Hive的核心架构
Hive中的核心组件有MetaStore、HiveServer2、Hive Client
MetaStore是元数据信息的访问接口,它不直接存储元数据的信息。而元数据信息默认是存储在Derby数据库中的,里面存储着数据库、表、表中的字段等数据的信息。默认确实是保存在Java自带的Derby数据库中的,但是由于derby数据库不支持并发,也就是说不支持同时两个客户端去操作derby数据库,因此通常情况下都会再去配置一个mysql数据库去存放元数据。
HiveServer2有两个功能,一个是提供JDBC/ODBC的访问接口,一个是提供用户认证的相关功能。
Hive Client提供了关于客户端访问Hive数据库的两种方式,分别是CLI和JDBC/ODBC。CLI的方式只是在安装了Hive的本地的客户端上能使用;如果想要远程访问Hive,那就需要使用另一种方式JDBC/ODBC。
下面是一个具体的实例:
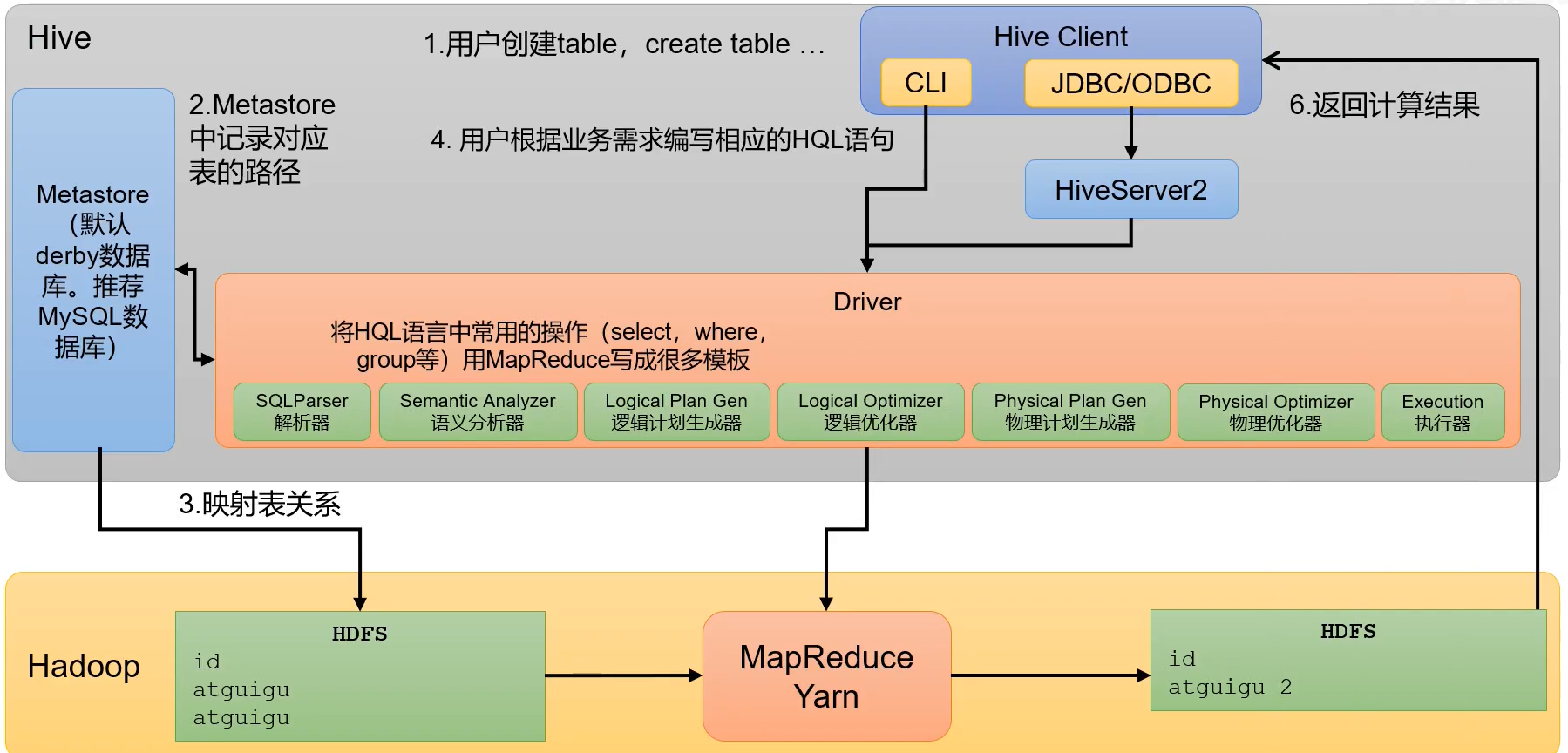
整体的情况是这样的:我在客户端执行了一条DDL命令,创建了一张数据表,然后MetaStore会保存这张表的元数据信息,并将具体的数据存储在HDFS上面。然后又在客户端执行Hive SQL语句来操作具体的表,在执行Hive SQL语句时会先对SQL语句进行解析,转化为MapReduce程序,然后再提交给Yarn进行资源的调配和运行。在SQL解析时会经过一个Driver程序,如果客户端是用的CLI来操作的,那么Driver就位于CLI中,如果客户端是远程写入的SQL,那么Driver就是位于HiveServer2中的。Driver的详细原理见下。

Driver驱动器中有七个部分组成,分别是解析器、语法分析器、逻辑计划生成器、逻辑优化器、物理计划生成器、物理优化器、执行器。
(1)、解析器:将SQL字符串转换成抽象语法树(AST)
(2)、语法分析树:将抽象语法树进一步划分为查询块(QeuryBlock)
(3)、逻辑计划生成器:根据语法树生成逻辑计划
(4)、逻辑优化器:对生成的逻辑计划进行优化。例如谓词下推
(5)、物理计划生成器:根据优化后的逻辑计划生成物理计划
(6)、物理优化器:对生成的物理计划进行优化。例如Map Join优化
(7)、执行器:执行计划,并将执行结果返回给客户端