【PyTorch从入门到实战】全面解析PyTorch框架:安装、原理、MNIST实战与核心组件
目录
引言:为什么选择PyTorch?
一、深度学习核心框架全面对比
关键结论:
二、PyTorch环境安装指南(CPU/GPU双版本)
2.1 前置准备:检查硬件与系统
2.2 CPU版本安装(超简单!)
2.3 GPU版本安装(重点!详细步骤前文有详细流程步骤截图)
步骤1:理解CUDA与显卡驱动的关系
步骤2:查看显卡信息与支持的CUDA版本
步骤3:安装CUDA Toolkit
步骤4:安装cuDNN(GPU加速库)
步骤5:安装PyTorch GPU版本
步骤6:验证GPU版本安装成功
2.4 常见安装问题解决
三、深入理解:为什么深度学习需要GPU?
3.1 CPU与GPU的核心结构对比
3.2 显卡核心参数解读(选购/使用参考)
3.3 深度学习中GPU的优势体现
四、PyTorch实战:MNIST手写数字识别(完整流程)
4.1 步骤1:导入依赖库
4.2 步骤2:加载与预处理MNIST数据集
2.1 下载数据集
2.2 用DataLoader批量加载数据
2.3 可视化数据集
4.3 步骤3:构建神经网络模型
3.1 定义模型类
3.2 初始化模型与设备配置
4.4 步骤4:定义损失函数与优化器
4.5 步骤5:模型训练
5.1 定义训练函数
5.2 定义测试函数
5.3 运行训练与测试
训练结果示例(GPU版):
4.6 步骤6:模型预测
五、深度学习优化器:原理、对比与选择
5.1 三种基础优化器:BGD、SGD、Mini-batch GD
5.2 进阶优化器:解决SGD的缺陷
1. 动量梯度下降(Momentum)
2. AdaGrad(自适应梯度)
3. RMSprop(Root Mean Square Prop)
4. Adam(Adaptive Moment Estimation)
5. AdamW
5.3 优化器选择建议
六、激活函数与梯度问题:从根源解决训练难题
6.1 为什么需要激活函数?
6.2 常见激活函数对比
6.3 梯度消失与梯度爆炸:根源与解决方法
6.3.1 问题根源:反向传播的连乘效应
6.3.2 解决方法
6.4 PyTorch中激活函数的使用
七、总结与进阶建议
7.1 核心知识点回顾
7.2 进阶学习建议
引言:为什么选择PyTorch?
在深度学习飞速发展的今天,选择一款合适的框架是入门和进阶的关键第一步。无论是学术研究、工业落地还是个人项目开发,一个易用、高效、生态完善的框架能极大降低开发成本,提升研发效率。
目前深度学习领域主流框架众多,但PyTorch凭借其"上手极容易、代码简洁直观、支持动态计算图"等优势,逐渐成为科研界和工业界的"新宠"——在GitHub上星标数量突破70万,各大招聘平台(如BOSS直聘、拉勾网)的深度学习岗位中,PyTorch技能需求占比已超过TensorFlow,成为名副其实的"主流框架"。
