秋招笔记-8.28
好久没写这玩意了哎哟我,主要前段时间的笔试面试都有点多,有笔试面试的日子就会懒得去写这个东西,不久后就是紧张刺激的二面了,今天的话先好好复习一下基本的八股,然后深挖项目背后的内容吧。
八股
C++
如何实现在main函数之前和之后执行?底层原理?
使用attribute constructor和attribute destructor即可,底层原理涉及到程序的启动和退出机制:
- 加载器阶段:操作系统将可执行文件加载到内存
- 初始化阶段:执行各种初始化工作,包括:设置全局变量、调用所有标记为constructor的函数
- main函数执行
- 清理阶段:程序结束时调用所有标记为destructor的函数
具体在哪些场景中会讨论内存对齐?有哪些内存相关的内容?
C++中内存对齐主要涉及结构体/类成员、数组、函数参数和全局变量,其核心规则是每个成员的起始地址必须是其对齐要求的整数倍,而整个结构体的大小必须是最大对齐要求的整数倍;
与内存对齐相关的工具包括编译器指令(如__attribute__((aligned(16)))、__declspec(align(16)))、C++11标准对齐关键字(alignas)、编译指示(#pragma pack)、标准库函数(std::aligned_alloc、std::align)、系统调用(POSIX的aligned_malloc、Windows的_aligned_malloc)、对齐相关的宏(alignof、offsetof、std::max_align_t)。
指针和引用的区别?
指针是存储其他变量地址的独立变量,有自己的内存空间,可以初始化为空值,可以改变指向不同变量,支持多级传递(指针的指针),使用sizeof返回指针本身大小,使用时需要&取地址和*解引用;而引用是变量的别名,没有独立内存空间,必须初始化且不能为空,一旦绑定就不能改变指向,不支持多级引用(只能有多个引用指向同一变量),使用sizeof返回原变量大小,语法更简洁无需解引用。在函数参数传递中,指针需要空指针检查,引用保证有效;在返回值语义上,指针可能返回空,引用必须返回有效值。
以下代码的含义?
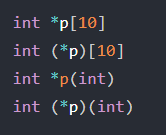
第一个是指针数组,第二个是数组指针,第三个是函数声明,第四个是函数指针。
new的底层原理?有几种new?
new的底层原理是通过调用operator new函数分配内存,然后调用构造函数初始化对象,最终返回指向新创建对象的指针;C++中有三种主要的new:普通new(如new int(10))会分配内存并构造对象,定位new(如new(ptr) int(10))在指定内存位置构造对象而不分配内存,数组new(如new int[10])分配连续内存并调用默认构造函数初始化数组元素,此外还有nothrow new(如new(std::nothrow) int)在分配失败时返回nullptr而不是抛出异常,以及自定义new通过重载operator new实现特定的内存分配策略。
被free回收的内存会立刻返还给操作系统吗?
free回收的内存不会立刻返还给操作系统,而是先归还给C运行时的内存管理器(如malloc/free库),内存管理器会将这块内存标记为可用并加入到空闲内存链表中,只有当程序的内存使用量显著减少且空闲内存块足够大时,内存管理器才会通过系统调用(如munmap或VirtualFree)将内存真正返还给操作系统。
sizeof和strlen的区别?
strlen专门针对C风格字符串(以\0结尾的字符数组),计算字符串的实际字符个数(不包括结尾的\0),是运行时计算需要遍历字符串直到遇到\0;而sizeof更泛用,适用于所有数据类型,计算数据类型或变量在内存中占用的字节数,是编译时计算在编译阶段就确定。
数组名和指针的差别?
数组名是数组首元素的地址,但它本身不是指针变量,数组名在大多数情况下会自动转换为指向首元素的指针,但数组名不能重新赋值(如arr = ptr是错误),而指针可以改变指向;sizeof对数组名返回整个数组的字节数(如int arr[10]的sizeof(arr)返回40),对指针返回指针本身的字节数(如int* ptr的sizeof(ptr)返回8);数组名不能进行指针运算(如arr++是错误),但转换为指针后可以;数组名作为函数参数时会退化为指针,失去数组的大小信息;数组名可以用&取地址(如&arr得到指向整个数组的指针),而指针的&得到指向指针的指针。
C++中结构体和类的区别?
C++中结构体和类的核心区别在于默认访问权限和默认继承权限:结构体的成员和函数默认是public访问权限,默认继承权限也是public,而类的成员和函数默认是private访问权限,默认继承权限是private。

const和constexpr的区别?
const是一个更灵活的常量修饰符,它修饰的变量或常量可以在编译时确定也可以在运行时确定,只要保证初始化即可,而constexpr是一个更严格的编译时常量修饰符,它修饰的变量或常量必须在编译时能够确定值,必须立即初始化且不能依赖运行时计算。
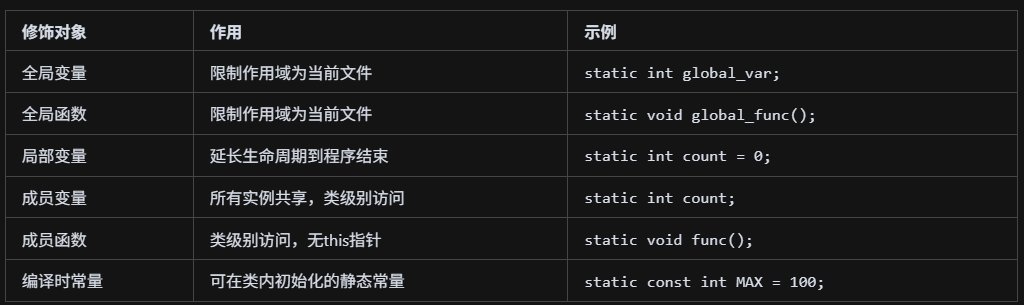
static和const的用法?
const是C++中的常量修饰符,可以修饰变量、指针、函数参数、函数返回值和类成员,修饰变量时表示该变量不可修改且必须初始化(可以是编译时或运行时初始化),修饰指针时可以分为指向常量的指针、常量指针或指向常量的常量指针,修饰成员变量时必须在构造函数初始化列表中初始化,修饰成员函数时表示该函数不会修改类的成员变量(底层原理是将this指针修饰为常量指针),修饰函数参数时表示参数在函数内部不可修改,修饰函数返回值时表示返回的指针或引用指向的内容不可修改。

static是C++中的静态修饰符,可以修饰全局变量、全局函数、局部变量和类成员,修饰全局变量或函数时限制其作用域为当前文件(其他文件不可访问),修饰局部变量时延长其生命周期到程序结束但作用域不变,修饰类成员变量时将其提升为类级别(所有实例共享一份,可通过类名直接访问,必须在类外定义),修饰类成员函数时同样提升为类级别(可通过类名调用,没有this指针,只能访问静态成员变量,不能访问非静态成员),静态成员变量在程序启动时初始化,静态成员函数常用于工具函数或单例模式实现。
什么是野指针和悬空指针?
野指针是指从未被正确初始化的指针,它指向的内存地址是随机的垃圾值,从未指向过有效内存。
悬空指针是指曾经指向有效内存,但现在指向的内存已经无效或被释放的指针。
如何理解C++中的重载、重写和隐藏?
重载是在同一个作用域中定义函数名相同但参数列表不同的函数,编译器根据传入的参数类型和数量自动选择最匹配的版本执行,是编译时确定的静态绑定;重写是基于继承关系,父类定义虚函数,子类重新实现该虚函数,通过父类指针调用子类对象时会执行子类的重写版本,实现运行时多态效果;隐藏是指子类定义了与父类同名的普通函数(非虚函数),此时父类的同名函数被隐藏,调用时根据指针类型决定执行哪个函数(父类指针调用父类函数,子类指针调用子类函数),子类的同名函数会覆盖父类的同名函数,无法通过父类指针调用子类的隐藏函数。
C++的类中有哪些默认的成员?
C++类中有6个默认成员函数:默认构造函数在类没有定义任何构造函数时自动生成,用于创建对象;拷贝构造函数在类没有定义拷贝构造函数时自动生成,用于用一个对象初始化另一个对象;移动构造函数在类没有定义任何拷贝控制函数时自动生成,用于高效地转移资源所有权;拷贝赋值运算符在类没有定义拷贝赋值运算符时自动生成,用于对象间的赋值操作;移动赋值运算符在类没有定义任何赋值运算符时自动生成,用于高效的资源转移赋值;析构函数总是会被自动生成,用于清理对象资源。
浅拷贝和深拷贝的区别?
