C++学习(4)模板与STL
一、为什么要有模板
C语言阶段我们写过Swap函数,在讲解引用的时候我用引用将其加以改进:
void Swap(int& left, int& right)
{int temp = left;left = right;right = temp;
}
void Swap(double& left, double& right)
{double temp = left;left = right;right = temp;
}
void Swap(char& left, char& right)
{char temp = left;left = right;right = temp;
}
//....
写这段代码的时候我们做的工作很简单,写一个Swap函数以后,其它的全部都是复制粘贴来并且只修改形参和临时变量的类型,也就是说,这些函数形成重载仅仅是在类型上,但是话又说回来了,内置类型都还没写完,如果再带上自定义类型的话,光Swap函数写着也烦。
假如有像Swap函数一样的情况,函数内部逻辑一样,只有临时变量和形参这些类型不一样,如果想要覆盖所有的类型,那么就需要不断复制粘贴再修改;如果最开始写的函数逻辑就有错误,那么几个甚至几十上百个复制粘贴只该类型的函数岂不是都是错的。
所以让人不禁考虑,能否创建出来一种方式,使得这种只有类型改变的情况都被兼顾。
C++设计者也是考虑到此,所以就给出了模板用于泛型编译创造一系列代码。
C++中的模板就像是这样的模板一样:

可以制造出外形一样的饼干、月饼等一系列食物,这些食物的区别就在于填充的材料不同。
二、什么是模板
C++模板是一种泛型编程(generic programming)机制,允许开发者编写与具体数据类型无关的通用代码,通过参数化类型实现代码复用和类型安全。其核心思想是将数据类型视为参数,在编译时根据实际传入的类型生成特定版本的代码,从而避免为不同数据类型重复编写逻辑相同的代码。
模板分为函数模板和类模板。
三、函数模板
1.概念
函数模板代表的是一系列函数,该函数模板与函数类型无关,在使用时根据实参类型生成对应类型的函数版本。
2.语法格式
template <typename T1,typename T2,.......,typename Tn>
返回值类型 函数名 (参数列表){}
可以观察到模板的关键字是template,类型相当于模板的参数,使用的是<>来包括,参数用关键字typename+类型名(其中typename可以用class代替,原因是因为这俩都有类型的意思,不能用struct代替)
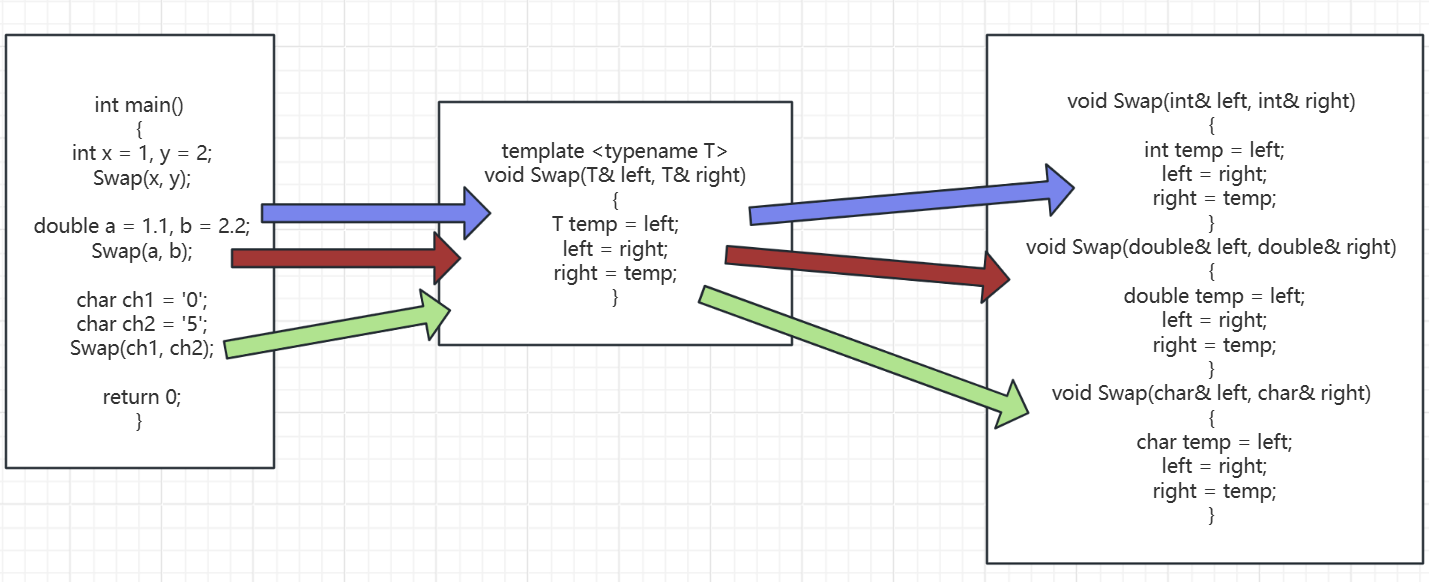
比如用这种格式写一个模板来生成Swap函数就是这样:
template <typename T>
void Swap(T& left, T& right)
{T temp = left;left = right;right = temp;
}写一个函数来测试:
template <typename T>
void Swap(T& left, T& right)
{T temp = left;left = right;right = temp;
}
int main()
{int x = 1, y = 2;double a = 1.1, b = 2.2;Swap(x, y);Swap(a, b);return 0;
}3.函数模板的原理
