【机器学习项目 心脏病预测】
文章目录
- 心脏病预测
- 导入数据集
- 数据集介绍
- 理解数据
- 数据处理
- 机器学习
- K近邻分类器
- 逻辑回归
- 支持向量分类器(SVC)
- 决策树分类器
- 随机森林分类器
- 结论
心脏病预测
在这个机器学习项目中,我们使用UCI心脏病数据集 UCI ,并将使用机器学习方法预测一个人是否患有心脏病。
import numpy as np # 导入NumPy库,用于支持大型、多维数组与矩阵运算,常用于数学计算
import pandas as pd # 导入Pandas库,用于数据读取、处理与分析(如DataFrame结构)
import matplotlib.pyplot as plt # 导入matplotlib中的pyplot模块,用于绘图和数据可视化
from matplotlib import rcParams # 导入rcParams用于设置matplotlib图像的默认样式(如字体、大小等)
from matplotlib.cm import rainbow # 从matplotlib的colormap模块导入rainbow颜色映射,用于给图像添加彩虹色彩
# %matplotlib inline # Jupyter Notebook专用魔法命令,使图像内嵌显示在Notebook中
import warnings # 导入warnings库,用于控制警告信息的显示
warnings.filterwarnings('ignore') # 忽略所有警告,避免在运行时输出烦人的提示信息
为了处理数据,将导入一些库。为了将可用的数据集划分为训练集和测试集,使用 train_test_split 方法。为了对特征进行标准化处理,使用 StandardScaler。
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
接下来,我将导入所有将要使用的机器学习算法:
- K近邻分类器(K Neighbors Classifier)
- 支持向量机分类器(Support Vector Classifier)
- 决策树分类器(Decision Tree Classifier)
- 随机森林分类器(Random Forest Classifier)
from sklearn.neighbors import KNeighborsClassifier # 从sklearn.neighbors模块导入K近邻分类器,用于基于距离进行分类
from sklearn.svm import SVC # 从sklearn.svm模块导入支持向量机分类器,适合高维数据的分类任务
from sklearn.tree import DecisionTreeClassifier # 从sklearn.tree模块导入决策树分类器,用于构建树结构进行决策
from sklearn.ensemble import RandomForestClassifier # 从sklearn.ensemble模块导入随机森林分类器,通过集成多棵决策树提高准确率
导入数据集
