Linux 详谈库制作与原理
目录
1. 什么是库
2. 静态库
静态库⽣成
静态库使⽤
3. 动态库
动态库⽣成
动态库使⽤
库运⾏搜索路径
问题
解决⽅案
4.⽬标⽂件
5. ELF⽂件
6. ELF从形成到加载轮廓
ELF形成可执⾏
ELF可执⾏⽂件加载
1. 什么是库
库是写好的现有的,成熟的,可以复⽤的代码。现实中每个程序都要依赖很多基础的底层库,不可能每个⼈的代码都从零开始,因此库的存在意义⾮同寻常。
本质上来说库是⼀种可执⾏代码的⼆进制形式,可以被操作系统载⼊内存执⾏。库有两种:
静态库 .a[Linux]、.lib[windows]
动态库 .so[Linux]、.dll[windows]
// ubuntu 动静态库
// C
$ ls -l /lib/x86_64-linux-gnu/libc-2.31.so
-rwxr-xr-x 1 root root 2029592 May 1 02:20 /lib/x86_64-linux-gnu/libc-2.31.so
$ ls -l /lib/x86_64-linux-gnu/libc.a
-rw-r--r-- 1 root root 5747594 May 1 02:20 /lib/x86_64-linux-gnu/libc.a
//C++
$ ls /usr/lib/gcc/x86_64-linux-gnu/9/libstdc++.so -l
lrwxrwxrwx 1 root root 40 Oct 24 2022 /usr/lib/gcc/x86_64-linuxgnu/9/libstdc++.so -> ../../../x86_64-linux-gnu/libstdc++.so.6
$ ls /usr/lib/gcc/x86_64-linux-gnu/9/libstdc++.a
/usr/lib/gcc/x86_64-linux-gnu/9/libstdc++.a// Centos 动静态库
// C
$ ls /lib64/libc-2.17.so -l
-rwxr-xr-x 1 root root 2156592 Jun 4 23:05 /lib64/libc-2.17.so[yzk@yzk-alicloud ~]$ ls /lib64/libc.a -l
rw-r--r-- 1 root root 5105516 Jun 4 23:05 /lib64/libc.a
// C++
$ ls /lib64/libstdc++.so.6 -l
lrwxrwxrwx 1 root root 19 Sep 18 20:59 /lib64/libstdc++.so.6 ->
libstdc++.so.6.0.19
$ ls /usr/lib/gcc/x86_64-redhat-linux/4.8.2/libstdc++.a -l
-rw-r--r-- 1 root root 2932366 Sep 30 2020 /usr/lib/gcc/x86_64-redhatlinux/4.8.2/libstdc++.a预备⼯作,准备好历史封装的libc代码,在任意新增"库⽂件"
// my_stdio.h
#pragma once
#define SIZE 1024
#define FLUSH_NONE 0
#define FLUSH_LINE 1
#define FLUSH_FULL 2
struct IO_FILE
{int flag; // 刷新⽅式int fileno; // ⽂件描述符char outbuffer[SIZE];int cap;int size;// TODO
};
typedef struct IO_FILE mFILE;
