从易用性的角度来看,哪个ETL平台比较好用?
在现代企业的数据架构中,ETL(提取、转换、加载)一直扮演着核心角色——它把分散各处、结构各异的数据源,整合成真正可用的数据资产。随着数字化转型不断深入,企业对于数据集成效率和质量的要求也越来越高,这时候,选对ETL平台,往往就成了提升整个数据工程效能的关键。
不过现实是,市面上ETL工具五花八门,功能各有侧重,企业在选型时难免遇到这样的困惑:这么多ETL平台,到底哪个更好用?技术团队追求灵活强大,管理者看重落地效率和总拥有成本(TCO),业务人员则只想更快拿到数据结果……面对这些不同声音,我们不妨从“易用性”这个实际维度切入,聊一聊主流ETL平台的特点,希望能给不同规模、不同技术背景的团队一些参考。
一、为什么“易用性”比你想象的更重要?
很多企业在选型时容易陷入一个误区:追求功能全面、架构先进,却忽略了落地过程中的实际阻力。
试想一下:
-
数据团队只有3个人,能否快速上手并维护一个复杂的ETL系统?
-
业务部门频繁提出新的数据同步需求,IT是否每次都要写脚本、调接口?
-
新员工入职,多久能独立完成一条数据管道的配置?
这些问题的答案,很大程度上取决于ETL平台的易用性。它直接影响:
-
项目的上线周期
-
日常运维的人力成本
-
跨部门协作的效率
-
整体数据治理的可持续性
换句话说,再强大的工具,如果没人愿意用、用不好,也等于零。
二、评判ETL平台易用性的五大核心标准
要客观评估“好不好用”,我们需要一套可量化的标准。以下是五个关键维度,适用于技术人员评估,也便于管理者做决策参考:
1. 学习成本:是否需要编程基础?
-
是否支持拖拽式操作?
-
是否对SQL/Python有强依赖?
-
新人能否在1-2天内完成基础任务?
2. 界面与交互设计:功能是否“看得见、找得到”?
-
菜单逻辑是否清晰?
-
流程配置是否直观?
-
错误提示是否明确?
3. 配置 vs. 编码:是低代码,还是写代码?
-
多少功能可以通过点击完成?
-
自定义逻辑是否必须依赖脚本?
-
是否支持模板复用?
4. 文档与社区支持:遇到问题能不能快速解决?
-
官方文档是否详尽、示例丰富?
-
是否有中文支持?
-
社区是否活跃?GitHub Issue响应是否及时?
5. 部署与运维难度:是“开箱即用”,还是“搭积木”?
-
是否支持SaaS化部署?
-
本地安装是否复杂?
-
升级、监控、告警是否自动化?
三、主流ETL平台横向对比(聚焦易用性)
我们选取了当前市场上关注度较高的几类ETL工具,从“易用性”角度进行打分和分析,帮助不同背景的企业找到最适合自己的选择。
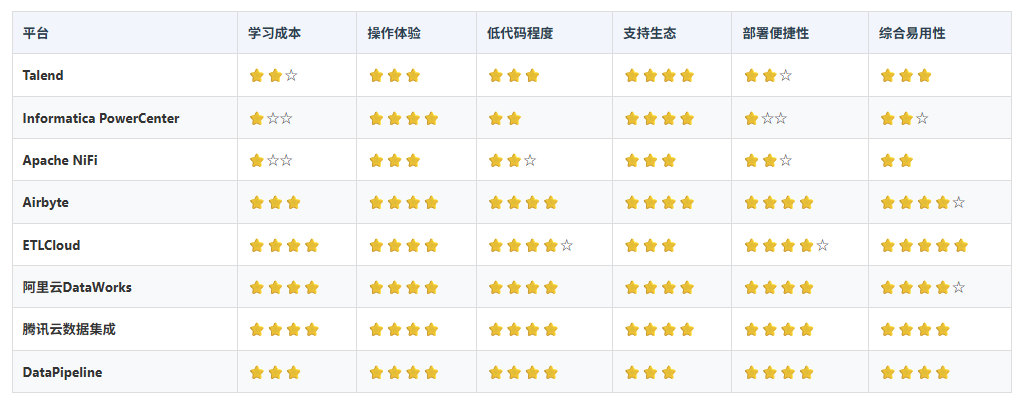
详细分析:
1. Talend
作为老牌ETL厂商,Talend功能强大,支持本地和云部署,拥有丰富的组件库。其Studio提供拖拽式设计,但整体界面略显陈旧,初学者仍需一定时间熟悉Job设计逻辑。适合有一定技术积累的中大型企业,学习曲线中等偏高。
2. Informatica PowerCenter
