Deeplizard 深度学习课程(五)—— 模型训练
前言
我们正在利用pytorch实现CNN。主要分为四个小部分:数据预处理、神经网络pytorch设计、训练神经网络 和 神经网络实验。
在上一节中我们已经搭建好了神经网络的框架,本节主要是训练模型,模型的训练主要包含以下七个步骤:
- Get batch:从训练集中取出一个批次 (batch) 的数据
- Pass batch:将这批数据传递给网络
- Calculate loss:计算预测值和真实值之间的差异 (损失函数)
- Calculate gradient:计算损失函数的梯度 及 网络的参数权重 (反向传播)
- Updata weights:通过梯度来更新权重,以减小损失 (优化算法)
- Repeat 1-5:重复步骤1-5,直至一个周期 (epoch) 完成
- Repeat 1-6:重复步骤1-6,完成多个epoch,以获得期望的精度
1. CNN的训练
1.1 使用单批次进行训练
我们首先从CNN_network中导入之前定义好的Network和train_set,然后对于单个batch,我们首先通过代码实现上述step1-5,尝试理解单个批次的训练过程。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optimfrom CNN_network import Network,train_setprint(torch.__version__) # 2.6.0
network = Network()
torch.set_grad_enabled(True) # 进行梯度跟踪,以便执行反向传播来更新模型参数。一般训练时打开,推理时关闭'''定义dataloader,对应step1,2'''
train_loader = torch.utils.data.DataLoader(train_set, batch_size=100, shuffle=True)
batch = next(iter(train_loader)) # iter将dataloader转换为一个迭代器
images, labels = batch'''计算损失,对应step3'''
preds = network(images)
loss = F.cross_entropy(preds, labels) # 这里注意,该函数第一个输入需要是原始输出分数(logits),所以不需要进行argmax操作
print('loss1:',loss.item()) # 从包含单个元素的tensor中提取出具体浮点数# 输出:2.304090976715088'''梯度计算,反向传播,对应step4'''
print(network.conv1.weight.grad) # 输出:None
loss.backward() # 用来计算梯度
print(network.conv1.weight.grad.shape) # 输出:torch.Size([6, 1, 5, 5]),和weight的shape一致'''优化算法,更新参数,对应step5'''
# 可以使用SGD或者Adam
# optimizer = optim.SGD(network.parameters(), lr=0.001, momentum=0.9)
optimizer = optim.Adam(network.parameters(), lr=0.01) # lr为学习率
# optimizer.zero_grad()
optimizer.step() # 更新权重# 查看更新后的损失
preds = network(images)
loss = F.cross_entropy(preds, labels)
print('loss2:',loss.item()) # 损失:2.301673173904419 -> 2.29020476341247561.2 进行完整训练
在1.1中,我们已经完成了单个batch的训练过程(step1-5),现在我们需要将这个过程扩展至训练集中的所有batch,并完成多个epoch。这里主要需要注意pytorch会累加梯度,所以在每个循环时,都必须先将梯度归零。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from CNN_network import Network,train_set
from tqdm import *def get_num_correct(preds, labels):return preds.argmax(dim=1).eq(labels).sum().item()network = Network()
torch.set_grad_enabled(True) # 梯度追踪# 定义dataloader和优化器
train_loader = DataLoader(train_set, batch_size=100, shuffle=True)