mFILE* mfopen(const char* filename, const char* mode);
int mfwrite(const void* ptr, int num, mFILE* stream);
void mfflush(mFILE* stream);
void mfclose(mFILE* stream);
// my_stdio.c
#include "my_stdio.h"
#include <string.h>
#include <stdlib.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <unistd.h>
mFILE* mfopen(const char* filename, const char* mode)
{int fd = -1;if (strcmp(mode, "r") == 0){fd = open(filename, O_RDONLY);}else if (strcmp(mode, "w") == 0){fd = open(filename, O_CREAT | O_WRONLY | O_TRUNC, 0666);}else if (strcmp(mode, "a") == 0){fd = open(filename, O_CREAT | O_WRONLY | O_APPEND, 0666);}if (fd < 0) return NULL;mFILE* mf = (mFILE*)malloc(sizeof(mFILE));if (!mf){close(fd);return NULL;}mf->fileno = fd;mf->flag = FLUSH_LINE;mf->size = 0;mf->cap = SIZE;return mf;
}
void mfflush(mFILE* stream)
{if (stream->size > 0){// 写到内核⽂件的⽂件缓冲区中!write(stream->fileno, stream->outbuffer, stream->size);// 刷新到外设fsync(stream->fileno);stream->size = 0;}
}
int mfwrite(const void* ptr, int num, mFILE* stream)
{// 1. 拷⻉memcpy(stream->outbuffer + stream->size, ptr, num);stream->size += num;// 2. 检测是否要刷新if (stream->flag == FLUSH_LINE && stream->size > 0 && stream -
> outbuffer[stream->size - 1] == '\n'){mfflush(stream);}return num;
}
void mfclose(mFILE* stream)
{if (stream->size > 0){mfflush(stream);}close(stream->fileno);
}
// my_string.h
#pragma once
int my_strlen(const char* s);
// my_string.c
#include "my_string.h"
int my_strlen(const char* s)
{const char* end = s;while (*end != '\0')end++;return end - s;
}2. 静态库
静态库(.a):程序在编译链接的时候把库的代码链接到可执⾏⽂件中,程序运⾏的时候将不再需要静态库。
