JUC并发编程09 - 内存(01) - JMM/cache
JMM
内存模型
Java 内存模型是 Java Memory Model(JMM),本身是一种抽象的概念,实际上并不存在,描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式
JMM 作用:
- 屏蔽各种硬件和操作系统的内存访问差异,实现让 Java 程序在各种平台下都能达到一致的内存访问效果
- 规定了线程和内存之间的一些关系
Java 内存模型(JMM)不是真实存在的内存结构,而是一套“游戏规则”,它规定了多线程环境下,变量怎么读、怎么写、什么时候对其他线程可见。
为什么需要 JMM?
- 有的电脑 CPU 多,缓存多;
- 有的操作系统处理内存的方式不同;
- 有的 CPU 会为了性能“乱序执行”代码。
如果 Java 程序直接依赖这些硬件行为,那同样的代码在 A 电脑上正常,在 B 电脑上就出 bug 了。所以,Java 说:我不管你们底层咋搞,我定一套统一规则(JMM),你们都按我的来,保证程序在任何平台表现一致!
目标:屏蔽硬件和操作系统的内存访问差异,让 Java 程序在所有平台上表现一致。
根据 JMM 的设计,系统存在一个主内存(Main Memory),Java 中所有变量都存储在主存中,对于所有线程都是共享的;每条线程都有自己的工作内存(Working Memory),工作内存中保存的是主存中某些变量的拷贝,线程对所有变量的操作都是先对变量进行拷贝,然后在工作内存中进行,不能直接操作主内存中的变量;线程之间无法相互直接访问,线程间的通信(传递)必须通过主内存来完成
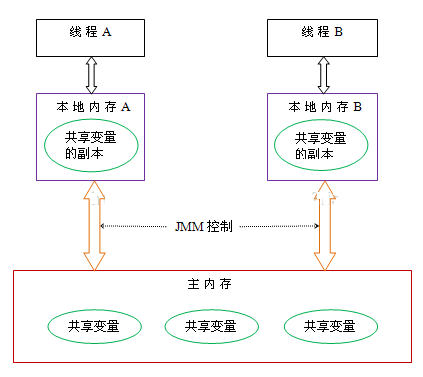
主内存与工作内存
想象一下你和你的朋友在玩一个游戏,这个游戏需要共享一些信息(比如分数)。这些信息就像 Java 中的变量,它们都存储在一个“公共记事本”里——这就是主内存。每个人手里还有一本自己的小笔记本——这就是工作内存。
- 主内存:相当于大家共用的一个大仓库,所有线程都能看到里面的东西。
- 工作内存:每个线程都有自己的小仓库,里面存的是从大仓库拷贝过来的东西。
线程操作变量的过程
当你想更新分数时,你不能直接在大仓库里改,而是要先在自己的小笔记本上改,然后再把新的分数告诉大仓库。同样,如果你想看最新的分数,也不能直接看大仓库,而是要看自己小笔记本上的最新记录。
为什么这么麻烦?
因为如果大家都直接在大仓库里乱写乱改,可能会出现混乱。比如你刚写完,别人又改了,那你写的就白费了。所以,JMM 设计了一套规则,让大家按规矩办事,才能保证数据的一致性。
主内存和工作内存:
- 主内存:计算机的内存,也就是经常提到的 8G 内存,16G 内存,存储所有共享变量的值
- 工作内存:存储该线程使用到的共享变量在主内存的的值的副本拷贝
JVM 和 JMM 之间的关系:JMM 中的主内存、工作内存与 JVM 中的 Java 堆、栈、方法区等并不是同一个层次的内存划分,这两者基本上是没有关系的,如果两者一定要勉强对应起来:
- 主内存主要对应于 Java 堆中的对象实例数据部分,而工作内存则对应于虚拟机栈中的部分区域
- 从更低层次上说,主内存直接对应于物理硬件的内存,工作内存对应寄存器和高速缓存
主内存与工作内存
JMM 的“主内存”和“工作内存”是抽象概念,不是真实物理内存划分。它们和 JVM 的堆、栈是不同层面的东西,但可以“勉强对应”到硬件和 JVM 结构上。
| 名称 | 全称 | 是啥? | 层级 |
|---|---|---|---|
| JVM 内存模型 | Java Virtual Machine Memory | JVM 运行时的内存结构,比如堆、栈、方法区等 | 真实存在的运行时数据区 |
| JMM | Java Memory Model | Java 内存模型,是一套多线程访问变量的规则,主内存、工作内存是它的抽象概念 | 抽象的规范,不是真实内存 |
- JVM 内存模型:讲的是“Java 程序运行时,数据存在哪?”
- JMM:讲的是“多个线程同时操作变量时,怎么保证大家看到的数据是一致的?”
