【CUDA进阶】MMA分析Bank Conflict与Swizzle(上)
目录
- 前言
- 1. 简述
- 2. MMA(Matrix Multiply-Accumulate)介绍
- 2.1 mma.m16n8k16 矩阵片段
- 2.2 乘加指令:mma
- 2.3 Warp 级矩阵加载指令:ldmatrix
- 2.4 Warp 级矩阵存储指令:stmatrix
- 3. 开发环境及框架搭建
- 4. hgemm_v1_mma_m16n8k16_naive_kernel
- 4.1 代码分析
- 4.2 LDMATRIX_X2_T 宏定义解析
- 4.3 LDMATRIX_X4 宏定义解析
- 4.4 HMMA16816 宏定义解析
- 结语
- 下载链接
- 参考
前言
学习 UP 主 比飞鸟贵重的多_HKL 的 【CUDA进阶】MMA分析Bank Conflict与Swizzle(已完结) 视频,记录下个人学习笔记,仅供自己参考😄
refer 1:【CUDA进阶】MMA分析Bank Conflict与Swizzle(已完结)
refer 2:https://github.com/xlite-dev/LeetCUDA
refer 3:https://github.com/Bruce-Lee-LY/cuda_hgemm
refer 4:https://github.com/Chtholly-Boss/swizzle
refer 5:https://chatgpt.com
1. 简述
上个 CUDA 系列我们主要讲了利用 tensor core 来加速 hgemm 半精度矩阵乘法,这个系列我们来讲 tensor core 的 MMA 接口、分析 bank conflict 问题以及学习 swizzle 解决方法
上个系列中我们使用的是 CUDA 封装好的 WMMA API 接口来实现 Hgemm,其优化思路和我们通用矩阵乘法 GEMM 和浮点数通用矩阵乘法 Sgemm 是一样的,但它实现的代码看起来更简单一些,因为很多操作都被简化了,WMMA 直接帮我们封装好了,我们只需要按照接口提供对应的数据即可,具体的乘法实现我们并不需要关注,相当于我们不用去写那些底层的东西
这个系列想要讲的核心内容是更细致的去分析一下之前的代码存在什么问题(例如 bank conflict),那这些问题其实相对来讲是比较隐晦的,我们如果使用 WMMA 接口是很难分析很难优化的,因此这里我们将换成更底层的 MMA 接口,这样一来我们就可以很容易地分析出 bank conflict 问题是怎么产生的,以及该如何利用 swizzle 等方法来解决它
我们主要参考的资料是 NVIDIA 官方文档:https://docs.nvidia.com/cuda/parallel-thread-execution/#warp-level-matrix-instructions-for-mma
2. MMA(Matrix Multiply-Accumulate)介绍
以下内容均翻译自官方文档:https://docs.nvidia.com/cuda/parallel-thread-execution/#warp-level-matrix-instructions
PTX 提供了两种执行矩阵乘累加计算的方法:
使用 wmma 指令:
这种线程束级别的计算由线程束中的所有线程协同执行,步骤如下:
- 使用
wmma.load操作将矩阵 A、B 和 C 从内存加载到寄存器中。操作完成后,每个线程中的目标寄存器会保存所加载矩阵的一个片段(fragment) - 对已加载的矩阵使用
wmma.mma操作执行矩阵乘累加运算。操作完成后,每个线程中的目标寄存器会保存由wmma.mma操作返回的结果矩阵的一个片段 - 使用
wmma.store操作将结果矩阵 D 存储回内存。或者,结果矩阵 D 也可以作为后续wmma.mma操作的参数 C wmma.load和wmma.store指令在为wmma.mma操作从内存加载输入矩阵以及将结果存储回内存时,会隐式处理矩阵元素的组织方式
使用 mma 指令:
与 wmma 类似,mma 也要求由线程束中的所有线程协同执行计算。不过在线程束中不同线程间分配矩阵元素,需要在调用 mma 操作前显式完成。mma 指令支持稠密矩阵和稀疏矩阵。当矩阵 A 是结构化稀疏矩阵时,可以使用稀疏矩阵变体
Note:PTX(Parallel Thread Execution) 是 NVIDIA 的虚拟指令集(ISA),CUDA C++ 编译器会先把你的内核(Kernel)翻译成 PTX,然后 Driver JIT 再把 PTX 转成最终 GPU 的机器码。我们可以把 PTX 想象成 NVIDIA GPU 的 “中间汇编语言” 或 “虚拟机器码”—就像 Java 的字节码(bytecode)或编译器里的中间表示(IR)一样
mma 指令对于 .f16 数据类型支持多种矩阵 shape 的计算包括 .m8n8k4、.m16n8k8、.m16n8k16,下面我们以常见的 .m16n8k16 矩阵 shape,数据类型 .f16 为例来讲解,其它类似
2.1 mma.m16n8k16 矩阵片段
执行浮点类型的 mma.m16n8k16 指令的 warp 会计算一个形状为 .m16n8k16 的 MMA 操作。矩阵的元素在 warp 中按线程分布,每个线程持有矩阵的一个片段
乘数 A:
| 寄存器类型 | 矩阵片段 | 元素顺序(从低到高) |
|---|---|---|
.f16 | 一个包含四个 .f16x2 寄存器的向量表达式,每个寄存器中包含两个来自矩阵 A 的 .f16 元素 | a0,a1,a2,a3,a4,a5,a6,a7 |
矩阵片段在各线程间的布局如下图所示:
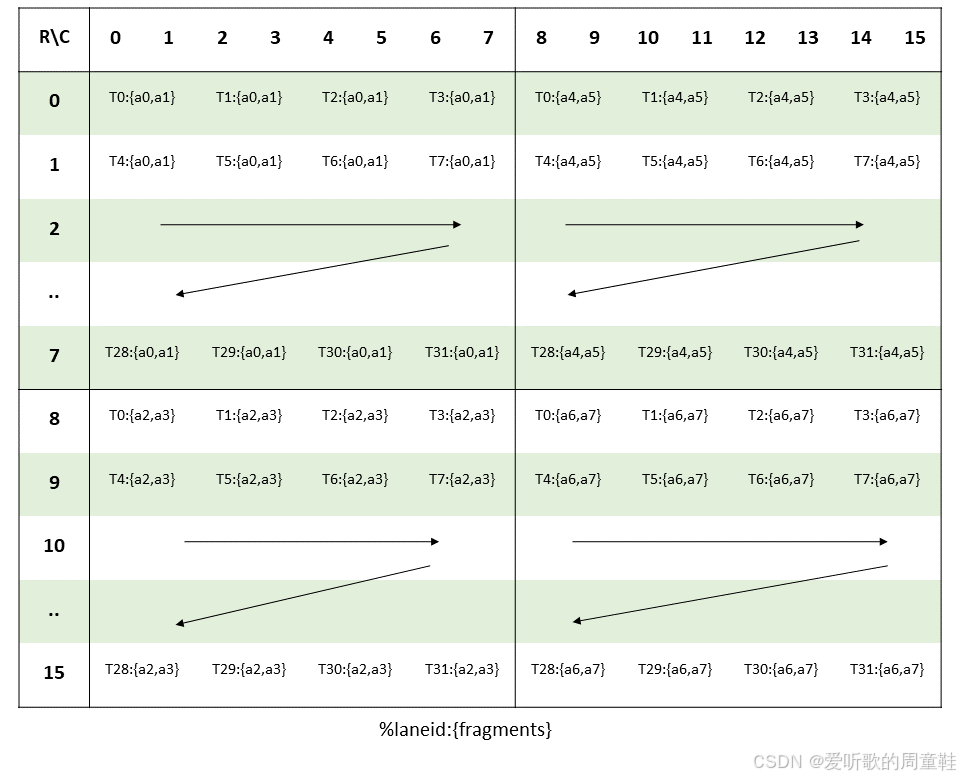
我们来简单分析下这个布局图:(from ChatGPT)
- 行(R):对应 A 片段在 M 维度上的 16 个元素行,编号 0…15
- 列(C):对应 A 片段在 K 维度上的 16 个元素列,编号 0…15,为了把每个
.f16x2寄存器映射到双列上的两个.f16元素,图中把 K=16 划分成 8 个单元格,每个单元格跨实际的两列元素
而表格中每个方格的内容形如:
T<laneId>:{aX,aY}
Tn表示 warp 中的第 n 号线程(也就是 PTX 里的%laneid){aX,aY}表示该线程用一个.f16x2寄存器载入了 A 片段中的两个.f16元素
矩阵片段行和列的计算方式为:
groupID = %laneid >> 2
threadID_in_group = %laneid % 4row = groupID for ai where 0 <= i < 2 || 4 <= i < 6groupID + 8 Otherwisecol = (threadID_in_group * 2) + (i & 0x1) for ai where i < 4
(threadID_in_group * 2) + (i & 0x1) + 8 for ai where i >= 4
乘数 B:
| 寄存器类型 | 矩阵片段 | 元素顺序(从低到高) |
|---|---|---|
.f16 | 一个包含两个 .f16x2 寄存器的向量表达式,每个寄存器中包含两个来自矩阵 B 的 .f16 元素 | b0,b1,b2,b3 |
矩阵片段在各线程间的布局如下图所示:
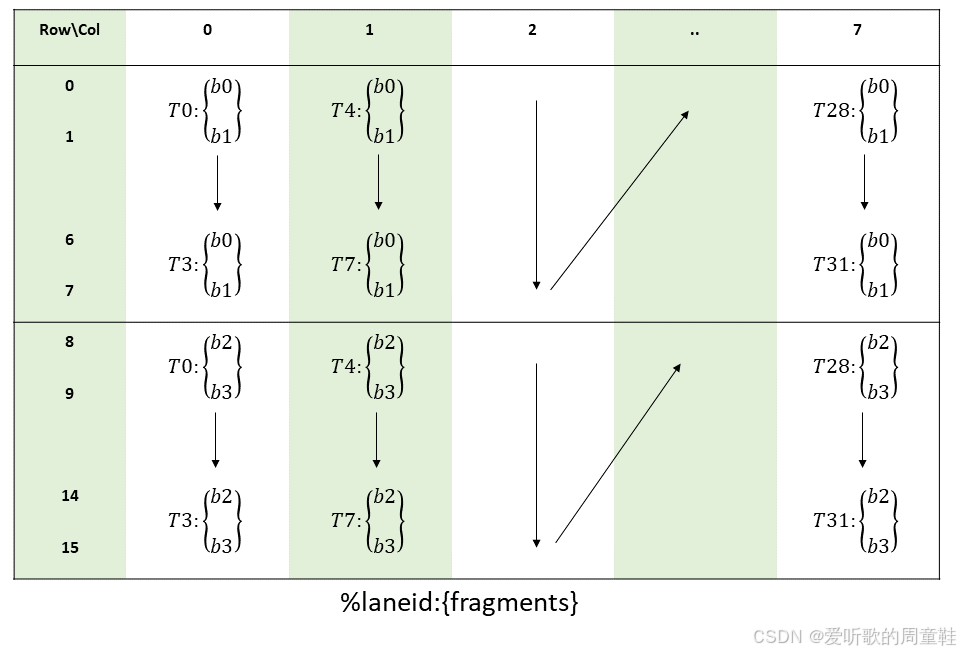
矩阵片段行和列的计算方式为:
groupID = %laneid >> 2
threadID_in_group = %laneid % 4row = (threadID_in_group * 2) + (i & 0x1) for bi where i < 2(threadID_in_group * 2) + (i & 0x1) + 8 for bi where i >= 2col = groupID
累加器 C 或 D:
| 寄存器类型 | 矩阵片段 | 元素顺序(从低到高) |
|---|---|---|