本文将基于PyTorch核心知识点,从"框架对比→环境安装→硬件原理→实战开发→核心组件解析"五个维度,带大家全面掌握PyTorch框架,即使是零基础也能快速入门!
一、深度学习核心框架全面对比
在学习PyTorch之前,我们先搞清楚:主流深度学习框架有哪些?各自的优缺点是什么?为什么PyTorch能脱颖而出?
下表整理了4款经典框架的核心特性,结合PPT内容和实际开发经验进行详细分析:
| 框架 | 开发公司/机构 | 核心优势 | 主要缺点 | 适用场景 |
|---|---|---|---|---|
| Caffe | Berkeley | 仅需配置文件即可搭建模型,无需编写代码 | 1. 安装流程复杂,依赖库兼容性差; | 早期CV领域固定模型(如AlexNet) |
| TensorFlow | | 1. 生态最完善,支持多平台(端侧、云端); | 1. 1.x版本代码冗余,动态图支持差; | 工业界大规模部署(如推荐系统、端侧AI) |
| Keras | 独立开发(后被Google收购) | 1. 基于TensorFlow封装,API极简; | 1. 灵活性差,自定义模型难度高; | 零基础入门、快速验证简单模型 |
| PyTorch | | 1. 支持动态计算图,调试直观; | 1. 早期工业部署工具不如TensorFlow成熟; | 科研实验、快速原型开发、工业界CV/NLP |
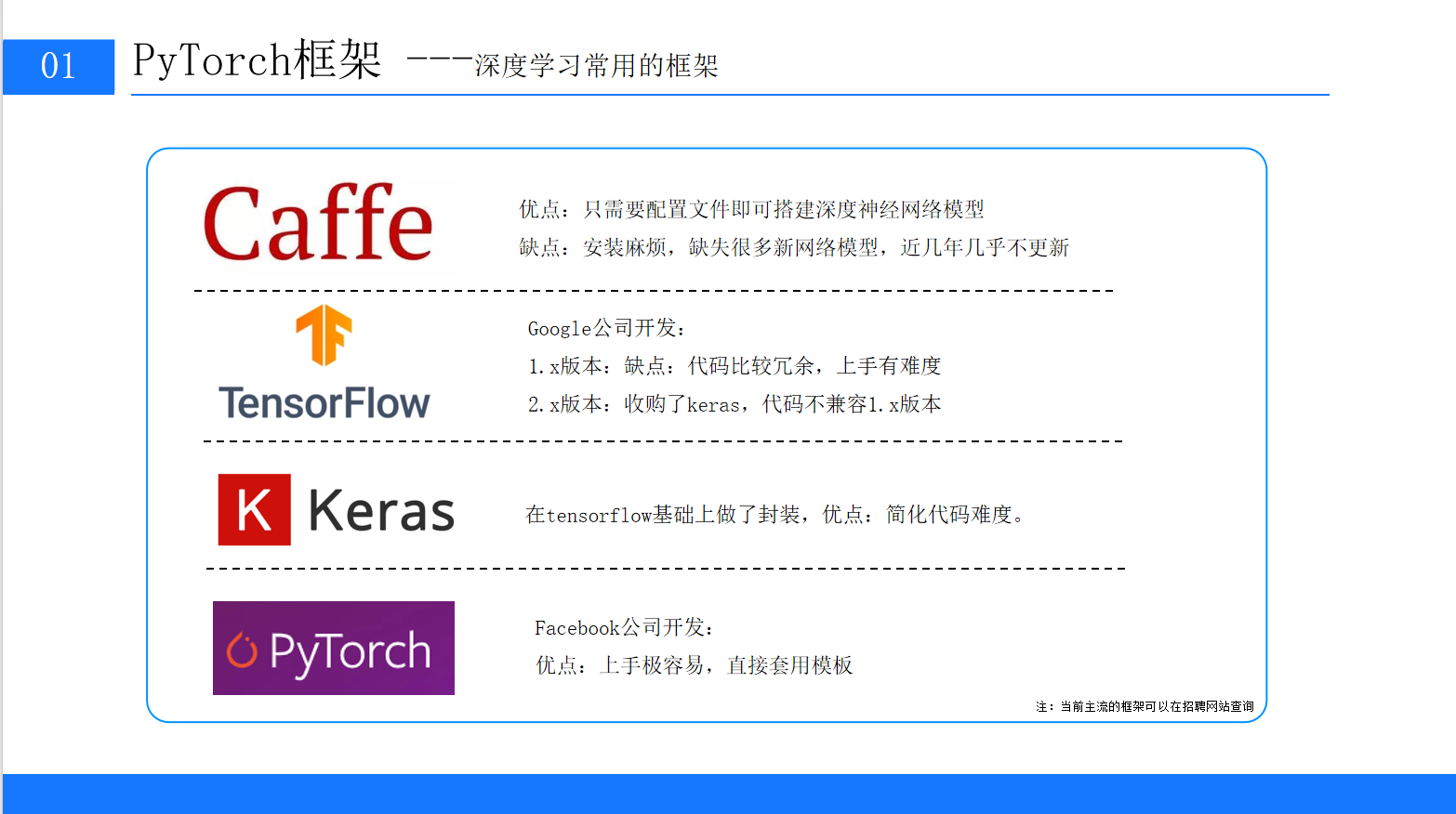
关键结论:
-
如果你是零基础入门:优先选PyTorch,其"Pythonic"的语法风格(如类定义、函数调用)与Python完全一致,无需额外学习复杂API;
-
如果你专注科研创新:PyTorch支持动态图,修改模型时无需重新定义计算图,调试效率远超TensorFlow 1.x;
-
如果你需要工业部署:PyTorch近年已完善部署生态(如TorchScript、ONNX、TorchServe),完全能满足大规模生产需求。
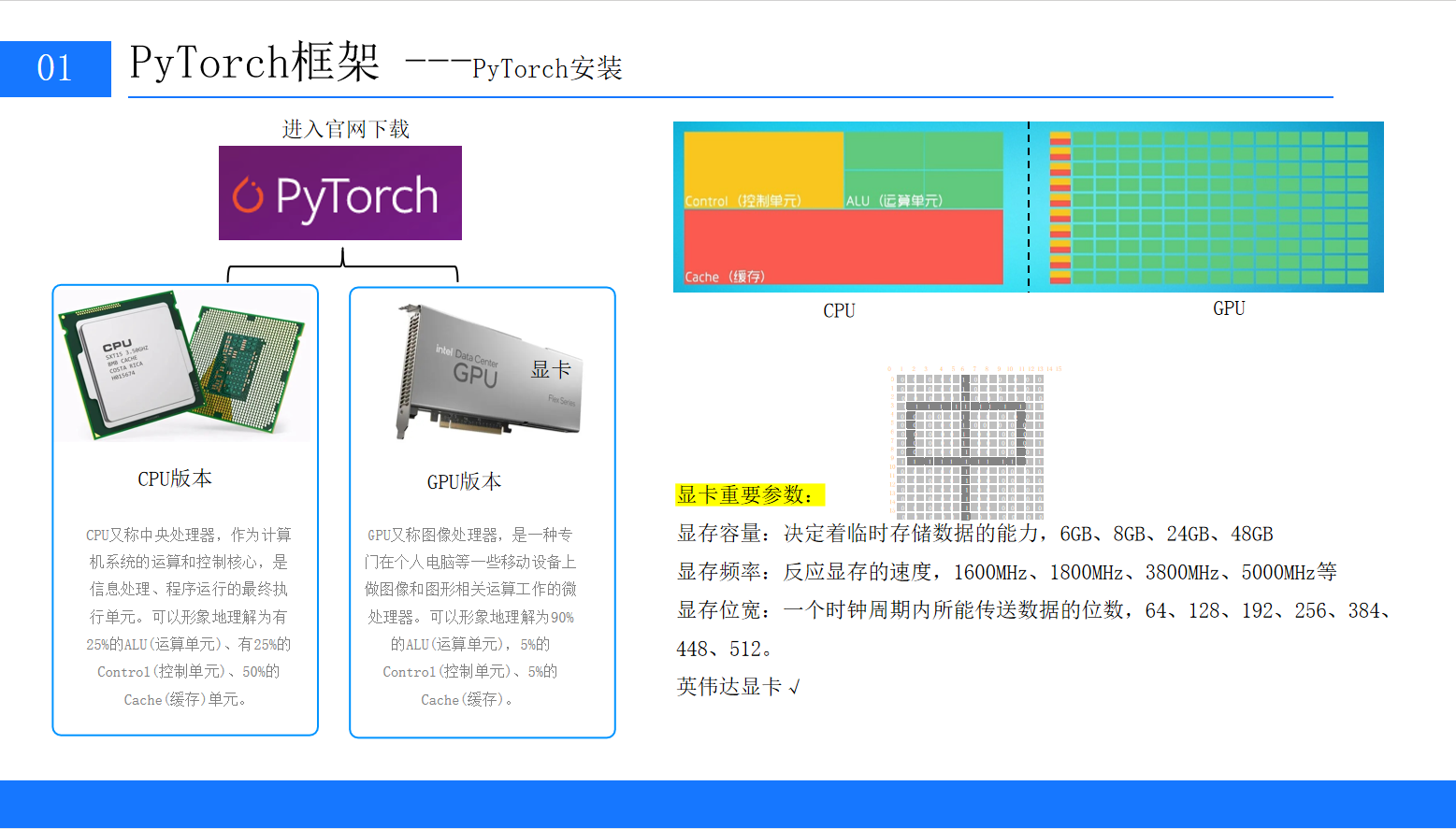
二、PyTorch环境安装指南(CPU/GPU双版本)
安装是入门的第一步,也是最容易踩坑的环节。PyTorch分为CPU版本和GPU版本:
-
CPU版本:适用于入门学习、小规模数据实验(无需显卡);
-
GPU版本:依赖NVIDIA显卡(AMD显卡暂不支持官方CUDA),适用于大规模数据训练(速度比CPU快10-100倍)。
2.1 前置准备:检查硬件与系统
-
系统要求:Windows 10/11、macOS 12+、Linux(Ubuntu 20.04推荐);
-
Python版本:3.8-3.11(PyTorch官方不支持Python 3.12及以上版本,避免版本不兼容);
