[Sync_ai_vid] 唇形同步推理流程 | Whisper架构
链接:https://github.com/bytedance/LatentSync/blob/main/docs/syncnet_arch.md
docs:LatentSync
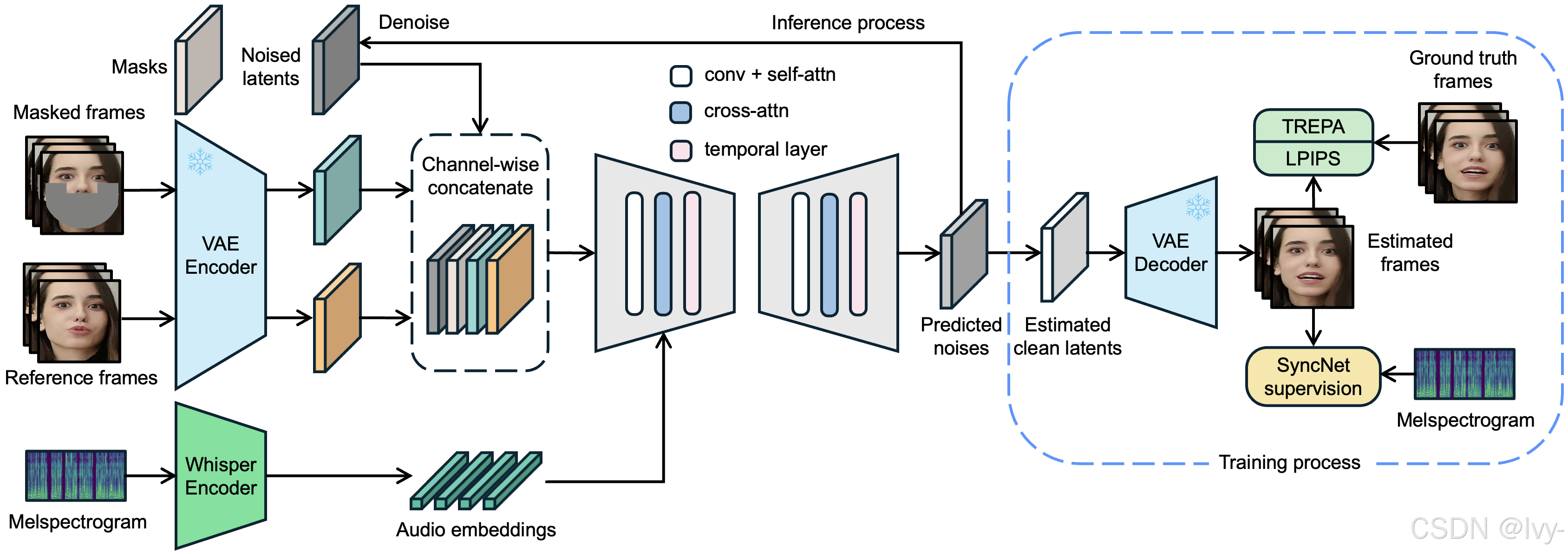
LatentSync是一个端到端唇语同步项目,能够生成语音与唇形完美匹配的逼真视频。
该项目通过使用*音频条件化3D U-Net*(一种生成式AI模型)来修改带有噪声的视频表征,整个过程由语音提取的音频线索引导,并通过专门的唇形同步评判网络进行评估。
项目还包含健壮的*数据准备*流程和*推理过程*编排系统。
可视化
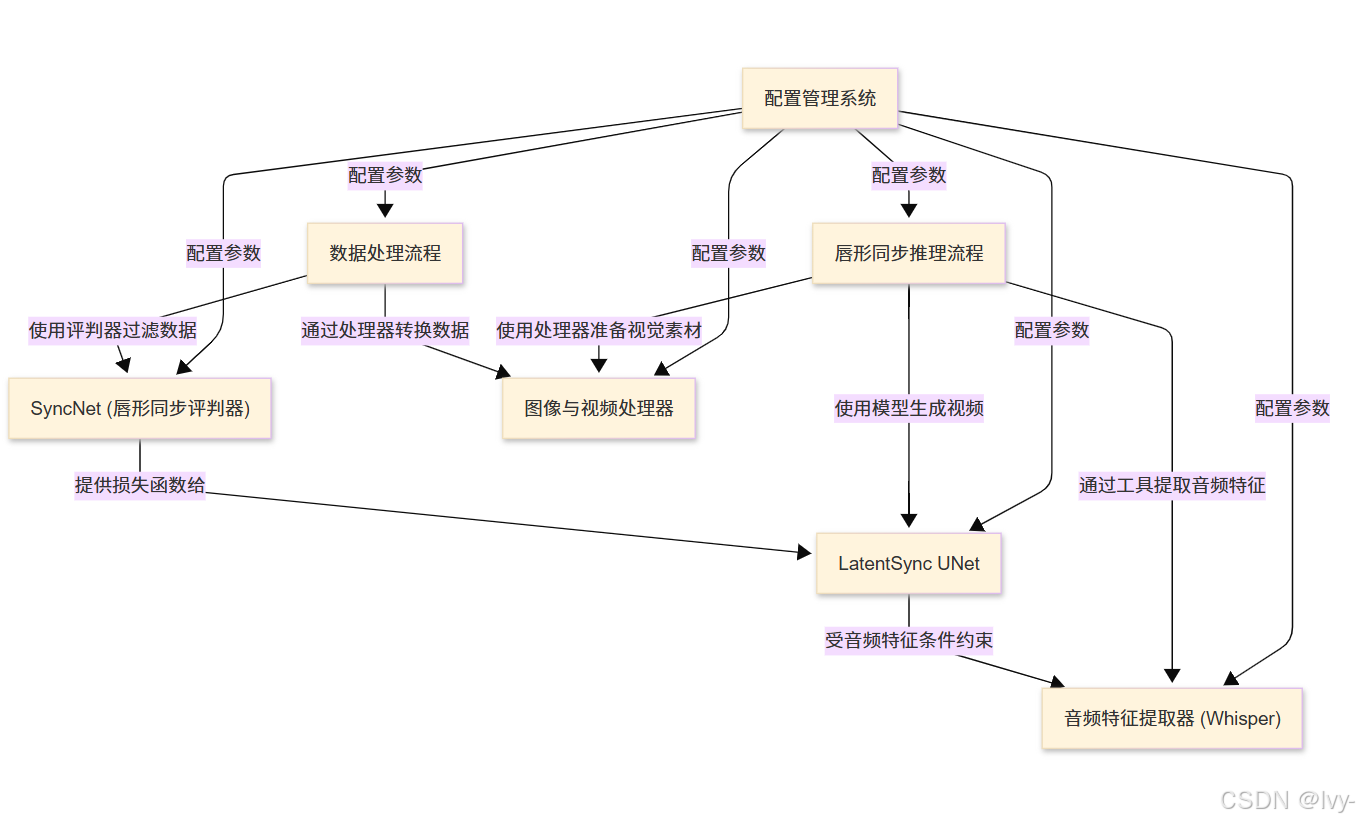
章节目录
- 唇形同步推理流程
- LatentSync UNet模型
- 音频特征提取器 (Whisper)
- SyncNet (唇形同步评判器)
- 图像与视频处理器
- 数据处理流程
- 配置管理系统
相关前文传送:
[1Prompt1Story] 注意力机制增强 IPCA | 去噪神经网络 UNet | U型架构分步去噪
第1章:唇形同步推理流程
是否曾观看过人物口型与语音不匹配的视频?这种不协调感相当明显
在视频创作领域,特别是需要修改现有视频中人物台词时,让唇形完美匹配新音频是一项重大挑战。
唇形同步推理流程正是为此而生。
想象它是一个全自动的电影工作室,只需输入原始视频和新音频轨道,就能生成唇形与音频完美同步的全新视频。
