卷积神经网络(CNN)搭建详解
目录
前言
一、环境准备
二、数据预处理:为模型准备 “食材”
1. 导入依赖库
2. 加载并可视化 MNIST 数据集
3. 创建 DataLoader:批量加载数据
4. 设备选择:自动适配 CPU/GPU/MPS
三、搭建 CNN 网络:设计 “特征提取器”
1.搭建 CNN 网络结构
2.定义训练与测试函数
(1)训练函数:模型学习过程
2)测试函数:模型性能评估
3. 配置训练参数并执行训练
完整代码如下:
总结
前言
卷积神经网络(CNN)是深度学习在计算机视觉领域的核心模型,凭借其 “局部感知” 和 “参数共享” 的特性,能高效提取图像特征,在手写数字识别、图像分类等任务中表现优异。本文将基于 PyTorch 框架,从数据预处理、网络搭建、模型训练到优化迭代,手把手教你实现一个能识别 MNIST 手写数字的 CNN 模型,代码可直接运行,新手也能快速上手!
一、环境准备
首先确保已安装以下依赖库,若未安装可通过pip命令安装:
pip install torch torchvision # PyTorch核心库+计算机视觉扩展库二、数据预处理:为模型准备 “食材”
MNIST 是手写数字识别的经典数据集,包含 70000 张 28×28 的灰度图像(60000 张训练集 + 10000 张测试集)。我们需要先下载数据集,并通过DataLoader封装成模型可读取的格式。
1. 导入依赖库
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
from matplotlib import pyplot as plt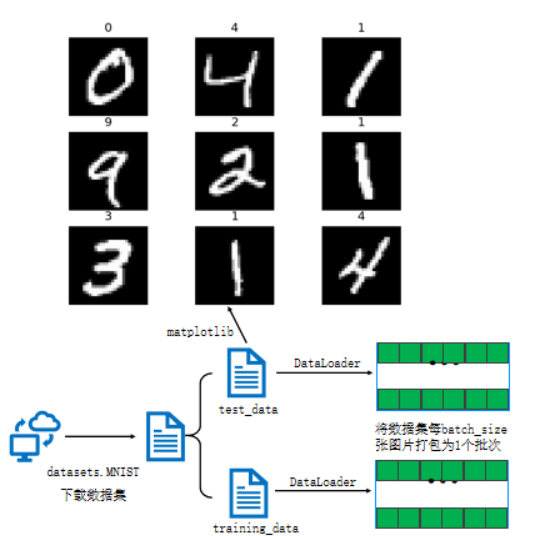
2. 加载并可视化 MNIST 数据集
MNIST 数据集包含 70000 张 28×28 的灰度手写数字图像(60000 张训练集 + 10000 张测试集),我们先通过torchvision.datasets下载并加载,再可视化部分样本直观了解数据格式。
# 加载MNIST训练集与测试集
train_data = datasets.MNIST(root='data', # 数据集保存路径(不存在则自动创建)train=True, # True=加载训练集,False=加载测试集download=True, # 若路径中无数据集,自动从官网下载transform=ToTensor() # 图像转换:PIL格式→Tensor格式(并归一化像素值到[0,1])
)test_data = datasets.MNIST(root='data',train=False,download=True,transform=ToTensor()
)# 可视化9个训练集样本(3行3列布局)
figure = plt.figure(figsize=(8, 8)) # 设置画布大小
for i in range(9):# 从训练集中取第i+100个样本(避开前100个样本,增加多样性)img, label = train_data[i + 100]ax = figure.add_subplot(3, 3, i + 1) # 创建子图ax.set_title(f"Label: {label}") # 标注样本真实标签ax.axis('off') # 隐藏坐标轴,更美观# 显示图像:squeeze()去除通道维度((1,28,28)→(28,28)),cmap='gray'用灰度显示ax.imshow(img.squeeze(), cmap='gray')
plt.show() # 统一显示所有子图,避免多次弹窗运行效果:

3. 创建 DataLoader:批量加载数据
直接使用原始数据集训练会占用大量内存,DataLoader可将数据按指定批次(batch_size)划分,同时支持打乱数据(训练集)和多线程加载,提升训练效率。
train_dataloader = DataLoader(train_data,batch_size=64, # 每批加载64个样本shuffle=True # 训练集打乱数据,避免模型学习数据顺序规律
