机器学习可解释库Shapash的快速使用教程(五)
文章目录
- 1 快速使用
- 1.1 安装
- 1.2 三个简单步骤快速入门
- 1.2.1 步骤 1:准备模型和数据
- 1.2.2 步骤 2:声明并编译 SmartExplainer
- 1.2.3 步骤 3:可视化和探索
- 1.2.4 启动 Web 应用
- 1.2.5 将解释结果导出为数据
- 2 Shapash的后端集成
- 2.1 方法一:SHAP后端集成
- 2.1.1 自动解释器选择
- 2.1.2 计算贡献度
- 2.1.3 使用预计算的SHAP值
- 2.1.4 交互值:特征互相影响值
- 2.1.5 性能考虑
- 2.1.6 与Shapash可视化集成
- 2.2 方法二:LIME后端集成
- 2.2.1 LIME 后端建模流程
- 2.2.2 在工作流程中使用 LIME 后端
- 2.2.3 处理不同模型类型
- 2.2.4 性能考虑
- 2.2.5 限制和注意事项
- 2.2.6 使用场景推荐
- 2.3 方法三:自定义后端
- 2.3.1 第一步:定义您的后端类
- 2.3.2 第二步:实现核心的 run_explainer 方法
- 2.3.3 第三步:处理多类别场景(可选)
- 2.3.4 第四步:添加自定义参数和方法
- 2.3.5 集成您的自定义后端
- 2.3.5.1 方法一:直接实例化
- 2.3.5.2 方法二:注册(高级)
- 2.3.6 自定义后端的最佳实践
- 2.3.7 真实示例:ELI5 后端
- 3 用于部署的SmartPredictor
- 3.1 为什么在部署中使用 SmartPredictor?
- 3.2 核心架构和工作流
- 3.3 关键组件
- 3.4 创建 SmartPredictor
- 3.4.1 方法 1:从 SmartExplainer 创建(推荐)
- 3.4.2 方法 2:直接初始化
- 3.5 处理新数据
- 3.5.1 步骤 1:添加输入数据
- 3.5.2 步骤 2:生成预测
- 3.5.3 步骤 3:计算贡献度
- 3.6 生成解释摘要
- 3.7 自定义解释
- 3.8 持久化和部署
- 3.9 生产集成
- 3.10 部署最佳实践
- 4 HTML报告生成
- 4.1 报告生成的工作原理
- 4.2 创建您的第一份报告
- 4.3 报告内容详解
- 4.4 自定义您的报告
- 4.5 报告生成的最佳使用场景
- 5 Web应用部署:Dash库的使用
- 5.1 基本 Web 应用程序部署
- 5.2 向 Web 应用程序添加额外数据
- 5.3 生产部署注意事项
- 5.3.1 主机配置
- 5.3.2 自定义 Web 应用程序设置
- 5.4 管理 Web 应用程序
- 5.4.1 启动应用程序
- 5.4.2 停止应用程序
- 5.4.3 使用自定义启动脚本进行高级部署
- 5.5 Web 应用程序部署的使用场景
- 6 参考文献
1 快速使用
Shapash 是一个 Python 库,旨在让每个人都能轻松理解和解释机器学习模型。它提供带有明确标签的清晰可视化,帮助技术人员和非技术人员理解模型如何进行预测。本快速入门指南将引导您通过基本步骤,在几分钟内快速上手 Shapash。
机器学习模型通常被视为无法解释预测过程的"黑盒"。Shapash 通过提供直观的可视化和交互式工具来弥合这一差距,揭示特征如何影响预测结果。无论您是需要向利益相关者解释模型的数据科学家,还是希望理解模型决策的业务用户,Shapash 都能让这一过程变得简单易行。
1.1 安装
在开始之前,请确保您已安装 Python 3.9 至 3.12 版本。您可以使用 pip 安装 Shapash:
pip install shapash
如需报告生成等额外功能,请安装附加依赖:
pip install shapash[report]
1.2 三个简单步骤快速入门
让我们通过一个基本示例,展示如何使用 Shapash 快速解释您的模型。
1.2.1 步骤 1:准备模型和数据
首先,让我们设置一个简单的机器学习模型。在本例中,我们将使用 Shapash 自带的房价数据集:
import pandas as pd
from category_encoders import OrdinalEncoder
from lightgbm import LGBMRegressor
from sklearn.model_selection import train_test_split
from shapash.data.data_loader import data_loading
from shapash import SmartExplainer# 加载数据集
house_df, house_dict = data_loading('house_prices')# 分离特征和目标变量
y_df = house_df['SalePrice'].to_frame()
X_df = house_df[house_df.columns.difference(['SalePrice'])]# 编码分类特征
categorical_features = [col for col in X_df.columns if X_df[col].dtype == 'object']
encoder = OrdinalEncoder(cols=categorical_features, handle_unknown='ignore', return_df=True)
X_df = encoder.transform(X_df)# 划分数据集
Xtrain, Xtest, ytrain, ytest = train_test_split(X_df, y_df, train_size=0.75, random_state=1)# 训练模型
regressor = LGBMRegressor(n_estimators=100).fit(Xtrain, ytrain)
1.2.2 步骤 2:声明并编译 SmartExplainer
现在,创建一个 SmartExplainer 对象,并用您的模型和数据进行编译:
# 声明 SmartExplainer
xpl = SmartExplainer(model=regressor,preprocessing=encoder, # 可选:帮助解码编码后的特征features_dict=house_dict # 可选:提供可读的特征名称
)# 使用测试数据编译
xpl.compile(x=Xtest,y_target=ytest # 可选:允许将预测值与实际值进行比较
)
SmartExplainer 是 Shapash 的核心组件。它接收您的训练模型,并使用 SHAP 或 LIME 等后端计算解释结果。compile 方法为可视化准备这些解释结果。
1.2.3 步骤 3:可视化和探索
编译好 SmartExplainer 后,您可以通过多种方式探索模型的行为:
1.2.4 启动 Web 应用
探索模型最简单的方式是通过 Shapash 的交互式 Web 应用:
app = xpl.run_app(title_story='House Prices', port=8020)
这将启动一个本地 Web 服务器,您可以:
- 在全局和局部可解释性之间切换
- 过滤和选择特定数据点
- 查看特征重要性和贡献度
- 比较不同样本的预测结果
完成后,只需停止应用:
app.kill()
1.2.5 将解释结果导出为数据
您还可以将解释结果导出为 pandas DataFrame 以便进一步分析:
