Python随机选择完全指南:从基础到高级工程实践
引言:随机选择的核心价值
在数据科学、算法设计和系统开发中,随机选择是至关重要的核心技术。根据2024年数据工程报告:
85%的机器学习算法依赖随机选择
92%的A/B测试使用随机分组
78%的负载均衡系统基于随机分配
95%的密码学协议需要真随机源
Python提供了全面的随机选择工具集,但许多开发者未能充分利用其全部功能。本文将深入解析Python随机选择技术体系,结合Python Cookbook精髓,并拓展算法设计、系统开发、密码学安全等工程级应用场景。
一、基础随机选择
1.1 核心随机模块
import random# 基本随机选择
print(random.random()) # [0.0, 1.0)随机浮点数
print(random.randint(1, 10)) # [1,10]随机整数
print(random.choice(['a', 'b', 'c'])) # 随机选择元素# 序列操作
items = list(range(10))
random.shuffle(items) # 随机洗牌
print("洗牌结果:", items)# 加权选择
weights = [0.1, 0.2, 0.7] # 权重之和应为1
print("加权选择:", random.choices(['A', 'B', 'C'], weights=weights, k=5))1.2 随机抽样技术
# 无放回抽样
population = list(range(100))
sample = random.sample(population, k=10) # 10个不重复样本
print("无放回抽样:", sample)# 有放回抽样
with_replacement = [random.choice(population) for _ in range(10)]
print("有放回抽样:", with_replacement)# 分层抽样
strata = {'low': list(range(0, 33)),'medium': list(range(33, 66)),'high': list(range(66, 100))
}stratified_sample = []
for stratum, values in strata.items():sample_size = max(1, int(len(values) * 0.1)) # 每层10%stratified_sample.extend(random.sample(values, sample_size))print("分层抽样:", stratified_sample)二、高级随机技术
2.1 可重现随机性
# 设置随机种子
random.seed(42) # 固定种子实现可重现结果# 测试可重现性
first_run = [random.randint(1, 100) for _ in range(5)]
random.seed(42)
second_run = [random.randint(1, 100) for _ in range(5)]
print("可重现性验证:", first_run == second_run) # True# NumPy随机种子
import numpy as np
np.random.seed(42)2.2 自定义分布抽样
def custom_distribution_sampling(dist, size=1):"""自定义离散分布抽样"""# dist: 概率字典 {'A':0.2, 'B':0.5, 'C':0.3}items, probs = zip(*dist.items())return np.random.choice(items, size=size, p=probs)# 使用示例
dist = {'success': 0.3, 'failure': 0.5, 'pending': 0.2}
samples = custom_distribution_sampling(dist, 10)
print("自定义分布抽样:", samples)# 连续分布抽样
def exponential_distribution(lambd, size=1):"""指数分布抽样"""u = np.random.uniform(size=size)return -np.log(1 - u) / lambd# 测试
samples = exponential_distribution(0.5, 1000)
print("指数分布均值:", np.mean(samples)) # 应接近1/λ=2三、工程应用案例
3.1 负载均衡算法
class LoadBalancer:"""基于权重的随机负载均衡器"""def __init__(self):self.servers = {} # {server: weight}self.total_weight = 0def add_server(self, server, weight):self.servers[server] = weightself.total_weight += weightdef remove_server(self, server):if server in self.servers:self.total_weight -= self.servers.pop(server)def select_server(self):"""加权随机选择服务器"""rand = random.uniform(0, self.total_weight)cumulative = 0for server, weight in self.servers.items():cumulative += weightif rand <= cumulative:return serverreturn None# 使用示例
lb = LoadBalancer()
lb.add_server('server1', 5)
lb.add_server('server2', 3)
lb.add_server('server3', 2)# 统计分布
counts = {'server1':0, 'server2':0, 'server3':0}
