【GPT入门】第60课 openCompose实践图文介绍指南
【GPT入门】第60课 openCompase实践图文介绍指南
- 概述
- 1.生成式大模型的评估指标
- 1.1 核心评估指标
- 1.2 支持的开源评估数据集及使用差异
- 1.3 数据集区别与选择
- 二、opencompass 安装与使用
- 2.1 安装
- 2.2 准备数据
- 2.3 部署模型
- 2.3 运行命令
- 2.3.1 数据集测试
- 2.3.2 指定模型评估
- 2.3.3 命令行评估
- 3. 采用lmdeploy与vllm评估加速
- 3.1 安装lmdeploy
- 3.2 配置
- 3.2.1 lmdeploy部署 qwen1.5b_0.5b_chat 失败
- 3.2.2 lmdeploy部署 qwen2_1_5b_instruct 成功
- 3.2.3 vllm 部署 失败
- 4. 自定义数据集测试
- 4.1 自定义数据集评估后还要做通用数据集测试的意义
- 5.TurboMind框架介绍
我是星星之火,学习大模型时,记录学习过程,加深理解,同时帮助后来者。
概述
- 为什么需要模型评估?
1.了解模型能力
2.微调选择基座模型的判断标准
3.比较多需要 - 如何进行模型评估?
使用opencompass框架,底层封装评估逻辑 - 何时进行模型评估?
选择微调基座模型时,微调效果测试
1.生成式大模型的评估指标
行业评估报告:
https://www.modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
1.1 核心评估指标
OpenCompass支持以下主要评估指标,覆盖生成式大模型的多样化需求:
准确率(Accuracy):用于选择题或分类任务,通过比对生成结果与标准答案计算正确率。在OpenCompass中通过metric=accuracy配置
困惑度(Perplexity, PPL):衡量模型对候选答案的预测能力,适用于选择题评估。需使用ppl类型的数据集配置(如ceval_ppl)
生成质量(GEN):通过文本生成结果提取答案,需结合后处理脚本解析输出。使用gen类型的数据集(如ceval_gen),配置metric=gen并指定后处理规则
ROUGE/LCS:用于文本生成任务的相似度评估,需安装rouge==1.0.1依赖,并在数据配置中设置metric=rouge
条件对数概率(CLP):结合上下文计算答案的条件概率,适用于复杂推理任务,需在模型配置中启用use_logprob=True
1.2 支持的开源评估数据集及使用差异
主流开源数据集
OpenCompass内置超过70个数据集,覆盖五大能力维度:
| 能力维度 | 数据 |
|---|---|
| 知识类 | C-Eval(中文考试题)、CMMLU(多语言知识问答)、MMLU(英文多选题)。 |
| 推理类 | GSM8K(数学推理)、BBH(复杂推理链)。 |
| 语言类 | CLUE(中文理解)、AFQMC(语义相似度)。 |
| 代码类 | HumanEval(代码生成)、MBPP(编程问题)。 |
| 多模态类 | MMBench(图像理解)、SEED - Bench(多模态问答)。 |
1.3 数据集区别与选择
数据集区别与选择
评估范式差异:
_gen后缀数据集:生成式评估,需后处理提取答案(如ceval_gen)
_ppl后缀数据集:困惑度评估,直接比对选项概率(如ceval_ppl)
领域覆盖:
C-Eval:侧重中文STEM和社会科学知识,包含1.3万道选择题
LawBench:法律领域专项评估,需额外克隆仓库并配置路径
二、opencompass 安装与使用
2.1 安装
参考官网:
https://doc.opencompass.org.cn/zh_CN//get_started/installation.html
我这里使用源码安装
-
安装conda环境 , conda放到数据盘:
mkdir /root/autodl-tmp/xxzhenv
conda create --prefix /root/autodl-tmp/xxzhenv/opencompass python=3.10 -y
conda config --add envs_dirs /root/autodl-tmp/xxzhenv
conda activate opencompass

-
源码安装opencompass
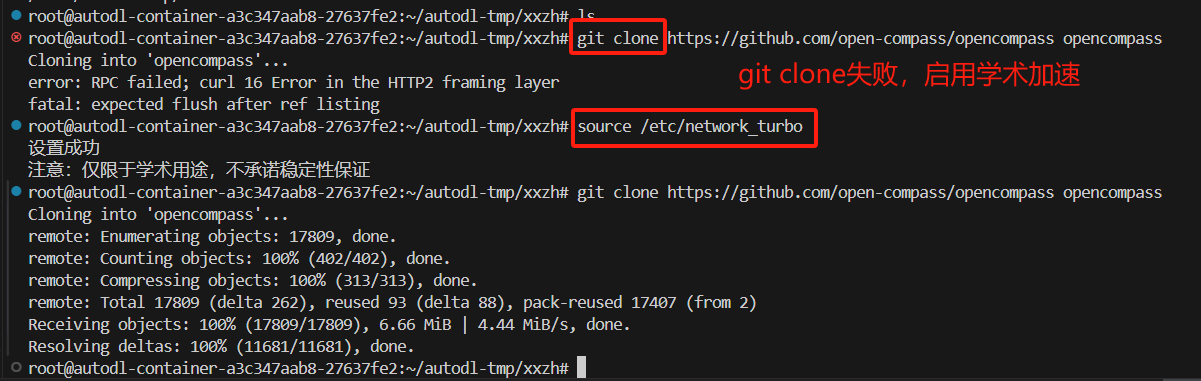
cd /root/autodl-tmp/xxzh
git clone https://github.com/open-compass/opencompass opencompass
cd opencompass
pip install -e .