浅拷贝只复制指针值(内存地址),不复制指针指向的内容,多个对象共享同一块内存,当一个对象修改数据时其他对象也会受影响,适用于所有类型的指针(动态内存、栈内存、全局内存等),性能好但容易导致内存管理问题(如重复释放、悬空指针);深拷贝复制指针指向的内容,为每个对象分配独立的内存空间,对象之间互不影响,内存管理安全但性能较差。
volatile,mutable和explicit的用法?

完整的多线程考虑线程安全需要哪些手段?
多线程中保证线程安全需要综合使用多种同步机制:volatile关键字只能防止编译器优化,确保每次都从内存读取最新值,但不能防止竞态条件,因此还需要互斥锁(mutex)来保护共享数据,防止多个线程同时访问和修改同一数据,原子操作(atomic)用于简单的读写操作,确保操作的原子性,读写锁(shared_mutex)允许多个线程同时读取但互斥写入,条件变量(condition_variable)用于线程间通信和同步,内存屏障(memory barrier)保证内存可见性和指令执行顺序。
C++有哪些异常处理的手段?
C++的异常处理机制主要包括try-catch语法结构和标准异常类体系:try-catch通过try块包含可能抛出异常的代码,catch块捕获并处理不同类型的异常,提供程序错误恢复和资源清理机制,确保程序健壮性;C++自带的标准异常类以std::exception为基类,分为逻辑错误类(如std::invalid_argument、std::out_of_range、std::length_error)和运行时错误类(如std::runtime_error、std::overflow_error),每种异常类都有特定的使用场景和错误描述,开发者可以根据具体错误类型选择合适的异常类抛出
C++中有哪些分配内存的手段?如果我想实现只允许在栈上分配内存的话怎么做?
C++的内存分配方式主要包括栈内存分配(自动分配和释放)、堆内存分配(手动new/delete)、静态内存分配(全局变量、静态变量)和智能指针管理(自动管理堆内存)这四种主要方式;如果要实现只允许在栈上分配内存,可以通过重载或禁用new操作符(使用= delete关键字)来阻止堆分配,或者通过将析构函数设为私有来阻止在堆上创建对象(因为堆分配的对象需要能够调用析构函数),这两种方法都能确保对象只能在栈上创建,提高内存安全性和避免内存泄漏问题。
delete释放内存的时候怎么知道具体的内存大小?
当使用new分配内存时,内存分配器会在实际分配给用户的内存块前面添加一个头部信息,这个头部记录了分配的内存大小、对齐要求等管理信息;当调用delete时,分配器会通过指针偏移计算找到这个头部信息,从中读取原始分配的内存大小,然后释放包含头部在内的整个内存块,所以用户不需要显式指定要释放的内存大小,分配器会自动管理这些信息。
分配器是什么?有什么用?
分配器(Allocator)的作用是管理内存的分配和释放,它负责在用户请求内存时分配适当大小的内存块,在内存块前面添加管理信息(如大小、对齐要求等),当用户释放内存时根据这些管理信息正确释放内存;分配器还负责内存碎片整理、内存池管理、性能优化等任务,不同的分配器可以针对不同的使用场景进行优化,比如小对象分配器、大对象分配器、线程安全分配器等,它是C++内存管理系统的核心组件,确保内存分配的高效性和安全性。
成员列表初始化和类中初始化的区别是什么?
成员列表初始化是在构造函数后面使用冒号语法直接初始化成员变量,它在对象构造时立即执行,效率更高,对于const成员、引用成员和没有默认构造函数的对象成员是必需的,初始化顺序按照成员在类中声明的顺序进行;类中初始化是在类定义中直接给成员变量赋值,它相当于在构造函数中赋值,对于有默认构造函数的成员会先调用默认构造函数再赋值,效率相对较低,但语法更简洁。
哪些情况一定要使用成员初始化列表?为什么?
const成员变量(因为const成员必须在构造时初始化且不能后续赋值)、引用成员变量(因为引用必须在声明时初始化且不能重新绑定)、没有默认构造函数的对象成员(因为无法在构造函数体内调用默认构造函数)、基类成员(因为基类必须在派生类构造前初始化)。
成员列表初始化的执行顺序是:先执行基类的构造函数,然后按照成员变量在类中声明的顺序执行成员初始化列表,最后才执行构造函数体内的代码。
什么是零拷贝?
零拷贝(Zero-Copy)是一种优化技术,指在数据传输过程中避免不必要的数据拷贝操作,直接在内存中移动数据指针或引用,而不实际复制数据内容。
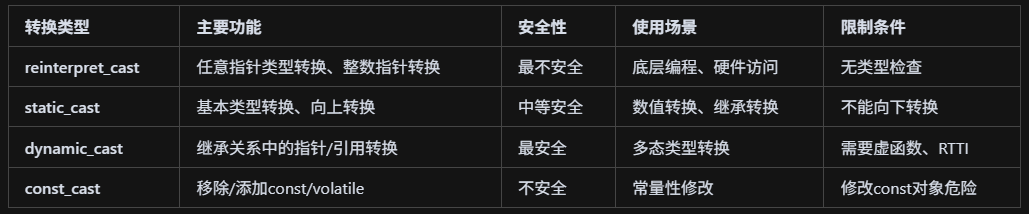
C++的四种类型转换?
reinterpret_cast是最强大的类型转换,允许任何指针类型间转换、整数和指针转换、函数指针转换等,但不进行任何安全检查,是最不安全的转换方式;static_cast支持基本类型转换、安全的向上转换(子类转父类),不进行运行时类型检查,但不能进行向下转换;dynamic_cast专门用于继承关系中的指针和引用转换,包含运行时类型检查,需要RTTI和虚函数支持,失败时指针返回nullptr、引用抛出异常;const_cast专门用于移除或添加const和volatile属性,可以修改对象的常量性,但修改const对象可能导致未定义行为。
C++调用函数入栈的过程?
C++函数入栈过程是:当函数被调用时,系统首先将返回地址(调用指令的下一条指令地址)压入栈中,然后按从右到左的顺序将函数参数压入栈中,接着将当前函数的局部变量按声明顺序压入栈中,同时保存当前函数的基址指针(EBP)并设置新的栈帧基址,最后为函数分配栈空间用于临时变量和计算,整个过程中栈指针(ESP)不断向下移动,栈帧指针(EBP)指向当前函数的栈帧基址,这样形成了完整的函数调用栈结构,确保函数执行完毕后能够正确返回到调用位置并恢复调用者的栈环境。
C++将临时变量作为返回值时的处理?
现代C++在按值返回时优先在“调用方的返回值存储位置”就地构造(RVO/强制拷贝省略,C++17对纯右值return T(...)强制生效),若返回的是命名局部变量则尝试NRVO(允许但不强制);若未能就地构造,则依次退化为移动构造、再不行才用拷贝构造,因此整体优先级就是“就地构造 > 移动 > 拷贝”,且这一过程发生在调用点的返回槽中而非先生成临时再拷贝。
引用能否动态绑定?
引用本身不能“动态绑定”:它在初始化时一次绑定,之后不能改绑;所谓“动态绑定”是指通过基类引用(或指针)调用虚函数时,调用目标在运行时依据对象的动态类型(如派生类实例)进行分派,因此你可以在初始化时用基类引用绑定一个派生对象并获得多态调用,但引用一旦绑定就固定不变。
对指针执行++操作具体到地址上来说移动几个字节?
对指针执行++时,地址前进的字节数等于其“所指向类型”的大小:对 T* p,p++ 前进 sizeof(T) 字节(如 char* 前进1、int* 常前进4、double* 前进8、S* 前进 sizeof(S),含对齐带来的填充),与指针本身占用的字节数无关;void* 与函数指针不支持指针算术,若需按字节步进请先转为 char*。
如何判断两个浮点数是否相等?
判断两个浮点数是否“相等”不应直接用==,而应做近似相等判断:先特殊处理NaN(恒不等)与±INF(仅同号同值相等),再检测 |a−b| ≤ max(eps_abs, eps_rel · max(|a|, |b|)),其中eps_abs用于接近0时的绝对误差阈值(如1e-12),eps_rel用于数值较大时的相对误差阈值(如1e-9);对极端要求可用ULP比较度量机器间隔距离。
类如何实现只能静态分配和动态分配?
