仿真干货|解析Abaqus AMD的兼容与并行效率问题

在日常的交流和观察过程中,许多用户反馈在Abaqus有限元仿真中遇到了AMD处理器相关的兼容性和并行效率问题,例如:
- AMD处理器性价比相较Intel更高,我做有限元仿真可以入手吗?但很多人说兼容性不好;
- 我们今年上了AMD新集群跑Abaqus,很多算例计算速度还不如5年前的Intel集群,甚至核用得越多,计算速度越慢;
- ……


综上所述,问题可主要归纳为两大类:
- AMD处理器运行Abaqus时出现非法指令(Illegal instruction)报错
- 多核并行计算时出现效率衰减,核数超过16核后计算速度显著降低
本文将通过对这些问题的系统性分析,从技术角度阐述根本原因和解决方案,帮助大家优化计算过程。
一、兼容性问题根源分析
问题分析:
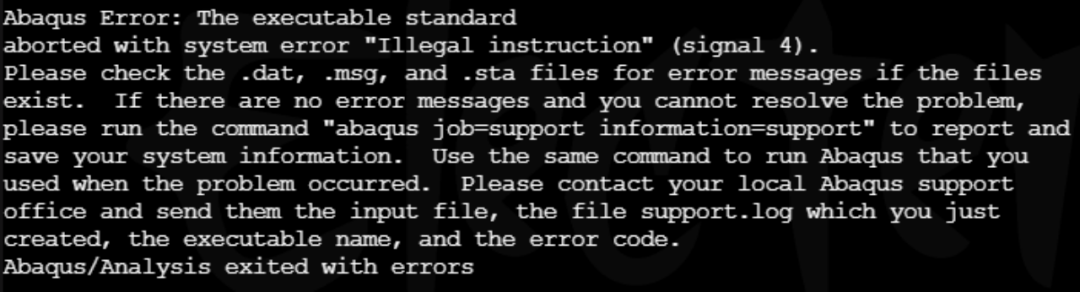
通过对比测试发现,Abaqus安装过程依赖特定的动态链接库,尤其是安装目录中的Intel MKL(Math Kernel Library)矩阵运算的动态链接库。由于历史版本Abaqus主要针对Intel处理器优化,这些库在Intel处理器上正常运行,但在AMD处理器环境下可能触发指令集冲突,导致计算中断。问题根源于Abaqus开发者早期未充分考虑AMD架构的兼容性,高版本软件虽支持AMD处理器,但默认库文件未做适配更新。例如,用户在实际测试中观察到,同一Abaqus安装包在Intel集群上顺利运行,但在AMD平台则报错Illegal instruction。
解决方案:
通过逐行比对新旧版本依赖库,替换不兼容的MKL库文件,识别并更新为兼容版本,使AMD平台成功运行原报错算例。
二、并行效率衰减机制研究
问题分析:
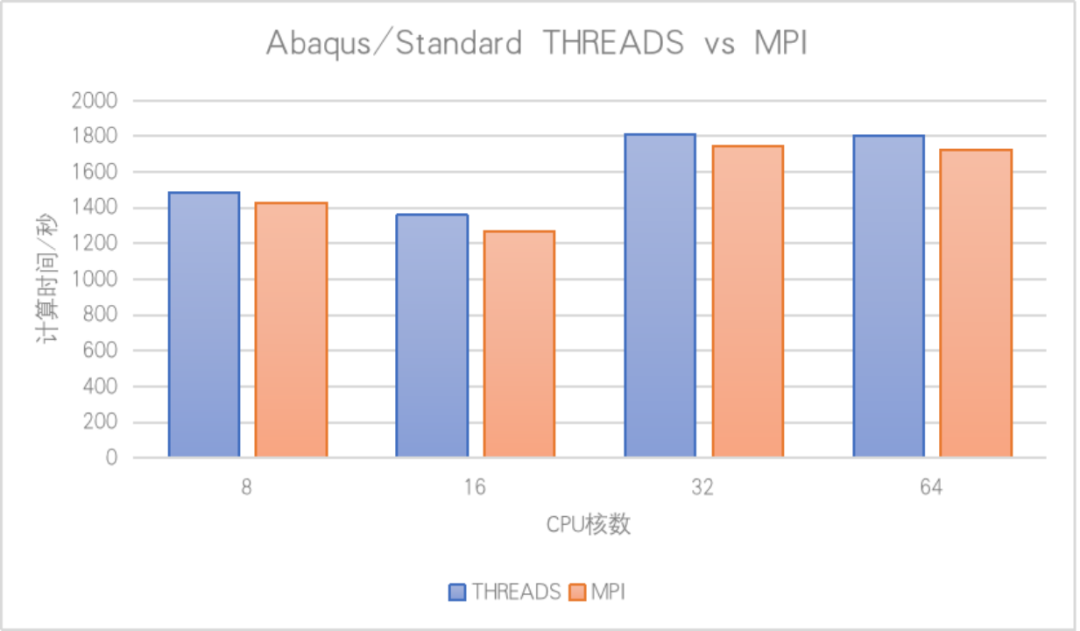
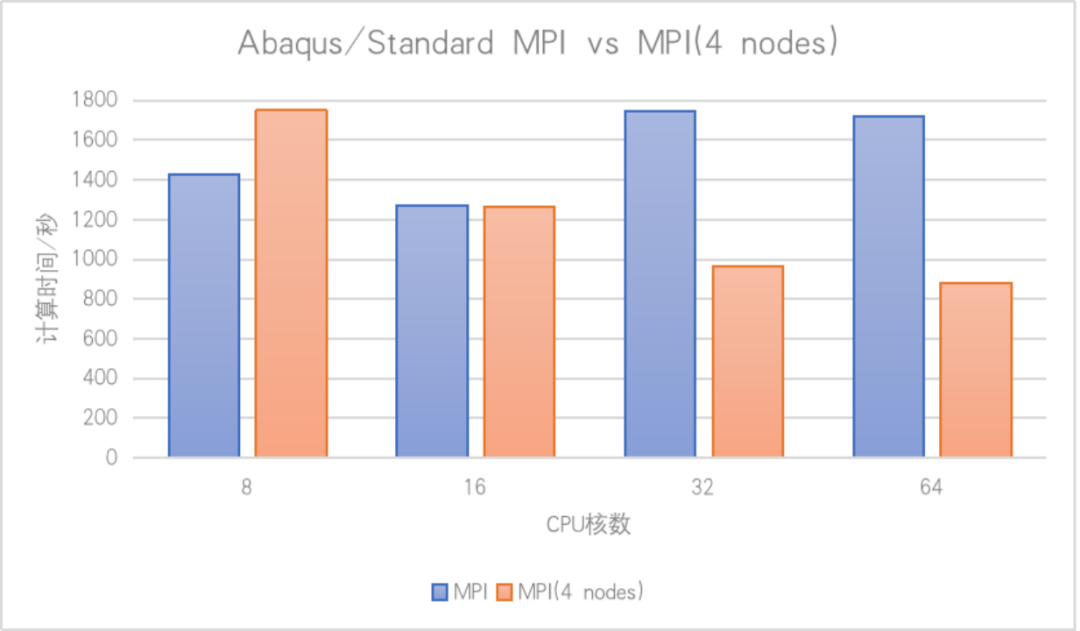