-
GPU要求:仅NVIDIA显卡支持(需确认显卡是否在CUDA支持列表中,如RTX 3060、RTX 4090、Tesla V100等)。
2.2 CPU版本安装(超简单!)
CPU版本无需依赖显卡,直接通过pip命令安装,步骤如下:
-
验证Python环境:
打开终端(Windows用CMD/PowerShell,macOS/Linux用终端),输入以下命令,确认Python版本在3.8-3.11之间:
python --version # 或 python3 --version(macOS/Linux) -
安装PyTorch:
直接执行官方CPU版本安装命令(截至2024年5月,最新稳定版为2.2.2):
pip install torch==2.2.2+cpu torchvision==0.17.2+cpu torchaudio==2.2.2+cpu -f https://download.pytorch.org/whl/torch_stable.html -
验证安装成功:
终端输入
python进入Python交互环境,执行以下代码,无报错则说明安装成功:import torch print(torch.__version__) # 输出2.2.2+cpu print(torch.cuda.is_available()) # 输出False(CPU版本不支持CUDA)
2.3 GPU版本安装(重点!详细步骤前文有详细流程步骤截图)
GPU版本依赖CUDA(NVIDIA的并行计算架构)和cuDNN(GPU加速深度学习库),安装步骤需严格遵循"版本兼容"原则,否则会出现"显卡驱动不匹配""CUDA无法调用"等问题。
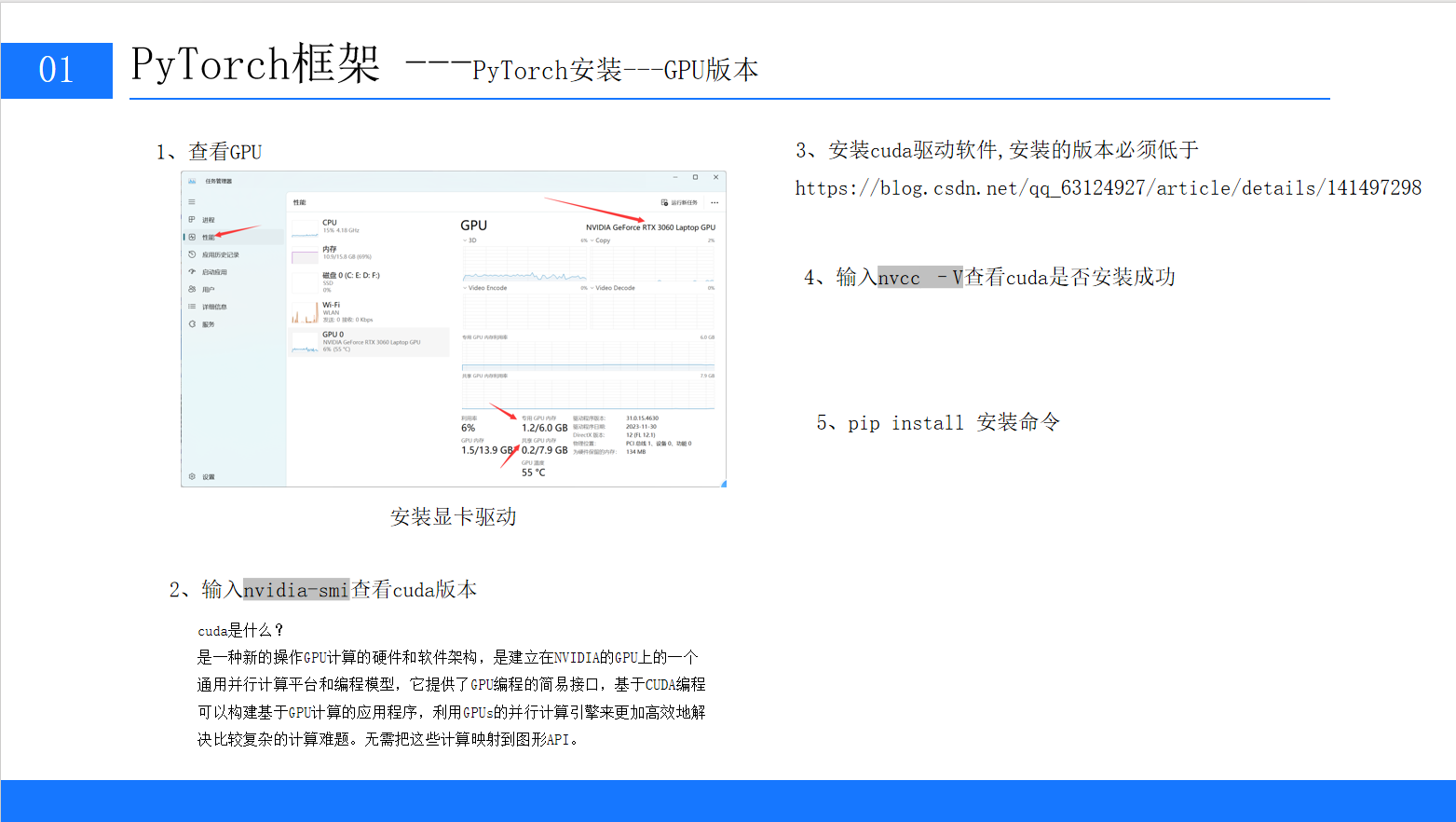
步骤1:理解CUDA与显卡驱动的关系
-
CUDA:是NVIDIA提供的GPU编程框架,PyTorch通过CUDA调用GPU资源;
-
显卡驱动:是连接操作系统和显卡的桥梁,必须满足"驱动版本 ≥ CUDA版本要求"(如CUDA 12.1需要驱动版本≥530.30.02)。
步骤2:查看显卡信息与支持的CUDA版本
-
打开终端,输入以下命令(Windows/Linux通用),查看显卡型号和支持的最高CUDA版本:
nvidia-smi # 需安装NVIDIA显卡驱动才能执行执行结果示例(以RTX 3060 Laptop GPU为例):
NVIDIA-SMI 546.33 Driver Version: 546.33 CUDA Version: 12.3关键信息:
-
Driver Version:显卡驱动版本(546.33,满足CUDA 12.3及以下版本需求); -
CUDA Version:显卡支持的最高CUDA版本(12.3,实际安装时可选择≤12.3的版本)。
-
-
若执行
nvidia-smi报错,说明未安装显卡驱动:-
Windows:前往NVIDIA官网,输入显卡型号下载驱动;
-
Ubuntu:通过命令
sudo ubuntu-drivers autoinstall自动安装推荐驱动。
-
步骤3:安装CUDA Toolkit
-
选择CUDA版本:建议选择"PyTorch官方支持的CUDA版本"(而非显卡支持的最高版本),避免兼容性问题。截至2024年5月,PyTorch 2.2.2支持的CUDA版本为11.8、12.1。
-
下载CUDA:
前往CUDA Toolkit下载页,选择对应系统和版本(以Windows 11、CUDA 12.1为例):
-
操作系统:Windows 11;
-
架构:x86_64;
-
安装类型:exe (local)。
-
-
安装CUDA:
-
双击安装包,选择"自定义安装";
-
取消勾选"Visual Studio Integration"(无需依赖VS);
-
安装路径默认即可(如
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1)。
-
-
验证CUDA安装:
打开新终端,输入以下命令,输出CUDA版本则说明安装成功:
nvcc -V # 注意是大写V成功结果:
Cuda compilation tools, release 12.1, V12.1.105
步骤4:安装cuDNN(GPU加速库)
cuDNN是NVIDIA专门为深度学习优化的库,能大幅提升卷积、池化等操作的速度:
-
前往cuDNN下载页,选择与CUDA版本匹配的cuDNN(如CUDA 12.1对应cuDNN 8.9.7);
-
下载后解压,将
bin、include、lib三个文件夹中的文件,分别复制到CUDA安装目录的对应文件夹下(如C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\bin)。
步骤5:安装PyTorch GPU版本
-
前往PyTorch官网,选择对应配置(以CUDA 12.1为例):
-
PyTorch Build:Stable (2.2.2);
-
OS:Windows;
-
Package:Pip;
-
Language:Python;
-
CUDA:12.1。
-
-
复制生成的安装命令,在终端执行:
pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu121
步骤6:验证GPU版本安装成功
进入Python交互环境,执行以下代码:
import torch
print(torch.__version__) # 输出2.2.2+cu121
print(torch.cuda.is_available()) # 输出True(表示GPU可用)
print(torch.cuda.get_device_name(0)) # 输出显卡型号(如NVIDIA GeForce RTX 3060 Laptop GPU)若torch.cuda.is_available()返回True,则GPU版本安装成功!