⼀个可执⾏程序可能⽤到许多的库,这些库运⾏有的是静态库,有的是动态库,⽽我们的编译默认为动态链接库,只有在该库下找不到动态.so的时候才会采⽤同名静态库。我们也可以使⽤ gcc的 -static 强转设置链接静态库。
静态库⽣成
// Makefile
libmystdio.a:my_stdio.o my_string.o@ar - rc $@ $ ^@echo "build $^ to $@ ... done"
% .o: % .c@gcc - c $ <@echo "compling $< to $@ ... done"
.PHONY:clean
clean :@rm - rf * .a * .o stdc *@echo "clean ... done"
.PHONY:output
output :@mkdir - p stdc / include@mkdir - p stdc / lib@cp - f * .h stdc / include@cp - f * .a stdc / lib@tar - czf stdc.tgz stdc@echo "output stdc ... donear 是 gnu 归档⼯具, rc 表⽰ (replace and create)
$ ar -tv libmystdio.a
rw-rw-r-- 1000/1000 2848 Oct 29 14:35 2024 my_stdio.o
rw-rw-r-- 1000/1000 1272 Oct 29 14:35 2024 my_string.ot: 列出静态库中的⽂件
v:verbose 详细信息
静态库使⽤
// 任意⽬录下,新建
// main.c,引⼊库头⽂件
#include "my_stdio.h"
#include "my_string.h"
#include <stdio.h>
int main()
{const char* s = "abcdefg";printf("%s: %d\n", s, my_strlen(s));mFILE* fp = mfopen("./log.txt", "a");if (fp == NULL) return 1;mfwrite(s, my_strlen(s), fp);mfwrite(s, my_strlen(s), fp);mfwrite(s, my_strlen(s), fp);mfclose(fp);return 0;
}
// 场景1:头⽂件和库⽂件安装到系统路径下
$ gcc main.c -lmystdio
// 场景2:头⽂件和库⽂件和我们⾃⼰的源⽂件在同⼀个路径下
$ gcc main.c -L. -lmymath
// 场景3:头⽂件和库⽂件有⾃⼰的独⽴路径
$ gcc main.c -I头⽂件路径 -L库⽂件路径 -lmymath-L: 指定库路径
-I: 指定头⽂件搜索路径
-l: 指定库名
测试⽬标⽂件⽣成后,静态库删掉,程序照样可以运⾏
关于 -static 选项,稍后介绍
库⽂件名称和引⼊库的名称:去掉前缀 lib ,去掉后缀 .so , .a ,如: libc.so -> c
3. 动态库
动态库(.so):程序在运⾏的时候才去链接动态库的代码,多个程序共享使⽤库的代码。
⼀个与动态库链接的可执⾏⽂件仅仅包含它⽤到的函数⼊⼝地址的⼀个表,⽽不是外部函数所在⽬标⽂件的整个机器码
在可执⾏⽂件开始运⾏以前,外部函数的机器码由操作系统从磁盘上的该动态库中复制到内存中,这个过程称为动态链接(dynamic linking)
动态库可以在多个程序间共享,所以动态链接使得可执⾏⽂件更⼩,节省了磁盘空间。操作系统采⽤虚拟内存机制允许物理内存中的⼀份动态库被要⽤到该库的所有进程共⽤,节省了内存和磁盘空间。
动态库⽣成
