JavaSE丨集合框架入门(二):从 0 掌握 Set 集合
这节我们接着学习 Set 集合。
一、Set 集合
1.1 Set 概述
java.util.Set 接口继承了 Collection 接口,是常用的一种集合类型。 相对于之前学习的List集合,Set集合特点如下:
除了具有 Collection 集合的特点,还具有自己的一些特点:
- Set是一种无序的集合
- Set是一种不带下标索引的集合
- Set是一种不能存放重复数据的集合
Set 接口继承体系:
Set 接口方法:

基础案例:
实例化一个Set集合,往里面添加元素并输出,注意观察集合特点(无序、不重复):
import java.util.Set;
import java.util.HashSet;
import java.util.Iterator;public class SetTest {public static void main(String[] args) {//1.实例化Set集合,指向HashSet实现类对象Set<String> set = new HashSet<>();set.add("hello1");set.add("hello2");set.add("hello3");set.add("hello4");set.add("hello5");set.add("hello5"); //添加失败 重复元素//增强for循环遍历for (String obj : set) {System.out.println(obj);}System.out.println("------------------");//迭代器遍历Iterator<String> it = set.iterator();while (it.hasNext()) {Object obj = it.next();System.out.println(obj);}}
}
运行结果:
hello1
hello4
hello5
hello2
hello3
------------------
hello1
hello4
hello5
hello2
hello3通过以上代码和运行结果,可以看出Set类型集合的特点:无序、不可重复
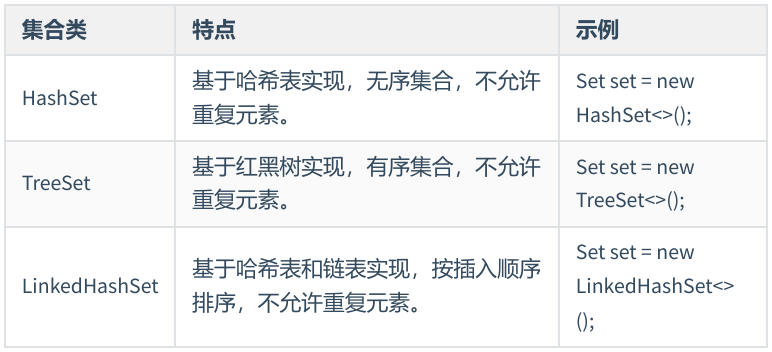
1.2 HashSet
java.util.HashSet 是Set接口的实现类,它使用哈希表(Hash Table)作为其底层数据结构来存储数据。
HashSet特点:
- 无序性:HashSet中的元素的存储顺序与插入顺序无关
HashSet使用哈希表来存储数据,哈希表根据元素的哈希值来确定元素的存储位置,而哈希值是根据元素的内容计算得到的,与插入顺序无关。
- 唯一性:HashSet中不允许重复的元素,即每个元素都是唯一的
关键:存储自定义对象时,必须同时重写hashCode()和equals(),否则无法保证唯一性(默认用地址值计算哈希,导致内容相同的对象被视为不同元素)。
- 允许null元素:HashSet允许存储null元素,但只能存储一个null元素, HashSet中不允许重复元素
- 高效性:HashSet的插入、删除和查找操作的时间复杂度都是O(1)
哈希表通过将元素的哈希值映射到数组的索引来实现快速的插入、删除和查找操作。
基础案例1:
实例化HashSet对象,往里面插入多个字符串,验证HashSet特点。
import java.util.HashSet;
import java.util.Set;public class HashSetTest {public static void main(String[] args) {//1.实例化HashSet对象Set<String> set = new HashSet<>();//2.添加元素set.add("hello");set.add("world");set.add("nihao");set.add("hello");set.add(null);set.add(null);System.out.println("size:"+set.size());//3.遍历for (String str : set) {System.out.println(str);}}
}
运行结果:
size:4
null
world
nihao
hello根据结果可知,HashSet无序、唯一、null值可存在且只能存在一个。
元素插入过程:
当向HashSet中插入元素时,先获取元素的hashCode()值,再检查HashSet中是否存在相同哈希值的元素,如果元素哈希值唯一,则直接插入元素
如果存在相同哈希值的元素,会调用元素的equals()方法来进一步判断元素是否是相同。如果相同,则不会插入重复元素;如果不同,则插入元素
案例展示:
重写Student类的hashCode()方法:
class Student {private String id; // 关键属性1(equals中比较)private String name; // 关键属性2(equals中比较)private int age; // 非关键属性(equals中不比较,hashCode中也不参与计算)// 构造方法public Student(String id, String name, int age) {this.id = id;this.name = name;this.age = age;}// 先重写equals()(必须与hashCode()基于相同属性)@Overridepublic boolean equals(Object obj){if (this == obj) {return true;}if (obj == null) {return false;}if (getClass() != obj.getClass()) {return false;}Student other = (Student)obj;if (name == null) {if (other.name != null) {return false;}}else if (!name.equals(other.name)) {return false;}if (age != other.age) {return false;}return true;}// 重写hashCode()(基于id和name计算)@Overridepublic int hashCode() {int result = 17; // 初始化哈希种子(非零经验值)// 处理id(引用类型,可能为null)int idHash = (id == null) ? 0 : id.hashCode();result = 31 * result + idHash; // 31是质数,减少哈希冲突// 处理name(引用类型,可能为null)int nameHash = (name == null) ? 0 : name.hashCode();result = 31 * result + nameHash;return result; // 返回最终哈希值}
}如果要往HashSet集合存储自定义类对象,那么一定要重写自定义类中的 hashCode方法和equals方法!
