MySQL-数据类型
数据类型
数据类型分类
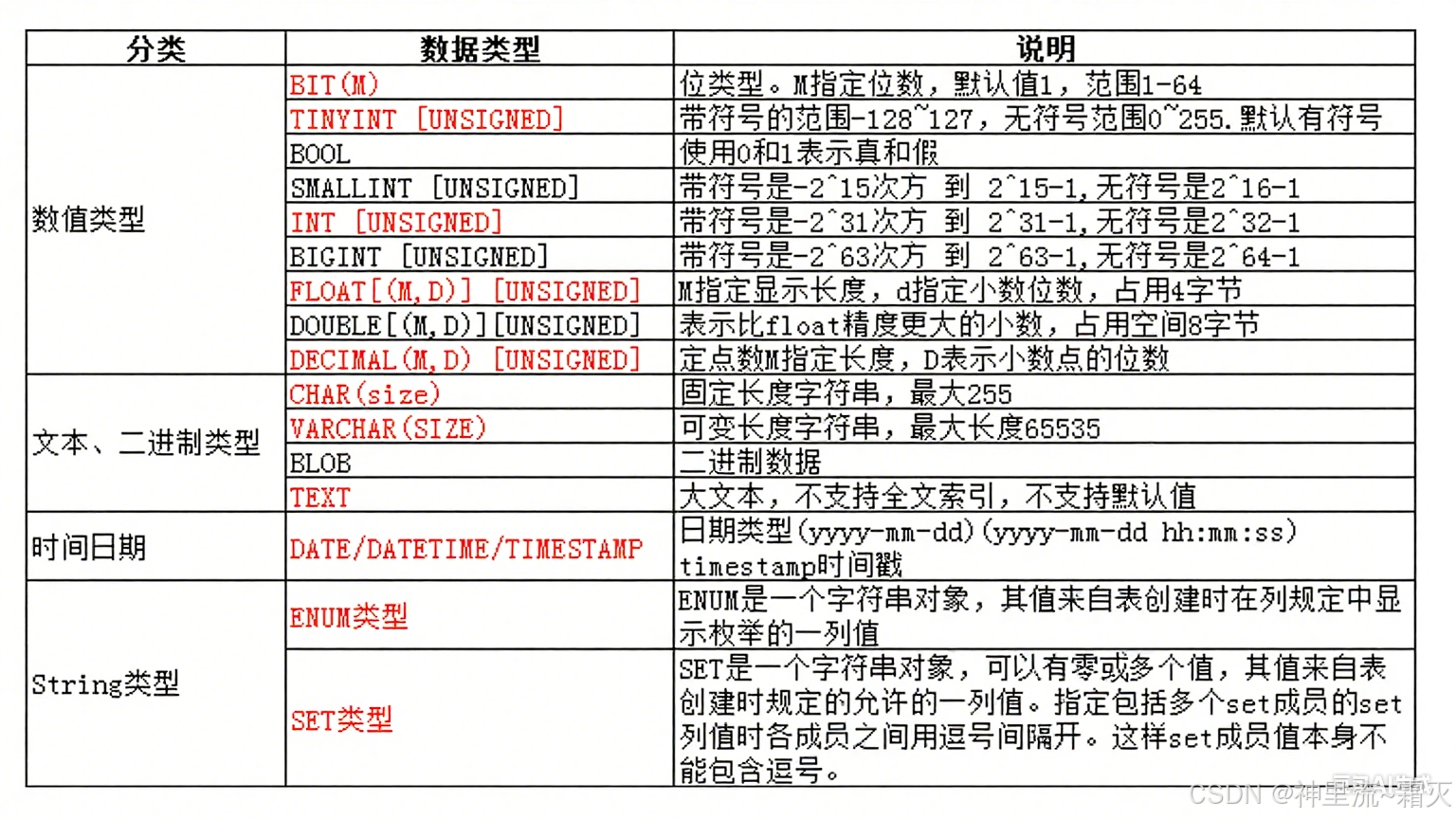
数值类型
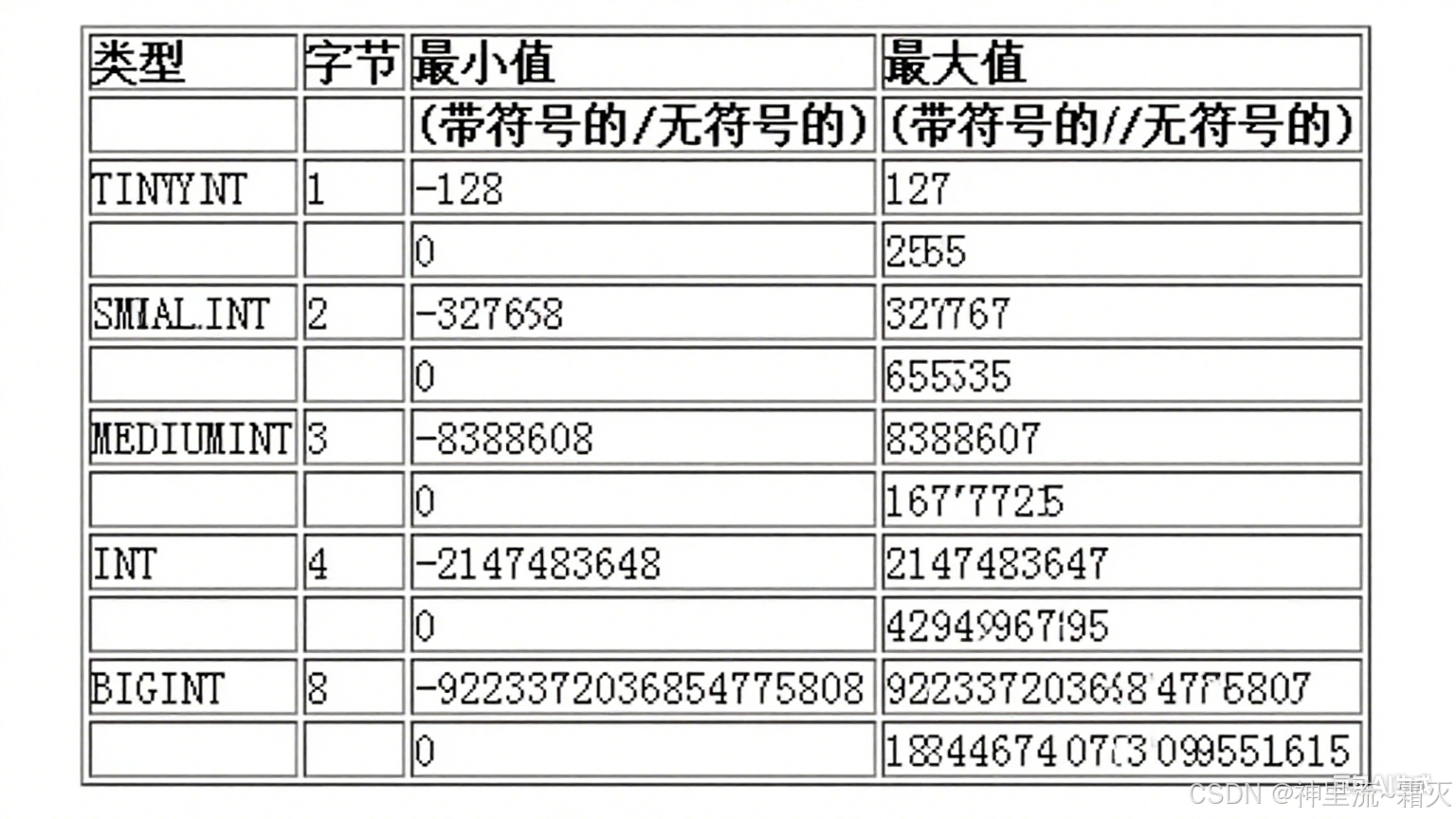
tinyint类型
在 MySQL 中,TINYINT是一种数值类型。TINYINT 类型用于存储非常小的整数值,它在数据库中占用 1 个字节(8 位)的存储空间。默认情况下,TINYINT 是有符号的,其取值范围是从 -128 到 127。这是因为在 8 位二进制补码表示中,最高位用作符号位,剩下 7 位表示数值。例如,二进制 10000000 表示 -128,01111111 表示 127。当使用 UNSIGNED 关键字修饰 TINYINT 时,它就变成了无符号类型,取值范围变为从 0 到 255。此时 8 位二进制全部用于表示数值,没有符号位,所以能表示的最大值更大。例如,二进制 11111111 表示 255 。
虽然 MySQL 有 BOOL 或 BOOLEAN 类型,但它们本质上也是基于 TINYINT 实现(0 代表 FALSE,非 0 代表 TRUE)。当需要存储一个相对较小的整数范围,如表示年级(1 - 12 )、月份(1 - 12 )、星期几(1 - 7 )等场景时,使用 TINYINT 可以有效节省存储空间。
如图所示:
我们首先创建一个名为“test_db”的表。

简单写一下表结构。
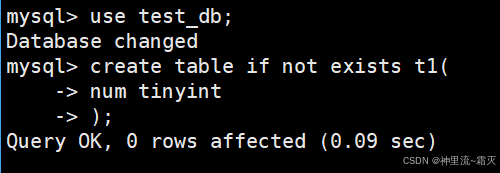
定义表的列,列名是 num,数据类型是 tinyint(1 字节小整数类型,默认有符号范围 -128 ~ 127 ,无符号则 0 ~ 255 )。
通过命令“desc t1”查看一下表结构。
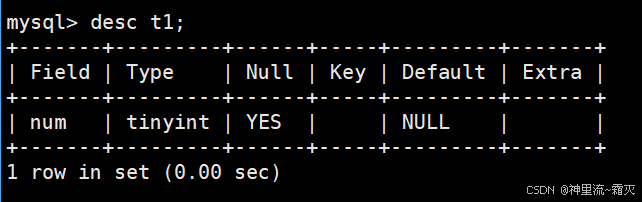
可以看出,Type(数据类型)列的数据类型是 tinyint,属于 1 字节的小整数类型,默认有符号范围 -128 ~ 127,无符号则 0 ~ 255 。
通过命令“show tables;”列出当前使用数据库中的所有表。
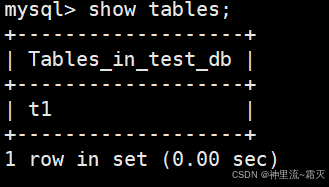
通过命令“SHOW CREATE TABLE t1;”查看表 t1 的创建语句及相关元信息。
- **
\num` tinyint DEFAULT NULL**:定义表的列,列名num,数据类型tinyint(1 字节小整数,默认有符号范围-128~127),DEFAULT NULL表示该列默认值为NULL`(允许空值 )。 DEFAULT CHARSET=utf8mb4:设置表的默认字符集为utf8mb4,能兼容更多 Unicode 字符(如 emoji 表情 ),比传统utf8更完善。COLLATE=utf8mb4_0900_ai_ci:定义字符排序规则,ai表示不区分重音,ci表示不区分大小写,0900是与 Unicode 9.0 相关的版本标识,影响字符串比较、排序的规则 。
