F010 Vue+Flask豆瓣图书推荐大数据可视化平台系统源码
F010 Vue+Flask豆瓣图书推荐大数据可视化平台系统源码
📚编号: F010
文章结尾部分有CSDN官方提供的学长 联系方式名片
博主开发经验15年,全栈工程师,专业搞定大模型、知识图谱、算法和可视化项目和比赛
视频介绍
推荐算法+Vue+Flask豆瓣图书大数据可视化平台系统源码+scrapy爬虫
关注B站,有好处!
1 系统功能
📚双协同过滤推荐算法进行图书推荐
📚scrapy爬取豆瓣图书数据解析后,存储到mysql数据库,利用pandas、numpy进行数据的清洗,因为我们要进行分析。
📚基于Flask开发接口,对接Vue前端,实现对书籍数据的可视化分析
📚数据出版、评分等数据分析功能 + 词云图等
📚外部接口实现了阿里云短信、百度身份证识别、支付宝沙箱支付集成。
📚登录+注册
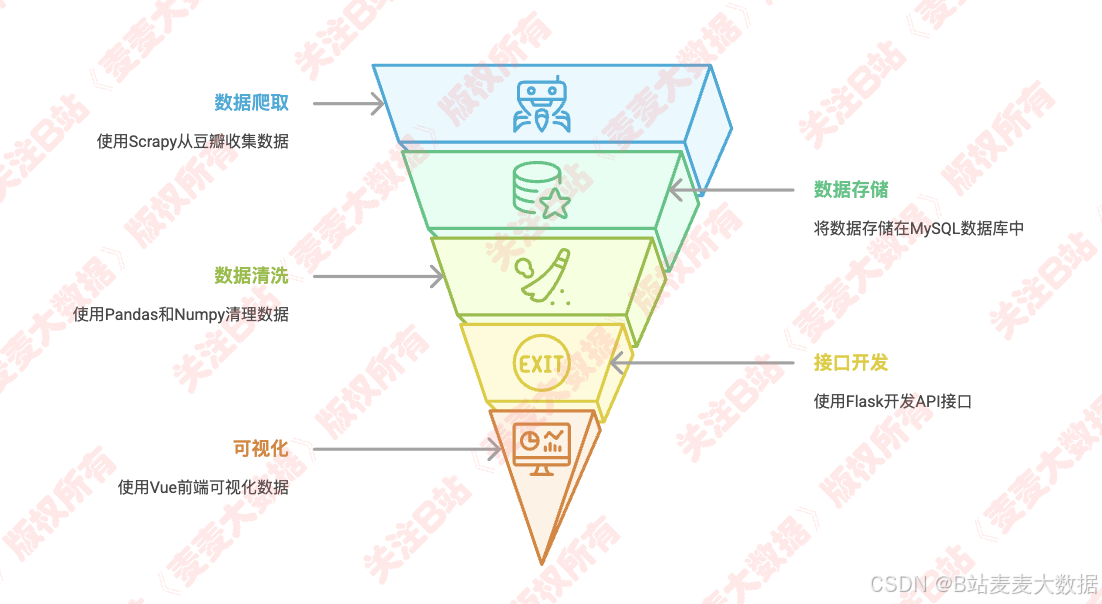
2 系统亮点 ⭐
- 爬取图书和书评数据量比较多,海量爬取