.f16 | 一个包含两个 .f16x2 寄存器的向量表达式,每个寄存器中包含两个来自矩阵 C(或 D) 的 .f16 元素 | c0,c1,c2,c3 |
矩阵片段在各线程间的布局如下图所示:
矩阵片段行和列的计算方式为:
groupID = %laneid >> 2
threadID_in_group = %laneid % 4row = groupID for ci where i < 2groupID + 8 for ci where i >= 2col = (threadID_in_group * 2) + (i & 0x1) for ci where i = {0,..,3}
Note:上面三个矩阵片段的在个线程间的布局图(Figure 1-3)非常重要,需要我们重点理解,这三张图将围绕着我们整个系列,后面我们也会经常提及!!!
2.2 乘加指令:mma
mma:执行矩阵乘累加操作
语法
半精度浮点类型:
mma.sync.aligned.m8n8k4.alayout.blayout.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k8.row.col.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k16.row.col.dtype.f16.f16.ctype d, a, b, c;.alayout = {.row, .col};
.blayout = {.row, .col};
.ctype = {.f16, .f32};
.dtype = {.f16, .f32};
描述
执行一个 MxNxK 的矩阵乘累加操作:
D = A * B + C
其中 A 矩阵为 MxK,B 矩阵为 KxN,C 和 D 矩阵为 MxN
- 同步与对齐:
.sync限定符强制线程等待全部 warp 线程执行相同mma指令后再继续.aligned限定符强制所有线程使用相同限定符,否则行为未定义
- 主序与次序:限定符
.alayout、.blayout分别用来指示 A、B 的行主或列主排序 - 元素类型:限定符
.atype、.btype、.ctype、.dtype指定 A、B、C、D 矩阵元素 - 操作数:
a、b为乘数 A、B 矩阵片段,c、d为累加器 C 和输出 D 矩阵片段
使用示例如下:
// f16 elements in C and D matrix
.reg .f16x2 %Ra<4>, %Rb<2>, %Rc<2>, %Rd<2>;
mma.sync.aligned.m16n8k16.row.col.f16.f16.f16.f16{%Rd0, %Rd1},{%Ra0, %Ra1, %Ra2, %Ra3},{%Rb0, %Rb1},{%Rc0, %Rc1};
2.3 Warp 级矩阵加载指令:ldmatrix
ldmatrix:从 共享内存 中同时加载一个或多个矩阵用于 mma 指令
语法
ldmatrix.sync.aligned.shape.num{.trans}{.ss}.type r, [p];ldmatrix.sync.aligned.m8n16.num{.ss}.dst_fmt.src_fmt r, [p];
ldmatrix.sync.aligned.m16n16.num.trans{.ss}.dst_fmt.src_fmt r, [p];.shape = {.m8n8, .m16n16};
.num = {.x1, .x2, .x4};
.ss = {.shared{::cta}};
.type = {.b16, .b8};
.dst_fmt = { .b8x16 };
.src_fmt = { .b6x16_p32, .b4x16_p64 };
{.trans}(可选),对加载的数据做转置r为目的寄存器列表p为共享内存地址操作数
描述
该指令由整个 warp 的所有线程协同执行,从由操作数 p 指定的共享内存地址(.shared 空间 )中一次性整体加载一个或多个矩阵分片到寄存器 r 中
- 通过
.shape指定每个矩阵的维度 - 通过
.num指定每次加载多少个矩阵 - 可选的
trans表示对加载后的矩阵分片做转置 .type决定元素类型
下表列出了每种 .shape 的矩阵加载情况:
| .shape | Matrix shape | Element size |
|---|---|---|
.m8n8 | 8x8 | 16-bit |
.m16n16 | 16x16 | 8-bit or 6-bit or 4-bit |
.m8n16 | 8x16 | 6-bit or 4-bit |
连续的 row 实例不需要在内存中连续存储。每个矩阵所需的八个地址由八个线程提供,具体取决于 .num 的值,如下表所示,每个地址对应于矩阵行开始。地址 addr0-addr7 对应于第一个矩阵的行,地址 addr8-addr15 对应于第二个矩阵的行,依此类推。
.num | Threads 0-7 | Threads 8-15 | Threads 16-23 | Threads 24-31 |
|---|---|---|---|---|
.x1 | addr0-addr7 | - | - | - |
.x2 | addr0-addr7 | addr8-addr15 | - | - |
.x4 | addr0-addr7 | addr8-addr15 | addr16-addr23 | addr24-addr31 |
读取 8x8 矩阵时,每 4 个连续线程共同加载 16 字节,所用地址必须按自然对齐方式设置。在一个 warp 中,每个线程都从它寄存器 r 中接收该行片段-线程 0 接收其寄存器中的第 1 个 16 位元素对,线程 1 接收第 2 个,以此类推,4 个线程就能合力完成一整行的加载
下图展示了针对一个 8x8 矩阵(元素宽度 16 位)在一个 warp 内的分片布局:
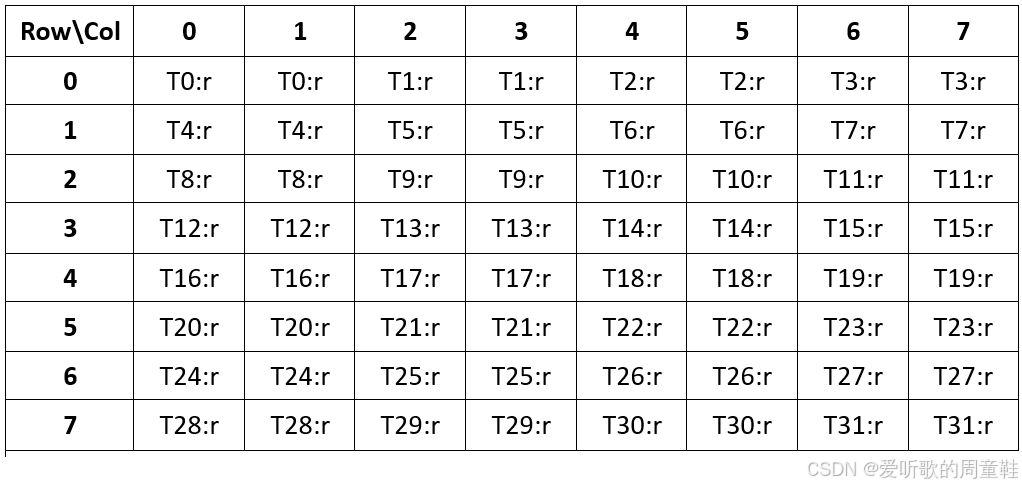
- 每行有 8 个元素,按列 0…7 编号,线程
laneId决定它加载哪一行
row = floor(laneId / 4) // 0 → 0,1,2,3 的线程加载第 0 行// 4 → 4,5,6,7 的线程加载第 1 行// … 以此类推至第 7 行
col = (laneId % 4) * 2 // 每个线程加载两个连续的列// 例如 laneId=0 → col=0,1;laneId=1 → col=2,3
- 线程 0-3 加载矩阵第 0 行的 col 0-1,2-3,4-5,6-7;线程 4-7 加载矩阵第 1 行,线程 8-11 加载第 2 行,以此类推
- 每个线程的寄存器
r中,存放了两个 16 位元素数据
当 .num = .x2 时,第二个矩阵的元素会按照上表中的布局被加载到每个线程的下一个目标寄存器中。类似地,当 .num = .x4 时,第三个和第四个矩阵的元素会被加载到每个线程的后续目标寄存器中。
使用示例如下:
// Load a single 8x8 matrix using 64-bit addressing
.reg .b64 addr;
.reg .b32 d;
ldmatrix.sync.aligned.m8n8.x1.shared::cta.b16 {d}, [addr];// Load two 8x8 matrices in column-major format
.reg .b64 addr;
.reg .b32 d<2>;
ldmatrix.sync.aligned.m8n8.x2.trans.shared.b16 {d0, d1}, [addr];// Load four 8x8 matrices
.reg .b64 addr;
.reg .b32 d<4>;
ldmatrix.sync.aligned.m8n8.x4.b16 {d0, d1, d2, d3}, [addr];// Load one 16x16 matrices of 64-bit elements and transpose them
.reg .b64 addr;
.reg .b32 d<2>;