C++有三种常见存储期——静态存储期(全局/静态变量,程序开始到结束)、自动存储期(俗称“栈上”,进入作用域分配、离开作用域自动销毁,发生在运行时)、动态存储期(“堆上”,用new/delete显式管理,运行时分配);要“只能在栈上/静态分配”,做法是禁用堆分配:在类内将operator new/operator new[]声明为= delete(或私有且不提供友元工厂),同时也建议删除对应的delete/delete[]重载来防误用,这样对象只能以自动或静态存储期方式创建;要“只能在堆上分配”,做法是禁止自动存储期:将析构函数设为private/protected(外部无法在作用域末尾调用析构,因而不能定义栈对象),并提供公开的工厂(返回std::unique_ptr或std::shared_ptr并内置删除器)来创建与销毁对象。
什么是工厂模式?什么是抽象工厂?
工厂模式是一种创建型设计模式,把“创建对象”的细节从调用方中抽离出来,由工厂根据参数或环境决定实例化哪种具体产品,调用方只依赖抽象接口而不直接new具体类,从而降低耦合、便于切换实现与扩展;抽象工厂是工厂模式的升级版,用于“一次性创建一组相关或相互依赖的产品族”(例如同一主题的按钮、文本框、菜单等),通过提供一套工厂接口来生成成套产品,保证产品族内部的一致性与可替换性,适合多平台/多皮肤/多配置的场景。
#include <memory>
#include <iostream>struct Shape { virtual void draw() = 0; virtual ~Shape() = default; };
struct Circle : Shape { void draw() override { std::cout << "Circle\n"; } };
struct Rect : Shape { void draw() override { std::cout << "Rect\n"; } };// 简单工厂:调用方不直接 new,交给工厂决定创建哪种产品
std::unique_ptr<Shape> makeShape(const std::string& kind) {if (kind == "circle") return std::make_unique<Circle>();if (kind == "rect") return std::make_unique<Rect>();return nullptr;
}int main() {auto s1 = makeShape("circle");auto s2 = makeShape("rect");s1->draw(); s2->draw();
}
///
///// 一组相关产品
struct Button { virtual void render() = 0; virtual ~Button() = default; };
struct Checkbox { virtual void render() = 0; virtual ~Checkbox() = default; };// Windows 系列产品
struct WinButton : Button { void render() override { std::cout << "Win Button\n"; } };
struct WinCheckbox : Checkbox { void render() override { std::cout << "Win Checkbox\n"; } };// Mac 系列产品
struct MacButton : Button { void render() override { std::cout << "Mac Button\n"; } };
struct MacCheckbox : Checkbox { void render() override { std::cout << "Mac Checkbox\n"; } };// 抽象工厂:定义“同一族”的创建接口
struct WidgetFactory {virtual std::unique_ptr<Button> createButton() = 0;virtual std::unique_ptr<Checkbox> createCheckbox() = 0;virtual ~WidgetFactory() = default;
};// 具体工厂:产出同一平台的一整套产品
struct WinFactory : WidgetFactory {std::unique_ptr<Button> createButton() override { return std::make_unique<WinButton>(); }std::unique_ptr<Checkbox> createCheckbox() override { return std::make_unique<WinCheckbox>(); }
};struct MacFactory : WidgetFactory {std::unique_ptr<Button> createButton() override { return std::make_unique<MacButton>(); }std::unique_ptr<Checkbox> createCheckbox() override { return std::make_unique<MacCheckbox>(); }
};int main() {std::unique_ptr<WidgetFactory> f = std::make_unique<WinFactory>(); // 切换成 MacFactory 即可全套替换auto btn = f->createButton();auto chk = f->createCheckbox();btn->render(); chk->render();
}简单地说,工厂模式就像“点外卖”:你告诉工厂“我要圆的/方的”,工厂在后台决定做“圆形按钮还是方形按钮”,最后把“成品”交给你,你不需要自己new具体类;抽象工厂像“点一整套套餐”:你说“我要Windows风格”或“Mac风格”,工厂就一次性给你同一风格的按钮、复选框、菜单等一整套,保证风格统一、能整体替换。一句话:工厂模式帮你“选并创建一个合适的产品”,抽象工厂帮你“选并创建一整套搭配好的产品”。
scanf/printf和cin/cout的区别是什么?
scanf/printf是C风格格式化I/O,靠格式串匹配参数,类型不安全(格式不匹配出未定义行为),默认也无内存边界检查(如%s易溢出,需用%Ns限长),但常更快;cin/cout是C++流I/O,类型安全(编译期检查、状态位错误处理)、可为自定义类型重载>>/<<,支持本地化与操纵器,默认较慢但可用ios::sync_with_stdio(false)和cin.tie(nullptr)显著提速;同时,printf在复杂格式化上更简洁,iostream语法更面向对象、可扩展。
为什么模版类放在.h文件中?
模板在编译期按“用到哪种实参就实例化哪种”规则进行实例化,编译器在每个使用模板的翻译单元里都必须“看见”模板的完整定义,只有声明不够;因此通常把模板类/函数的“声明+定义”都放在.h(或.hxx/.tpp/.inl并在.h中包含)里,让所有用到它的.cpp在编译时可见;若把定义放在某个.cpp里,其他.cpp在实例化时看不到定义会导致链接错误。
什么是条件编译?
条件编译是通过预处理指令在编译前按条件选择性地包含或排除代码的机制,常用指令有#if/#elif/#else/#endif、#ifdef/#ifndef,用于按平台、编译器、配置开关(如DEBUG)、功能特性等切换不同实现或屏蔽代码;条件由宏控制(可在代码中#define或编译命令用-D定义),典型场景包括跨平台适配、调试/日志开关、版本或功能裁剪,以及头文件保护(#ifndef/#define/#endif 形式的包含卫士);它发生在预处理阶段,不执行类型检查或语义分析,被排除的代码对本次编译“不可见”。
如何阻止一个类被实例化?
将构造函数设为private/protected(且不提供友元/工厂)可以阻止外部实例化;把类做成抽象类(至少一个纯虚函数未被该类实现)也能阻止直接实例化,只有派生类实现后才能实例化。
Debug和Release的区别?
Debug通常关闭大部分优化(O0/O1),保留完整调试符号并开启断言与运行时检查(如迭代器/越界/调试堆),因此编译快、运行慢、体积大、便于调试;Release开启高级优化(O2/O3、内联、去死代码等),剥离或最小化符号,定义NDEBUG关闭断言,一般编译慢、运行快、体积小,但更容易暴露未定义行为或竞态等隐藏问题。
如何理解静态链接和动态链接?
链接发生在编译之后、生成可执行文件之前,静态链接会把所需库的机器码拷贝进可执行文件,形成自包含二进制(部署独立、无运行时库依赖,但体积较大、更新需重链且每个程序各自一份);动态链接则在装载/运行时由动态链接器把共享库(.so/.dll)映射进进程,并把可执行文件中的未解析符号通过重定位(如PLT/GOT、导入表)绑定到库实现(可执行体积小、多个进程可共享同一库的代码页、库可独立升级,但存在运行时依赖与版本兼容风险,加载/绑定有少量开销)。
什么叫静态编译和动态编译?
“静态编译”通常指提前编译(AOT):在构建阶段把源码直接编成目标代码/机器码,运行时不再编译(典型如C/C++常规流程);“动态编译”通常指即时编译(JIT):在运行时将中间表示/字节码按需要编译并可结合运行时信息做优化(如Java、.NET、JS 引擎)。
NULL和nullptr的区别?
在C++中NULL通常是一个宏,历史上多为0或((void)0),在C++里常等同整数常量0,会参与整数方向的重载与模板推导,容易造成歧义(如在重载int与T之间更倾向选int);而nullptr是C++11引入的关键字,类型为std::nullptr_t,专门表示“空指针”,只与任意指针/指向成员指针兼容,参与重载时优先匹配指针版本,不会与整数产生混淆;nullptr可隐式转为bool为false,但不会隐式转为整型(需显式转换),可用于模板与重载消除歧义,更安全可读。
auto和decltype的区别?
auto根据“初始化表达式”的类型推断,必须有初始化;推断结果默认会丢弃顶层const与引用(除非写成auto&/const auto&/auto&&),数组和函数会退化为指针。decltype根据“表达式的形式”决定类型:对未加括号的标识符,产出其声明类型(保留const/引用)。
lambda表达式的底层原理?