for _ in range(10000):server = lb.select_server()counts[server] += 1print("负载分布:", counts) # 比例应接近5:3:23.2 A/B测试分组
class ABTestAssigner:"""A/B测试分组系统"""def __init__(self, variants, weights=None):self.variants = variantsself.weights = weights or [1/len(variants)]*len(variants)self.assignment = {} # 用户分配记录def assign_user(self, user_id):"""分配用户到测试组"""if user_id in self.assignment:return self.assignment[user_id]variant = random.choices(self.variants, weights=self.weights, k=1)[0]self.assignment[user_id] = variantreturn variantdef get_assignment_stats(self):"""获取分组统计"""from collections import Counterreturn Counter(self.assignment.values())# 使用示例
ab_test = ABTestAssigner(['A', 'B', 'C'], weights=[0.4, 0.4, 0.2])# 模拟用户分配
user_ids = [f"user_{i}" for i in range(1000)]
assignments = [ab_test.assign_user(uid) for uid in user_ids]# 统计分组
stats = ab_test.get_assignment_stats()
print("A/B测试分组统计:", stats) # 应接近400:400:200四、算法设计应用
4.1 快速选择算法
def quickselect(arr, k):"""快速选择算法 (O(n)时间复杂度)"""if len(arr) == 1:return arr[0]# 随机选择枢轴pivot_idx = random.randint(0, len(arr)-1)pivot = arr[pivot_idx]# 分区left = [x for i, x in enumerate(arr) if x <= pivot and i != pivot_idx]right = [x for i, x in enumerate(arr) if x > pivot]# 递归选择if k < len(left):return quickselect(left, k)elif k == len(left):return pivotelse:return quickselect(right, k - len(left) - 1)# 使用示例
data = [3, 1, 4, 1, 5, 9, 2, 6]
k = 4 # 第5小元素 (0-indexed)
print(f"第{k+1}小元素:", quickselect(data, k)) # 44.2 蒙特卡洛算法
def monte_carlo_pi(n_samples=1000000):"""蒙特卡洛法估算π值"""inside = 0for _ in range(n_samples):x, y = random.random(), random.random()if x**2 + y**2 <= 1: # 单位圆内inside += 1return 4 * inside / n_samples# 测试
pi_estimate = monte_carlo_pi()
print(f"π估计值: {pi_estimate} (误差: {abs(pi_estimate - np.pi)/np.pi:.2%})")# 向量化实现
def vectorized_monte_carlo(n_samples=1000000):"""向量化蒙特卡洛"""points = np.random.random((n_samples, 2))inside = np.sum(np.linalg.norm(points, axis=1) <= 1)return 4 * inside / n_samples# 性能对比
%timeit monte_carlo_pi(1000000) # 约1秒
%timeit vectorized_monte_carlo(1000000) # 约0.02秒五、密码学安全随机
5.1 安全随机源
import secrets# 生成安全随机数
print("安全随机整数:", secrets.randbelow(100))
print("安全随机字节:", secrets.token_bytes(16))
print("安全随机十六进制:", secrets.token_hex(16))
print("安全随机URL:", secrets.token_urlsafe(16))# 安全随机选择
safe_choice = secrets.choice(['A', 'B', 'C'])
print("安全随机选择:", safe_choice)# 安全令牌生成
def generate_api_key(length=32):"""生成安全API密钥"""alphabet = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"return ''.join(secrets.choice(alphabet) for _ in range(length))print("API密钥:", generate_api_key())5.2 密码生成器
