【RAGFlow代码详解-14】知识图谱处理
系统架构
知识图谱处理流水线由 graphrag/general/index.py 中的 run_graphrag() 函数编排,实现子图生成、图合并、实体解析、社区检测四阶段工作流程。
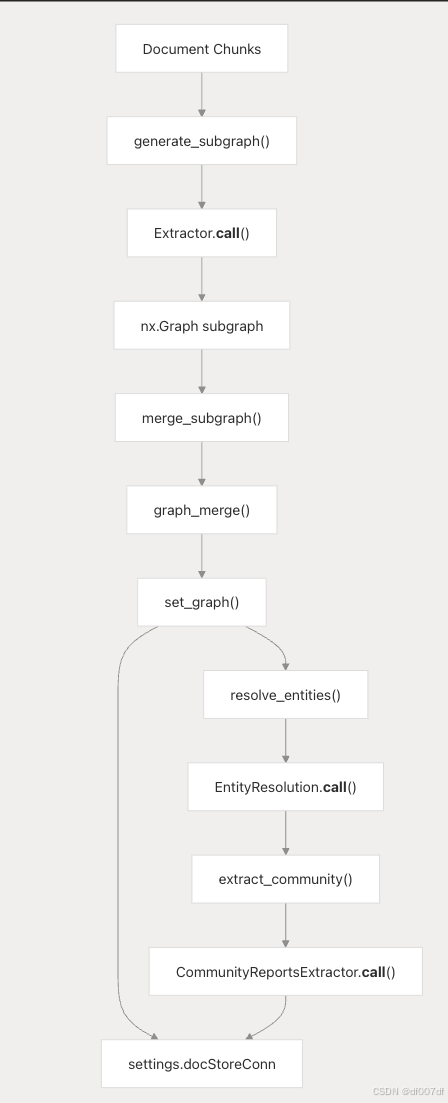
具有代码实体的知识图谱处理管道
系统通过 settings.docStoreConn 以多个索引形式存储图形数据:
- 序列化 nx.node_link_data 的全局图
- 每个文档 knowledge_graph_kwd: “subgraph” 的子图
- 带有 knowledge_graph_kwd 的实体块 :“实体”
- 关系 knowledge_graph_kwd: “relation” 块
- 社区报告 knowledge_graph_kwd: “community_report”
核心处理类
图提取器实现
提取系统是围绕抽象 Extractor 类构建的,具有通过配置选择的两个具体实现:
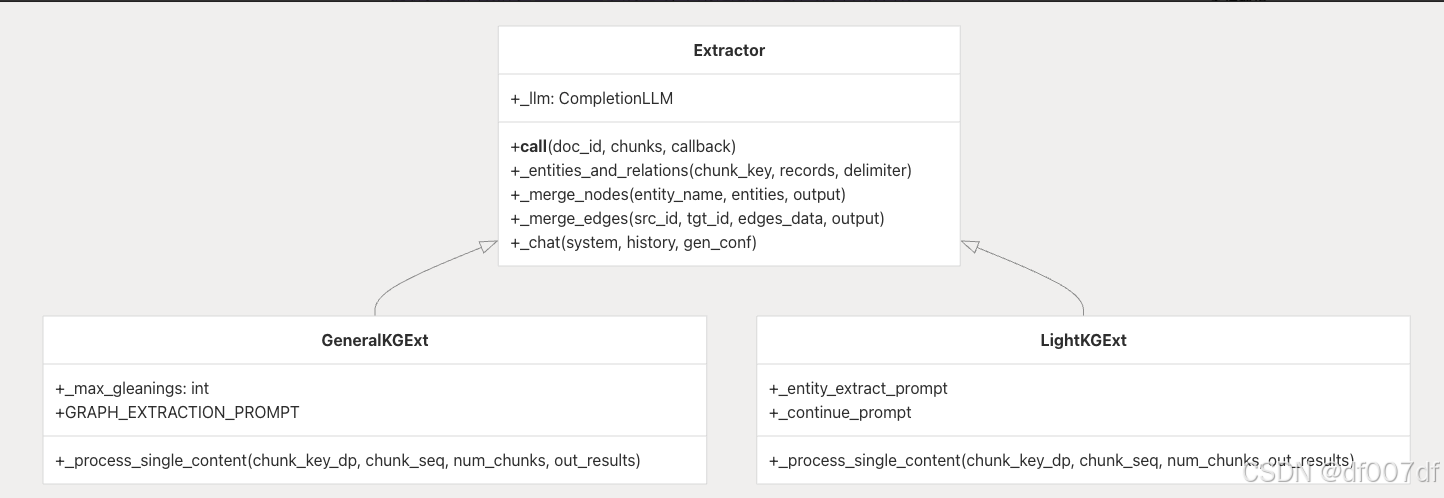
提取器类层次结构
generate_subgraph() 函数实例化适当的提取器:
Selection logic from graphrag/general/index.py:60-65
extractor = (LightKGExt if "method" not in row["kb_parser_config"].get("graphrag", {}) or row["kb_parser_config"]["graphrag"]["method"] != "general"else GeneralKGExt)