1.3 TreeSet
TreeSet是SortedSet(Set接口的子接口)的实现类,它基于红黑树(Red Black Tree)数据结构实现。
TreeSet特点:
- 有序性:插入的元素会自动排序,每次插入、删除或查询操作后,TreeSet会自动调整元素的顺序,以保持有序性。
- 唯一性:TreeSet中不允许重复的元素,即集合中的元素是唯一的。如果尝试插入一个已经存在的元素,该操作将被忽略。
- 动态性:TreeSet是一个动态集合,可以根据需要随时添加、删除和修改元素。插入和删除操作的时间复杂度为O(log n),其中n是集合中的元素数量。
- 高效性:由于TreeSet底层采用红黑树数据结构,它具有快速的查找和插入性能。对于有序集合的操作,TreeSet通常比HashSet更高效。
基础案例:
准备一个TreeSet集合,放入多个自定义类Person对象,观察是否自动进行排序。
基础类Person类:
import java.util.Set;import java.util.TreeSet;class Person {private String name;private int age;public Person() {}public Person(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "Person [name=" + name + ", age=" + age + "]";}
}测试类:
public class Test_Person {public static void main(String[] args) {//1.实例化TreeSetSet<Person> set = new TreeSet<>();//2.添加元素set.add(new Person("zs", 21));set.add(new Person("ls", 20));set.add(new Person("tom", 19));//3.遍历集合for (Person person : set) {System.out.println(person);}}
}运行程序发现:
//程序运行,提示异常,具体如下:
Exception in thread "main" java.lang.ClassCastException:
java.lang.Comparableat java.util.TreeMap.compare(TreeMap.java:1290)at java.util.TreeMap.put(TreeMap.java:538)at java.util.TreeSet.add(TreeSet.java:255)at Test_Person.main(Test_Person.java:41)问题分析:
根据异常提示可知错误原因是: Person 无法转化成 Comparable ,从而导致 ClassCastException 异常 。 为什么会这样呢?
解析:
TreeSet是一个有序集合,存储数据时,一定要指定元素的排序规则,有两种指定的方式,具体如下:
- 自然排序(元素所属类型要实现 java.lang.Comparable 接口)
- 比较器排序
1)自然排序
如果一个类,实现了 java.lang.Comparable 接口,并重写了 compareTO 方法,那么这个类的对象就是可以比较大小的。
public interface Comparable<T> {public int compareTo(T o);
}compareTo方法说明:
int result = this.属性.compareTo(o.属性);
- result的值大于0,说明this比o大
- result的值小于0,说明this比o小
- result的值等于0,说明this和o相等
元素插入过程:
当向TreeSet插入元素时,TreeSet会使用元素的 compareTo() 方法来比较元素之间的大小关系。根据比较结果,TreeSet会将元素插入到合适的位置,以保持有序性。如果两个元素相等( compareTo() 方法返回0),TreeSet会认为这是重复的元素,只会保留一个。
基础 Person 类:
//定义Person类,实现自然排序
public class Person implements Comparable<Person> {private String name;private int age;public Person() {}public Person(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "Person [name=" + name + ", age=" + age + "]";}//重写方法,指定比较规则:先按name升序,name相同则按age降序@Overridepublic int compareTo(Person o) {//注意:字符串比较需要使用compareTo方法int r = name.compareTo(o.name);if(r == 0) {r = o.age - this.age;}return r;}
}测试类:
import java.util.Set;
import java.util.TreeSet;
import com.briup.chap08.bean.Person;//自然排序测试
public class Test073_Comparable {public static void main(String[] args) {//1.实例化TreeSetSet<Person> set = new TreeSet<>();//2.添加元素set.add(new Person("zs", 21));set.add(new Person("ww", 20));set.add(new Person("zs", 21));set.add(new Person("tom", 19));set.add(new Person("tom", 23));set.add(new Person("jack", 20));//3.遍历集合for (Person person : set) {System.out.println(person);}}
}运行结果:
Person [name=jack, age=20]
Person [name=tom, age=23]
Person [name=tom, age=19]
Person [name=ww, age=20]
Person [name=zs, age=21]对于整型、浮点型元素,它们会按照从小到大的顺序进行排序。对于字符串类型的元素,它们会按照字典顺序进行排序。
注意事项:compareTo方法的放回结果,只关心正数、负数、零,不关心具体的值是多少
2)TreeSet 比较器排序
思考:如果上述案例中Person类不是自定义类,而是第三方提供好的(不可以修改源码),那么如何实现排序规则的指定?