ldmatrix.sync.aligned.m16n16.x1.trans.shared.b8 {d0, d1}, [addr];// Load two 16x16 matrices of 64-bit elements and transpose them
.reg .b64 addr;
.reg .b32 d<4>;
ldmatrix.sync.aligned.m16n16.x2.trans.shared::cta.b8 {d0, d1, d2, d3}, [addr];// Load two 16x16 matrices of 6-bit elements and transpose them
.reg .b64 addr;
.reg .b32 d<4>;
ldmatrix.sync.aligned.m16n16.x2.trans.shared::cta.b8x16.b6x16_p32 {d0, d1, d2, d3}, [addr];
对于 ldmatrix 有以下几点需要重点说明:
1. 对于 half(16-bit)矩阵元素的加载仅支持 8x8 大小,要加载 16x16 大小的 half 矩阵元素时需要使用 .num 参数,即 .x4
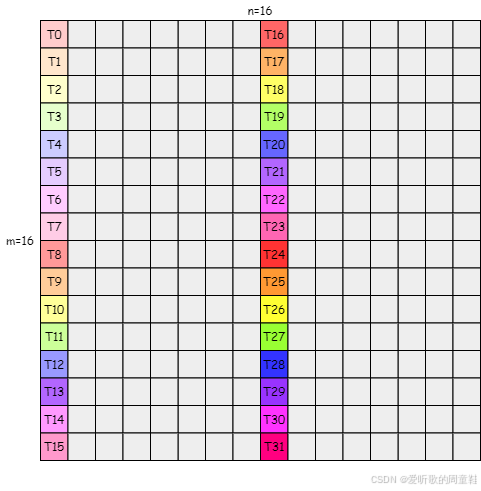
2. 对于一个 8x8 矩阵(元素类型 half, 16-bit)在利用 ldmatrix 指令将数据从 shared memory 加载到 register 中时,需要由 8 个线程提供 8 个 shared memory 起始地址,如 Figure 5 所示,但是 8x8 矩阵所有元素并不是只加载到这 8 个线程的寄存器中,而是加载到 warp 内 32 个线程的寄存器中,加载后的布局图如 Figure 4 所示,也就是 Figure 1 中的左上部分(1/4 区域)
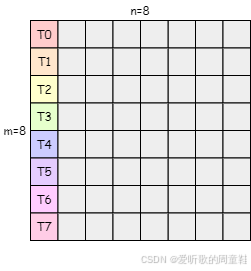
3. 对于 16x16 矩阵的加载则需要 4 个 8x8 组别,每个组别各需要 8 个线程提供 shared memory 的起始地址,总共需要 32 个线程即一个 warp 来提供 32 个地址,这 32 个线程提供的 shared memory 起始地址如 Figure 6 所示,加载后的布局图如 Figure 1 所示
2.4 Warp 级矩阵存储指令:stmatrix
stmatrix:将一个或多个矩阵同时存储到共享内存中
语法
stmatrix.sync.aligned.shape.num{.trans}{.ss}.type [p], r;.shape = {.m8n8, .m16n8};
.num = {.x1, .x2, .x4};
.ss = {.shared{::cta}};
.type = {.b16, .b8};
描述
由整个 warp 的所有线程协同执行,将一个或多个矩阵分片存储到由地址操作数 p 指定的 .shared 共享内存空间中。如果未显式指定状态空间,则采用通用寻址模式,使 p 中的地址指向 .shared 空间;若通用地址不在 .shared 空间内,则行为未定义。
.shape限定存储矩阵的维度,每个元素位宽由.type决定;其中.m16n8仅在.b8类型下可用.num为.x1、.x2、.x4时,分别表示存储一个、两个或四个矩阵- 强制性的
.sync表示所有线程必须同步执行该指令,强制性的.aligned表示所有线程必须使用相同的限定符执行;在有条件执行的代码中,务必确保所有线程评估条件结果一致,否则行为未定义
源操作数 r 是一个大括号括起的向量表达式,包含 1、2 或 4 个 32 位寄存器(对应 .num 的值),每个寄存器保存一个矩阵分片。
使用示例如下:
// Store a single 8x8 matrix using 64-bit addressing
.reg .b64 addr;
.reg .b32 r;
stmatrix.sync.aligned.m8n8.x1.shared.b16 [addr], {r};// Store two 8x8 matrices in column-major format
.reg .b64 addr;
.reg .b32 r<2>;
stmatrix.sync.aligned.m8n8.x2.trans.shared::cta.b16 [addr], {r0, r1};// Store four 8x8 matrices
.reg .b64 addr;
.reg .b32 r<4>;
stmatrix.sync.aligned.m8n8.x4.b16 [addr], {r0, r1, r2, r3};// Store a single 16x8 matrix using generic addressing
.reg .b64 addr;
.reg .b32 r;
stmatrix.sync.aligned.m16n8.x1.trans.shared.b8 [addr], {r};// Store two 16x8 matrices
.reg .b64 addr;
.reg .b32 r<2>;
stmatrix.sync.aligned.m16n8.x2.trans.shared::cta.b8 [addr],{r0, r1};// Store four 16x8 matrices
.reg .b64 addr;
.reg .b32 r<4>;
stmatrix.sync.aligned.m16n8.x4.b8 [addr], {r0, r1, r2, r3};
更多细节大家可以查看 CUDA PTX 官方文档:https://docs.nvidia.com/cuda/parallel-thread-execution/#warp-level-matrix-instructions
3. 开发环境及框架搭建
整个项目的目录结构如下:
cuda_learn/
├── CMakeLists.txt
└── mma_and_swizzle├── CMakeLists.txt├── common│ ├── common.h│ ├── cuda_timer.h│ ├── logging.h│ ├── matrix.h│ ├── ptx.h│ ├── tester.h│ └── util.h├── hgemm_v1_mma_m16n8k16_naive.cu├── v1_simple_wmma.cu├── v2_shared_memory_wmma.cu├── v3_shared_memory_wmma_padding.cu├── v4_shared_memory_mma.cu└── v5_shared_memory_mma_swizzle.cu3 directories, 15 files
其中 common 文件夹来自于 cuda_hgemm,hgemm 实现代码来自于 LeetCUDA 以及 swizzle,具体的内容我们后续会依次分析
cuda_learn 文件夹下的 CMakeLists.txt 内容如下:
cmake_minimum_required(VERSION 3.20.0)
project(cuda_practice VERSION 0.1.0 LANGUAGES CUDA CXX C)
set(CMAKE_CUDA_ARCHITECTURES 89)
find_package(CUDAToolkit)
add_subdirectory(mma_and_swizzle)
Note:显卡的 CUDA Compute Capability 可查询官方文档:https://developer.nvidia.com/cuda-gpus
mma_and_swizzle 文件夹下的 CMakeLists.txt 内容如下:
add_executable(hgemm_v1_mma_m16n8k16_naive hgemm_v1_mma_m16n8k16_naive.cu)
target_link_libraries(hgemm_v1_mma_m16n8k16_naive PRIVATE CUDA::cudart ${CUDA_cublas_LIBRARY})