// Makefile
libmystdio.so:my_stdio.o my_string.ogcc -o $@ $^ -shared
%.o:%.cgcc -fPIC -c $<
.PHONY:clean
clean:@rm -rf *.so *.o stdc*@echo "clean ... done"
.PHONY:output
output:@mkdir -p stdc/include@mkdir -p stdc/lib@cp -f *.h stdc/include@cp -f *.so stdc/lib@tar -czf stdc.tgz stdc@echo "output stdc ... done"shared: 表⽰⽣成共享库格式
fPIC:产⽣位置⽆关码(position independent code)
库名规则:libxxx.so
动态库使⽤
// 场景1:头⽂件和库⽂件安装到系统路径下
$ gcc main.c -lmystdio
// 场景2:头⽂件和库⽂件和我们⾃⼰的源⽂件在同⼀个路径下
$ gcc main.c -L. -lmymath // 从左到右搜索-L指定的⽬录
// 场景3:头⽂件和库⽂件有⾃⼰的独⽴路径
$ gcc main.c -I头⽂件路径 -L库⽂件路径 -lmymath
$ ldd libmystdio.so // 查看库或者可执⾏程序的依赖
linux-vdso.so.1 => (0x00007fffacbbf000)
libc.so.6 => /lib64/libc.so.6 (0x00007f8917335000)
/lib64/ld-linux-x86-64.so.2 (0x00007f8917905000)
// 以场景2为例
$ ll
total 24
-rwxrwxr-x 1 yzk yzk 8592 Oct 29 14:50 libmystdio.so
-rw-rw-r-- 1 yzk yzk 359 Oct 19 16:07 main.c
-rw-rw-r-- 1 yzk yzk 447 Oct 29 14:50 my_stdio.h
-rw-rw-r-- 1 yzk yzk 447 Oct 29 14:50 my_string.h
$ gcc main.c -L. -lmystdio
$ ll
total 36
-rwxrwxr-x 1 yzk yzk 8600 Oct 29 14:51 a.out
-rwxrwxr-x 1 yzk yzk 8592 Oct 29 14:50 libmystdio.so
-rw-rw-r-- 1 yzk yzk 359 Oct 19 16:07 main.c
-rw-rw-r-- 1 yzk yzk 447 Oct 29 14:50 my_stdio.h
-rw-rw-r-- 1 yzk yzk 447 Oct 29 14:50 my_string.h
[yzk@yzk-alicloud other]$ ./a.out
...库运⾏搜索路径
问题
$ ldd a.outlinux-vdso.so.1 => (0x00007fff4d396000)libmystdio.so => not foundlibc.so.6 => /lib64/libc.so.6 (0x00007fa2aef30000)/lib64/ld-linux-x86-64.so.2 (0x00007fa2af2fe000)解决⽅案
拷⻉ .so ⽂件到系统共享库路径下, ⼀般指 /usr/lib、/usr/local/lib、/lib64 或者开篇指明的库路径等
向系统共享库路径下建⽴同名软连接
更改环境变量: LD_LIBRARY_PATH