summary_df = xpl.to_pandas(max_contrib=3, # 显示前 3 个贡献最大的特征threshold=5000, # 最小贡献阈值
)
这将创建一个 DataFrame,显示每个特征对单个预测的贡献度,便于程序化分析模型行为。
2 Shapash的后端集成
2.1 方法一:SHAP后端集成
SHAP(SHapley Additive exPlanations)后端是集成到Shapash中的核心可解释性方法之一,为解释机器学习模型预测提供了强大功能。该后端利用流行的SHAP库计算Shapley值,这种值基于合作博弈论提供了特征重要性的统一度量标准。
SHAP值通过在特征间分配归因,为解释单个预测提供了数学上合理的方法。Shapash中的SHAP后端弥合了SHAP的理论强大性与实用、用户友好的可视化之间的差距。这种集成使数据科学家能够:
- 生成一致且局部准确的解释
- 处理分类和回归模型
- 使用各种模型类型(基于树的模型、线性模型和模型无关型)
- 通过多种图表类型可视化解释
2.1.1 自动解释器选择
SHAP后端的关键优势之一是其智能解释器选择机制。当初始化后端时,它会自动确定最适合您模型的SHAP解释器:
def __init__(self, model, preprocessing=None, masker=None, explainer_args=None, explainer_compute_args=None):# ... 初始化代码 ...if self.explainer_args:if "explainer" in self.explainer_args.keys():shap_parameters = {k: v for k, v in self.explainer_args.items() if k != "explainer"}self.explainer = self.explainer_args["explainer"](**shap_parameters)else:self.explainer = shap.Explainer(**self.explainer_args)else:# 基于模型类型自动选择if shap.explainers.Linear.supports_model_with_masker(model, self.masker):self.explainer = shap.Explainer(model=model, masker=self.masker)elif shap.explainers.Tree.supports_model_with_masker(model, None):self.explainer = shap.Explainer(model=model)elif shap.explainers.Additive.supports_model_with_masker(model, self.masker):self.explainer = shap.Explainer(model=model, masker=self.masker)# ... 回退到模型无关方法 ...
这种自动选择过程按效率和准确性的顺序尝试不同的解释器:
- LinearExplainer 用于线性模型
- TreeExplainer 用于基于树的模型(最有效)
- AdditiveExplainer 用于加性模型
- KernelExplainer 或 PermutationExplainer 作为模型无关的回退方案
2.1.2 计算贡献度
核心功能在run_explainer方法中实现:
def run_explainer(self, x: pd.DataFrame) -> dict:"""使用Shap解释器计算并返回局部贡献度参数----------x : pd.DataFrame模型使用的观测数据框返回-------explain_data : pd.DataFrame 或 pd.DataFrame列表局部贡献度"""print("INFO: Shap解释器类型 -", self.explainer)contributions = self.explainer(x, **self.explainer_compute_args)explain_data = dict(contributions=contributions.values)return explain_data
该方法接收输入数据,使用选定的解释器计算SHAP值,并以Shapash可以进一步处理的标准格式返回它们。
2.1.3 使用预计算的SHAP值
如果您已经在Shapash外部计算了SHAP值,可以直接使用它们:
# 手动计算SHAP值
masker = pd.DataFrame(shap.kmeans(x_test, 50).data, columns=x_test.columns)
explainer = shap.explainers.PermutationExplainer(model=model.predict_proba, masker=masker)
shap_contrib = explainer.shap_values(x_test)# 与Shapash一起使用
xpl = SmartExplainer(model=model,preprocessing=preprocessing
)xpl.compile(contributions=shap_contrib, # 预计算的SHAP值x=x_test,y_pred=predictions
)
2.1.4 交互值:特征互相影响值
SHAP后端还支持计算SHAP交互值,这些值显示特征如何相互影响:
def get_shap_interaction_values(x_df, explainer):"""计算给定数据框的shap交互值。同时检查解释器是否为TreeExplainer。"""if not isinstance(explainer, shap.TreeExplainer):raise ValueError(f"解释器类型 ({type(explainer)}) 不是TreeExplainer。"f"Shap交互值只能为TreeExplainer类型计算")shap_interaction_values = explainer.shap_interaction_values(x_df)# 对于向量输出模型,求和贡献度if isinstance(shap_interaction_values, list):shap_interaction_values = np.sum(shap_interaction_values, axis=0)return shap_interaction_values
SHAP交互值目前仅支持使用TreeExplainer的基于树的模型。这是SHAP库本身的限制,而非Shapash的限制。
2.1.5 性能考虑
不同的SHAP解释器具有不同的性能特征:
| 解释器 | 速度 | 准确性 | 模型类型 |
|---|---|---|---|
| TreeExplainer | 非常快 | 精确 | 基于树的模型 |
| LinearExplainer | 快 | 精确 | 线性模型 |
| AdditiveExplainer | 快 | 精确 | 加性模型 |
| PermutationExplainer | 慢 | 近似 | 任何模型 |
| KernelExplainer | 非常慢 | 近似 | 任何模型 |
对于大型数据集,考虑将TreeExplainer与基于树的模型一起使用,或提供背景数据集(掩码器)以提高性能。
