推荐系统王树森(三)粗排精排
排序01:多目标模型_哔哩哔哩_bilibili
github-PPT
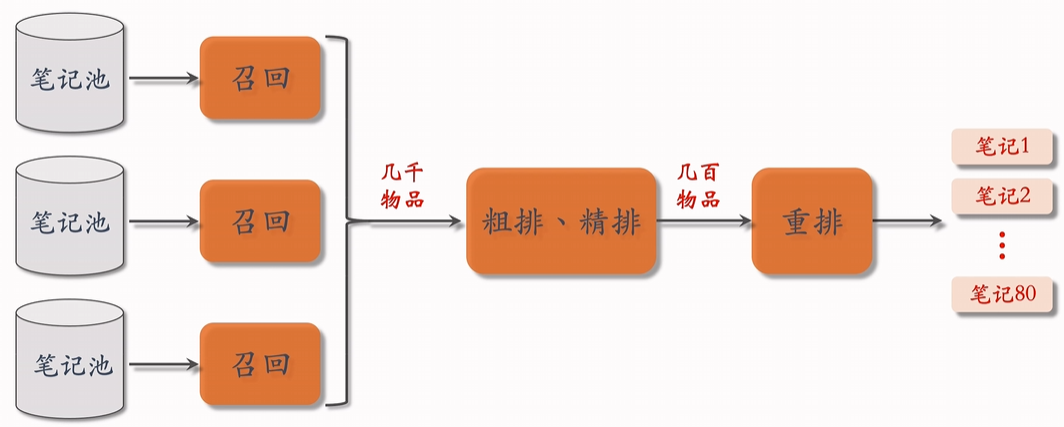
在下列链路中 聚焦于粗排、精排部分。前面介绍精排,粗排和精排相近,为了效率提高进行简化。
目录
0. 排序模型的特征
1. 多目标排序模型(特征拟合四大指标)
2. Multi-gate Mixture-of-Experts (MMoE)多门控专家混合模型
3. 融合预估分数(如何加权融合)
4. 视频播放建模(时长和完播率)
5. 粗排模型——三塔模型
0. 排序模型的特征
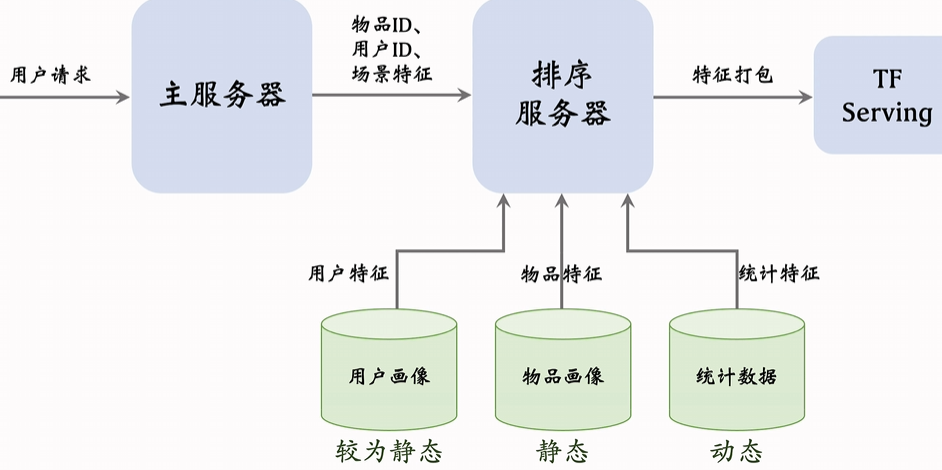
输入特征包含:之前提到的用户、物品特征,还有统计特征和场景特征。
1. 笔记统计特征 (Item-level Aggregates)
-
最近 30 天(或 7天、1天、1小时)的曝光数、点击数、点赞数、收藏数。
-
按照用户属性分桶,比如性别、年龄。
-
作者特征:发文数量、粉丝数、消费指标(历史曝光/点击/点赞/收藏等)。
2. 用户统计特征 (User-level Aggregates)
-
用户最近 30 天(或 7天、1天、1小时)的曝光数、点击数、点赞数、收藏数。