传统企业的“常青树”,功能深度无可挑剔,尤其在金融、电信等行业广泛应用。但其客户端臃肿,部署复杂,且高度依赖专业培训。虽然界面成熟,但操作流程繁琐,对新手极不友好,更适合已有IT体系支撑的大型组织。
3. Apache NiFi
开源项目中的“技术派代表”,流程可视化能力强,支持实时流处理。但由于完全依赖配置文件和处理器连接,缺乏标准化模板,初学者容易迷失在“连线海洋”中。适合技术团队主导、追求灵活性的场景。
4. Airbyte
近年来崛起的开源新秀,主打“开发者友好”和“极简主义”。界面清爽,预置大量数据源连接器(over 300+),支持Docker一键部署,社区活跃,文档清晰。虽然是开源项目,但其设计理念明显偏向降低使用门槛,非常适合中小企业快速搭建数据管道。
5. ETLCloud(国内云原生平台)
这是近年来国内ETL领域的一匹黑马。完全基于云原生架构,强调“开箱即用”。最大的亮点是:
-
全中文界面,符合国内用户习惯
-
支持拖拽式流程编排,无需编码即可完成90%以上的集成任务
-
提供跨云支持(阿里云、腾讯云、AWS等),适配混合云环境
-
一键部署、自动监控、失败重试等运维功能内置
-
尤其适合希望“快速见效”的企业,真正实现了“让业务人员也能参与数据集成”
6. 国内SaaS化平台(DataWorks、腾讯云数据集成、DataPipeline)
这类平台普遍具备以下优势:
-
深度集成国内主流数据库(如OceanBase、PolarDB、达梦)
-
支持微信/钉钉告警、审批流等本土化功能
-
提供免费试用和按量计费模式
-
中文文档完善,技术支持响应快
特别是阿里云DataWorks,作为MaxCompute的配套工具,在数据开发、调度、质量监控方面形成闭环,适合已使用阿里云生态的企业。
四、按角色推荐:谁该用什么ETL平台?
根据我们的评估,结合企业规模、团队能力和业务需求,给出如下推荐:
中小企业 / 初学者 / 快速落地项目
这些平台共同特点是:低学习成本、界面友好、部署简单、支持中文。无需组建专门的数据工程团队,也能在几天内完成数据同步上线。尤其适合电商、SaaS、教育等行业,需要快速打通CRM、ERP、广告投放等系统的场景。
中大型企业 / 复杂数据治理需求
当企业已有成熟的数据架构,且需要处理PB级数据、多系统集成、复杂清洗逻辑时,这类平台的功能深度和稳定性更具优势。虽然上手慢,但长期来看可控性强,适合建立企业级数据中台。
技术型团队 / 开发主导 / 实时流处理
这类工具灵活性极高,适合定制化开发。但前提是团队具备较强的Java/Python能力,且愿意投入时间维护。

最后
技术选型从来不是非黑即白的选择题。ETL平台的“好用”,最终要回归到企业的实际场景:
-
你是想快速验证一个数据项目,还是建设长期稳定的数据底座?
-
你的团队是3人小分队,还是百人数据中台?
-
你更看重上线速度,还是控制粒度?
但可以肯定的是,在数字化转型加速的今天,“易用性”正在成为ETL平台的核心竞争力。毕竟,最好的工具,不是功能最多的,而是最让人愿意用、用得起来的。