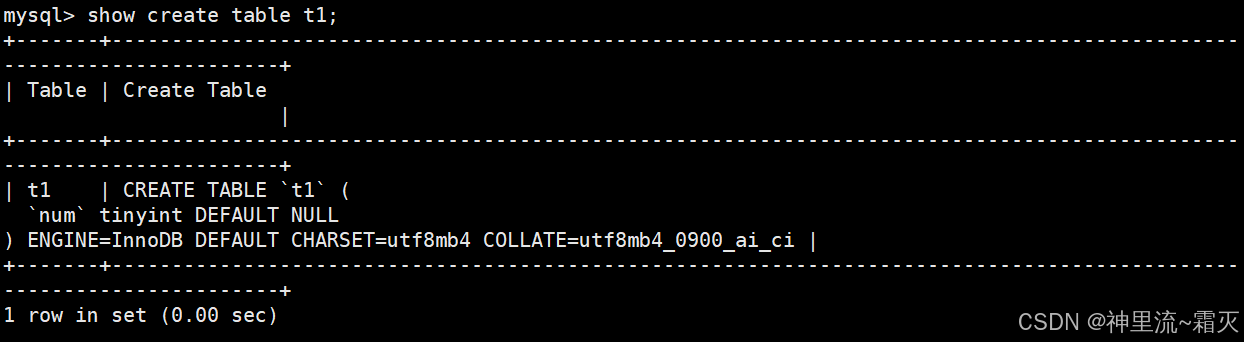
通过命令“ SHOW CREATE TABLE t1\G ;”查看表 t1 的创建语句及相关元数据。(\G 是 MySQL 命令行的语法,替代传统的分号 ; ,让结果按垂直(键值对)格式展示,适合长语句阅读,避免因语句过长换行混乱。)
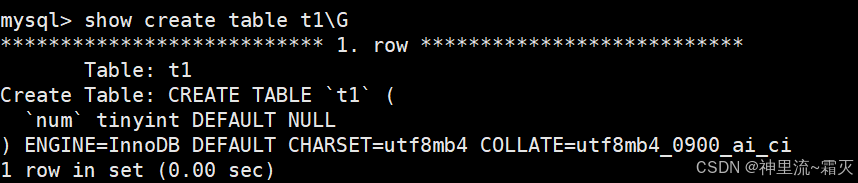
- **
CREATE TABLE \t1`**:标准 SQL 语法,声明创建名为t1` 的表(反引号包裹表名,避免与 MySQL 关键字冲突 )。 \num` tinyint DEFAULT NULL`:定义表的列:- 列名
num,数据类型tinyint(1 字节整数,默认有符号范围-128 ~ 127)。 DEFAULT NULL表示该列允许空值,插入数据时若不指定num值,默认填NULL。
- 列名
DEFAULT CHARSET=utf8mb4:设置表的默认字符集为utf8mb4,兼容 Unicode 字符(如 emoji 表情 ),比传统utf8更完善。COLLATE=utf8mb4_0900_ai_ci:定义字符排序规则:utf8mb4是字符集,0900关联 Unicode 9.0 版本,ai表示 “不区分重音”(Accent Insensitive ),ci表示 “不区分大小写”(Case Insensitive ),影响字符串比较、排序逻辑。
好,接下来我们来做tinyint数值越界测试。
前面我们知道 tinyint 是一种占用 1 个字节(8 位)存储空间的整数类型,根据是否为有符号类型,其取值范围有所不同。
有符号的 TINYINT
在计算机中,有符号整数通常采用补码形式存储。对于 8 位二进制数,最高位(最左边的一位)被用作符号位,0表示正数,1表示负数 。剩下的 7 位用来表示数值大小。
最小值是二进制10000000,它表示的十进制数是-128 ;最大值是二进制01111111 ,对应的十进制数是127 。所以,有符号TINYINT的取值范围是-128到127。
无符号的 TINYINT
当使用UNSIGNED关键字修饰TINYINT时,所有 8 位二进制数都用于表示数值,不存在符号位。
最小值是二进制00000000,对应十进制数0 ;最大值是二进制11111111,换算成十进制数是255 。即无符号TINYINT的取值范围是0到255 。
那么,此时我们在 t1 中插入几组数值。
如图所示
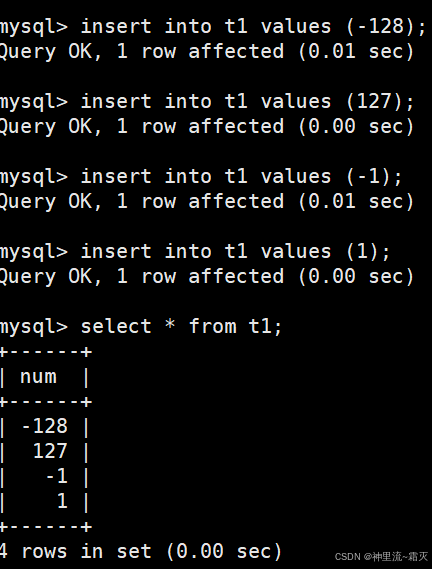
可以看出,能够正确插入。接下来我们来插入几组特别的数值。
如图所示
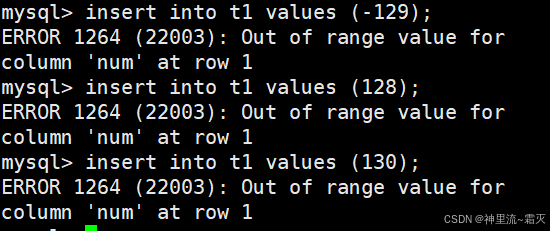
很明显,出现了报错,这是什么原因呢?
前面我们讲的都是有符号的,那么我们不妨再来了解一下无符号的。