生活例子:公司档案管理系统
想象你是一家公司的员工,公司有个大档案室(主内存),每个部门有自己的小资料柜(工作内存)。
主内存(JMM 抽象) ≈ 公司中央档案室
- 所有重要文件(比如员工工资、项目进度)都存在这里。
- 是唯一的、共享的、权威的数据源。
- 对应到硬件:就是你电脑的物理内存(8G/16G 那块)
工作内存(JMM 抽象) ≈ 各部门的小资料柜
- 每个部门(线程)为了提高效率,会从中央档案室拷贝一份文件到自己桌上。
- 平时看、改文件都在自己桌上操作。
- 改完后再统一归档回中央档案室。
- 对应到硬件:CPU 的高速缓存(Cache)和寄存器
注意:这个“小资料柜”不是公司规定的正式部门(比如人事部、财务部),而是为了干活方便临时用的!—— 就像 JMM 的“工作内存”不是 JVM 的正式内存区,而是抽象出来的概念。
变量到底存在哪?
public class MemoryLocationDemo {// 静态变量:存在方法区(JVM 层面)public static int counter = 0;public static void main(String[] args) {// 局部变量:存在虚拟机栈(JVM 层面)int localVar = 100;// 对象实例:存在堆(JVM 层面)Person p = new Person();p.age = 25; // p.age 这个字段值存在堆中}
}class Person {int age;
}JVM 内存划分(真实存在)
| 据 | 存在哪? | 说明 |
|---|---|---|
counter | 方法区 | 静态变量 |
localVar | 虚拟机栈 | 局部变量,每个线程有自己的栈 |
new Person() | 堆 | 对象实例数据 |
p.age = 25 | 堆 | 对象的字段值存在堆中 |
那 JMM 的“主内存”和“工作内存”在哪?
我们来看 p.age 被多线程访问时的情况:
Person sharedPerson = new Person(); // 对象在堆中Thread t1 = new Thread(() -> {sharedPerson.age = 30; // 线程1 修改 age
});Thread t2 = new Thread(() -> {System.out.println(sharedPerson.age); // 线程2 读取 age
});此时 JMM 是怎么工作的?
| 步骤 | JVM 层面(真实) | JMM 层面(抽象) |
|---|---|---|
1. sharedPerson 创建 | 对象存在堆中 | 堆中的数据属于 JMM 的主内存 |
2. t1 要修改 age | 从堆读取 | t1 把 age 值拷贝到自己的工作内存(其实是 CPU 缓存) |
3. t1 修改 age=30 | 还没写回堆 | 在工作内存中修改 |
| 4. 写回 | 最终写回堆 | 同步回 JMM 的主内存 |
5. t2 读取 age | 从堆读?还是缓存? | 必须从主内存获取最新值(如果用了 volatile) |
| JMM 抽象概念 | “勉强对应”到 JVM 哪里? | 更底层对应(硬件) |
|---|---|---|
| 主内存 | Java 堆中的对象实例数据、方法区的静态变量 | 物理内存(RAM) |
| 工作内存 | 虚拟机栈中的部分变量副本、CPU 缓存 | CPU 高速缓存(Cache)、寄存器 |
常见误区
误区1:主内存 = 堆,工作内存 = 栈
- 堆里的对象数据属于主内存的一部分,但主内存还包括方法区的静态变量等。
- 栈里的局部变量可能被线程频繁访问,会进入工作内存(CPU 缓存),但栈本身 ≠ 工作内存。
JMM 的主内存 ≈ 堆 + 方法区中的共享数据
JMM 的工作内存 ≈ CPU 缓存 + 寄存器(用于存储线程使用的变量副本)
内存交互
Java 内存模型定义了 8 个原子操作,这些操作保证了主内存和工作内存之间的交互是安全且一致的。每个操作都是原子的,即不可分割的。
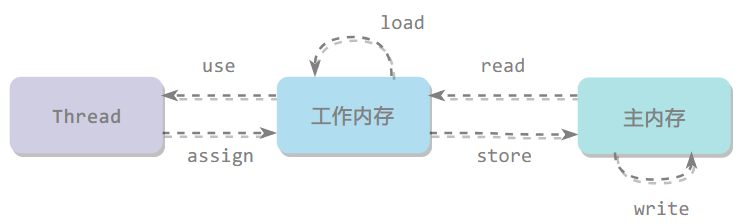
| 操作 | 作用 |
|---|---|
| lock | 将变量标识为被当前线程独占 |
| unlock | 释放变量的锁定状态 |
| read | 从主内存读取变量值到工作内存 |
| load | 将 read 得到的值放入工作内存的变量副本 |
| use | 将工作内存中的变量值传递给执行引擎 |
| assign | 将执行引擎接收到的值赋给工作内存的变量 |
| store | 将工作内存中的变量值传送到主内存 |
| write | 将 store 得到的值放入主内存的变量 |
三大特性
可见性
可见性:是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值
存在不可见问题的根本原因是由于缓存的存在,线程持有的是共享变量的副本,无法感知其他线程对于共享变量的更改,导致读取的值不是最新的。但是 final 修饰的变量是不可变的,就算有缓存,也不会存在不可见的问题
- 初始状态, t 线程刚开始从主内存读取了 run 的值到工作内存
- 因为 t 线程要频繁从主内存中读取 run 的值,JIT 编译器会将 run 的值缓存至自己工作内存中的高速缓存中,减少对主存中 run 的访问,提高效率
- 1 秒之后,main 线程修改了 run 的值,并同步至主存,而 t 是从自己工作内存中的高速缓存中读取这个变量的值,结果永远是旧值
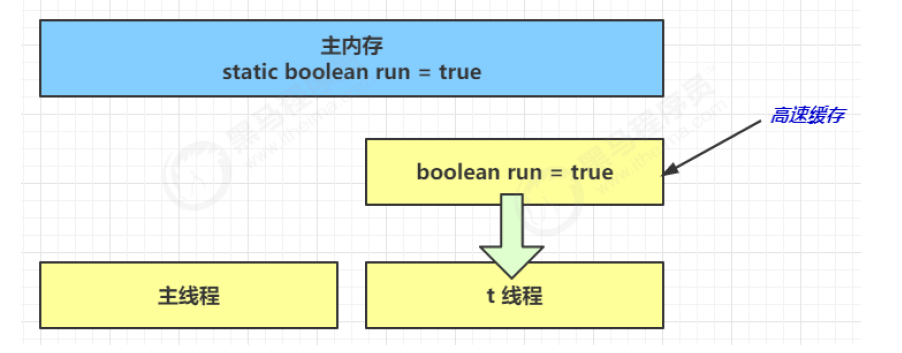
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看到这个修改后的值。如果存在不可见性问题,那么一个线程对共享变量的修改可能无法被其他线程及时感知到。
为什么会出现不可见性问题?