ldconfig⽅案:配置/ etc/ld.so.conf.d/ ,ldconfig更新
[root@localhost linux]# cat /etc/ld.so.conf.d/bit.conf
/root/tools/linux
[root@localhost linux]# ldconfig // 要⽣效,这⾥要执⾏ldconfig,重新加载库搜索路径4.⽬标⽂件
编译和链接这两个步骤,在Windows下被我们的IDE封装的很完美,我们⼀般都是⼀键构建⾮常⽅便,但⼀旦遇到错误的时候呢,尤其是链接相关的错误,很多⼈就束⼿⽆策了。在Linux下,我们之前也学习过如何通过gcc编译器来完成这⼀系列操作。
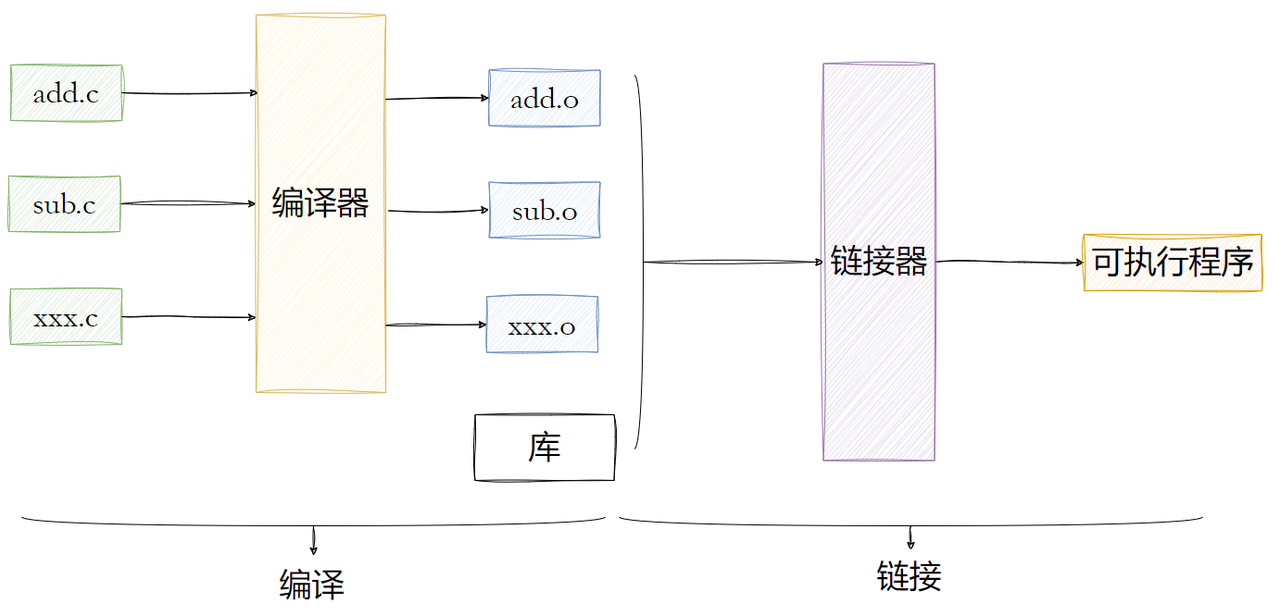
接下来我们深⼊探讨⼀下编译和链接的整个过程,来更好的理解动静态库的使⽤原理。
先来回顾下什么是编译呢?编译的过程其实就是将我们程序的源代码翻译成CPU能够直接运⾏的机器代码。
⽐如:在⼀个源⽂件 hello.c ⾥便简单输出"hello world!",并且调⽤⼀个run函数,⽽这个函数被定义在另⼀个原⽂件 code.c 中。这⾥我们就可以调⽤ gcc -c 来分别编译这两个原⽂件。
// hello.c
#include<stdio.h>
void run();
int main() {printf("hello world!\n");run();return 0;
}
// code.c
#include<stdio.h>
void run() {printf("running...\n");
}// 编译两个源⽂件
$ gcc -c hello.c
$ gcc -c code.c
$ ls
code.c code.o hello.c hello.o可以看到,在编译之后会⽣成两个扩展名为 .o 的⽂件,它们被称作⽬标⽂件。要注意的是如果我们修改了⼀个原⽂件,那么只需要单独编译它这⼀个,⽽不需要浪费时间重新编译整个⼯程。⽬标⽂件是⼀个⼆进制的⽂件,⽂件的格式是 ELF ,是对⼆进制代码的⼀种封装。
$ file hello.o
hello.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
## file命令⽤于辨识⽂件类型。5. ELF⽂件
要理解编译链链接的细节,我们不得不了解⼀下ELF⽂件。其实有以下四种⽂件其实都是ELF⽂件:
可重定位⽂件(Relocatable File) :即 xxx.o ⽂件。包含适合于与其他⽬标⽂件链接来创
建可执⾏⽂件或者共享⽬标⽂件的代码和数据。
可执⾏⽂件(Executable File) :即可执⾏程序。
共享⽬标⽂件(Shared Object File) :即 xxx.so⽂件。
内核转储(core dumps) ,存放当前进程的执⾏上下⽂,⽤于dump信号触发。
⼀个ELF⽂件由以下四部分组成:
ELF头(ELF header) :描述⽂件的主要特性。其位于⽂件的开始位置,它的主要⽬的是定位⽂件的其他部分。
程序头表(Program header table) :列举了所有有效的段(segments)和他们的属性。表⾥记着每个段的开始的位置和位移(offset)、⻓度,毕竟这些段,都是紧密的放在⼆进制⽂件中,需要段表的描述信息,才能把他们每个段分割开。
节头表(Section header table) :包含对节(sections)的描述。
节(Section ):ELF⽂件中的基本组成单位,包含了特定类型的数据。ELF⽂件的各种信息和数据都存储在不同的节中,如代码节存储了可执⾏代码,数据节存储了全局变量和静态数据等。
最常⻅的节:
代码节(.text):⽤于保存机器指令,是程序的主要执⾏部分。
数据节(.data):保存已初始化的全局变量和局部静态变量。
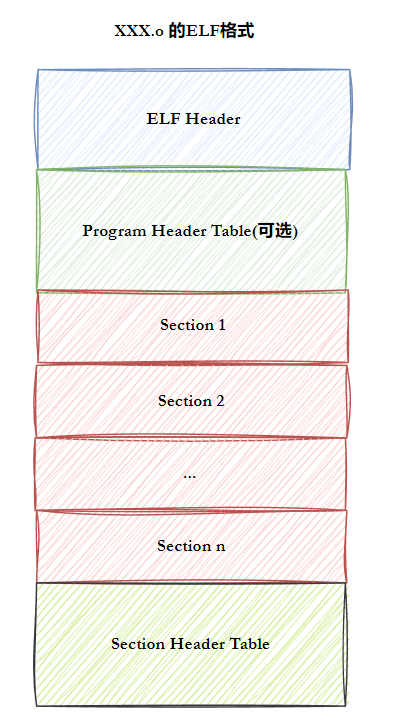
6. ELF从形成到加载轮廓
ELF形成可执⾏
step-1:将多份 C/C++ 源代码,翻译成为⽬标 .o ⽂件
step-2:将多份 .o ⽂件section进⾏合并
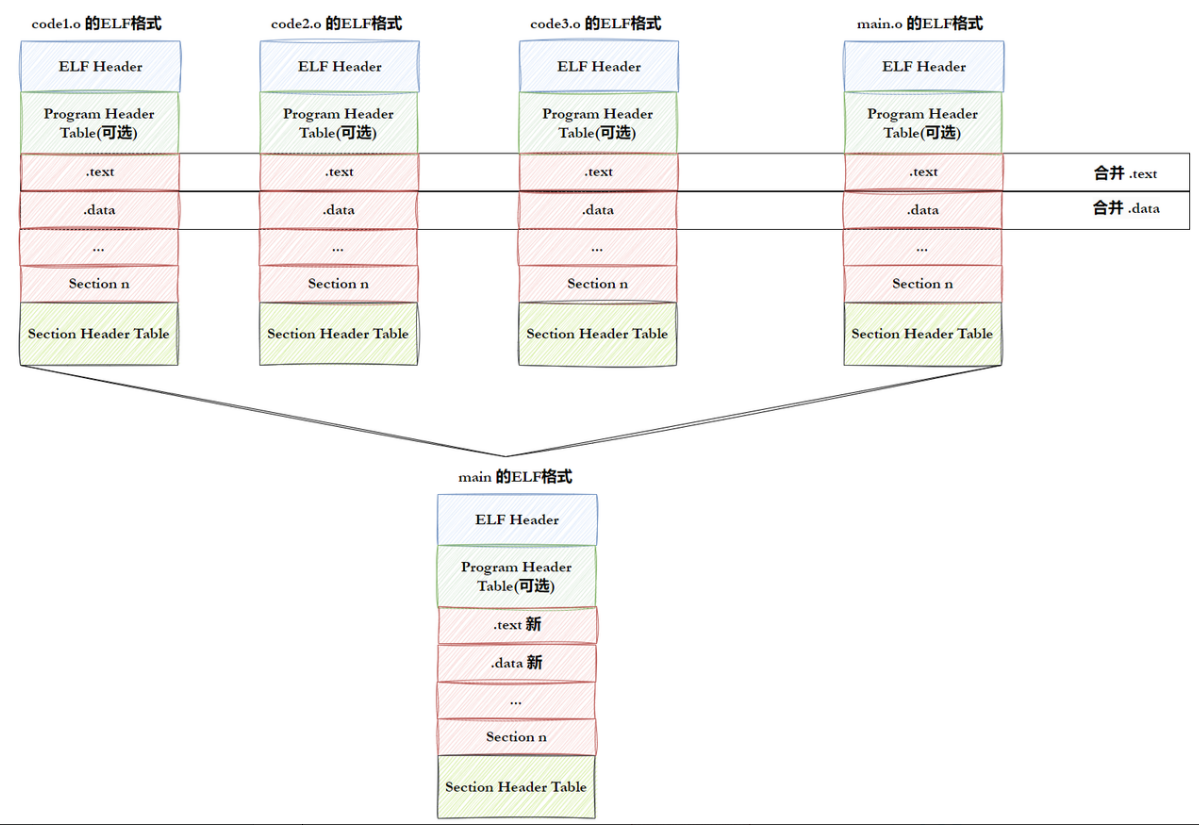
注意:实际合并是在链接时进⾏的,但是并不是这么简单的合并,也会涉及对库合并,此处不做过多追究
ELF可执⾏⽂件加载
⼀个ELF会有多种不同的Section,在加载到内存的时候,也会进⾏Section合并,形成segment合并原则:相同属性,⽐如:可读,可写,可执⾏,需要加载时申请空间等.
这样,即便是不同的Section,在加载到内存中,可能会以segment的形式,加载到⼀起很显然,这个合并⼯作也已经在形成ELF的时候,合并⽅式已经确定了,具体合并原则被记录在了ELF的 程序头表(Program header table) 中
# 查看可执⾏程序的section
$ readelf -S a.out
There are 31 section headers, starting at offset 0x19d8:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .interp PROGBITS 0000000000400238 00000238
000000000000001c 0000000000000000 A 0 0 1
[ 2] .note.ABI-tag NOTE 0000000000400254 00000254
0000000000000020 0000000000000000 A 0 0 4
[ 3] .note.gnu.build-i NOTE 0000000000400274 00000274
0000000000000024 0000000000000000 A 0 0 4
[ 4] .gnu.hash GNU_HASH 0000000000400298 00000298
000000000000001c 0000000000000000 A 5 0 8
[ 5] .dynsym DYNSYM 00000000004002b8 000002b8
0000000000000048 0000000000000018 A 6 1 8
[ 6] .dynstr STRTAB 0000000000400300 00000300
0000000000000038 0000000000000000 A 0 0 1
[ 7] .gnu.version VERSYM 0000000000400338 00000338
0000000000000006 0000000000000002 A 5 0 2
[ 8] .gnu.version_r VERNEED 0000000000400340 00000340
0000000000000020 0000000000000000 A 6 1 8
[ 9] .rela.dyn RELA 0000000000400360 00000360
0000000000000018 0000000000000018 A 5 0 8
[10] .rela.plt RELA 0000000000400378 00000378
0000000000000018 0000000000000018 AI 5 24 8
[11] .init PROGBITS 0000000000400390 00000390
...