2.4 常见安装问题解决
-
"nvidia-smi显示的CUDA版本与nvcc -V不一致":
-
原因:
nvidia-smi显示的是显卡支持的最高CUDA版本,nvcc -V显示的是实际安装的CUDA版本,两者不一致是正常的,只要安装的CUDA版本≤最高版本即可。
-
-
"torch.cuda.is_available()返回False":
-
检查CUDA版本与PyTorch是否匹配(如CUDA 12.1需对应PyTorch cu121版本);
-
检查显卡驱动版本是否满足CUDA要求(参考NVIDIA官网的驱动-CUDA对应表)。
-
-
"pip安装速度慢":
-
临时使用国内源(如阿里云):
pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu121 -i https://mirrors.aliyun.com/pypi/simple/
-
2.使用whl本地下载:(前文有详细介绍)
CUDA安装与PyTorch框架安装与初步认识-CSDN博客
三、深入理解:为什么深度学习需要GPU?
很多初学者会疑惑:"CPU也能跑模型,为什么一定要用GPU?"这需要从CPU和GPU的硬件结构差异说起。
3.1 CPU与GPU的核心结构对比
PPT中用"运算单元(ALU)、控制单元(Control)、缓存(Cache)"的比例,形象地展示了两者的区别:
| 硬件 | ALU(运算单元)占比 | Control(控制单元)占比 | Cache(缓存)占比 | 核心特点 |
|---|---|---|---|---|
| CPU(中央处理器) | 25% | 25% | 50% | 1. 控制单元强,擅长逻辑判断; |
| GPU(图像处理器) | 90% | 5% | 5% | 1. 运算单元极多(数千核心); |
通俗比喻:
-
CPU像"全能项目经理",擅长处理复杂逻辑、协调多个任务,但同时处理的任务数量有限;
-
GPU像"工厂流水线工人",虽然单个工人能力有限,但 thousands of 工人同时工作,能快速完成大量重复计算(如深度学习中的矩阵乘法)。
3.2 显卡核心参数解读(选购/使用参考)
如果需要选购显卡或优化模型训练速度,需关注以下3个核心参数:
-
显存容量:
-
作用:临时存储模型参数、训练数据(如 batch_size=64 的MNIST数据需占用约100MB显存);
-
推荐:入门级(6GB,如RTX 3060)、进阶级(12GB,如RTX 4070)、工业级(24GB+,如RTX A100);
-
注意:显存不足会导致"CUDA out of memory"错误,可通过减小 batch_size 解决。
-
-
显存频率:
-
作用:反映显存读写速度,频率越高,数据传输越快;
-
常见值:1600MHz、3800MHz、5000MHz(需注意"有效频率",如GDDR6显存会翻倍,3800MHz实际为7600MHz)。
-
-
显存位宽:
-
作用:一个时钟周期内传输数据的位数,位宽越大,带宽越高(带宽=频率×位宽/8);
-
常见值:64bit(入门)、256bit(中端)、384bit(高端);
-
例:RTX 3060(192bit)的带宽远高于RTX 2060(128bit),训练速度更快。
-
3.3 深度学习中GPU的优势体现
以"MNIST手写数字识别"为例,对比CPU和GPU的训练速度:
-
CPU(i7-12700H):训练1个epoch(60000张图片)需约30秒;
-
GPU(RTX 3060 Laptop):训练1个epoch仅需约2秒,速度提升15倍!
原因:深度学习中的"前向传播"和"反向传播"本质是矩阵乘法(如28×28的图片展平为784维向量,与128维的权重矩阵相乘),GPU的数千个ALU可同时计算矩阵中的每个元素,而CPU只能串行计算。
四、PyTorch实战:MNIST手写数字识别(完整流程)
理论讲完,我们通过经典的"MNIST手写数字识别"案例,实战PyTorch的核心流程:数据加载→模型构建→训练→测试。
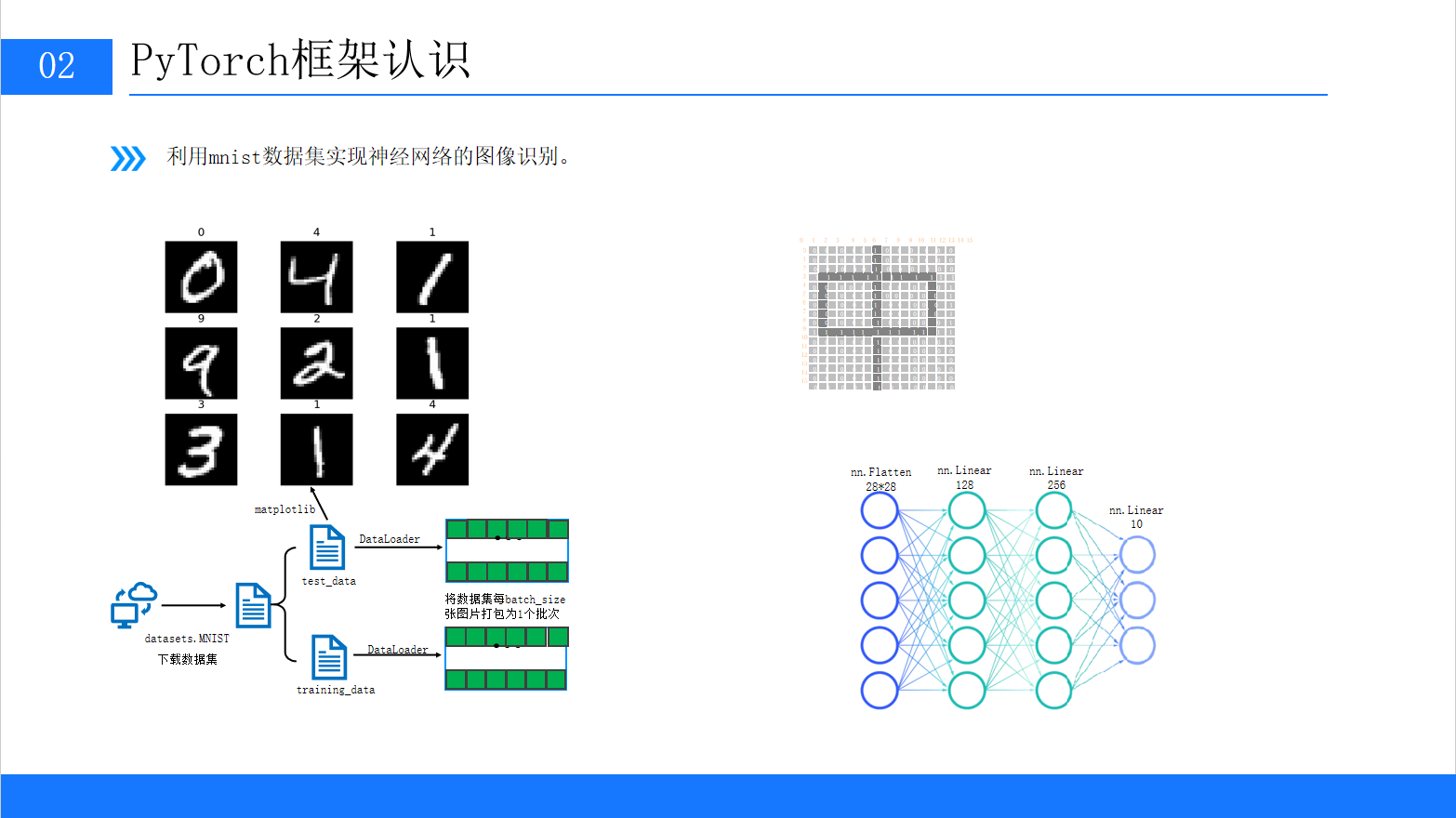
MNIST数据集包含60000张训练图片和10000张测试图片,每张图片是28×28的灰度图,标签为0-9的数字。
4.1 步骤1:导入依赖库
首先导入PyTorch核心库、数据加载库和可视化库:
# 导入PyTorch核心库
import torch
import torch.nn as nn # 神经网络模块
import torch.optim as optim # 优化器模块
from torch.utils.data import DataLoader # 数据加载器 # 导入MNIST数据集和图像预处理库
from torchvision import datasets # 内置数据集
from torchvision.transforms import ToTensor # 图像转Tensor # 导入可视化库
import matplotlib.pyplot as plt4.2 步骤2:加载与预处理MNIST数据集
PyTorch的torchvision.datasets模块已内置MNIST数据集,可直接下载并使用;DataLoader用于将数据集按batch_size打包,方便批量训练。
2.1 下载数据集
# 下载训练集(train=True)
training_data = datasets.MNIST( root="data", # 数据集保存路径 train=True, # 是否为训练集 download=True, # 若本地无数据,则自动下载 transform=ToTensor() # 预处理:将PIL图像转为Tensor(维度:[1,28,28],值范围[0,1])
) # 下载测试集(train=False)
test_data = datasets.MNIST( root="data", train=False, download=True, transform=ToTensor()
)-
下载说明:首次运行会自动下载约10MB的数据集,保存在
./data目录下; -
数据维度:每张图片的Tensor形状为
(1, 28, 28),其中1表示灰度通道(彩色图为3),28×28是图片分辨率。
2.2 用DataLoader批量加载数据
batch_size = 64 # 每个批次包含64张图片 # 训练集DataLoader(shuffle=True:每次训练前打乱数据,提升泛化能力)
train_dataloader = DataLoader(training_data, batch_size=batch_size, shuffle=True) # 测试集DataLoader(shuffle=False:测试时无需打乱数据)
test_dataloader = DataLoader(test_data, batch_size=batch_size, shuffle=False)-
batch_size选择:显存不足时减小(如32),显存充足时增大(如128),越大训练速度越快; -
数据迭代:
train_dataloader是可迭代对象,每次迭代返回(X, y),其中X是(64,1,28,28)的Tensor,y是(64,)的标签(0-9)。
2.3 可视化数据集
用matplotlib查看几张训练图片,直观了解数据:
# 从训练集中取一个批次
train_features, train_labels = next(iter(train_dataloader))
print(f"特征维度: {train_features.shape}") # 输出:特征维度: torch.Size([64, 1, 28, 28])
print(f"标签维度: {train_labels.shape}") # 输出:标签维度: torch.Size([64]) # 可视化第1张图片
plt.figure(figsize=(3, 3))