)test_dataloader = DataLoader(test_data,batch_size=64,shuffle=False # 测试集无需打乱,仅用于评估性能
)# 验证数据格式:查看一个批次的数据形状
for x, y in test_dataloader:print(f"输入图像形状 [N, C, H, W]: {x.shape}") # N=批次大小,C=通道数,H=高度,W=宽度print(f"标签形状: {y.shape} | 标签数据类型: {y.dtype}")break输出结果:
说明数据已成功封装:每个 batch 包含 64 张 1 通道、28×28 的图像,以及对应的 64 个标签(0-9 的整数)。
4. 设备选择:自动适配 CPU/GPU/MPS
PyTorch 支持 CPU、GPU(NVIDIA)和 MPS(苹果 M 系列芯片)训练,通过以下代码自动选择最优设备,提升训练速度:
device = ("cuda"if torch.cuda.is_available() # 优先使用NVIDIA GPUelse "mps"if torch.backends.mps.is_available() # 其次使用苹果MPSelse "cpu" # 最后使用CPU
)
print(f"使用训练设备: {device}")三、搭建 CNN 网络:设计 “特征提取器”
1.搭建 CNN 网络结构
CNN 的核心结构包括卷积层(提取图像特征)、激活层(引入非线性)、池化层(降维减参)和全连接层(最终分类)。我们将搭建一个包含 3 个卷积模块的 CNN,结构如下:
输入层 → 卷积层1 → ReLU → 池化层1 → 卷积层2 → ReLU → 卷积层3 → ReLU → 池化层2 → 全连接层 → 输出层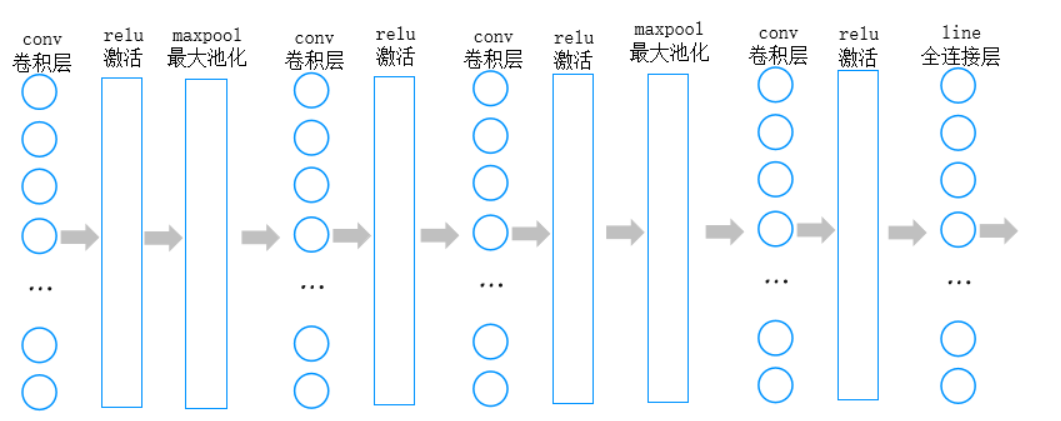
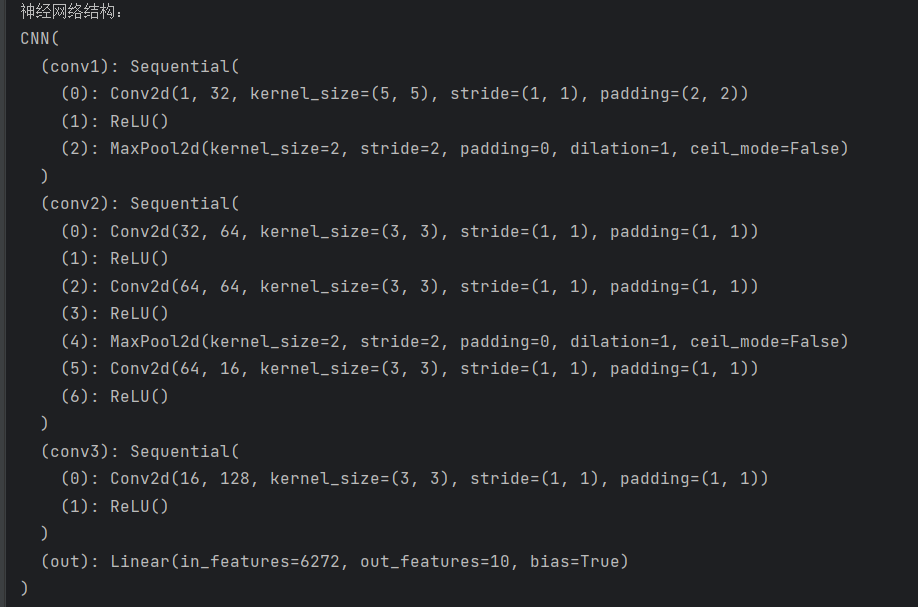
class CNN(nn.Module):def __init__(self):super().__init__() # 继承nn.Module的初始化方法# 卷积模块1:输入(1,28,28) → 输出(32,14,14)self.conv1 = nn.Sequential(# 卷积层:1个输入通道→32个输出通道(32个卷积核),核大小5×5,步长1, padding=2(保证输入输出尺寸一致)nn.Conv2d(in_channels=1, out_channels=32, kernel_size=5, stride=1, padding=2),nn.ReLU(), # 激活层:引入非线性,增强模型表达能力nn.MaxPool2d(kernel_size=2) # 池化层:2×2池化,尺寸减半(28→14),减少计算量)# 卷积模块2:输入(32,14,14) → 输出(16,7,7)self.conv2 = nn.Sequential(nn.Conv2d(32, 64, 3, 1, 1), # 3×3卷积核,padding=1(尺寸不变)nn.ReLU(),nn.Conv2d(64, 64, 3, 1, 1), # 再添加一层卷积,增强特征提取能力nn.ReLU(),nn.MaxPool2d(kernel_size=2), # 池化后尺寸14→7nn.Conv2d(64, 16, 3, 1, 1), # 减少通道数,降低后续计算量nn.ReLU())# 卷积模块3:输入(16,7,7) → 输出(128,7,7)self.conv3 = nn.Sequential(nn.Conv2d(16, 128, 3, 1, 1), # 增加通道数,提取更复杂的特征nn.ReLU())# 全连接层:输入(128×7×7) → 输出(10)(10个类别:0-9)self.out = nn.Linear(128 * 7 * 7, 10)# 前向传播:定义数据在网络中的流动路径def forward(self, x):x = self.conv1(x) # 经过卷积模块1x = self.conv2(x) # 经过卷积模块2x = self.conv3(x) # 经过卷积模块3x = x.view(x.size(0), -1) # 展平操作:(batch_size, 128,7,7) → (batch_size, 128×7×7)out = self.out(x) # 全连接层输出类别分数return out# 初始化模型,并移动到指定设备(CPU/GPU/MPS)