其实道理很简单,只有模板中有Swap函数,那么编译器一读实参的类型,要int要double,那么就搞一个int类型的Swap,再搞一个double类型的Swap,生成这两个函数以后,自然xy的交换和ab的交换就能实现了。
4.函数模板实例化
用不同类型的参数使用函数模板,称为函数的实例化。函数实例化分为隐式实例化和显式实例化。
①隐式实例化
隐式实例化就是上面我们所演示的,只要传参,系统就会自动去识别到底用什么类型的实例化模板。
一般来说,隐式实例化就够用了,但是难免会有的程序员非常不负责任:
template <typename T>
T Add(const T& x, const T& y)
{return x + y;
}
int main()
{int x = 1, y = 2;double a = 1.1, b = 2.2;Add(x, a);Add(y, b);return 0;
}这段代码连编译都过不去,原因很简单,你给的模板参数只有一个T,也就意味着将来你只会用一个类型去代入模板生成函数,但是下面两个Swap函数的调用可就为难编译器了,比如x是int类型的变量,a是double类型的变量,那请问,你模板就一个类型,我到底生成成double的还是int的,所以编译就不能放过你。
这也是模板的一大特点——不接受自动类型转换(隐式类型转换)
对于这个问题有两种解决方法,比较简单的就是直接强转:
template <typename T>
T Add(const T& x, const T& y)
{return x + y;
}
int main()
{int x = 1, y = 2;double a = 1.1, b = 2.2;Add(x, (int)a);//Add(y, b);return 0;
}
第二个方法就是显式实例化模板。
②显式实例化
template <typename T>
T Add(const T& x, const T& y)
{return x + y;
}
int main()
{int x = 1, y = 2;double a = 1.1, b = 2.2;Add(x, (int)a);Add<int>(y, b);return 0;
}
如果类型不匹配,编译器就会尝试隐式类型转换,如果无法转换成功,编译器将会直接报错。
5.模板参数匹配原则
匹配原则简单说就是不选贵的,只选对的。
比如这样一段代码:
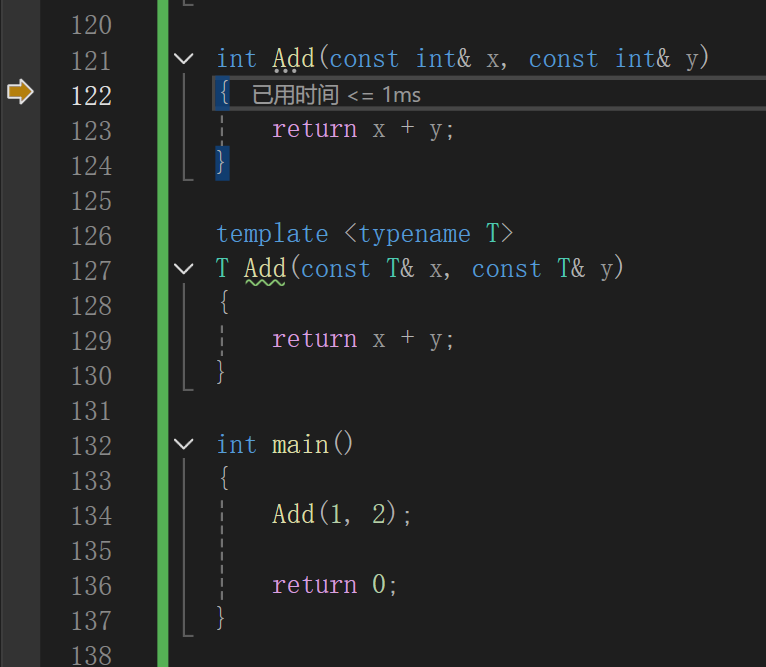
int Add(const int& x, const int& y)
{return x + y;
}template <typename T>
T Add(const T& x, const T& y)
{return x + y;
}int main()
{Add(1, 2);return 0;
}①非模板函数与同名的模板函数同时存在,模板函数可以生成这个非模板函数,则用非模板函数
简单来说就是,你如果是一个懒汉,你在金钱充裕的情况下,会选择自己做饭还是点外卖,答案很简单,肯定是点外卖,因为谁不愿意吃现成的。
通过调试也能看到:
②非模板函数与同名的模板函数同时存在,模板函数生成的函数更加符合,则选择模板函数
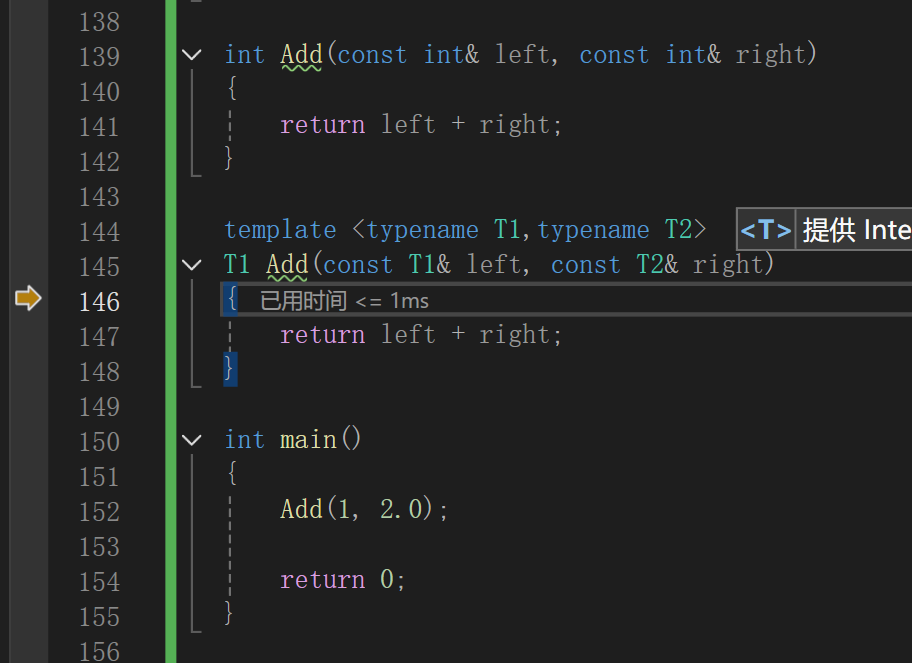
int Add(const int& left, const int& right)