2.2 准备数据
继续安装官网引导:
https://doc.opencompass.org.cn/zh_CN//get_started/installation.html
准备第三方数据集:
自建以及第三方数据集:OpenCompass 还提供了一些第三方数据集及自建中文数据集。运行以下命令手动下载解压。
在 OpenCompass 项目根目录下运行下面命令,将数据集准备至 ${OpenCompass}目录下, 解压自动生成data目录:
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
unzip OpenCompassData-core-20240207.zip
查看数据集:
(/root/autodl-tmp/xxzhenv/opencompass) root@autodl-container-a3c347aab8-27637fe2:~/autodl-tmp/xxzh/opencompass# ls data
AGIEval CLUE LCSTS Xsum commonsenseqa gsm8k lambada mmlu piqa strategyqa tydiqa
ARC FewCLUE SuperGLUE ceval drop hellaswag math nq race summedits winogrande
BBH GAOKAO-BENCH TheoremQA cmmlu flores_first100 humaneval mbpp openbookqa siqa triviaqa xstory_cloze
2.3 部署模型
-
开启学术加速,加快下载速度
source /etc/network_turbo -
pip install modelscope
-
后面测试用到如下两个模型
modelscope download --model Qwen/Qwen1.5-0.5B-Chat --local_dir /root/autodl-tmp/models/Qwen/Qwen1.5-0.5B-Chat