根本原因在于缓存的存在。每个线程都有自己的工作内存(可以理解为缓存),它们持有的是共享变量的副本。当一个线程修改了某个共享变量的值时,这个修改只会在该线程的工作内存中生效,而不会立即同步到主内存中。因此,其他线程在读取这个变量时,可能会从自己的工作内存中读取到旧值,而不是最新的值。
但是,对于 final 修饰的变量来说,由于它们是不可变的,即使有缓存也不会存在不可见性问题,因为这些变量一旦初始化后就不能再被修改。
生活例子:办公室里的公告板
假设你在一个办公室里工作,办公室里有一个公告板(相当于主内存),每个员工(相当于线程)都有自己的笔记本(相当于工作内存)。
场景1:正常情况下的信息传递
- 发布通知:经理在公告板上发布了一条新的通知。
- 查看通知:每个员工定期查看公告板上的最新通知,并将通知内容记录在自己的笔记本上。
在这种情况下,所有员工都能及时看到最新的通知内容。
场景2:信息传递不畅
- 发布通知:经理在公告板上发布了一条新的通知。
- 员工A查看通知:员工A看到了这条通知,并将其记录在自己的笔记本上。
- 员工B查看通知:员工B没有直接查看公告板,而是查看了员工A的笔记本,但员工A还没有更新自己的笔记本。
结果是,员工B看到的是旧的通知内容,而不是最新的通知内容。
public class VisibilityDemo {static boolean run = true;public static void main(String[] args) throws InterruptedException {Thread t = new Thread(() -> {while (run) {// 线程t执行某些操作}});t.start();Thread.sleep(1000);run = false; // 主线程修改run的值}
}在这个例子中,主线程修改了 run 的值,但由于 t 线程持有 run 变量的副本,并且频繁地从自己的工作内存中读取 run 的值,导致它永远读取到的是旧值,从而无法停止。
解决方案:使用 volatile 关键字
public class VisibilityDemo {static volatile boolean run = true;public static void main(String[] args) throws InterruptedException {Thread t = new Thread(() -> {while (run) {// 线程t执行某些操作}});t.start();Thread.sleep(1000);run = false; // 主线程修改run的值}
}通过将 run 变量声明为 volatile,可以确保每次读取 run 的值时都直接从主内存中读取,而不是从工作内存中读取,从而保证了可见性。
| 情况 | 描述 |
|---|---|
| 存在缓存 | 线程持有共享变量的副本,无法感知其他线程对共享变量的更改,导致读取的值不是最新的。 |
使用 volatile | 确保每次读取变量时都直接从主内存中读取,而不是从工作内存中读取,从而保证了可见性。 |
原子性
原子性:不可分割,完整性,也就是说某个线程正在做某个具体业务时,中间不可以被分割,需要具体完成,要么同时成功,要么同时失败,保证指令不会受到线程上下文切换的影响
定义原子操作的使用规则:
- 不允许 read 和 load、store 和 write 操作之一单独出现,必须顺序执行,但是不要求连续
- 不允许一个线程丢弃 assign 操作,必须同步回主存
- 不允许一个线程无原因地(没有发生过任何 assign 操作)把数据从工作内存同步会主内存中
- 一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(assign 或者 load)的变量,即对一个变量实施 use 和 store 操作之前,必须先自行 assign 和 load 操作
- 一个变量在同一时刻只允许一条线程对其进行 lock 操作,但 lock 操作可以被同一线程重复执行多次,多次执行 lock 后,只有执行相同次数的 unlock 操作,变量才会被解锁,lock 和 unlock 必须成对出现
- 如果对一个变量执行 lock 操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量之前需要重新从主存加载
- 如果一个变量事先没有被 lock 操作锁定,则不允许执行 unlock 操作,也不允许去 unlock 一个被其他线程锁定的变量
- 对一个变量执行 unlock 操作之前,必须先把此变量同步到主内存中(执行 store 和 write 操作)
原子性 = 一件事要么全做完,要么完全不做,中间不能被打断。
就像你去银行转账:“从A账户扣100元” 和 “往B账户加100元” 必须一起成功,或一起失败。
如果只扣了钱但没到账,那可就出大事了!在多线程中,原子性保证了某个操作不会被线程切换“切开”,避免出现“一半完成”的脏数据。
规则1:read 和 load、store 和 write 必须成对出现,但不一定要连续
你从主内存“读”了一个数据,就必须“加载”到工作内存里,否则读了等于白读。你从工作内存“存”一个数据,就必须“写”回主内存,否则存了也白存。