-
按 笔记类型分桶:这些统计特征能刻画用户兴趣偏好和活跃度。
-
图文 vs 视频(例如图文点击率、视频点击率)。
-
类目(如美妆、科技、美食等分类点击率)。
-
3. 场景特征 (Context Features)
-
用户地理位置:GeoHash(经纬度编码)、城市。
-
时间特征:当前时刻(分段并 embedding),是否周末、是否节假日。
-
设备特征:手机品牌、型号、操作系统。
离散特征 (Categorical Features)
-
常见:用户ID、笔记ID、作者ID、类别、关键词、城市、手机品牌等。
-
处理方式:Embedding,把离散ID映射到低维向量空间,捕捉语义和相似性。
连续特征 (Continuous Features)
-
分桶 (Bucketing):把连续值离散化,再转成 one-hot/embedding,例如年龄、笔记字数、视频长度。
-
数值变换:对数/平滑,比如:
-
曝光数、点击数、点赞数 → log(1+x),避免长尾。
-
点击率、点赞率等比例特征,可以做平滑(防止样本少时波动过大)。
-
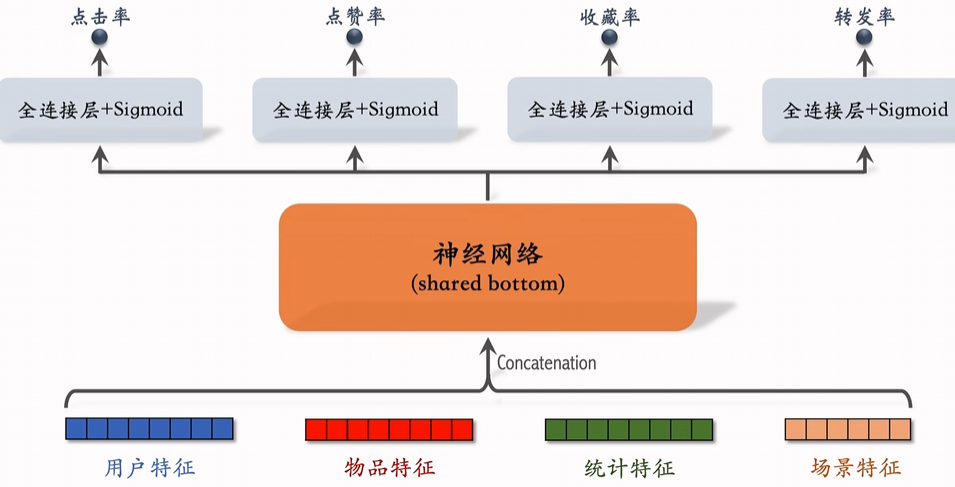
1. 多目标排序模型(特征拟合四大指标)
