语义分割目前还是研究热点吗?
语义分割模型复现、改进与对比实验
提供一系列语义分割模型的复现、改进以及对比实验,欢迎进行深入交流与探讨。如有详细需求,请随时联系。
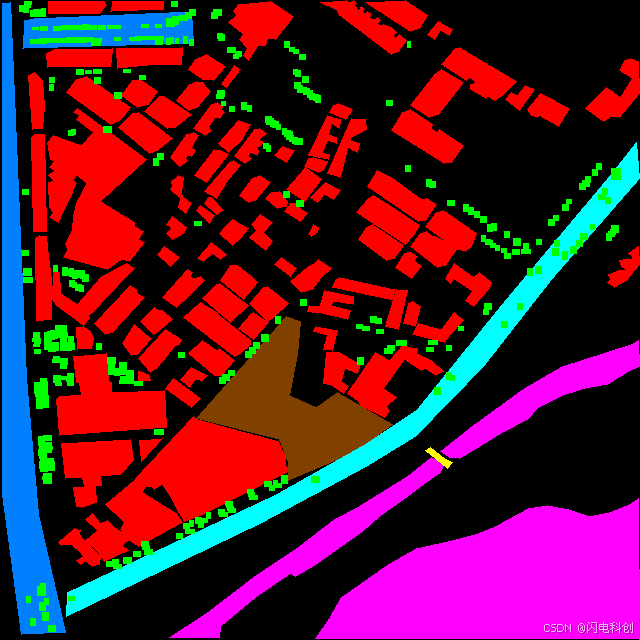
1. 支持的语义分割模型
可复现并改进以下主流语义分割模型:
- DeepLabV3+
- PSPNet
- HRNet
- SegFormer
- U-Net
- U^2-Net
- CeNet
- ERFNet
- HCANet
- HiFormer
- UI-Unet
- nnU-Net
- SAUNet
- UNext
- DSCNet
- CMUNext
- UKAN
以及其他相关模型。可以根据您的需求,提供所需的数据集进行模型训练与预测。
2. 主干网络的改进与选择
提供多种主干网络改进方案,包括但不限于以下架构:
- 轻量化主干网络:如基于 DeepLabV3+、U-Net、Transformer 的轻量化改进。
- 主干网络架构选择:包括 ResNet 系列、MobileNet 系列、EfficientNet 系列、ViT 系列、GhostNet 系列、Vision Mamba 系列、QFormer、Res2Net、FCANet、DeFormer、DPN、Channel ViT、Agent Attention、Conformer、SPPNet、StarNet、Swin Transformer、BatchFormer、Convolutional KAN、SpikFormer(脉冲神经网络)、胶囊网络(Capsule Networks)、B-COS 神经网络等。
- 对比实验:针对不同主干网络,进行全面对比实验,分析其对语义分割模型性能的影响。
3. 可选卷积模块
我们支持多种卷积模块的选择与应用:
- 深度可分离卷积(Depthwise Separable Convolution)
- Ghost模块(Ghost Module)
- Conv-Kan
- 动态卷积(Dynamic Convolution)
- 可变形卷积(Deformable Convolution)
- 分组卷积(Group Convolution)
- 部分卷积(Partial Convolution)
- 动态蛇形卷积(Dynamic Snake Convolution)
- 大核卷积(Large Kernel Convolution)
- 膨胀卷积(Dilated Convolution)
等多种卷积模块,可根据需求进行灵活组合,提升模型性能。
4. 可选注意力机制
支持多种注意力机制的集成,以提高模型的表现力:
- ECANet
- SENet
- Channel Attention(CA)
- Convolutional Block Attention Module(CBAM)
- Pixel-wise Attention(PSA)
- Self-Gating Enhancement (SGE)
- Spatial Knowledge Attention (SKA)
- Residual Channel-wise Attention (RCBA)
- Residual Channel-wise Attention (RCCA)
- Enhanced Multi-Scale Attention (EMSA)
- Global Attention Mechanism (GAM)
- Bottleneck Attention Module (BAM)
- Adaptive Feature Normalization Block (AFNB)
- Adaptive Spatial Feature Fusion (ASFF)
- Feature Attention Network (FAN)
- Spatial Transformer Network (STN)
- SWiFTFormer
- BiFormer
- Squeeze-and-Excitation (SE)
- Feature Channel Attention (FCA)
- Cross Pixel-wise Channel Attention (CPCA)
- MUSE (Multi-scale Uncertainty and Saliency Enhancement)
- RepConv
- Conv2Former
- Multi-Dimensional Transformer Attention (MDTA)
等先进的注意力机制,可灵活选择并集成到分割网络中,进一步提高模型的注意力集中能力与性能。
附加服务:
- 提供网盘链接,方便模型和数据集的下载。
- 可提供正式发票。