- 实现影片库搜索,多种Echarts图形分析、jieba分析;
- 完全responsive 自适应,自动可以适配H5移动端;
- 卡片式登录页面 + 大数据Style动画;
- 实现的分析图:世界地图、交互式时间轴、词云、多种折线图、面积图、大数据图、滚动柱状图、饼图、水滴图等。
3 设计图
- 系统架构
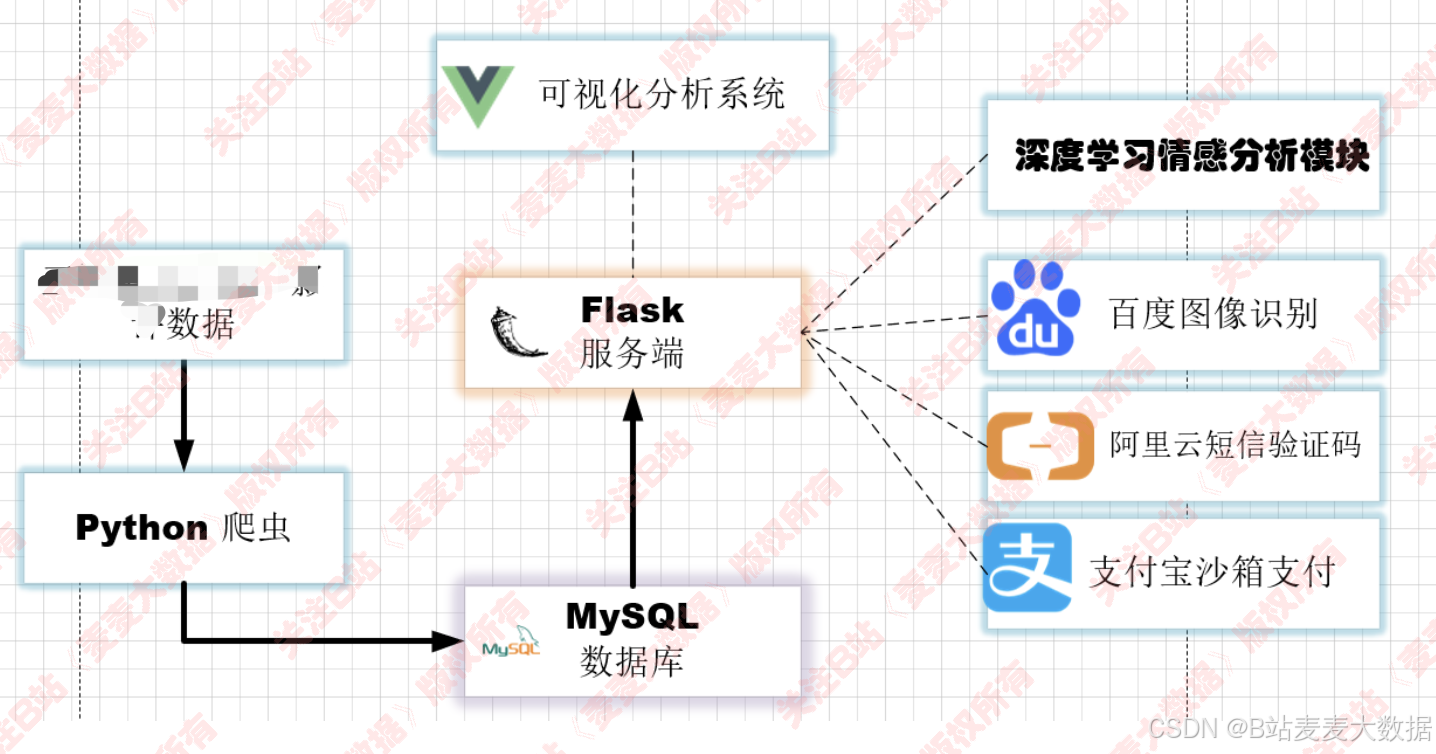
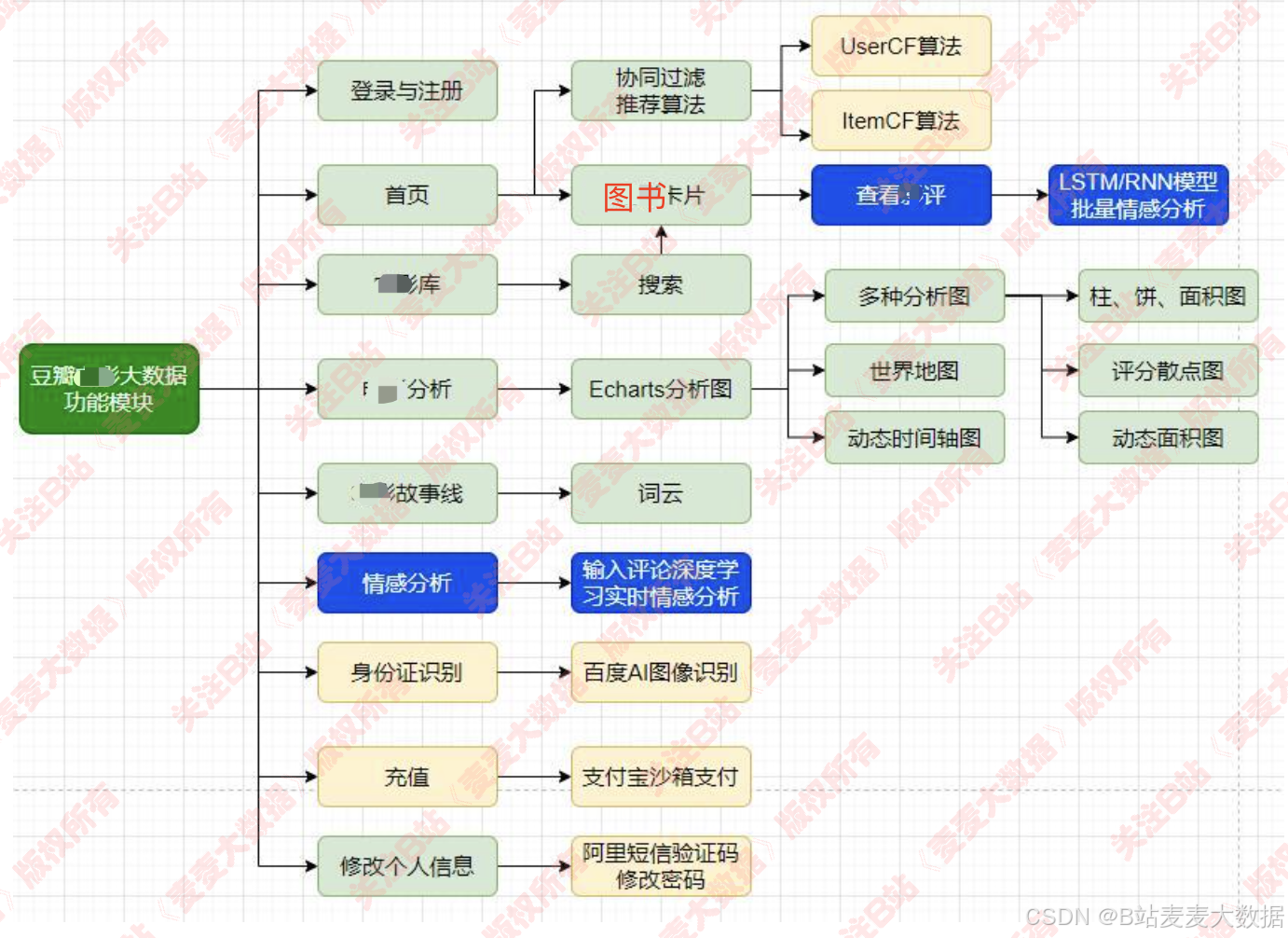
- 功能模块图
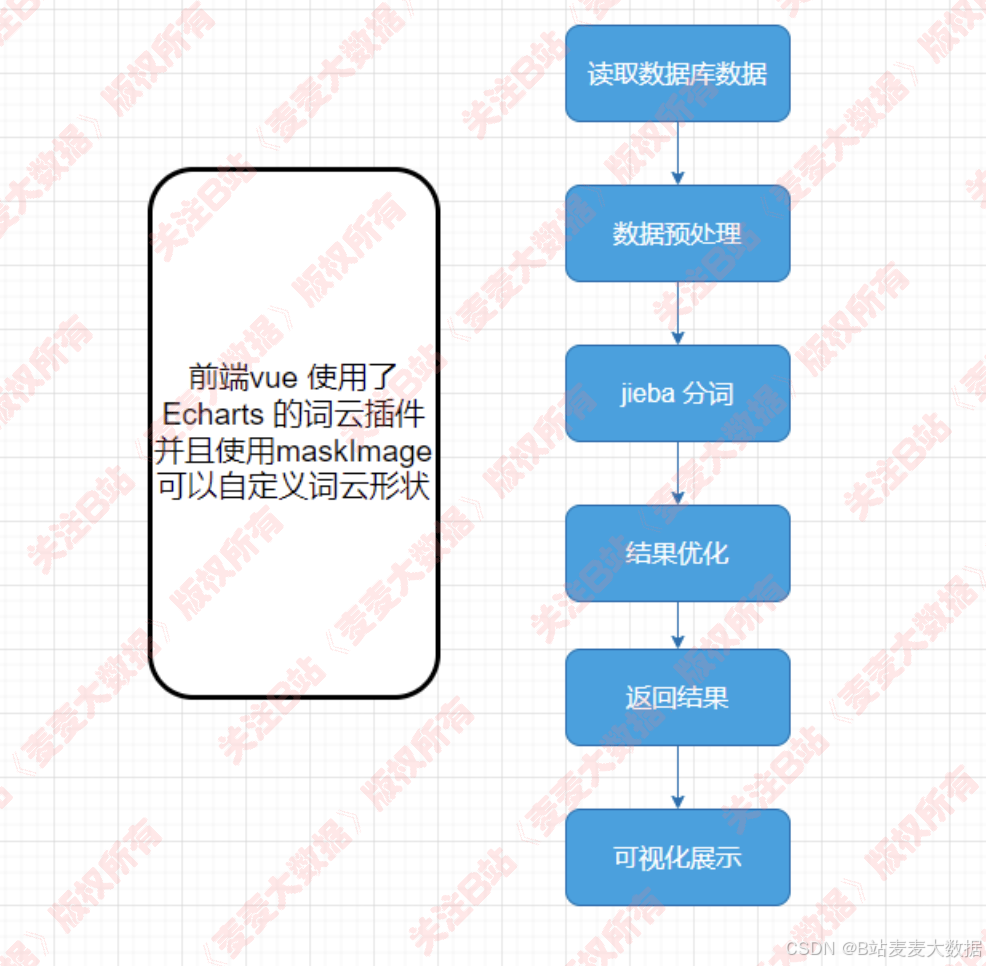
- 词云
4 功能介绍
4.1 登录
4.2 推荐算法
主页展示图书卡片
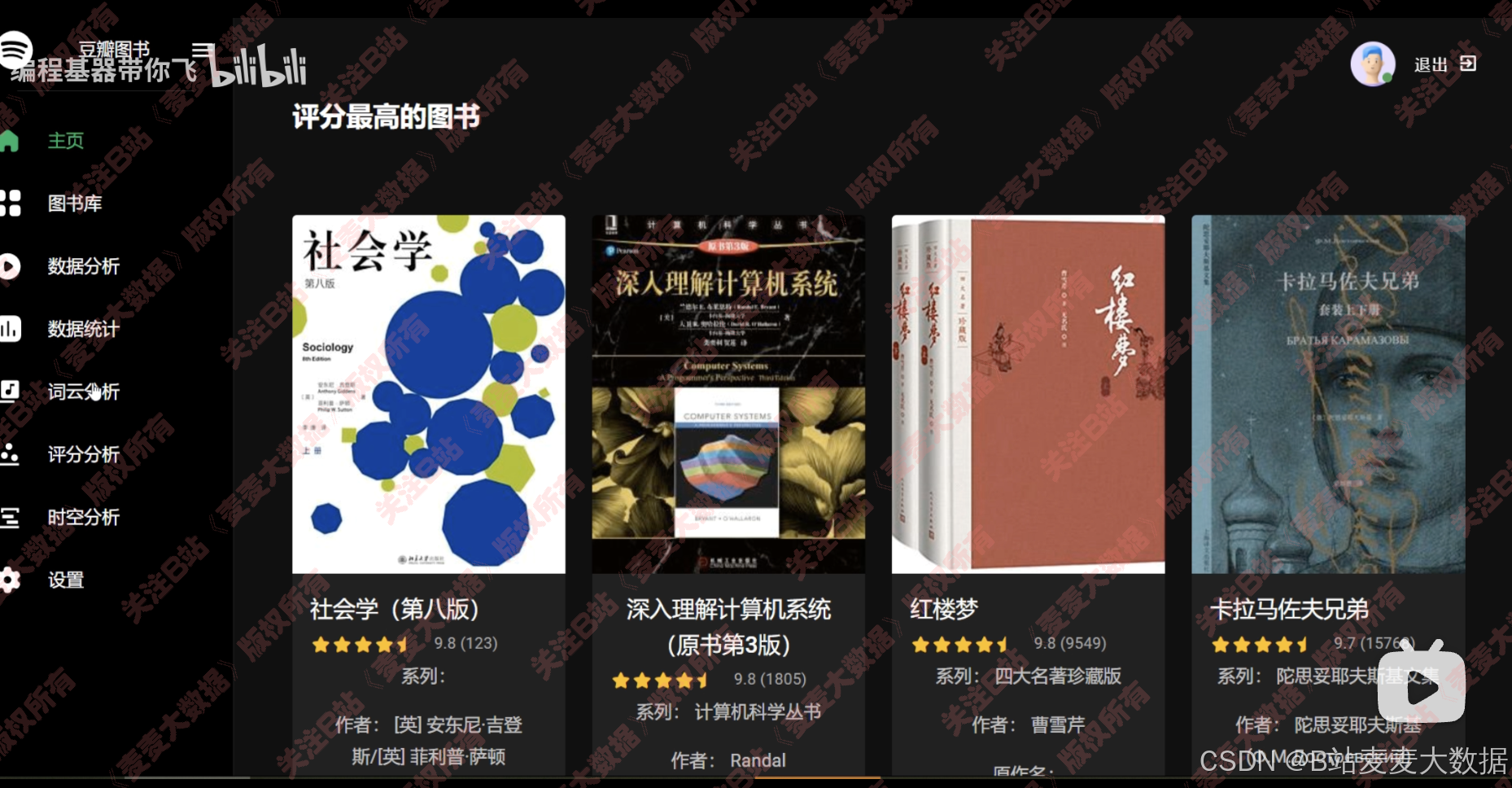
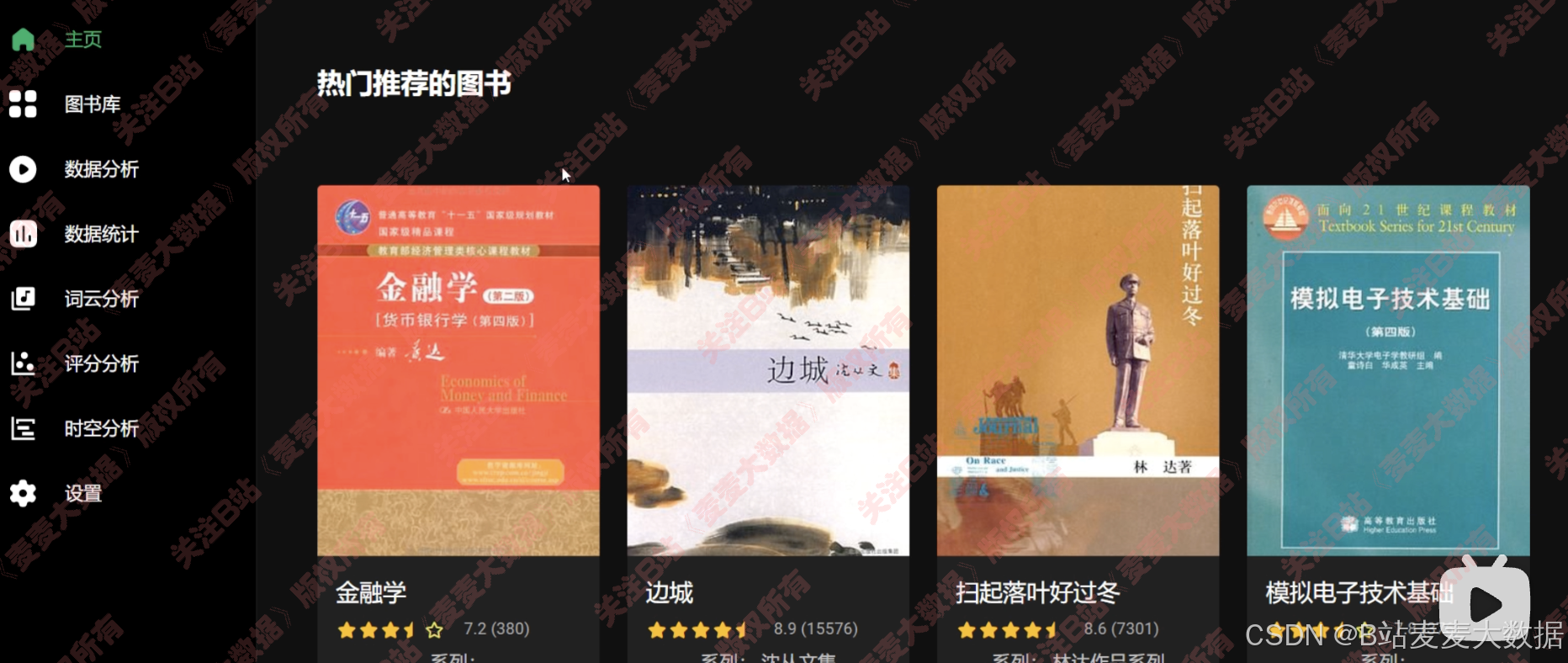
两种推荐算法usercf + itemcf 进行协同过滤之推荐
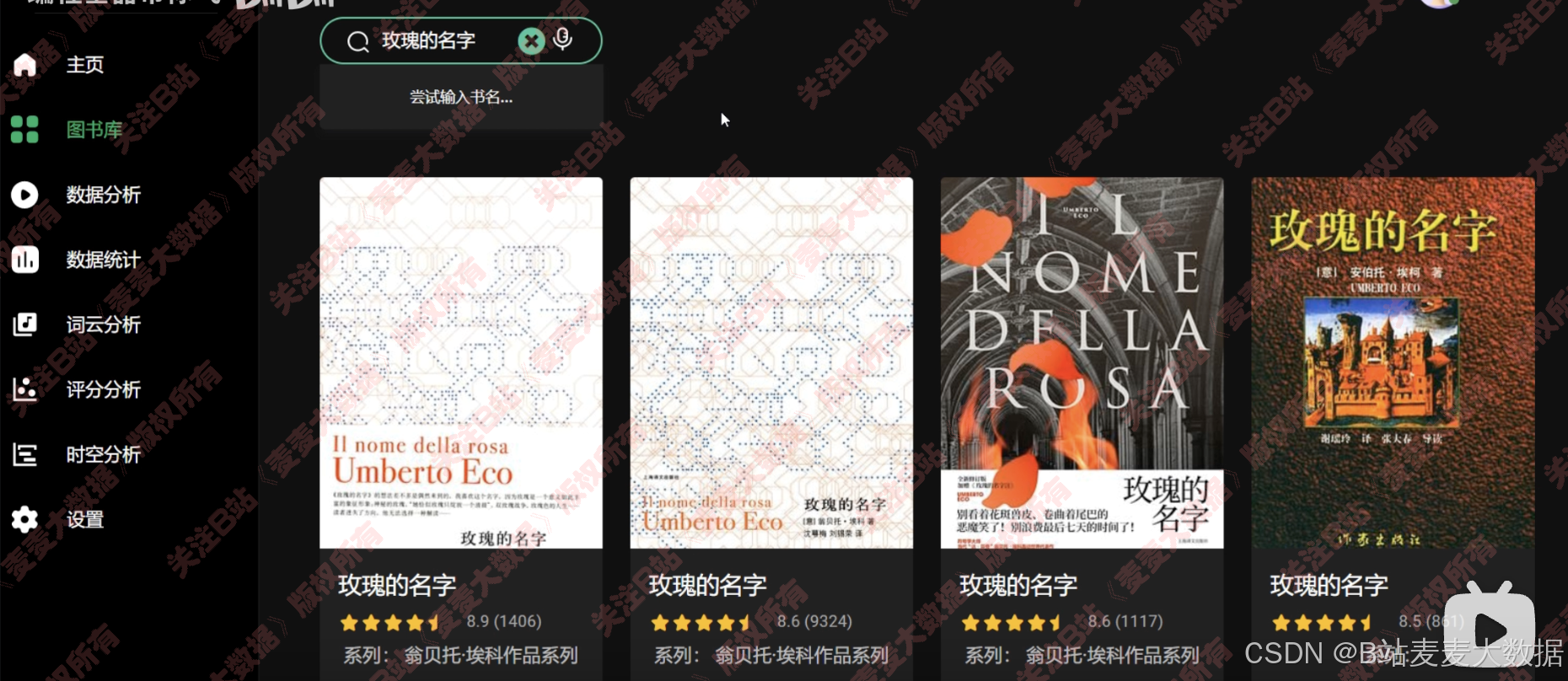