C++的lambda本质是编译器为每个lambda生成一个“匿名闭包类”,捕获的外部变量按捕获方式变成该类的成员(按值拷贝、按引用存引用/指针,亦支持初始化/移动捕获),lambda体被实现为该类的operator(),调用lambda即调用这个对象的operator();无捕获lambda可隐式转换为函数指针,泛型lambda对应模板化的operator(),mutable则使operator()成为非常量成员以便修改按值捕获的副本;因此lambda与“仿函数”(重载operator()的类)在本质上等价,lambda只是更简洁的语法糖,用自动生成的仿函数类承载行为与所需环境,体内临时局部变量并不会变成成员。
trivial destructor是什么?
trivial destructor(平凡析构函数)指的是“什么都不做、且可被编译器省略调用”的析构函数:类本身没有用户自定义析构函数、无虚析构、无虚基类,且其所有基类与成员的析构函数也都为平凡;这类类型的销毁是零开销,编译器可在离开作用域、释放内存时不生成析构代码,允许像POD一样用memcpy/memmove搬移、批量释放内存而无需逐个析构,静态存储期对象也无需注册退出时回调。
什么是RAII?
RAII(Resource Acquisition Is Initialization,资源获取即初始化)是一种C++资源管理范式:在对象构造函数中获取资源(内存、文件句柄、互斥锁、网络连接等),在析构函数中自动释放资源,从而将资源的生命周期与对象作用域绑定,确保无论正常返回还是异常抛出都能确定性释放,提供异常安全与零泄漏;典型例子有std::unique_ptr/std::shared_ptr管理内存、std::lock_guard管理互斥锁、std::fstream管理文件、std::vector管理动态数组。
RAII的要点就是“构造即获得、析构即释放”,把资源的生命周期绑定到对象作用域上,从而在正常返回或异常路径下都能自动、确定性地清理资源。
STL中的hashtable是如何实现的?
STL 的 unordered_map/unordered_set 主流实现采用“开链法(拉链法)”解决冲突——先用哈希函数将键映射到某个桶(hash(key) % bucket_count),同桶内用单向链表(有的实现是内联链)串起所有哈希到该桶的节点;查找时先定位桶,再用相等谓词在线性遍历该桶链表比对键;装载因子超出 max_load_factor 会 rehash 扩桶并重新分布元素。
什么是特性萃取?
特性萃取就是在C++模板元编程中,编译期“查询类型特性并据此生成不同代码”的一组技术与工具:用它可判断类型属性(如是否整型、是否可平凡拷贝)、做类型变换(去引用/去const/衰减),并据此启用或禁用某段实现(SFINAE、std::enable_if、std::conditional、if constexpr),实现零运行期开销的按类型定制与优化。
如何释放vector的空间?
clear()只删元素不减容量;想真正归还内存,优先用“重建/交换”——v = std::vector<T>();或std::vector<T>().swap(v),两者都会让v变为空并释放原缓冲(最可靠)。
如何在共享内存上使用STL的容器?
在共享内存中直接用普通STL容器会失效,因为其内部指针与默认分配器只对单进程有效;正确做法是把容器放在共享内存区中用placement new构造,并使用“共享内存感知”的分配器与可重定位指针(如Boost.Interprocess的managed_shared_memory、allocator和offset_ptr),从而让容器的内部节点与字符串/向量元素都分配在共享内存里,同时用跨进程同步原语(interprocess_mutex/condition)保护并发;实践中最省心的是直接用Boost.Interprocess提供的容器(或std容器+其allocator重绑定),避免原生指针/默认std::string等跨进程不可用对象;若不改容器,可退而求其次用序列化在进程间搬运数据而非共享内存内原位共享。
有哪些STL容器的迭代器?

构造函数和析构函数可以抛出异常吗?
构造函数可以抛出异常,一旦抛出,对象被视为未构造成功,已完成构造的子对象与成员会按逆序自动析构,异常继续向外传播(用RAII确保不泄露资源);析构函数原则上不应抛出异常,且自C++11起析构函数默认noexcept(true),若在栈展开期间(处理另一个异常时)析构函数再抛异常会导致std::terminate,因此若必须报告错误应吞并/记录或提供显式接口返回错误,而非从析构函数抛出;只有在明确声明noexcept(false)且保证不会与栈展开相叠时,才可技术上抛出,但强烈不建议。
“异常栈展开”指抛出异常后,运行时从当前函数向调用者逐层回退调用栈,依次执行已构造对象的析构函数、释放资源,并在每层查找可匹配的catch;如果在栈展开过程中又抛出第二个异常(典型是析构函数或noexcept函数里再抛出,且未被就地捕获),两个异常“相撞”,标准规定将立即调用std::terminate终止程序,这也是为何析构函数默认noexcept(true)且不应对外抛异常的原因。
拷贝构造函数和赋值运算符重载的区别?
拷贝构造函数用于“创建新对象时用另一个同类型对象来初始化”,在对象定义的那一刻触发(如T b = a; 以值传参/返回也会用到),职责是把源对象的状态拷入正在被构造的对象;赋值运算符重载(operator=)用于“已有对象被另一个同类型对象赋值”,在对象已存在后触发(如b = a;),需要先安全处理自赋值、再释放旧资源、再拷入新状态,并返回this;二者都可默认生成(成员逐个拷贝),也都有对应的移动版本,但语义不同:拷贝构造是初始化,赋值运算是重置已有对象的内容。
模板类和模板函数的区别?
模板函数通常能从实参进行类型推导并参与重载与重载决议(模板部分有序化),但不支持偏特化(仅可全特化);模板类一般需要显式给出模板实参,不过自C++17起支持类模板实参推导(CTAD)与推导指引,在部分场景可省略实参,且模板类支持偏特化以便对不同类型定制实现。
简单地说,模板函数可以隐式调用而模板类只能显式调用。
静态函数可以定义为虚函数吗?
不可以。静态成员函数不能定义为虚函数,因为虚函数的动态绑定依赖对象的this指针(通过虚函数表按动态类型分派),而静态函数没有this也不属于任何对象实例;因此静态函数既不能virtual、也不能被override(只能发生名字隐藏),同样也不存在“纯虚静态函数”。虚函数仅适用于非静态成员函数。
非静态成员函数的虚调用流程可理解为:通过当前对象的this先取到对象内隐藏的虚表指针(vptr),再经由vptr定位虚函数表(vtable),从表中取出对应槽位的函数地址并调用;而静态成员函数没有this,也就没有vptr可用,无法进行基于vtable的动态分派,因此不能是virtual。
什么是移动构造函数?为什么需要移动构造函数?
移动构造函数是形如 T(T&&) 的构造函数,用于从右值/临时对象把资源“所有权”转移到新对象(而非复制资源),并把源对象置为“有效但未指定”的可析构状态(如置空指针),因此避免了深拷贝的昂贵成本;它广泛用于返回值优化、容器扩容/重排、以 std::move 显式转右值的场景,能显著提升性能和减少内存分配拷贝开销,通常应标注 noexcept 以便容器优先采用移动而非拷贝。
构造函数的执行顺序?
先构造“虚基类”(若有,多继承/虚继承时按声明顺序由最派生类负责),再构造“非虚基类”(按类中基类声明顺序),随后构造“成员对象”(按成员在类内的声明顺序),最后才执行构造函数体里的代码;成员初始化必须发生在函数体之前,初始化列表只是提供实参,真实顺序仍以“基类/成员的声明顺序”为准;委托构造(this(...))时会先完成被委托的那个构造函数的全部步骤再回到当前构造;在基类与成员构造完成后,虚表指针等对象布局已就绪,然后才进入你写的构造函数体。
无符号数和有符号数进行计算时会怎样?
有符号数会转变成无符号数,负数通过补码的形式转变。
extern关键字的作用?
extern用于声明具有外部链接(external linkage)的标识符,让其它源文件能引用同一个实体,本身不分配存储;对变量而言,通常在头文件写extern int g;作声明,在某个且仅一个源文件中写int g = 0;作定义(ODR:只能定义一次);注意extern int g = 42;在命名空间作用域是“带初始化的定义”,不是纯声明;函数声明默认就是extern,无需显式写;const在命名空间作用域默认内部链接,若需跨文件共享应写extern const int c;并在一个源文件定义const int c = ...;;extern不等于“必须分开声明/定义”,只是常见做法;另有extern "C"用于关闭C++名字改编以与C链接。
atomic的底层原理?
C++的std::atomic底层依赖CPU提供的原子指令(如CAS、原子加/交换、LL/SC)在硬件层面保证“不可分割”的读改写,同时配合缓存一致性协议和内存屏障/内存序(acquire/release、acq_rel、seq_cst、relaxed 等)来约束可见性与指令重排;大多数标量类型直接用硬件原子指令,超出硬件支持的大小/对齐时实现可能退化为内部加锁。
有哪些导致内存泄露的场景?
