操作系统-虚拟内存篇
虚拟内存
虚拟内存的设计目标是避免程序直接操作物理内存—— 若程序直接引用绝对物理地址,可能因地址冲突导致程序互相干扰,甚至引发系统崩溃。其实现核心是 “地址隔离与映射”:
虚拟内存的概念是由操作系统为每个程序分配一套虚拟地址,然后再由一个中间结构来记录虚拟地址到真实地址的映射关系
由此我们得出结论
- 程序使用的内存地址为虚拟内存地址
- 硬件使用的内存地址为物理内存地址
操作系统使用CPU芯片中的内存管理单元(MMU)实现虚拟地址和真实地址的映射
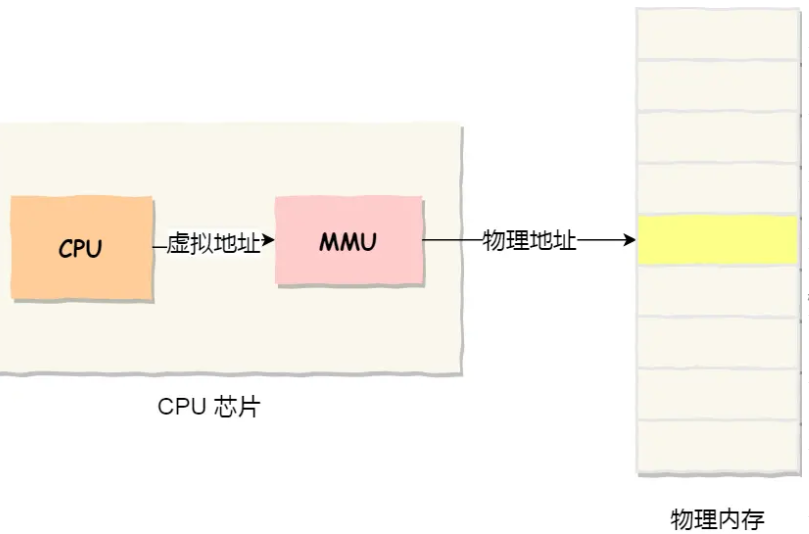
那么MMU是怎么实现这种映射关系的呢
是通过内存分段和内存分页来实现的
内存分段
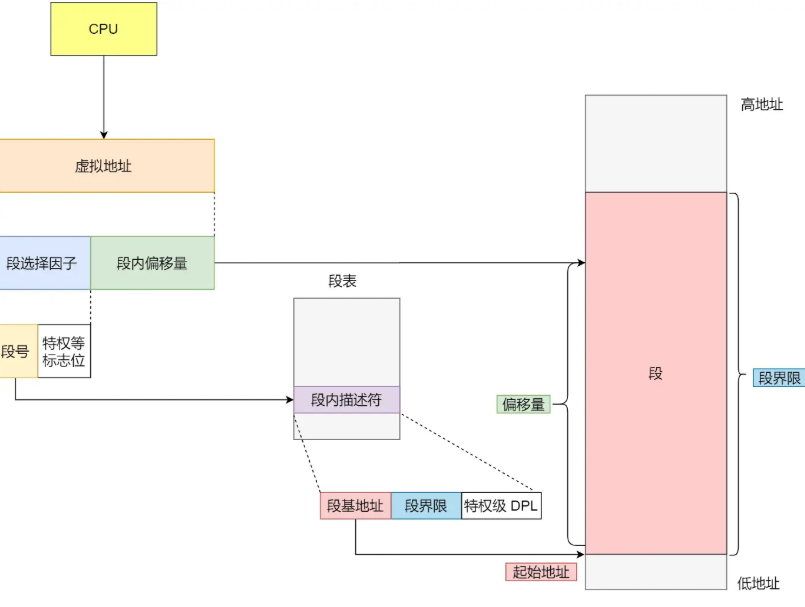
内存分段的核心思路是:按程序的功能模块(如代码段、数据段、栈段)划分虚拟地址空间,每个模块对应一个 “段”,再通过段表实现虚拟段到物理段的映射。
虚拟地址通过段表和物理地址做映射,通过段号作为索引快速找到段基地址和段界限等信息。段基地址就是当前段在物理内存中的起始位置,加上偏移量就是这个虚拟地址需要的全部真实物理地址空间。然而分段的方式会导致2个问题的出现
- 内存碎片
- 内存交换效率低
内存碎片的产生这里就不细讲了,参考JVM中的标记-清除算法大概心里就清楚了。
不过内存碎片分为外部内存碎片和内部内存碎片,对于分段来说,是按程序大小分配的段空间,一般不存在内部内存碎片,只会存在外部内存碎片,也就是段段之间的空间无法再分配导致浪费的情况。
为了解决内存碎片的问题,引入了内存交换方法
内存交换的本质如下,a和b两个段之间有100m空间碎片无法被利用,将b传入磁盘再重传内存中,重传的时候直接紧跟a后面实现,对于这个内存交换空间也成为Swap空间,是从磁盘划分出来用于磁盘和内存的空间交换。