2.1.6 与Shapash可视化集成
一旦使用后端计算了SHAP值,Shapash就提供了丰富的可视化功能:
# 局部解释图
xpl.plot.local_plot(index=0)# 特征重要性图
xpl.plot.features_importance()# 贡献度图
xpl.plot.contribution_plot(feature='age')# 交互图(用于树模型)
xpl.plot.interactions_plot(feature1='age', feature2='income')
这些可视化自动使用后端计算的SHAP值,提供了理解模型行为的直观方式。
2.2 方法二:LIME后端集成
Shapash 与 LIME(Local Interpretable Model-agnostic Explanations,局部可解释模型无关解释)库实现了无缝集成,让您能够利用 LIME 的局部解释功能,同时受益于 Shapash 丰富的可视化和报告特性。这种集成使您能够为单个预测创建直观的模型无关解释,同时不影响可解释性工作流程的质量。
Shapash 中的 LIME 后端采用简洁的模块化架构,扩展了基础后端功能。其核心在于,LimeBackend 类继承自 BaseBackend,实现了使用 LIME 算法方法计算局部贡献所需的特定逻辑。
2.2.1 LIME 后端建模流程
使用 LIME 后端时,Shapash 遵循系统化流程生成解释:
- 初始化:后端使用您的训练数据或提供的背景数据集创建 LIME 表格解释器
- 局部解释:对于每个观测值,LIME 在实例周围生成扰动数据集,并拟合一个简单可解释的模型
- 特征贡献提取:从局部代理模型中提取系数作为特征贡献
- 格式化:将贡献格式化为 Shapash 可用于可视化和分析的一致结构
# LIME 后端流程的简化伪代码
def run_explainer(self, x):# 创建 LIME 解释器explainer = lime_tabular.LimeTabularExplainer(data.values, feature_names=x.columns, mode=self._case)# 计算每个观测值的贡献lime_contrib = []for i in x.index:if self._case == "classification":exp = explainer.explain_instance(x.loc[i], self.model.predict_proba, num_features=x.shape[1])else: # 回归exp = explainer.explain_instance(x.loc[i], self.model.predict, num_features=x.shape[1])lime_contrib.append(transform_contributions(exp))return {"contributions": pd.DataFrame(lime_contrib, index=x.index)}
这种方法确保每个解释在局部上忠实于模型行为,同时保持对人类的可解释性。
2.2.2 在工作流程中使用 LIME 后端
将 LIME 后端集成到 Shapash 工作流程中非常简单。您可以在创建 SmartExplainer 时指定后端:
from shapash import SmartExplainer# 使用 LIME 后端初始化 SmartExplainer
xpl = SmartExplainer(model=your_model,backend='lime', # 指定 LIME 后端data=X_train, # LIME 的背景数据preprocessing=your_preprocessor
)# 使用测试数据编译
xpl.compile(x=X_test)
LIME 后端需要背景数据来创建有意义的局部解释。您可以通过初始化时的 data 参数提供此数据。如果未提供,LIME 将使用传递给 compile 方法的数据作为背景数据。
编译完成后,您可以将所有 Shapash 可视化功能与基于 LIME 的解释一起使用:
# 生成本地解释图
xpl.plot.local_plot(index=0)# 将贡献导出到 pandas
contributions_df = xpl.to_pandas(max_contrib=3)# 生成特征重要性
xpl.plot.features_importance()
2.2.3 处理不同模型类型
LIME 后端根据您的模型类型自动调整解释策略:
- 二元分类:对于二元分类问题,LIME 为正类生成解释,显示每个特征如何推动预测向类别 1 发展。
- 多类分类:对于多类模型,后端为每个类生成单独的解释,返回一个贡献 DataFrame 列表——模型中每个类一个。
# 后端自动检测多类场景
if num_classes > 2:contribution = []for j in range(num_classes):# 为每个类生成解释exp = explainer.explain_instance(x.loc[i], self.model.predict_proba, top_labels=num_classes)contribution.append(extract_class_contributions(exp, j))return contribution
- 回归:对于回归任务,LIME 解释每个特征如何影响预测的数值,正贡献增加预测值,负贡献减少预测值。
2.2.4 性能考虑
LIME 以计算密集而闻名,特别是在为大型数据集解释预测时。Shapash LIME 后端顺序处理每个观测值,对于包含大量样本的数据集可能很耗时。
为了提高性能,请考虑以下策略:
- 数据子集化:仅解释预测的代表性样本
- 使用多处理:实现并行处理(如教程所示)
- 减少 num_samples:调整 LIME 的 num_samples 参数以获得更快但可能不太稳定的解释
- 考虑 SHAP:对于大型数据集,SHAP 后端通常提供更好的性能
2.2.5 限制和注意事项
虽然 LIME 后端提供了有价值的局部解释,但需要注意一些限制:
- 不支持特征分组:与 SHAP 后端不同,LIME 不支持特征分组(support_groups = False)
- 计算成本:对于大多数模型,LIME 解释比 SHAP 计算成本更高
- 稳定性:由于随机采样过程,LIME 解释在不同运行间可能有所不同
- 全局解释:虽然 LIME 擅长局部解释,但其全局特征重要性是通过聚合局部解释得出的,而非直接计算
2.2.6 使用场景推荐
LIME 后端在以下场景中特别有用:
- 模型无关需求:当您需要适用于不同模型类型的解释时
- 局部保真度重点:当理解单个预测比全局模式更重要时
- 偏好简单模型:当您希望基于易于解释的线性模型获得解释时
- 中小型数据集:当计算资源不是限制因素时
对于大型数据集或需要特征分组功能时,请考虑使用 SHAP 后端。
2.3 方法三:自定义后端
Shapash 的灵活架构允许您通过创建自定义后端来扩展其可解释性能力。本指南将引导您完成实现自有后端的过程,以便将专业的解释方法与 Shapash 的可视化和报告工具集成。
Shapash 的核心采用模块化后端系统,将解释的计算与可视化和分析分离开来。BaseBackend 类作为所有后端必须实现的抽象基础,确保不同解释方法之间的一致性。
后端架构遵循明确的关注点分离原则:
- BaseBackend:定义所有后端接口的抽象类