plt.imshow(train_features[0].squeeze(), cmap="gray") # squeeze()去除通道维度(1,28,28)→(28,28)
plt.title(f"Label: {train_labels[0].item()}")
plt.axis("off")
plt.show()运行后会显示一张28×28的灰度数字图片,标签为对应的数字(如5)。
4.3 步骤3:构建神经网络模型
我们构建一个简单的全连接神经网络,结构如下(参考PPT):
输入层(28×28=784维)→ Flatten(展平)→ 隐藏层1(128维,ReLU激活)→ 隐藏层2(256维,ReLU激活)→ 输出层(10维,对应0-9数字)
3.1 定义模型类
PyTorch中模型需继承nn.Module,并重写__init__(定义层)和forward(前向传播)方法:
class NeuralNetwork(nn.Module): def __init__(self): super().__init__() # 调用父类构造函数 # 1. 展平层:将(1,28,28)的图像展平为784维向量 self.flatten = nn.Flatten() # 2. 全连接层序列:Linear(线性变换)+ ReLU(激活函数) self.linear_relu_stack = nn.Sequential( nn.Linear(28 * 28, 128), # 输入784维,输出128维 nn.ReLU(), # 激活函数:ReLU(x) = max(0, x) nn.Linear(128, 256), # 输入128维,输出256维 nn.ReLU(), nn.Linear(256, 10) # 输入256维,输出10维(对应10个数字) ) # 前向传播:定义数据流向 def forward(self, x): x = self.flatten(x) # 展平:(batch_size,1,28,28) → (batch_size,784) logits = self.linear_relu_stack(x) # 经过全连接层:(batch_size,784) → (batch_size,10) return logits3.2 初始化模型与设备配置
将模型移动到GPU(若可用),提升训练速度:
# 配置设备:优先使用GPU,若无则用CPU
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"使用设备: {device}") # 初始化模型并移动到设备
model = NeuralNetwork().to(device)
print(model) # 打印模型结构运行后输出模型结构:
使用设备: cuda
NeuralNetwork( (flatten): Flatten(start_dim=1, end_dim=-1) (linear_relu_stack): Sequential( (0): Linear(in_features=784, out_features=128, bias=True) (1): ReLU() (2): Linear(in_features=128, out_features=256, bias=True) (3): ReLU() (4): Linear(in_features=256, out_features=10, bias=True) )
)4.4 步骤4:定义损失函数与优化器
-
损失函数:用于衡量模型预测值与真实标签的差距,分类任务常用
CrossEntropyLoss; -
优化器:用于更新模型参数,最小化损失函数,常用
Adam(自适应学习率,收敛快)。
# 损失函数:交叉熵损失(适用于多分类任务)
loss_fn = nn.CrossEntropyLoss() # 优化器:Adam优化器,学习率lr=1e-3(超参数,可调整)
optimizer = optim.Adam(model.parameters(), lr=1e-3)-
学习率
lr:过大可能导致训练不稳定(损失波动大),过小可能导致收敛慢,常用值为1e-4~1e-2; -
model.parameters():自动获取模型中所有可训练参数(如Linear层的权重和偏置)。
4.5 步骤5:模型训练
训练流程核心是"前向传播→计算损失→反向传播→更新参数",循环多个epoch(遍历整个训练集的次数)。
5.1 定义训练函数
def train(dataloader, model, loss_fn, optimizer): size = len(dataloader.dataset) # 训练集总样本数(60000) model.train() # 切换到训练模式(启用Dropout、BatchNorm等) # 遍历每个批次 for batch, (X, y) in enumerate(dataloader): # 将数据移动到设备(GPU/CPU) X, y = X.to(device), y.to(device) # 1. 前向传播:计算模型预测值 pred = model(X) # 2. 计算损失 loss = loss_fn(pred, y) # 3. 反向传播:计算梯度 loss.backward() # 4. 更新参数:根据梯度调整模型参数 optimizer.step() # 5. 清空梯度:避免下一个批次的梯度累积 optimizer.zero_grad() # 每100个批次打印一次训练信息 if batch % 100 == 0: loss, current = loss.item(), (batch + 1) * len(X) print(f"损失: {loss:>7f} [{current:>5d}/{size:>5d}]")5.2 定义测试函数
测试函数用于评估模型在测试集上的性能(准确率),不更新参数:
def test(dataloader, model, loss_fn): size = len(dataloader.dataset) # 测试集总样本数(10000) num_batches = len(dataloader) # 测试集批次数 model.eval() # 切换到评估模式(禁用Dropout、BatchNorm等) test_loss, correct = 0, 0 # 禁用梯度计算(测试时无需反向传播,节省内存) with torch.no_grad(): for X, y in dataloader: X, y = X.to(device), y.to(device) pred = model(X) # 累加测试损失 test_loss += loss_fn(pred, y).item() # 累加正确预测数(pred.argmax(1)取预测概率最大的类别) correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 计算平均损失和准确率 test_loss /= num_batches correct /= size print(f"测试误差: \n 准确率: {(100*correct):>0.1f}%, 平均损失: {test_loss:>8f} \n")5.3 运行训练与测试
设置epochs=5(遍历5次训练集),每次训练后测试模型性能:
epochs = 5
for t in range(epochs): print(f"Epoch {t+1}\n-------------------------------") train(train_dataloader, model, loss_fn, optimizer) test(test_dataloader, model, loss_fn)
print("训练完成!")训练结果示例(GPU版):
Epoch 1
-------------------------------
损失: 2.302588 [ 64/60000]
损失: 0.321456 [ 6464/60000]
损失: 0.198765 [12864/60000]
...