规则2:不允许线程丢弃 assign 操作,必须同步回主存
你在自己笔记本上改了数据(assign),不能只改不报,必须通过 store + write 同步回去。
规则3:不允许无原因地把数据同步回主内存
你不能凭空往主内存写一个值。必须是你自己先改过(assign),才能写回去。
规则4:新变量只能在主内存诞生,use/store 前必须先 load/assign
一个变量必须先初始化,才能使用或写回。
规则5:一个变量同一时刻只能被一个线程 lock,lock 多次要 unlock 多次
lock 是排他的,但可重入。
规则6:lock 之后,工作内存的值被清空,必须重新 load
你拿到锁后,不能用旧数据,必须重新从主内存读。
规则7:没有 lock 的变量,不能 unlock;不能 unlock 别人的锁
你不能释放别人拿着的锁。
规则8:unlock 之前,必须先 store + write 同步回主内存
你改了数据,必须先保存再释放锁。
有序性
有序性:在本线程内观察,所有操作都是有序的;在一个线程观察另一个线程,所有操作都是无序的,无序是因为发生了指令重排序
CPU 的基本工作是执行存储的指令序列,即程序,程序的执行过程实际上是不断地取出指令、分析指令、执行指令的过程,为了提高性能,编译器和处理器会对指令重排,一般分为以下三种:
源代码 -> 编译器优化的重排 -> 指令并行的重排 -> 内存系统的重排 -> 最终执行指令现代 CPU 支持多级指令流水线,几乎所有的冯•诺伊曼型计算机的 CPU,其工作都可以分为 5 个阶段:取指令、指令译码、执行指令、访存取数和结果写回,可以称之为五级指令流水线。CPU 可以在一个时钟周期内,同时运行五条指令的不同阶段(每个线程不同的阶段),本质上流水线技术并不能缩短单条指令的执行时间,但变相地提高了指令地吞吐率
处理器在进行重排序时,必须要考虑指令之间的数据依赖性
- 单线程环境也存在指令重排,由于存在依赖性,最终执行结果和代码顺序的结果一致
- 多线程环境中线程交替执行,由于编译器优化重排,会获取其他线程处在不同阶段的指令同时执行
补充知识:
- 指令周期是取出一条指令并执行这条指令的时间,一般由若干个机器周期组成
- 机器周期也称为 CPU 周期,一条指令的执行过程划分为若干个阶段(如取指、译码、执行等),每一阶段完成一个基本操作,完成一个基本操作所需要的时间称为机器周期
- 振荡周期指周期性信号作周期性重复变化的时间间隔
有序性 = 程序执行的顺序,看起来是按你写的代码顺序来的。但在多线程世界里,这个“看起来”可能会骗你!在本线程内,看起来是有序的;但其他线程看过来,可能是乱序的。原因就是:指令重排序。
生活例子:做煎饼果子的“流水线”
想象你是个煎饼摊老板,做一份煎饼要 5 步:
- 打鸡蛋 🥚
- 刷酱 🧴
- 摊面糊 🥞
- 加葱花 🧅
- 折叠打包 📦
你很聪明,发现有些步骤可以“并行”或“调换顺序”,只要最终结果一样,就能更快出餐!
比如:
- 你可以先摊面糊(3),再打鸡蛋(1)——只要鸡蛋落在面糊上就行。
- 你可以在等面糊熟的时候,提前刷酱(2)。
这就是“重排序”:只要不影响最终结果,顺序可以调整,提高效率。但问题来了:
顾客(另一个线程)从外面看,以为你是按 1→2→3→4→5 做的,实际上你是 3→1→2→4→5,顺序乱了!如果顾客根据“你以为的顺序”来判断进度,就会出错!这就是有序性问题。
为什么会有指令重排序?
现代 CPU 和编译器为了提高性能,会做三类重排序:
源代码↓
【编译器优化重排】 → 比如把变量声明提前↓
【指令并行重排】 → CPU 同时执行不相关的指令(流水线)↓
【内存系统重排】 → 缓存、写缓冲区导致写入顺序变化↓
最终执行的指令CPU 五级流水线(就像工厂流水线):
| 阶段 | 干啥 |
|---|---|
| 1. 取指令 | 从内存拿指令 |
| 2. 指令译码 | 看懂这条指令是干啥的 |
| 3. 执行指令 | 真正执行(比如加法) |
| 4. 访存取数 | 读写内存数据 |
| 5. 结果写回 | 把结果写回寄存器 |
CPU 可以在一个时钟周期内,同时处理 5 条指令的不同阶段,就像 5 个人接力干活,大大提升效率!但这也意味着:指令的实际执行顺序 ≠ 你写的代码顺序。
public class ReorderDemo {static int x = 0, y = 0;static int a = 0, b = 0;public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {a = 1; // 步骤1x = b; // 步骤2});Thread t2 = new Thread(() -> {b = 1; // 步骤3y = a; // 步骤4});t1.start();t2.start();t1.join();t2.join();System.out.println("x=" + x + ", y=" + y);}
}因为指令重排序,有可能结果为:
- 线程1:
a=1; x=b;可能被重排序为x=b; a=1; - 线程2:
b=1; y=a;可能被重排序为y=a; b=1;
执行顺序变成:
线程1:x = b; // 此时 b=0
线程2:y = a; // 此时 a=0
线程1:a = 1;
线程2:b = 1;结果:x=0, y=0
如何解决有序性问题?
