mysql(自写)
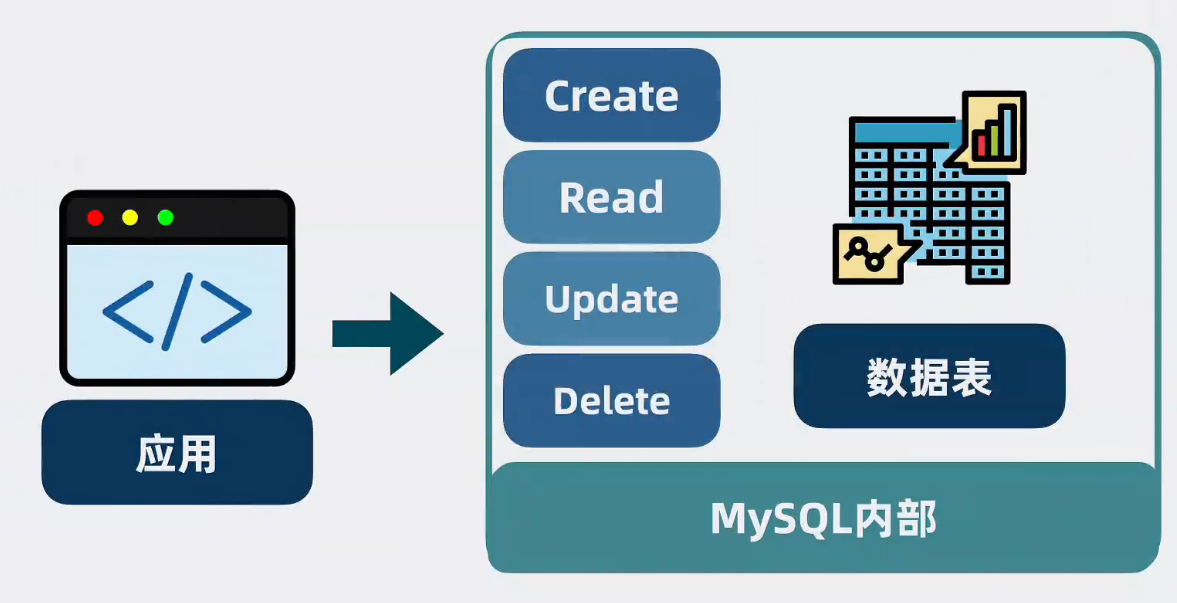
Mysql介于应用和数据之间,通过一些设计 ,将大量数据变成一张张像excel的数据表
数据页:
mysql将数据拆成一个一个的数据页
索引:
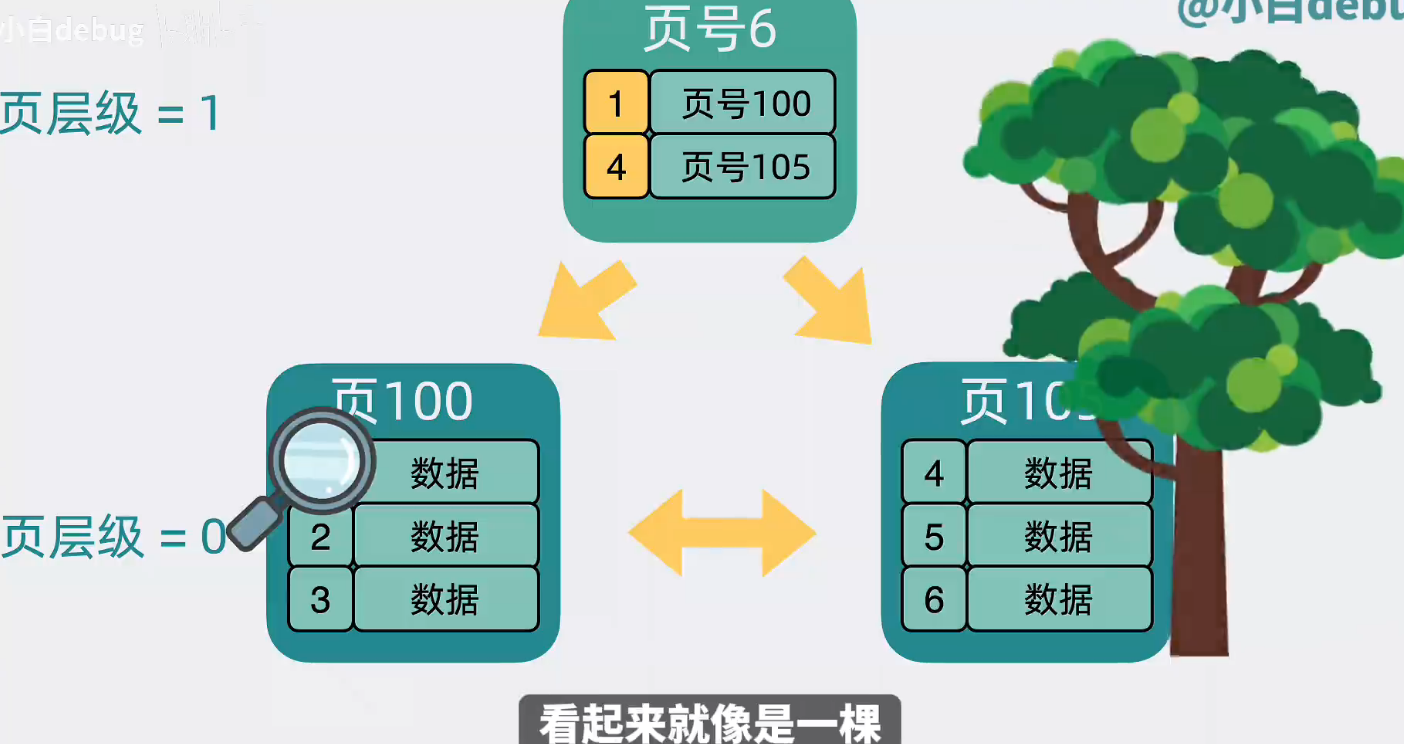
为每个页加入页号,再为每行数据加入序号,这个序号就是所谓的主键。 将每个页的页号和所在页最小的主键提出来,放入到一个新生成的数据页中,并且给数据也加入层级的概念,这样就可以根据上层的数据页,快速缩小查找范围,加速查找数据页的过程。现在页和页之间看起来就像是一颗树,这个可以加速查找数据页的树,就是常说的b+树索引