- 具体实现:特定的后端实现,如 ShapBackend 和 LimeBackend
- SmartExplainer:编排解释过程的主类
2.3.1 第一步:定义您的后端类
首先,创建一个继承自 BaseBackend 的新类,并定义所需的类属性:
from shapash.backend.base_backend import BaseBackend
import pandas as pdclass CustomBackend(BaseBackend):# 必需的类属性name = "custom" # 后端的唯一标识符column_aggregation = "sum" # 如何聚合分组特征的贡献度support_groups = True # 后端是否支持特征分组supported_cases = ["classification", "regression"] # 支持的模型类型def __init__(self, model, preprocessing=None, **kwargs):super().__init__(model, preprocessing)# 在此添加任何自定义初始化参数self.custom_param = kwargs.get('custom_param', 'default_value')
2.3.2 第二步:实现核心的 run_explainer 方法
run_explainer 方法是您后端的核心。它计算每个观测值的局部贡献度,并以标准化格式返回结果。
def run_explainer(self, x: pd.DataFrame) -> dict:"""使用您的自定义解释方法计算局部贡献度。参数----------x : pd.DataFrame模型使用的观测数据框返回-------explain_data : dict包含局部贡献度的字典,至少包含:- 'contributions':贡献度数组或数据框"""# 在此实现您的自定义解释逻辑# 这是您集成解释算法的地方# 示例结构(需根据您的特定方法调整):contributions = self._compute_custom_contributions(x)# 以预期格式返回结果explain_data = {'contributions': contributions}return explain_data
2.3.3 第三步:处理多类别场景(可选)
如果您的后端支持分类任务,则需要适当处理多类别场景:
def run_explainer(self, x: pd.DataFrame) -> dict:# ... 前面的代码 ...if self._case == "classification" and len(self._classes) > 2:# 对于多类别分类,返回数据框列表# 每个类别一个数据框contributions_list = []for class_idx in range(len(self._classes)):class_contributions = self._compute_contributions_for_class(x, class_idx)contributions_list.append(class_contributions)explain_data = {'contributions': contributions_list}else:# 对于二元分类或回归任务contributions = self._compute_custom_contributions(x)explain_data = {'contributions': contributions}return explain_data
2.3.4 第四步:添加自定义参数和方法
您可以根据解释方法的特定需求,为后端添加自定义参数和方法:
class CustomBackend(BaseBackend):def __init__(self, model, preprocessing=None, custom_param1=None, custom_param2=None):super().__init__(model, preprocessing)self.custom_param1 = custom_param1self.custom_param2 = custom_param2def validate_custom_parameters(self):"""验证后端特定的自定义参数。"""if self.custom_param1 is not None and not isinstance(self.custom_param1, (int, float)):raise ValueError("custom_param1 必须是数值类型")def compute_advanced_metrics(self, x, contributions):"""计算特定于您方法的高级解释指标。"""# 在此实现自定义指标pass
2.3.5 集成您的自定义后端
实现自定义后端后,可以通过两种方式将其与 Shapash 集成:
2.3.5.1 方法一:直接实例化
创建您的后端实例并将其直接传递给 SmartExplainer:
from shapash import SmartExplainer# 创建您的自定义后端实例
custom_backend = CustomBackend(model=your_model,preprocessing=your_preprocessor,custom_param1=0.5,custom_param2=True
)# 使用您的自定义后端初始化 SmartExplainer
xpl = SmartExplainer(model=your_model,backend=custom_backend,preprocessing=your_preprocessor,features_dict=your_features_dict
)# 像往常一样编译和使用
xpl.compile(x=x_test)
xpl.plot.features_importance()
2.3.5.2 方法二:注册(高级)
为了更无缝的集成,您可以将后端注册到 Shapash 的后端发现系统:
# 在您的后端模块中
from shapash.backend.base_backend import BaseBackendclass CustomBackend(BaseBackend):name = "custom"# ... 实现 ...# 使其可被发现,确保在 Shapash 加载时导入
# 可能需要修改后端 __init__.py 或使用入口点
2.3.6 自定义后端的最佳实践
创建自定义后端时,请遵循以下最佳实践以确保兼容性和性能:
- 适当的输入验证
始终验证输入并处理边界情况:
def run_explainer(self, x: pd.DataFrame) -> dict:# 输入验证if not isinstance(x, pd.DataFrame):raise TypeError("输入 x 必须是 pandas 数据框")if x.empty:raise ValueError("输入数据框不能为空")# 检查列是否与预期特征匹配expected_features = self._get_expected_features()if not set(x.columns) == set(expected_features):raise ValueError("输入列与预期特征不匹配")# ... 其他实现 ...