两个提取器都使用 trio.open_nursery() 以及 call 和 handle_single_relationship_extraction() 和 handle_single_entity_extraction() 函数同时处理块。
图作和存储
图形数据流经 graphrag/utils.py 中的几个实用函数:
具有函数名称的图形存储管道
GraphChange 数据类跟踪修改:
- removed_nodes: Set[str]
- added_updated_nodes: Set[str]
- removed_edges: Set[Tuple[str, str]]
- added_updated_edges: Set[Tuple[str, str]]
实体解析系统
EntityResolution 类使用字符串相似性和 LLM 确认合并相似实体:
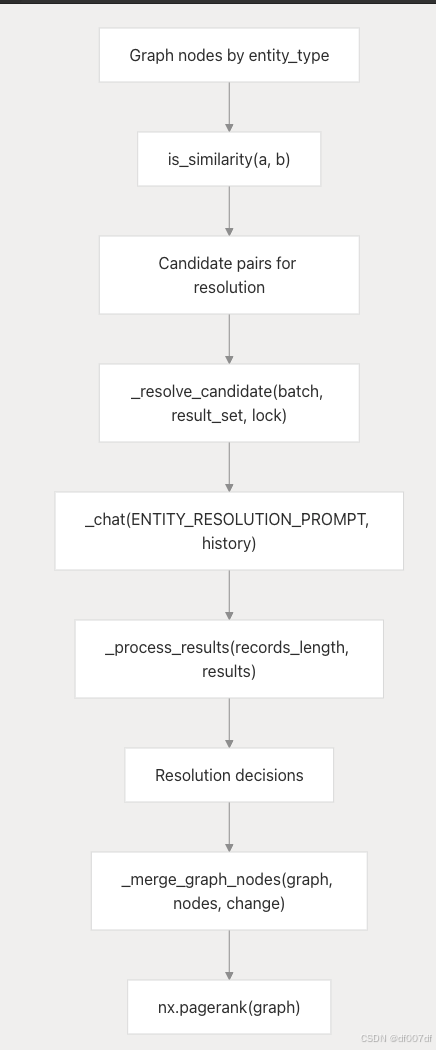
实体解析处理流程
EntityResolution.__call__() 方法使用并发处理 with trio.Semaphore(max_concurrent_tasks) 来限制并行 LLM 调用和 trio。Lock() 来协调结果更新。
相似性检测使用不同的算法:
- 英文文本:
editdistance.eval()用于字符级相似性 - 非英语文本:字符集与可配置阈值重叠
- 数字感知:
_has_digit_in_2gram_diff()防止错误匹配
管道执行和并发
任务编排
run_graphrag() 函数通过分布式锁定协调完整的处理流水线:
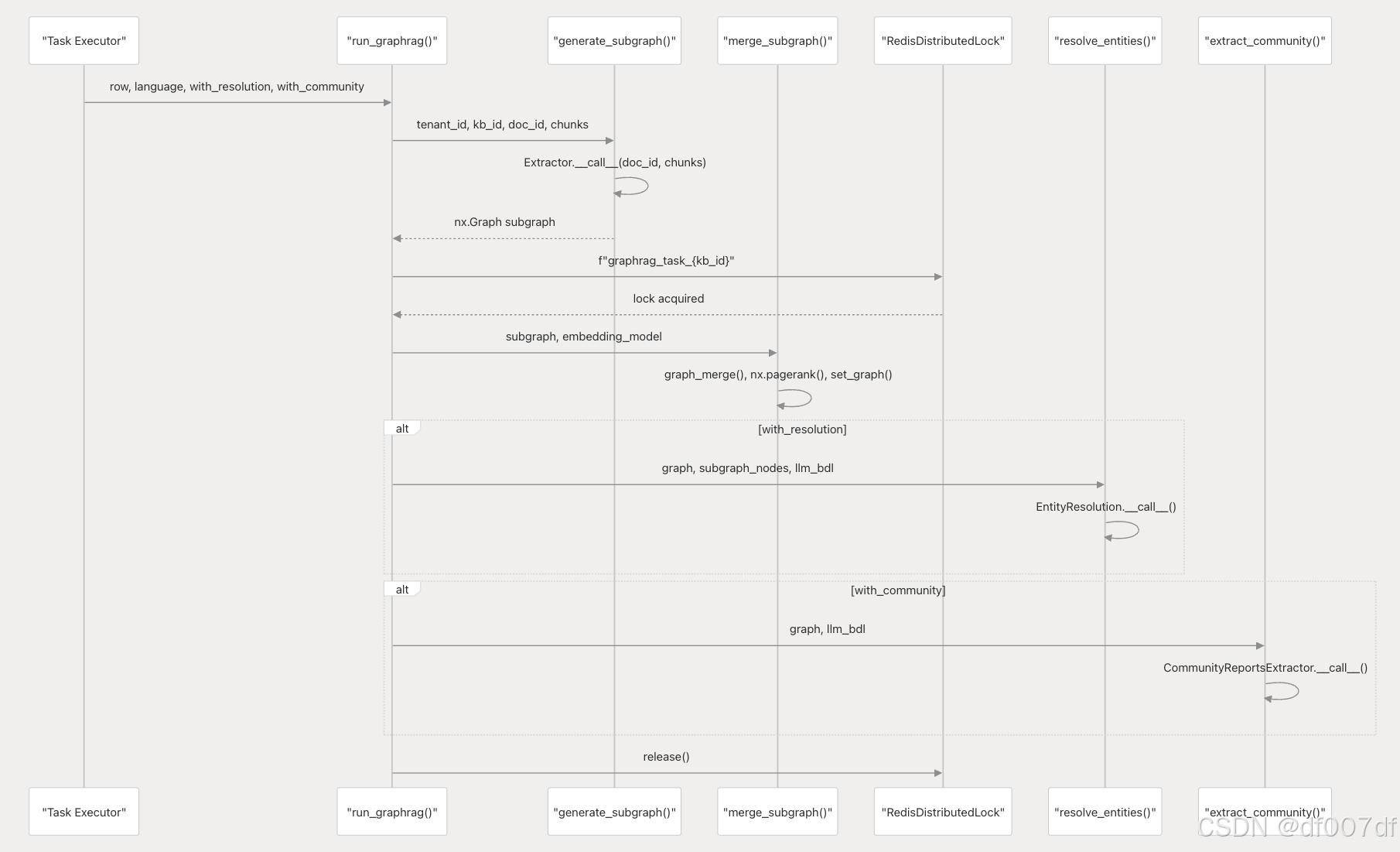
使用函数调用执行管道
并发控制和资源管理
系统使用 trio 异步原语实现多个并发控制:
| 元件 | 并发控制 | 目的 |
|---|---|---|
| chat_limiter = trio.CapacityLimiter(10) | LLM 请求速率限制 | 防止压倒性的 LLM API |
| RedisDistributedLock(f"graphrag_task_{kb_id}") | 进程间同步 | 防止并发图修改 |
| trio.Semaphore(max_concurrent_tasks) | 实体解析批处理 | 控制并行实体解析 |
| trio.open_nursery() | 并发块处理 | 并行化嵌入生成 |
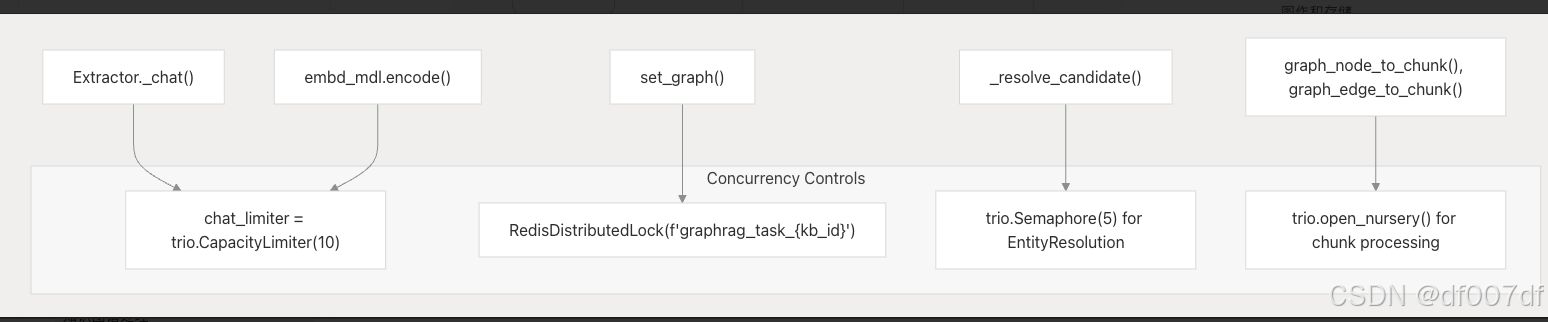
具有控制原语的并发架构
该 chat_limiter 是全局定义的,并在所有图形处理作中共享,以防止违反 API 速率限制。
社区检测和报告
莱顿算法集成
CommunityReportsExtractor 使用 Leiden 算法进行分层社区检测:
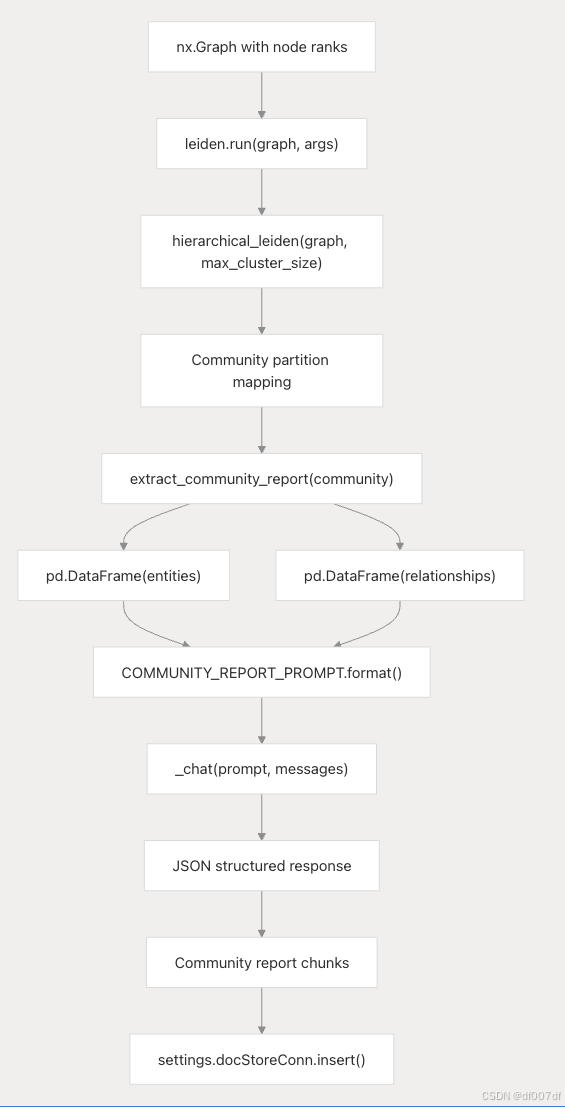
社区检测实施流程
leiden.run() 函数返回一个分层结构:
Return format from leiden.run()
results_by_level = {level: {community_id: {"weight": normalized_weight,"nodes": [node_list]}}
}社区报告生成
