Med-SA 论文总结
论文名称:Medical SAM adapter: Adapting segment anything model for medical image
segmentation 发表于《Medical Image Analysis》2025
作者:Junde Wu a , Ziyue Wang b , Mingxuan Hong a , Wei Ji c , Huazhu Fu d , Yanwu Xu e ,
Min Xu f,g , Yueming Jin a,b,*
https://doi.org/10.1016/j.media.2025.103547
目录
Existing Problem:
本文主要内容:
SD-Trans
HyP-Adpt
相关概念
参数高效微调 PEFT
Method
Med-SA architecture
SD-Trans architecture
HyP-Adpt architecture
Prompt 生成策略
Experiment
Datasets
评估标准
实现细节
Github代码详解
Adaptation模块的代码
加入Adapter后的ViT block
冻结参数操作
decoder
记录
报错
Existing Problem:
-
SAM在医学图像分割领域表现不好,因为缺乏具体医学知识,包括低图像对比度,组织边界模糊,微小病变区域等。
-
MedSAM解决此问题是fully fine-tune原始的SAM模型,这样计算成本和内存占用都很高。且fully fine-tune真的有必要嘛?因为先前的研究表明,预训练的视觉模型对医学图像具有很强的可移植性。
-
Adaption是一种高效参数微调技术,在NLP领域使用广泛,但面临两个挑战:(如果不懂的化还要看看Adaption)
(1) 医学图像模态通常是3D的,如CT,MRI,SAM可以被应用在3D图像的每个切片上来获取最终结果,但没有考虑到3D医学图像分割中固有的紧密的体积相关性——如何将2D SAM 适配到3D医学图像分割上;
(2) Adaption应用在CV领域的研究有限,特别是交互式模型(如SAM,prompt很重要),如何融合Adaption和prompt还没有被探索。
注:Adaption的主要思路就是将带有部分参数的adapter模块插入到原始模型中,在保持大型预训练模型不变的情况下,仅更新少量额外的adapter参数。
本文主要内容:
针对以上问题,本文提出Med-SA,是探索SAM在medical domain首批工作。
几个主要的点:
-
使用轻量且有效的adaptation技术,而不是fine-tune SAM,将特定领域的医学知识融入分割模型—— 参数高效微调PEFT技术Adaption 来微调预训练的SAM(小工作量,仅更新SAM参数(13M)的2%)
-
提出空间深度转置 Space-Depth Transpose(SD-Trans)来适配2D和3D场景
-
提出超提示适配器 Hyper-Prompting Adapter (HyP-Adpt) 以实现提示条件下的适配
SD-Trans
解决医学图像形态问题(3D图像)
作用:将输入嵌入的spatial维度转置到depth维度,使得相同的self-attention模块能够在给定不同输入时处理不同维度的信息(等会看看代码,是什么意思)
HyP-Adpt
解决基于Prompt的适配问题
作用:实现 prompt-conditioned Adaption。在该Adapter中,我们使用视觉prompt来生成一系列权重,这些权重可高效应用于Adapter模块,促进广泛且深入的prompt-Adapter交互。(看看什么是视觉Prompt)
相关概念
参数高效微调 PEFT
-
全称:Parameter-efficent fine-tuning
-
相比于fully fine-tuning全量微调,PEFT冻结大部分参数,只更新少量参数(通常少于5%)
-
相关研究表明(Bitfit),PEFT比全量微调效果好,因为PEFT能避免catastrophic forgetting灾难性遗忘,且在跨域场景中泛化性更强
-