同理,我们简单写一下t2的表结构
然后我们在t2中插入几组数值。
![]()
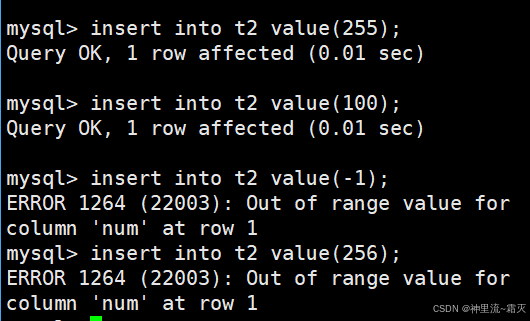
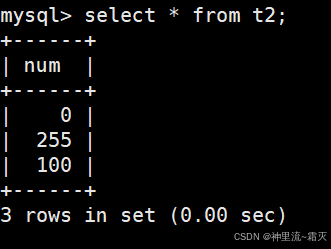
同样的为什么有的数值可以有的数值却不行呢?
如果我们箱 MySQL 特定的类型中插入不合法的数据,MySQL 一般都是直接拦截我们,不让我们做对应的操作;反过来,如果我们已经将数据成功插入到 MySQl 中,那么一定是合法的。所以,在 MySQL中 一般而言,数据本身也是一种 约束。
了解了 tinyint 之后,同学们可以自己试着推导一下其他类型。
注意1:
在MySQL中,整型可以指定是有符号的和无符号的,默认是有符号的。可以通过UNSIGNED来说明某个字段是无符号的】
注意2:
尽量不使用unsigned,对于int类型可能存放不下的数据,int unsigned同样可能存放不 下,与其如此,还不如设计时,将int类型提升为bigint类型
bit类型
在 MySQL 中,BIT 类型用于存储用于存储 bit 类型,用于存储位值(二进制数据)。它可以存储从 1 位到 64 位的二进制数据,具体长度可以通过括号指定,例如 BIT(5) 表示存储 5 位二进制数。
BIT(M) 可以存储 M 位的二进制数,M 的取值范围是 1 到 64,默认值为 1。例如 BIT(3) 可存储的范围是 000 到 111(二进制),对应十进制的 0 到 7。
插入数据时,可以使用二进制字面量(如 b'101')、十进制数或十六进制数(如 0x5)。查询时,直接查询会返回二进制数据,通常需要使用函数转换为可读性更好的形式,如 BIN()(转为二进制字符串)、HEX()(转为十六进制)或 CAST(col AS UNSIGNED)(转为十进制)。
基本语法: bit[(M)] : 位字段类型。M表示每个值的位数,范围从1到64。如果M被忽略,默认为1。
如图所示,我们在看一下。
上次我们在这个数据库进行了tinyint类型测试,这次我们还在这个数据库中进行测试。
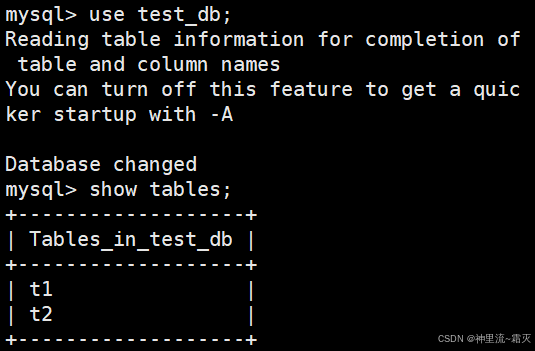
首先我们来查看一下这个数据库中的所有表的情况。
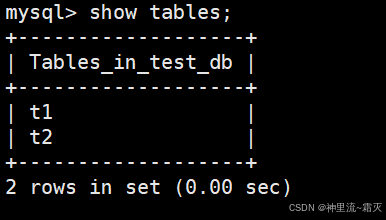
可以看到,前两个表是我们进行tinyint类型测试时所建立的表,接下来我们建立一个t3来进行bit类型的测试。
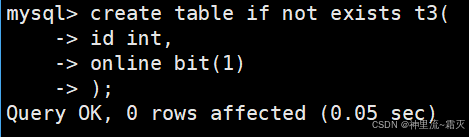
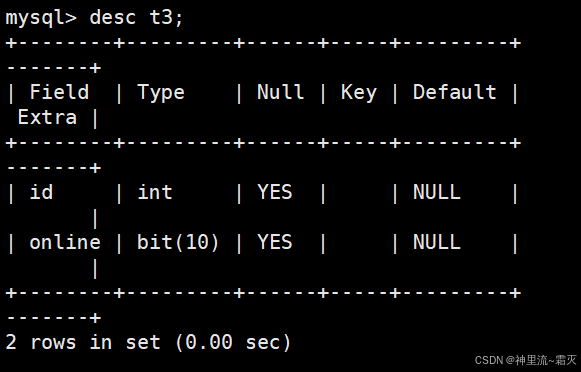
查看一下表 t3 的结构信息
接着我们来插入几组数据。
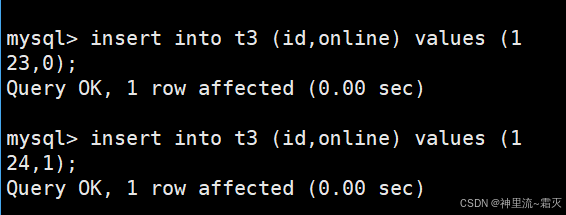
可以看到,数据插入成功。
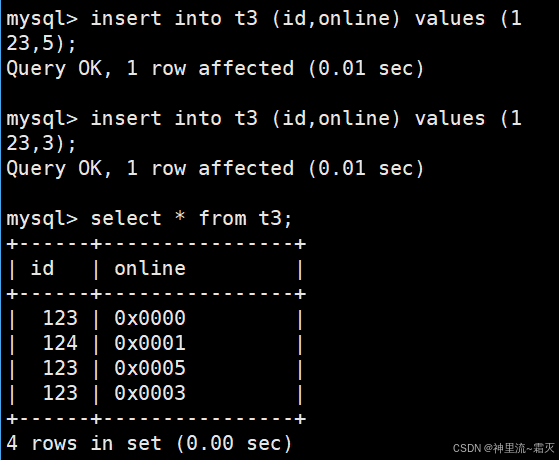