每个社区都通过以下方式 CommunityReportsExtractor.__call__() 生成结构化报告:
| 田 | 目的 | 数据源 |
|---|---|---|
| title | 社区标识符 | 从实体分析生成的 LLM |
| summary | 执行概况 | 实体关系和描述 |
| rating | 影响严重性 (0-10) | 社区重要性的法学硕士评估 |
| findings | 关键见解列表 | 实体属性和关系模式 |
| entities | 成员实体名称 | 社区节点成员资格 |
| weight | 社区重要性 | 成员的规范化 PageRank 总和 |
报告存储为块, knowledge_graph_kwd: "community_report" 以便在问答期间检索。
性能优化和缓存
基于 Redis 的缓存系统
系统使用 REDIS_CONN 实现多级缓存,用于昂贵的作:
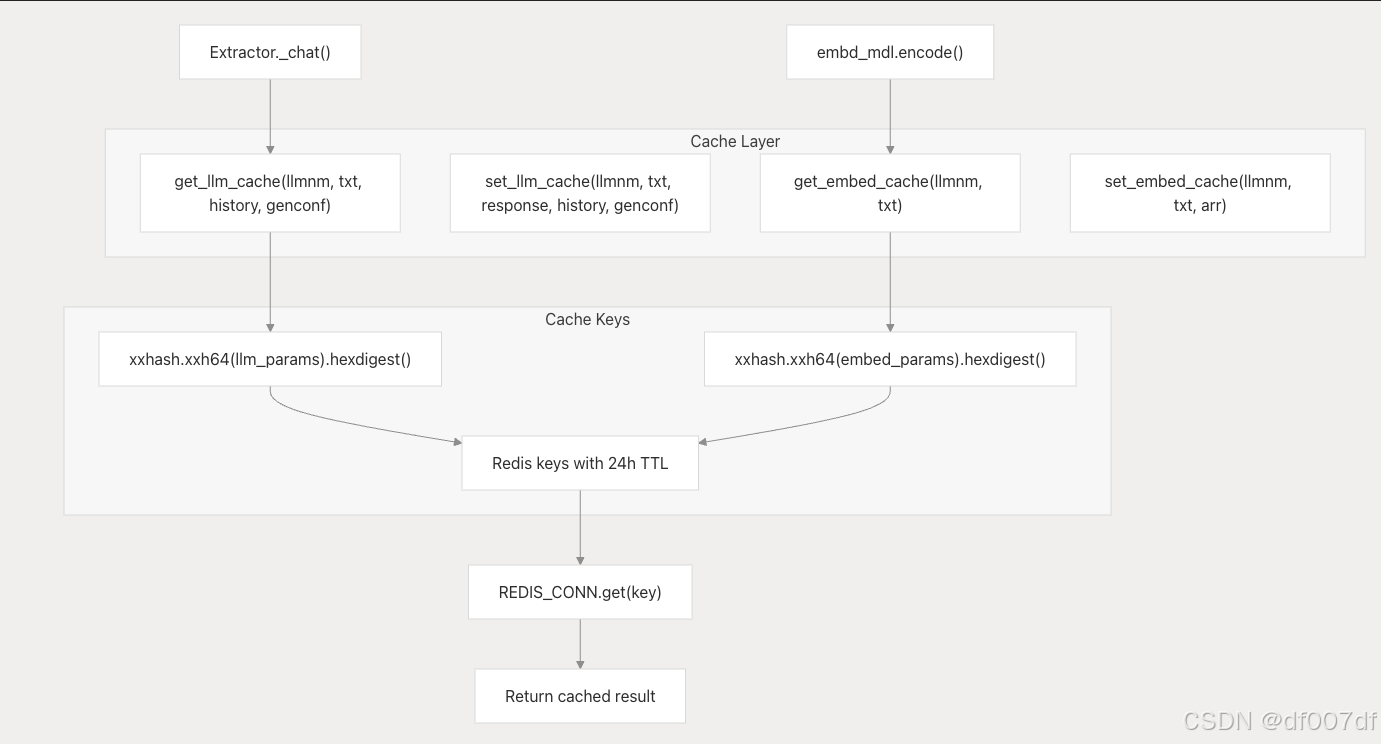
多级缓存架构
处理优化
系统通过多种机制优化性能:
| 优化 | 实现 | 位置 |
|---|---|---|
| 并发 LLM 调用 | trio.open_nursery() 与 chat_limiter | graphrag/general/extractor.py 105-108 |
| 批处理文档作 | es_bulk_size = 每个插入 4 个块 | graphrag/utils.py 517-525 |
| 文本截断 | truncate(ck, int(self._llm.max_length*0.8)) | graphrag/general/extractor.py 107 |
| 图重建 | rebuild_graph() 用于增量更新 graphrag/utils.py 605-647 | |
| 嵌入矢量化 | np.array(json.loads(bin)) 反序列化 | graphrag/utils.py 129 |
它可以 chat_limiter = trio.CapacityLimiter(10) 防止 LLM API 不堪重负,同时允许在整个图形处理管道中控制并发性。
配置和定制
解析器配置
GraphRAG 是通过知识库解析器设置配置的:
Example configuration structure
kb_parser_config = {"graphrag": {"method": "general", # or "light""entity_types": ["organization", "person", "location"],"with_resolution": True,"with_community": True}
}
提取方法
系统支持两种提取方法:
- 轻量级 :使用 LightKGExt 快速、轻量级提取
- 常规 :使用具有高级功能的 GeneralKGExt 进行全面提取
方法选择由配置决定:
From graphrag/general/index.py:60-63
extractor = (LightKGExt if "method" not in row["kb_parser_config"].get("graphrag", {}) or row["kb_parser_config"]["graphrag"]["method"] != "general"else GeneralKGExt)