- 性能优化
对于大型数据集,考虑实现批处理:
def run_explainer(self, x: pd.DataFrame, batch_size=1000) -> dict:"""以批处理方式处理数据以获得更好的内存管理。"""if len(x) <= batch_size:return self._process_single_batch(x)# 分批处理results = []for i in range(0, len(x), batch_size):batch = x.iloc[i:i + batch_size]batch_result = self._process_single_batch(batch)results.append(batch_result)# 合并结果combined_contributions = pd.concat([r['contributions'] for r in results])return {'contributions': combined_contributions}
- 错误处理和日志记录
实现健壮的错误处理和信息性日志记录:
import loggingclass CustomBackend(BaseBackend):def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)self.logger = logging.getLogger(__name__)def run_explainer(self, x: pd.DataFrame) -> dict:try:self.logger.info(f"正在计算 {len(x)} 个样本的贡献度")result = self._compute_contributions(x)self.logger.info("成功计算贡献度")return resultexcept Exception as e:self.logger.error(f"计算贡献度失败:{str(e)}")raise
始终使用分类和回归模型测试您的自定义后端,确保其适当处理空数据集、缺失值和多类别场景等边界情况。
2.3.7 真实示例:ELI5 后端
让我们通过实现 ELI5(另一个流行的解释库)的后端来创建一个实际示例:
import eli5
from eli5.sklearn import explain_prediction_sklearn
import pandas as pd
import numpy as np
from shapash.backend.base_backend import BaseBackendclass Eli5Backend(BaseBackend):name = "eli5"column_aggregation = "sum"support_groups = False # ELI5 原生不支持特征分组supported_cases = ["classification", "regression"]def run_explainer(self, x: pd.DataFrame) -> dict:"""使用 ELI5 计算贡献度。"""contributions_list = []for idx in x.index:sample = x.loc[idx:idx]# 获取 ELI5 解释explanation = explain_prediction_sklearn(self.model, sample,top=len(x.columns))# 提取特征贡献度feature_contributions = {}for feature, weight in explanation.targets[0].feature_weights.pos.items():feature_contributions[feature] = weightfor feature, weight in explanation.targets[0].feature_weights.neg.items():feature_contributions[feature] = weight# 创建贡献度行contrib_row = []for col in x.columns:contrib_row.append(feature_contributions.get(col, 0.0))contributions_list.append(contrib_row)# 创建数据框contributions = pd.DataFrame(contributions_list,index=x.index,columns=x.columns)return {'contributions': contributions}
此示例演示了如何包装现有的解释库(ELI5)以与 Shapash 的可视化和报告功能配合使用。
3 用于部署的SmartPredictor
SmartPredictor 是 Shapash 库中的一个专用组件,专为在生产环境中部署具有可解释性功能的机器学习模型而设计。它通过提供轻量级、一致且高效的方式来生成预测及其局部解释,弥合了模型开发与运营部署之间的差距。
SmartPredictor 类作为 SmartExplainer 的生产就绪版本,提供了针对生产用例量身定制的额外一致性检查和优化。它允许您在具有正确结构的新数据集上自动重现相同的可解释性结果,使其非常适合集成到 API、批处理系统或任何需要模型预测附带清晰、可解释解释的生产环境中。
3.1 为什么在部署中使用 SmartPredictor?
当将机器学习模型从开发环境迁移到生产环境时,会出现几个挑战:
- 一致性:确保在不同环境中一致地应用相同的预处理、预测和解释流程
- 性能:针对效率至关重要的生产工作负载进行优化
- 可解释性:保持向利益相关者或最终用户解释预测的能力
- 集成:使其易于集成到现有生产系统中
SmartPredictor 通过以下方式解决这些挑战:
- 轻量级设计:比 SmartExplainer 更高效,适用于生产工作负载
- 一致性检查:在处理前验证所有参数和数据结构
- 自动化流程:在统一工作流中处理预处理、预测和解释
- 灵活输出:提供可配置的解释摘要以适应不同用例
SmartPredictor 专为需要一致高效地生成带解释的预测的生产环境而设计。如果您仍处于探索阶段,建议先使用 SmartExplainer,然后在准备部署时转换为 SmartPredictor。
3.2 核心架构和工作流
SmartPredictor 遵循一个定义明确的工作流,确保训练和预测阶段之间的一致性:
- 初始化 SmartPredictor
- 添加输入数据
- 应用预处理
- 计算预测