动态内存未成对释放(new/malloc后遗漏delete/free或配对错误)、指针丢失(重置/覆盖原指针或realloc失败直接覆盖导致原块无法找回)、异常或提前返回导致释放路径未执行(缺少RAII)、容器存裸指针未统一释放、shared_ptr循环引用未用weak_ptr打破、长期持有的全局/单例/缓存/内存池未清理、注册的回调/监听未注销、以及线程/句柄等广义资源未正确关闭。
如何在STL的map和unordered_map的键中使用自定义类型?
在std::map中自定义类型做键需要提供“严格弱序”的比较规则:要么为类型实现operator<,要么在map<Key, T, Compare>里传入自定义比较器(比较器需满足严格弱序,且比较为const、不可修改键);在std::unordered_map中做键需要提供“哈希+相等”规则:要么为类型提供std::hash<Key>特化并实现operator==,要么在unordered_map<Key, T, Hasher, KeyEqual>里传入自定义Hasher与KeyEqual(需满足相等则哈希相同的一致性)。
STL中的优先队列实现原理?
std::priority_queue本质是用随机访问容器(默认vector)承载的二叉堆,通过数组下标关系维护堆性质(父i,子2i+1/2i+2),比较器决定是大根堆还是小根堆(默认std::less为大根堆,std::greater可做小根堆);push是在末尾插入后上滤,pop是将堆顶与末尾交换后下滤并pop_back,topO(1)、push/popO(log n);它只是堆序而非全序,不支持就地减键,需要“删后重插”或重建;底层通常是vector,也可换满足随机访问的容器。
一次性建堆(make_heap/构造priority_queue时把一批元素建成堆)是O(N);取堆顶top是O(1);每次插入push或删除堆顶pop都要通过上滤/下滤维护堆性质,时间复杂度为O(log N)。标准priority_queue不支持就地更新键值,若要“修改某元素的优先级”,一般做法是删除后重插,整体仍按每次O(log N)计。
全特化,偏特化和普通模板?
模板“主模板”是通用版本;“偏特化”在仍保留模板参数的前提下对某些形态(如某个参数为指针、某两个类型相同等)定制实现;“全特化”则把所有模板参数都固定为具体类型,变成该类型的专属实现。匹配优先级(类模板):全特化 > 更专的偏特化 > 主模板;函数模板不支持偏特化,只能“重载或全特化”(常用重载替代偏特化)。
// 主模板
template<class T, class U>
struct Box { static constexpr const char* name() { return "primary"; } };// 偏特化:第二个参数固定为 int
template<class T>
struct Box<T, int> { static constexpr const char* name() { return "partial T,int"; } };// 偏特化:两个参数相同
template<class T>
struct Box<T, T> { static constexpr const char* name() { return "partial T,T"; } };// 全特化:T=double, U=int
template<>
struct Box<double, int> { static constexpr const char* name() { return "full double,int"; } };// 使用:优先匹配全特化/更专偏特化
static_assert(std::string_view(Box<float,char>::name()) == "primary");
static_assert(std::string_view(Box<long,int>::name()) == "partial T,int");
static_assert(std::string_view(Box<char,char>::name()) == "partial T,T");
static_assert(std::string_view(Box<double,int>::name()) == "full double,int");C++中有几种for循环?
C++严格意义上有两种“for”语法:传统for循环(for(init; cond; step))适合按索引/自定义步进与多变量控制;范围for(range-based for,for(auto … : range))用于直接遍历容器/数组/初始化列表,写法简洁,读写性取决于使用auto/auto&/const auto&。
传统for提供init/条件/步进三段式控制,便于按索引遍历、任意步长、多变量更新、需要下标的位置访问与复杂循环逻辑;范围for(for(auto … : range))语法更简洁,直接基于容器的begin/end迭代顺序遍历,默认按值(auto,拷贝)、按引用(auto&,可原地改)、按只读引用(const auto&,只读)决定是否修改元素,但不直接提供下标、步长或多变量控制,想要下标需手动计数器。
vector的元素是存在栈上还是堆上?
std::vector本体只是一个很小的头部,典型包含三样东西:指向元素区的指针、当前元素数 size、容量 capacity。元素区是“一块连续内存”,通常由分配器在堆上申请;vector内部就用那个指针指向这块堆内存,所以能做到“本体在栈/堆/静态区取决于你把 vector 放哪儿,而元素在堆上”。当需要扩容时,vector会在堆上申请更大的一块连续内存,搬移已有元素,更新指针、size、capacity。注意标准 std::vector没有小对象优化(SBO),因此元素区不会自动待在栈上;只有使用自定义分配器/容器(如 small_vector)才可能把一小段元素放到对象内部。
操作系统
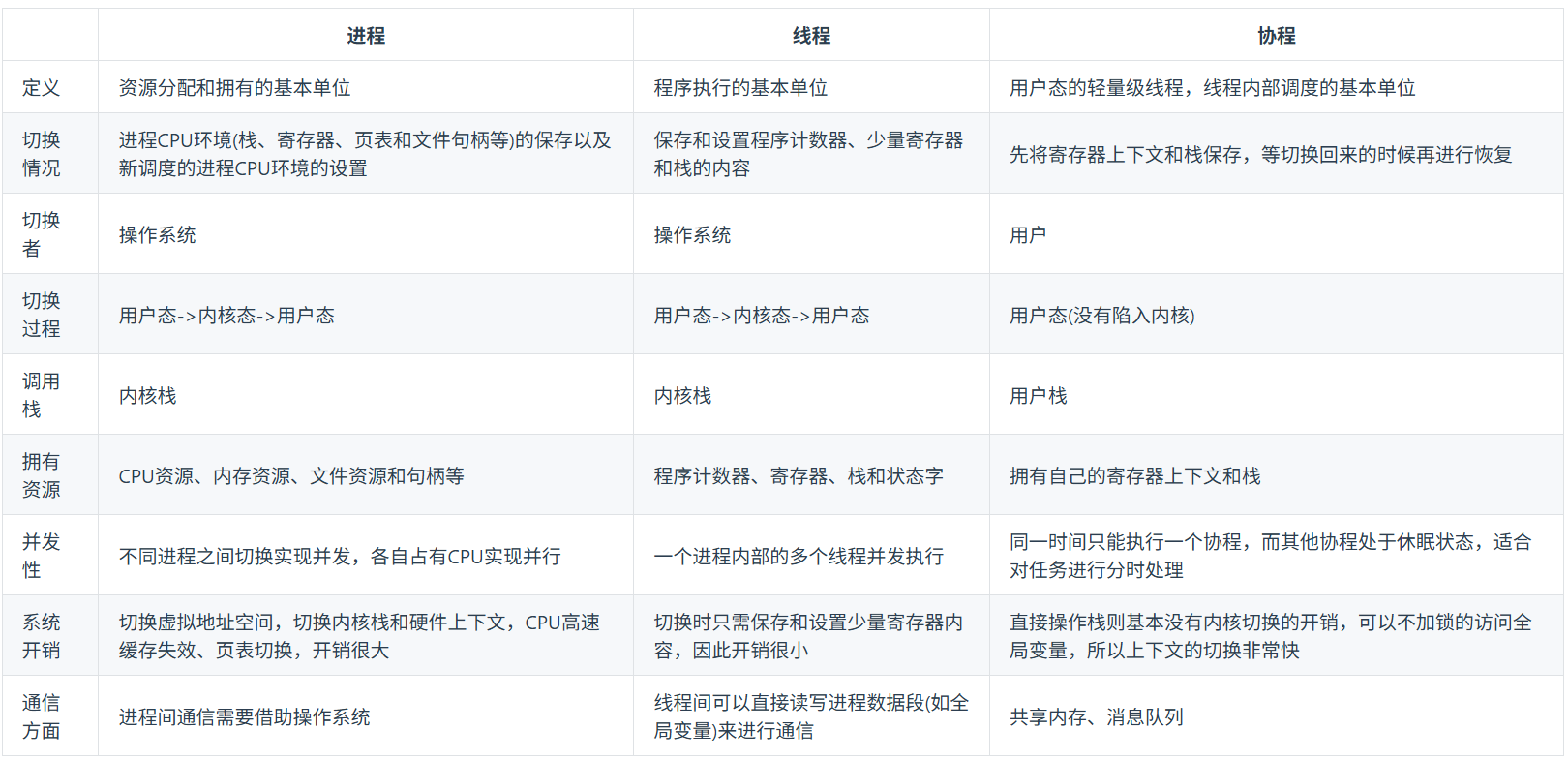
进程,线程和协程的区别?