在所有PEFT方法中,Adaption是微调大模型用于下游任务的有效工具。如(arXiv preprint arXiv:
2205.13535,arXiv preprint arXiv:2203.16329. )、
Method
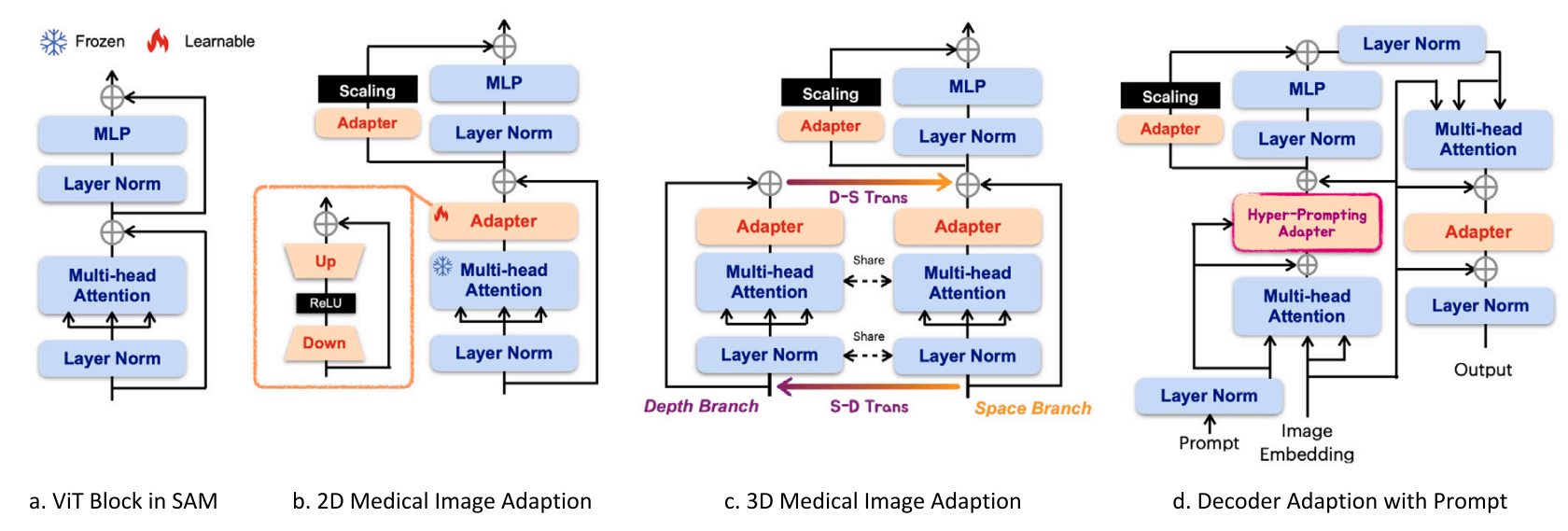
Med-SA architecture
-
冻结预训练SAM的参数
-
加入Adapter模块,集成到指定位置
-
Adapter起到瓶颈模型的作用(看图1b),由下采样,ReLU激活,上采样组成
-
下采样使用简单的MLP将输入压缩到低维度
-
上采样使用另一个MLP将压缩后的嵌入拓展回原始维度
-
-
在SAM的encoder中,我们在每个标准的ViT模块中放置2个Adapter(看图1b)
-
第一个Adapter,在Multi-head Attention后面
-
Multi-head Attention在ViT中起关键作用,它通过增强模型捕捉输入的flattened image patches之前的关系,来捕捉全局和局部依赖。
-
-
第二个Adapter,在后面的残差路径中。
-
MLP在ViT中也很重要,可防止ViT生成秩为1的矩阵,避免输出退化。所以将Adapter并行集成到MLP模块中,Adapter的特定任务特征对固定分支的通用特征起到补充作用,丰富整体特征
-
我们在Adapter之后引入了缩放因子s,用于平衡这两类特征。(作者关于Adapter位置和缩放因子,做了消融实验,见论文4.7)
-
-
-
在SAM的decoder中,我们在每个标准的ViT模块中放置3个Adapter(看图1d)
-
第一个Adapter,用于整合prompt嵌入,引入Hyper-Prompting,超提示适配器(HyP-Adpt)
-
第二个Adapter,与encoder一致,用于适配经残差加强的嵌入,与MLP并行
-
第三个Adapter,在image嵌入到prompt 交叉注意力的残差连接之后(还需要再理解),并在此之后又连接了另一个残差连接和层归一化,以输出最终结果。
-
SD-Trans architecture
-
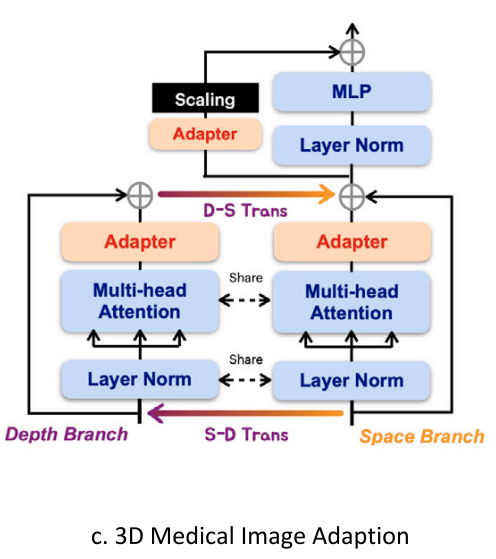
本文提出空间深度专转置 Space-Depth Transpose(SD-Trans)来适配3D场景,考虑每个slice之间的联系
-
如图1c所示,对于每一个block,我们将attention操作分成两个分支:space分支和depth分支(3D图像多一个深度维度)。对于一个带有深度D的3D样本
-
space分支:输入D×N×L到multi-head attention,N是embeddings的数量number,L是embeddings的长度long(N是样本数,L是特征数?)。D 对应操作的次数,使得交互能够在 N×L 上进行,从而捕捉空间相关性
-
depth分支:我们转置输入矩阵得到 N×D×L,输入multi-head attention,尽管使用了相同的注意力机制,但现在的交互是在 D×L 上进行的,这使得深度相关性的学习成为可能。最后,我们将深度分支的结果转置回其原始形状,并将它们添加到空间分支的输出中,从而整合了深度信息。
-
HyP-Adpt architecture
-
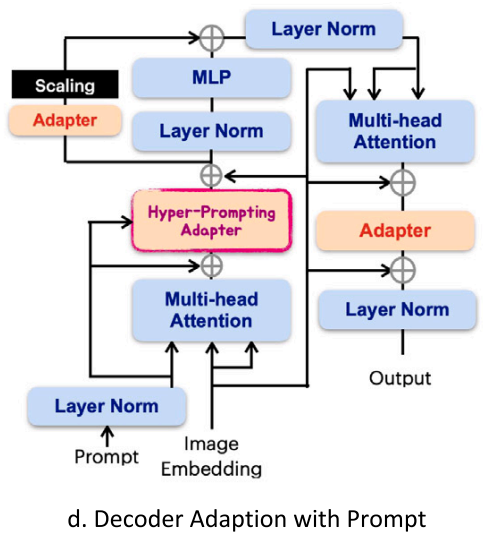
将adaptation应用在交互式视觉模型的探索还很少,且自然场景和医学领域的交互行为差距很大
-
本文提出Hyper-Prompting Adapter (HyP-Adpt),用于实现prompt-conditioned adaptation,如图1d所示
-
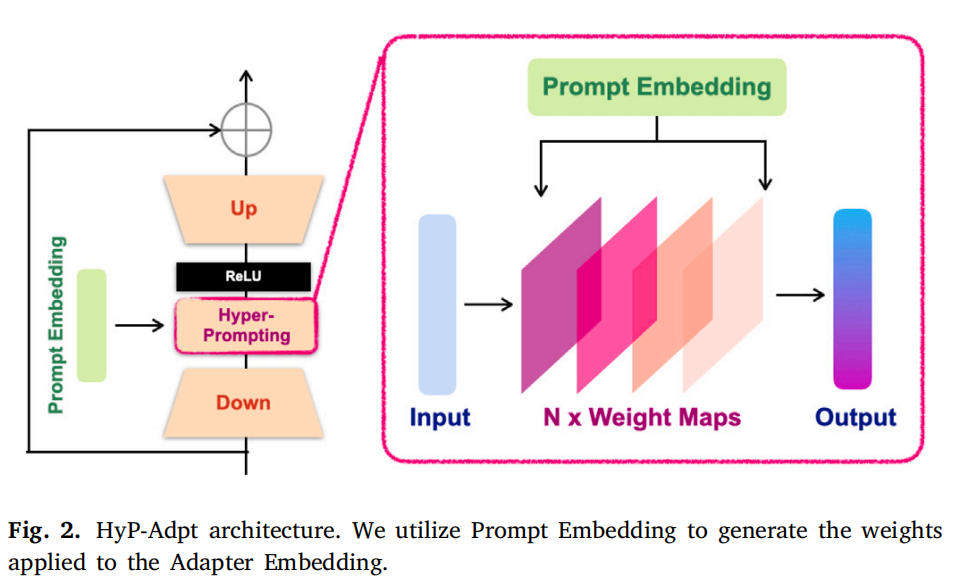
HyP-Adpt的详细结构如图2所示
-
HyP-Adpt的核心思想是利用prompt embedding为adapter生成用于知识条件化的权重。具体而言,我们利用投影和reshaping操作,从prompt embedding中生成一系列权重图。然后,这些权重图通过矩阵相乘被直接应用到adapter上
-
这种方法能够实现广泛且深入的特征级交互,同时与生成整个网络相比,还能显著减少所需的参数数量。