{return left + right;
}template <typename T1,typename T2>
T1 Add(const T1& left, const T2& right)
{return left + right;
}int main()
{Add(1, 2.0);return 0;
}这个也好类比,比如说虽然金钱充裕,但是你在家住,那么拿外卖这个事在家长看来就是十恶不赦,吃现成就别想了,因为它们觉得家里做的更好,所以你还得老老实实自己做点东西吃。
就像这里的模板有更适合你的营养一样,不是有句玩笑话就说,外卖富含人体不需要的一百种成分。
同样可以调试:
四、类模板
道理基本上与函数模板类似。
1.语法格式
template <class T1,class T2,......,class T3>
class 类模板名
{ // 类内成员定义 };
2.类的实例化
在C语言阶段我们实现Stack的数据类型用的是typedef,当时的解释是,这样的话就可以随心去修改数据类型了,但是其实还有问题:
typedef int STDataType;
class Stack
{
public:Stack(int n = 4):_arr((STDataType*)malloc(sizeof(STDataType)*n)),_capacity(n),_top(0){if (_arr == nullptr){perror("malloc fail!");exit(1);}}~Stack(){free(_arr);_arr = nullptr;_capacity = _top = 0;}void Push(STDataType x){if (_top == _capacity){_capacity *= 2;STDataType* temp = (STDataType*)realloc(_arr, sizeof(STDataType) * _capacity);if (temp == nullptr){perror("realloc fail!");exit(1);}}_arr[_top++] = x;}private:STDataType* _arr;int _capacity;int _top;
};假如现在的栈你想改成double类型的,确实只改typedef就可以了,但是呢,你一改是不是就不再能用存int的栈了,二者不能同时存在,复制粘贴的话,肯定不能同名,也就意味着,同一作用域是不能出现两种栈的,这个时候借助模板:
template <typename T>
class Stack
{
public:Stack(int n = 4):_arr((T*)malloc(sizeof(T)* n)), _capacity(n), _top(0){if (_arr == nullptr){perror("malloc fail!");exit(1);}}~Stack(){free(_arr);_arr = nullptr;_capacity = _top = 0;}void Push(T x){if (_top == _capacity){_capacity *= 2;T* temp = (T*)realloc(_arr, sizeof(T) * _capacity);if (temp == nullptr){perror("realloc fail!");exit(1);}}_arr[_top++] = x;}private:T* _arr;int _capacity;int _top;