if(CMAKE_BUILD_TYPE STREQUAL "Debug")target_compile_options(hgemm_v1_mma_m16n8k16_naive PRIVATE $<$<COMPILE_LANGUAGE:CUDA>:-G>)
else()target_compile_options(hgemm_v1_mma_m16n8k16_naive PRIVATE -lineinfo)
endif()add_executable(v1_simple_wmma v1_simple_wmma.cu)
target_link_libraries(v1_simple_wmma PRIVATE CUDA::cudart ${CUDA_cublas_LIBRARY})
if(CMAKE_BUILD_TYPE STREQUAL "Debug")target_compile_options(v1_simple_wmma PRIVATE $<$<COMPILE_LANGUAGE:CUDA>:-G>)
else()target_compile_options(v1_simple_wmma PRIVATE -lineinfo)
endif()add_executable(v2_shared_memory_wmma v2_shared_memory_wmma.cu)
target_link_libraries(v2_shared_memory_wmma PRIVATE CUDA::cudart ${CUDA_cublas_LIBRARY})
if(CMAKE_BUILD_TYPE STREQUAL "Debug")target_compile_options(v2_shared_memory_wmma PRIVATE $<$<COMPILE_LANGUAGE:CUDA>:-G>)
else()target_compile_options(v2_shared_memory_wmma PRIVATE -lineinfo)
endif()add_executable(v3_shared_memory_wmma_padding v3_shared_memory_wmma_padding.cu)
target_link_libraries(v3_shared_memory_wmma_padding PRIVATE CUDA::cudart ${CUDA_cublas_LIBRARY})
if(CMAKE_BUILD_TYPE STREQUAL "Debug")target_compile_options(v3_shared_memory_wmma_padding PRIVATE $<$<COMPILE_LANGUAGE:CUDA>:-G>)
else()target_compile_options(v3_shared_memory_wmma_padding PRIVATE -lineinfo)
endif()add_executable(v4_shared_memory_mma v4_shared_memory_mma.cu)
target_link_libraries(v4_shared_memory_mma PRIVATE CUDA::cudart ${CUDA_cublas_LIBRARY})
if(CMAKE_BUILD_TYPE STREQUAL "Debug")target_compile_options(v4_shared_memory_mma PRIVATE $<$<COMPILE_LANGUAGE:CUDA>:-G>)
else()target_compile_options(v4_shared_memory_mma PRIVATE -lineinfo)
endif()add_executable(v5_shared_memory_mma_swizzle v5_shared_memory_mma_swizzle.cu)
target_link_libraries(v5_shared_memory_mma_swizzle PRIVATE CUDA::cudart ${CUDA_cublas_LIBRARY})
if(CMAKE_BUILD_TYPE STREQUAL "Debug")target_compile_options(v5_shared_memory_mma_swizzle PRIVATE $<$<COMPILE_LANGUAGE:CUDA>:-G>)
else()target_compile_options(v5_shared_memory_mma_swizzle PRIVATE -lineinfo)
endif()
编译运行指令如下:
cd cuda_learn
mkdir build && cd build
cmake .. -DCMAKE_BUILD_TYPE=Debug && make -j24
./mma_and_swizzle/hgemm_v1_mma_m16n8k16_naive
Note:关于 common 文件夹下工具类和测试类的实现我们在 【CUDA进阶】Tensor Core实战教程(上) 文章中有分析过,这边博主就不再赘述了
OK,整个框架搭建完成后我们就来看看 GPU 上如何通过更底层的 MMA 指令来实现 hgemm
4. hgemm_v1_mma_m16n8k16_naive_kernel
在了解完 MMA 指令之后,我们一起来看看如何利用 MMA 来实现 hgemm 半精度矩阵乘法,请注意我们这个系列并不是学习 MMA 指令来优化 hgemm,而是借助它来帮我们分析 WMMA 中可能存在的 bank conflict 问题以及学习 swizzle 解决方法
因此我们来看一个原生版本的实现即可,也就是单纯调用 mma 接口不做任何优化来实现 hgemm:

我们要实现的是半精度矩阵乘法 Cm×n=Am×k×Bk×nC_{m\times n} = A_{m\times k}\times B_{k\times n}Cm×n=Am×k×Bk×n,在我们的示例中 m=512,n=2048,k=1024m=512,n=2048,k=1024m=512,n=2048,k=1024
在 V1 版本中每个 block 启动 32 个线程即一个 warp 来完成 C 中 16x8 的输出 tile,也就是每个 block 完成的是 16x1024 * 1024x8 的矩阵乘法计算
前面我们提到 mma 指令针对 .f16 数据类型支持多种 shape 的计算,这里我们使用的是 mma.m16n8k16 接口,也就是一个 warp 实现的是 16x8x16 的矩阵乘积,因此如果要实现 16x1024 * 1024x8 就需要沿着 K 维度(步长即 MMA_K = 16)不断去调用 mma 指令乘积,每次 mma 指令完成的是 16x16 * 16x8 的计算,如上图所示
4.1 代码分析
实现代码如下:
#include <iostream>
#include <cuda_runtime.h>
#include "common/tester.h"
#include "common/common.h"#define WARP_SIZE 32
#define LDST32BITS(value) (reinterpret_cast<half2 *>(&(value))[0])
#define LDST128BITS(value) (reinterpret_cast<float4 *>(&(value))[0])
#define LDMATRIX_X2_T(R0, R1, addr) \asm volatile( \"ldmatrix.sync.aligned.x2.trans.m8n8.shared.b16 {%0, %1}, [%2];\n" \: "=r"(R0), "=r"(R1) \: "r"(addr))using namespace nvcuda;// only 1 warp per block(32 threads), m16n8k16. A, B, C: all row_major.