在兼容性问题解决后,测试发现AMD平台存在并行效率异常:以100万自由度的模型为例(Abaqus/Standard求解器),单节点内核数扩展至32核时,计算耗时较16核反而增加。
经测试排查发现,在并行效率问题上,该直接求解器默认是混合并行模式,也就是在单个节点内部的时候,强制采用共享内存并行,节点之间是MPI通信,该模式在核心较少时(如8-16核)效率尚可,但在高核数AMD服务器上(如64核以上)出现效率下降。这是因为共享内存并行在单节点内管理数据时,核心数超过临界点(16核)后,内存带宽和通信开销成为瓶颈,导致计算速度变慢。如下图,对比测试显示,32核共享并行计算时间比16核更长。
解决方案:
启用混合并行模式,结合消息传递接口(MPI)分布式并行与多线程共享并行。具体操作包括将计算任务分解为多个part,并平均分配到4个不同节点上,同时通过节点间高速通信降低延迟。测试数据证实,在相同核数下,跨节点混合模式显著减少计算时间,主要得益于分布式并行减少了单节点资源争用。
三、总结
综上所述, 本次效率提升有以下几点原因:
1、模型被分解为多个Part,可使得单元操作并行化;
2、全局矩阵求解分解为多个Part,充分发挥了单个节点的共享内存并行效率,规避单节点大于16核之后共享内存并行效率低的问题;
3、神工坊®集群具有现代化的HPC系统,集群计算机之间配备有Infiniband,提供了高带宽、低延迟和可靠的数据交换,这将使得MPI通信损耗降得很低。
由于AMD平台的核数一般较多,以AMD EPYC™ 7002 Series双路、128核的服务器为例,通常调度器默认是用完一个节点,再用另一个节点。其所导致的后果就是——核越多越慢,花费更高的成本却得到了更差的服务 。
Abaqus在AMD平台的性能和兼容性优化关键在依赖库适配与并行模式配置。软件安装过程需针对性替换兼容库文件,以避免指令冲突;并行计算时则应灵活切换混合模式,匹配硬件架构特点。这些优化需深入高性能计算(HPC)基础知识,对技术能力要求较高,但能显著提升计算资源利用率和仿真效率。错误配置则可能导致资源浪费,例如在单节点高核数环境下,计算成本增加10倍但速度反而下降,而优化后成本减半、效率翻倍。