现在我们已经导入了所有需要的库,可以开始导入数据集并查看内容。数据集保存在文件 dataset.csv 中。我将使用 pandas 的 read_csv 方法来读取该数据集。
dataset = pd.read_csv('dataset.csv')
数据集介绍
该数据集用于心脏病预测,包含患者的多个临床和生理特征,及最终的心脏病诊断结果(target)。下面是每个字段的详细说明:
| 字段名 | 含义 | 备注 |
|---|---|---|
age | 年龄 | 患者年龄(岁) |
sex | 性别 | 1表示男性,0表示女性 |
cp | 胸痛类型 | 0-3的分类,表示不同类型的胸痛 |
trestbps | 静息血压 | 静息时的血压(mm Hg) |
chol | 血清胆固醇 | 血液中的胆固醇含量(mg/dl) |
fbs | 空腹血糖 | 空腹血糖是否大于120 mg/dl(1表示是,0表示否) |
restecg | 静息心电图结果 | 0-2的分类,反映心电图的不同类型结果 |
thalach | 最大心率 | 运动测试时达到的最大心率 |
exang | 运动诱发的心绞痛 | 1表示有,0表示无 |
oldpeak | 运动相较静息的ST段压低 | 表示心脏缺血的严重程度 |
slope | ST段抬高/压低斜率 | 0-2的分类,表示运动时ST段的变化趋势 |
ca | 主要血管数 | 0-3之间,血管造影检测的主要血管数量 |
thal | 地中海贫血检测结果 | 1、2、3表示不同类型 |
target | 心脏病诊断结果 | 1表示有心脏病,0表示无心脏病 |
总结:
此数据集包含了患者的年龄、性别、血压、胆固醇、心电图信息等多个变量,目标是预测患者是否患有心脏病。数据中既有数值型特征,也有分类特征,适合用机器学习分类算法进行建模。
数据集现在已经加载到变量 dataset 中。在正式开始处理和可视化之前,我会先用 describe() 和 info() 方法简单查看一下数据的大致情况。
dataset.info()
# --------------<class 'pandas.core.frame.DataFrame'>
RangeIndex: 303 entries, 0 to 302
Data columns (total 14 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 age 303 non-null int64 1 sex 303 non-null int64 2 cp 303 non-null int64 3 trestbps 303 non-null int64 4 chol 303 non-null int64 5 fbs 303 non-null int64 6 restecg 303 non-null int64 7 thalach 303 non-null int64 8 exang 303 non-null int64 9 oldpeak 303 non-null float6410 slope 303 non-null int64 11 ca 303 non-null int64 12 thal 303 non-null int64 13 target 303 non-null int64