template<const int MMA_M = 16, const int MMA_N = 8, const int MMA_K = 16>
__global__ void hgemm_mma_m16n8k16_naive_kernel(half* A, half* B, half* C, int M, int N, int K){const int bx = blockIdx.x;const int by = blockIdx.y;const int NUM_K_TILES = div_ceil(K, MMA_K);constexpr int BM = MMA_M; // 16constexpr int BN = MMA_N; // 8constexpr int BK = MMA_K; // 16__shared__ half s_a[MMA_M][MMA_K]; // 16x16__shared__ half s_b[MMA_K][MMA_N]; // 16x8__shared__ half s_c[MMA_M][MMA_N]; // 16x8const int tid = threadIdx.y * blockDim.x + threadIdx.x; // within blockconst int lane_id = tid % WARP_SIZE; // 0~31// s_a[16][16],每行 16,每线程 load 8,需要 2 线程,共 16 行,需 2x16=32 线程const int load_smem_a_m = tid / 2; // row 0~15const int load_smem_a_k = (tid % 2) * 8; // col 0,8// s_b[16][8],每行 8,每线程 load 8,需要 1 线程,共 16 行,需要 1x16=16 线程,只需 warp 中一半线程加载const int load_smem_b_k = tid; // row 0~31, but only use 0~15const int load_smem_b_n = 0; // col 0const int load_gmem_a_m = by * BM + load_smem_a_m; // global mconst int load_gmem_b_n = bx * BN + load_smem_b_n; // global nif(load_gmem_a_m >= M && load_gmem_b_n >= N){return;}uint32_t RC[2] = {0, 0};#pragma unrollfor(int k = 0; k < NUM_K_TILES; ++k){// gmem_a -> smem_aint load_gmem_a_k = k * BK + load_smem_a_k; // global col of aint load_gmem_a_addr = load_gmem_a_m * K + load_gmem_a_k;LDST128BITS(s_a[load_smem_a_m][load_smem_a_k]) = LDST128BITS(A[load_gmem_a_addr]);// gmem_b -> smem_bif(lane_id < MMA_K){int load_gmem_b_k = k * MMA_K + load_smem_b_k; // global row of bint load_gmem_b_addr = load_gmem_b_k * N + load_gmem_b_n;LDST128BITS(s_b[load_smem_b_k][load_smem_b_n]) = LDST128BITS(B[load_gmem_b_addr]);}__syncthreads();uint32_t RA[4];uint32_t RB[2];// ldmatrix for s_a, ldmatrix.trans for s_b.// s_a: (0,1) * 8 -> 0,8 -> [(0~15),(0,8)]uint32_t load_smem_a_ptr = __cvta_generic_to_shared(&s_a[lane_id % 16][(lane_id / 16) * 8]);LDMATRIX_X4(RA[0], RA[1], RA[2], RA[3], load_smem_a_ptr);uint32_t load_smem_b_ptr = __cvta_generic_to_shared(&s_b[lane_id % 16][0]);LDMATRIX_X2_T(RB[0], RB[1], load_smem_b_ptr);HMMA16816(RC[0], RC[1], RA[0], RA[1], RA[2], RA[3], RB[0], RB[1], RC[0], RC[1]);__syncthreads(); }// s_c[16][8]// https://docs.nvidia.com/cuda/parallel-thread-execution/index.html// #matrix-fragments-for-mma-m16n8k16-with-floating-point-type// [0~7][0~3 u32 -> 0~7 f16], [8~15][0~3 u32 -> 0~7 f16]LDST32BITS(s_c[lane_id / 4][(lane_id % 4) * 2]) = LDST32BITS(RC[0]);LDST32BITS(s_c[lane_id / 4 + 8][(lane_id % 4) * 2]) = LDST32BITS(RC[1]);__syncthreads();// store s_c[16][8]if(lane_id < MMA_M){// store 128 bits per memory issue.int store_gmem_c_m = by * BM + lane_id;int store_gmem_c_n = bx * BN;int store_gmem_c_addr = store_gmem_c_m * N + store_gmem_c_n;LDST128BITS(C[store_gmem_c_addr]) = LDST128BITS(s_c[lane_id][0]);}
}void hgemm_mma_m16n8k16_naive(half* A, half* B, half* C, int M, int N, int K){constexpr int WMMA_M = 16;constexpr int WMMA_N = 8;constexpr int WMMA_K = 16;dim3 block(32);dim3 grid(div_ceil(N, WMMA_N), div_ceil(M, WMMA_M));hgemm_mma_m16n8k16_naive_kernel<WMMA_M, WMMA_N, WMMA_K><<<grid, block>>>(A, B, C, M, N, K);
}int main(int argc, char* argv[]){Tester tester(512, 2048, 1024, 1, 10, 100, true);tester.evaluate(hgemm_mma_m16n8k16_naive, "hgemm_mma_m16n8k16_naive");return 0;
}
下面我们把 hgemm_mma_m16n8k16_naive_kernel 从头到尾拆解成几个大模块,并在每个模块里逐行说明它的作用、数据流和并行策略:(from ChatGPT)
1. 网格和线程组织
- Block 大小
dim3 block(32);
每个 block 只启用 32 个线程,也就是正好一个 warp。这意味着一个 block(即一个 warp)负责计算一个 16x8 的输出 tile
- Grid 大小
dim3 grid(div_ceil(N, MMA_N), div_ceil(M, MMA_M));
grid.x = ceil(N/8):沿输出矩阵列方向(N)划分 tilegrid.y = ceil(M/16):沿输出矩阵行方向(M)划分 tile
因此,网格中的每个 block(bx, by)负责输出矩阵 C 上坐标为(row=by×16,col=bx×8\text{row} = by \times 16, \ \text{col} = bx \times 8row=by×16, col=bx×8)处的 16x8 子块
2. 核函数声明与模板参数
// only 1 warp per block(32 threads), m16n8k16. A, B, C: all row_major.