图书库可以根据关键词模糊搜索需要的图书
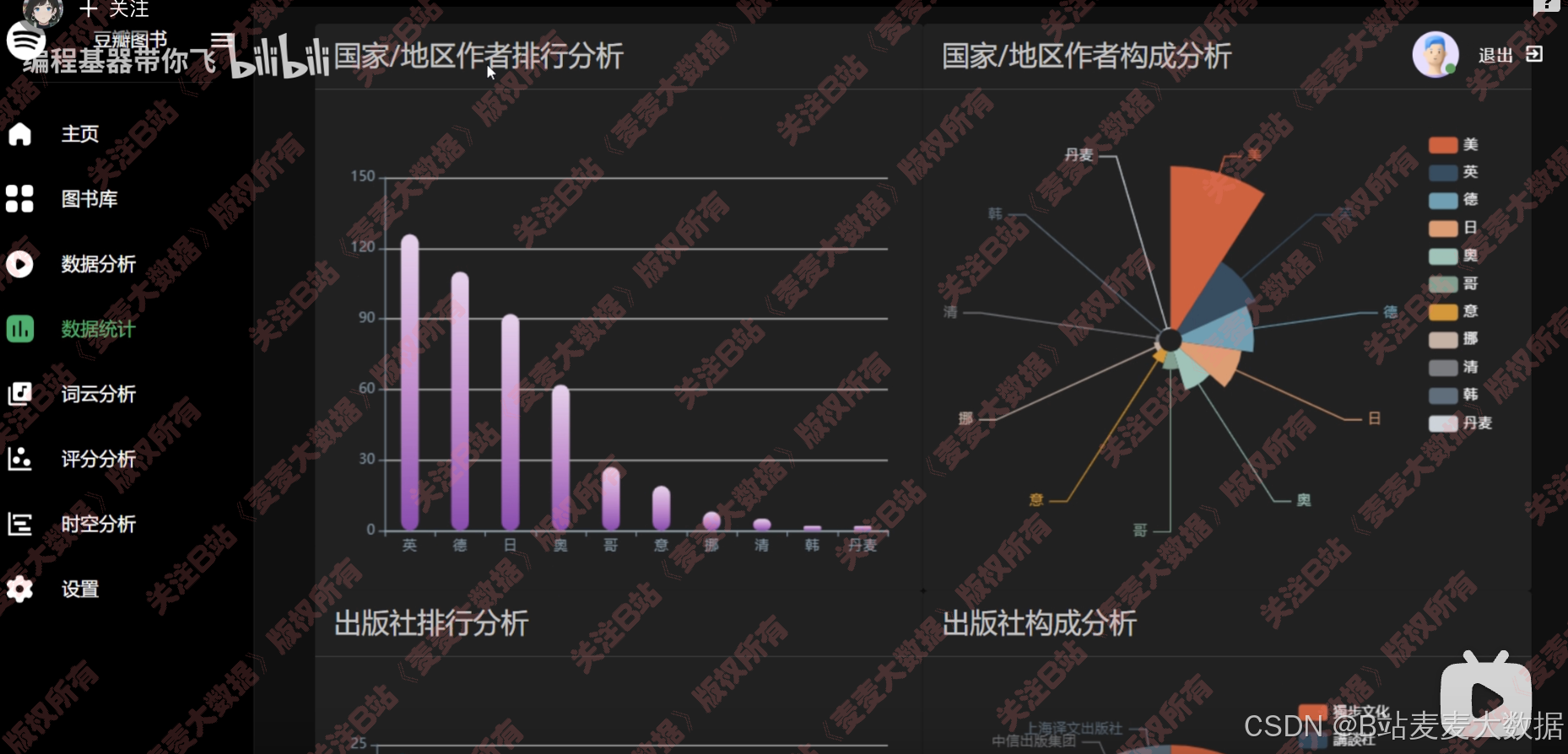
4.3 可视化分析
基于多种echarts图形对图书数据进行多个角度之分析:
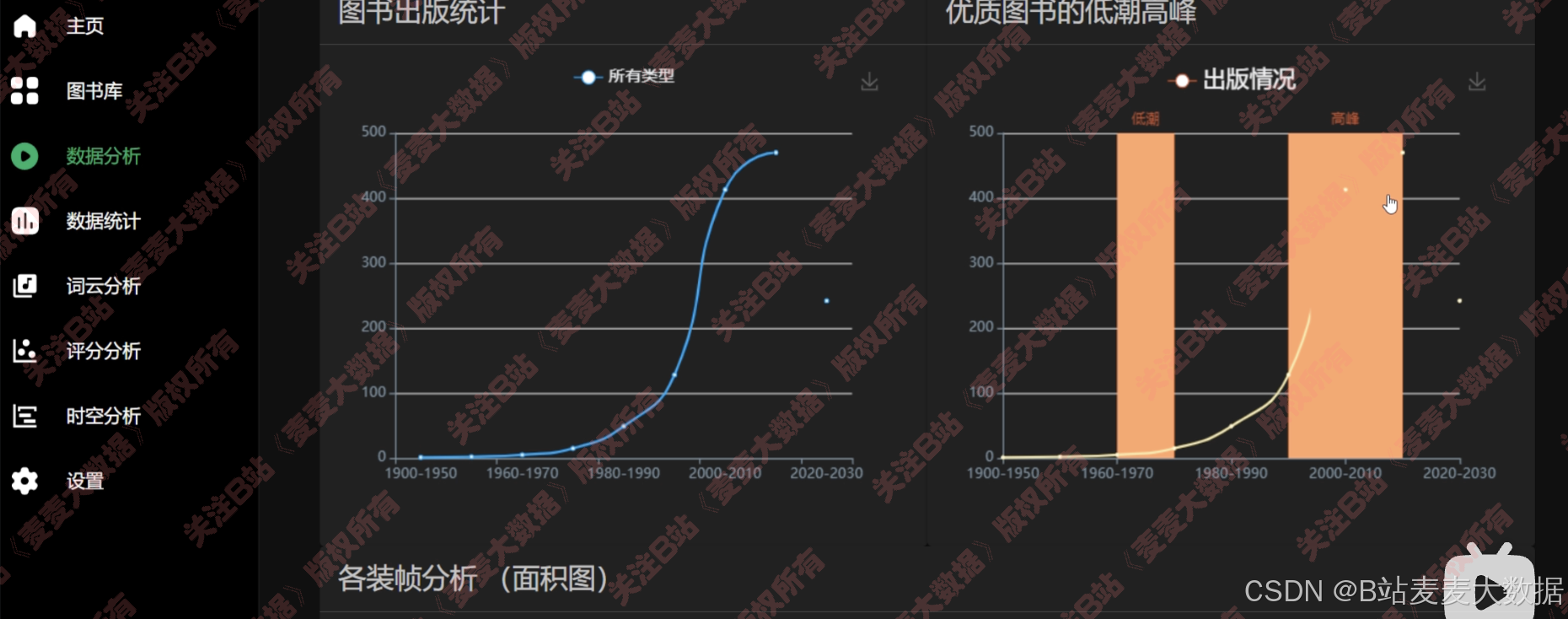
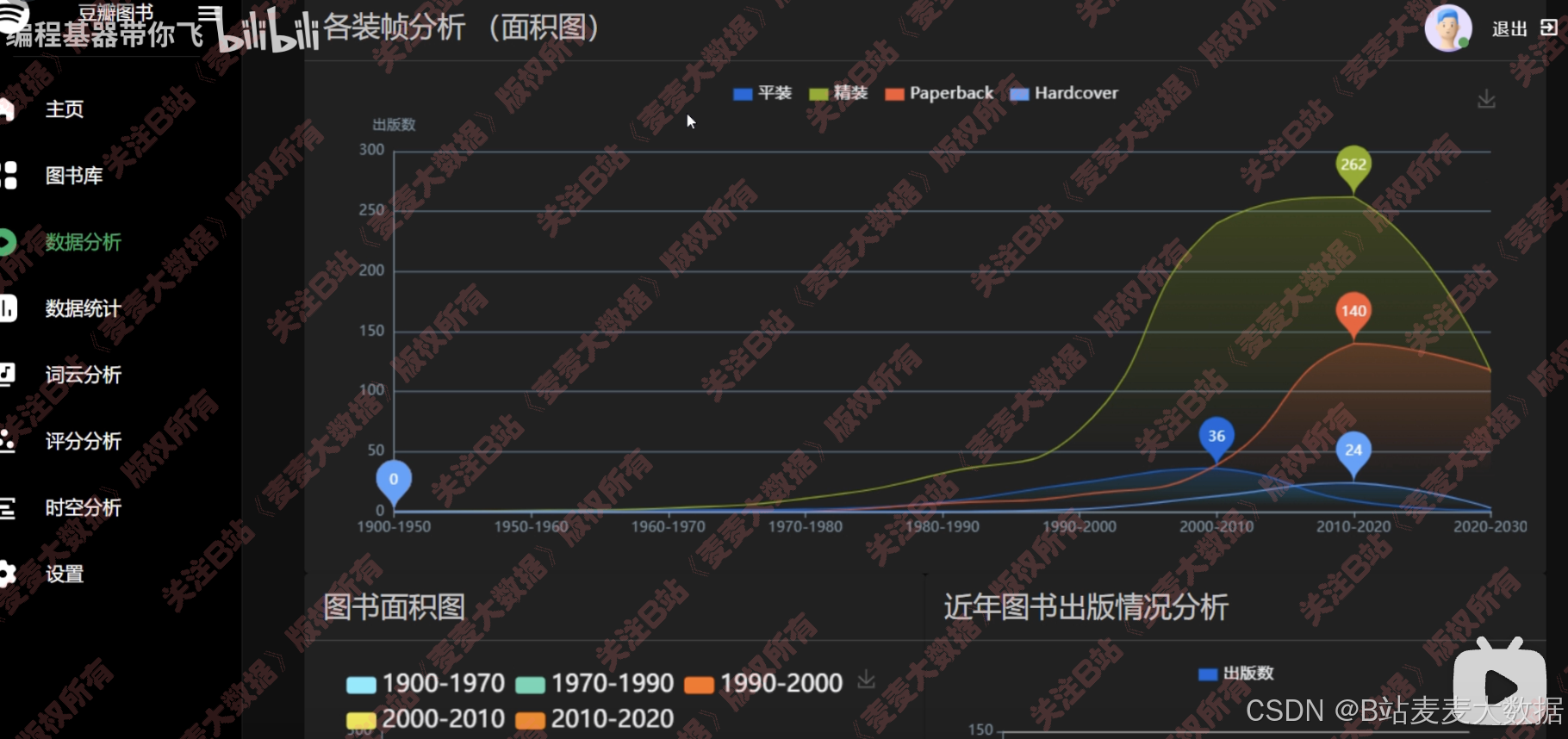
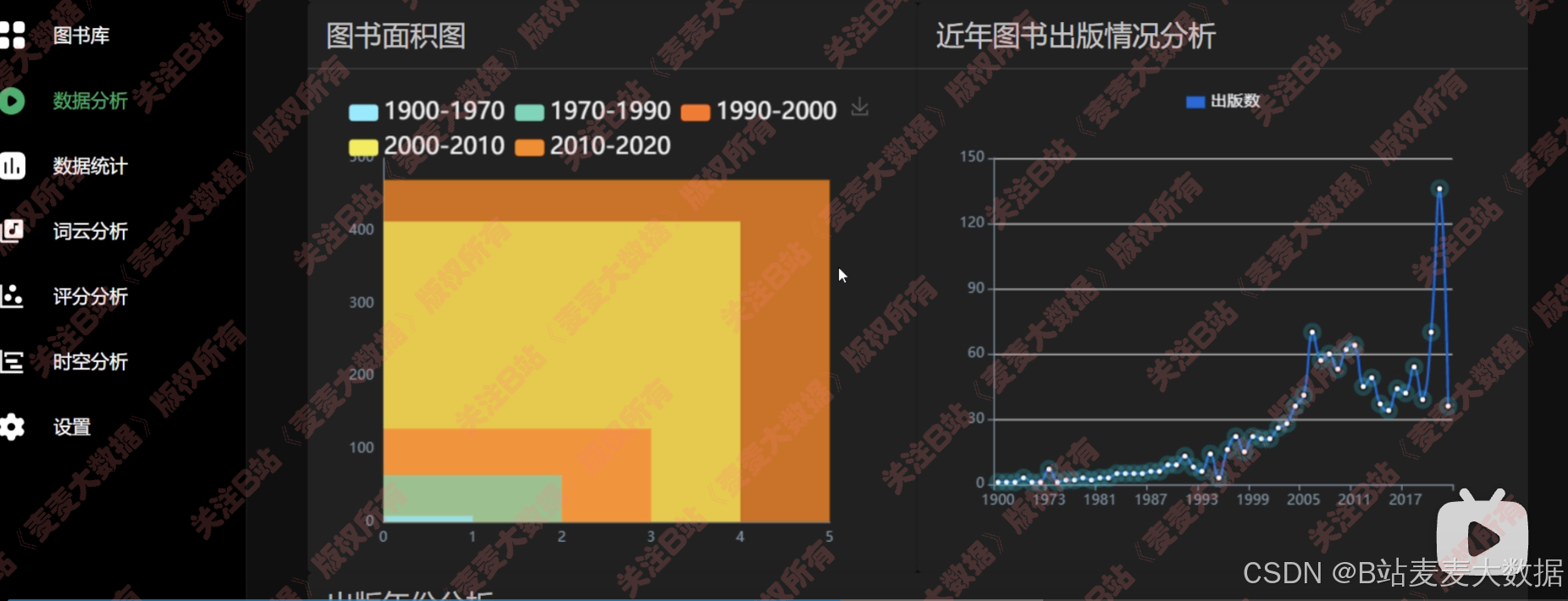
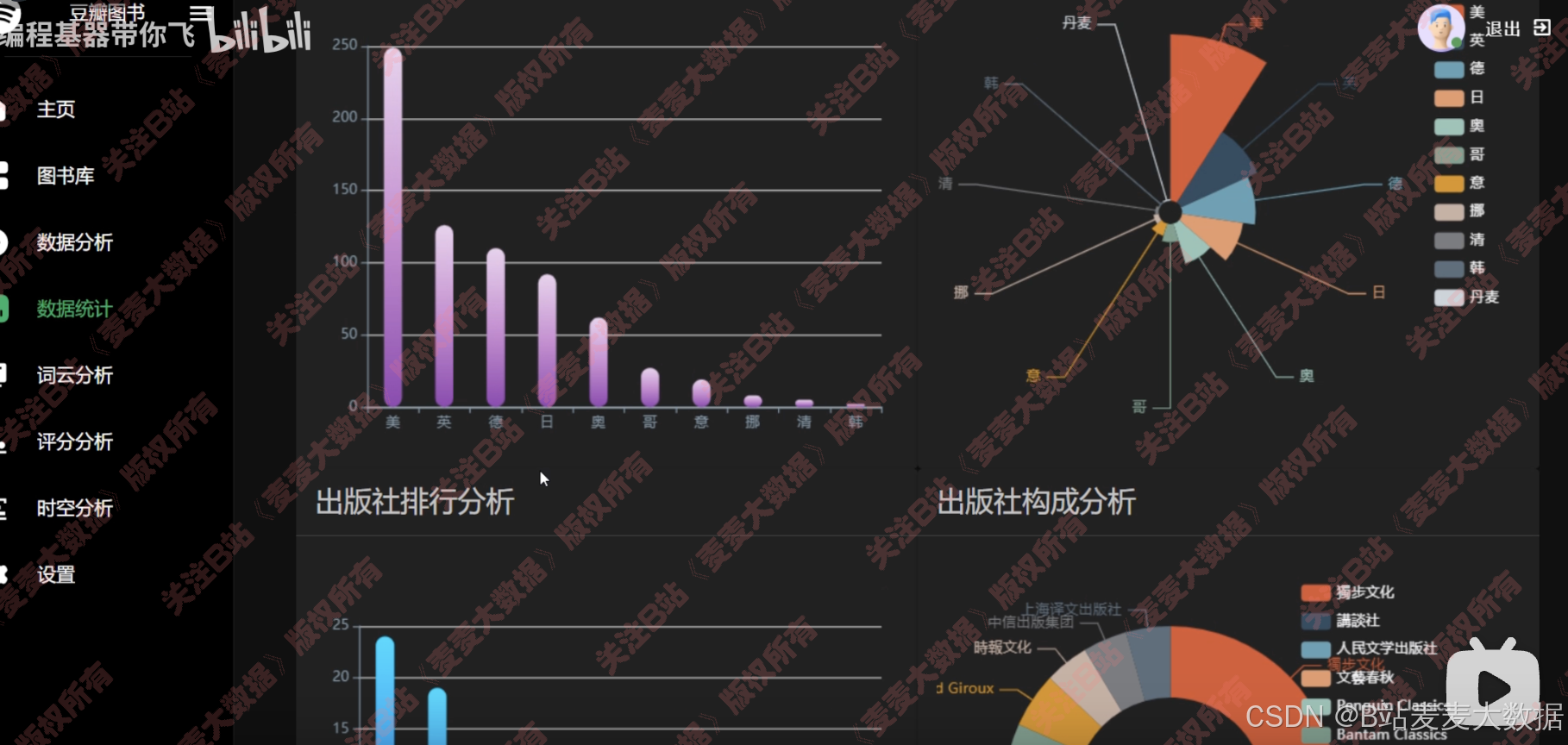
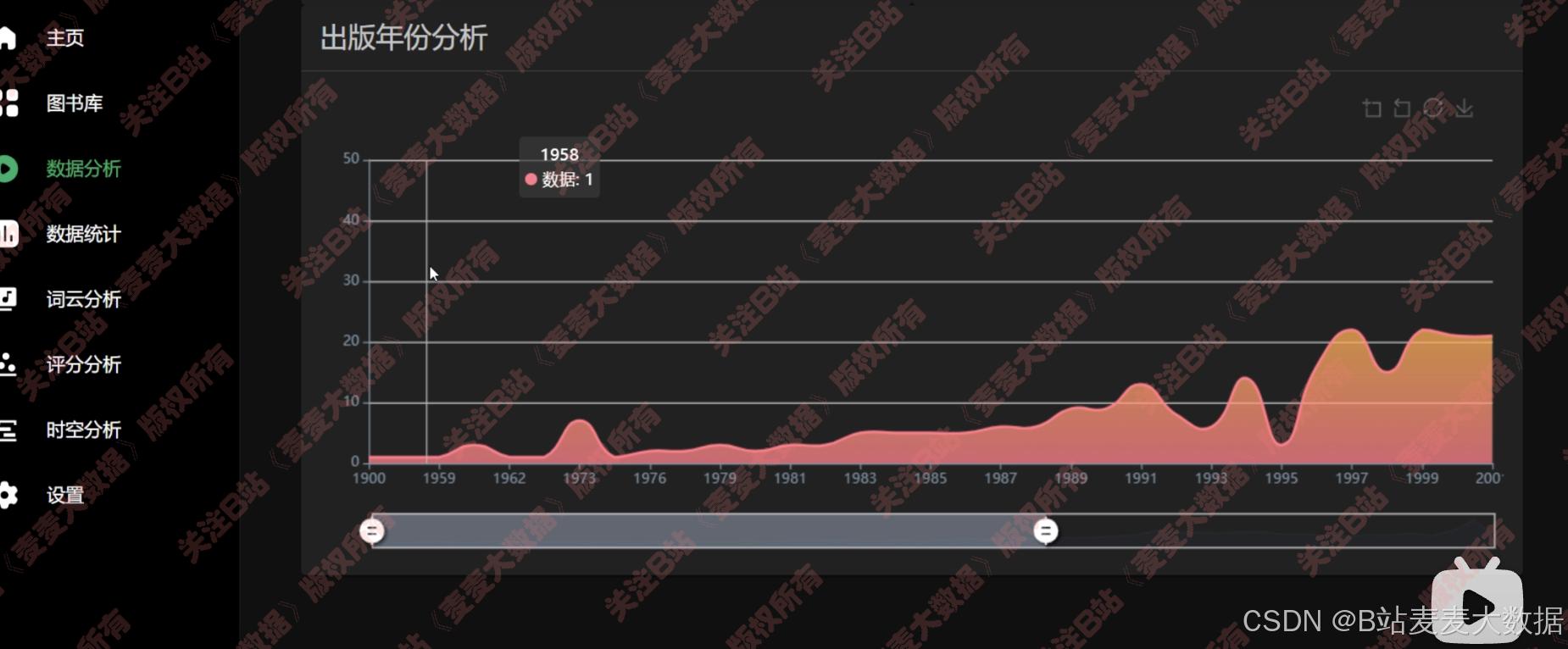
折线图,可以缩放x轴
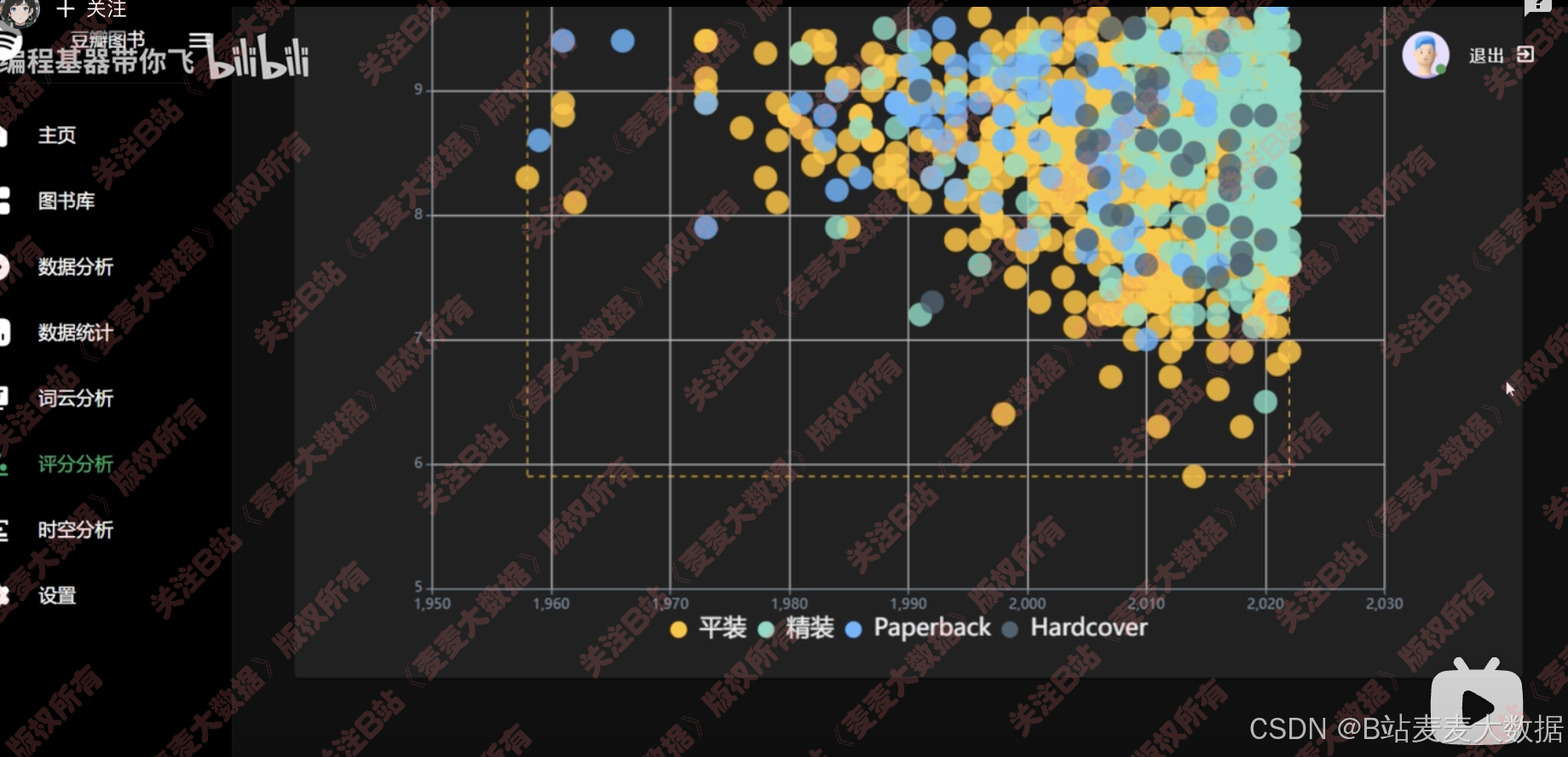
散点图的评分分析,点击每个点都是一本图书的信息
词云分析,基于jieba分词进行词频

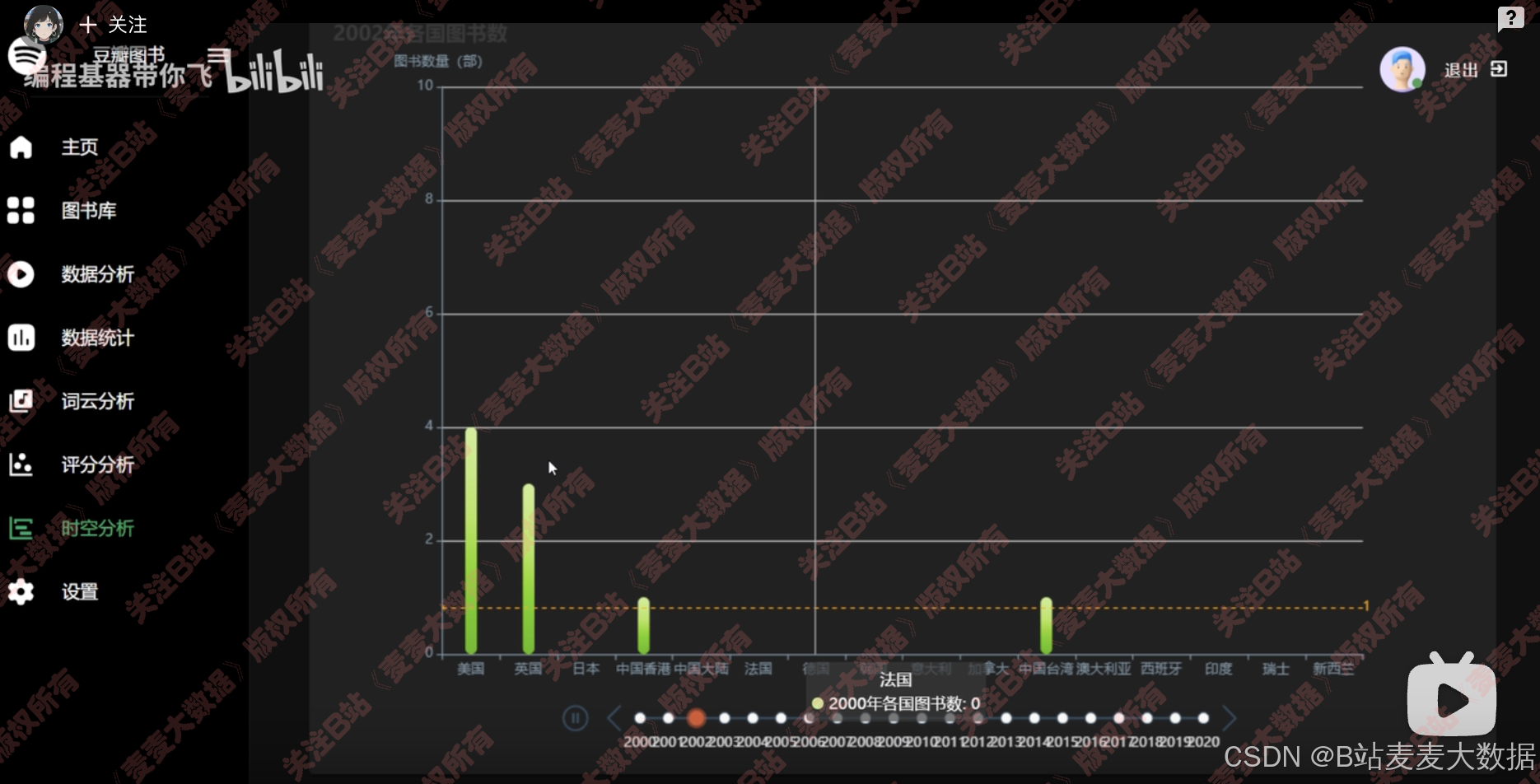
时空分析,基于时间范围的柱状图
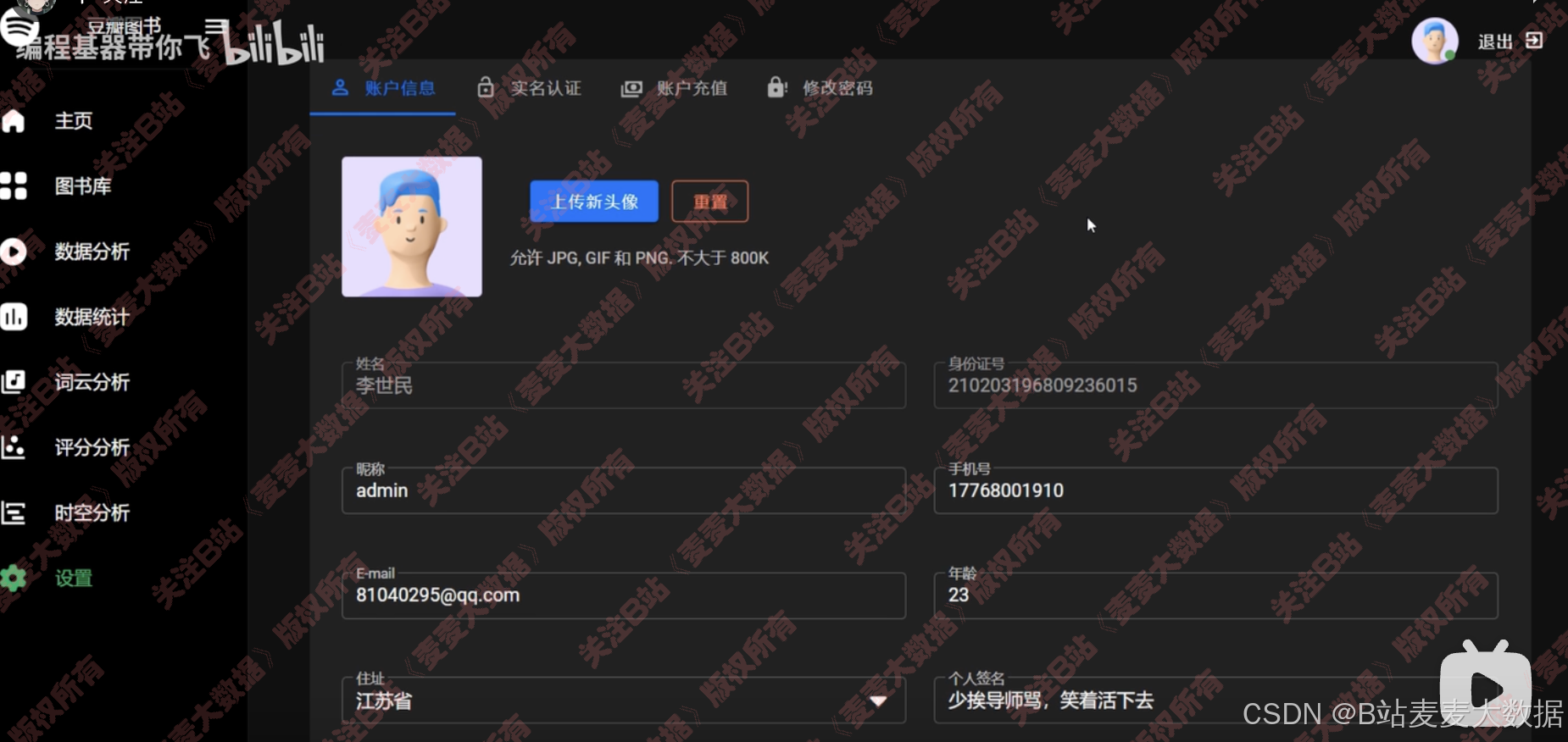