modelscope download --model Qwen/Qwen2.5-1.5B-Instruct --local_dir /root/autodl-tmp/models/Qwen/Qwen2.5-1.5B-Instruct
- 计算模型大小知识复习
模型总大小:

模型位数:
 都是16位。
都是16位。
按照上节课 【GPT入门】第59课 大模型内存计算指南 思路计算
0.5B,16位的,应该是1G
1.5B, 16位, 应该是3G
就是模型大小B与8bit的G单位大小一致。
2.3 运行命令
下文,参考 opencompass官网 操作,但增加操作截图与命令讲解
2.3.1 数据集测试
分为开源数据集和自定义数据集测试
- 一定要在微调的数据集测试和开源数据集测试(基本能力没有变化)
2.3.2 指定模型评估
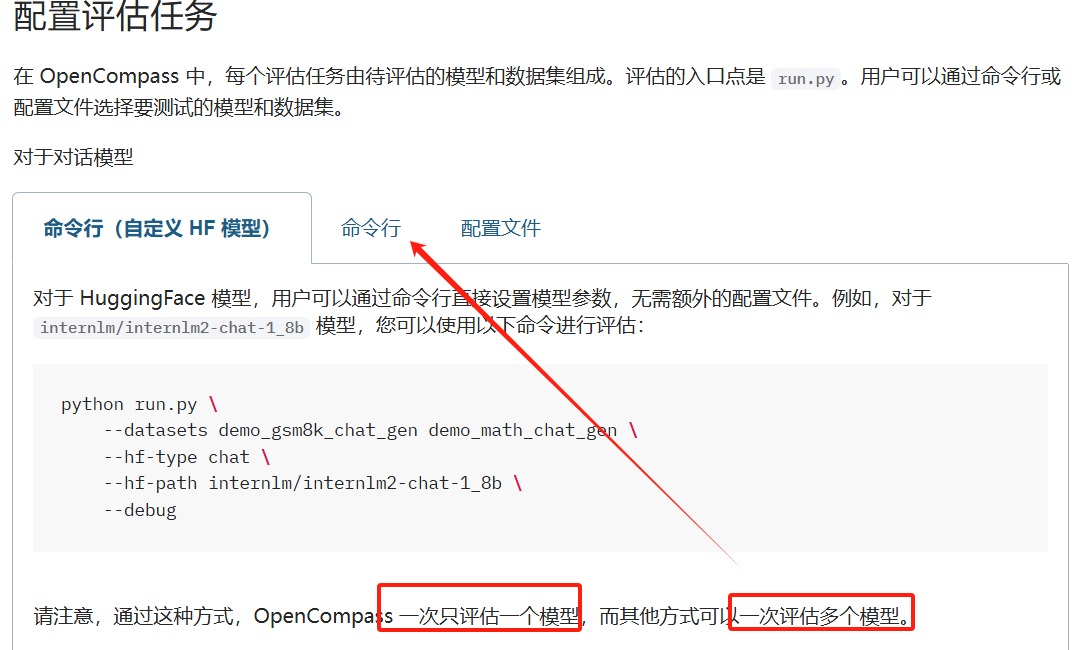
demo_gsm8k_chat_gen demo_math_chat_gen 上面数据下载回来的data数据
python run.py \--datasets demo_gsm8k_chat_gen demo_math_chat_gen \--hf-type chat \--hf-path /root/autodl-tmp/models/Qwen/Qwen1.5-0.5B-Chat \--debug
hf-type可以不指定,由程序自动识别
执行结果:
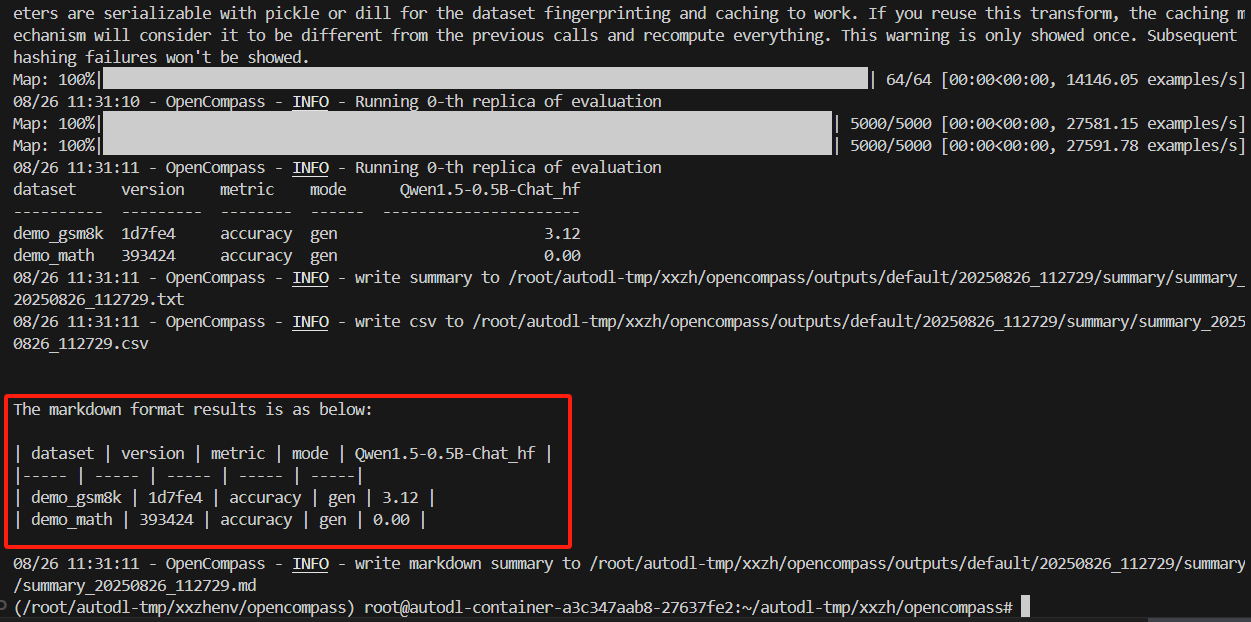
- 运行结果
每次测试生成一个测试目录,包含测试数据和测试结果
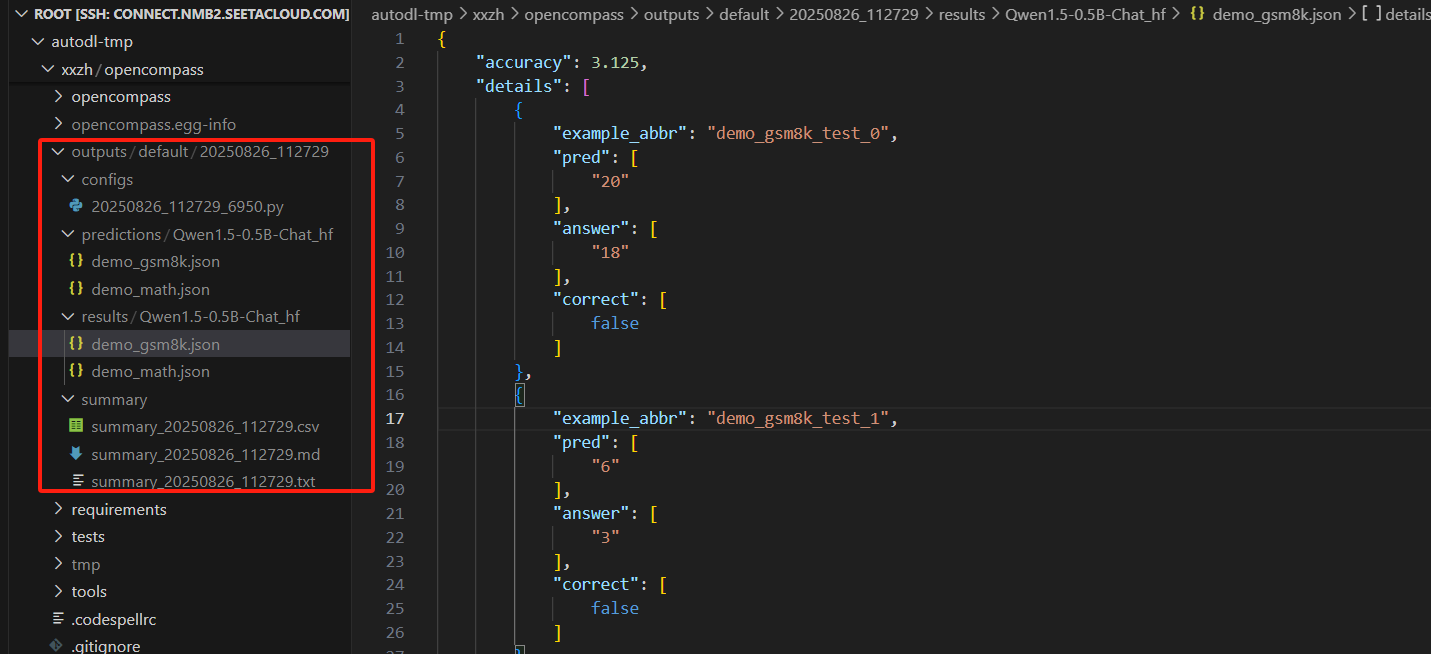
2.3.3 命令行评估
- 参数说明
可以一次评估多个模型
在 --models 中指定 模型的配置文件的路径,可以是多个路径,即同时评估多个对应的模型
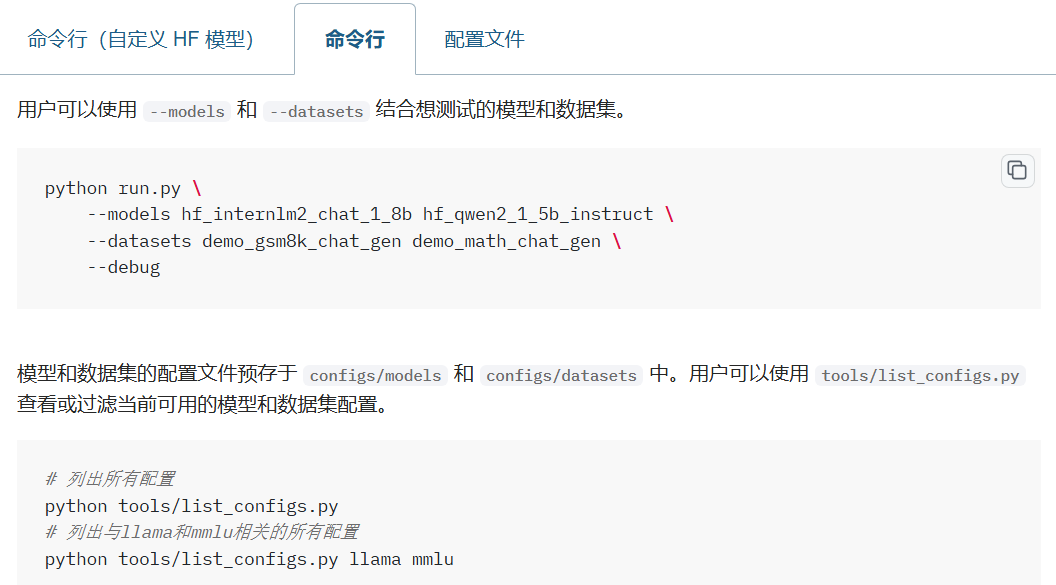
- qwen1的配置文件修改,直接修改源码的配置文件
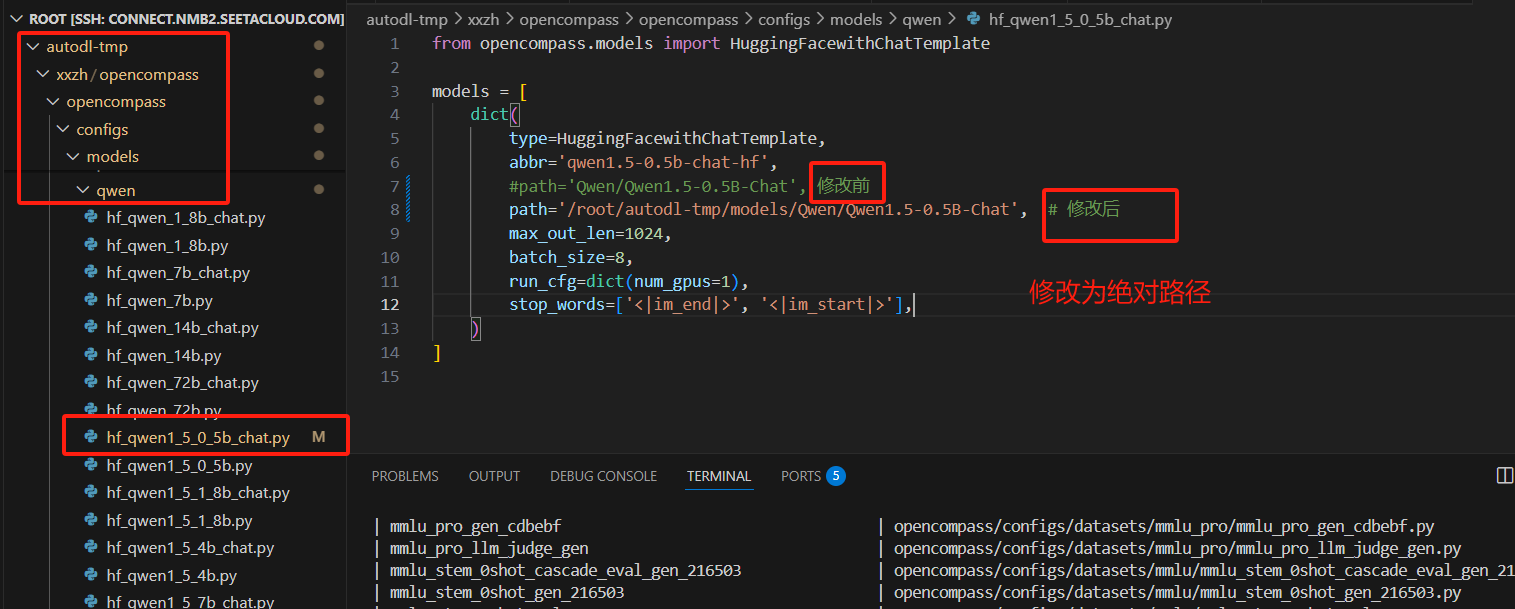