作为LatentSync的用户友好界面,它将所有技术模块无缝衔接,最终输出专业级成品。
流程核心功能
唇形同步推理流程如同电影制作的总导演,虽不亲自处理每个细节,但精准调度各专业模块的协作:
- 加载专家模块:首先加载VAE、UNet和音频编码器等AI模型(后续章节将详细解析)
- 输入预处理:对原始视频和音频进行标准化处理,为模型提供标准输入格式
- 核心算法调度:执行"扩散过程"——通过多轮迭代精修视频帧使其匹配音频特征
- 数据格式转换:在潜在空间(压缩编码空间)完成处理后,将数据还原为可视像素
- 成品合成:将生成视频帧与原始/新音频流合并输出最终视频
使用指南
无需专业编程知识,通过命令行或网页界面即可轻松使用:
命令行调用示例
python -m scripts.inference \--video_path "assets/your_video.mp4" \--audio_path "assets/your_audio.wav" \--video_out_path "output_video.mp4" \--inference_steps 20 \--guidance_scale 1.5
参数说明:
--video_path:原始视频路径--audio_path:目标音频文件--video_out_path:输出视频路径--inference_steps:迭代优化次数(值越大质量越高耗时越长)--guidance_scale:音频控制强度(值越大唇形同步精度越高)
执行后将在项目目录生成output_video.mp4,其中人物唇形已完美匹配新音频。
