏:禁止把密码、Token 写进镜像,应使用环境变量或 Vault 动态注入。
日志卷:把容器内日志目录挂载到宿主机,集中收集,方便排查。
ELK:Elasticsearch+Logstash+Kibana 组合,用于大规模日志检索与可视化。
定时清理:docker system prune、volume prune 等命令,定期释放磁盘空间。
写在最后:
希望这篇博客能够为你在Docker容器开发和部署项目中提供一些启发和指导。如果你有任何问题或需要进一步的建议,欢迎在评论区留言交流。让我们一起探索IT世界的无限可能!
博主还分享了本文相关文章,请各位大佬批评指正:
1、Intellij idea高效使用教程
2、AI编程工具合集
3、CodeGeeX一款基于大模型全能的智能编程助手
4、Git 代码提交注释管理规范
5、解释 Git 的基本概念和使用方式。
6、postman介绍、安装、使用、功能特点、注意事项
7、Windows10安装Docker Desktop(大妈看了都会)
8、02-pycharm详细安装教程(大妈看了都会)
9、01-Python详细安装教程(大妈看了都会)
10、2024年最新版IntelliJ IDEA下载安装过程(含Java环境搭建)
感谢以下文章提供参数:
1、最新IntelliJ IDEA下载安装以及Java环境搭建教程(含Java入门教程)
2、https://kimi.moonshot.cn/
3、分享一下快速搭建IntelliJ IDEA开发环境的完整教程
4、JDK的环境配置(超详细教程)
5、下载与安装启动(IntelliJ IDEA | JDK | Maven)
6、Java编程神器对决:飞算JavaAI单挑全球劲旅