-
形式上,我们在adapter的缩减嵌入 edown上进行超提示操作,此时提示信息(point,box)被拼接并缩减为prompt embedding eprompt. 然后使用eprompt来生成权重图序列
-
以其中一个为例:
-
其中Re表示reshape,M表示MLP层将 eprompt∈RN×L 投影成 eprompt∈RN×Lin*Lout ,其中 * 是数值乘法,Lin是 edown的长度,Lout是输出的目标长度。(为了后续和edown的维度匹配)
-
随后我们将eprompt从一维嵌入reshape成了二维权重wprompt∈RN×Lin*Lout,并将其应用于edown,可以表示为:
-
其中⊗表示矩阵乘积,我们沿着长度维度对元素进行归一化,之后应用 ReLU 激活函数。
-
作者为Hyper-prompt设置了3层,每个权重都由单独的MLP层进行投影。HyP-Adpt 有助于根据提示信息调整参数,并且能更灵活地适应不同的模态和下游任务。
Prompt 生成策略
-
Med-SA仅采用sparse prompt:click prompt 和 bounding box
-
对于bounding box,采用和SAM相同的方式
-
对于click prompt,因为SAM论文仅给了有限的生成策略,本文设计了自己的生成方法。
-
使用positive click表示前景区域,negative click表示背景区域
-
结合随机和迭代点击采样策略来训练模型。先通过随机采样进行prompt初始化,然后利用迭代采样程序加入一些click。(看一下代码什么是迭代采样程序),这种采样策略模拟了与用户真实的交互,因为每次点击都被放置在网络利用之前的click集合生成的预测的错误区域中。(细节见代码)
-
-
-
本文对3D图像的每个切片进行提示,以确保分割的一致性
Experiment
-
只更新全部SAM模型参数的2%,比其他模型好(如MedSAM, nnUnet, TransUnet, UNetr, Swin-UNetr, segdiff等)
-
医学图像分割的主要挑战是3D图像处理和重叠器官的模糊边界
Datasets
-
针对不同模态的5个数据集 (包括:CT, MRI, 超声,解剖图,皮肤镜),与17个医学图像分割任务对比
-
BTCV:3D 腹部多器官数据集,CT 扫描图像,包含带标签的12种解剖结构,来自50名受试者,共有1463张轴向增强腹部临床 CT 图像,每次 CT 扫描包含 85 至 198 个切片,轴向尺寸为 512×512。
-
REFUGE2:2D 视网膜眼底图像数据集,用于两项分割任务(视盘和视杯),包含 1200 张带标签的分辨率为 2124×2056 的 RGB 图像
-
BraTS2021:3D 数据集,MRI 扫描图像。用于脑胶质母细胞瘤子区域分割,包含来自多个机构的 1280 次多参数 MRI 扫描。每次 MRI 扫描包含 155 个切片,轴向尺寸为 240×240。
-
TNMIX:2D 甲状腺结节分割基准数据集,超声图像,包含不同分辨率的图像,是一个混合数据集,其中有来自 TNSCUI(Ma 等人,2017)的 4554 个样本和来自 DDTI(Pedraza 等人,2015)的 637 个样本。
-
ISIC2019:2D 皮肤镜图像数据集,用于皮肤病变分析,包含 25331 张有标注的黑色素瘤分割标签的图像。这些数据来自不同的中心,具有不同的分辨率。
-
这些数据集总共涵盖了 17 个分割对象,Med-SA采用它们默认的训练集、验证集和测试集划分方式
-
评估标准
-
分别使用Dice score和Hausdorff Distance (HD) 作为关键指标,来评估逐像素的分割准确率和分割边界质量。
-
HD: 衡量两个点集之间的最大不匹配程度,描述了从一个集合中的点到另一个集合中最近点的最大距离。在医学图像分割中, 通常用于比较自动分割结果与真实标注(金标准)之间的边界差异。
-