进程是资源拥有的基本单位(独立虚拟地址空间等),线程是CPU调度的基本单位(同进程内共享地址空间),协程是用户态的协作式调度单元(不由内核抢占,需显式挂起/恢复);三者的切换开销约为:进程最大(地址空间/TLB切换)、线程次之(不换地址空间)、协程最小(用户态保存少量寄存器/栈指针);进程间通信需IPC(管道/共享内存/消息队列/socket等),线程虽共享内存但必须用同步原语避免数据竞争,协程间也可通过共享数据或通道通信,只是若调用阻塞I/O会卡住所在线程及其全部协程,需配合异步I/O或线程池;并行并非线程专属,只要有多核,进程和线程都可并行,单核下二者皆并发;协程并不“凭空提速”,主要是以极低切换成本和更简洁的同步风格组织异步流程,真正利用多核要靠多线程/多进程。
多进程和多线程相比有何区别?如何保障安全?
多进程彼此拥有独立虚拟地址空间,隔离强、崩溃互不影响,适合安全性与稳定性高的场景,但创建/切换与进程间通信(管道/共享内存/消息队列/socket)成本更高;多线程共享同一进程地址空间,通信开销小、延迟低、易并行,但易出现数据竞争、死锁与可见性问题。
多进程侧重最小权限与边界隔离(沙箱、权限降级、命名空间/容器化、严格IPC协议与输入验证、监控与故障隔离);多线程侧重正确同步和内存模型(mutex/rwlock/atomic/condvar、固定锁顺序、缩小临界区、避免伪共享与阻塞I/O、线程池限流)、启用检测工具(TSAN/ASan)与RAII确保异常路径也能释放资源。
有哪些进程间通信模式?
进程间通信(IPC)常见方式有管道(pipe/匿名,仅亲缘进程,字节流、半双工;FIFO/命名管道,任意进程、文件路径标识)、消息队列(System V msg、POSIX mqueue,按消息为单位、内核排队,便于解耦,并非“异步I/O”,而是异步消息传递)、共享内存(System V shm、POSIX shm_open+mmap,最快但需自带同步,如信号量/互斥锁/读写锁/原子)、信号(signal,轻量异步通知,携带信息极少,适合事件而非大数据)、信号量(System V sem、POSIX sem_open,计数/二值,用于跨进程同步,不等同互斥锁但可实现互斥/限流)、套接字(UNIX域socket用于同机、TCP/UDP用于跨机,最通用、支持全双工与多路复用)、内存映射文件(mmap文件,共享页+文件持久化,配合锁实现同步)、文件锁(flock/fcntl 锁,基于文件的互斥/协作)、更高层的RPC/总线(gRPC/Thrift、DBus/Windows管道等)便于跨语言与复杂协议。
快表是什么?有何作用?
“快表”指TLB(Translation Lookaside Buffer,地址变换旁路缓存),是CPU里的小型高速缓存,用来保存最近使用的虚拟页到物理页的映射以及权限信息,从而在访存时快速完成地址转换,避免每次都去多级页表“走表”,显著降低内存访问延迟;命中TLB则直接得到物理地址,未命中会触发页表遍历(硬件或软件页步行),代价更高;与之相关的机制包括进程切换时的TLB刷新或使用ASID/PCID减刷、映射变更时的TLB shootdown、多页尺寸(如HugePage)以提高覆盖率并降低miss。
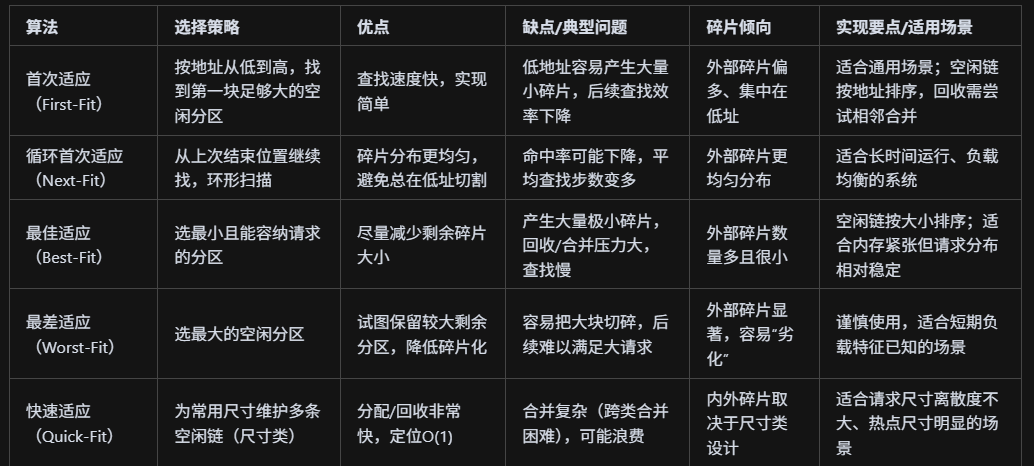
什么是动态分区分配算法?有几种?
动态分区分配算法是操作系统在可变大小的空闲内存分区中按进程需求“现场切割并分配”的策略,典型有:首次适应(First-Fit,按地址从低到高找第一块足够大的,快、易产生低址碎片)、循环首次适应(Next-Fit,从上次位置继续找,碎片更均匀但命中率可能下降)、最佳适应(Best-Fit,挑最小且能装下的分区,外碎片多、查找慢)、最差适应(Worst-Fit,挑最大的分区,试图保留大块但易退化)、快速适应(Quick-Fit,按常用尺寸维护多条空闲链,分配/回收快但合并复杂)。
什么是内存地址?
内存地址本质是一个固定位宽的“二进制无符号整数”(常见是 32 位或 64 位)。
有哪几种回收线程的方法?
等待线程结束(join)是自己不干预对方,仅阻塞等待线程自然退出并回收资源、拿到返回值;结束线程是主动让线程退出,最好用协作式信号(如中断/取消令牌)让其在安全点收尾,但仍需随后 join 才算彻底回收(强制终止风险大,不推荐);分离线程(detach/守护)则放弃后续同步与结果获取,线程结束时由系统自动回收,调用方不再等待,适合无需结果且能自清理的后台任务。
malloc的底层?
在常见的类 Unix 实现中(如 glibc 的 malloc),小块分配多通过 brk/sbrk 扩展“堆”获得,free 后不会立刻还内核,而是回到分配器的空闲结构(如 bins/tcache)以便复用;较大的分配通常用匿名 mmap 独立映射,free 时多直接 munmap 归还内核,因此不进入堆内的空闲链表但仍受分配器管理。
守护进程、僵尸进程和孤儿进程分别是什么?
守护进程是脱离终端与会话、通常由系统在后台长期运行的服务进程(无控制终端,常被 init/systemd 收养);僵尸进程是子进程已退出但父进程未调用 wait 回收,导致仅残留进程表项(状态 Z),占用 PID 且无法被直接杀死,只能让父进程 wait 或结束父进程由 init/systemd 代为回收;孤儿进程是父进程先退出、子进程还在运行的情况,子进程会被 init/systemd 收养并继续正常运行,日后退出时会被及时回收,孤儿不等于僵尸。
什么是局部性原理?
局部性原理指程序访问数据/指令时呈现“集中性”:时间局部性是指“刚被访问过的内容短期内更可能再次被访问”(如循环体内的变量、指令),空间局部性是指“与当前地址相邻的地址更可能被访问”(如顺序遍历数组)。基于此,系统用多级缓存与预取优化:缓存会保留近期访问的数据/指令(时间局部性),并按缓存行(一次抓取一小块连续内存)把目标附近的数据一起加载(空间局部性);类似思想也体现在页缓存、TLB、磁盘/文件系统缓存等层次的设计中。
有哪些终止进程的方式?
终止进程通常按“优雅到强制”的梯度进行:首选正常退出(返回 main 或调用 exit,触发清理),或发送可捕获信号如 SIGTERM、SIGINT(shell 中 kill/killall/pkill 默认发 SIGTERM,Windows 可用发送 WM_CLOSE/WM_QUIT 或 taskkill 不带 /F);需要诊断时可用 abort 触发 SIGABRT 生成 core dump;若进程卡死再用不可捕获的 SIGKILL(kill -9)或 Windows 的 TerminateProcess/taskkill /F 强制结束;此外,未捕获的致命信号(如 SIGSEGV)、内核 OOM Killer、服务管理器(如 systemd 的 stop:先 SIGTERM,超时后 SIGKILL)、容器的 docker stop(同样先 TERM 后 KILL),以及最后一个线程退出都会导致进程终止。
如何理解操作系统中的中断和异常?
