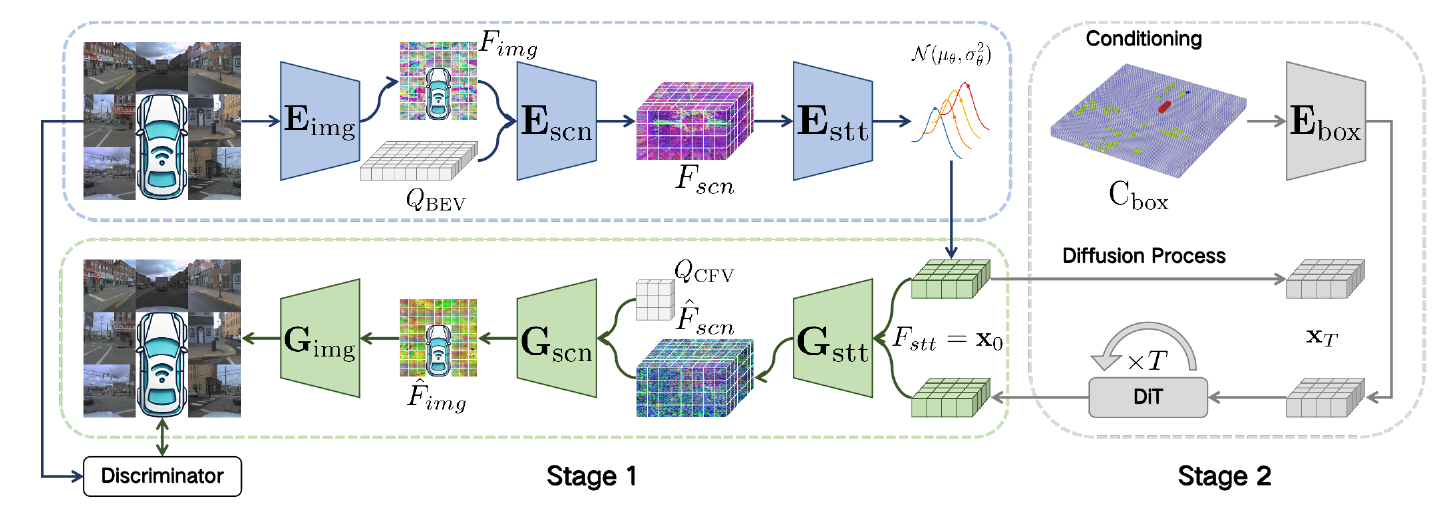
BEV-VAE
论文提出目标
为训练端到端驾驶模型特别是NVS提供数据增强手段。
现有方法特点
- 主流的都是基于微调的Stable Diffusion模型
- 多视角图像生成视为带有相邻视角一致性约束的二维合成任务
- 只能一定程度的保证空间一致性
- 依赖于图像空间中视角相关的交叉注意力机制来隐式建模3D结构,缺乏统一的结构化表征
- 难以支持任意相机位姿的新视角合成,也无法直接基于3D布局进行可控生成
- 3D bbox的二维投影导致深度丢失,不同物体的投影在图像空间中overlap,引入遮挡歧义
- 生成模型必须同时学习生成跨视角空间一致的图像
- 夸视角具有歧义的二维条件对齐很难,训练过程复杂且几何基础薄弱
BEV-VAE的特点
- 统一3D场景表征的多视角图像生成
- 编码阶段显式构建空间对齐的BEV潜在空间
- BEV空间中直接实现基于扩散模型的生成方案
- 跨视角对齐实现高保真重建
- BEV潜在空间支持通过操控相机位姿实现新视角合成,支持任意相机位姿进行NVS
- 允许基于3D物体布局(如改变物体数量、位置或类别)的可控生成
- 生成全部7V 环视图像的方法,证明了鲁棒性和实用性
实现思路与框架

图1:多视角图像生成两种范式的对比。(a) 图像潜在空间生成依赖3D物体的2D投影指导图像合成,通过跨视角注意力机制强制实现空间一致性;(b) BEV潜在空间生成以3D OCC为条件产生统一表征,从中解码出所有视角,天然保持空间一致性,并可通过调整相机位姿实现新视角合成。
链接
GitHub - Czm369/bev-vae: BEV-VAE: Multi-view Image Generation with Spatial Consistency for Autonomous Driving