方法1:使用 volatile(禁止重排序)
static volatile int a = 0; // 加上 volatile
static volatile int b = 0;volatile 会插入内存屏障,告诉 CPU 和编译器:这个变量前后不能重排序!必须按我写的顺序来!
方法2:使用 synchronized
synchronized(this) {a = 1;x = b;
}同步块内部虽然也可能重排序,但进入和退出同步块时有内存语义保证,相当于“顺序锁”。
方法3:使用 Thread.start() 和 Thread.join()
重排序的“底线”:数据依赖性
CPU 和编译器不会瞎重排序,它们会看有没有数据依赖:
| 情况 | 能重排序吗? | 例子 |
|---|---|---|
| 无依赖 | 可以 | a=1; b=2; → 可以调换 |
| 有依赖 | 不可以 | a=1; b=a; → 不能把 b=a 放 a=1 前面 |
所以单线程下,重排序不会改变程序结果,因为依赖关系在那。
但多线程下,你依赖的变量可能是另一个线程改的,顺序一乱,结果就变了。
cache
缓存机制
缓存结构
在计算机系统中,CPU 高速缓存(CPU Cache,简称缓存)是用于减少处理器访问内存所需平均时间的部件;在存储体系中位于自顶向下的第二层,仅次于 CPU 寄存器;其容量远小于内存,但速度却可以接近处理器的频率
CPU 处理器速度远远大于在主内存中的,为了解决速度差异,在它们之间架设了多级缓存,如 L1、L2、L3 级别的缓存,这些缓存离 CPU 越近就越快,将频繁操作的数据缓存到这里,加快访问速度
从 CPU 到 大约需要的时钟周期 寄存器 1 cycle (4GHz 的 CPU 约为 0.25ns) L1 3~4 cycle L2 10~20 cycle L3 40~45 cycle 内存 120~240 cycle
想象一下你正在做一道复杂的数学题。你需要不断地翻阅课本和笔记来找公式和数据。如果你每次都要从书架上拿书来看,那会非常耗时。但是,如果你把常用的公式和数据记在一张小卡片上,放在手边,那么每次需要的时候直接看卡片就好了,这样效率就高多了。
计算机中的缓存就像这张小卡片。CPU(中央处理器)是计算机的大脑,它需要频繁地访问内存来获取数据和指令。但内存的速度相对较慢,如果每次都直接从内存中读取数据,CPU就会浪费很多时间等待。因此,计算机设计了多级缓存,这些缓存就像是不同大小的小卡片,离CPU越近的缓存速度越快,容量越小。
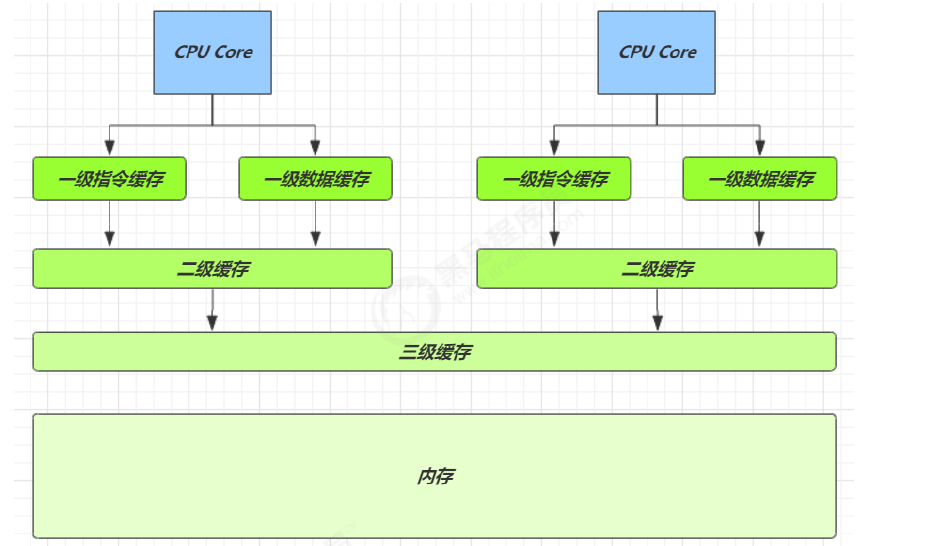
我们来看看图中的缓存结构:
- CPU Core:这是计算机的大脑,负责处理所有的计算任务。
- 一级指令缓存和一级数据缓存 (L1 Cache):这是离CPU最近的缓存,分为指令缓存和数据缓存。指令缓存存储CPU即将执行的指令,数据缓存存储CPU即将使用的数据。L1缓存速度最快,但容量最小。
- 二级缓存 (L2 Cache):比L1缓存稍远一点,容量更大,速度稍慢。
- 三级缓存 (L3 Cache):这是多核CPU共享的缓存,容量最大,速度最慢(相对于L1和L2来说)。
- 内存:这是计算机的主要存储器,容量最大,但速度最慢。
缓存使用
当处理器发出内存访问请求时,会先查看缓存内是否有请求数据,如果存在(命中),则不用访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器
缓存之所以有效,主要因为程序运行时对内存的访问呈现局部性(Locality)特征。既包括空间局部性(Spatial Locality),也包括时间局部性(Temporal Locality),有效利用这种局部性,缓存可以达到极高的命中率
一句口水话总结缓存的作用:先翻小本本,找不到再去大仓库找,顺便抄一份带回来,下次就快了。
当 CPU 想要读一个数据(比如变量 x = 5),它不会直接冲去内存翻找,而是按下面几步来:
第一步:查缓存(有没有现成的?)
