HITTER——让双足人形打乒乓球(且可根据球的走向移动脚步):高层模型规划器做轨迹预测和击球规划,低层RL控制器完成击球
前言
今年以来,让人形机器人跳舞、跑步、拳击的视频层出不穷(这类工作基本会在模仿人类动作的前提下用RL反复训练),但
- 一方面,大家基本已经审美疲劳了,所以很多人觉得不如让人形机器人好好干活——让机器人干好活也是我司「七月在线」的第一重点
如此,关注到了Large Behavior Models,很快会解读 - 二方面,真正让人形机器人与高度动态环境自主互动的工作并不多
今天上午,我朋友圈内好几个朋友发了如下这个「人形机器人打乒乓球」的视频
UC伯克利:让人形机器人打乒乓球
我的第一反应是想到了去年24年年初斯坦福推出的炒虾机器人mobile aloha
- 当时最让我震撼的是三人团队也可以搞机器人或具身了
其次,总算看到机器人干点有用的事情了(比如家务) - 自那之后,心中便被其彻底点燃了一把火——对我而言,做软硬一体的产品比做纯软的应用 远远更具吸引力,加之23年起做的大模型应用开发太卷了
自此,我便和团队开始逐步发力具身智能,24年q2搭建团队,24年q3确定发力方向(一开始先只弄机械臂,25年再弄人形),24年q4正式切入具身开发
故本次人形打乒乓球,我愿意称之为人形的mobile aloha时刻
此外,实话讲,我们之前给一客户提供过让机械臂打乒乓球的解决方案,但让人形机器人打乒乓球,之前确实没咋想到,毕竟让双足人形干点活真不容易,我司努力了一年,也就在人形的展厅讲解、灵巧操作、箱子搬运做到了落地能力(跳舞/跑步/拳击跟干活无关)
- 而对于自主打乒乓球这个(自主这点很有含金量),算是人形干活的另一个落地场景了(比如陪练),不再只是单纯对人类动作的模仿,还得面对实时的动态环境,所以得加上对球的动态轨迹预测,即By combining a model-based planner for accurate ball trajectory prediction with a reinforcement learning–based whole-body controller
- 我相信未来一年内,会陆续出现人形机器人打羽毛球、网球、保龄球、高尔夫这样的工作,如此,明年的机器人运动会便会很有看点——且人形资本市场会因此再次走高 毕竟下半年起 人形已开始出现疲软态势,不会像今年的机器人运动会还只是个鸡肋
第一部分 HITTER
1.1 引言、相关工作
1.1.1 引言
如HITTER原论文所说,近年来,该领域在
- 运动控制[1-来自上海AI LAB的PIM,即Learning Humanoid Locomotion with Perceptive Internal Model]
- 动作模仿
[2],即Beyondmimic,也是巧,我在上一篇博客《BeyondMimic——通过引导式扩散实现动作捕捉:基于Diffuse-CLoC构建扩散框架,可模仿动作、导航避障(含UniTracker的详解)》中刚解读过
[3],即Kungfubot,详见此文《KungfuBot——基于物理约束和自适应运动追踪的人形全身控制PBHC,用于学习打拳或跳舞(即RL下的动作模仿和运控)》
方面取得了令人瞩目的进展
然而,大多数现有工作仍然主要关注于自由空间中的控制或与静态地面的交互。例如