- 计算贡献度
- 生成解释摘要
- 输出结果
3.3 关键组件
SmartPredictor 由几个协同工作的关键组件组成:
- 模型存储:保存训练好的模型对象
- 预处理流程:保持训练期间使用的相同预处理步骤
- 后端集成:使用可解释性后端(SHAP、LIME 等)计算贡献度
- 特征映射:管理技术特征名称与业务友好名称之间的关系
- 解释过滤:提供可配置选项来汇总解释
3.4 创建 SmartPredictor
有两种主要方法可以创建 SmartPredictor:
3.4.1 方法 1:从 SmartExplainer 创建(推荐)
最常见的方法是将现有的 SmartExplainer 转换为 SmartPredictor:
# 假设您有一个已编译的 SmartExplainer
predictor = xpl.to_smartpredictor()
此方法确保探索阶段的所有配置、预处理步骤和映射都保留在部署对象中。
3.4.2 方法 2:直接初始化
您也可以通过指定所有必需参数直接创建 SmartPredictor:
predictor = SmartPredictor(features_dict=my_features_dict,model=my_model,backend=my_backend,columns_dict=my_columns_dict,features_types=my_features_type_dict,label_dict=my_label_dict,preprocessing=my_preprocess,postprocessing=my_postprocess
)
这种方法让您拥有完全控制权,但需要仔细配置所有参数。
3.5 处理新数据
初始化后,SmartPredictor 通过结构化工作流处理新数据:
3.5.1 步骤 1:添加输入数据
add_input() 方法是处理新数据的入口点:
predictor.add_input(x=xtest_df)
此方法执行几个关键操作:
- 验证输入数据结构和类型
- 应用预处理和后处理
- 重新排序特征以匹配模型的预期格式
- 如果未提供,则计算预测和贡献度
3.5.2 步骤 2:生成预测
SmartPredictor 可以使用训练好的模型生成预测:
predictions = predictor.predict()
此方法将模型应用于预处理数据,并以一致格式返回预测结果。
3.5.3 步骤 3:计算贡献度
为了实现可解释性,SmartPredictor 计算特征贡献度:
contributions = predictor.compute_contributions()
这使用配置的后端(SHAP、LIME 等)来计算每个特征对预测的贡献程度。
3.6 生成解释摘要
SmartPredictor 的真正威力在于其生成清晰、简洁的解释摘要的能力:
基本摘要
summary_df = predictor.summarize()
这会生成一个 DataFrame,显示每个预测的最重要特征及其贡献度:
| pred | proba | feature_1 | value_1 | contribution_1 | feature_2 | value_2 | contribution_2 |
|---|---|---|---|---|---|---|---|
| 0 | 0.756 | Sex | 1.0 | 0.322 | Pclass | 3.0 | 0.155 |
| 1 | 0.629 | Sex | 2.0 | 0.585 | Pclass | 1.0 | 0.371 |
| 2 | 0.543 | Sex | 2.0 | -0.487 | Pclass | 3.0 | 0.255 |
3.7 自定义解释
您可以使用 modify_mask() 方法自定义解释的呈现方式:
# 仅显示主要贡献者
predictor.modify_mask(max_contrib=1)# 隐藏负贡献度
predictor.modify_mask(positive=True)# 应用阈值来隐藏小的贡献度
predictor.modify_mask(threshold=0.1)# 隐藏特定特征
predictor.modify_mask(features_to_hide=['unimportant_feature'])
这些选项允许您根据特定用例和受众定制解释。
3.8 持久化和部署
SmartPredictor 包含内置的持久化功能,便于部署:
保存和加载
# 保存预测器
predictor.save('path_to_pkl/predictor.pkl')# 加载预测器
from shapash.utils.load_smartpredictor import load_smartpredictor
predictor_load = load_smartpredictor('path_to_pkl/predictor.pkl')
这使得将具有可解释性的模型部署到生产环境变得容易。
3.9 生产集成
SmartPredictor 旨在与生产系统无缝集成:
- API 集成:在 REST API 中使用,提供带解释的预测
- 批处理:在批处理模式下高效处理大型数据集
- 实时应用:部署在需要快速解释的低延迟环境中
- 监控系统:与模型监控工具集成,跟踪预测质量
3.10 部署最佳实践
在生产环境中部署 SmartPredictor 时,请考虑这些最佳实践:
- 验证输入数据:始终确保输入数据符合预期的格式和类型
- 监控性能:跟踪预测和解释的计算时间
- 版本控制:维护 SmartPredictor 对象的版本以及模型版本
- 错误处理:为边缘情况和无效输入实施适当的错误处理
- 资源管理:注意内存使用,特别是在处理大型数据集时
部署到生产环境时,务必使用生产数据样本测试您的 SmartPredictor,以确保在上线前正确处理所有边缘情况。
4 HTML报告生成
Shapash 的报告生成功能通过创建独立的 HTML 报告来满足这一需求,这些报告只需互联网连接即可查看,无需外部依赖或服务器。
报告生成功能将您的模型分析转化为专业文档,包括:
- 项目概览和元数据
- 数据集探索和分析
- 模型文档和参数
- 可解释性可视化
- 性能指标和评估
4.1 报告生成的工作原理
报告生成过程遵循清晰的工作流程,利用 Shapash 现有的 SmartExplainer 基础设施。让我们探讨其架构和流程:
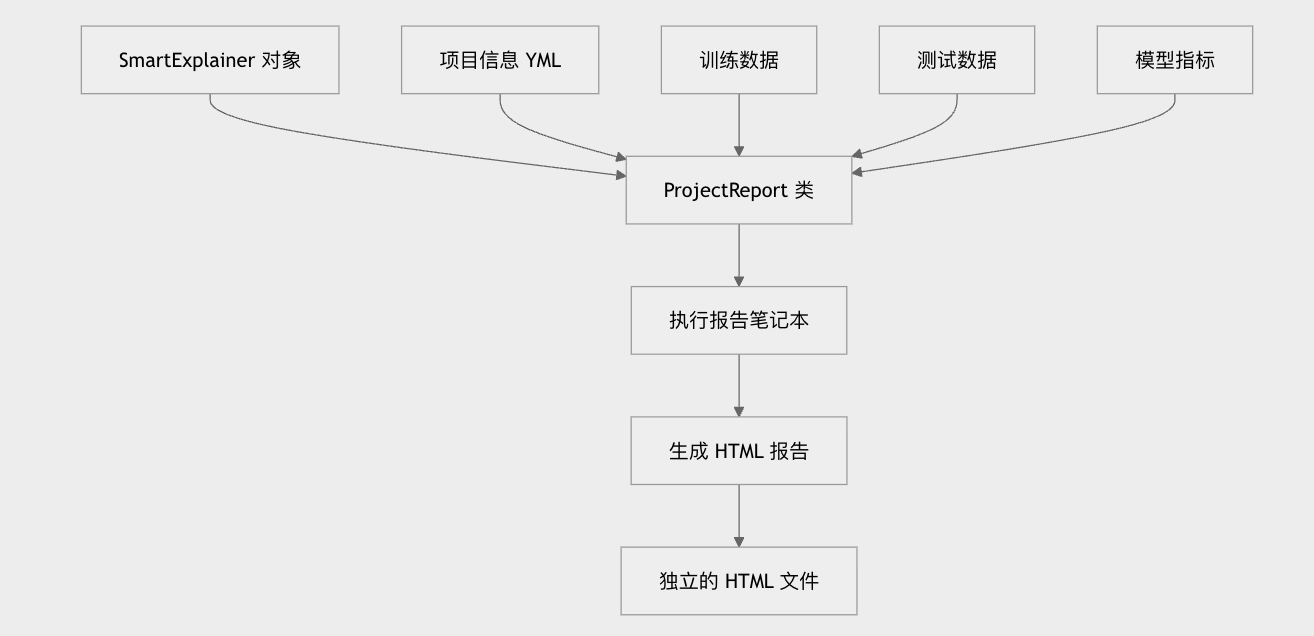
此功能的核心是 ProjectReport 类,它负责协调所有报告内容的收集和格式化。该类接收一个编译好的 SmartExplainer 对象和额外数据,为您的机器学习项目创建全面分析。