dtypes: float64(1), int64(13)
memory usage: 33.3 KB
看起来数据集总共有 303 行,并且没有缺失值。数据集中共有 13 个特征,外加一个我们希望预测的目标值。
dataset.describe()

每个特征列的数值范围不同,而且差别较大。例如,age(年龄)的最大值是 77,而 chol(血清胆固醇)的最大值则达到 564。
理解数据
现在,我们可以通过可视化来更好地理解数据,然后再考虑需要进行的处理操作。
import seaborn as sns # 导入seaborn库,基于matplotlib的高级数据可视化工具,绘制美观的统计图表
import matplotlib.pyplot as plt # 导入matplotlib的pyplot模块,用于绘图和显示图像plt.figure(figsize=(20,14)) # 创建一个新的绘图窗口,设置尺寸为宽20英寸,高14英寸
corr = dataset.corr() # 计算数据集中各特征之间的相关系数矩阵,返回一个DataFrame"""
viridis":渐变绿色调,视觉舒适。
"magma":暗色调渐变,风格现代。
"plasma":鲜艳明亮的渐变色。
"coolwarm":蓝红对比色,适合正负相关。
"cividis":色盲友好配色。
"rocket" 或 "mako":seaborn自带的高级配色。
"""
sns.heatmap(corr, # 传入相关系数矩阵作为热力图的数据来源annot=True, # 在热力图的每个方格内显示对应的数值(相关系数)fmt=".2f", # 格式化数值,保留两位小数cmap="viridis", # 使用“viridis”配色方案,颜色从蓝绿到黄xticklabels=corr.columns, # 设置x轴刻度标签为相关系数矩阵的列名(即特征名称)yticklabels=corr.columns # 设置y轴刻度标签为相关系数矩阵的列名(即特征名称)
)
plt.show() # 显示绘制的热力图窗口

从上面的相关矩阵可以看出,部分特征与目标值呈负相关,而有些特征则呈正相关。
接下来,将查看每个变量的直方图。
# 绘制数据集中所有数值型特征的直方图,帮助观察各特征的分布情况和数据集中趋势
import matplotlib.pyplot as pltplt.figure(figsize=(15,10)) # 设置画布大小,宽15英寸,高10英寸
dataset.hist(figsize=(15,10)) # 也可以直接在hist里设置figsize
plt.tight_layout() # 自动调整子图间距,避免重叠
plt.show()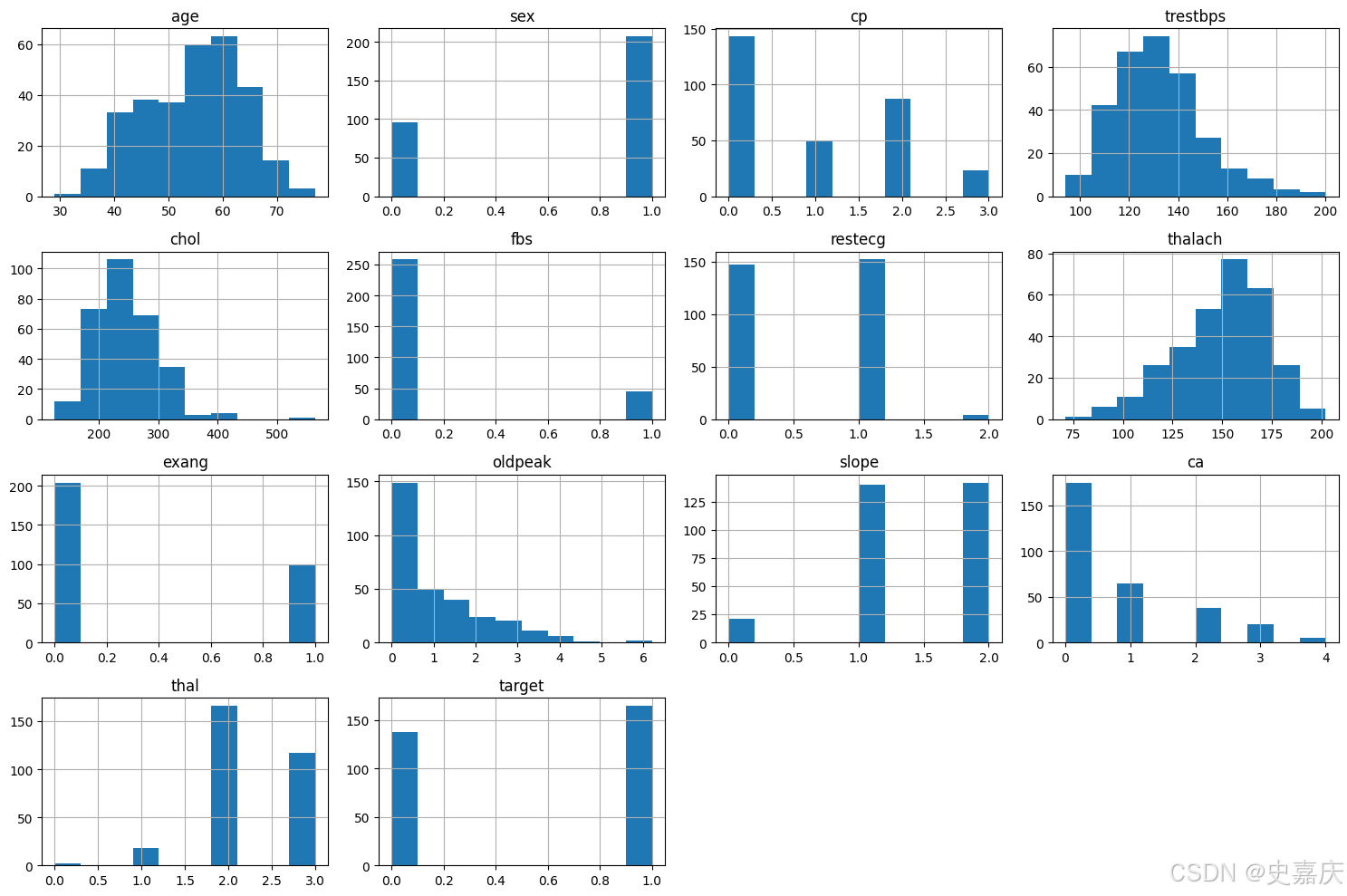
从上面的直方图可以看出,每个特征的分布范围都不同。因此,在进行预测之前进行特征缩放会很有帮助。此外,分类特征也非常明显。
使用目标类别大致均衡的数据集是一个好的实践。因此先检查一下数据集中各类别的数量是否平衡。