中断与异常都是让CPU暂时转入内核处理的机制:中断是来自外部设备或时钟的异步事件(与当前指令无因果),用于驱动I/O与时间片调度;异常是由当前指令执行引发的同步事件(有因果),用于报告错误或提供陷入内核的通道(如系统调用)。
程序从堆中分配内存时虚拟内存有何变化?
当程序从堆分配内存时,进程的虚拟地址空间会被“扩展或新增映射”,常见有两条路径——小块多通过 brk/sbrk 把现有堆段向高地址扩展(同一个匿名可写 VMA 变大);大块多通过 mmap 新建一段匿名可写的独立 VMA。分配当下通常只是“保留/建立虚拟映射”,实际物理页不会立刻分配;等到首次访问(尤其写)时触发缺页异常,内核分配并清零物理页、建立页表,RSS 随之增加。这些映射以页为单位对齐,可能受内核 overcommit 策略影响;释放时,小块回到分配器内部复用(VMA 不变),大块往往直接 munmap 删除对应 VMA。
简言之:先保留虚拟地址,访问时再用页故障把物理页“拉”进来。
什么是抖动现象?
“抖动(thrashing)”指进程或系统的工作集超出物理内存,导致频繁缺页和页面换入换出,CPU 大量时间花在页故障处理与磁盘 I/O 上而几乎不做有效计算,系统整体吞吐骤降、响应变慢。典型成因包括物理内存不足、并发进程过多(总工作集过大)、不良访问局部性或过激的 overcommit。缓解思路:减少并发/限制内存占用、增大物理内存或减小内存需求、优化数据结构与访问局部性、合理配置 swap 与内核内存管理参数(如降低并发、调优 swappiness)、分级缓存与分块处理以匹配可用内存。
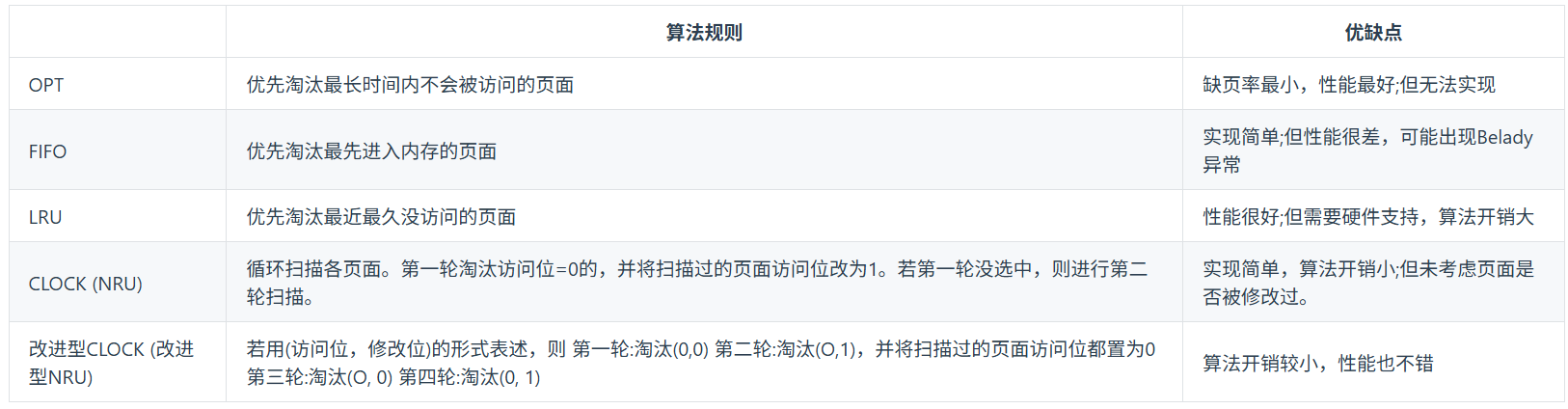
有哪些常见的页面置换算法?
什么时候用多线程什么时候用多进程?
IO 密集且需要高效共享数据:用多线程/异步;CPU 密集或需要崩溃/权限/内存隔离、热重启与限资源:用多进程(也常更能吃满多核,绕过如 Python GIL);既要并发又要稳:多进程 + 每进程少量线程。线程启动/切换轻、共享易但互相牵连;进程启动/IPC 重、内存占用高但隔离与容错强。
PCB(进程控制块)是什么?
PCB(进程控制块)是内核为每个进程维护的核心数据结构,记录进程的“身份证与全部状态”,用于创建、调度、切换、挂起/唤醒与终止等操作;PCB 通常是通过链表的⽅式进⾏组织,把具有相同状态的进程链在⼀起,组成各种队列。
有哪些类型的线程?
内核级线程(1:1)由内核直接调度,阻塞/系统调用不会拖累同进程其他线程,可充分利用多核,优点是通用与可观测性强,代价是创建/切换开销较高;用户级线程(M:1)在用户态库内调度,创建/切换极轻且可定制,但一旦线程发生阻塞(如阻塞式系统调用)会卡住整个进程,且不能在多核上真正并行;轻量级线程/混合模型(M:N,LWP 作为内核可调度实体)用若干 LWP 承载更多用户线程,实现“用户态快速调度 + 内核态真并行/阻塞脱钩”的折中,复杂度更高但能在性能与并行性之间取得平衡。
用户空间和内核空间分别是什么?是怎样的对应关系?
用户空间是普通进程运行的受限地址空间,只能执行非特权指令、访问自身映射的内存;内核空间是操作系统内核运行的特权地址空间,可访问硬件与所有物理内存并执行特权指令。对应关系上,每个进程都有独立的用户虚拟地址空间;而同一份内核地址空间通常被映射进每个进程(仅在内核态可访问),两者通过系统调用、异常或中断发生“态切换”进入内核再返回用户态。
计算机网络
一次完整的HTTP请求过程?
用户在浏览器输入 URL → 浏览器做规范化与安全策略(如 HSTS)、查本地缓存/Service Worker;若需联网,先做域名解析:浏览器/系统/路由器/运营商递归解析器的多级 DNS 缓存命中则直接用,否则客户端把查询发给本地递归解析器,由它向根→顶级域→权威 DNS 迭代查询得到 IP(常配合 CDN 返回就近节点)→ 得到 IP 后发起连接:HTTP/1.1/2 走 TCP(三次握手),HTTPS 还要先做 TLS 握手协商密钥与证书校验;HTTP/3 则直接走 QUIC(基于 UDP)完成握手与加密 → 连接建立后发送 HTTP 请求(方法、路径、头、可选体),服务器处理并返回响应(状态码、头、体,可能压缩/分块/缓存控制)→ 浏览器依据响应更新缓存、处理重定向/跨域策略,解析 HTML 继续并发获取子资源(可能复用连接:HTTP/1.1 keep-alive、HTTP/2 多路复用、HTTP/3 多路复用)→ 渲染页面。
DNS是什么?
DNS(Domain Name System)是互联网的分布式、层级化命名系统与协议集合,用于把域名解析为IP地址(A/AAAA),以及提供别名(CNAME)、邮件交换(MX)、服务发现(SRV)、文本(TXT)等记录;它不是“简单的转换关系”,而是由递归解析器与权威DNS服务器协作、依靠缓存与根/顶级/权威多级查询完成解析的系统。
简言之:DNS让人类易记的域名可被机器定位到具体服务端地址,并承担更多与命名相关的元信息发布。
什么是域名解析和区域传送?分别使用什么传输层协议?
域名解析是把域名查询成具体记录(如 A/AAAA/CNAME 等)的过程,通常由递归解析器向权威 DNS 按层级查询并结合缓存返回结果;区域传送是权威 DNS 服务器之间为同一域名区域(zone)同步权威数据的机制,包括全量 AXFR 与增量 IXFR,依 SOA 序列号进行更新一致性维护。
域名解析请求体积小、数量巨大、追求低时延与高并发,因此默认用 UDP/53(必要时报文过大或需可靠性再回退 TCP/53,或使用 DoT/DoH 加密);区域传送数据量大、需可靠有序与完整校验,并常配 ACL/TSIG 做访问控制,所以规定使用 TCP/53,便于长连接与可靠传输。
什么是粘包/拆包?如何解决?
