Agent实战教程:Langgraph的StateGraph以及State怎么用
LangGraph的StateGraph是一个用于构建状态图的核心组件,用于创建有状态的多步骤工作流程。以下是基本用法:

StateGraph基本概念
StateGraph允许你定义一个图结构,其中每个节点代表一个操作,边定义了节点之间的连接关系,整个图维护一个共享的状态。
基本用法步骤
1. 定义状态结构
from typing import TypedDict
from langgraph.graph import StateGraph, ENDclass GraphState(TypedDict):input: stroutput: strstep_count: int
2. 创建StateGraph实例
# 创建StateGraph,指定状态类型
workflow = StateGraph(GraphState)
3. 定义节点函数
def node_1(state: GraphState) -> GraphState:"""第一个节点的处理逻辑"""return {"input": state["input"],"output": f"处理了: {state['input']}","step_count": state.get("step_count", 0) + 1}def node_2(state: GraphState) -> GraphState:"""第二个节点的处理逻辑"""return {"input": state["input"],"output": state["output"] + " -> 进一步处理","step_count": state["step_count"] + 1}
4. 添加节点
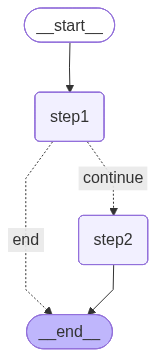
workflow.add_node("step1", node_1)
workflow.add_node("step2", node_2)
5. 定义边连接
# 设置入口点
workflow.set_entry_point("step1")# 添加边
workflow.add_edge("step1", "step2")
workflow.add_edge("step2", END)
6. 条件边的使用
你还可以添加条件边来实现分支逻辑:
def should_continue(state: GraphState) -> str:"""决定下一步走向的条件函数"""if state["step_count"] < 3:return "continue"else:return "end"# 添加条件边
workflow.add_conditional_edges("step1",should_continue,{"continue": "step2","end": END}
)
7. 编译并运行
# 编译图
app = workflow.compile()# 运行图
initial_state = {"input": "Hello World","output": "","step_count": 0
}result = app.invoke(initial_state)
print(result)
State基本概念
在现代AI应用开发中,如何优雅地管理复杂工作流的状态流转是一个关键挑战。LangGraph的State机制为我们提供了一套强大而灵活的状态管理解决方案。本文将深入探讨LangGraph State的设计理念、核心特性和实际应用。
什么是LangGraph State?
LangGraph State是LangGraph框架中用于定义和管理图状态的核心组件。它不仅定义了数据的结构模式(Schema),还通过reducer函数指定了状态更新的逻辑。State既是所有节点和边的输入模式,也是节点间数据流转的载体。
核心设计理念
LangGraph State的设计遵循以下几个核心原则:
- 类型安全: 通过TypedDict或Pydantic模型确保数据结构的正确性
- 状态隔离: 支持多层次的状态模式,实现输入、输出和内部状态的分离
- 灵活性: 节点可以读写任何已声明的状态通道
- 可扩展性: 支持运行时动态添加新的状态通道
核心关系
state_schema- 图的内部状态模式,定义了图内部所有可能的状态字段input_schema- 图的输入模式,是state_schema的子集,定义图接受什么输入output_schema- 图的输出模式,是state_schema的子集,定义图返回什么输出
具体说明
state_schema(必需)
- 图的完整内部状态,包含所有节点可能读写的字段
- 所有节点都可以访问和写入这个schema中的任何字段
- 是图的"全局状态空间"
input_schema(可选)
- 如果不指定,默认等于
state_schema - 限制图的输入接口,只能传入这些字段
- 是
state_schema的子集或相等
output_schema(可选)
- 如果不指定,默认等于
state_schema - 限制图的输出接口,只返回这些字段
- 是
state_schema的子集或相等
实际例子
# 内部完整状态
class OverallState(TypedDict):foo: str # 内部处理字段user_input: str # 输入字段graph_output: str # 输出字段# 限制输入只包含user_input
class InputState(TypedDict):user_input: str# 限制输出只包含graph_output
class OutputState(TypedDict):graph_output: str# 创建图
builder = StateGraph(OverallState, # 内部完整状态input_schema=InputState, # 输入限制output_schema=OutputState # 输出限制
)
关系图示
输入 → [InputState] → [OverallState] → [OutputState] → 输出(输入过滤) (内部完整状态) (输出过滤)
这种设计的好处:
- 封装性: 内部处理细节不会暴露给外部
- 接口清晰: 明确定义输入输出契约
- 灵活性: 内部可以有更多临时状态字段用于节点间通信
下面是一些例子
基础单模式使用
最简单的情况下,所有节点共享同一个状态模式:
from typing import TypedDict
from langgraph.graph import StateGraph, START, ENDclass SimpleState(TypedDict):input: stroutput: strstep_count: intdef process_node(state: SimpleState) -> SimpleState:return {"input": state["input"],"output": f"处理结果: {state['input']}","step_count": state.get("step_count", 0) + 1}# 创建简单的状态图
workflow = StateGraph(SimpleState)
workflow.add_node("processor", process_node)
workflow.add_edge(START, "processor")
workflow.add_edge("processor", END)app = workflow.compile()
result = app.invoke({"input": "Hello", "output": "", "step_count": 0})
多模式架构:输入输出分离
在实际应用中,我们常常需要区分输入、输出和内部状态:
from typing import TypedDict
from langgraph.graph import StateGraph, START, ENDclass InputState(TypedDict):"""用户输入接口"""user_input: strclass OutputState(TypedDict):"""最终输出接口"""graph_output: strstep_count:intclass OverallState(TypedDict):"""内部完整状态"""user_input: strintermediate_result: strprocessed_data: strgraph_output: strstep_count: intclass PrivateState(TypedDict):"""节点间私有通信"""private_data: strinternal_flag: booldef input_node(state: InputState) -> OverallState:"""输入处理节点"""return {"user_input": state["user_input"],"intermediate_result": f"开始处理: {state['user_input']}","step_count": 1}def processing_node(state: OverallState) -> PrivateState:"""数据处理节点"""processed = state["intermediate_result"].upper()return {"private_data": f"私有处理: {processed}","internal_flag": len(state["user_input"]) > 5}def intermediate_node(state: PrivateState) -> OverallState:"""中间处理节点"""additional_info = " (长文本)" if state["internal_flag"] else " (短文本)"return {"processed_data": state["private_data"] + additional_info}def output_node(state: OverallState) -> OutputState:"""输出生成节点"""final_result = f"最终结果: {state['processed_data']} | 步骤: {state.get('step_count', 0)}"return {"graph_output": final_result}# 创建多模式状态图
builder = StateGraph(OverallState,input=InputState,output=OutputState
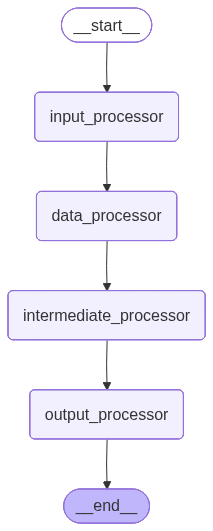
)builder.add_node("input_processor", input_node)
builder.add_node("data_processor", processing_node)
builder.add_node("intermediate_processor", intermediate_node)
builder.add_node("output_processor", output_node)builder.add_edge(START, "input_processor")
builder.add_edge("input_processor", "data_processor")
builder.add_edge("data_processor", "intermediate_processor")
builder.add_edge("intermediate_processor", "output_processor")
builder.add_edge("output_processor", END)graph = builder.compile()# 测试输入
input_data = {"user_input": "Hello LangGraph","extra_input":"额外输入"}print("输入:", input_data)# 执行图
result = graph.invoke(input_data)print("输出:", result)png_data=graph.get_graph().draw_mermaid_png()
with open("state.png", "wb") as f:f.write(png_data)
输出如下
输入: {'user_input': 'Hello LangGraph', 'extra_input': '额外输入'}
输出: {'graph_output': '最终结果: 私有处理: 开始处理: HELLO LANGGRAPH (长文本) | 步骤: 1', 'step_count': 1}