rcParams['figure.figsize'] = 8, 6 # 设置绘图窗口大小为宽8英寸,高6英寸
plt.bar( # 绘制柱状图dataset['target'].unique(), # x轴:目标类别的唯一值(如0和1)dataset['target'].value_counts(), # y轴:各类别对应的样本数量color=['red', 'green'] # 柱子颜色,类别0为红色,类别1为绿色
)
plt.xticks([0, 1]) # 设置x轴刻度为0和1,表示目标类别标签
plt.xlabel('Target Classes') # x轴标签为“目标类别”
plt.ylabel('Count') # y轴标签为“数量”
plt.title('Count of each Target Class') # 图表标题为“各目标类别的数量”
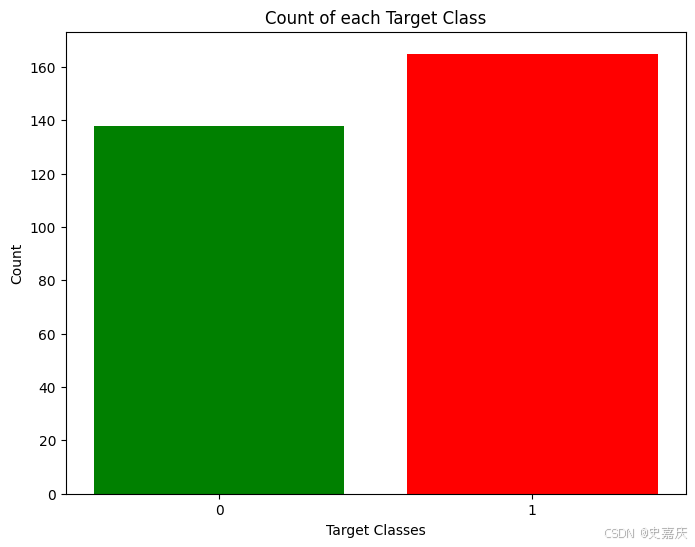
这两个类别的比例虽然不完全是各占50%,但比例已经足够合理,可以继续使用当前数据,而无需删除或增加样本。
数据处理
在探索数据集后,发现需要将一些分类变量做编码,并且在训练机器学习模型之前对所有数值进行缩放。
首先,会使用 get_dummies 方法为分类变量进行one hot 编码。在此之前,我们先回顾一下数据集。
dataset = pd.get_dummies(dataset, columns=['sex', 'cp', 'fbs', 'restecg', 'exang', 'slope', 'ca', 'thal'],dtype=int)
# 使用 pandas 的 get_dummies 方法,将指定的分类变量列进行转换
# columns 参数指定需要转换的分类列,转换后每个类别会变成单独的二进制列(0或1)
# 这样可以让机器学习模型更好地处理分类数据
dataset
现在,将使用 sklearn 中的 StandardScaler 对数据集进行标准化处理。
standardScaler = StandardScaler()
# 创建 StandardScaler 对象,用于对数据进行标准化处理(均值为0,方差为1)columns_to_scale = ['age', 'trestbps', 'chol', 'thalach', 'oldpeak']
# 指定需要进行标准化的数值特征列dataset[columns_to_scale] = standardScaler.fit_transform(dataset[columns_to_scale])
# 对指定列的数据进行标准化:先计算均值和标准差(fit),然后转换数据(transform)
# 标准化后的数据替换原数据列
dataset
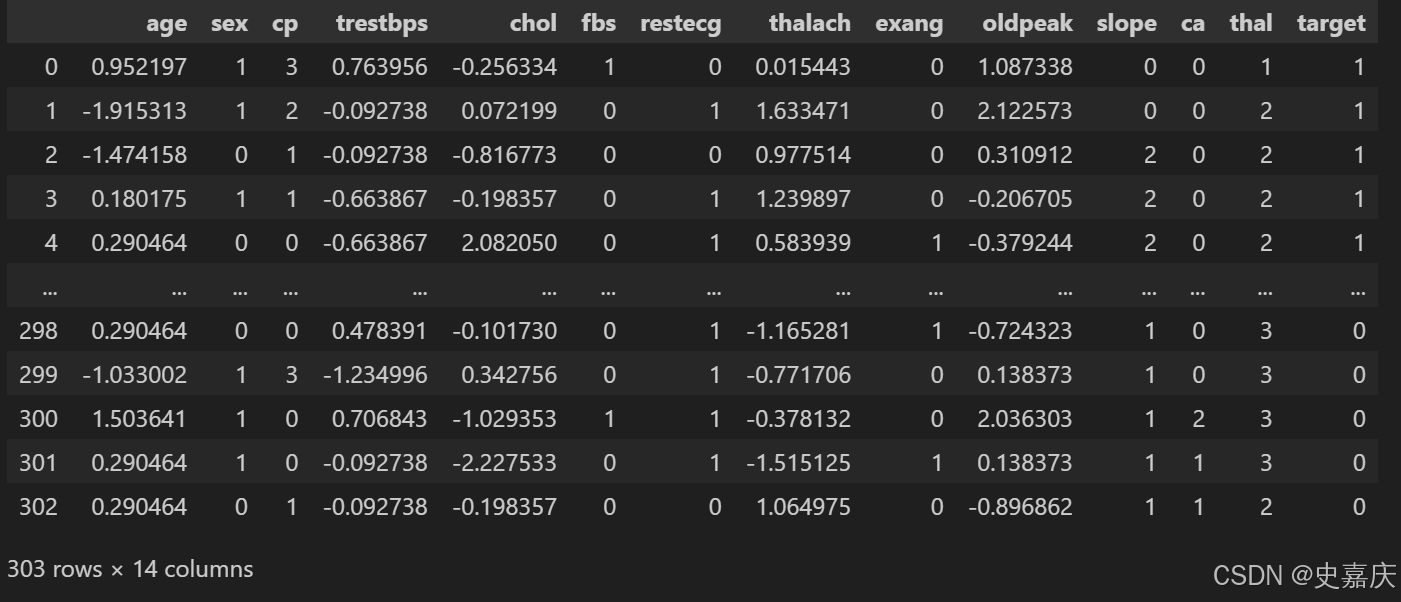
至此,数据已经准备好,可以用于我们的机器学习应用了。
机器学习
接下来,将导入 train_test_split,用来将数据集划分为训练集和测试集。然后会导入所有用于训练和测试的机器学习模型。