- 保持平衡[4],即Hub: Learning extreme humanoid balance
- 行走[1],或模仿人类姿态[2]
而很少有研究涉及 “在动态环境中与高速移动物体交互” 等这种更具挑战性的任务
此类交互本质上更加困难:它们不仅要求在数十个关节之间实现协调控制,还需要在极短的时间尺度下运行紧密的感知-动作闭环
- 乒乓球运动正是这一挑战的典型代表。球速超过每秒5米,仅留给系统亚秒级的反应时间,迫使机器人在几百毫秒内完成感知、预测、规划和击打
- 与行走或静态操作不同,成功不仅依赖于灵活的全身动作,还需将快速挥臂与腰部旋转、迅速步伐和动态平衡恢复有机结合,以确保精准击球并为下一回合做好准备
且与羽毛球[5]或网球[6]等其他球拍类运动相比,乒乓球因距离更短、回合更快、反应窗口更小而具有更高的挑战性
因此,人形机器人乒乓球成为机器人领域独特的测试平台,原因在于:
- 其高度动态性,要求快速的球轨迹预测与击球规划
- 连续回合需要每次击球后的敏捷动作与平衡恢复
- 类人的击球动作对于效果和自然性都至关重要
为了解决这些挑战,来自UC伯克利的研究者们提出了HITTER

- 其paper地址为:HITTER: A HumanoId Table TEnnis Robot via Hierarchical Planning and Learning
其作者包括
Zhi Su, Bike Zhang, Nima Rahmanian, Yuman Gao, Qiayuan Liao, Caitlin Regan,
Koushil Sreenath, S. Shankar Sastry - 其项目地址为:humanoid-table-tennis.github.io
其采用了分层框架,将高层规划与低层控制分离
- 在高层,基于模型的规划器能够高精度地估算球的轨迹,并预测击球的位置、速度和时机
即规划器需要快速进行轨迹预测和击球规划,从而为控制器提供稳定的接口,并在训练过程中提升采样效率 - 在低层,基于RL的全身控制器被训练用于执行类人的击球动作,同时跟踪由规划器指定的球拍目标
即在连续击球任务上训练强化学习控制器,使其能够学习灵活的动作和可靠的平衡恢复能力;以及仅在训练中引入两种人体参考动作,通过这些参考,控制器能够获得自然且类人的击球动作
1.1.2 相关工作
首先,对于乒乓球机器人
机器人乒乓球已成为高速感知、规划与控制的重要测试平台,要求系统能够以极快的反应速度将球以竞技水平的速度击回
近年来,该领域在硬件、控制与学习方面取得了显著进展
- 例如,有研究者开发出了一种轻量级、高扭矩的机器人手臂,结合模型预测控制,实现了多样化击球风格的高精度执行
[7-High speed robotic table tennis swinging using lightweight hardware with model predictive control]
同样,基于模型的击球速度控制方法也展示了高成功率的精准回球能力 [8-Modelbased trajectory prediction and hitting velocity control for a new table tennis robot] - 在学习领域,DeepMind 的 Gemini Robotics 团队提出了用于乒乓球的快速基于学习的技术开创性工作