除了主键索引,也可以为其他数据表的列(字段)去建立索引,这就是辅助索引
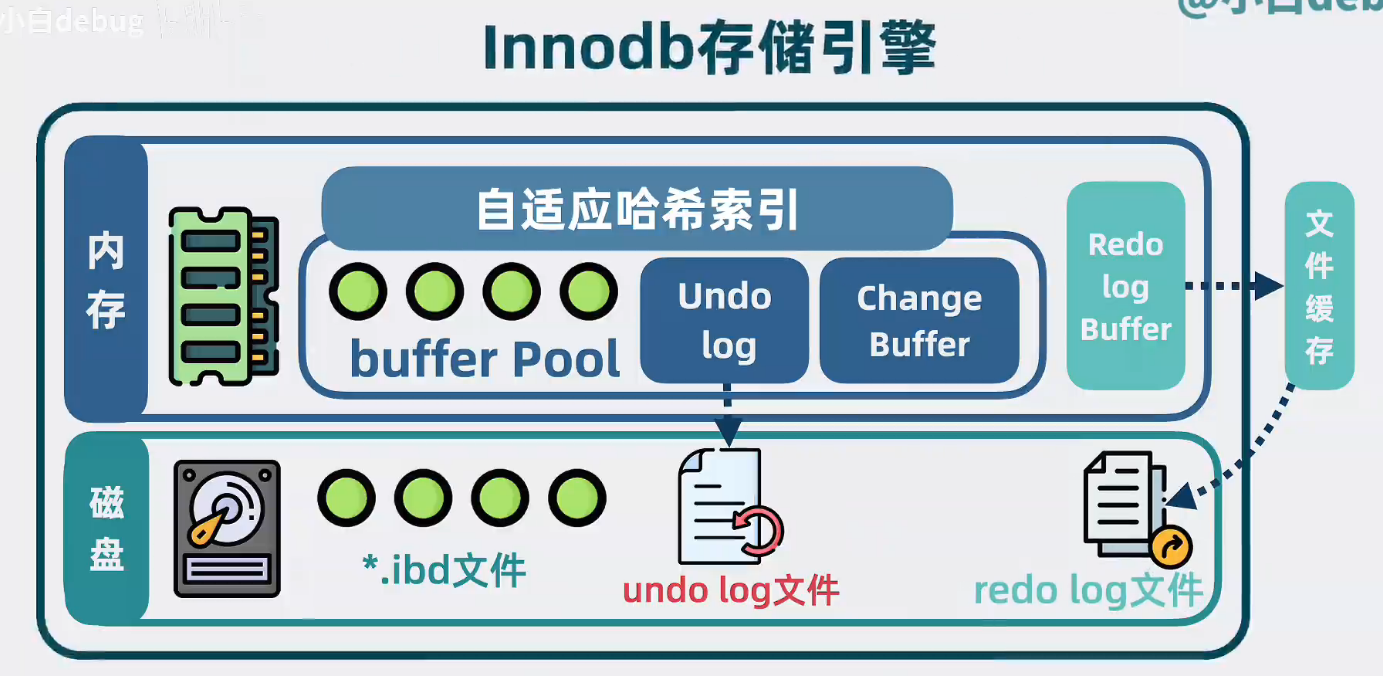
Buffer Pool
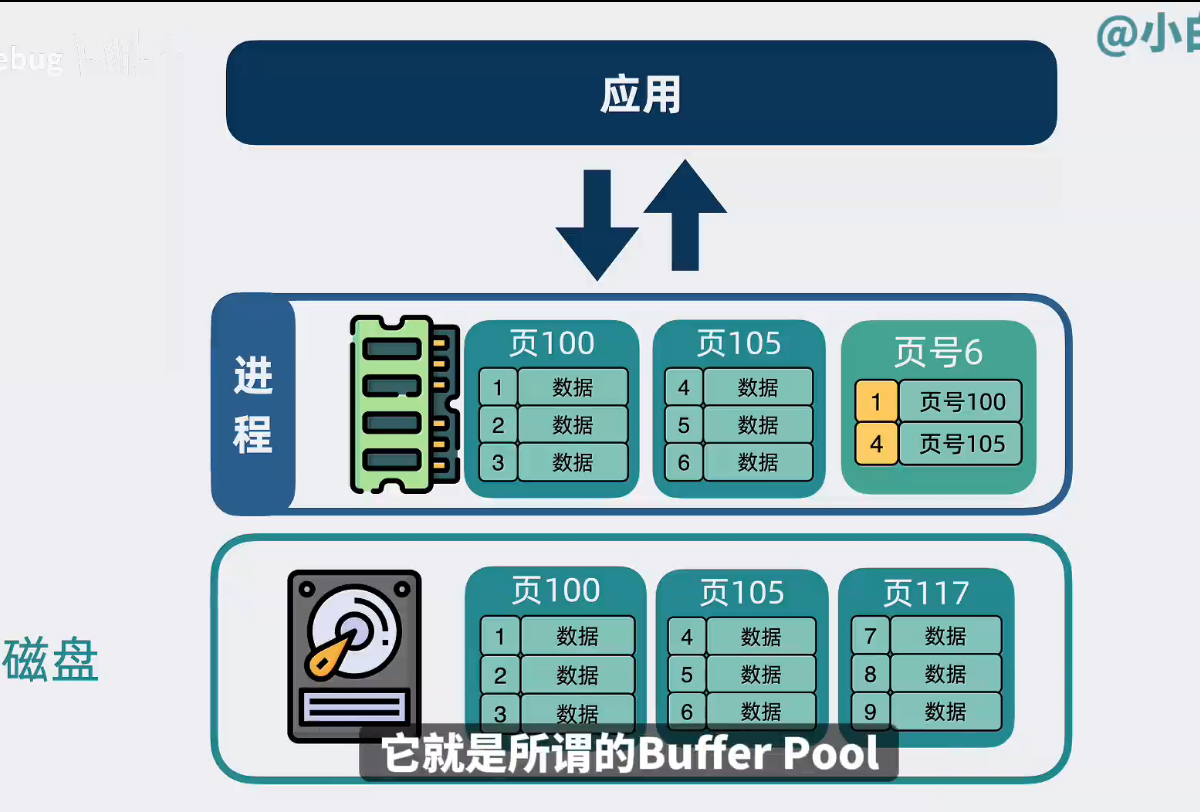
应用和磁盘间,加一层缓存,缓存里装的就是索引页和部分数据(先读buffer pool,有对应数据就返回,没数据就去磁盘找)
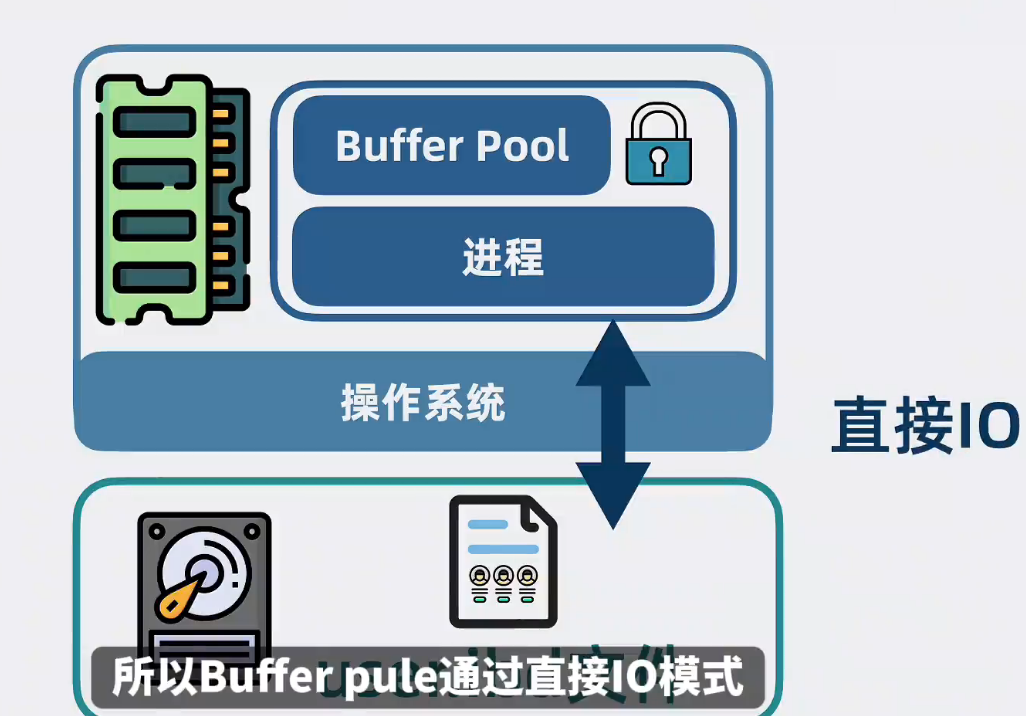
进程自己维护的Buffer Pool可以定制更多缓存策略,还能实现加锁等各种数据表高级特性,所以有了Buffer Poll,就没必要使用操作系统的文件缓存了。Buffer Pool通过直接IO模式,绕过操作系统的缓存机制,直接从磁盘读取数据