我们不妨再来看一下这几组数据。
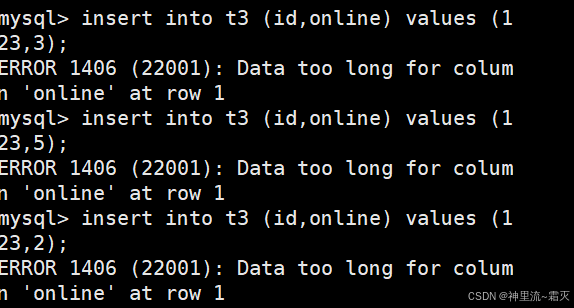
为什么这几组数据会插入失败呢?
在 MySQL 中,每一个列都定义了特定的数据类型,不同数据类型所能存储的数据长度和格式是有规定的 。比如,VARCHAR(10) 类型意味着该列最多能存储 10 个字符。
当你执行 INSERT INTO t3 (id,online) VALUES (123,3); 这类插入语句时,online 列的值插入失败,大概率是因为 online 列定义的数据类型允许存储的数据长度小于你实际插入的数据所占用的长度。
假设 online 列被定义为 VARCHAR(1) 类型,那么它最多只能存储 1 个字符。 当你插入 3 或者 5 时,虽然它们从数值角度看比较小,但作为字符串存储时,3 和 5 都各占 1 个字符长度,是符合插入要求的。但如果你插入一个长度超过 1 个字符的字符串,比如 12,就会出现 Data too long for column 'online' 这样的数据过长错误 。
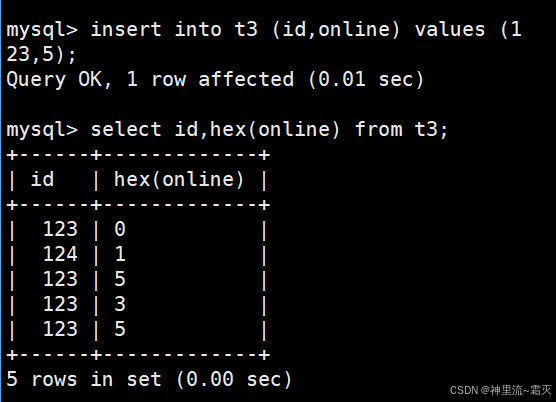
然后,我们来查看一下表 t3 中的数据。
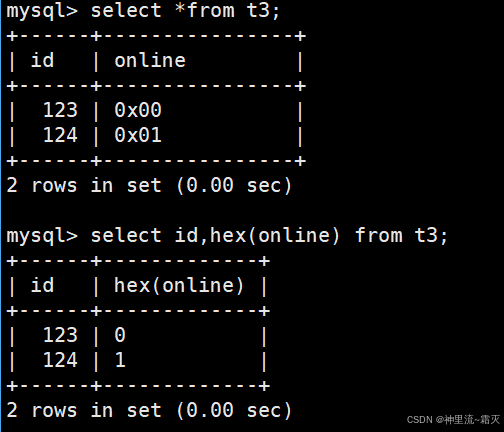
可以看到,表中的数据其实都是相同的,只是数据格式有所差异而已。
从查询结果看,online 列实际是 BIT 类型(如 BIT(1) 或 BIT(n) )。BIT 类型存储的是二进制位数据,但 MySQL 客户端显示时,会根据场景自动转换格式。
MySQL 命令行客户端(或其他工具)遇到 BIT 类型,会默认把二进制值转成 十六进制字符串 展示,格式为 0x + 十六进制值(比如 0x00、0x01 )。这是客户端为了让二进制数据 “可读” 做的默认转换,本质上存的是二进制位,只是显示成了类似 “地址 / 十六进制编码” 的形式。
HEX() 会把 BIT 类型的二进制值,按 “十进制数值对应的十六进制” 转换 。比如:二进制 0(对应十进制 0 ),HEX() 转成字符串 0;二进制 1(对应十进制 1 ),HEX() 转成字符串 1 。结果就变成了直观的数值形式(0、1 ),因为 HEX() 函数专注于提取二进制的 “数值十六进制表示”,而非客户端默认的 “编码展示”。
不管怎么显示,online 列 存储的都是二进制位(比如 BIT(1) 存 0 或 1 的二进制 )。不同查询方式只是 “翻译” 成了人类易读的格式。
接着我们来修改 一下t3 表中 online 字段的数据类型,将其改为 BIT(10) 类型(即存储 10 位的二进制数据 )。
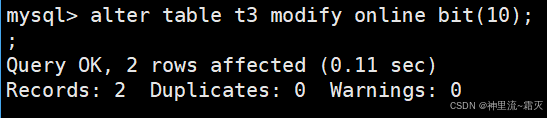
查看一下表 t3 中的数据结构。
我们来插入几组数据并查看一下。
我们不妨用字符也来试试呢?