template<const int MMA_M = 16, const int MMA_N = 8, const int MMA_K = 16>
__global__ void hgemm_mma_m16n8k16_naive_kernel(half* A, half* B, half* C, int M, int N, int K)
- 模板参数
MMA_MxMMA_NxMMA_K = 16x8x16:决定一次mma.sync.aligned.m16n8k16操作处理的子矩阵大小 - 输入输出指针:
A:大小 MxK 的半精度矩阵(行主)B:大小 KxN 的半精度矩阵(行主)C:大小 MxN 的半精度矩阵(行主),既是输入累加初值,也是输出
- 尺寸参数
M, N, K:原始矩阵的大小,用于边界检查和全局地址计算
3. Block/Tile 定位与常量定义
const int bx = blockIdx.x;
const int by = blockIdx.y;
const int NUM_K_TILES = div_ceil(K, MMA_K);
constexpr int BM = MMA_M; // 16
constexpr int BN = MMA_N; // 8
constexpr int BK = MMA_K; // 16
bx, by:网格坐标,每个 block 负责输出矩阵 C 中一个 16x8 的子块NUM_K_TILES = ⌈K/16⌉:要在 K 维度上分块的次数,因为一次只能载入 16 列/行(MMA_K)BM, BN, BK:分块大小
4. 分配 Shared Memory
__shared__ half s_a[MMA_M][MMA_K]; // 16x16
__shared__ half s_b[MMA_K][MMA_N]; // 16x8
__shared__ half s_c[MMA_M][MMA_N]; // 16x8
s_a用来缓存 A 的一个 16x16 的子块s_b用来缓存 B 的一个 16x8 的子块s_c用来缓存中间累加结果(对应输出的 16x8 子块)
5. 线程与 lane 索引
const int tid = threadIdx.y * blockDim.x + threadIdx.x; // within block
const int lane_id = tid % WARP_SIZE; // 0~31
tid:block 内的全局线程索引,由于 block 中我们只 launch 了 32 个 thread 即一个 warp,因此 tid 取值其实就等同于threadIdx.x即 0~31lane_id:warp 内的线程编号(0…31),后续用来做ldmatrix、mma操作的分片映射
6. Global->Shared 数据加载策略(索引计算)
// s_a[16][16],每行 16,每线程 load 8,需要 2 线程,共 16 行,需 2x16=32 线程
const int load_smem_a_m = tid / 2; // row 0~15
const int load_smem_a_k = (tid % 2) * 8; // col 0,8
// s_b[16][8],每行 8,每线程 load 8,需要 1 线程,共 16 行,需要 1x16=16 线程,只需 warp 中一半线程加载
const int load_smem_b_k = tid; // row 0~31, but only use 0~15
const int load_smem_b_n = 0; // col 0
const int load_gmem_a_m = by * BM + load_smem_a_m; // global m
const int load_gmem_b_n = bx * BN + load_smem_b_n; // global n
if(load_gmem_a_m >= M && load_gmem_b_n >= N){return;
}
load_smem_a_m:决定这个线程负责 Shared A 的哪一行(共 16 行,由 32 线程覆盖,2 线程/行)load_smem_a_k:决定当前线程是加载 0-7 还是 8-15(每组 8 元素,由同一线程一次性LDST128BITS向量加载)load_smem_b_k:决定这个线程负责 Shared B 的哪一行(共 16 行,只需要 warp 中的前一半线程加载,1 线程/行)load_smem_b_n:由于 Shared B 大小是 16x8,因此每行一个线程即可,通过向量化一次性加载 8 个元素,因此列索引为 0load_gmem_a_m:映射到全局 A 的行索引load_gmem_b_n:映射到全局 B 的列索引
7. 声明寄存器累加器片段
uint32_t RC[2] = {0, 0};
RC[2]:用来存half2结果的 2 个寄存器,一个half2包含两个 fp16
8. 主循环(K 维度分块)
每个 K-tile 循环一次,先装载 A 的子块(16x16)和 B 的子块(16x8)到 Shared Memory
8.1 将数据从 Global A/B 载入 Shared A/B
#pragma unrollfor(int k = 0; k < NUM_K_TILES; ++k){// gmem_a -> smem_aint load_gmem_a_k = k * BK + load_smem_a_k; // global col of aint load_gmem_a_addr = load_gmem_a_m * K + load_gmem_a_k;LDST128BITS(s_a[load_smem_a_m][load_smem_a_k]) = LDST128BITS(A[load_gmem_a_addr]);// gmem_b -> smem_bif(lane_id < MMA_K){int load_gmem_b_k = k * MMA_K + load_smem_b_k; // global row of bint load_gmem_b_addr = load_gmem_b_k * N + load_gmem_b_n;LDST128BITS(s_b[load_smem_b_k][load_smem_b_n]) = LDST128BITS(B[load_gmem_b_addr]);}__syncthreads();
load_gmem_a_k:映射到全局 A 的列索引load_gmem_a_addr:全局 A 的线性地址LDST128BITS:用reinterpret_cast<float4*>做 128-bit 向量化 load/store,一次搬 8 个 half(16 bytes)load_gmem_b_k:映射到全局 B 的行索引load_gmem_b_addr:全局 B 的线性地址- 只有
lane_id < 16(warp 前半)线程参与 Shared B 的加载,把 B 的 16 行各自加载 8 列(一次向量化 load 8 个 half)到 Shared B 的对应行
加载过程如下图所示:

8.2 声明寄存器片段
uint32_t RA[4]; // 存放 A 片段的 4 个 half2 矢量
uint32_t RB[2]; // 存放 B 片段的 2 个 half2 矢量
- 一个
half2包含两个 fp16,一次mma.m16n8k16需要每个线程加载 A 的 4 个 half2(共 16x16),B 的两个 half2(共 16x8)
8.3 将数据从 Shared Memory 载入寄存器:ldmatrix
// ldmatrix for s_a, ldmatrix.trans for s_b.