model = CNN().to(device)
print("CNN神经网络结构:")
print(model) # 打印模型结构,验证是否正确输出模型结构:
2.定义训练与测试函数
(1)训练函数:模型学习过程
训练的核心是 “前向传播算损失→反向传播求梯度→优化器更新参数”,同时定期打印训练进度。
def train(dataloader, model, loss_fn, optimizer):model.train() # 开启训练模式(启用Dropout、BatchNorm等训练特有的层)batch_size_num = 0 # 批次计数器,用于控制打印频率for x, y in dataloader:# 将数据移动到与模型相同的设备(避免设备不匹配报错)x, y = x.to(device), y.to(device)# 1. 前向传播:计算模型预测值pred = model(x) # PyTorch自动调用forward()方法,无需手动调用# 2. 计算损失:用交叉熵损失(适用于多分类任务)loss = loss_fn(pred, y)# 3. 反向传播与参数更新optimizer.zero_grad() # 清零上一轮的梯度(避免梯度累积)loss.backward() # 反向传播:计算各参数的梯度optimizer.step() # 优化器:根据梯度更新模型参数# 记录损失值与批次号loss_value = loss.item() # 获取损失的数值(脱离计算图,避免内存占用)batch_size_num += 1# 每100个批次打印一次损失(便于观察训练趋势)if batch_size_num % 100 == 0:print(f"loss: {loss_value:>7f} [batch: {batch_size_num}]")2)测试函数:模型性能评估
测试阶段无需更新参数,仅需计算测试集的准确率和平均损失,评估模型泛化能力。
def test(dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集总样本数num_batches = len(dataloader) # 测试集总批次数model.eval() # 开启评估模式(关闭Dropout等训练层)test_loss, correct = 0, 0 # 初始化测试损失和正确预测数# 禁用梯度计算:测试阶段无需求梯度,节省内存和计算时间with torch.no_grad():for x, y in dataloader:x, y = x.to(device), y.to(device)pred = model(x)# 累加测试损失和正确预测数test_loss += loss_fn(pred, y).item()# pred.argmax(1):取每个样本预测分数最高的类别(维度1为类别维度)correct += (pred.argmax(1) == y).type(torch.float).sum().item()# 计算平均损失和准确率test_loss /= num_batches # 平均损失=总损失/批次数correct /= size # 准确率=正确预测数/总样本数print(f"Test result: \n Accuracy: {(100 * correct):>0.1f}%, Avg loss: {test_loss:>8f}\n")3. 配置训练参数并执行训练
设置损失函数、优化器和训练轮次(epochs),然后循环执行训练和测试。
# 1. 配置训练参数
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失函数(多分类任务首选)
