机器学习基本概述
目录
什么是机器学习
机器如何学习
深度学习
学习方法
基础术语
算法分类
有监督学习
无监督学习
半监督学习
强化学习
机器学习建模
模型拟合
-
什么是机器学习
- 从数据中获取规律,利用规律从新的数据产生新的预测
-
机器如何学习
- 1、机器获取训练数据
- 2、分批将训练数据给机器进行训练
- 3、训练数据获得模型(公式)
- 4、测试集给出数据
- 5、通过模型预测结果
-
深度学习
- 大脑仿生
- 模拟生物神经元(树突、细胞核、轴突)
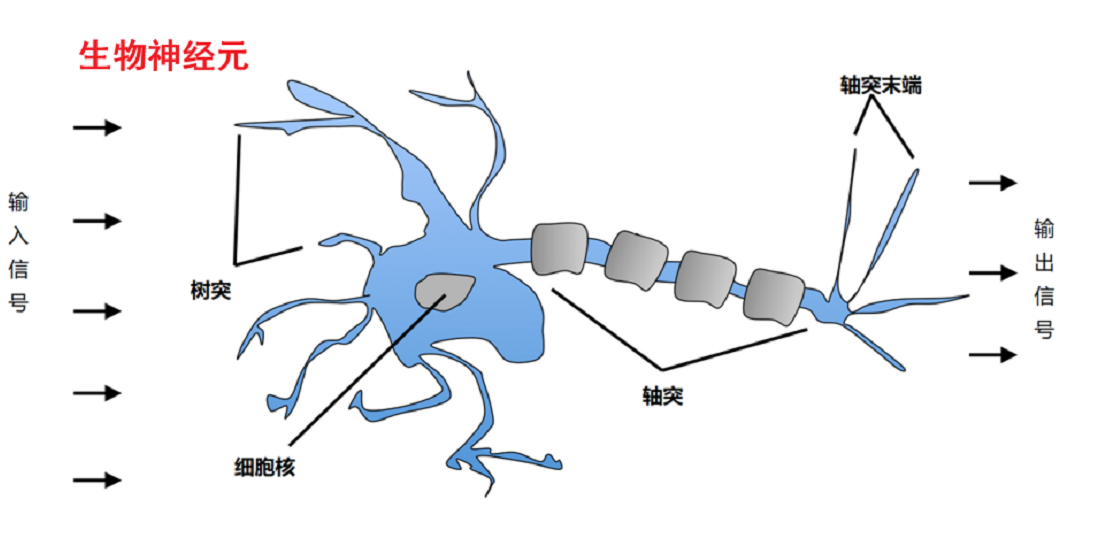
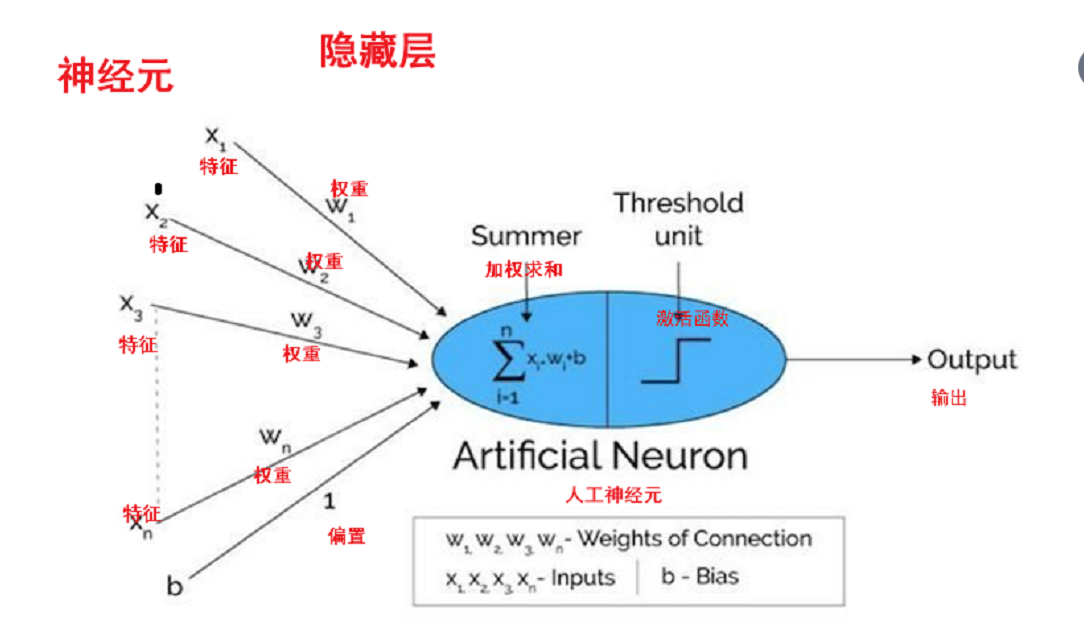
-
学习方法
- 基于规则的学习
- 程序员基于经验利用手动的if-else方式进行预测
- 缺点:跟不上更新速度,容易延迟(例如:新词语出现但是经验延迟无法预测)
- 基于模型的学习
- 从数据中自动学出规律
- 1、训练数据集
- 2、模型训练
- 3、利用测试集验证预测结果
- 从数据中自动学出规律
- 基于规则的学习
-
基础术语
- 样本:一行数据就是一个样本;多个样本组成数据集;有时一条样本被叫成一条记录
- 特征:一列数据一个特征,有时也被称为属性
- 标签/目标值:模型要预测的那一列数据(结果)
- 训练集:用来训练模型(model)的数据集训(训练集、测试集 比例:8 : 2,7 : 3 )
- 测试集:用来测试模型的数据集