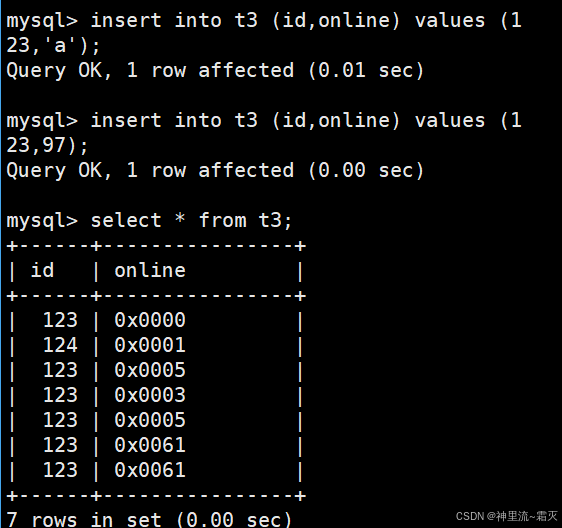
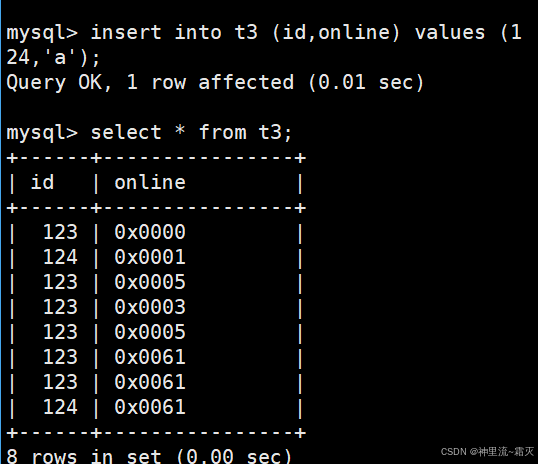
因为 online 字段类型是 BIT 类型,MySQL 会自动将字符 'a' 转换为对应的二进制值再存储。字符 'a' 的 ASCII 码是十进制 97,转换为二进制后存储到 BIT 字段中,后续查询时以十六进制等形式展示 。
online 字段的值以十六进制形式展示(如 0x0000、0x0001 等 ),这是因为 online 是 BIT 类型,MySQL 客户端默认将二进制的 BIT 数据转换为十六进制字符串来显示,方便查看 。
最后,bit字段在显示时,是按照ASCII码对应的值显示。如果我们有这样的值,只存放0或1,这时可以定义bit(1)。这样可以节省空间。
小数类型
float类型
在 MySQL 中,FLOAT 是用于种用于存储单精度浮点数的小数类型,适用于需要存储小数但对精度要求不是极高的场景。
语法:float[(m, d)] [unsigned] : M指定显示长度,d指定小数位数,占用空间4个字节(m 和 d 仅限制显示和插入时的格式,不改变 FLOAT 本身 6~7 位有效数字的精度上限。)
固定占用 4 字节,这是由单精度浮点数的标准(IEEE 754)决定的。
- 最小非零正值:约
1.175494351e-38 - 最大正值:约
3.402823466e+38 - 支持正负值(带符号)。
FLOAT 的精度约为 6~7 位有效数字(即从第一个非零数字开始,最多能精确表示 7 位数字。FLOAT 是单精度(4 字节),DOUBLE 是双精度(8 字节),DOUBLE 的精度更高(约 15~17 位有效数字),但占用空间更大。若对精度要求高(如金融数据),建议用 DOUBLE 或 DECIMAL;若仅需近似值(如科学计算、统计数据),FLOAT 更节省空间。
FLOAT 是 MySQL 中用于存储单精度浮点数的类型,优势是占用空间小(4 字节),适合存储精度要求不高的小数;但由于存在精度丢失风险,不适合需要精确计算的场景(如金融)。使用时需根据业务对精度和存储空间的需求,在 FLOAT、DOUBLE、DECIMAL 之间选择。
好,接下来我们来进行一下小小的测试。
创建一个新的表并查看一下这个表的数据结构。
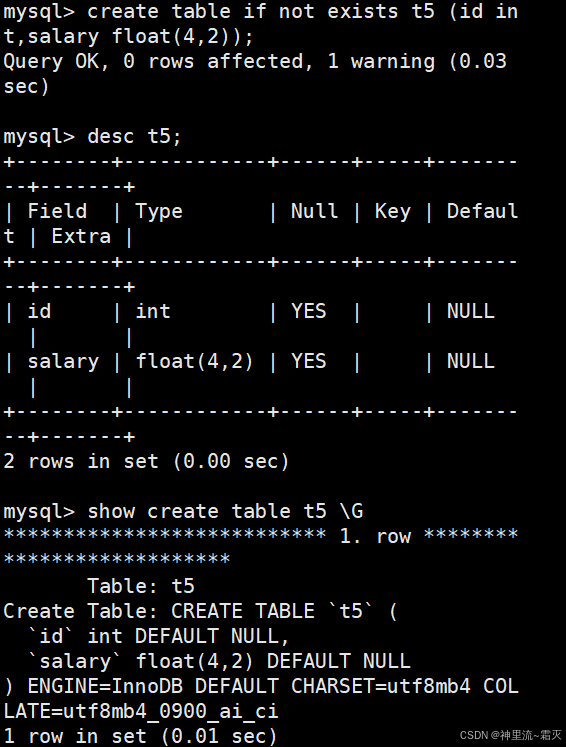
我们可以看到salary 字段类型为 float(4,2) ,其中 (4,2) 表示该 FLOAT 类型字段总共有 4 位数字(包括整数部分和小数部分 ),小数部分占 2 位 。
然后插入几组数据。
查看一下所插入的几组数据。
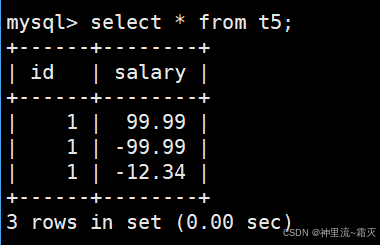
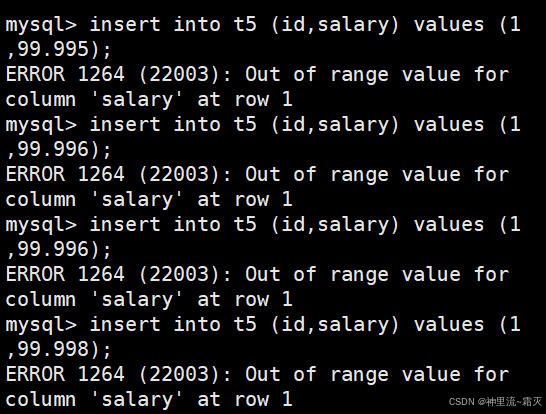
我们再来插入几组特别的数据。
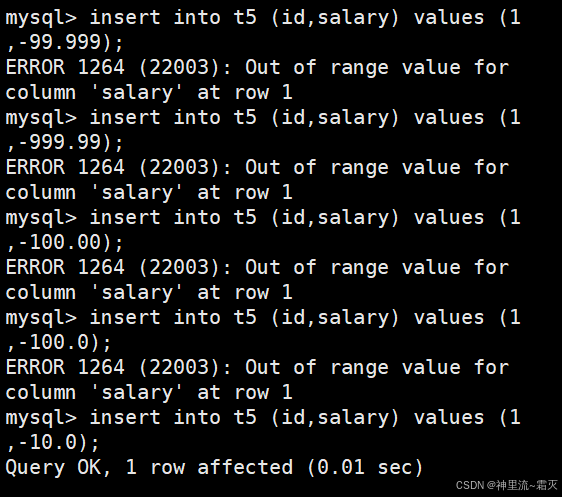
为什么这里插入数据会失败呢?