HD计算示例:假设有两个点集 A 和 B,正向豪斯多夫距离 H(A,B)是 A 中每个点到 B 中最近点的距离的最大值,反向豪斯多夫距离 H(B,A)是 B 中每个点到 A 中最近点的距离的最大值,而豪斯多夫距离 H(A,B) = max(H(A,B), H(B,A))。在图像分割里,就是计算分割结果边界点集和真实边界点集之间的这种距离 。
-
-
还报告了几个分割任务的平均交并比(mIoU),以方便更好地进行比较。
实现细节
-
对2D图像,遵循SAM默认的训练设置
-
对3D图像,Med-SA使用更小的batch_size:16
-
对于 REFUGE2、TNMIX 和 ISIC 数据集,模型训练 40 个epochs。对于三维 BTCV 和 BraTS 数据集,训练延长至 60 个epochs。
-
所有实验均在 PyTorch 平台上实现,并在 4 块 NVIDIA A100 GPU 上进行训练和测试。
-
2D图像被调整成1024×1024,3D图像的原始体数据被调整为128×128×128,不进行裁剪/填充。
-
对于交互式模型的prompt设置,遵循以往研究进行4种不同的prompt设置
-
一个随机的正点,记为 “1 - point”
-
三个正点,记为 “3 - points”
-
与目标重叠 50% 的边界框,记为 “BBox 0.5”
-
与目标重叠 75% 的边界框,记为 “BBox 0.75”
-
-
为确保分割的一致性,我们为三维图像的每个切片单独提供提示。为了最小化随机提示带来的随机性,我们在所有数据集上重复进行了五次 Med - SA 实验,文中展示平均结果。
Github代码详解
GitHub - SuperMedIntel/Medical-SAM-Adapter: Adapting Segment Anything Model for Medical Image Segmentation
-
下载并解压后,cd进入该目录,安装环境:conda env create -f environment.yml
-
conda activate sam_adapt 进入环境
-
下载预训练权重(SAM的sam_vit_b_01ec64.pth)放入./checkpoint/sam文件夹
-
下载给的案例数据集ISIC和csv文件放在data/isic目录下
-
即可运行(一张单卡16G的情况,batchsize=2, image_size调成了512来跑的isic)
Adaptation模块的代码
# 代码的models-common-adapter.py内
class Adapter(nn.Module):def __init__(self, D_features, mlp_ratio=0.25, act_layer=nn.GELU, skip_connect=True):super().__init__()self.skip_connect = skip_connectD_hidden_features = int(D_features * mlp_ratio) # 隐藏层维度计算self.act = act_layer()self.D_fc1 = nn.Linear(D_features, D_hidden_features)self.D_fc2 = nn.Linear(D_hidden_features, D_features)def forward(self, x):# x is (BT, HW+1, D)xs = self.D_fc1(x) # 降维xs = self.act(xs) # 激活xs = self.D_fc2(xs) # 还原回原始维度if self.skip_connect: # 如果有残差结构x = x + xselse:x = xsreturn x加入Adapter后的ViT block
在image_encoder内,如果是sam_adpt模型,就使用AdapterBlock
# 对应图1b,1c,在代码的adapter_block.py内
class AdapterBlock(nn.Module):"""Transformer blocks with support of window attention and residual propagation blocks"""