};到时候你给啥类型那他就用啥类型替换T,这样岂不美哉。
另外还得强调一下,这种类不是说了嘛,其实跟结构体有点像,如果不看的话,你也不知道他有啥属性,到Stack这里是,如果不知道存什么类型的,那么很明显根本无法生成类。
所以对于类的实例化,必须显式实例化:
int main()
{Stack<int> st1;Stack<double> st2;return 0;
}另外再说一下,模板不建议将类的声明与定义分到两个文件中,会出现链接错误,具体原因后面讲,如果非得在一个文件分离,也是必须带上模板:
template<class T>
void Stack<T>::Push(const T& x)
{// 扩容_array[_top] = x;++_top;
}看着也是超级臃肿。
五、STL简介
1.什么是STL
STL(Standard Template Library,标准模板库)是C++标准库的核心组成部分,提供了一套基于模板的通用数据结构和算法组件,旨在实现代码的高度复用、类型安全和高效执行。其核心理念是通过泛型编程(Generic Programming)将数据结构和算法解耦,使开发者无需重复实现底层功能,专注于业务逻辑。
2.STL版本
这个是AI找的,因为了解而已,没必要浪费时间去找:
以下是STL(Standard Template Library)从诞生到现代的主要版本演进历程,按发展阶段分段叙述:
原始版本(HP STL,1994年)
由Alexander Stepanov与Meng Lee在惠普实验室开发,首次将泛型编程理念落地为可复用的代码库。这一版本开源免费,允许任意修改和传播,奠定了STL的核心设计:容器(如vector、list)、算法(如sort)和迭代器的分离。其价值在于证明了“数据结构与算法解耦”的可行性,成为所有后续实现的基础。
早期商业分支版本(1990年代中期)
P.J.版本:由P.J. Plauger开发,被Microsoft Visual C++采用。其代码闭源且命名晦涩(如早期std::vector实现符号混乱),可读性差,但成为Windows生态的早期STL支柱。
RW版本:由Rogue Wave公司开发,应用于Borland C++ Builder。同样闭源,普及度低,后被STLport替代。
这些版本虽基于HP实现,但因封闭性限制了社区协作与优化。
开源奠基版本(SGI STL,1990年代末)
由硅谷图形公司(SGI)主导,被GCC编译器采用为Linux默认实现。其核心优势在于开源可修改、代码可读性高(如清晰的std::vector命名),并引入先进内存分配器提升性能。SGI版本成为学习STL源码的黄金标准,经典设计如vector的倍增扩容策略、红黑树实现的map均被广泛参考。
3.STL的六大组件
具体事宜到后面一点一点展开,现在看看了解了解就行了。
4.STL重要性
STL包括数据结构和算法,所以运用合适的数据结构和算法,就可以提高项目开发的效率;STL库属于标准库,所以在C++的不同编译器下也可以使用;提升程序效率的话不多说了,笔试题中用STL可以更容易的做题,面试只要与C++相关的岗位,STL库也必不可少。
接下来逐步学习STL的内容,还会拓展学习更多更复杂的数据结构和算法。