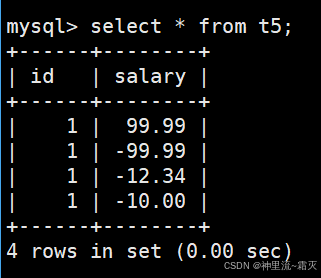
可以看出,“-10.0”这个值是被成功插入了的。
我们再来插入几组数据。
查看一下刚才所插入的数据。
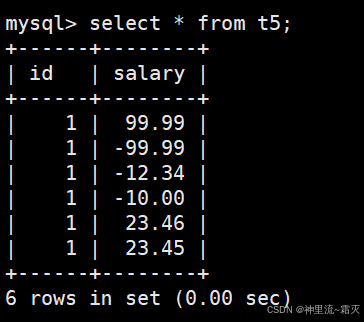
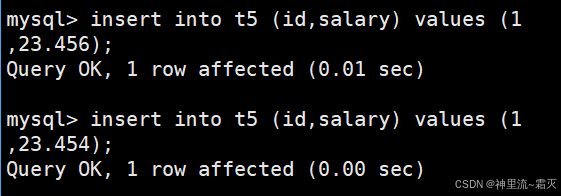
如果同学们还不理解的话,我们不妨再来多插入几组数据试试。
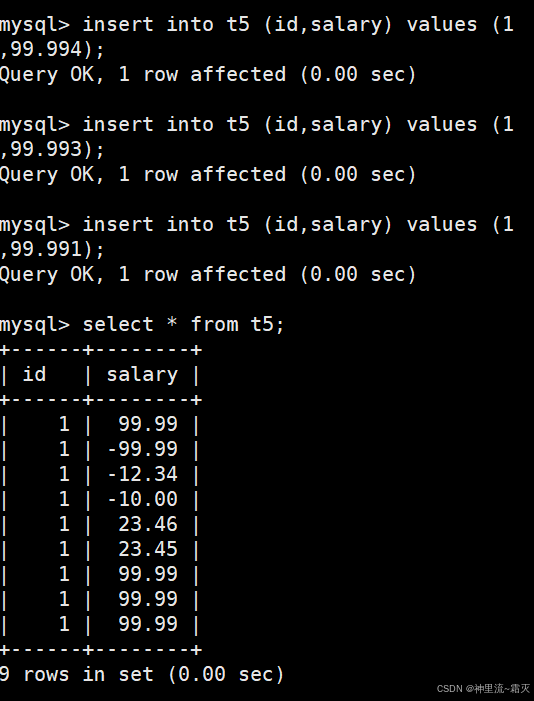
再来看一下这几组特别的数据。
到这里同学们能不能想到什么呢?四舍五入?对,就是四舍五入。
在 MySQL 中,FLOAT 类型的精度特性和四舍五入规则是其最容易被误解的部分,尤其涉及到小数存储和计算时的误差问题。
FLOAT 是单精度浮点数,遵循 IEEE 754 标准,其精度由存储方式决定。存储大小是4 字节(32 位),其中 1 位符号位、8 位指数位、23 位尾数位。有效数字约 6~7 位(从第一个非零数字开始计数)。这意味着超过 7 位的有效数字无法被精确存储,会被截断或近似。
这里有一个关于flaoat类型的问题的缺陷,就是二进制无法精确表示所有十进制小数。
计算机用二进制存储浮点数,但某些十进制小数(如 0.1、0.2)无法被二进制精确表示,只能存储近似值。例如:十进制 0.1 转换为二进制是无限循环小数 0.0001100110011...,FLOAT 只能存储其前 23 位近似值,导致实际存储值为 0.10000000149011612。
MySQL 对 FLOAT 类型的四舍五入主要发生在插入数据(我们在刚才的插入数据就遇到了这项的问题)和查询显示两个阶段。
1. 插入数据时的四舍五入(受 D 影响)
当插入的数值小数位数超过 D 时,会按四舍五入保留 D 位小数(一般情况下超过这个会报错);若整数部分长度超过 M-D(整数部分最大允许位数),则取决于 SQL 模式:
- 非严格模式(默认):截断并警告,保留最大值(如
FLOAT(5,2)插入123.456会变成99.99)。 - 严格模式(
STRICT_ALL_TABLES):直接报错(Data too long for column)。
2. 查询显示时的四舍五入(受 D 和客户端设置影响)
- 若定义了
D(如FLOAT(5,2)),查询时会自动按D位小数显示(即使存储的是近似值)。 - 若未定义
D(如FLOAT),客户端会根据数值大小自动选择显示格式,可能省略末尾的 0 或进行四舍五入。
FLOAT 是单精度浮点数,仅能精确存储 6~7 位有效数字,因二进制存储特性,部分十进制小数无法精确表示。四舍五入插入时:小数位超 D 则四舍五入(否则报错);整数部分超范围可能截断或报错(取决于 SQL 模式)。显示时:按 D 位小数或客户端规则四舍五入,不改变实际存储的近似值。
decimal类型
在 MySQL 中,DECIMAL 是一种用于存储精确数值的数据类型,专为需要高精度计算的场景设计,例如金融交易、货币金额、税率等对精度要求极高的领域。与浮点型(FLOAT/DOUBLE)相比,DECIMAL 能完全避免精度丢失问题,是处理精确数值的最佳选择。例如:DECIMAL(8, 2) 表示总共 8 位数字,其中小数点后占 2 位,可存储的范围是 -999999.99 到 999999.99。
语法: decimal(m, d) [unsigned] : 定点数m指定长度,d表示小数点的位数
- decimal(5,2) 表示的范围是 -999.99 ~ 999.99
- decimal(5,2) unsigned 表示的范围 0 ~ 999.99
- decimal和float很像,但是有区别: float和decimal表示的精度不一样