实际报告生成通过 Jupyter 笔记本执行过程实现:
execute_report函数将您的解释器和数据保存到工作目录- 它使用 Papermill 执行基础报告笔记本,注入您的特定数据和参数
- 最后,
export_and_save_report函数将执行的笔记本转换为干净的 HTML 文件
4.2 创建您的第一份报告
开始使用报告生成功能非常简单。让我们通过一个基本示例:
# 首先,创建并编译您的 SmartExplainer
from shapash import SmartExplainerxpl = SmartExplainer(model=regressor,preprocessing=encoder,features_dict=house_dict
)xpl.compile(x=Xtest, y_pred=y_pred, y_target=ytest)# 生成报告
xpl.generate_report(output_file='output/report.html', project_info_file='utils/project_info.yml',x_train=Xtrain,y_train=ytrain,y_test=ytest,title_story="房价报告",title_description="本文档是使用 Shapash 生成的数据科学报告",metrics=[{'path': 'sklearn.metrics.mean_absolute_error','name': '平均绝对误差', },{'path': 'sklearn.metrics.mean_squared_error','name': '均方误差',}]
)
此代码生成一份完整的 HTML 报告,包含您项目的所有关键信息。主要参数包括:
output_file:HTML 报告的保存路径project_info_file:包含项目元数据的 YML 文件路径x_train、y_train、y_test:用于分析的训练和测试数据title_story和title_description:报告标题和描述metrics:要包含的评估指标列表
project_info_file 对良好的文档记录至关重要。它应包含"项目概览"、“数据来源”、"方法论"等部分。对日期字段使用 ‘auto’ 值可自动包含当前日期。
4.3 报告内容详解
生成的报告包含几个关键部分,提供机器学习项目的完整视图:
- 项目信息
此部分显示 YML 文件中的元数据,包括项目概览、团队信息、数据来源和方法论。YML 格式灵活:
Project Overview:title: 房价预测description: 使用回归模型预测房价date: auto # 自动插入当前日期Data Source:source: Kaggle 房价数据集size: 1460 条记录features: 79 个特征Methodology:approach: 随机森林回归validation: 训练-测试分割 (75-25)
- 数据集分析
报告执行全面的数据探索,比较训练和测试数据集:
- 全局分析:包括行数、特征数和缺失值的总体统计
- 单变量分析:每个特征的分布图,比较训练集与测试集
- 目标分析:目标变量在各数据集中的分布
- 多变量分析:相关矩阵和特征关系
此分析有助于识别数据漂移,并确保测试集能很好地代表训练数据。
- 模型文档
报告自动提取并显示模型信息:
- 模型类和库(如 sklearn 的 RandomForestRegressor)
- 库版本
- 组织化表格中的所有模型参数
此部分提供模型架构和配置的透明度,无需手动文档记录。
- 模型可解释性
利用 Shapash 强大的可解释性功能,报告包括:
- 特征重要性:显示哪些特征对预测影响最大的全局重要性分数
- 贡献图:详细分析每个特征如何影响整个数据集的预测
- 交互图(可选):特征交互及其组合效果的可视化
这些可视化帮助利益相关者不仅了解模型预测什么,还了解为何做出这些预测。
- 模型性能
报告使用可自定义指标评估模型性能:
metrics=[{'path': 'sklearn.metrics.mean_absolute_error','name': '平均绝对误差', },{'path': 'sklearn.metrics.confusion_matrix','name': '混淆矩阵',},{'path': 'custom_module.custom_metric','name': '自定义业务指标','use_proba_values': True # 用于基于概率的指标}
]
系统支持标准 sklearn 指标和自定义指标函数,使其适应特定业务需求。
4.4 自定义您的报告
虽然基础报告很全面,但 Shapash 允许广泛的自定义:
- 创建自定义报告
您可以通过以下方式修改报告结构:
- 复制基础报告笔记本(shapash/report/base_report.ipynb)
- 根据需要添加、删除或修改单元格
- 在
generate_report方法中指定自定义笔记本路径:
xpl.generate_report(output_file='output/custom_report.html',notebook_path="path/to/your/custom_report.ipynb",# ... 其他参数
)
此方法让您可以添加特定业务分析、删除不相关部分或包含额外可视化。
- 配置选项
报告生成包括几个配置选项:
| 参数 | 默认值 | 描述 |
|---|---|---|
| max_points | 200 | 图表中显示的最大点数 |
| display_interaction_plot | False | 是否包含交互图 |
| nb_top_interactions | 5 | 显示的顶级交互数量 |
| title_story | “Shapash report” | 报告标题 |
| title_description | “” | 报告副标题/描述 |
这些选项让您可以在细节与性能之间取得平衡,并根据受众定制报告。
4.5 报告生成的最佳使用场景
要从 Shapash 报告中获得最大价值:
-
完善项目信息 YML:花时间填写所有相关部分。此元数据构成报告可信度的基础。
-
包含训练和测试数据:提供
x_train、y_train和y_test可实现全面的数据集分析,并帮助识别数据漂移。 -
选择相关指标:选择对利益相关者重要的指标。业务指标通常比技术指标更有共鸣。
-
考虑受众:在最终确定前使用
working_dir参数测试自定义报告。技术团队可能需要更多细节,而业务利益相关者则更喜欢高层见解。 -