测试误差: 准确率: 97.2%, 平均损失: 0.089765 Epoch 2
-------------------------------
...
测试误差: 准确率: 98.1%, 平均损失: 0.058432 ... Epoch 5
-------------------------------
...
测试误差: 准确率: 98.7%, 平均损失: 0.038211 训练完成!可以看到,随着epoch增加,训练损失逐渐降低,测试准确率逐渐提升,最终达到98.7%,效果良好。
4.6 步骤6:模型预测
训练完成后,用模型预测新的手写数字图片:
# 从测试集中取一张图片
x, y = test_data[0][0], test_data[0][1] # 预测
model.eval()
with torch.no_grad(): x = x.to(device) pred = model(x) predicted = pred.argmax(1).item() # 预测类别 actual = y # 真实类别 print(f"预测结果: {predicted}, 真实标签: {actual}") # 可视化预测结果
plt.figure(figsize=(3, 3))
plt.imshow(x.cpu().squeeze(), cmap="gray")
plt.title(f"Predicted: {predicted}, Actual: {actual}")
plt.axis("off")
plt.show()运行后会输出预测结果(如"预测结果: 7, 真实标签: 7"),并显示对应的图片。
完整代码如下:
import torch
from torch import nn
from torch.nn import CrossEntropyLoss
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor#数据转换,张量'''下载训练数据集'''
training_data = datasets.MNIST(root='./data',#表示下载的数据到哪个路径train=True,download=True,transform=ToTensor()#转化为张量,图片不能直接出入网络
)#Numpy 数组只能在CPU上运行
test_data = datasets.MNIST(root='./data',train=False,download=True,transform=ToTensor()
)
# #MINIST包含70000张手写数字图像:60000张用于训练,10000张用于测试
# print(len(training_data))
# from matplotlib import pyplot as plt
# figure = plt.figure()
# for i in range(9):
# img, label = training_data[i+59000]
# figure.add_subplot(3,3,i+1)
# plt.title(label)
# plt.axis('off')
# plt.imshow(img.squeeze(), cmap='gray')
# a = img.squeeze()#squeeze()将张量格式
# plt.show()
#
training_dataloader = DataLoader(dataset=training_data,batch_size=64)#64张图片为一个包 1.损失函数计算需要 2.gpu一次性接受的图片个数 #初始化配置,没有真正取图片
test_dataloader = DataLoader(dataset=test_data,batch_size=64)device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"#调用的是cpu还是gpu
print(f'Using {device} device')class NeuralNetwork(nn.Module): #nn.Module:调用类的方式使用神经网络,底层的处理父类def __init__(self): #self:NeuralNetworksuper().__init__() #继承父类的初始化self.flatten = nn.Flatten()#展开,创建一个展开对象self.hidden1 = nn.Linear(28*28,128)#nn.linear:全连接self.hidden2 =\nn.Linear(128,256)self.out=nn.Linear(256,10)def forward(self,x): #前向传播,数据的流向x=self.flatten(x)#省略掉了.forward函数名(父类里特殊机制实现的)x=self.hidden1(x)x=torch.relu(x)#激活函数,torch使用relu函数,tanhx=self.hidden2(x)x=torch.relu(x)x=self.out(x)return xmodel=NeuralNetwork().to(device)#把刚刚创建的模型传入到Gpuprint(model)def train(dataloader,model,loss_fn,optimizer):model.train()#告诉模型,我要开始训练,模型中w进行随机化操作,已经更行w,在训练过程中w会被修改的#model.train()/ model.evalbatched_size_num=1for X,y in dataloader:X,y=X.to(device),y.to(device)pred=model.forward(X)#前向传播的时候不需要y,计算损失函数的时候才需要loss=loss_fn(pred,y) #通过传入损失函数计算方法计算损失值loss(本案例为交叉熵函数)#Backpropagation #进来一个batch的数据,计算一次梯度,更新一次网络optimizer.zero_grad()#梯度值清零loss.backward() #反向传播计算得到每个参数的梯度值woptimizer.step() #根据梯度更新网络参数loss_value=loss.item()if batched_size_num%100==0:#每100次打印一次结果print(f'loss:{loss_value:>10f}[number:{batched_size_num}]')batched_size_num+=1loss_fn=nn.CrossEntropyLoss()#创建损失函数类并实例化#返回一个网络层