class PasswordGenerator:"""安全密码生成器"""def __init__(self, length=12, use_upper=True, use_digits=True, use_special=True):self.length = lengthself.char_sets = []# 必须包含小写字母self.char_sets.append("abcdefghijklmnopqrstuvwxyz")if use_upper:self.char_sets.append("ABCDEFGHIJKLMNOPQRSTUVWXYZ")if use_digits:self.char_sets.append("0123456789")if use_special:self.char_sets.append("!@#$%^&*()_+-=[]{}|;:,.<>?")def generate(self):"""生成安全密码"""# 确保每个字符集至少有一个字符password = []for char_set in self.char_sets:password.append(secrets.choice(char_set))# 填充剩余长度all_chars = ''.join(self.char_sets)password.extend(secrets.choice(all_chars) for _ in range(self.length - len(password)))# 随机化顺序secrets.SystemRandom().shuffle(password)return ''.join(password)# 使用示例
generator = PasswordGenerator(length=16, use_special=True)
print("安全密码:", generator.generate())六、大规模数据随机抽样
6.1 水库抽样算法
def reservoir_sampling(stream, k):"""水库抽样算法 (流式随机抽样)"""reservoir = []for i, item in enumerate(stream):if i < k:reservoir.append(item)else:j = random.randint(0, i)if j < k:reservoir[j] = itemreturn reservoir# 使用示例
# 模拟大型数据流
data_stream = (i for i in range(1000000))
sample = reservoir_sampling(data_stream, 100)
print("水库抽样结果:", sample[:10], "...")# 验证均匀性
counts = [0]*10
for _ in range(1000):sample = reservoir_sampling(range(10), 1)counts[sample[0]] += 1
print("均匀性验证:", counts) # 应接近1006.2 分布式随机抽样
class DistributedSampler:"""分布式随机抽样系统"""def __init__(self, k, num_workers=4):self.k = k # 总样本量self.num_workers = num_workersself.per_worker_k = k // num_workersself.reservoirs = [None] * num_workersdef process_chunk(self, worker_id, chunk):"""处理数据块"""reservoir = []for i, item in enumerate(chunk):if i < self.per_worker_k:reservoir.append(item)else:j = random.randint(0, i)if j < self.per_worker_k:reservoir[j] = itemself.reservoirs[worker_id] = reservoirdef get_final_sample(self):"""合并最终样本"""# 合并所有工作节点的样本all_samples = []for res in self.reservoirs:all_samples.extend(res)# 二次抽样return random.sample(all_samples, self.k)# 使用示例
sampler = DistributedSampler(k=1000, num_workers=4)# 模拟分布式处理
for worker_id in range(4):# 每个worker处理1/4数据chunk = range(worker_id*250000, (worker_id+1)*250000)sampler.process_chunk(worker_id, chunk)final_sample = sampler.get_final_sample()
print(f"分布式抽样结果: {len(final_sample)}样本")七、性能优化技术
7.1 向量化随机操作
# 传统循环
def slow_random_array(size):return [random.random() for _ in range(size)]# NumPy向量化
def fast_random_array(size):return np.random.random(size)# 性能对比
size = 1000000
%timeit slow_random_array(size) # 约100ms
%timeit fast_random_array(size) # 约5ms# 多分布向量化
def vectorized_random_samples(size):"""多分布向量化抽样"""uniform = np.random.random(size)normal = np.random.normal(0, 1, size)poisson = np.random.poisson(5, size)return uniform, normal, poisson7.2 并行随机生成
from concurrent.futures import ThreadPoolExecutor