# 查看section合并的segment
$ readelf -l a.out
Elf file type is EXEC (Executable file)
Entry point 0x4003e0
There are 9 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
PHDR 0x0000000000000040 0x0000000000400040 0x0000000000400040
0x00000000000001f8 0x00000000000001f8 R E 8
INTERP 0x0000000000000238 0x0000000000400238 0x0000000000400238
0x000000000000001c 0x000000000000001c R 1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000
0x0000000000000744 0x0000000000000744 R E 200000
LOAD 0x0000000000000e10 0x0000000000600e10 0x0000000000600e10
0x0000000000000218 0x0000000000000220 RW 200000
DYNAMIC 0x0000000000000e28 0x0000000000600e28 0x0000000000600e28
0x00000000000001d0 0x00000000000001d0 RW 8
NOTE 0x0000000000000254 0x0000000000400254 0x0000000000400254
0x0000000000000044 0x0000000000000044 R 4
GNU_EH_FRAME 0x00000000000005a0 0x00000000004005a0 0x00000000004005a0
0x000000000000004c 0x000000000000004c R 4
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 10
GNU_RELRO 0x0000000000000e10 0x0000000000600e10 0x0000000000600e10
0x00000000000001f0 0x00000000000001f0 R 1
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.ABI-tag .note.gnu.build-id .gnu.hash .dynsym .dynstr
.gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .plt.got .text
.fini .rodata .eh_frame_hdr .eh_frame
03 .init_array .fini_array .jcr .dynamic .got .got.plt .data .bss
04 .dynamic
05 .note.ABI-tag .note.gnu.build-id
06 .eh_frame_hdr
07
08 .init_array .fini_array .jcr .dynamic .got为什么要将section合并成为segmentSection合并的主要原因是为了减少⻚⾯碎⽚,提⾼内存使⽤效率。如果不进⾏合并,假设⻚⾯⼤⼩为4096字节(内存块基本⼤⼩,加载,管理的基本单位),如果.text部分为4097字节,.init部分为512字节,那么它们将占⽤3个⻚⾯,⽽合并后,它们只需2个⻚⾯。此外,操作系统在加载程序时,会将具有相同属性的section合并成⼀个⼤的segment,这样就可以实现不同的访问权限,从⽽优化内存管理和权限访问控制。
对于 程序头表 和 节头表 ⼜有什么⽤呢,其实 ELF ⽂件提供 2 个不同的视图/视⻆来让我们理解这两个部分:
链接视图(Linking view) - 对应节头表 Section header table
⽂件结构的粒度更细,将⽂件按功能模块的差异进⾏划分,静态链接分析的时候⼀般关注的是链接视图,能够理解 ELF ⽂件中包含的各个部分的信息。
为了空间布局上的效率,将来在链接⽬标⽂件时,链接器会把很多节(section)合并,规整成可执⾏的段(segment)、可读写的段、只读段等。合并了后,空间利⽤率就⾼了,否则,很⼩的很⼩的⼀段,未来物理内存⻚浪费太⼤(物理内存⻚分配⼀般都是整数倍⼀块给你,⽐如4k),所以,链接器趁着链接就把⼩块们都合并了。执⾏视图(execution view) - 对应程序头表 Program header table
告诉操作系统,如何加载可执⾏⽂件,完成进程内存的初始化。⼀个可执⾏程序的格式中,⼀定有 program header table 。