我们可以使用比较器(Comparator)来自定义排序规则。
比较器排序步骤:
- 创建一个实现了Comparator接口的比较器类,并重写其中的 compare() 方法
- 该方法定义了元素之间的比较规则。在 compare() 方法中,我们可以根据元素的属性进行比较,并返回负整数、零或正整数,来表示元素之间的大小关系。
- 创建TreeSet对象时,将比较器对象作为参数传递给构造函数,这样,TreeSet 会根据比较器来进行排序。
compare方法说明:
int result = compare(o1, o2);
- result的值大于0,表示升序
- result的值小于0,表示降序
- result的值等于0,表示元素相等,不能插入
注意:这里和自然排序的规则是一样的,只关心正数、负数、零,不关心具体的值是多少
案例展示:
使用比较器排序,对上述案例中Person进行排序,要求先按age升序,age相同则按name降序。
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;public class TestPerson {public static void main(String[] args) {//1.准备自定义比较器对象//匿名内部类形式Comparator<Person> comp = new Comparator<Person>() {//重写比较算法:先按age升序,age相同则按name降序@Overridepublic int compare(Person o1,Person o2){int r = o1.getAge() - o2.getAge();if (r == 0) {//注意:比较字符串需使用compareTo()方法r = o2.getName().compareTo(o1.getName());}return r;}};//2.实例化TreeSet,传入自定义比较器对象Set<Person> set = new TreeSet<>(comp);//3.添加元素set.add(new Person("zs",21));set.add(new Person("ww",20));set.add(new Person("zs",21));set.add(new Person("tom",19));set.add(new Person("tom",23));set.add(new Person("jack",20));//4.遍历集合for (Person person : set) {System.out.println(person);}}
}运行结果:
Person [name=tom, age=19]
Person [name=ww, age=20]
Person [name=jack, age=20]
Person [name=zs, age=21]
Person [name=tom, age=23]注意:如果同时使用自然排序和比较器排序,比较器排序将覆盖自然排序。
| 对比项 | 自然排序(Comparable) | 比较器排序(Comparator) |
|---|---|---|
| 实现位置 | 元素类内部实现接口,重写 compareTo | 元素类外部创建比较器,重写 compare |
| 排序规则数量 | 一个类只能有一种自然排序规则 | 一个类可以有多个比较器,实现不同规则 |
| 优先级 | 若同时传比较器,自然排序会被覆盖 | 传入比较器时,优先用比较器规则 |
| 适用场景 | 元素有固定、单一排序规则(如 Integer 数值) | 需要临时、多样化排序(如有时按年龄,有时按姓名) |
| 代码侵入性 | 必须修改元素类代码(让其实现 Comparable) | 无需修改元素类,外部单独定义规则 |
1.4 LinkedHashSet
LinkedHashSet 是 HashSet 的一个子类,具有 HashSet 的高效性能和唯一性特性,并且保持了元素的插入顺序,其底层基于哈希表和链表实现。
案例展示:
实例化一个LinkedHashSet集合对象,存入多个String字符串,观察是否唯一及顺序存储。
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.Set;public class Test_LinkedHashSet {public static void main(String[] args) {//1.实例化LinkedHashSetSet<String> set = new LinkedHashSet<>();//2.添加元素set.add("bbb");set.add("aaa");set.add("abc");set.add("bbc");set.add("abc");//3.迭代器遍历Iterator it = set.iterator();while (it.hasNext()) {System.out.println(it.next());}}
}运行结果:
bbb
aaa
abc
bbc1.5 Set 小结
下节我们学习Map集合。