CPU 先问:“L1 缓存,你有没有这个数据?”有的话就直接拿走,速度飞快!(这叫命中 hit)没有 的话继续往下问 L2 → L3。
第二步:没命中?去内存拿!
如果所有缓存都没有,CPU 就得去内存里找这个数据。这就像你做饭时发现调料罐里没有盐,只能去厨房柜子里翻大包装的盐。
第三步:顺手存一份,下次更快
从内存拿到数据后,CPU 不仅自己用,还会顺手把这份数据存进缓存里,方便下次快速访问。就像你把大包盐倒一点到小盐罐里,下次做饭直接用小罐,不用再翻柜子了。
为什么缓存这么聪明?——靠“局部性原理”
缓存之所以有效,是因为程序有个“坏习惯”:喜欢反复访问最近用过的数据,或者附近的数据。这就叫“局部性(Locality)”,分两种:
时间局部性
最近用过的数据,很可能马上还会用!你早上刷牙,挤完牙膏后,可能还要用一次?所以你不会把牙膏盖子拧回去,而是留在那儿,等下还要用。
空间局部性
访问了一个数据,它附近的数据也很可能马上要用!你在书架上找《三体》,顺手也会看看旁边的《流浪地球》和《乡村教师》——因为它们都在一个区域。
伪共享
缓存以缓存行 cache line 为单位,每个缓存行对应着一块内存,一般是 64 byte(8 个 long),在 CPU 从主存获取数据时,以 cache line 为单位加载,于是相邻的数据会一并加载到缓存中
缓存会造成数据副本的产生,即同一份数据会缓存在不同核心的缓存行中,CPU 要保证数据的一致性,需要做到某个 CPU 核心更改了数据,其它 CPU 核心对应的整个缓存行必须失效,这就是伪共享
解决方法:
padding:通过填充,让数据落在不同的 cache line 中
@Contended:原理参考 无锁 → Adder → 优化机制 → 伪共享
Linux 查看 CPU 缓存行:
- 命令:
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size64- 内存地址格式:[高位组标记] [低位索引] [偏移量]
什么是缓存行(Cache Line)?
想象一下,你有一个大冰箱(主内存),每次从冰箱拿东西时,不是只拿你需要的那一小块食物,而是拿一大盘子的食物回来。这个大盘子就是“缓存行”,通常大小是64字节。
为什么会有伪共享?
假设你和你的室友共用一个冰箱,你们各自负责不同的食物。但是,如果你们的常用食物恰好放在同一个大盘子里,那么当一个人更新了自己负责的食物信息时,整个大盘子的信息都会被标记为“过期”。这样,另一个人再想查看自己的食物信息时,就必须重新从冰箱里拿新的大盘子回来。这就是“伪共享”。
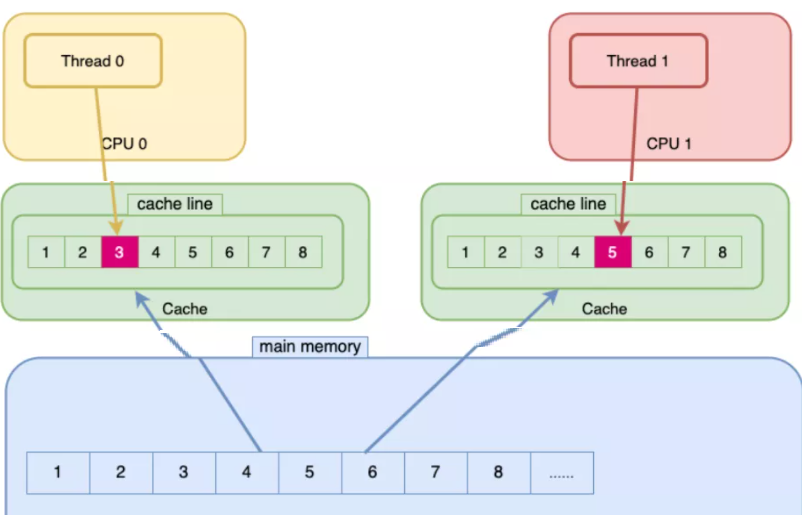
在图中,有两个线程(Thread 0 和 Thread 1),分别运行在两个CPU核心上(CPU 0 和 CPU 1)。每个CPU核心都有自己的缓存,而缓存是以缓存行为单位加载数据的。
- Thread 0 需要访问数据
3,于是将包含3的整个缓存行([1, 2, 3, 4, 5, 6, 7, 8])加载到自己的缓存中。 - Thread 1 需要访问数据
5,同样将包含5的整个缓存行([1, 2, 3, 4, 5, 6, 7, 8])加载到自己的缓存中。
现在问题来了:如果 Thread 0 修改了数据 3,为了保证数据一致性,Thread 1 缓存中的整个缓存行都会被标记为无效,即使 Thread 1 只关心数据 5。这就导致了不必要的缓存失效和重新加载,降低了性能。
解决方法
Padding(填充)
为了避免这种情况,可以通过在数据之间添加填充(padding),使得不同线程关心的数据落在不同的缓存行中。例如:
public class PaddedCounter {private volatile long counter;private long p1, p2, p3, p4, p5, p6; // 填充字段,确保 counter 单独占用一个缓存行
}这样,即使有多个线程同时修改不同的 PaddedCounter 实例,也不会因为它们的数据在同一缓存行中而导致伪共享。
@Contended 注解
Java 提供了 @Contended 注解来自动处理伪共享问题。当你在一个类的字段上使用 @Contended 注解时,JVM 会自动为该字段添加足够的填充,使其单独占用一个缓存行。
import jdk.internal.vm.annotation.Contended;public class ContendedCounter {@Contendedprivate volatile long counter;