[9],即Robotic Table Tennis: A Case Study into a High Speed Learning System
[10],即Sasprompt: Large language models as numerical optimizers for robot selfimprovement
在该工作的基础上,通过采用分层架构和虚实迁移,实现了业余人类水平的竞技表现[11-Achieving human level competitive robot table tennis]
- 此外,除了专用的机器人乒乓球设备,通用人形机器人也已被证明能够通过阻抗控制进行乒乓球对打 [12-Impedance control and its effects on a humanoid robot playing table tennis]
然而,已有工作中,人形机器人被限制为静止站立,缺乏灵活的移动能力,从而限制了有效击球范围
在本研究中,作者聚焦于类人且灵活的伸展运动,用于乒乓球击球,这一能力此前尚未在人形机器人上得到展示
其次,对于人形机器人全身控制
近年来,仿人机器人全身控制取得了快速进展
- 早期的研究主要集中在训练人形机器人利用大规模强化学习来模仿特定的人体动作
[13],即Exbody,详见此文《可跳简单舞蹈的Exbody 2——从MDM、RobotMDM到全身运动控制策略Exbody:人体运动扩散模型赋能机器人的训练》
[14],即Omnih2o,详见此文《H2O与OmniH2O——通过RGB摄像头或VR全身实时摇操:仿真RL中训练,然后再sim2real(含师生学习与策略蒸馏详解)》
其他方法则将控制分为上半身和下半身的独立策略,以简化学习和协调过程
[15],即Falcon,详见此文《人形loco-manipulation专题——涵盖Mobile-TeleVision、下肢RL-上肢模仿的AMO、上下双智能体联合训练的FALCON》的第三部分 - 近期的研究趋势转向开发能够模仿多种人体动作的通用全身运动跟踪器
[16],即Twist,详见此文《TWIST——基于动捕的全身遥操模仿学习:教师策略RL训练,学生策略结合RL和BC联合优化》
[17],即Gmt: General motion tracking for humanoid whole-body control
在这些进展的基础上[特别是2-Beyondmimic],HITTER是专为实现与环境快速且动态交互(如击球)而设计的类人全身控制器
1.1.3 系统概述
HITTER采用了一个分层系统框架,将基于模型的规划器与基于学习的全身控制器集成在一起(见图2)
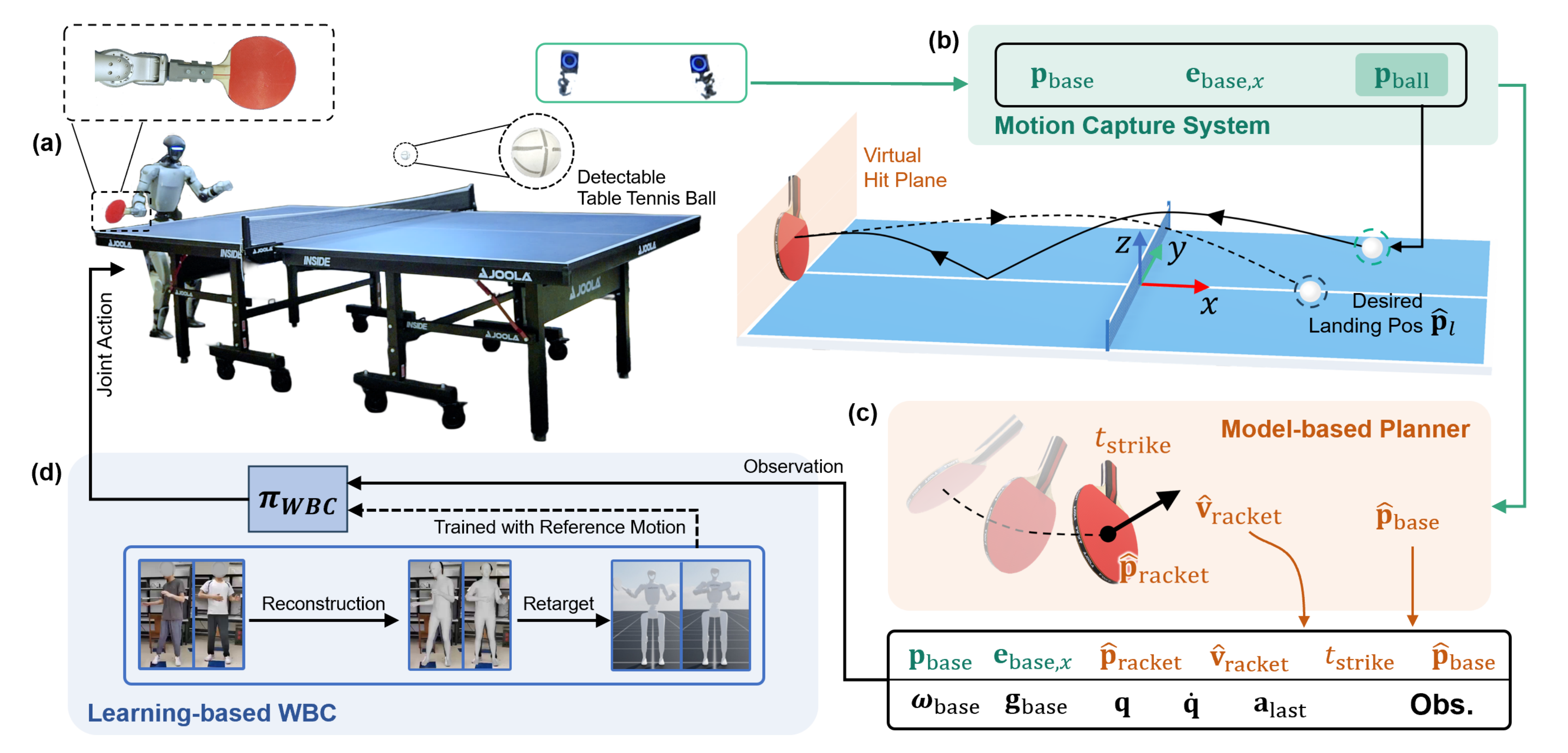
- 九台OptiTrack摄像机用于追踪球的位置,运动捕捉系统以360 Hz的频率运行,能够实现毫米级的精度
估算得到的球位置信息被提供给基于模型的规划器,规划器预测击球位置和时间,并计算Unitree G1仿人机器人在击球瞬间所需的球拍速度 - 机器人配备了强化学习策略,能够处理观测信息,并以50 Hz的频率输出29个关节的期望关节位置。这些关节位置设定值通过PD控制器转换为关节力矩
如上图图2所示,作者使用一张标准尺寸的球台,尺寸为2.74米×1.525米,台面距离地面0.76米。坐标系定义在台面中心,x轴与球台长边对齐,z轴指向上方