optimizer = optim.Adam(network.parameters(), lr=0.01)for epoch in range(10):total_loss = 0total_correct = 0for batch in train_loader: # Get batchimages, labels = batchpreds = network(images) # Pass batchloss = F.cross_entropy(preds, labels) # calculate lossoptimizer.zero_grad() # 这里十分重要!!! pytorch会累加梯度,所以在每个循环时,都必须先将梯度归零loss.backward() # caculate gradientsoptimizer.step() # updata weighttotal_loss += loss.item()total_correct += get_num_correct(preds, labels)print('epoch:',epoch,'total_loss:',total_loss,'total_correct:',total_correct)# 输出: epoch: 0 total_loss: 366.4912240803242 total_correct: 46024# epoch: 1 total_loss: 235.92201751470566 total_correct: 51292# epoch: 2 total_loss: 215.5054646730423 total_correct: 52008# epoch: 3 total_loss: 206.86244517564774 total_correct: 52381# epoch: 4 total_loss: 201.20621101558208 total_correct: 52571# epoch: 5 total_loss: 193.69272831827402 total_correct: 52881# epoch: 6 total_loss: 191.46736193448305 total_correct: 52985# epoch: 7 total_loss: 189.72856015712023 total_correct: 53056# epoch: 8 total_loss: 187.67594435811043 total_correct: 53127# epoch: 9 total_loss: 186.0401075705886 total_correct: 53138
# 训练完成后保存最终模型
torch.save(network.state_dict(), './weight/final_model.pth')2. 分析结果
2.1 绘制混淆矩阵
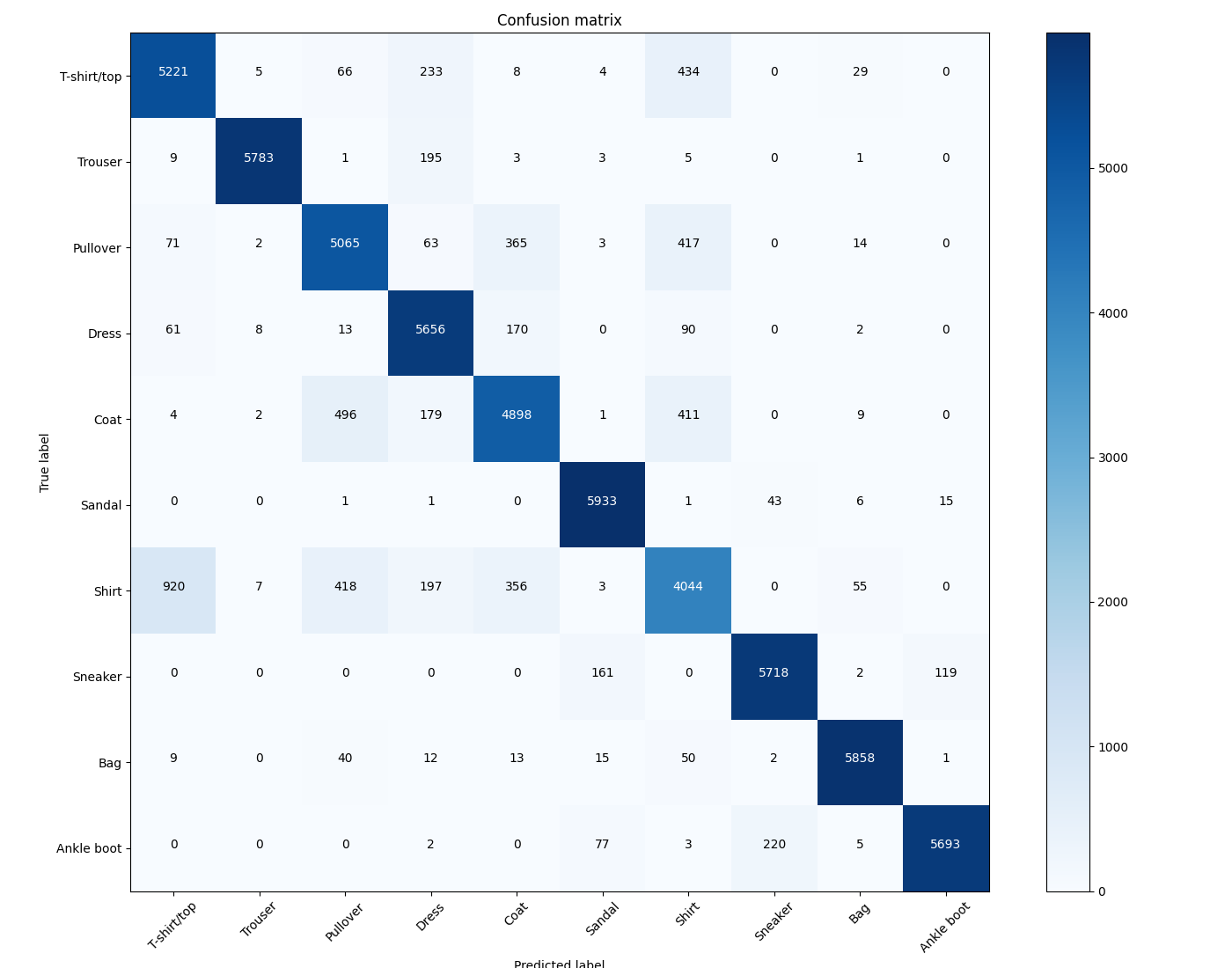
在训练完网络之后,我们可以通过绘制一个混淆矩阵来分析网络预测的效果。
这里,我们首先预测训练集中的所有数据(在进行推理时,需要关闭梯度计算,下面有装饰函数和局部关闭两种方式),然后可以看到在训练集中的6w个数据,使用1.2训练好的模型,预测精度接近90%。
import torch
from torch.utils.data import DataLoader
from CNN_network import Network,train_set@torch.no_grad() # 也可以使用这个装饰来关闭推理
def get_all_pred(model,loader):'''用来预测所有结果,返回一个合并的tensor'''all_pred = torch.tensor([])for batch in loader:images, labels = batchpreds = model(images)all_pred = torch.cat((all_pred, preds),dim=0) # 沿着行方向,将preds拼接到all_pred上return all_preddef get_num_correct(preds, labels):return preds.argmax(dim=1).eq(labels).sum().item()network = Network()# 加载训练好的权重
weight_path = './weight/final_model.pth'
network.load_state_dict(torch.load(weight_path))network.eval() # 设置为评估模式with torch.no_grad(): # 推理时,不需要被跟踪prediction_loader = DataLoader(train_set, batch_size=10000)train_pred = get_all_pred(network, prediction_loader)
print(train_pred.requires_grad) # 检查 train_pred 是否需要梯度计算 # False# 进行预测
preds_correct = get_num_correct(train_pred, train_set.targets)
print('total correct', preds_correct,'accuracy', preds_correct / len(train_set))
# 输出: total correct 53869 accurarcy 0.8978166666666667然后我们可以调用sklearn.metrics包中的函数来计算混淆矩阵,并在resource文件夹中的plot_confusion.py中自定义一个函数用来可视化混淆矩阵。
这里要注意:第一,绘制完图像后,需要执行plt.show()才会显式地将绘制好的图显示出来;第二,resource文件夹中还需要新建一个__init__.py脚本,这样resource文件夹才会被读取为一个包。(这里__init__.py脚本可以为空文件,或定义包级别导入 from .plot_confusion import plot_confusion_matrix,这样可以直接:from resource import plot_confusion_matrix)