TCP是“有序字节流”而非消息协议,发送方多次write的数据在接收方可能一次recv合并(粘包),一条大消息也可能被多次recv拆开(拆包);这源于TCP不保留消息边界,内核会按MSS、拥塞/滑动窗口、缓冲区、Nagle/延迟ACK等策略对数据分段或合并,但对应用层只呈现连续字节序列。
在应用层自定义“消息边界”,常见做法有固定长度帧、分隔符帧(需转义/限定内容)、长度前缀帧(先发长度再发负载,最通用),并在接收端用缓冲循环解析(累积、判断是否够一帧、够则切出处理,否则继续收);可按需关闭Nagle或调缓冲以优化时延,但根本办法始终是设计明确的帧协议(如HTTP的Content-Length/Chunked、WebSocket帧、gRPC长度前缀)。
HTTP报文的种类?结构?
HTTP 报文分为请求报文与响应报文,二者结构相同的核心框架是“起始行 + 首部字段 + 空行 + 可选消息体”。请求报文的起始行为“方法 请求目标 版本”(如“GET /path HTTP/1.1”);响应报文的起始行为“版本 状态码 原因短语”(如“HTTP/1.1 200 OK”)。首部是多行“Key: Value”(如 Host、Content-Type、Content-Length、Cookie/Set-Cookie、Cache-Control 等),空行后为可选的消息体(文本/JSON/二进制等),实体长度通过 Content-Length 或分块传输(Transfer-Encoding: chunked)指示。
什么是SSL/TLS?
客户端发 ClientHello;服务器回 ServerHello + 服务器证书(内含服务器的 RSA 公钥),客户端用内置 CA 公钥验签证书并校验域名/有效期;客户端本地生成“预主密钥”(Pre-Master Secret,里含协议版本以防降级),用服务器 RSA 公钥加密后通过 ClientKeyExchange 发送给服务器;服务器用自己的 RSA 私钥解密得到预主密钥;双方再结合握手中的随机数(ClientRandom、ServerRandom)通过 KDF 推导出主密钥与会话对称密钥;随后交换 ChangeCipherSpec 与 Finished 完成握手,之后应用数据用对称加密保护。
什么是Cookie和Session?有何作用?
HTTP 无状态,常用 Cookie + Session 维持会话。Session 存在服务端,保存用户状态;浏览器仅保存一个高熵的 session_id 在 Cookie 里,每次请求自动带上,服务端据此取回会话。
Cookie 是“客户端载体/通道”,尽量只放 session_id,配合 HttpOnly、Secure、SameSite;Session 是“服务端状态”,需做过期清理与分布式共享(如放 Redis)。替代方案有无状态 Token(如 JWT),减轻服务端存储但撤销困难。
ARP协议的内容?
在同一子网内,源主机要向某个目标IP发包时先查本机ARP缓存,未命中就广播“Who has 目标IP? tell 源IP”,只有把该IP配置在网卡上的目标主机会单播回复其MAC,源主机据此把以太网帧直接发往目标MAC;若目标不在本子网,源主机不会解析目标IP的MAC,而是先解析默认网关的MAC(同样通过ARP广播获得),把数据包交给网关,由网关在下一跳所连接的子网内继续为目标IP做ARP并转发,直至到达目标。
DDos攻击和SYN泛洪攻击是一回事吗?
DDoS 是指“分布式拒绝服务”的攻防范畴,特点是由大量分布在各处的攻击源同时向目标施压,方式多样(带宽耗尽、连接耗尽、应用层耗尽等);SYN 泛洪是其中一种具体技术,利用 TCP 三次握手只发 SYN 不完成握手,迫使服务端为海量半连接(SYN-RECV)分配状态与重传计时,耗尽 backlog/内存/CPU,导致正常连接受阻。简言之:DDoS讲“多源与目标被拒绝”的大框架,SYN 泛洪是实现 DDoS/DoS 的一类“连接耗尽”手段。
为什么TCP需要第三次握手?
三次握手是为“双方都确认对方能收发、并完成双方初始序号同步”。具体来说,第一次(SYN)客户端证明“我能发给你”,第二次(SYN+ACK)服务器证明“我能收到你且你也能收到我吗?并告诉你我的初始序号”,第三次(ACK)客户端确认“我确实收到了你的SYN+ACK,序号同步完成”。若只有两次,服务器无法确定客户端是否收到自己的SYN+ACK,可能因旧的/重传的SYN导致服务器进入已建立而客户端并未建立,产生半开连接与资源浪费;第三次ACK消除了这种不一致与“脏旧报文”的隐患,确保连接状态一致且可靠。
对称密钥加密和非对称密钥加密的优缺点?
对称加密用同一把密钥加解密,优点是实现简单、速度快,适合大数据量传输;缺点是密钥分发与管理困难,一旦密钥被截获等同明文泄露。非对称加密用公钥/私钥对,能解决密钥分发并支持数字签名与身份认证,但计算开销大、吞吐低,并依赖证书/PKI 来确保公钥可信。
TCP流量控制和拥塞避免的内容?
流量控制由接收方在 ACK 中通告接收窗口 rwnd,限制发送方别把接收端“撑爆”;拥塞控制用发送端的拥塞窗口 cwnd 适应网络容量避免“挤爆”链路,典型过程为慢启动(cwnd 指数增长至阈值 ssthresh)→ 拥塞避免(线性增长)→ 出现三重重复 ACK 触发快速重传+快速恢复(ssthresh=½cwnd,cwnd 调整并温和探测),实际可发送窗口为 min(rwnd, cwnd),启用 SACK 可更精确恢复丢包。
TCP有哪些重传的方式?
超时重传(RTO)在定时器到期仍未获确认时重发最早未确认段,视为严重拥塞并大幅回退窗口;快速重传在收到≥3 个重复 ACK 时立即重传缺失段,不等超时,并配合快速恢复温和收缩窗口;启用 SACK 时进行基于选择确认的精细化重传,现代实现还常配合 RACK/TLP 等机制加速检测与补救。
使用socket建立完整的TCP网络架构是如何实现的?
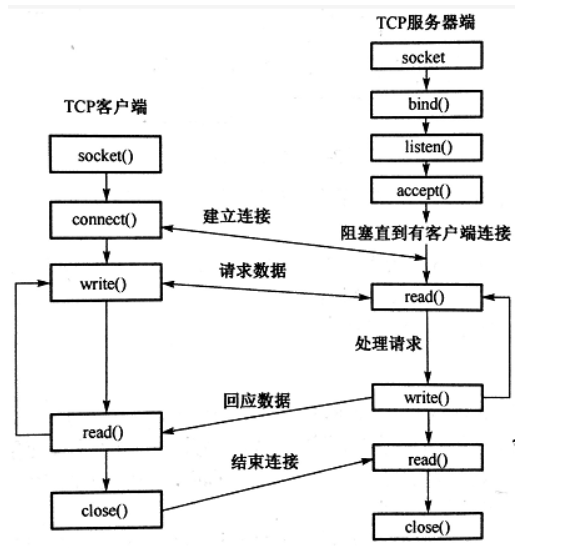
服务端创建 socket 并设置协议族/类型,bind 本地 IP:端口后 listen 等待连接;客户端创建 socket 调用 connect 发起连接,请求与服务端完成三次握手;服务端 accept 返回已连接 socket,随后双方在该连接上用 send/recv(或 write/read)收发数据;需要断开时通常由一方先发起关闭,双方通过四次挥手完成连接终止(可支持半关闭);整体上,socket 是操作系统提供的网络通信端点与编程接口,内核为其维护状态与收发缓冲。
常见的HTTP状态码?
- 1xx 信息类:100 Continue(继续发送主体)、101 Switching Protocols(切协议)。用于握手/升级流程观察。
- 2xx 成功类:200 OK(常规成功)、201 Created(资源已创建)、204 No Content(无实体成功)。确认业务正确与幂等性。
- 3xx 重定向类:301/308 永久重定向、302/307 临时重定向、303 See Other、304 Not Modified(缓存命中)。诊断看 Location、缓存条件/协商头。
- 4xx 客户端错误:400 Bad Request(请求格式/参数错误)、401 Unauthorized(缺少/错误认证,查 WWW-Authenticate)、403 Forbidden(权限/策略阻断)、404 Not Found(路由/资源不存在)、405 方法不被允许、408 超时、409 冲突、410 Gone(永久移除)、413/414/415 负载/URI/媒体类型问题、429 限流(关注重试)、451 法律限制。重点核对请求、鉴权、限流与规范。
- 5xx 服务端错误:500 内部错误、501 未实现、502 网关错误、503 服务不可用(可配 Retry-After)、504 网关超时。优先查后端故障、依赖超时、容量与熔断。