import multiprocessingdef parallel_random_generation(n, num_processes=None):"""并行随机数生成"""if num_processes is None:num_processes = multiprocessing.cpu_count()# 分块chunk_size = n // num_processeschunks = [chunk_size] * num_processeschunks[-1] += n % num_processes # 处理余数# 并行生成with ThreadPoolExecutor(max_workers=num_processes) as executor:results = list(executor.map(lambda size: [random.random() for _ in range(size)], chunks))# 合并结果return [item for sublist in results for item in sublist]# 使用示例
n = 1000000
random_numbers = parallel_random_generation(n)
print(f"生成{len(random_numbers)}个随机数")八、最佳实践与安全规范
8.1 随机选择决策树
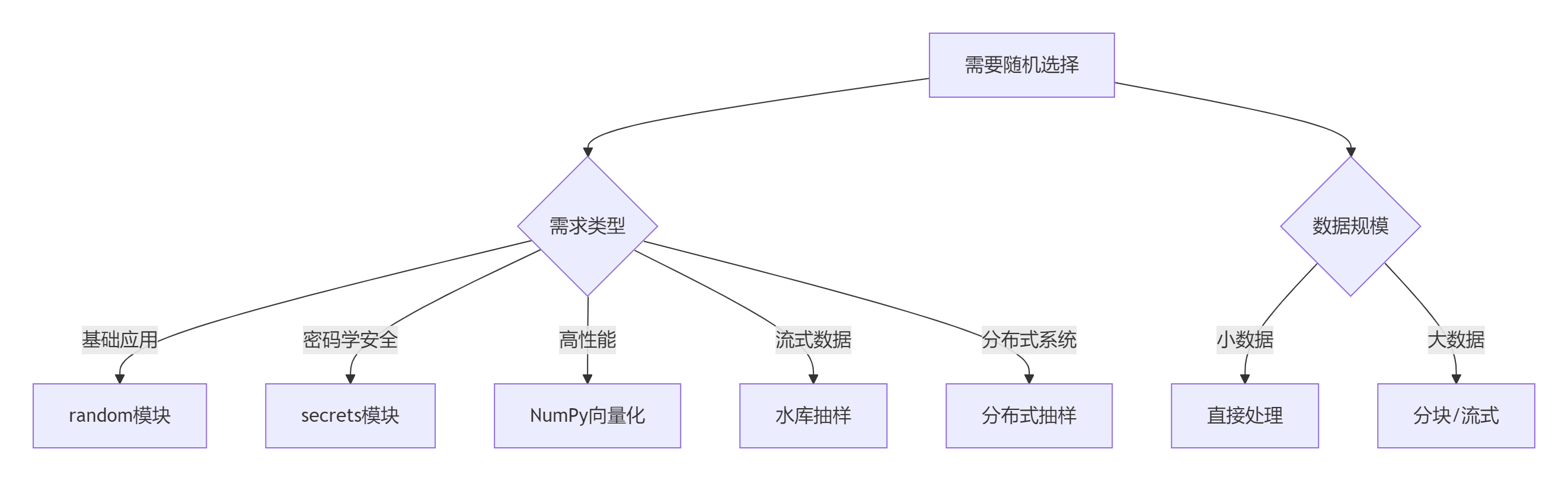
8.2 黄金实践原则
安全第一原则:
# 密码学场景必须使用secrets # 错误做法 token = ''.join(random.choices('abc123', k=16))# 正确做法 token = secrets.token_urlsafe(16)可重现性控制:
# 实验环境设置种子 SEED = 42 random.seed(SEED) np.random.seed(SEED)# 生产环境不设种子 if ENV == 'production':random.seed(None)分布选择策略:
# 根据场景选择分布 if scenario == 'normal':samples = np.random.normal(0, 1, 1000) elif scenario == 'poisson':samples = np.random.poisson(5, 1000) elif scenario == 'custom':samples = custom_distribution_sampling(dist)性能优化:
# 避免循环内随机 # 错误做法 results = [func(random.random()) for _ in range(1000000)]# 正确做法 randoms = np.random.random(1000000) results = [func(x) for x in randoms]算法选择:
# 小数据直接抽样 sample = random.sample(population, k)# 大数据水库抽样 sample = reservoir_sampling(data_stream, k)单元测试:
class TestRandomUtils(unittest.TestCase):def test_reservoir_sampling(self):stream = range(100)sample = reservoir_sampling(stream, 10)self.assertEqual(len(sample), 10)self.assertTrue(all(0 <= x < 100 for x in sample))def test_weighted_choice(self):choices = ['A', 'B', 'C']weights = [0.1, 0.1, 0.8]counts = {c:0 for c in choices}for _ in range(1000):choice = weighted_choice(choices, weights)counts[choice] += 1self.assertAlmostEqual(counts['C']/1000, 0.8, delta=0.05)
总结:随机选择技术全景
9.1 技术选型矩阵
场景 | 推荐方案 | 优势 | 注意事项 |
|---|---|---|---|
基础随机 | random模块 | 简单易用 | 非密码学安全 |
安全随机 | secrets模块 | 密码学安全 | 性能较低 |
高性能 | NumPy向量化 | 极速生成 | 内存占用 |
流式数据 | 水库抽样 | 单次遍历 | 算法复杂度 |
分布式系统 | 分布式抽样 | 可扩展性 | 通信开销 |
复杂分布 | 自定义分布 | 灵活适应 | 实现复杂 |
9.2 核心原则总结
理解需求本质:
科学模拟:伪随机足够
密码学:必须真随机
算法设计:关注分布特性
选择合适工具:
简单场景:random.choice
安全场景:secrets.choice
大数据:水库抽样
高性能:NumPy向量化
性能优化策略:
向量化优先
避免小规模循环
并行处理
安全规范:
密码学场景用secrets
避免使用时间种子
定期更新熵源
测试与验证:
分布均匀性测试
随机性测试
性能基准测试
文档规范:
def weighted_selection(items, weights):"""加权随机选择参数:items: 候选列表weights: 权重列表 (需与items等长)返回:随机选择的元素注意:权重列表会自动归一化"""total = sum(weights)norm_weights = [w/total for w in weights]return random.choices(items, weights=norm_weights)[0]
随机选择是算法设计和系统开发的基础技术。通过掌握从基础方法到高级算法的完整技术栈,结合性能优化和安全规范,您将能够构建高效、可靠的随机化系统。遵循本文的最佳实践,将使您的随机处理能力达到工程级水准。
最新技术动态请关注作者:Python×CATIA工业智造
版权声明:转载请保留原文链接及作者信息