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
from resource.plot_confusion import plot_confusion_matrix# 计算混淆矩阵
cm = confusion_matrix(train_set.targets, train_pred.argmax(dim=1))
print(cm)
# 输出:
#[[5221 5 66 233 8 4 434 0 29 0]
# [ 9 5783 1 195 3 3 5 0 1 0]
# [ 71 2 5065 63 365 3 417 0 14 0]
# [ 61 8 13 5656 170 0 90 0 2 0]
# [ 4 2 496 179 4898 1 411 0 9 0]
# [ 0 0 1 1 0 5933 1 43 6 15]
# [ 920 7 418 197 356 3 4044 0 55 0]
# [ 0 0 0 0 0 161 0 5718 2 119]
# [ 9 0 40 12 13 15 50 2 5858 1]
# [ 0 0 0 2 0 77 3 220 5 5693]]# 调用resouce文件夹中自己定义的函数绘制混淆矩阵
plt.figure(figsize=(14,12))
plot_confusion_matrix(cm, classes=train_set.classes)
plt.show()在混淆矩阵中,对角线上的元素是真实值和预测值完全一致的,其他位置都是预测错误的。下图中可明显发现 真实值为Shirt的很容易被错误预测为T-shirt
其中,resoure文件夹中的plot_confusion.py函数具体定义如下:
import itertools
import numpy as np
import matplotlib.pyplot as pltdef plot_confusion_matrix(cm, classes, normalize=False, title='Confusion matrix', cmap=plt.cm.Blues): #可以在这里改色调if normalize:cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]print("Normalized confusion matrix")else:print('Confusion matrix, without normalization')print(cm)plt.imshow(cm, interpolation='nearest', cmap=cmap)plt.title(title)plt.colorbar()tick_marks = np.arange(len(classes))plt.xticks(tick_marks, classes, rotation=45)plt.yticks(tick_marks, classes)fmt = '.2f' if normalize else 'd'thresh = cm.max() / 2.for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):plt.text(j, i, format(cm[i, j], fmt), horizontalalignment="center", color="white" if cm[i, j] > thresh else "black")plt.tight_layout()plt.ylabel('True label')plt.xlabel('Predicted label')2.2 拼接 与 堆叠
在处理批量数据时,我们需要将这些数据连接在一起,用一个tensor来进行表示,这就涉及到以下两种操作:
- 拼接(concat) 是在一个现有的轴上连接 tensor torch.cat()
- 堆叠(stack) 是新建一个轴,在这个新轴上连接 tensor torch.stack()
在之前我们已经学过 tensor.squeeze () 和 tensor.unsqueeze(dim=k) 分别会 删除长度为1的轴 / 在第k个索引上新建一个长度为1的轴。
下面我们来看一下在pytorch上如何进行以上两种操作:
import torch
t1 = torch.tensor([1,1,1])
t2 = torch.tensor([2,2,2])
t3 = torch.tensor([3,3,3])print(torch.cat((t1,t2,t3),dim=0))
# tensor([1, 1, 1, 2, 2, 2, 3, 3, 3])print(torch.stack((t1,t2,t3),dim=0))
# tensor([[1, 1, 1],
# [2, 2, 2],
# [3, 3, 3]])下面是几个区分堆叠和拼接的简单例子:
1.将这三张连接为一个batch,需要用stack,新建一个batch通道
2.将这三张连接为一个batch,只需用cat,在batch轴上连接
3.将这六张连接为一个batch,需要先对上面三张stack,再和下面cat