直接IO方式是指绕过操作系统的缓存机制,直接从磁盘中读取到用户态空间缓冲区,避免了数据从磁盘拷贝到内核态缓冲区,再从内核态缓存区拷贝到用户态缓冲区的两次复制,所以大大提升了性能
自适应哈希索引
就算有了Buffer,Poll,要查到某个数据也,也依然要查找B+树,查询复杂度O(lgn).可以使用查询你速度为O(1)的哈希表进行优化,记录每个数据页的查询频率,对于热点数据页,以查询的值为key,数据页地址为value构建哈希表
ChangeBuffer
大部分数据表除了主键索引外,还会加一些辅助索引。那对于这类数据表的写操作,更新完主键索引的数据页之后还需要更新辅助索引页,这样,读取辅助索引页的磁盘IO必然少不了
可以先将要写入的数据收集到一块内存里(这就是ChangeBuffer),等哪天磁盘里的索引页正好被读入Buffer Pool的时候,再将写入数据应用到索引页中,通过这个方式,减少了大量的磁盘IO提升性能
Undo Log
在数据库中有一个叫事物的概(就是可以让多行数据要么同时更新成功,要么同时失败,就是所谓的原子性)。为了实现这一点,我们就知道写数据时每行数据原来长啥样,方便对更新后的数据进行回滚,因此就有了undo log ,更新Buffer Pool数据叶的时候,会用旧数据生成Undo log记录,会用旧数据生成undo log ,存储在bufferpool中的特殊undo log 内存页中,并随着Buffer Pool的刷盘机制,不定时写入到磁盘的Undo log 文件中
Redo Log
将事务中更新数据行的操作都写入到Redo Log Buffer内存中,在事务提交的时候进行redo log刷磁盘,将数据固化到redo log文件中,数据库进程崩溃重启后,就能通过Redo Log File找到历史操作记录重做数据,保证了事务里的多行数据变更,要么都成功,要么都失败
Redo Log File是由顺序写入的,Buffer Pool的内存数据随机分散在磁盘内,顺序写磁盘性能是随机写的几十倍
InnoDB
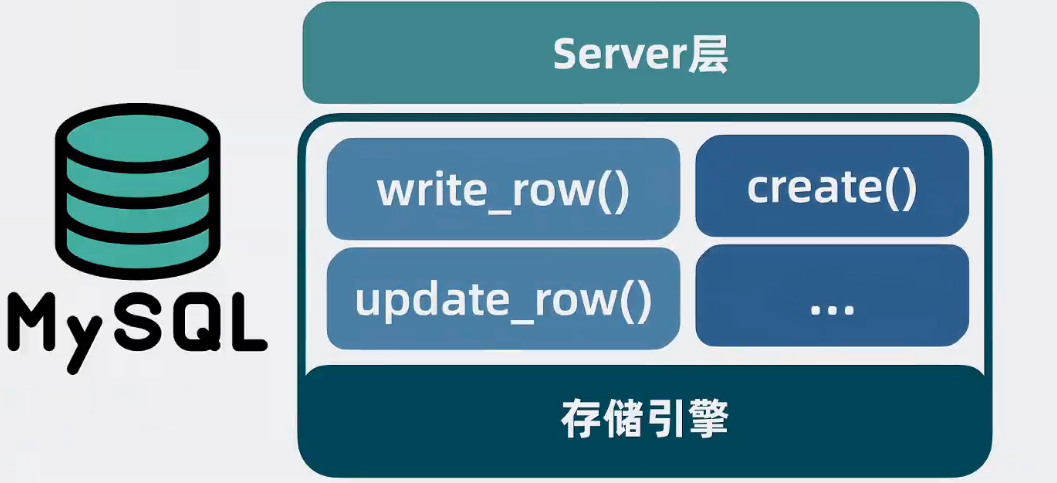