项目还提供基于Gradio的网页界面,通过可视化操作实现相同功能。
技术实现
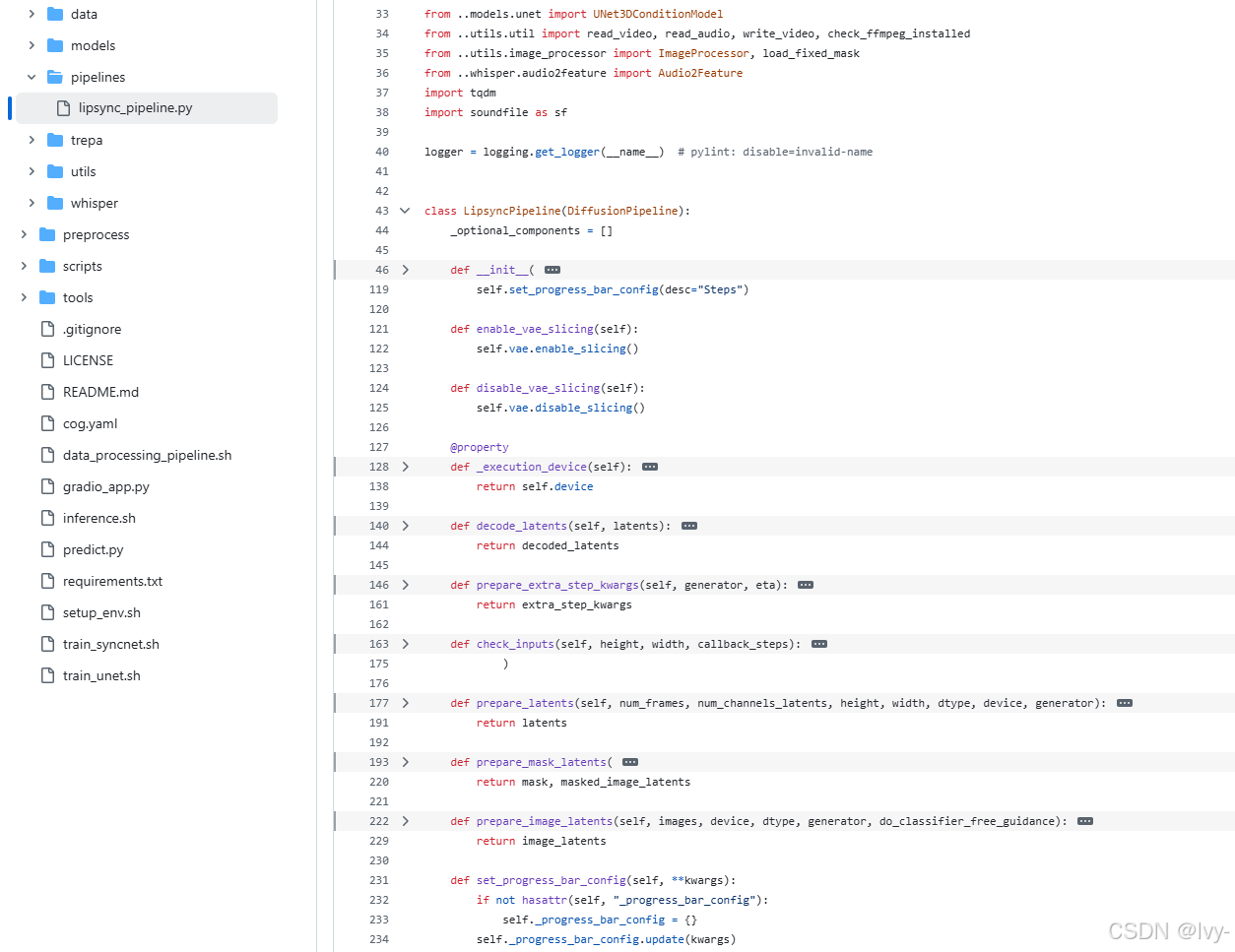
流程核心由LipsyncPipeline类实现(位于latentsync/pipelines/lipsync_pipeline.py),其工作流程如下:
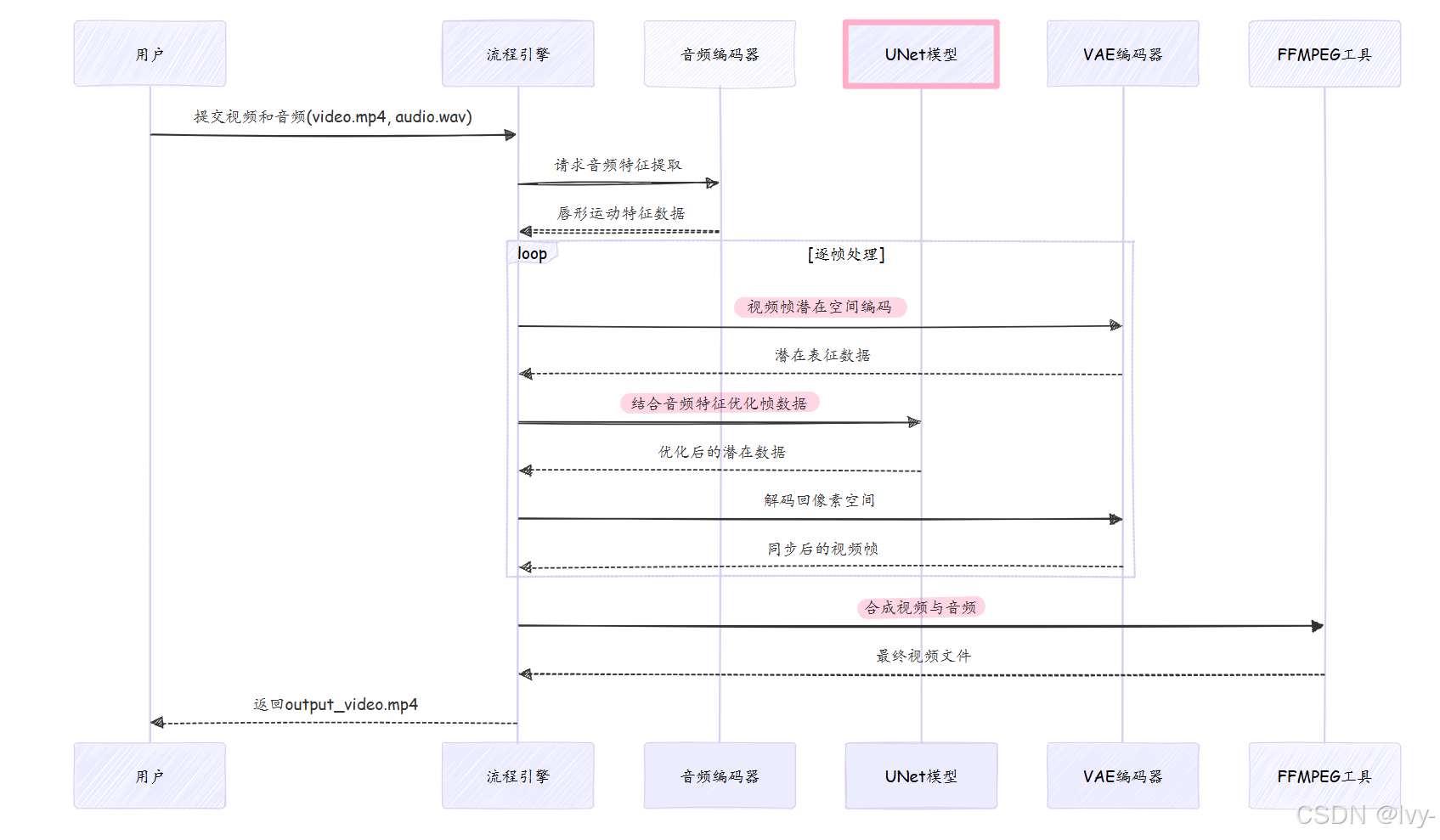
关键代码段
1. 模块初始化
class LipsyncPipeline(DiffusionPipeline):def __init__(self, vae, audio_encoder, unet, scheduler):self.register_modules(vae=vae,audio_encoder=audio_encoder,unet=unet,scheduler=scheduler,)
初始化时加载VAE(变分自编码器)、音频编码器、UNet(生成网络)和调度器等核心模块。
2. 音频特征提取
whisper_feature = self.audio_encoder.audio2feat(audio_path)
whisper_chunks = self.audio_encoder.feature2chunks(feature_array=whisper_feature, fps=video_fps)
使用Whisper模型将音频转换为唇形运动特征,并按视频帧率切分时间片段。