// s_a: (0,1) * 8 -> 0,8 -> [(0~15),(0,8)]
uint32_t load_smem_a_ptr = __cvta_generic_to_shared(&s_a[lane_id % 16][(lane_id / 16) * 8]);
LDMATRIX_X4(RA[0], RA[1], RA[2], RA[3], load_smem_a_ptr);
uint32_t load_smem_b_ptr = __cvta_generic_to_shared(&s_b[lane_id % 16][0]);
LDMATRIX_X2_T(RB[0], RB[1], load_smem_b_ptr);
__cvta_generic_to_shared:把 C 指针转换成 PTXshared空间下的地址格式- A 片段(
.m8n8.x4).x4:一次性加载 4 个 8x8 子块(即 Shared A 的整个 16x16),分给 4 个寄存器- 每个线程加载它负责的两列x两行,共 4 个 half2
- B 片段(
.m8n8.x2.trans).trans:要做转置加载,因为 B 的 Shared 布局是行主,但 MMA 需要列主.x2:每个线程一次加载 Shared B(16x8)中自己负责的两列的上下两半(共 16 行)的数据,分给 2 个寄存器
每个线程提供一个行起始地址和其对应的寄存器,ldmatrix 会通过行起始地址将开始往后的 8 个 half 变量读入到寄存器中,32 个线程提供的行起始地址如 Figure 6 所示。
但需要注意的是,读入到的寄存器并不是该线程拥有的寄存器,而是像 Figure 1 一样的布局,例如线程 0 提供的行起始地址往后的 8 个 half 变量分别赋值到了线程 0、线程 1、线程 2 以及线程 3 的各个寄存器中,并不是全部赋值到了线程 0 的寄存器
现在我们就来 Debug 验证下 warp 内的 32 个线程将 16x16 的矩阵数据从 shared memory 搬运到 register 后的布局是不是真的如 Figure 1 所示的一样
我们以 T0(thread0) 为例,如 Figure 1 所示 T0 搬运的应该是 s_a 中的 s_a[0][0], s_a[0][1]、s_a[8][0], s_a[8][1]、s_a[0][8], s_a[0][9]、s_a[8][8], s_a[8][9] 这 8 个 half,调试结果如下图所示:

先看 RA[0],我们先通过 进制转换(正整数)- 锤子在线工具 将其转换为十六进制数:

可以看到转换的十六进制数分别是 BAEE 和 3B55,接着我们再通过 Float toy 将其转换为 half:


可以看到和我们预期的一样,再来看一个 RA[3]:



大家可以自行验证下,对于 s_b 同理,其布局如 Figure 2 所示
8.4 执行 MMA
HMMA16816(RC[0], RC[1], RA[0], RA[1], RA[2], RA[3], RB[0], RB[1], RC[0], RC[1]);
__syncthreads();
等价于 PTX 指令:
mma.sync.aligned.m16n8k16.row.col.f16.f16.f16.f16{ RC0, RC1 },{ RA0, RA1, RA2, RA3 },{ RB0, RB1 },{ RC0, RC1 };
- 把 AxB 的 16x8 局部乘加结果,累加到寄存器
RC[0..1]中 __syncthreads():同步,确保本轮计算完成- 实际上 MMA 执行与 shared memory、寄存器之间不会有冲突,因此这个同步不加也可以
9. 将寄存器结果写回 Shared C
// s_c[16][8]
// https://docs.nvidia.com/cuda/parallel-thread-execution/index.html
// #matrix-fragments-for-mma-m16n8k16-with-floating-point-type
// [0~7][0~3 u32 -> 0~7 f16], [8~15][0~3 u32 -> 0~7 f16]
LDST32BITS(s_c[lane_id / 4][(lane_id % 4) * 2]) = LDST32BITS(RC[0]);
LDST32BITS(s_c[lane_id / 4 + 8][(lane_id % 4) * 2]) = LDST32BITS(RC[1]);__syncthreads();
- 每个线程的
RC[0]含子块上半(rows 0-7)对应行的 2 列,RC[1]含下半(rows 8-15) lane_id / 4:决定是第几行(lane_id % 4) * 2:决定这一行的哪两列LDST32BITS:向量化把两个half写回 Shared C,共同累积所有 K-tile 的结果
写回的过程需要遵循 C 的布局,如 Figure 3 所示
10. 将矩阵乘积结果从 Shared C 写回 Global C
// store s_c[16][8]
if(lane_id < MMA_M){// store 128 bits per memory issue.int store_gmem_c_m = by * BM + lane_id;int store_gmem_c_n = bx * BN;int store_gmem_c_addr = store_gmem_c_m * N + store_gmem_c_n;LDST128BITS(C[store_gmem_c_addr]) = LDST128BITS(s_c[lane_id][0]);
}
land_id < MMA_M:只有前 16 个线程负责把 Shared C 的 16x8 子块写回全局内存- 一次
LDST128BITS把一整行的 8 个half(128 bit)写出,连续存储到 C 的对应位置
总体数据流非常清晰,包括以下几个部分:
1. 分块(tiling):输出按 16x8 分块,输入按 16 列分块
2. Load A,B → Shared:warp 内 32 线程协作,把 A 的 16x16、B 的 16x8 块载到 shared memory
3. Shared → Fragment:ldmatrix 将 shared 布局 → 寄存器布局,同时做必要的转置
4. MMA:单指令完成一个 16x8x16 的矩阵乘积
5. 寄存器 → Shared C:把累加结果展开到 Shared C 的 16x8
6. Shared C → Global C:warp 内前半线程一次向量化写出整行
这样就完成了一个 16x8 子块的 hgemm 计算,循环所有 K-tile 后输出最终结果
4.2 LDMATRIX_X2_T 宏定义解析
博主对 LDMATRIX_X2_T 宏定义的实现有些困惑,下面我们一起来看看 LDMATRIX_X2_T 这个宏是如何定义 ldmatrix 的 PTX 指令的
#define LDMATRIX_X2_T(R0, R1, addr) \asm volatile( \"ldmatrix.sync.aligned.x2.trans.m8n8.shared.b16 {%0, %1}, [%2];\n" \: "=r"(R0), "=r"(R1) \: "r"(addr))
这个宏其实是 GNU 扩展内联汇编(extended asm)+ PTX 指令串 的壳,我们把它从外到里拆开讲:(from ChatGPT)
1. 宏本体
#define LDMATRIX_X2_T(R0, R1, addr) \asm volatile(...)
asm ...:告诉 NVCC 插入 设备端内联汇编,在 CUDA 设备函数里,这里的 “汇编” 是 PTX,不是主机 x86/ARM 指令volatile:不要优化或重排 这条 asm,对和内存交互的 PTX(如ldmatrix)通常建议加上
2. 指令串与占位符
"ldmatrix.sync.aligned.x2.trans.m8n8.shared.b16 {%0, %1}, [%2];\n"
- 这行是 原封不动的 PTX 指令,只是把真正的寄存器/地址用占位符
%0,%1,%2先占位 {%0, %1}:PTX 的 向量寄存器列表 语法,ldmatrix.x2需要 两个目的寄存器[%2]:PTX 的 内存寻址操作数 语法,%2将被替换成一个寄存器,里面放的是共享内存地址(通常来自__cvta_generic_to_shared(ptr)的返回值)
占位符编号的规则:按输出操作数先,输入操作数后 的顺序,从 0 开始编号,所以:
%0➡ 第 1 个输出%1➡ 第 2 个输出%2➡ 第 1 个输入
3. 约束与操作数三段(outputs : inputs : clobbers)
: "=r"(R0), "=r"(R1) // 输出
: "r"(addr) // 输入
// (无 clobbers)
- 这是 GUN 扩展 asm 的三段式写法:
asm("....": 输出 : 输入 : 损坏寄存器/内存) "=r"输出约束:=表示 写出(Write-only),指令会 定义 这个寄存器的值r表示这个操作数要放在一个 32 位通用寄存器 里- 这里的
R0,R1必须是 C/C++ 侧的 32 位变量(通常是uint32_t/unsigned),和 PTX 的目的寄存器一一对应 - 如果是 “读改写” 输出(既做输入又做输出),要用
"+r"(var),只写的话用"=r"
"r"(addr)输入约束:r表示把addr放进一个 32 位通用寄存器里再交给 PTX- 由于
ldmatrix ... .shared ...期望的是 共享内存地址(32 位 offset),因此在调用宏前应当传addr = __cvta_generic_to_shared(ptr); - 如果直接把 64 位通用指针传进来,既不匹配
.shared,位宽也不对
- clobbers(缺省):
- 这里没写第三段,表示 不额外声明破坏 的寄存器/内存
- 某些场景为了更严格的排序,可以在第三段加
"memory",防止编译器把周围的内存访问跨过这条 asm 语句进行重排
4. 整体的数据与寄存器流
- 输入:
addr(%2)是 本线程 提供的一行起始地址(共享内存空间),ldmatrix.x2会按照固定的 lane➡行/列映射,从[%2]起始的两块 8x8 子矩阵里为该 lane 装 两对 b16 元素 - 输出:结果写入
%0和%1(即R0、R1),每个 32 位寄存器包含 两个连续的 16-bit 元素(PTX 语义上是.b16x2,也可看作half2的比特形态) - 这两个输出随后会被当作
.f16x2片段交给mma.sync使用
5. 形参与类型要点
R0,R1最好声明为uint32_t或unsigned,这是和"r"约束最契合的 32 比特addr应为uint32_t(或unsigned),来源于:
uint32_t addr = __cvta_generic_to_shared(&s_b[lane_id % 16][0]);
这样 %2 就是合法的 32 位 .shared 地址
6. 一句话总结
这个宏做的事就是用 GNU 扩展内联汇编把一条 PTX ldmatrix.x2.trans.m8n8.shared.b16 指令嵌进去,要编译器分配三个 32 位通用寄存器来承接两个 写出(R0,R1)和一个 读入(addr)操作数;指令会从共享内存按 8x8 的转置布局为当前 lane 装两对 16-bit 元素到 R0/R1。我们在 C 侧把它们当作 uint32_t 传递即可,语义上就是两个 half 的打包(.f16x2)
4.3 LDMATRIX_X4 宏定义解析
在 4.2 小节我们对 LDMATRIX_X2_T 宏定义做了详细分析,下面我们来简要看下 LDMATRIX_X4 这个宏是如何把 Shared Memory A 的 16x16 tile 一次性搬到 4 个寄存器里的:(from ChatGPT)
1. 宏本体与约束
#define LDMATRIX_X4(R0, R1, R2, R3, addr) \asm volatile("ldmatrix.sync.aligned.x4.m8n8.shared.b16 {%0, %1, %2, %3}, [%4];\n" \: "=r"(R0), "=r"(R1), "=r"(R2), "=r"(R3) \: "r"(addr))
asm volatile(...):插入设备端 PTX 指令,volatile禁止编译器重排/删减这条指令- 指令串:
ldmatrix.sync.aligned.x4.m8n8.shared.b16.m8n8:按 8x8 矩阵分片装载.x4:每个线程装 4 份 8x8 分片(对应 4 个目标寄存器).shared.b16:从 shared 空间按 16-bit 元素 读- 无
.trans:保持原布局加载(A 一般按行主放在 shared,匹配mma ... row.col的 A 需要行主片段)
- 占位符与约束:
{%0, %1, %2, %3}➡ 4 个 输出 寄存器 ➡"=r"(R0...R3):每个都是 32-bit 通用寄存器,各自装 2xb16(等价 half2 的位模式)[%4]➡ 输入 地址 ➡"r"(addr):一个 32-bit 的 shared 地址(通常来自__cvta_generic_to_shared(...))
