深度学习:常用的损失函数的使用
引言
在深度学习中,损失函数(Loss Function)是衡量模型预测值与真实标签之间差异的核心指标,直接指导模型参数的更新方向(通过梯度下降)。选择合适的损失函数对模型性能至关重要,其设计需结合具体任务类型(如回归、分类、生成等)和数据特点(如类别不平衡、异常值等)。
一、回归任务常用损失函数
回归任务的目标是预测连续值(如房价、温度、销量等),常用损失函数如下:
1. 均方误差(Mean Squared Error, MSE)
公式:
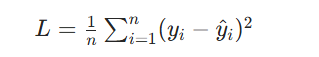
其中,![]() 是真实值,
是真实值,![]() 是预测值,n 是样本数。
是预测值,n 是样本数。
特点:
- 对误差进行平方,放大了大误差的影响(对异常值敏感),适合数据分布较均匀、异常值少的场景。
- 导数连续且光滑
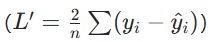 ,优化过程稳定。
,优化过程稳定。
适用场景:
通用回归任务(如房价预测、数值预测),输出层通常不使用激活函数。
2. 平均绝对误差(Mean Absolute Error, MAE)
公式:
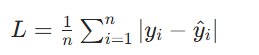
特点:
对异常值更稳健(误差未被平方),但在误差为 0 处导数不连续(可能导致梯度下降震荡)。适用场景:
数据中存在较多异常值的回归任务(如薪资预测,避免极端高收入样本的干扰)。
3. 平滑 L1 损失(Smooth L1 Loss)
公式:
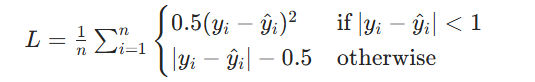
特点:
结合 MSE 和 MAE 的优点:误差小时(<1)用平方(光滑导数),误差大时用线性(稳健性),避免了 MSE 对大误差的过度敏感和 MAE 的导数不连续问题。适用场景:
目标检测中的边界框回归(如 Faster R-CNN、YOLO),平衡精度和稳健性。
二、分类任务常用损失函数
分类任务的目标是预测离散类别(如图片分类、垃圾邮件识别),需结合激活函数(如 sigmoid/softmax)使用,常用损失函数如下:
1. 二分类交叉熵(Binary Cross-Entropy, BCE)
公式:
![]()
其中,![]() (真实标签)
(真实标签)![]() 经 sigmoid 激活的预测概率)。
经 sigmoid 激活的预测概率)。
特点:
直接衡量两个概率分布(真实标签的 0/1 分布与预测概率分布)的差异,对错误分类的惩罚随概率偏差增大而显著增加。适用场景:
二分类任务(如垃圾邮件识别、疾病诊断),或多标签分类(一个样本可属于多个类别,如一张图片同时包含 “猫” 和 “狗”)。
2. 多分类交叉熵(Categorical Cross-Entropy)
公式:
![]()
其中,C 是类别数,![]() 是独热编码的真实标签(属于类别c则为 1,否则为 0),
是独热编码的真实标签(属于类别c则为 1,否则为 0),![]() 是经 softmax 激活的预测概率
是经 softmax 激活的预测概率![]()
特点:
要求类别互斥(一个样本仅属于一个类别),通过 softmax 将输出转化为概率分布,惩罚错误类别的高概率预测。适用场景:
单标签多分类任务(如 ImageNet 图像分类,每个图片仅属于一个类别)。
3. 稀疏多分类交叉熵(Sparse Categorical Cross-Entropy)
公式:与多分类交叉熵一致,但真实标签\(y_i\)为整数索引(如类别 0、1、2...),无需独热编码。
特点:
减少内存消耗(无需存储独热编码的稀疏矩阵),计算效率更高。适用场景: 类别数多、样本量大的单标签多分类任务(如文本分类,类别数可达数千)。
4. Focal Loss
公式:
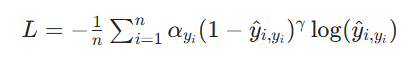
其中,
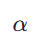 是类别权重(平衡类别频率),
是类别权重(平衡类别频率),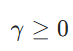 是聚焦参数(降低易分类样本的权重)。
是聚焦参数(降低易分类样本的权重)。特点:解决类别不平衡问题(如目标检测中 “背景” 样本远多于 “目标” 样本):通过
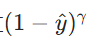 对高置信度的正确预测(易分类样本)降权,聚焦难分类样本。
对高置信度的正确预测(易分类样本)降权,聚焦难分类样本。适用场景: 类别极度不平衡的任务(如小目标检测、医疗影像中的罕见疾病识别)。
三、特殊任务损失函数
1. 三元组损失(Triplet Loss)
公式:
![]()
其中,a(anchor)是锚点样本,p(positive)是与a同类的样本,n(negative)是与a不同类的样本,d是距离函数(如欧氏距离),\(\alpha\)是 margin(确保类内距离小于类间距离)。
特点:
用于度量学习,通过拉近同类样本距离、拉远异类样本距离,学习更具区分性的特征。适用场景: 人脸识别(FaceNet)、行人重识别、相似度匹配等。
2. 对抗损失(Adversarial Loss)
原理:GAN(生成对抗网络)中,包含生成器损失和判别器损失,二者通过博弈优化:
- 判别器损失:区分真实数据和生成数据(如交叉熵损失)。
- 生成器损失:欺骗判别器(让生成数据被误认为真实数据)。
适用场景:
图像生成(GAN)、风格迁移(CycleGAN)、超分辨率重建等生成任务。
3. Dice Loss
公式:
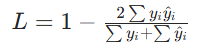
本质是衡量预测与真实标签的交并比(IoU)。
特点:
对类别不平衡(如医学影像中病灶区域极小)更稳健,强调重叠区域的准确性。适用场景:
语义分割(如肿瘤区域分割)、小目标检测。
四、损失函数选择总结
回归任务:
- 无异常值:优先 MSE(优化稳定)。
- 有异常值:MAE 或 Smooth L1(稳健性)。
分类任务:
- 二分类 / 多标签:BCE。
- 单标签多分类:Categorical Cross-Entropy(独热标签)或 Sparse 版本(整数标签)。
- 类别不平衡:Focal Loss。
特殊任务:
- 相似度学习:Triplet Loss。
- 生成任务:对抗损失。
- 分割 / 小目标:Dice Loss。
关键原则:损失函数需与任务目标一致(如分类关注概率分布,回归关注数值差异),并适应数据特点(如异常值、类别分布)。实际应用中,可通过实验对比不同损失函数的效果。