相关前文传送:[Meetily后端框架] Whisper转录服务器 | 后端服务管理脚本
⭕Whisper架构
Whisper是OpenAI推出的开源自动语音识别(ASR)系统,基于Transformer架构,专为多语言语音转录和翻译设计。
其核心特点包括大规模训练数据、端到端处理能力,以及支持多任务学习。
核心组件:
编码器-解码器结构:
- 编码器:将输入音频信号转换为
高维特征表示,使用卷积层降低序列长度后,通过Transformer块提取时序特征。 - 解码器:根据编码器输出生成文本,支持自回归预测(逐词生成)或直接输出完整序列。
多任务处理:
- 单一模型同时支持语音识别(转文本)和语音翻译(转目标语言文本),通过特殊标记(如
<|translate|>)切换任务模式。
特点:
大规模预训练:
- 训练数据覆盖68万小时多语言、多领域音频,包含弱监督数据(如网络音频与字幕对齐)。
多语言支持:
- 支持近百种语言的转录和翻译,通过语言识别模块自动判断输入语种。
鲁棒性优化:
- 对背景噪声、口音、跨语种混杂语音有较强适应能力,部分归功于
数据增强和多样化训练样本。
应用场景:
- 实时语音转写(如会议记录)。
- 跨语言翻译(如视频字幕生成)。
- 语音助手底层技术。
性能优势:
- 在无领域微调情况下,英语转录错误率(WER)接近人类水平(约2-3%)。
- 开源模型提供多种尺寸(如
tiny、base、large),平衡速度与精度需求。
3. 扩散过程核心循环
for j, t in enumerate(timesteps):noise_pred = self.unet(unet_input, t, encoder_hidden_states=audio_embeds).samplelatents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
通过UNet模型多轮迭代优化潜在表征,每轮结合音频特征调整唇形数据,由调度器控制优化步长。
4. 数据解码与融合
decoded_latents = self.decode_latents(latents)
synced_video_frames = self.paste_surrounding_pixels_back(decoded_latents, ref_pixel_values, 1 - masks)
将优化后的潜在数据解码为视频帧,并智能融合到原始视频中(仅修改唇部区域)。
5. 最终合成
command = f"ffmpeg -y -i temp/video.mp4 -i temp/audio.wav -c:v libx264 {video_out_path}"
subprocess.run(command, shell=True)
使用FFmpeg工具将处理后的视频帧与原始音频流合并输出最终视频。
总结
唇形同步推理流程作为LatentSync的中枢系统,通过:
- 标准化输入处理
- 多模态特征融合
- 迭代式帧优化
- 智能区域融合
- 流媒体合成
实现了影视级唇形同步效果。
下一章将深入解析其核心组件——LatentSync UNet模型的工作原理。
下一章:LatentSync UNet模型