利用特征字典:使用
features_dict提供人类可读的特征名称。这使报告对非技术读者更易理解。 -
对于大型数据集,考虑使用
max_points参数限制图表中的点数。这可以在保持视觉清晰度的同时改善报告加载时间。
5 Web应用部署:Dash库的使用
Shapash 提供了一个交互式 Web 应用程序,允许用户通过直观的可视化来探索和理解机器学习模型的预测结果。本指南将指导您部署 Shapash Web 应用程序,使相关利益方能够访问您的模型解释。
Shapash Web 应用程序使用 Dash 构建,Dash 是一个用于创建分析型 Web 应用程序的 Python 框架。它提供了一个交互式界面,用户无需编写代码即可探索模型预测、特征贡献和各种可解释性可视化。
该 Web 应用程序包含几个关键组件:
- 交互式数据表:显示包含预测值和实际值的数据集样本
- 特征重要性图:显示全局特征重要性指标
- 贡献图:可视化每个特征如何影响预测结果
- 局部解释视图:提供单个预测的详细解释
- 过滤功能:允许用户根据特征值对数据进行子集筛选
5.1 基本 Web 应用程序部署
部署 Shapash Web 应用程序非常简单。在创建和编译 SmartExplainer 对象后,您可以通过单个方法调用来启动 Web 应用程序。
# 首先编译您的 SmartExplainer
xpl.compile(x=Xtest, y_pred=ypred, y_target=ytest)# 启动 Web 应用程序
app = xpl.run_app(title_story='房价', port=8020)
run_app() 方法接受多个参数:
- title_story:Web 应用程序的自定义标题
- port:Web 服务器的端口号(默认:8050)
- host:主机地址(默认:‘127.0.0.1’)
- debug:调试模式标志
当您运行此代码时,Shapash 会启动一个本地 Web 服务器并提供一个 URL,您可以在浏览器中打开该 URL 来访问交互式应用程序。
5.2 向 Web 应用程序添加额外数据
Shapash 的一个强大功能是能够包含模型中未使用但可以为探索预测提供有价值上下文的额外数据。这对于筛选和理解数据的特定子集特别有用。
# 定义要包含的额外数据
additional_data = df_car_accident.loc[Xtest.index, ["year_acc", "Description"]]
additional_features_dict = {"year_acc": "年份"}# 使用额外数据进行编译
xpl.compile(x=Xtest, y_pred=ypred,y_target=ytest,additional_data=additional_data,additional_features_dict=additional_features_dict,
)# 启动应用程序
app = xpl.run_app()
额外特征在 Web 应用程序中以斜体名称显示,名称前带有下划线,使其易于与模型特征区分。这些额外特征可用于筛选,并在检查单个预测时提供更多上下文。
5.3 生产部署注意事项
对于生产部署,您需要考虑几个因素以确保 Web 应用程序的健壮性和可访问性:
5.3.1 主机配置
默认情况下,Shapash 在 127.0.0.1(本地主机)上运行。要使其可以从其他机器访问,请将主机指定为 0.0.0.0:
app = xpl.run_app(host='0.0.0.0', port=8080)
5.3.2 自定义 Web 应用程序设置
您可以通过 settings 参数自定义 Web 应用程序的各个方面:
settings = {"rows": 1000, # 要显示的行数"points": 1000, # 图表的点数"violin": 10, # 小提琴图的类别数"features": 20 # 要显示的特征数
}app = xpl.run_app(settings=settings)
5.4 管理 Web 应用程序
5.4.1 启动应用程序
启动 Web 应用程序的最简单方法是通过 SmartExplainer 的 run_app() 方法,它会为您处理所有初始化:
app = xpl.run_app()
5.4.2 停止应用程序
当您完成 Web 应用程序的使用后,正确关闭它以释放资源非常重要:
app.kill()
这会停止底层的 Dash 服务器并释放它使用的端口。
5.4.3 使用自定义启动脚本进行高级部署
为了更好地控制部署过程,您可以创建一个类似于示例中提供的自定义启动脚本:
import pandas as pd
from shapash import SmartExplainer# 加载您的模型和数据
# ...(您的模型加载代码)# 创建 SmartExplainer
xpl = SmartExplainer(model=model, preprocessing=encoder)
xpl.compile(X_test, y_pred=y_pred, y_target=y_target)# 初始化应用程序
xpl.init_app()
app = xpl.smartapp.app# 运行服务器
if __name__ == "__main__":app.run_server(debug=False, host="0.0.0.0", port=8080)
这种方法为您配置和部署 Web 应用程序提供了更大的灵活性。
在生产环境中部署时,考虑使用生产级的 WSGI 服务器(如 Gunicorn 或 uWSGI)代替内置的 Flask 开发服务器。这将为您提供更好的性能、稳定性和安全性。
5.5 Web 应用程序部署的使用场景
-
数据大小考虑:注意加载到 Web 应用程序中的数据量。大型数据集会降低性能。使用 rows 参数限制显示的样本数量。
-
特征选择:专注于最重要的特征,避免让用户感到不知所措。您可以使用 features 参数控制默认显示的特征数量。
-
安全性:在公开部署时,确保不会暴露敏感数据。Web 应用程序设计用于模型解释,而不是作为生产预测接口。
-
性能:对于具有许多特征的复杂模型,考虑预先计算解释以提高 Web 应用程序的响应速度。
-
自定义:利用 features_dict 和 label_dict 参数,使用业务术语而不是技术特征名称,使界面更加用户友好。
通过遵循这些指南并了解部署选项,您可以有效地使用 Shapash 的 Web 应用程序,使您的机器学习模型对组织内的相关利益方更加透明和可访问。
6 参考文献
以上信息大多来自zread.ai对Shapash github库的解析