排序根据预估笔记的一些指标(点击率 点赞率 收藏率 转发率)多目标神经网络拟合
再对这些指标加权融合成“分数”
系统需要记录笔记的:曝光次数 点击次数 点赞次数 收藏次数 转发次数
训练的时候 这四个指标 就是预测用户是否点击,是否点赞,是二分类,用交叉熵损失
![]()
困难:类别不平衡,曝光中点击的很少;点击中收藏的很少,正样本远少于负样本。
采用负样本降采样 平衡类别并提高训练效率。
但是负样本比例减少会导致预测的点击率虚高,需要校准。 点击率=正/总

2. Multi-gate Mixture-of-Experts (MMoE)多门控专家混合模型
MOE Mixture of Experts,专家混合模型:准备一组“专家模型”(experts),每个专家只擅长一部分任务或数据模式。 然后通过一个“门控网络”(gating network),动态决定输入应该交给哪些专家来处理,并加权融合输出。
特征输入到 几个结构相似不共享参数的神经网络(被称为专家)再分别输出几个向量。
也用softmax 额外训练加权权重。 为不同的指标训练不同的权重。
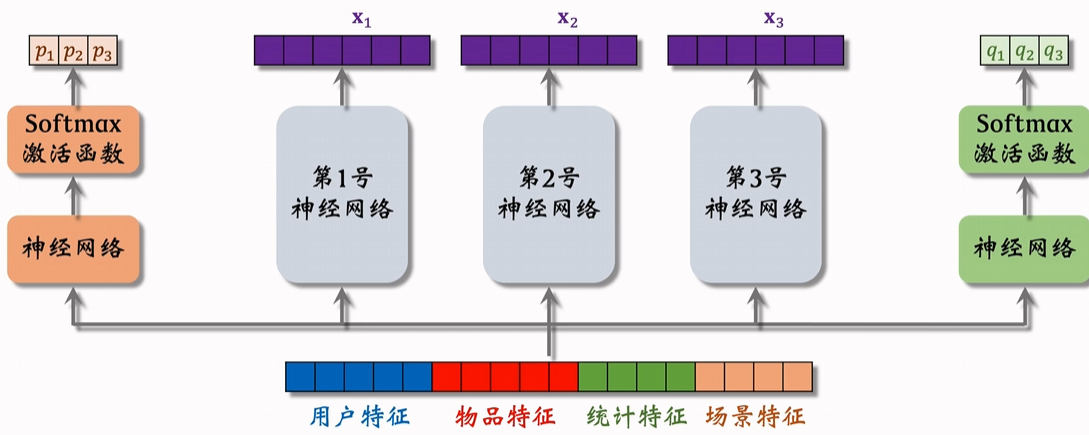
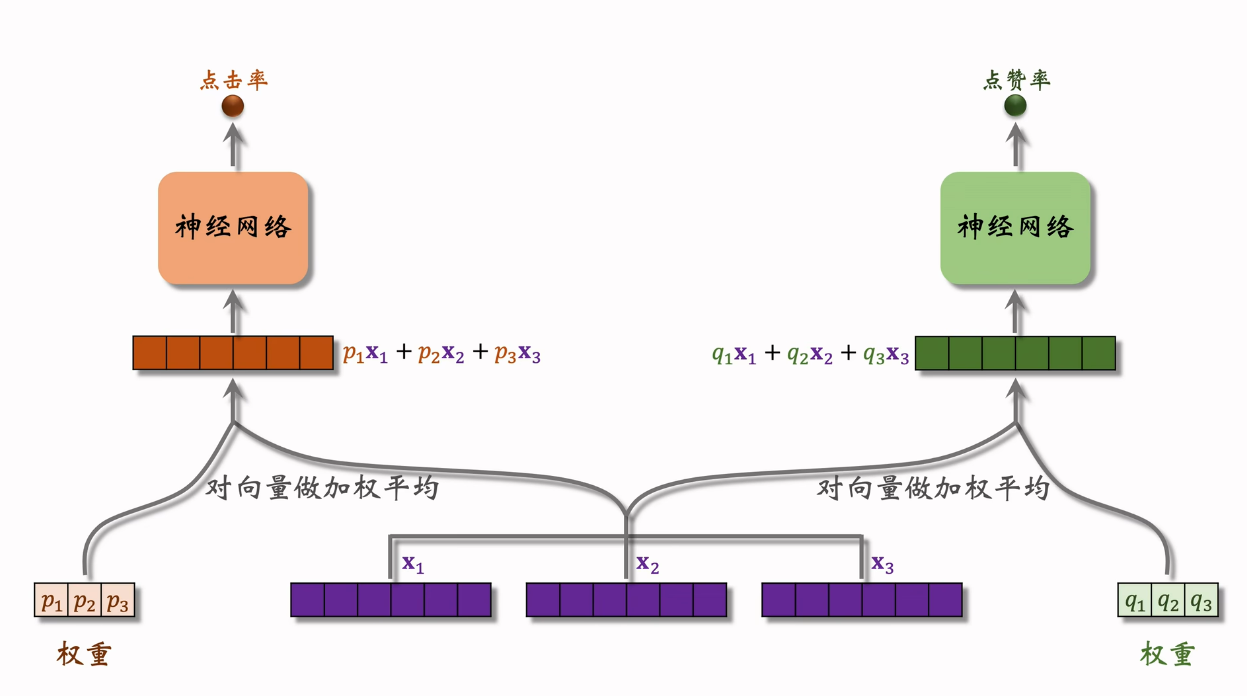