- qwen2.5 的配置文件修改,直接修改源码的配置文件
修改内容说明:
hf_qwen1_5_0_5b_chat
configs/models/qwen/hf_qwen1_5_0_5b_chat.py
把该文件的path的配置改为 本地绝对路径
run_cfg=dict(num_gpus=0) 指定在第几个gpu运行
configs/models/qwen/hf_qwen2_5_1_5b_instruct.py
- 查配置的方法
- 列出所有配置
这里设置了配置文件与配置名称的映射关系
python tools/list_configs.py - 列出所有qwen的配置
python tools/list_configs.py hf_qwen
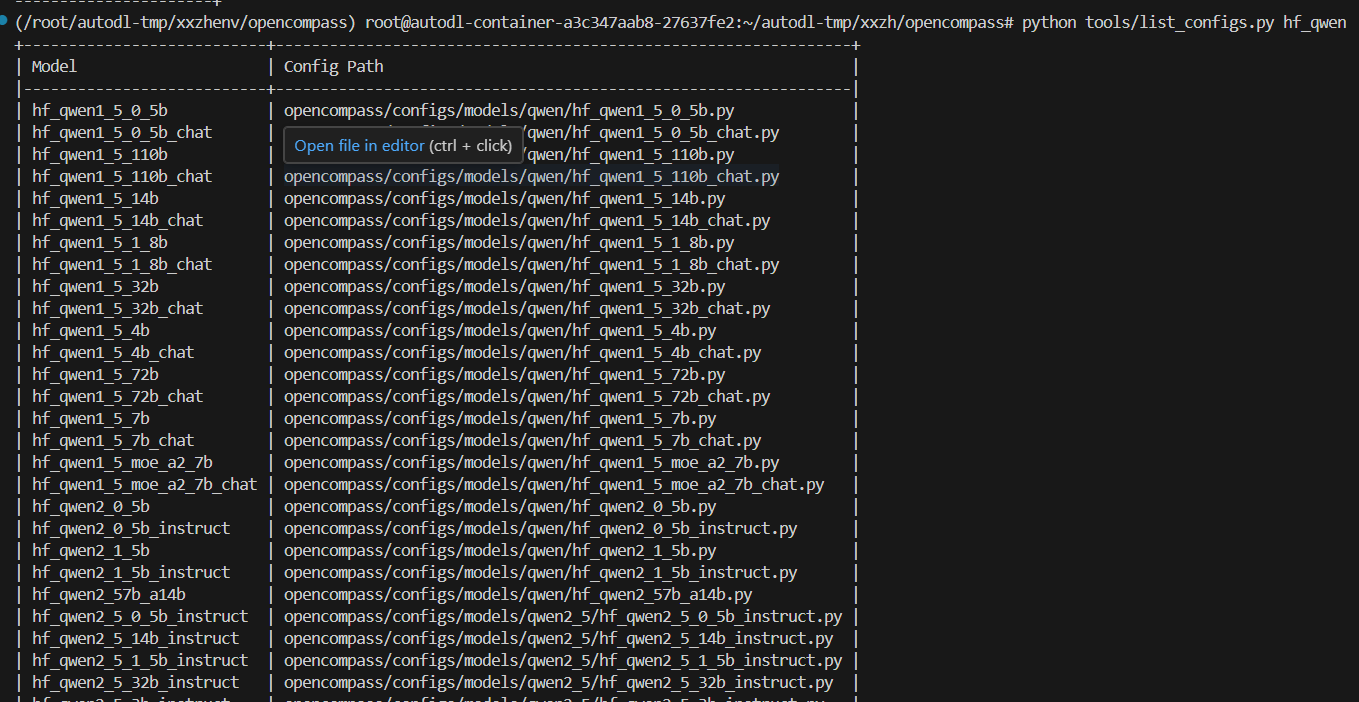
用户可以使用 --models 和 --datasets 结合想测试的模型和数据集。
因此,最后的命令如下:
python run.py \--models hf_qwen1_5_0_5b_chat hf_qwen2_5_1_5b_instruct \--datasets demo_gsm8k_chat_gen demo_math_chat_gen \--debug
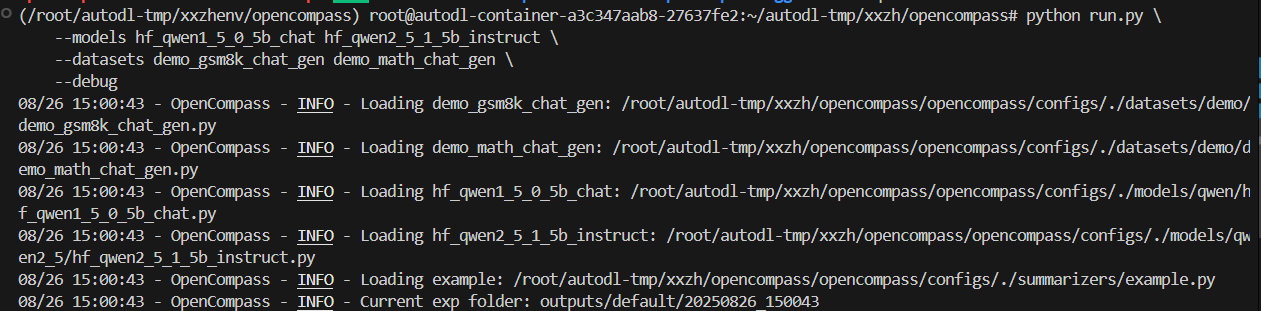
-
评估过程,cpu, gpu使用情况
-
测试结果
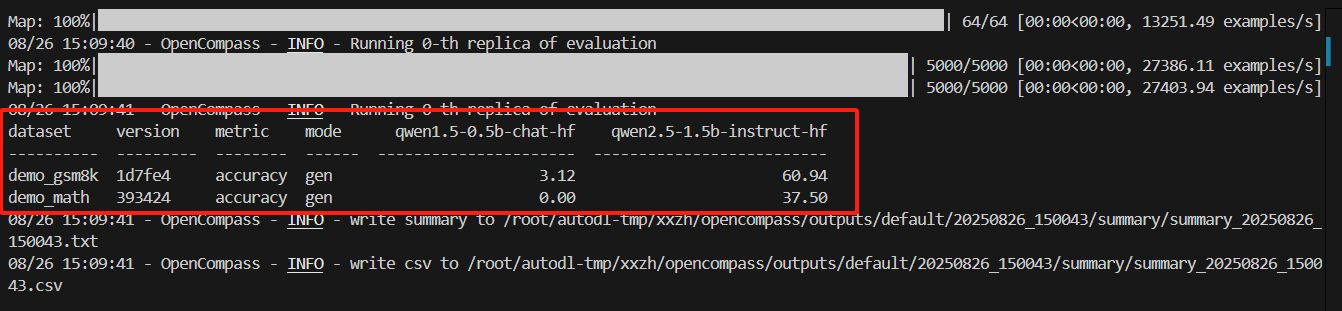
评估结果:qwen2.5-1.5b-instruct是有数学推理能力,而 qwen1.5-0.5b-chat是没有推理能力的。
3. 采用lmdeploy与vllm评估加速
3.1 安装lmdeploy
pip install lmdeploy
3.2 配置
3.2.1 lmdeploy部署 qwen1.5b_0.5b_chat 失败
configs/models/qwen目录下,有hf, lmdeploy , vllm的部署支持
lmdeploy_qwen_1_8b_chat 是最新的版本的配置文件,没有0.5B的,就用该文件进行修改。