说⽩了就是:⼀个在链接时作⽤,⼀个在运⾏加载时作⽤。
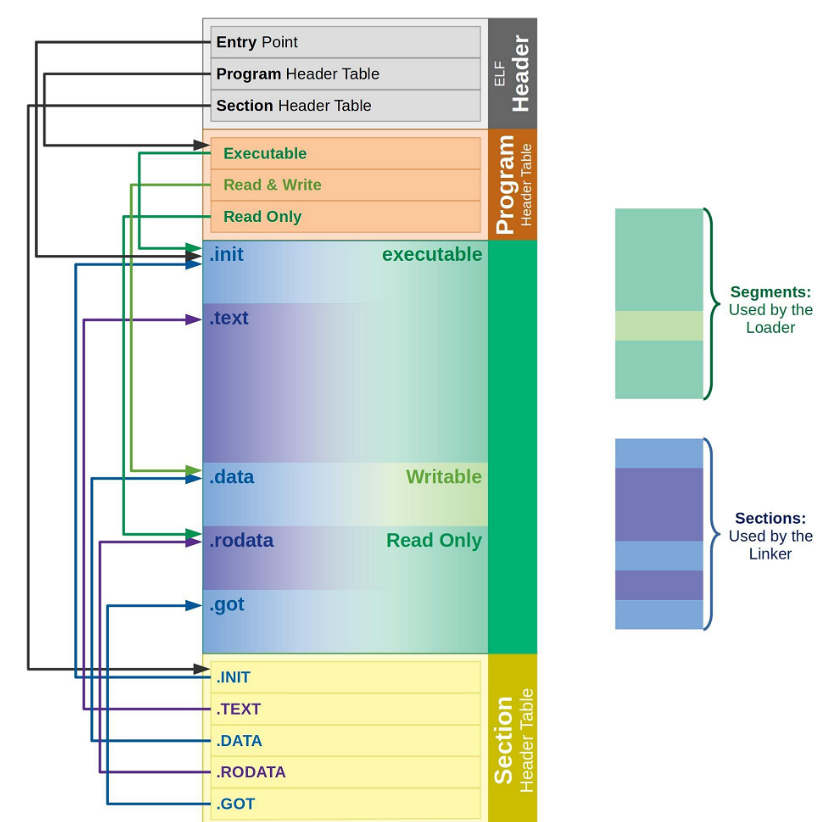
从 链接视图 来看:
命令 readelf -S hello.o 可以帮助查看ELF⽂件的 节头表。
.text节 :是保存了程序代码指令的代码节。
.data节 :保存了初始化的全局变量和局部静态变量等数据。
.rodata节 :保存了只读的数据,如⼀⾏C语⾔代码中的字符串。由于.rodata节是只读的,所以只能存在于⼀个可执⾏⽂件的只读段中。因此,只能是在text段(不是data段)中找到.rodata节。
.BSS节 :为未初始化的全局变量和局部静态变量预留位置
.symtab节 : Symbol Table 符号表,就是源码⾥⾯那些函数名、变量名和代码的对应关系。
.got.plt节 (全局偏移表-过程链接表):.got节保存了全局偏移表。.got节和.plt节⼀起提供了对导⼊的共享库函数的访问⼊⼝,由动态链接器在运⾏时进⾏修改。对于GOT的理解,我们后⾯会说。
使⽤ readelf 命令查看 .so ⽂件可以看到该节。
从 执⾏视图 来看:
告诉操作系统哪些模块可以被加载进内存。
加载进内存之后哪些分段是可读可写,哪些分段是只读,哪些分段是可执⾏的。
我们可以在 ELF头 中找到⽂件的基本信息,以及可以看到ELF头是如何定位程序头表和节头表的。例如我们查看下hello.o这个可重定位⽂件的主要信息:
// 查看⽬标⽂件
$ readelf -h hello.o
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64 # ⽂件类
型
Data: 2's complement, little endian # 指定的
编码⽅式
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file) # 指出ELF
⽂件的类型
Machine: Advanced Micro Devices X86-64 # 该程序
需要的体系结构
Version: 0x1
Entry point address: 0x0 # 系统第
⼀个传输控制的虚拟地址,在那启动进程。假如⽂件没有如何关联的⼊⼝点,该成员就保持为0。
Start of program headers: 0 (bytes into file)
Start of section headers: 728 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes) # 保存着ELF头⼤⼩(以字节计数)
Size of program headers: 0 (bytes) # 保存着在⽂件的程序头表
(program header table)中⼀个⼊⼝的⼤⼩
Number of program headers: 0 # 保存着在程序头表中⼊⼝的个
数。因此,e_phentsize和e_phnum的乘机就是表的⼤⼩(以字节计数).假如没有程序头表,变量为0。
Size of section headers: 64 (bytes) # 保存着section头的⼤⼩(以字节
计数)。⼀个section头是在section头表的⼀个⼊⼝
Number of section headers: 13 # 保存着在section header
table中的⼊⼝数⽬。因此,e_shentsize和e_shnum的乘积就是section头表的⼤⼩(以字节计数)。
假如⽂件没有section头表,值为0。
Section header string table index: 12 # 保存着跟section名字字符表相
关⼊⼝的section头表(section header table)索引。
// 查看可执⾏程序
$ gcc *.o
$ readelf -h a.out
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: DYN (Shared object file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x1060
Start of program headers: 64 (bytes into file)
Start of section headers: 14768 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 13
Size of section headers: 64 (bytes)
Number of section headers: 31
Section header string table index: 30对于 ELF HEADER 这部分来说,我们只⽤知道其作⽤即可,它的主要⽬的是定位⽂件的其他部分。