DECIMAL 以字符串形式存储数值(而非二进制浮点数),因此不会有精度损失,其存 储空间根据 M 动态分配。每 9 位数字占用 4 个字节;剩余数字按以下规则:1~2 位占 1 字节,3~4 位占 2 字节,5~6 位占 3 字节,7~9 位占 4 字节。例如:DECIMAL(18, 2):18 位数字 → 2 组 9 位 → 占用 8 字节。DECIMAL(5, 2):5 位数字 → 1 组 5 位 → 占用 3 字节。
| 类型 | 特点 | 适用场景 |
|---|---|---|
DECIMAL | 精确存储,无精度损失,速度较慢 | 货币、金额、税率等精确计算 |
FLOAT | 单精度浮点型,精度约 7 位,速度快 | 科学计算(可接受微小误差) |
DOUBLE | 双精度浮点型,精度约 15 位,速度快 | 科学计算(高精度需求) |
注意:float表示的精度大约是7位。 decimal整数最大位数m为65。支持小数最大位数d是30。如果d被省略,默认为0.如果m被省略, 默认是10。 建议:如果希望小数的精度高,推荐使用decimal
DECIMAL 是 MySQL 中处理精确数值的核心类型,通过 M 和 D 可灵活控制数值范围和精度,尤其适合金融、电商等对金额计算要求严格的场景。使用时需根据业务需求合理设置 M 和 D,平衡精度与存储空间。
同理,创建一个名为 t7 的表。
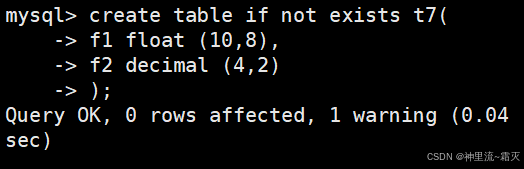
查看一下这个表的数据结构。
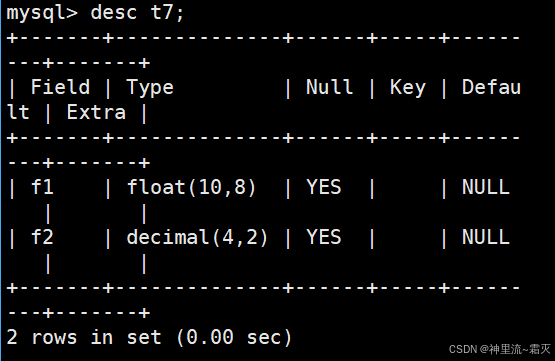
插入几组数据来测试一下。
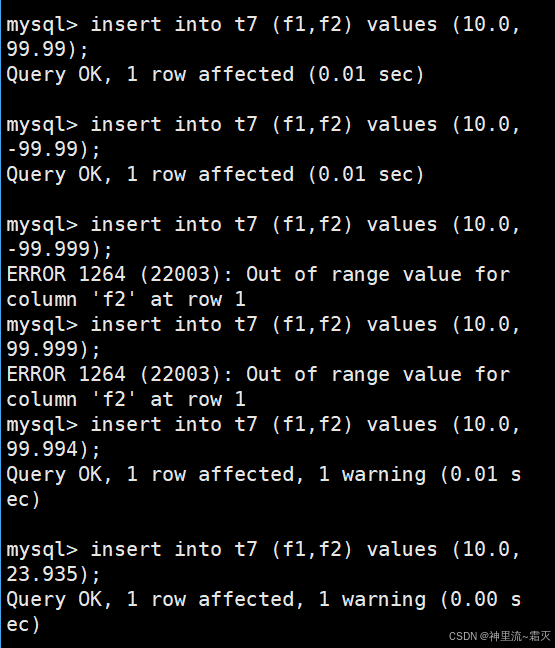
解释一下这两条报错信息。
两条报错均为 ERROR 1264 (22003): Out of range value for column 'f2' at row 1 ,关键原因是:f2 字段( DECIMAL 类型 )有预先定义的精度(总位数 M 和小数位数 D )限制,插入的 -99.999、99.999 这两个值,其小数位数或整体数值范围超出了 f2 字段定义的范围,导致 MySQL 判定为 “超出范围(Out of range)”,从而拒绝插入操作 。
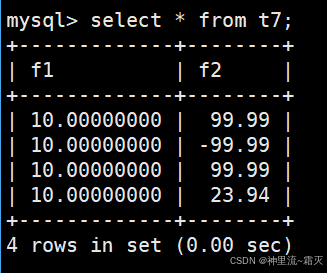
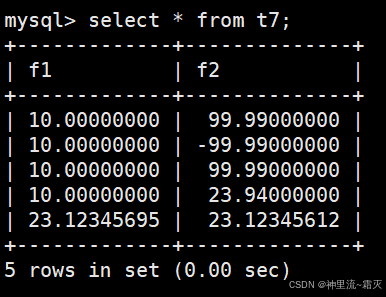
查看一下表t7中的数据。
试着修改一下表结构。
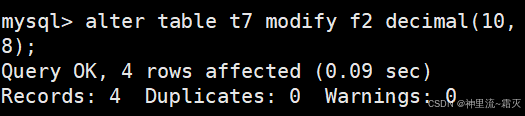
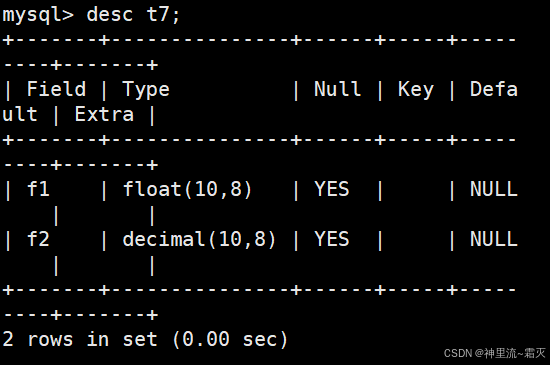
查看一下表结构。
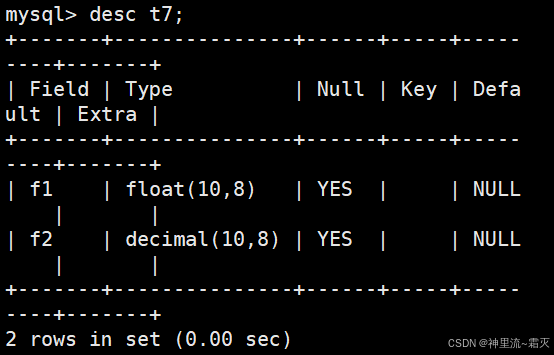
然后插入两组较长数据进行测试。

查看一下插入的结果。
最后查看一下表的数据结构。
字符串类型
char
在 MySQL 中,CHAR 是一种固定长度的字符串类型,适用于存储长度相对固定的字符数据。
语法: char(L): 固定长度字符串,L是可以存储的长度,单位为字符,最大长度值可以为255(L:表示字符串的固定长度,范围为 0~255 个字符(默认值为 1))。
- 例如:
CHAR(10)表示存储固定长度为 10 的字符串。 - 例如: char(2) 表示可以存放两个字符,可以是字母或汉字,但是不能超过2个, 最多只能是255
与 VARCHAR 类型的对比
| 特性 | CHAR(L) | VARCHAR(L) |
|---|---|---|
| 长度特性 | 固定长度,不足补空格 | 可变长度,仅占用实际字符 + 1~2 字节长度标识 |
| 适用场景 | 长度固定的数据(如手机号、性别) | 长度可变的数据(如姓名、地址) |
| 存储空间 | 始终占用 L 个字符对应的字节 | 随实际内容长度动态变化 |