在下文中,作者假设人形机器人位于球台x < 0的一侧
1.2 基于模型的规划器
基于模型的规划器在每个时间步接收球的位置,并预测球拍的击球位置、速度和时机。随后,这些预测结果会传递给全身控制器,以生成机器人的动作
简言之,两个阶段
- 球来了
预测来球的速度、来球的位置 - 打回去
合理的击球位置、时机、球拍速度
1.2.1 球来了:状态估计、对乒乓球的轨迹预测(预测来球的速度、来球的位置)
在预测球的轨迹之前,作者首先需要估算其速度,因为该速度无法直接通过运动捕捉系统获得
- 为此,作者对每个坐标方向上球的位置随时间变化的数据,
,采用二阶多项式进行最小二乘拟合
拟合过程中使用最近的31个位置测量值,从而为位置和速度提供平滑的估计 - 当检测到球在桌面上反弹时,清空位置测量缓冲区,以防止包含反弹前的数据
随后,通过计算及其导数
,即可获得当前时刻球的位置和速度的平滑估计值
为了预测球的轨迹,作者采用了与文献[7-High speed robotic table tennisswinging using lightweight hardware with model predictive control]中相同的混合动力学模型——定义为公式1a、公式1b:
- 其中(1a)描述了球的连续时间飞行动力学,
和
分别表示其加速度和速度。这里,
为空气阻力系数,g为重力向量。假设旋转足够小,因此可以忽略由旋转引起的效应,如马格努斯力
- 方程(1b)则对球在桌面弹跳时的离散时间碰撞动力学进行建模,其中v−和v+分别表示碰撞前后的速度
其中,恢复系数矩阵为
其中
和
分别表示水平和垂直方向的恢复系数
且冲击状态集为
作者从15 条记录的球轨迹中估算参数,
和
。在每一条轨迹中,球从球桌的一侧发射,落在对侧弹跳一次,然后离开球桌
通过将记录的数据拟合到以下内容来识别这些参数:
其中 和
分别由p(t)的一阶和二阶导数估算得到。基于该模型,作者采用显式逐步时间积分的方法,利用上文「1.2.1 状态估计」中的估算值初始化,以预测球的未来位置和速度
假设存在一个预定义的虚拟击球平面,位于x=−1.37 米时,可以计算出相应的击打时间和位置
1.2.2 打回去——期望的球拍速度(由基于“落点和击球位置”而定的出球速度 + 来球速度共同决定)、时机
除了与球接触之外,作者的目标是成功将球回击,这需要确定球拍在击球瞬间的朝向和速度
假设在击球时,球拍平面与其速度向量垂直。与那些旨在精确控制落点的方法不同,作者的目标是确保回球有效,因此,作者采用了简化的击球后飞行模型和球拍–球的相互作用模型
- 对于球拍与球的相互作用 这点上,在球拍与球接触期间,作者假设沿球拍表面法线方向的恢复系数为
,并忽略切向摩擦
- 对于击球后的飞行模型,击球后,假定球在飞行过程中仅受重力作用
给定球在台面上的期望落点、期望击球位置
,以及从击球到落点的预定飞行时间
- 期望的出球速度
计算如下
其中
被设置在对方球台的中心
- 根据期望的出球速度
,可以计算出期望的球拍速度
,如下所示
其中
是指该方向上的单位向量
期望的球拍速度以及预测的击球位置(这里据我判断,应该就是期望的击球位置)和时间,随后被传递给基于学习的全身控制器,该控制器生成相应的机器人运动
1.3 基于学习的全身控制器
- 基于模型的规划器预测期望的球拍击球位置
、速度
和击球时刻
。这些预测结果被传递给基于学习的全身控制器(WBC),由其生成对应的人形机器人全身运动