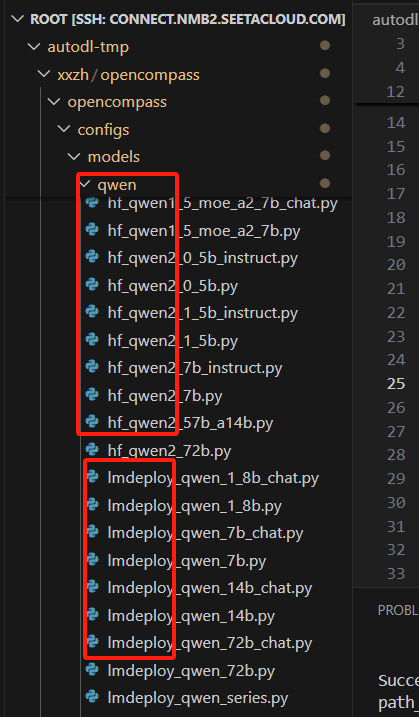
/root/autodl-tmp/models/Qwen/Qwen1.5-0.5B-Chat
python run.py
–models lmdeploy_qwen_1_8b_chat
–datasets demo_gsm8k_chat_gen demo_math_chat_gen
–debug
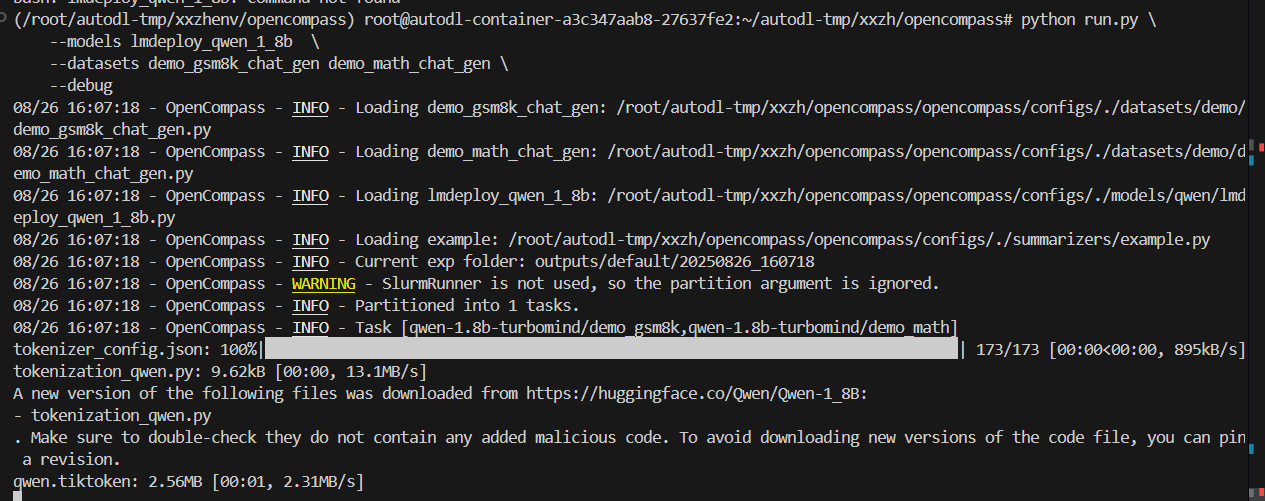
(/root/autodl-tmp/xxzhenv/opencompass) root@autodl-container-a3c347aab8-27637fe2:~/autodl-tmp/xxzh/opencompass# python run.py \--models lmdeploy_qwen_1_8b_chat \--datasets demo_gsm8k_chat_gen demo_math_chat_gen \--debug/root/autodl-tmp/xxzh/opencompass/opencompass/configs/models/qwen/lmdeploy_qwen2_1_5b_instruct.py
INFO 08-26 16:22:59 [__init__.py:241] Automatically detected platform cuda.
08/26 16:23:01 - OpenCompass - INFO - Loading demo_gsm8k_chat_gen: /root/autodl-tmp/xxzh/opencompass/opencompass/configs/./datasets/demo/demo_gsm8k_chat_gen.py
08/26 16:23:01 - OpenCompass - INFO - Loading demo_math_chat_gen: /root/autodl-tmp/xxzh/opencompass/opencompass/configs/./datasets/demo/demo_math_chat_gen.py
08/26 16:23:01 - OpenCompass - INFO - Loading lmdeploy_qwen_1_8b_chat: /root/autodl-tmp/xxzh/opencompass/opencompass/configs/./models/qwen/lmdeploy_qwen_1_8b_chat.py
08/26 16:23:01 - OpenCompass - INFO - Loading example: /root/autodl-tmp/xxzh/opencompass/opencompass/configs/./summarizers/example.py
08/26 16:23:01 - OpenCompass - INFO - Current exp folder: outputs/default/20250826_162301
08/26 16:23:01 - OpenCompass - WARNING - SlurmRunner is not used, so the partition argument is ignored.
08/26 16:23:01 - OpenCompass - INFO - Partitioned into 1 tasks.
08/26 16:23:02 - OpenCompass - INFO - Task [qwen-1.8b-chat-turbomind/demo_gsm8k,qwen-1.8b-chat-turbomind/demo_math]
Fetching 24 files: 100%|█████████████████████████████████████████████████████████████████████████████| 24/24 [00:00<00:00, 189930.75it/s]
[TM][WARNING] [LlamaTritonModel] `max_context_token_num` is not set, default to 7168.