}查看 Linux CPU 缓存行大小
在 Linux 系统中,你可以通过以下命令查看 CPU 缓存行的大小:
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size这条命令会输出缓存行的大小,通常是64字节。
缓存一致
缓存一致性:当多个处理器运算任务都涉及到同一块主内存区域的时候,将可能导致各自的缓存数据不一样
MESI(Modified Exclusive Shared Or Invalid)是一种广泛使用的支持写回策略的缓存一致性协议,CPU 中每个缓存行(caceh line)使用 4 种状态进行标记(使用额外的两位 bit 表示):
M:被修改(Modified)
该缓存行只被缓存在该 CPU 的缓存中,并且是被修改过的,与主存中的数据不一致 (dirty),该缓存行中的内存需要写回 (write back) 主存。该状态的数据再次被修改不会发送广播,因为其他核心的数据已经在第一次修改时失效一次
当被写回主存之后,该缓存行的状态会变成独享 (exclusive) 状态
E:独享的(Exclusive)
该缓存行只被缓存在该 CPU 的缓存中,是未被修改过的 (clear),与主存中数据一致,修改数据不需要通知其他 CPU 核心,该状态可以在任何时刻有其它 CPU 读取该内存时变成共享状态 (shared)
当 CPU 修改该缓存行中内容时,该状态可以变成 Modified 状态
S:共享的(Shared)
该状态意味着该缓存行可能被多个 CPU 缓存,并且各个缓存中的数据与主存数据一致,当 CPU 修改该缓存行中,会向其它 CPU 核心广播一个请求,使该缓存行变成无效状态 (Invalid),然后再更新当前 Cache 里的数据
I:无效的(Invalid)
该缓存是无效的,可能有其它 CPU 修改了该缓存行
解决方法:各个处理器访问缓存时都遵循一些协议,在读写时要根据协议进行操作,协议主要有 MSI、MESI 等
什么是缓存一致性?
想象一下,你和你的室友各自有一本笔记本(缓存),你们共同记录一些重要信息(主内存)。如果你们俩都记了同样的内容,但没有及时同步,那么你们的笔记可能会出现不一致的情况。这就类似于多处理器系统中的缓存一致性问题。
当多个处理器同时访问同一块主内存区域时,它们各自的缓存可能会保存不同的数据副本,导致数据不一致。为了解决这个问题,我们需要一套协议来确保所有处理器的缓存数据保持一致,这就是“缓存一致性”。
MESI 协议:保证缓存一致性的关键
MESI 是一种广泛使用的缓存一致性协议,它通过四种状态(M、E、S、I)来标记每个缓存行的状态,确保数据的一致性。
MESI 状态详解:
M: 被修改 (Modified)
- 含义:这个缓存行只被当前 CPU 缓存,并且已经被修改过,与主内存的数据不一致。
- 操作:
- 如果其他 CPU 需要读取这个缓存行的数据,当前 CPU 必须先将数据写回主内存,然后更新其他 CPU 的缓存。
- 当前 CPU 再次修改这个缓存行时,不需要通知其他 CPU,因为其他 CPU 的缓存已经失效。
E: 独享的 (Exclusive)
- 含义:这个缓存行只被当前 CPU 缓存,并且未被修改过,与主内存的数据一致。
- 操作:
- 如果其他 CPU 需要读取这个缓存行的数据,当前 CPU 可以直接将数据共享给其他 CPU,状态变为 S。
- 当前 CPU 修改这个缓存行时,状态变为 M。
S: 共享的 (Shared)
- 含义:这个缓存行可能被多个 CPU 缓存,并且各个缓存中的数据与主内存的数据一致。
- 操作:
- 如果某个 CPU 需要修改这个缓存行的数据,必须先发送广播请求,使其他 CPU 的缓存行变为 I,然后再进行修改。
I: 无效的 (Invalid)
- 含义:这个缓存行是无效的,可能有其他 CPU 修改了该缓存行。
- 操作:
- 如果需要使用这个缓存行的数据,必须从主内存重新加载。
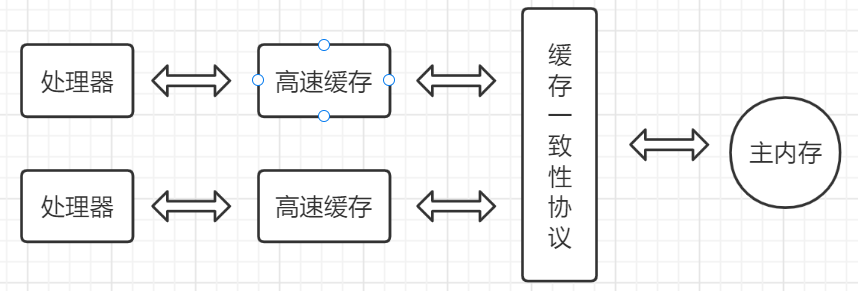
在图中,有两个处理器分别有自己的高速缓存,它们通过缓存一致性协议与主内存进行交互。
- 初始状态:两个处理器的缓存都是空的。
- 处理器 1 读取数据:处理器 1 从主内存读取数据到自己的缓存中,此时缓存行状态为 E。