- 且作者在Isaac Lab [19] 中训练了 WBC 策略
,并以零样本迁移的方式部署到实际机器人上。该策略采用无模型强化学习算法 PPO [20] 进行端到端训练。关节 PD 增益按照 [2] 的启发式方法设定
1.3.1 人体动作参考
为了促进类人的动作表现,作者在策略训练中引入了人体动作参考。他们使用两种参考挥拍动作:正手和反手,这两种动作均通过相同的流程生成
- 首先,录制人类执行挥拍动作的视频片段
- 然后,利用GVHMR [22] 从该视频重建对应的 SMPL[21] 动作片段,随后通过 GMR [23],[16] 将其重新定向到人形机器人上
最终得到的动作片段包含以30 Hz 采样的基础姿态和关节位置
按照 BeyondMimic [2] 的方法,作者增强了运动以实现更好的跟踪
- 首先,将基础姿态和关节位置从 30 Hz 插值到 50 Hz,以匹配策略的控制频率
- 然后,利用中心差分法计算基础线速度、角速度和关节速度
通过正向运动学,获得每个身体部位的姿态
和扭转速度
由于只跟踪上半身的运动,B 仅包含骨盆以上的身体部位(骨盆、躯干和手臂)。骨盆被选为锚定身体,其余身体部位的目标姿态按照 [2] 的方法计算
处理完成后,每个动作片段包含 94 帧(1.88秒),击打动作发生在第 43 帧 (0.86 秒)
1.3.2 马尔可夫决策过程(MDP)设置
第一,对于底座与球拍的独立指令
作者没有像文献[5]那样,在击球时使用球拍的全局位置和速度作为指令,而是将底座和球拍的指令分离,以提升训练效率
- 首先,指令
指定了世界坐标系下期望的基座位置,促使机器人及时到达目标位置
- 第二个指令
指定了球拍相对于基座的位置以及球拍的速度(两者均以世界坐标系表示)
期望的基座朝向始终设定为面向前方
为了使策略能够连续击球并在不同挥拍类型之间切换,每个训练回合持续10秒。完成一次挥拍后,作者会均匀采样下一次挥拍类型(正手或反手),并在击球时随机采样球拍目标位置、球拍目标速度和底座目标位置,这些采样结果取决于挥拍类型
击球平面固定在机器人前方0.4米的位置,因此只对球拍目标位置的y和z坐标进行采样。正手和反手的目标区域被定义为互不重叠
第二,对于奖励函数
为了生成既能模仿参考动作又能跟踪给定指令的动作,作者遵循[24-Deepmimic]的方法,将总奖励定义为:
其中 鼓励对上半身参考动作的模仿,
奖励对指令目标的跟踪,
提供正则化。
、
和
分别为对应的奖励权重
和
都是在整个回合中持续施加的稠密奖励。相比之下,
包含了若干稀疏但权重相对较高的项。例如,球拍的位置、速度和朝向的跟踪奖励仅在击球时刻前后的短暂时间窗口内激活,而底座位置的跟踪奖励则只在击球前激活,从而使策略能够在击球后为过渡到下一个目标位置做好准备
第三,对于非对称Actor-Critic
为了在训练过程中为critic提供在部署时策略无法获得的额外信息,作者采用了非对称actor–critic框架 [25](见表I)。例如,为了提升参考轨迹跟踪性能,作者在critic的观测中增加了机器人本体姿态TB,从而有助于更准确地估算回报。由于中的若干项是稀疏的,回合回报取决于剩余击打次数
因此,作者还为评判器额外提供了当前回合剩余的时间。执行器和评判器均采用三层隐藏层的多层感知机(MLP)实现,隐藏层规模分别为512、256和128
// 待更