| 尾部空格处理 | 插入时补空格,读取时自动截断 | 保留尾部空格(插入时不补,读取时不截) |
| 性能 | 读写速度快(适合频繁查询的固定字段) | 读写速度略慢(需处理长度标识) |
CHAR 类型适合存储长度固定的字符串,通过牺牲部分存储空间换取更高的读写性能。在设计表结构时,若字段长度基本固定(如证件号、状态码等),优先选择 CHAR;若长度差异较大(如描述信息、备注等),则更适合 VARCHAR。
同理,创建名为t8的表,并查看一下它的表结构。
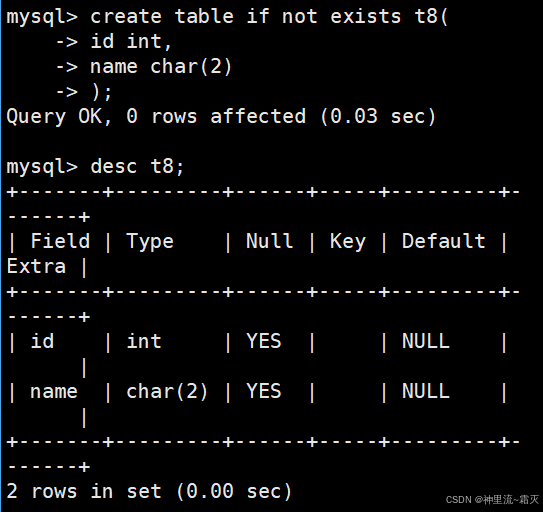
然后插入几组数据。
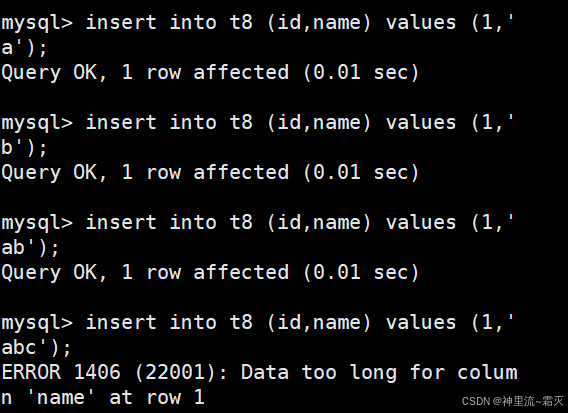
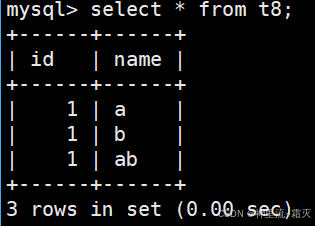
可以看出这张图片中有几条错误信息,这是因为在执行向 t8 表插入数据的操作时,name 字段接收到的数据长度超过了该字段定义的长度限制 ,导致第 1 行插入失败 。
查看一下我们刚下向表t8插入的几组数据。
对于 adders 字段,定义的长度(256 )超过了 CHAR 类型字段长度的最大值(255 );MySQL 中 CHAR 类型允许的最大长度是 255 个字符,若需要存储更长的字符数据,建议使用 BLOB(二进制大对象,适合存储图片、文件等二进制数据 )或 TEXT(文本类型,适合存储长文本 ,又细分为 TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT 等,有不同的存储上限 )类型来替代 。
简单说,就是创建表时,CHAR 类型字段 adders 定义的长度 256 超过了 MySQL 规定的 CHAR 最大长度 255,所以创建失败,需换类型解决 。
varchar类型
在 MySQL 中,VARCHAR是一种可变长度的字符串数据类型,用于存储可变长度的字符数据。
语法: varchar(L): 可变长度字符串,L表示字符长度,最大长度65535个字节。
VARCHAR存储数据时,实际占用的空间由两部分组成,即字符串本身占用的字节数加上用于记录字符串长度的字节数。记录长度的字节数与N的大小有关:
- 当
N不超过 255 时,使用 1 个字节来记录长度。比如VARCHAR(10)存储字符串"hello",占用的空间是字符串本身的 5 个字节加上记录长度的 1 个字节,共 6 个字节。 - 当
N大于 255 时,使用 2 个字节来记录长度。
对于长度变化较大的字符串数据,相比固定长度的CHAR类型,VARCHAR不会像CHAR那样不管实际内容长短都占用固定长度的空间,因此能有效节省存储空间。例如存储不同长度的用户评论,VARCHAR更合适。
与 CHAR 类型的对比
| 特性 | VARCHAR(N) | CHAR(N) |
|---|---|---|
| 长度特性 | 可变长度,根据实际存储内容占用空间 | 固定长度,无论实际内容长短,都占用固定的 N 个字符空间 |
| 适用场景 | 适合存储长度不确定、变化较大的字符串,如文章内容、商品描述 | 适合存储长度固定的字符串,如身份证号、邮编、性别标识(男 / 女 ) |
| 存储空间 | 字符串实际长度 + 长度记录字节数(1 或 2 字节) | 始终占用 N 个字符对应的字节数 |
| 尾部空格处理 | 保留尾部空格 | 插入时自动填充空格至 N 长度,读取时自动去除尾部空格 |
| 性能 | 插入和更新时可能因长度变化产生额外开销,性能略逊于 CHAR;查询性能在合理索引下影响不大 | 固定长度便于数据定位,读写性能相对较高 |
最后,MySQL数据库类型初阶的数据类型就先暂时讲到这里,varchar类型的测试这里由于实践关系就不做测试了,过程都是和前面一样的。