-
算法分类
-
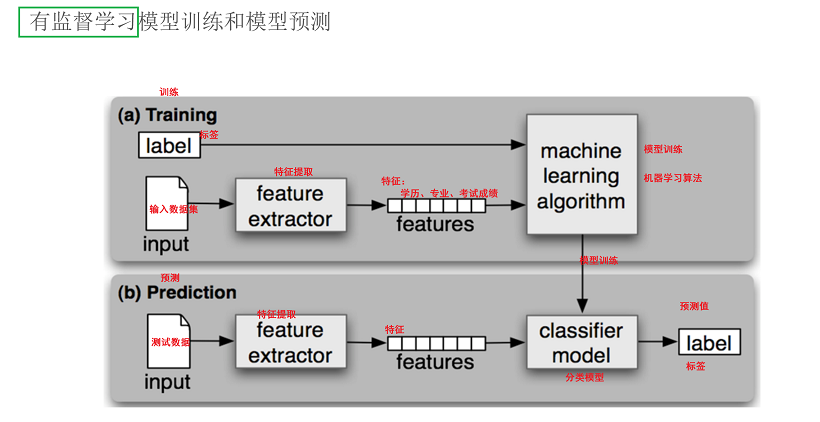
有监督学习
- 输入数据是由输入特征值和目标值所组成
- 即输入的训练数据有标签的
- 分类:分类(目标值(标签值)是不连续的)、回归(目标值(标签值)是连续的)
-
无监督学习
- 输入数据没有被标记,即样本数据类别未知,没有标签,根据样本间的相似性,对样本集聚类,以发现事物内部结构及相互关系
-
半监督学习
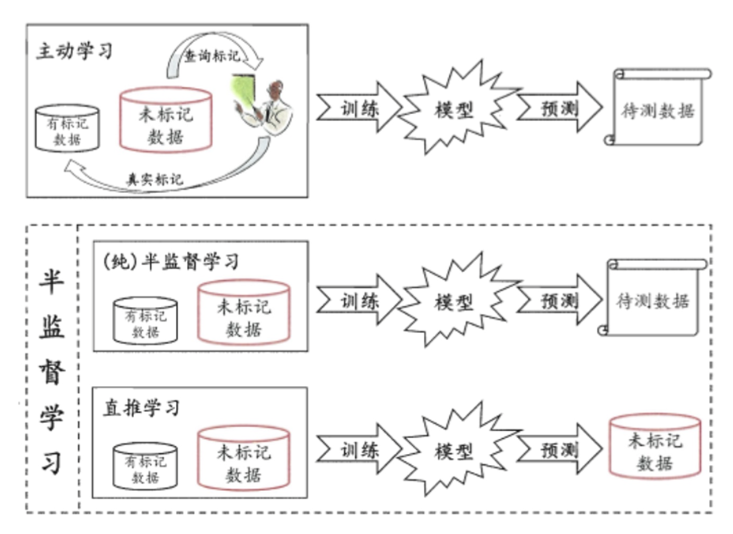
- 让专家标注少量数据,利用已经标记的数据
- 半监督学习方式可大幅降低标记成本
-
强化学习
- 通过构建四个要素:智能体,环境状态,行动,奖励,agent根据环境状态进行行动获得最多的累计奖励
-
-
机器学习建模
- 1、获取数据
- 2、数据基本处理(异常值、非空值处理)
- 3、特征工程(特征提取、特征预处理、特征降维、特征选择、特征组合)
- 4、机器学习(模型训练)
- 5、模型评估
-
模型拟合
- 欠拟合:模型在训练集上表现很差、在测试集表现也很差
- 原因:模型过于简单
- 过拟合:模型在训练集上表现很好、在测试集表现很差
- 原因:模型太过于复杂、数据不纯、训练数据太少
- 泛化:模型在新数据集(非训练数据)上的表现好坏的能力
- 奥卡姆剃刀原则:给定两个具有相同泛化误差的模型,较简单的模型比较复杂的模型更可取
- 欠拟合:模型在训练集上表现很差、在测试集表现也很差