2. 实际加载数据
典型的地址计算是:
uint32_t addr = __cvta_generic_to_shared(&s_a[laneId % 16][(laneId / 16) * 8]);
laneId ∈ [0, 31]:warp 内线程号(laneId / 16) * 8:当laneId < 16取 0(左半 8 列),否则取 8(右半 8 列)laneId % 16:行号 0…15
这样配合 .x4 的语义:一次性把 A 的 16x16 tile 当作 4 个 8x8 子块加载,每个线程各拿到 每个子块中它负责的那“两列相邻 b16”,分别落在 R0..R3 四个寄存器:
R0⬅ 左上 8x8 子块(rows 0-7,col 0-7)该 lane 的 2xb16R1⬅ 左下 8x8 子块(rows 8-15,col 0-7)该 lane 的 2xb16R2⬅ 右上 8x8 子块(rows 0-7,col 8-15)该 lane 的 2xb16R3⬅ 右下 8x8 子块(rows 8-15,col 8-15)该 lane 的 2xb16- 如 Figure 1 所示
每个寄存器是 32-bit:高 16 位 + 低 16 位各放入一个 half,后续把 R0..R3 原样(用 "r" 约束)喂给 mma.sync.aligned.m16n8k16.row.col.f16.f16.f16.f16,PTX 会把它们按 .f16x2 解释并参与矩阵乘加
3. 一句话总结
LDMATRIX_X4 一条指令把 A 的 16x16 tile 当作 4 个 8x8 子块加载到 4 个 32-bit 寄存器 R0..R3,每个寄存器里是该 lane 负责的 “两邻列 b16”(= half2 位模式)
4.4 HMMA16816 宏定义解析
HMMA16816 宏定义如下
#define HMMA16816(RD0, RD1, RA0, RA1, RA2, RA3, RB0, RB1, RC0, RC1) \asm volatile("mma.sync.aligned.m16n8k16.row.col.f16.f16.f16.f16 {%0, %1}, {%2, %3, %4, %5}, {%6, %7}, {%8, %9};\n" \: "=r"(RD0), "=r"(RD1) \: "r"(RA0), "r"(RA1), "r"(RA2), "r"(RA3), "r"(RB0), "r"(RB1), "r"(RC0), "r"(RC1))
下面我们把核心 MMA 计算指令 HMMA16816 宏按 PTX 指令 ➡→ 占位符 → 约束/寄存器 拆开说明:
1. 指令本体
mma.sync.aligned.m16n8k16.row.col.f16.f16.f16.f16{D0, D1}, // 输出 D 片段(每线程 2×.b32,语义是两份 .f16x2){A0, A1, A2, A3}, // 输入 A 片段(每线程 4×.b32,每个装 2×f16){B0, B1}, // 输入 B 片段(每线程 2×.b32,每个装 2×f16){C0, C1}; // 输入 C 片段(每线程 2×.b32,每个装 2×f16)
- 形状
m16n8k16:一个 warp 完成 16x8x16 的矩阵乘积即D = A * B + C .row.col:A 以 行主 布局解释,B 以 列主 布局解释(这就是我们给 B 用ldmatrix ... .trans的原因)- 四种
.f16:A/B/C/D 元素都是 FP16,在寄存器层面一律以 打包的.f16x2(放在一个 32-bit 容器)传递
2. 占位符与内联 asm 绑定位
宏里把 PTX 写成了带占位符的字符串:
"mma.sync.aligned.m16n8k16.row.col.f16.f16.f16.f16 \{%0, %1}, {%2, %3, %4, %5}, {%6, %7}, {%8, %9};\n"
占位符编号由 输出先、输入后 的顺序决定:
%0, %1→ 第 1、2 个 输出(D0、D1)%2..%7→ A0…B1(输入)%8, %9→ C0、C1(输入)
3. 约束字符串
: "=r"(RD0), "=r"(RD1) // 输出:2× .b32 寄存器
: "r"(RA0), "r"(RA1), "r"(RA2), "r"(RA3), // A:4× .b32"r"(RB0), "r"(RB1), // B:2× .b32"r"(RC0), "r"(RC1) // C:2× .b32
"r"“要求一个 32-bit 通用寄存器(PTX.b32),契合.f16x2的 “位桶” 形式RD0,RD1用"=r"表示 写出RA*、RB*、RC*用"r"表示输入
OK,以上就是 hgemm_v1_mma_m16n8k16_naive_kernel 这个核函数的总体分析了
代码理解透了之后,下面我们就要来着重分析 bank conflict 问题了
结语
这篇文章我们主要是通过 CUDA PTX 官方文档一起来学习了 MMA 指令,包括乘加、矩阵加载和矩阵存储等指令,并利用 MMA 指令实现了一个简易版本的 hgemm 矩阵乘法,还对其进行了详细的分析
更多的难点在于 MMA 指令从官方文档到代码实现是如何对应的,官方文档中内存排布、数据搬运该如何理解,对应到代码中又该如何实现,理解完这些之后我们再回过头来看代码会轻松很多,那大家在学习的过程中可以多看看官方文档
篇幅原因,下篇文章我们再来正式进入 bank conflict 的分析,并学习 swizzle 解决方法,敬请期待🤗
下载链接
- MMA 与 Swizzle 代码下载链接【提取码:1234】
参考
- https://docs.nvidia.com/cuda/parallel-thread-execution/#warp-level-matrix-instructions-for-mma
- 【CUDA进阶】MMA分析Bank Conflict与Swizzle(已完结)
- https://github.com/xlite-dev/LeetCUDA
- https://github.com/Bruce-Lee-LY/cuda_hgemm
- https://github.com/Chtholly-Boss/swizzle
- https://chatgpt.com