optimizer=torch.optim.AdamW(model.parameters(),lr=1)#优化器需要传入模型参数迭代器(继承于父类)和学习率train(training_dataloader,model,loss_fn,optimizer)def test(test_dataloader,model,loss_fn):size=len(test_dataloader.dataset) #10000num_batches=len(test_dataloader) #打包的数量model.eval() #测试,w就不能再更新test_loss,correct=0,0with torch.no_grad(): #一个上下文管理器,关闭梯度计算for X,y in test_dataloader:x,y=X.to(device),y.to(device)#送到Gpu(有的话)pred=model.forward(X)test_loss+=loss_fn(pred,y).item()correct+=(pred.argmax(1)==y).type(torch.float).sum().item()a=(pred.argmax(1)==y)b=(pred.argmax(1)==y).type(torch.float)test_loss/=num_batches#用来衡量模型测试的好坏correct/=size#平均的正确率print(f'Test result :\n Accuray:{100*correct}% Avg loss:{test_loss:.5f}\n')epochs = 100 #第一次是w随机拟合,增加迭代次数,获得优化的w
for epoch in range(epochs):print(f'epoch {epoch + 1}')train(training_dataloader,model,loss_fn,optimizer)print("Finish training")test(test_dataloader,model,loss_fn)五、深度学习优化器:原理、对比与选择
在实战中,优化器的选择直接影响模型的训练速度和收敛效果。PPT中提到了多种优化器,我们这里详细解析核心优化器的原理、优缺点及适用场景。
5.1 三种基础优化器:BGD、SGD、Mini-batch GD
这三种优化器的核心区别在于"计算梯度时使用的样本数量"。
| 优化器 | 核心原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 批量梯度下降(BGD) | 用全部训练样本计算梯度,更新一次参数 | 1. 梯度稳定,收敛到全局最优; | 1. 内存占用大(如百万级样本无法加载); | 小数据集(样本数<1万) |
| 随机梯度下降(SGD) | 用单个随机样本计算梯度,更新一次参数 | 1. 内存占用小; | 1. 梯度波动大,易陷入局部最优; | 不推荐(已被Mini-batch替代) |
| 小批量梯度下降(Mini-batch GD) | 用batch_size个样本计算梯度,更新一次参数 | 1. 平衡速度与稳定性; | 1. 需要调整batch_size; | 所有场景(主流选择) |
示例:
-
BGD:60000张MNIST图片→计算1次梯度→更新1次参数;
-
SGD:1张图片→计算1次梯度→更新1次参数;
-
Mini-batch GD(batch_size=64):64张图片→计算1次梯度→更新1次参数。
5.2 进阶优化器:解决SGD的缺陷
基础SGD存在"学习率固定、易陷入局部最优"的问题,进阶优化器通过"动量、自适应学习率"等机制优化这些问题。
1. 动量梯度下降(Momentum)
-
原理:模拟物理中的"动量",积累之前的梯度方向,减少当前梯度的波动(如小球下坡时积累速度);
-
公式:
v = γ*v - lr*∇L,θ = θ + v(γ为动量系数,通常取0.9); -
优点:加快收敛速度,减少震荡;
-
缺点:动量方向可能与当前梯度方向相反,导致过冲。
2. AdaGrad(自适应梯度)
-
原理:对每个参数单独调整学习率——梯度大的参数,学习率减小;梯度小的参数,学习率增大;
-
优点:适合稀疏数据(如NLP中的词向量);
-
缺点:学习率随训练次数单调递减,后期可能趋近于0,导致训练停滞。
3. RMSprop(Root Mean Square Prop)
-
原理:改进AdaGrad,用"指数移动平均"代替累计梯度,避免学习率过早趋近于0;
-
优点:解决AdaGrad的停滞问题,收敛稳定;
-
缺点:仍需手动调整学习率。
4. Adam(Adaptive Moment Estimation)
-
原理:结合Momentum(动量)和RMSprop(自适应学习率)的优点,同时考虑梯度的一阶矩(均值)和二阶矩(方差);
-
优点:
-
自适应学习率,无需手动调整;
-
收敛速度快,稳定性好;
-
对超参数不敏感;
-
-
缺点:在极个别任务(如生成对抗网络)中,收敛效果可能不如SGD;
-
适用场景:绝大多数深度学习任务(默认选择)。
5. AdamW
-
原理:在Adam基础上加入"权重衰减(Weight Decay)",抑制过拟合;
-
优点:比Adam的正则化效果更好,泛化能力更强;
-
适用场景:复杂模型(如Transformer、ResNet)。
5.3 优化器选择建议
-
入门首选:Adam(无需调参,收敛快);
-
复杂模型:AdamW(加入权重衰减,抑制过拟合);
-
追求极致性能:SGD + Momentum(需耐心调整学习率,可能获得更好的泛化能力);
-
稀疏数据:RMSprop(如文本分类、推荐系统)。
PyTorch中优化器的定义示例:
# 1. SGD + Momentum
optimizer_sgd = optim.SGD(model.parameters(), lr=1e-3, momentum=0.9) # 2. Adam
optimizer_adam = optim.Adam(model.parameters(), lr=1e-3) # 3. AdamW
optimizer_adamw = optim.AdamW(model.parameters(), lr=1e-3, weight_decay=1e-4)六、激活函数与梯度问题:从根源解决训练难题
激活函数是神经网络的"灵魂"——没有激活函数,无论多少层神经网络,都等价于单层线性模型。同时,激活函数的选择直接影响"梯度消失/爆炸"问题,这是深度学习训练中的核心难题。

6.1 为什么需要激活函数?
线性模型的表达能力有限,无法拟合复杂的数据分布(如MNIST的数字分类)。激活函数通过"非线性变换",让神经网络具备拟合任意复杂函数的能力。
示例:
-
无激活函数:
y = W2*(W1*x + b1) + b2 = (W2*W1)*x + (W2*b1 + b2),仍是线性模型; -
有激活函数:
y = ReLU(W2*ReLU(W1*x + b1) + b2),具备非线性表达能力。
6.2 常见激活函数对比
PPT中重点提到了ReLU,这里对比4种经典激活函数:
| 激活函数 | 函数表达式 | 导数范围 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|
| Sigmoid | σ(x) = 1/(1+e^-x) | (0, 0.25] | 1. 输出在(0,1),可表示概率; | 1. 梯度消失(x>3或x<-3时导数趋近于0); | 二分类任务输出层、RNN |
| Tanh | tanh(x) = (e^x - e^-x)/(e^x + e^-x) | (-1, 1) | 1. 输出零均值; | 仍存在梯度消失问题(x>3或x<-3时导数趋近于0) | RNN、早期CNN |
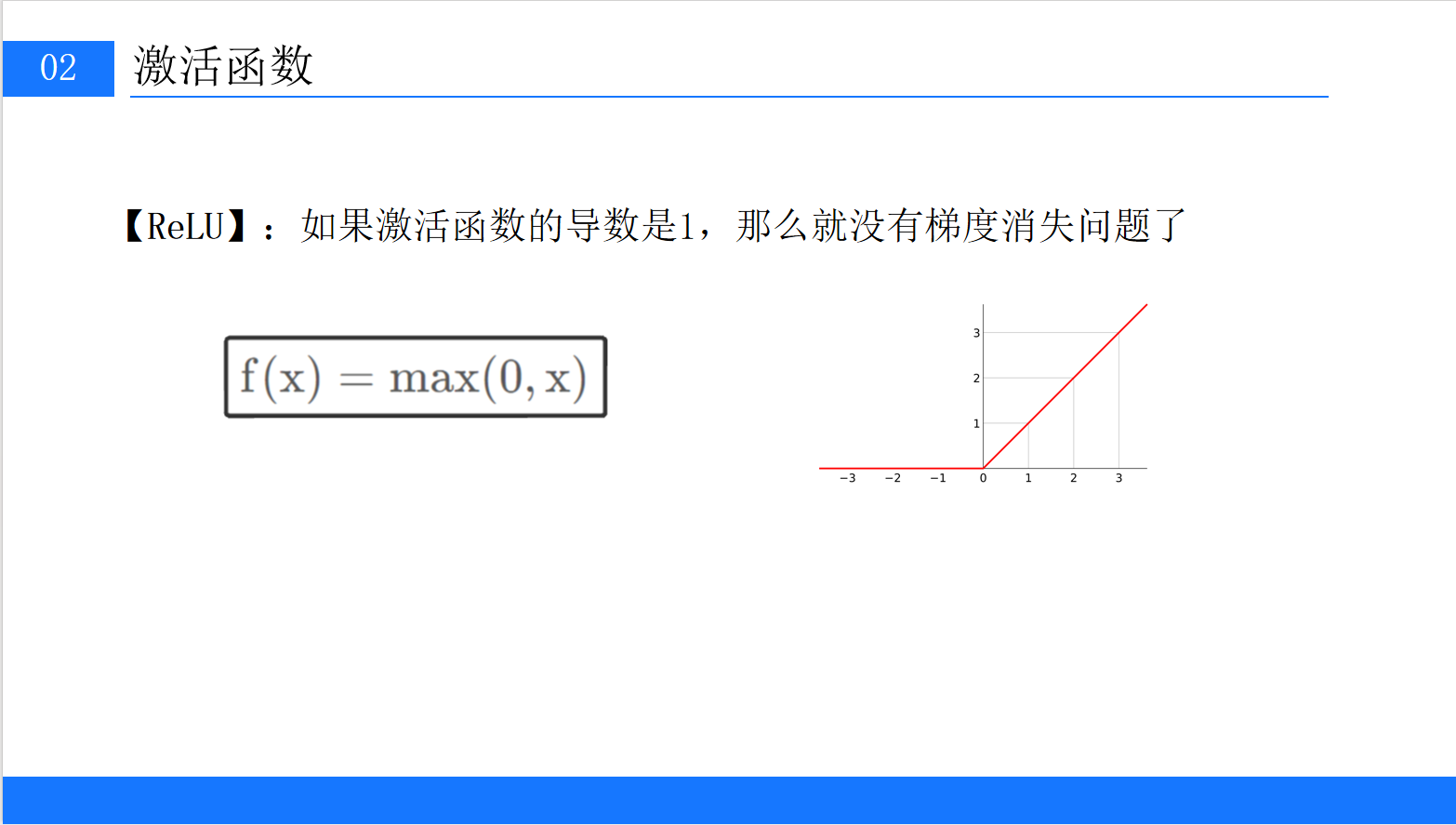
| ReLU | ReLU(x) = max(0, x) | {0, 1} | 1. 解决梯度消失(x>0时导数=1); | 1. 死亡ReLU(x<0时导数=0,参数永久不更新); | 绝大多数CNN、Transformer的隐藏层 |
| Leaky ReLU | Leaky ReLU(x) = max(αx, x)(α=0.01) | {α, 1} | 解决死亡ReLU问题(x<0时导数=α≠0) | 增加超参数α,需调参 | 替代ReLU的备选(如ResNet) |
6.3 梯度消失与梯度爆炸:根源与解决方法
6.3.1 问题根源:反向传播的连乘效应
神经网络的梯度通过"链式法则"反向传播,每层的梯度是前一层梯度与当前层激活函数导数的乘积。
-
梯度消失:若激活函数导数<1(如Sigmoid的导数≤0.25),深层网络中梯度经过多层连乘后,会趋近于0(如0.25^20 ≈ 9.5e-13),导致深层参数无法更新;
-
梯度爆炸:若权重矩阵的特征值>1,梯度经过多层连乘后会趋近于无穷大,导致参数更新过大,训练不稳定。
6.3.2 解决方法
-
选择合适的激活函数:
-
用ReLU、Leaky ReLU替代Sigmoid、Tanh,避免梯度消失;
-
示例:在MNIST模型中,我们用ReLU激活函数,有效避免了梯度消失。
-
-
权重初始化:
-
用He初始化(适用于ReLU)、Xavier初始化(适用于Sigmoid/Tanh),确保每层梯度的方差一致;
-
PyTorch中
nn.Linear默认用He初始化,无需手动设置。
-
-
梯度裁剪(Gradient Clipping):
-
对梯度的范数进行限制,超过阈值时裁剪,避免梯度爆炸;
-
示例:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) # 梯度范数不超过1.0
-
-
批量归一化(Batch Normalization):
-
对每层输入进行标准化(均值=0,方差=1),稳定梯度,加速收敛;
-
示例:在模型中加入
nn.BatchNorm1d:self.linear_relu_stack = nn.Sequential( nn.Linear(28 * 28, 128), nn.BatchNorm1d(128), # 批量归一化 nn.ReLU(), nn.Linear(128, 256), nn.BatchNorm1d(256), nn.ReLU(), nn.Linear(256, 10) )
-
6.4 PyTorch中激活函数的使用
激活函数可通过nn模块直接调用,示例如下:
# 1. 在模型中定义激活函数
class Model(nn.Module): def __init__(self): super().__init__() self.fc1 = nn.Linear(784, 128) self.relu = nn.ReLU() # 实例化ReLU self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.fc1(x) x = self.relu(x) # 应用ReLU x = self.fc2(x) return x # 2. 直接在forward中使用(简化写法)
class Model(nn.Module): def __init__(self): super().__init__() self.fc1 = nn.Linear(784, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = nn.functional.relu(self.fc1(x)) # 直接调用functional中的relu x = self.fc2(x) return x七、总结与进阶建议
7.1 核心知识点回顾
-
框架选择:PyTorch以"易用性、动态图、活跃社区"成为主流,适合入门和科研;
-
环境安装:GPU版本需严格遵循"显卡驱动→CUDA→cuDNN→PyTorch"的顺序,注意版本兼容;
-
硬件原理:GPU的高ALU占比适合并行计算,是深度学习加速的关键;
-
实战流程:数据加载(DataLoader)→模型构建(nn.Module)→损失函数+优化器→训练+测试;
-
核心组件:
-
优化器:Adam是默认选择,复杂模型用AdamW;
-
激活函数:ReLU解决梯度消失,Leaky ReLU解决死亡ReLU;
-
梯度问题:通过激活函数、权重初始化、梯度裁剪解决。
-
7.2 进阶学习建议
-
学习CNN与CV任务:PyTorch的
torchvision模块提供了ResNet、ViT等经典模型,可用于图像分类、目标检测; -
学习NLP与Transformer:用
Hugging Face Transformers库,快速实现BERT、GPT等模型; -
模型部署:学习TorchScript、ONNX、TensorRT,将PyTorch模型部署到端侧(手机)或云端;
-
官方资源:
-
PyTorch官方教程:Welcome to PyTorch Tutorials — PyTorch Tutorials 2.8.0+cu128 documentation
-
PyTorch文档:PyTorch documentation — PyTorch 2.8 documentation
-
通过本文的学习,相信大家已经掌握了PyTorch的核心基础。深度学习的关键在于"实践",建议大家基于本文的MNIST案例,尝试修改模型结构(如增加隐藏层、调整batch_size)、更换优化器(如用SGD替代Adam),观察模型性能的变化,逐步积累实战经验!