2025-08-26 16:23:06,670 - lmdeploy - WARNING - turbomind.py:291 - get 219 model params
08/26 16:23:08 - OpenCompass - INFO - using stop words: ['<|im_start|>', '<|endoftext|>', '<|im_end|>']
Map: 100%|█████████████████████████████████████████████████████████████████████████████████| 7473/7473 [00:00<00:00, 26316.75 examples/s]
Map: 100%|█████████████████████████████████████████████████████████████████████████████████| 1319/1319 [00:00<00:00, 25295.66 examples/s]
08/26 16:23:09 - OpenCompass - INFO - Start inferencing [qwen-1.8b-chat-turbomind/demo_gsm8k]
Traceback (most recent call last):File "/root/autodl-tmp/xxzh/opencompass/run.py", line 4, in <module>main()File "/root/autodl-tmp/xxzh/opencompass/opencompass/cli/main.py", line 354, in mainrunner(tasks)File "/root/autodl-tmp/xxzh/opencompass/opencompass/runners/base.py", line 38, in __call__status = self.launch(tasks)File "/root/autodl-tmp/xxzh/opencompass/opencompass/runners/local.py", line 128, in launchtask.run(cur_model=getattr(self, 'cur_model',File "/root/autodl-tmp/xxzh/opencompass/opencompass/tasks/openicl_infer.py", line 89, in runself._inference()File "/root/autodl-tmp/xxzh/opencompass/opencompass/tasks/openicl_infer.py", line 134, in _inferenceinferencer.inference(retriever,File "/root/autodl-tmp/xxzh/opencompass/opencompass/openicl/icl_inferencer/icl_gen_inferencer.py", line 100, in inferenceprompt_list = self.get_generation_prompt_list_from_retriever_indices(File "/root/autodl-tmp/xxzh/opencompass/opencompass/openicl/icl_inferencer/icl_gen_inferencer.py", line 223, in get_generation_prompt_list_from_retriever_indicesprompt_token_num = self.model.get_token_len_from_template(File "/root/autodl-tmp/xxzh/opencompass/opencompass/models/base.py", line 225, in get_token_len_from_templatetoken_lens = [self.get_token_len(prompt) for prompt in prompts]File "/root/autodl-tmp/xxzh/opencompass/opencompass/models/base.py", line 225, in <listcomp>token_lens = [self.get_token_len(prompt) for prompt in prompts]File "/root/autodl-tmp/xxzh/opencompass/opencompass/models/turbomind_with_tf_above_v4_33.py", line 203, in get_token_lent = self.tokenizer.apply_chat_template(m, add_generation_prompt=True, return_dict=True)File "/root/autodl-tmp/xxzhenv/opencompass/lib/python3.10/site-packages/transformers/tokenization_utils_base.py", line 1620, in apply_chat_templatechat_template = self.get_chat_template(chat_template, tools)File "/root/autodl-tmp/xxzhenv/opencompass/lib/python3.10/site-packages/transformers/tokenization_utils_base.py", line 1798, in get_chat_templateraise ValueError(
ValueError: Cannot use chat template functions because tokenizer.chat_template is not set and no template argument was passed! For information about writing templates and setting the tokenizer.chat_template attribute, please see the documentation at https://huggingface.co/docs/transformers/main/en/chat_templating
好吧,没跑成功
3.2.2 lmdeploy部署 qwen2_1_5b_instruct 成功
- 换一个模型跑,跑qwen2_1_5b_instruct 模型
/root/autodl-tmp/xxzh/opencompass/opencompass/configs/models/qwen/lmdeploy_qwen2_1_5b_instruct.py 的 path修改为本地路径
from opencompass.models import TurboMindModelwithChatTemplatemodels = [dict(type=TurboMindModelwithChatTemplate,abbr='qwen2-1.5b-instruct-turbomind',path='/root/autodl-tmp/models/Qwen/Qwen2.5-1.5B-Instruct',engine_config=dict(session_len=16384, max_batch_size=16, tp=1),gen_config=dict(top_k=1, temperature=1e-6, top_p=0.9, max_new_tokens=4096),max_seq_len=16384,max_out_len=4096,batch_size=16,run_cfg=dict(num_gpus=1),)
]
(/root/autodl-tmp/xxzhenv/opencompass) root@autodl-container-a3c347aab8-27637fe2:~/autodl-tmp/xxzh/opencompass# python run.py
–models lmdeploy_qwen2_1_5b_instruct
–datasets demo_gsm8k_chat_gen demo_math_chat_gen
–debug
执行结果:
评估速度明显比huggingface方式快。
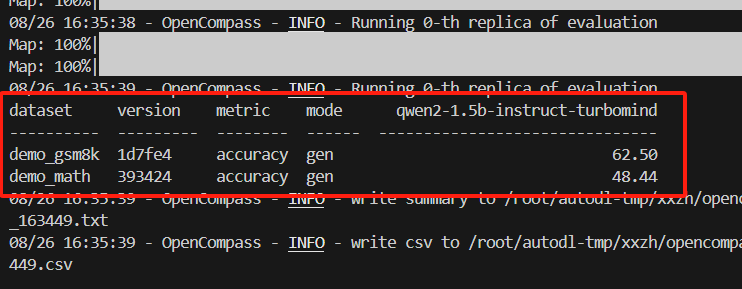
- 换数据集测试,数据集改为:ceval_gen