4.4 个人设置
5 推荐算法
算法介绍:首先构建用户-图书评分矩阵,包含5个用户和5本书籍的评分数据(含缺失值)。接着进行数据预处理:对每个用户评分进行中心化处理(减去该用户的平均分)以消除评分偏差。然后计算用户相似度矩阵——使用中心化后的数据填充0值后,通过余弦相似度衡量用户间兴趣相似度。核心推荐阶段:选取目标用户(如"用户A"),基于相似用户的加权评分预测其对未评分书籍的评分(权重由相似度决定),最后输出预测分最高的未评分书籍作为推荐结果。整个流程完成了从数据准备、相似度计算到评分预测和推荐生成的完整闭环。
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity# 生成示例数据 - 用户对图书的评分(0-5分)
# 行:用户,列:图书,缺失值为NaN
ratings_data = {'用户A': [5, 4, np.nan, 1, np.nan],'用户B': [np.nan, 5, 4, np.nan, 2],'用户C': [4, np.nan, np.nan, 3, 5],'用户D': [np.nan, 2, 5, 4, np.nan],'用户E': [3, np.nan, 4, np.nan, 5]
}
books = ['编程基础', 'Python进阶', '机器学习', '深度学习', '算法导论']# 创建评分数据框
ratings_df = pd.DataFrame(ratings_data, index=books)
print("原始评分数据:")
print(ratings_df)# 数据预处理 - 中心化(减去用户平均分)
def normalize_data(df):return df.sub(df.mean(axis=1), axis=0)# 使用平均值填充缺失值
def fill_nan(df):return df.fillna(df.mean(axis=1))# 计算用户相似度矩阵
def calculate_similarity(normalized_df):# 填充缺失值为0(中心化后的平均值为0)filled_df = normalized_df.fillna(0)# 计算余弦相似度similarity = cosine_similarity(filled_df.T)return pd.DataFrame(similarity, index=normalized_df.columns, columns=normalized_df.columns)# 预测用户对图书的评分
def predict_ratings(user_id, normalized_df, similarity_df):# 获取目标用户评分向量user_ratings = normalized_df[user_id]# 排除目标用户自身similarity_users = similarity_df[user_id].drop(user_id)# 计算预测评分numerator = np.zeros(len(books))denominator = 1e-8 # 避免除以0for other_user, sim in similarity_users.items():# 只有相似度大于0且该用户有评分时才考虑if sim > 0:other_ratings = normalized_df[other_user].fillna(0)numerator += sim * other_ratings.valuesdenominator += sim# 计算预测评分predicted = numerator / denominator if denominator != 0 else 0return predicted + ratings_df.mean(axis=1)[user_id] # 加上平均分恢复原始评分尺度# 主推荐函数
def recommend_books(user_id, top_n=2):# 1. 数据预处理normalized_df = normalize_data(ratings_df)# 2. 计算相似度矩阵similarity_df = calculate_similarity(normalized_df)# 3. 预测所有书籍评分predicted_ratings = predict_ratings(user_id, normalized_df, similarity_df)# 4. 获取未评分书籍user_ratings = ratings_df[user_id]unrated_books = user_ratings[user_ratings.isnull()].index# 5. 推荐评分最高的书籍recommendations = predicted_ratings.loc[unrated_books].nlargest(top_n)return recommendations# 示例使用
if __name__ == "__main__":target_user = '用户A'recommendations = recommend_books(target_user)print(f"\n给{target_user}的推荐书籍:")for book, rating in recommendations.items():print(f"- {book} (预测评分: {rating:.2f})")