optimizer = torch.optim.Adam( # Adam优化器(收敛快,自适应学习率)model.parameters(), # 待优化的模型参数lr=0.0001 # 学习率:控制参数更新幅度(0.0001为经验值,避免过大导致震荡)
)
epochs = 10 # 训练轮次:全量数据训练10次(可根据需求调整,5-10轮足够收敛)# 2. 执行训练与测试
for t in range(epochs):print(f"Epoch {t + 1}\n--------------")train(train_dataloader, model, loss_fn, optimizer) # 训练一轮test(test_dataloader, model, loss_fn) # 测试一轮
print("Training Done!") # 训练完成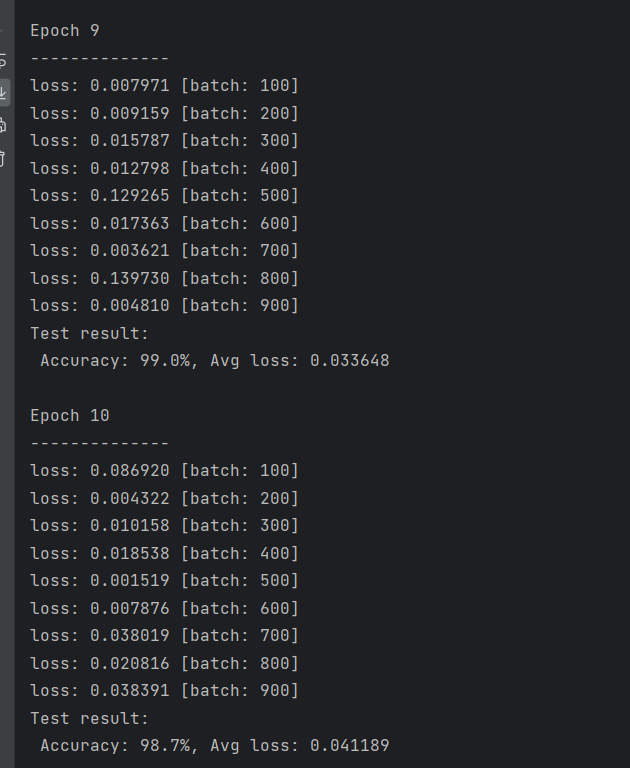
完整代码如下:
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
from matplotlib import pyplot as plt# 1. 加载MNIST数据集(这部分没问题,保留)
train_data = datasets.MNIST(root='data',train=True,download=True,transform=ToTensor(),
)
test_data = datasets.MNIST(root='data',train=False,download=True,transform=ToTensor(),
)# 2. 显示部分训练数据(修正plt.show()位置,避免每次循环都弹出窗口)
figure = plt.figure(figsize=(8, 8)) # 设置图大小,显示更清晰
for i in range(9):img, label = train_data[i + 100]ax = figure.add_subplot(3, 3, i + 1)ax.set_title(f"Label: {label}") # 明确标注标签ax.axis('off')ax.imshow(img.squeeze(), cmap='gray') # squeeze() 去除通道维度(1,28,28)→ (28,28)
plt.show() # 循环结束后统一显示,避免多次弹窗# 3. 创建数据加载器(没问题,保留)
train_dataloader = DataLoader(train_data, batch_size=64, shuffle=True) # 训练集添加shuffle,打乱数据
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=False) # 测试集无需shuffle# 4. 查看数据形状(没问题,保留)
for x, y in test_dataloader:print(f"shape of x [N, C, H, W]: {x.shape}") # 输出应为 (64, 1, 28, 28)print(f"shape of y: {y.shape} {y.dtype}") # 输出应为 (64,) torch.int64break# 5. 设备选择(修正MPS检测语法,确保兼容性)
device = ("cuda"if torch.cuda.is_available()else "mps"if torch.backends.mps.is_available()else "cpu"
)
print(f"using {device} device")class CNN(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=32, kernel_size=5, stride=1, padding=2),nn.ReLU(),nn.MaxPool2d(kernel_size=2))self.conv2 = nn.Sequential(nn.Conv2d(32, 64, 3, 1, 1),nn.ReLU(),nn.Conv2d(64, 64, 3, 1, 