def __init__(self,args,dim: int,num_heads: int,mlp_ratio: float = 4.0,scale: float = 0.5,qkv_bias: bool = True,norm_layer: Type[nn.Module] = nn.LayerNorm,act_layer: Type[nn.Module] = nn.GELU,use_rel_pos: bool = False,rel_pos_zero_init: bool = True,window_size: int = 0,input_size: Optional[Tuple[int, int]] = None,) -> None:"""Args:dim (int): Number of input channels.num_heads (int): Number of attention heads in each ViT block.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.qkv_bias (bool): If True, add a learnable bias to query, key, value.norm_layer (nn.Module): Normalization layer.act_layer (nn.Module): Activation layer.use_rel_pos (bool): If True, add relative positional embeddings to the attention map.rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.window_size (int): Window size for window attention blocks. If it equals 0, thenuse global attention.input_size (tuple(int, int) or None): Input resolution for calculating the relativepositional parameter size."""super().__init__()self.args = argsself.norm1 = norm_layer(dim)self.attn = Attention(dim,num_heads=num_heads,qkv_bias=qkv_bias,use_rel_pos=use_rel_pos,rel_pos_zero_init=rel_pos_zero_init,input_size=input_size if window_size == 0 else (window_size, window_size),)
if(args.mid_dim != None):adapter_dim = args.mid_dimelse:adapter_dim = dim
self.MLP_Adapter = Adapter(adapter_dim, skip_connect=False) # MLP-adapter, no skip connectionself.Space_Adapter = Adapter(adapter_dim) # with skip connectionself.scale = scaleself.Depth_Adapter = Adapter(adapter_dim, skip_connect=False) # no skip connectionself.norm2 = norm_layer(dim)self.mlp = MLPBlock(embedding_dim=dim, mlp_dim=int(dim * mlp_ratio), act=act_layer)
self.window_size = window_size
def forward(self, x: torch.Tensor) -> torch.Tensor:shortcut = x # 保留原始x,后面用作残差连接# Window partition 窗口划分if self.window_size > 0: # 如果窗口大小大于0 则将特征图划分为多个不重叠的窗口H, W = x.shape[1], x.shape[2]x, pad_hw = window_partition(x, self.window_size)