这也会造成一种现象:某仿真平台主打单位核时低廉,但是用户租用他们的平台跑仿真软件,实际上付出了将近10倍的钱,工作效率却没有提升。平台反而成为“自来水”推荐给其他同事使用,仅仅是因为表面上的价格便宜。
而SimForge™高性能仿真云平台以超算HPC集群作为硬件支撑,实现了跨节点大规模并行计算,可以满足复杂结构模型和算法仿真时对大量计算资源的需求,缩短了大规模仿真用时,为工业设计的高效运行提供保证。并对平台上的仿真软件进行了高性能适配,同时根据用户需求进行兼容性适配,真正做到按需最大化每一核时的价值。欢迎广大工程师同行注册试用——
1. 专业GPU并行渲染,操作丝滑如本地仿真
SimForge™ 高性能仿真云平台实现了多 GPU 的分时共享,同时支持大规模仿真数据的多 GPU 服务端并行渲染,让10亿+网格可视化无压力。
2. "超算级资源池+工业级软件栈"的垂直整合架构
SimForge™ 拥有亚洲最大的价值2亿的商业仿真软件授权,搭建了“传统商软+开源/国产软件+自研定制软件”的“工业级软件栈”,配合超算资源支持,单体软件并行最高可达2048核。

3. 打破工程仿真信息孤岛,在线协同范式升级
实时同步操作界面:区别于大部分仿真云平台只有子母账号管理功能,SimForge 在账号管理功能之外,是可以实现实时同步操作的。
跨设备与跨账号无缝协同:关注到不同用户对账号信息保密需求不同,SimForge支持——“相同账号不同设备,同时登录协同操作”,“不同账号同时进入作业协同操作”两种使用情景。

4. 实时计费,精准结算,风险可控
SimForge™ 采用实时计费,精准结算的模式,让用户在使用过程中能够清晰了解费用情况,风险可控。无论是短期的集中计算任务,还是长期的研发项目,都能根据实际使用情况灵活计费,避免了资源浪费和不必要的成本支出,以及日常软硬件维护的烦恼。