python run.py \--models lmdeploy_qwen2_1_5b_instruct \--datasets ceval_gen \--debug
评估结果:
| dataset | version | metric | mode | qwen2-1.5b-instruct-turbomind |
|---|---|---|---|---|
| ceval-computer_network | db9ce2 | accuracy | gen | 68.42 |
| ceval-operating_system | 1c2571 | accuracy | gen | 52.63 |
| ceval-computer_architecture | a74dad | accuracy | gen | 76.19 |
| ceval-college_programming | 4ca32a | accuracy | gen | 70.27 |
| ceval-college_physics | 963fa8 | accuracy | gen | 47.37 |
| ceval-college_chemistry | e78857 | accuracy | gen | 41.67 |
| ceval-advanced_mathematics | ce03e2 | accuracy | gen | 26.32 |
| ceval-probability_and_statistics | 65e812 | accuracy | gen | 33.33 |
| ceval-discrete_mathematics | e894ae | accuracy | gen | 43.75 |
| ceval-electrical_engineer | ae42b9 | accuracy | gen | 56.76 |
| ceval-metrology_engineer | ee34ea | accuracy | gen | 87.50 |
| ceval-high_school_mathematics | 1dc5bf | accuracy | gen | 22.22 |
| ceval-high_school_physics | adf25f | accuracy | gen | 78.95 |
| ceval-high_school_chemistry | 2ed27f | accuracy | gen | 52.63 |
| ceval-high_school_biology | 8e2b9a | accuracy | gen | 68.42 |
| ceval-middle_school_mathematics | bee8d5 | accuracy | gen | 63.16 |
| ceval-middle_school_biology | 86817c | accuracy | gen | 90.48 |
| ceval-middle_school_physics | 8accf6 | accuracy | gen | 89.47 |
| ceval-middle_school_chemistry | 167a15 | accuracy | gen | 95.00 |
| ceval-veterinary_medicine | b4e08d | accuracy | gen | 73.91 |
| ceval-college_economics | f3f4e6 | accuracy | gen | 52.73 |
| ceval-business_administration | c1614e | accuracy | gen | 54.55 |
| ceval-marxism | cf874c | accuracy | gen | 78.95 |
| ceval-mao_zedong_thought | 51c7a4 | accuracy | gen | 87.50 |
| ceval-education_science | 591fee | accuracy | gen | 79.31 |
| ceval-teacher_qualification | 4e4ced | accuracy | gen | 84.09 |
| ceval-high_school_politics | 5c0de2 | accuracy | gen | 78.95 |
| ceval-high_school_geography | 865461 | accuracy | gen | 73.68 |
| ceval-middle_school_politics | 5be3e7 | accuracy | gen | 85.71 |
| ceval-middle_school_geography | 8a63be | accuracy | gen | 91.67 |
| ceval-modern_chinese_history | fc01af | accuracy | gen | 86.96 |
| ceval-ideological_and_moral_cultivation | a2aa4a | accuracy | gen | 100.00 |
| ceval-logic | f5b022 | accuracy | gen | 59.09 |
| ceval-law | a110a1 | accuracy | gen | 41.67 |
| ceval-chinese_language_and_literature | 0f8b68 | accuracy | gen | 47.83 |
| ceval-art_studies | 2a1300 | accuracy | gen | 63.64 |
| ceval-professional_tour_guide | 4e673e | accuracy | gen | 79.31 |
| ceval-legal_professional | ce8787 | accuracy | gen | 65.22 |
| ceval-high_school_chinese | 315705 | accuracy | gen | 36.84 |
| ceval-high_school_history | 7eb30a | accuracy | gen | 70.00 |
| ceval-middle_school_history | 48ab4a | accuracy | gen | 90.91 |
| ceval-civil_servant | 87d061 | accuracy | gen | 59.57 |
| ceval-sports_science | 70f27b | accuracy | gen | 68.42 |
| ceval-plant_protection | 8941f9 | accuracy | gen | 63.64 |
| ceval-basic_medicine | c409d6 | accuracy | gen | 73.68 |
| ceval-clinical_medicine | 49e82d | accuracy | gen | 59.09 |
| ceval-urban_and_rural_planner | 95b885 | accuracy | gen | 63.04 |
| ceval-accountant | 002837 | accuracy | gen | 61.22 |
| ceval-fire_engineer | bc23f5 | accuracy | gen | 67.74 |
| ceval-environmental_impact_assessment_engineer | c64e2d | accuracy | gen | 61.29 |
| ceval-tax_accountant | 3a5e3c | accuracy | gen | 59.18 |
| ceval-physician | 6e277d | accuracy | gen | 71.43 |
3.2.3 vllm 部署 失败
vllm_qwen1_5_0_5b_chat
python run.py
–models vllm_qwen1_5_0_5b_chat
–datasets demo_gsm8k_chat_gen demo_math_chat_gen
–debug
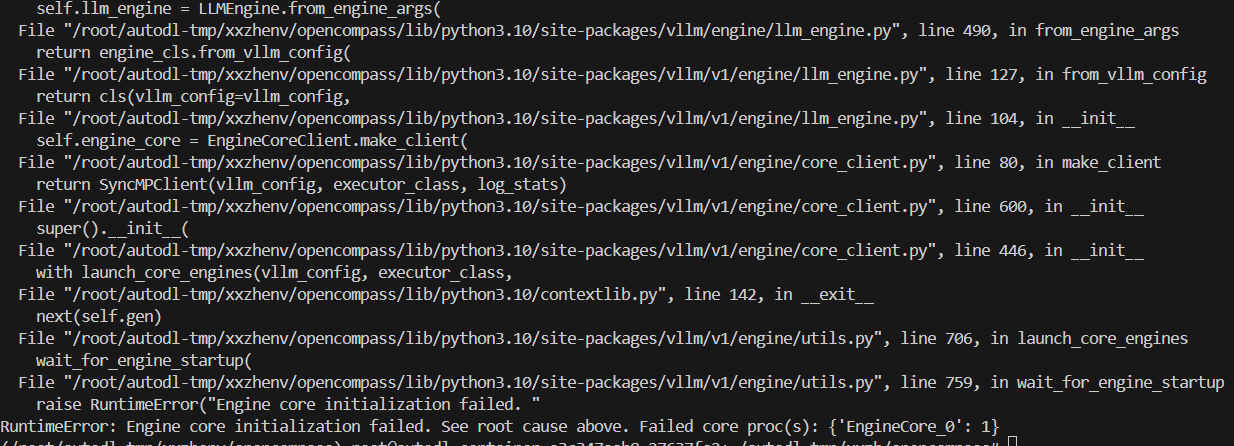
版本安装有问题。。。安装vllm也报错。。。,多组件兼容性问题,需要找一致的版本才行
4. 自定义数据集测试
4.1 自定义数据集评估后还要做通用数据集测试的意义
意义是:检查是否过拟合
模型评估的是模型的整体能力
对话模板:影响的是模型的对话方式,几乎可以忽略不计
5.TurboMind框架介绍
https://lmdeploy.readthedocs.io/zh-cn/latest/inference/turbomind.html