1),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Conv2d(64, 16, 3, 1, 1),nn.ReLU())self.conv3 = nn.Sequential(nn.Conv2d(16, 128, 3, 1, 1),nn.ReLU())self.out = nn.Linear(128 * 7 *7 , 10)def forward(self, x):x = self.conv1(x)x = self.conv2(x)x = self.conv3(x)x = x.view(x.size(0), -1)out = self.out(x)return outmodel = CNN().to(device)
print("神经网络结构:")
print(model)def train(dataloader, model, loss_fn, optimizer):model.train() # 开启训练模式(启用Dropout、BatchNorm等训练特有的层)batch_size_num = 0 # 修正计数器初始值(从0开始更合理)for x, y in dataloader:# 将数据移动到目标设备(与模型同设备)x, y = x.to(device), y.to(device)# 修复:调用model(x)即可(PyTorch会自动调用forward方法,无需手动调用)pred = model(x)# 计算损失(CrossEntropyLoss适用于多分类任务)loss = loss_fn(pred, y)# 反向传播三步:清零梯度→计算梯度→更新参数optimizer.zero_grad() # 清零上一轮的梯度(避免累积)loss.backward() # 反向传播计算梯度optimizer.step() # 优化器更新模型参数loss_value = loss.item() # 获取损失的数值(脱离计算图)batch_size_num += 1if batch_size_num % 100 == 0:print(f"loss: {loss_value:>7f} [batch: {batch_size_num}]")def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)model.eval()test_loss, correct = 0, 0with torch.no_grad():for x, y in dataloader:x, y = x.to(device), y.to(device)pred = model(x)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()#test_loss /= num_batchescorrect /= sizeprint(f"Test result: \n Accuracy: {(100 * correct):>0.1f}%, Avg loss: {test_loss:>8f}\n")loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)epochs = 10
for t in range(epochs):print(f"Epoch {t + 1}\n--------------")train(train_dataloader, model, loss_fn, optimizer)test(test_dataloader, model, loss_fn)
print("Training Done!")总结
本文通过 PyTorch 实现了一个完整的 CNN 手写数字识别流程,核心要点包括:
- 数据处理:用
datasets加载 MNIST,DataLoader批量管理,matplotlib可视化样本。 - 网络设计:通过多卷积层 + 池化层提取图像特征,全连接层完成分类,确保输入输出尺寸匹配。
- 训练逻辑:前向传播算损失、反向传播求梯度、优化器更新参数,测试阶段禁用梯度计算。
代码可直接复制运行,适合新手入门 CNN 和 PyTorch 实战,也可基于此框架扩展到其他