## 3d branch 3D分支处理if self.args.thd: hh, ww = x.shape[1], x.shape[2]if self.args.chunk: # 确定深度维度大小depth = self.args.chunkelse:depth = x.shape[0]# 重新排列,将depth维度单独分离出来xd = rearrange(x, '(b d) h w c -> (b h w) d c ', d=depth)# xd = rearrange(xd, '(b d) n c -> (b n) d c', d=self.in_chans)xd = self.norm1(xd) # 归一化dh, _ = closest_numbers(depth) # 获取最接近的两个数,用于将深度维度重新排列成二维 dh*dw=depthxd = rearrange(xd, 'bhw (dh dw) c -> bhw dh dw c', dh= dh)xd = self.Depth_Adapter(self.attn(xd))xd = rearrange(xd, '(b n) dh dw c ->(b dh dw) n c', n= hh * ww )
x = self.norm1(x) # 归一化x = self.attn(x) # 注意力机制,给输入x乘上注意力系数 图中的 multi-head attentionx = self.Space_Adapter(x) # 图中第一个 Adapter
if self.args.thd: # 如果是3D图片xd = rearrange(xd, 'b (hh ww) c -> b hh ww c', hh= hh )x = x + xd
# Reverse window partitionif self.window_size > 0:x = window_unpartition(x, self.window_size, pad_hw, (H, W))
x = shortcut + x # resnet# MLP块xn = self.norm2(x) # 归一化# 论文中并行的 MLP 和 Adapter self.scale是缩放因子x = x + self.mlp(xn) + self.scale * self.MLP_Adapter(xn) # 第二个Adapterreturn x冻结参数操作
'''Train,在function.py文件内的def train_sam内'''
# 控制哪些参数参与训练、哪些参数被冻结(只训练Adapter模块,冻结其他权重)
if args.mod == 'sam_adpt':for n, value in net.image_encoder.named_parameters(): if "Adapter" not in n: # 冻结非 Adapter 参数value.requires_grad = False else: # 解冻 Adapter 参数value.requires_grad = Truedecoder
decoder的代码中没有看到对应图1d的实现,请大佬们指教,以下是GitHub中的代码:
class MaskDecoder(nn.Module):def __init__(self,*,transformer_dim: int,transformer: nn.Module,num_multimask_outputs: int,activation: Type[nn.Module] = nn.GELU,iou_head_depth: int = 3,iou_head_hidden_dim: int = 256,) -> None:"""Predicts masks given an image and prompt embeddings, using atransformer architecture.