我们期望的是综合多个专家的结果 但可能会出现极化现象(softmax的一个专家权重接近1)
可以在训练时,对 softmax的输出使用 dropout 每个数值被 mask 的概率是 10% 每个专家被丢弃的概率是 10%,这样会强迫每个任务根据多个专家做预测。
如果用 dropout,假如发生极化,某个 softmax 输出的某个元素接近 1,如果这个被 mask,预测的结果肯定错的离谱。为了让预测尽量精准,神经网络会尽量避免极化的发生。
3. 融合预估分数(如何加权融合)
![]()
![]()
![]()
![]()
![]() 权重既有乘积又有指数
权重既有乘积又有指数
![]()
![]() 排名靠前得分高
排名靠前得分高

![]() 转化过程的参数指数乘积 (超参数都取1则为实际收益)
转化过程的参数指数乘积 (超参数都取1则为实际收益)

4. 视频播放建模(时长和完播率)
视频也有笔记的四个特征,但是视频更重要的观看时长和完播率(比点赞收藏等特征甚至更有说服力)
技巧:训练时长的时候映射为 y=t/1+t
好处1. 对于大的t 把“无限的时长”转成“有界的概率标签” 2.短时长的时候就接近于t
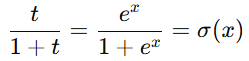 p接近y 的时候 即exp(x) 接近 t
