kafka(自写)
kafka是一个开源的分布式的事件流处理平台
消息队列Kafka是什么?架构是怎么样的?5分钟快速入门_哔哩哔哩_bilibili
使用kafka作为一个消息中间件,将服务之间的通信和数据交换解耦
Kafka的本质是日志消息代理 日志的特点就是append-only和不可变 它能带来的显而易见的好处是强大的局部性 内存中可以抽象为buffer 内核态里它又是page cache 磁盘上它会集中在同一磁道 从上至下利于软件和操作系统进行快速写入 这也是为什么大量知名系统 不论是MySQL Server的binlog还是redis的aof 都是使用类似的方式 它是典型的IO密集型应用 所以它并不是线程池 Kafka的大量技术细节都在解决IO性能 包括但不限于零拷贝
消息队列都能实现解耦,异步,削峰的功能
kafka优势:高吞吐性能
kafka最开始就是一个简单的消息队列,可用于生产者和消费者之间削峰
然后对其进行升级
高性能:
如果生产者和消费者都变多,会争抢等待同一个消息队列
解决办法:可以对消息进行分类,每类都是一个topic,生产者将数据按topic投递到不同的队列中。消费者则需要订阅不同的topic。
但是单个topic的消息可能还是过多,可以将单个队列拆成好几段,每段就是一个partition分区,每个消费者负责一个partition,这样就大大降低了争抢,提升了消息队列的性能
高扩展性:
随着patition变多,如果partition都在同一台机器上的话,就会导致单机cpu和内存过高。影响整体系统性能,于是我们可以申请更多的机器,将partition分散部署在多台机器上,每一台机器就代表一个broker,我们可以通过增加broker缓解机器cpu过高带来的性能问题
高可用:
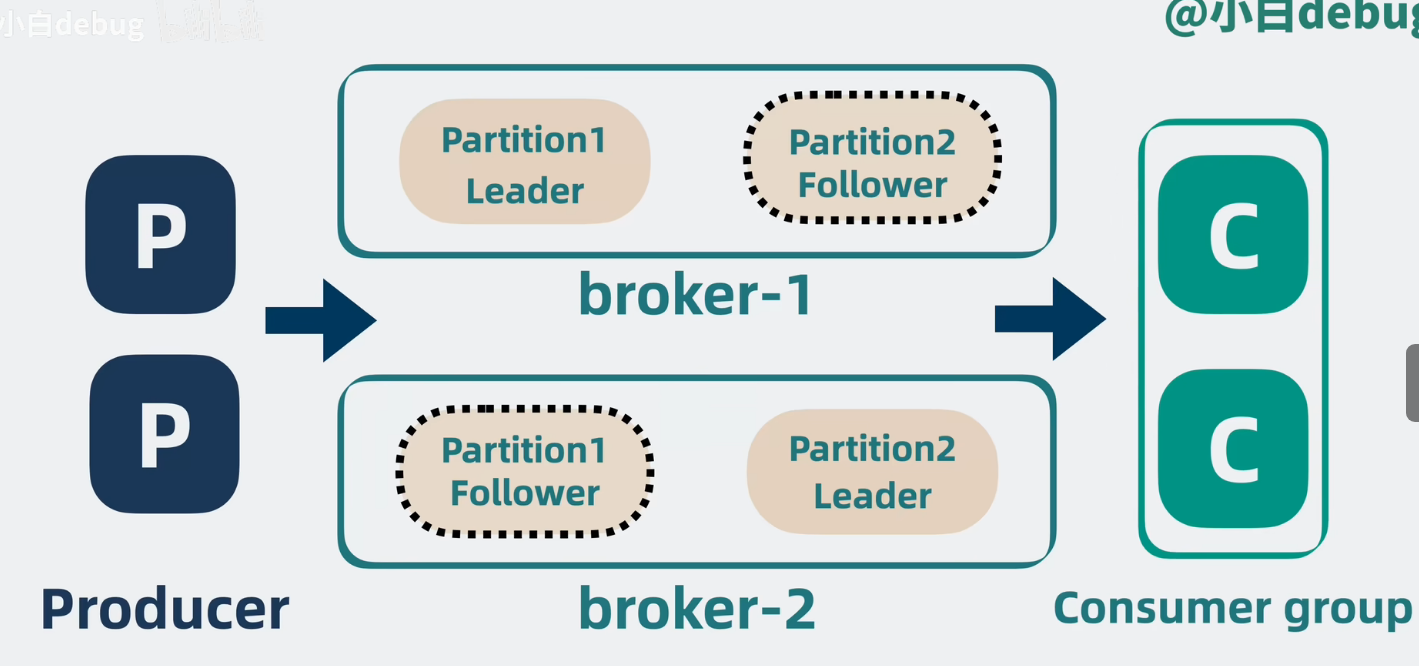
如果其中一个patition所在的broker挂了,那broker里所有的partition的消息都没了。可以给一个partition多加几个副本(broker-1,broker-2),这几个副本(broker-1,broker-2)统称为replicas,将它们分为leader,follower,leader负责应付生产者和消费者的读写请求,而follower只管同步leader的消息,将leader和follower分散到不同的broker上,这样leader所在的broker挂了也不会影响到follower所在的broker,并且还能从follower中选举出一个新的leader,这样就保证了消息队列的高可用
持久化和过期策略
如果所有broker都挂了,那岂不是数据全丢了,为了解决这个问题,不能光把数据放内存里,还要持久化到磁盘中,这样哪怕全部broker都挂了,数据也不会全丢,重启服务后也能从磁盘里读出数据,继续工作。还可以给数据加上保留策略(即retention policy),比如磁盘数据超过一定大小,消息放置超过一定时间就会别清理掉
Consumer Group
按现在的方式,每次新增的消费者,之能跟着最新的offset接着消费,如果我想让新增的消费者从某个offset开始消费,于是引入消费者组的概念,也就是consumer group,不同消费者组维护自己的消费进度
ZooKeeper
组件太多了,而且每个组件都有自己的数据和状态,所以还需要有个组件统一维护这些组件的状态信息,于是引入了zookeeper组件,它会定期和broker通信,获取整个kafka集群的状态,以此来判断某些broker是不是跪了,某些消费者消费到哪里了
Kafka 应用场景
Kafka是架构中常见的中间件之一,可以对流量进行削峰填谷,经常在秒杀活动,大数据和日志的异构同步中