从这里我们大概也能知道为什么交换效率低了,空间碎片不可避免且如果启动关闭程序变得频繁,内存碎片增多,交换次数上升,而交换是通过磁盘IO来操作的,一切就不言而喻了。于是出现了内存分页
内存分页
分页的本质是将虚拟内存和物理内存也按照固定大小进行连续划分,并且一一映射,减少了内存交换的数据数量。使用段的时候,每次交换都需要以段为单位,现在交换以页为单位
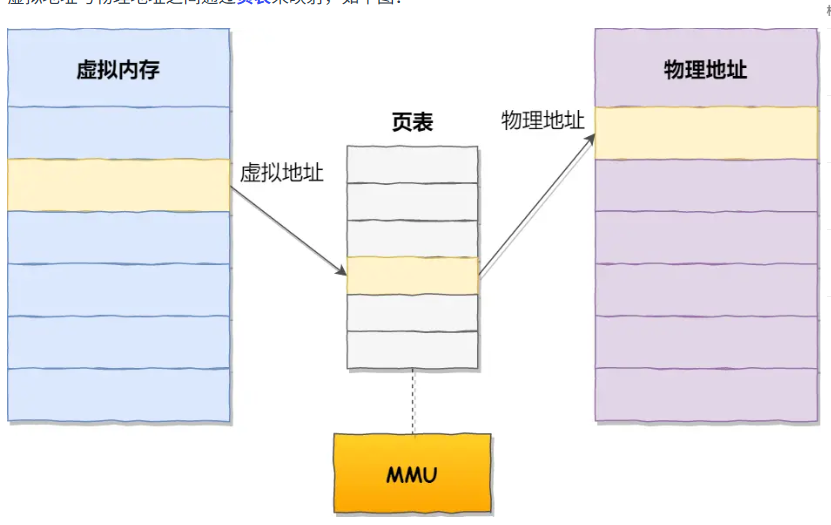
如果进程需要的虚拟内存无法找到对应物理内存,系统就会产生缺页异常来进入系统内核态,由内核分配物理空间并更新页表,恢复程序正常运行
内存分页机制下,分配内存的基本单位为页,因此可能会出现内部内存碎片的问题,不过也问题不大,页本身就很小,即使有大量这点碎片无足轻重。并且每个程序只能产生1个内部内存碎片,因此不可能出现碎片过多程序拖慢的问题
分页的映射实际上是和分段差不多的,不过做了优化,由于页很小,因此页数是很多的,如果做一一映射会导致大量内存用来存储页表
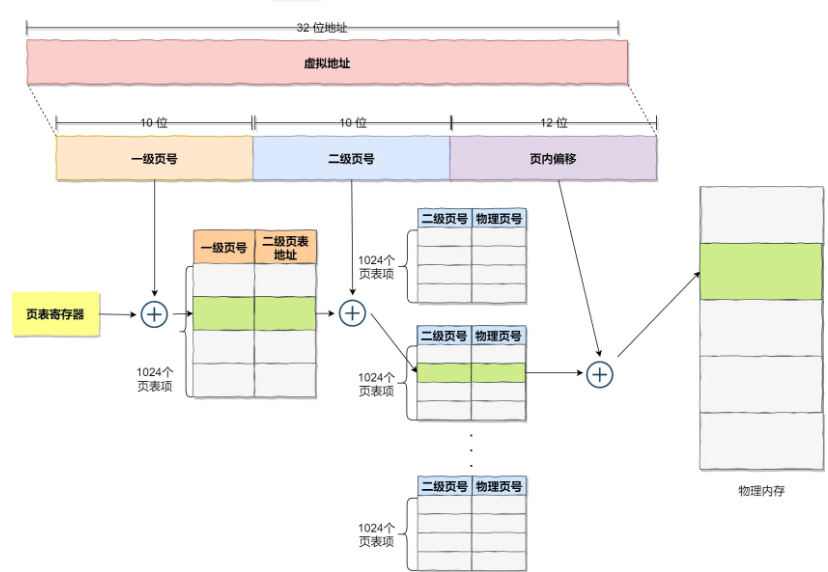
为了解决上诉问题,又引入了多级页表的概念,概念图如下
一级页表的痛点
以 32 位系统、4KB 页大小为例:
- 虚拟地址空间总大小 = 4GB,每页 4KB,因此虚拟页数量 = 4GB / 4KB = 1,048,576 个(约 100 万);
- 若采用 “一级页表”,每个页表项需 4 字节(存储物理页号等信息),则一级页表总大小 = 100 万 × 4 字节 = 4MB。
这会导致两个问题:
- 空间浪费:每个程序无论实际使用多少虚拟页,都需分配 4MB 页表空间
- 内存占用高:若系统同时运行 100 个程序,仅页表就需占用 400MB 物理内存,资源消耗过大。
多级页表的优化逻辑
多级页表的核心是 “按需创建下级页表”—— 将虚拟地址的 “页号” 拆分为多个层级,仅为已使用的虚拟页创建下级页表,未使用的层级无需分配空间。以 “二级页表” 为例:
- 虚拟地址拆分:将 32 位虚拟地址拆分为 “一级页号(10 位) + 二级页号(10 位) + 页内偏移量(12 位)”;
- 一级页表作用:仅存储 “一级页号 → 二级页表基地址” 的映射,每个一级页表项对应一个二级页表;
- 二级页表作用:存储 “二级页号 → 物理页号” 的映射,仅为已使用的虚拟页创建二级页表项。
(3)二级页表的空间优势
仍以 32 位系统、4KB 页大小为例:
- 一级页表项数量 = 2^10 = 1024 个,总大小 = 1024 × 4 字节 = 4KB;
- 每个二级页表项数量 = 2^10 = 1024 个,总大小 = 4KB;若程序仅使用 10 个虚拟页,则仅需创建 1 个二级页表(4KB),无需创建其他 1023 个二级页表;
- 程序总页表空间 = 一级页表(4KB) + 1 个二级页表(4KB) = 8KB,远小于一级页表的 4MB,空间利用率大幅提升。
段页式内存管理
分段的优势是 “按功能模块隔离地址”,分页的优势是 “无外部碎片、交换效率高”。通过 “段页式内存管理”—— 先分段,再分页,实现完美结合
1. 段页式的核心逻辑
将虚拟地址空间先按 “段” 划分(如代码段、数据段),每个段再按 “页” 划分(固定大小的虚拟页),物理内存仅按 “页” 划分。映射过程分为三步:
- 段表查询:虚拟地址中的 “段号” 查询段表,获取该段的 “页表基地址”(每个段对应一个独立的页表);
- 页表查询:用虚拟地址中的 “页号” 查询该段对应的页表,获取 “物理页号”
- 计算物理地址:物理地址 = 物理页号 × 页大小 + 页内偏移量。
2. 段页式的优势与应用
- Windows、Linux、macOS 这些主流操作系统均采用段页式内存管理,平衡了地址隔离性、内存利用率与访问性能;
- 只有很少的内部内存碎片且提高了交换效率,并且有了分段的优势,程序之间的隔离性提高