p接近y 的时候 即exp(x) 接近 t
使用交叉熵 因为试用于 0~1之间概率型的变量


对于完播率:二元交叉熵 用p拟合y![]()
但因为长视频完播率低吃亏 所以需要修正;
f函数是一个 这个时长的视频平均完播率的映射函数;比值相当于在这个时长下 相对平均数的水平。
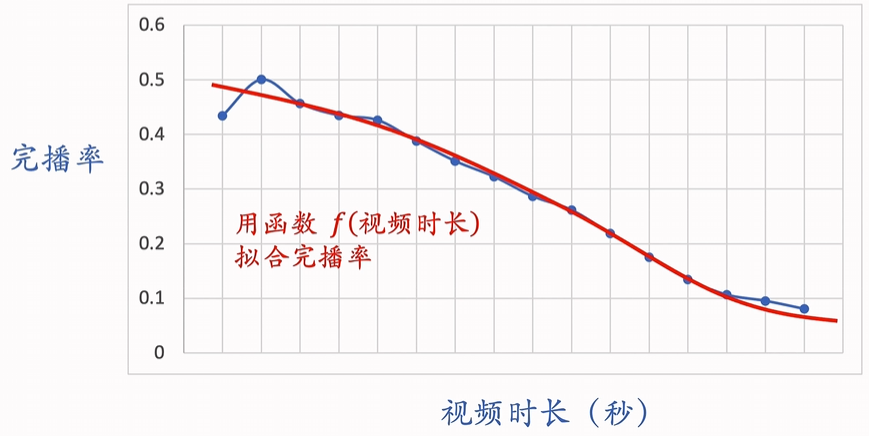
视频越长 需要除以越小的f函数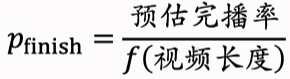
5. 粗排模型——三塔模型
相对于精排,粗排因为需要处理更多的数据 可以以准确率为代价换取更高效的速率。
精排 将用户特征 物品特征进行融合,n篇候选笔记就需要n次推理。
召回的时候 双塔模型 物体表征b离线计算存储 询问时只用调用户表征a。 后期融合
召回速度快但效果不太好,精排效果好但低效。
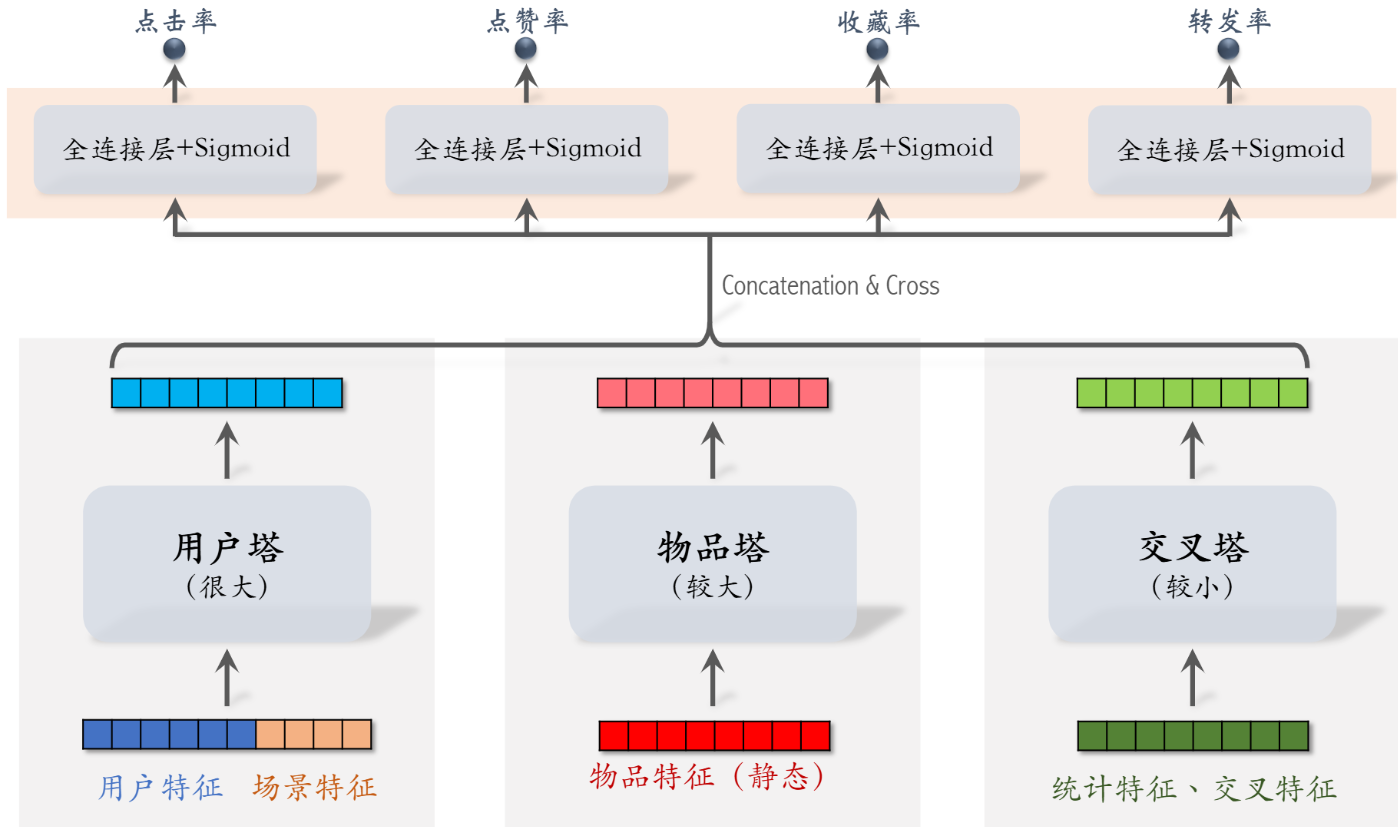

三塔模型 用户塔(用户+场景)每次只需要一次推理;
物品塔可以记入缓存重复运用(粗排有筛选 精排无筛选 所以精排可以缓存);
交叉塔:统计特性 以及user-item交互特性 每次都需要推理,次数多 所以要求网络简单 快速运算。