Arguments:transformer_dim (int): the channel dimension of the transformertransformer (nn.Module): the transformer used to predict masksnum_multimask_outputs (int): the number of masks to predictwhen disambiguating masksactivation (nn.Module): the type of activation to use whenupscaling masksiou_head_depth (int): the depth of the MLP used to predictmask qualityiou_head_hidden_dim (int): the hidden dimension of the MLPused to predict mask quality"""super().__init__()self.transformer_dim = transformer_dimself.transformer = transformer
self.iou_token = nn.Embedding(1, transformer_dim)self.num_multimask_outputs = num_multimask_outputsself.num_mask_tokens = max(4, num_multimask_outputs) # for backward compatibility on loading checkpointsself.mask_tokens = nn.Embedding(self.num_mask_tokens, transformer_dim)
self.output_upscaling = nn.Sequential(nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2),LayerNorm2d(transformer_dim // 4),activation(),nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2),activation(),)self.output_hypernetworks_mlps = nn.ModuleList([MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3)for i in range(self.num_mask_tokens)])
self.iou_prediction_head = MLP(transformer_dim, iou_head_hidden_dim, self.num_mask_tokens, iou_head_depth)
def forward(self,image_embeddings: torch.Tensor,image_pe: torch.Tensor,sparse_prompt_embeddings: torch.Tensor,dense_prompt_embeddings: torch.Tensor,multimask_output: bool,) -> Tuple[torch.Tensor, torch.Tensor]:"""Predict masks given image and prompt embeddings.
Arguments:image_embeddings (torch.Tensor): the embeddings from the image encoderimage_pe (torch.Tensor): positional encoding with the shape of image_embeddingssparse_prompt_embeddings (torch.Tensor): the embeddings of the points and boxesdense_prompt_embeddings (torch.Tensor): the embeddings of the mask inputsmultimask_output (bool): Whether to return multiple masks or a singlemask.
Returns:torch.Tensor: batched predicted maskstorch.Tensor: batched predictions of mask quality"""masks, iou_pred = self.predict_masks(image_embeddings=image_embeddings,image_pe=image_pe,sparse_prompt_embeddings=sparse_prompt_embeddings,dense_prompt_embeddings=dense_prompt_embeddings,)
# Select the correct mask or masks for outputmask_slice = slice(0, self.num_multimask_outputs)masks = masks[:, mask_slice, :, :]iou_pred = iou_pred[:, mask_slice]
# Prepare outputreturn masks, iou_pred记录
报错
安装环境:conda env create -f environment.yml 报错pip failed,因为找不到torch==1.12.1+cu113
去pytorch官网找了对应的版本安装
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch然后更新依赖包
conda env update -f environment.yml --prune # --prune 会移除环境中多余的包还是报错找不到torch==1.12.1+cu113, 重新使用pip安装后,再更新依赖包成功
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113conda env update -f environment.yml --prune # --prune 会移除环境中多余的包