sql语句如何转成存储引擎的函数接口呢
Server层
本质是sql语句和InnoDB存储引擎的中间层,在server层内提供一个连接管理模块,用于管理来自引用的网络连接,并提供一个分析器用于判断sql语句有没有语法错误,再提供一个优化器,用于根据一定的规则,选择改用什么索引生成执行计划,之后提供一个执行器根据执行计划去调用InnoDB存储引擎的接口函数
binlog是什么
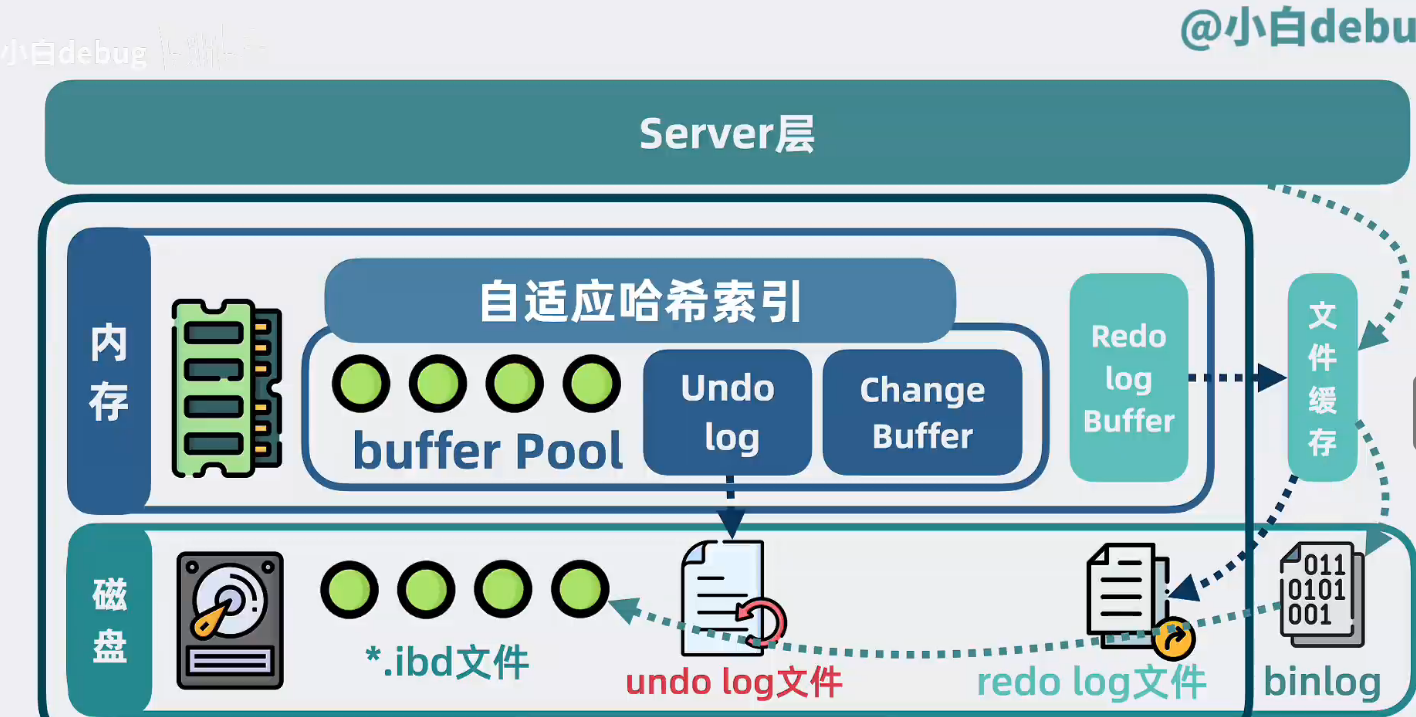
redolog 是环形写的,写入数据多的时候会把最开始写入的删除掉,所以没法完全恢复,只能用来恢复部分最近数据(当然,这部分也是比较大的了)