- 处理器 2 读取相同数据:处理器 2 也读取相同的数据,此时两个处理器的缓存行状态都变为 S。
- 处理器 1 修改数据:处理器 1 修改数据,发送广播请求使处理器 2 的缓存行变为 I,然后处理器 1 的缓存行状态变为 M。
- 处理器 2 读取数据:处理器 2 重新从主内存读取数据,此时缓存行状态变为 S。
解决方法:遵循缓存一致性协议
为了保证缓存一致性,各个处理器在访问缓存时必须遵循一定的协议,如 MSI、MESI 等。这些协议规定了在读写操作时的具体步骤,确保所有处理器的缓存数据保持一致。
例如,在 MESI 协议中,当一个处理器修改了某个缓存行的数据时,会发送广播请求使其他处理器的相应缓存行变为无效状态,然后再进行修改。这样可以避免数据不一致的问题。
处理机制
用大白话总结:多核世界里,大家都有“小本本”(缓存),谁改了数据,得通知别人“别用旧数据了”——这就是现代 CPU 保证并发安全的底层机制。
单核 CPU:一个人干活,不用抢
想象你一个人在厨房做饭,你拿起盐罐、加盐、放回,整个过程不会被打断。在单核 CPU 中,基本的内存操作(比如读/写一个 int)是自动原子的,因为同一时间只有一个任务在执行,没人跟你抢。
int x = 1; // 单核下,这个赋值天然就是原子的多核时代:每个人都有小本本,容易乱
现在你和你室友一起做饭,你们都有一张“调料记录表”(缓存),记录盐还有多少。
- 你看到盐快没了,决定加盐,并更新你的表:“盐 = 满”。
- 但你室友也同时看到盐少,他也加盐,并更新他的表。
结果:你们都以为加了一次盐,实际上加了两次,还可能撒了一地。这就是数据不一致。
这就是多核并发问题:每个核心有自己的缓存,共享变量可能被同时修改,导致数据错乱。
CPU 怎么解决?两种“锁”的方式
CPU 提供了两种硬件级别的机制来保证共享数据的安全:
方式1:总线锁定 — “全场静止,我先改!”
就像你在会议室喊:“所有人别说话!我要宣布一个重要消息!”这时所有人都得闭嘴,等你说完才能继续。
技术细节:
- 当 CPU 要修改一个共享变量时,它在总线上发出
LOCK#信号。 - 其他所有 CPU 核心被强制暂停访问内存,直到这个操作完成。
- 保证这个读-改-写操作是原子的。
缺点:太霸道,影响性能
- 所有内存操作都被阻塞,哪怕别人不关心这个变量。
- 就像为了你加盐,让全厨房停工 10 秒,太浪费。
什么时候用?
当数据跨缓存行或没被缓存时,CPU 无法用缓存锁定,只能上“总线锁”。
方式2:缓存锁定 — “我改了,你们自己更新!”
你加完盐后,只在微信群里发一条:“盐我加满了,你们刷新下记录。”其他人看到消息,就把自己的旧记录划掉,重新查一次。这就是现代 CPU 更常用的机制:基于 MESI 协议 + 嗅探机制。
它是怎么工作的?
- CPU 修改自己缓存中的共享变量(比如
volatile int count)。 - 通过总线嗅探,广播这个修改事件。
- 其他 CPU “嗅探”到这条消息,发现这个地址的数据变了。
- 立即将自己缓存中对应的缓存行标记为 Invalid(无效)。
- 下次它们要读这个变量时,发现缓存无效 → 自动从主内存重新加载最新值。
这就是 volatile 关键字的底层实现原理!
关键机制:总线嗅探
嗅探机制 = 每个 CPU 都在“听群消息”
- 所有 CPU 核心都连接在一条公共总线上。
- 每个核心都时刻监听总线上的数据变化。
- 一旦发现某个内存地址被修改,就检查自己缓存里有没有这份数据。
- 有 → 标记为无效(I)
- 没有 → 忽略
好处:不需要锁住整个总线,只影响相关核心,效率高。
但也有副作用:总线风暴
什么是总线风暴?
想象你们家微信群:
- 你每秒发 100 条:“我加盐了!”、“我又加了!”、“再加一点!”……
- 你室友虽然不关心盐,但也得每秒看 100 次消息,累死了。
在 CPU 中:
- 某个核心高频修改 volatile 变量。
- 每次修改都要广播通知所有核心。
- 所有核心都要“嗅探”这条消息,即使它们根本不用这个变量。
- 导致总线流量爆炸,带宽耗尽,性能暴跌。
这就是 总线风暴。总线风暴的后果:
- CPU 总线带宽被占满
- 其他正常的数据传输变慢
- 整个系统性能下降
所以,不要滥用 volatile 和 synchronized,要根据实际场景,合理使用并发控制。
// 错误示范:高频 volatile 写,可能引发总线风暴
volatile long counter = 0;
// 多个线程疯狂 ++counter,每改一次就广播一次