y = dataset['target'] # 提取目标变量“target”,作为标签y
X = dataset.drop(['target'], axis=1) # 从数据集中删除“target”列,剩余特征作为输入X# 使用train_test_split函数将数据集划分为训练集和测试集
# test_size=0.33表示33%的数据用作测试集,67%用作训练集
# random_state=0保证分割的可重复性,即每次运行结果相同
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0)K近邻分类器
分类准确率会随着我们选择的邻居数(K值)不同而变化。因此,将绘制不同K值对应的得分曲线,找出最佳的K值。
knn_scores = [] # 创建一个空列表,用来存储不同K值对应的分类准确率for k in range(1, 21): # 遍历K值从1到20knn_classifier = KNeighborsClassifier(n_neighbors=k) # 创建K近邻分类器,设置邻居数为kknn_classifier.fit(X_train, y_train) # 用训练集训练模型knn_scores.append(knn_classifier.score(X_test, y_test)) # 计算模型在测试集上的准确率,并加入列表中已经得到了不同邻居数对应的准确率,保存在数组 knn_scores 中。 接下来,将绘制这组数据,看看哪个K值对应的准确率最高。
plt.plot([k for k in range(1, 21)], knn_scores, color='red')
# 绘制K值(1到20)与对应准确率的折线图,线条颜色为红色
for i in range(1, 21):plt.text(i, knn_scores[i-1], (i, knn_scores[i-1])) # 在每个点上显示对应的K值和准确率,方便查看具体数值
plt.xticks([i for i in range(1, 21)])
# 设置x轴刻度为1到20的整数,表示不同的邻居数K
plt.xlabel('Number of Neighbors (K)')
# 设置x轴标签为“邻居数(K)”
plt.ylabel('Scores')
# 设置y轴标签为“准确率
plt.title('K Neighbors Classifier scores for different K values')
# 设置图表标题为“不同K值下K近邻分类器的准确率”
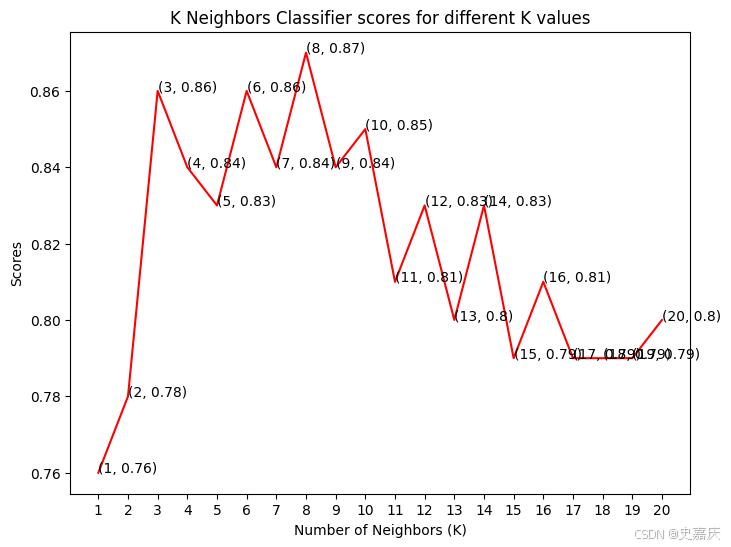
为了不复杂化代码,文字重叠的问题我们就先忽略吧,绘图可以交给ai大模型微调一下,此处不过多阐述。
从图中可以看到,当我们邻居数K=8的情况下,准确率是最高的,有87%。
逻辑回归
# 导入逻辑回归模型
from sklearn.linear_model import LogisticRegression# 初始化逻辑回归模型,设置随机种子和最大迭代次数
log_reg = LogisticRegression(random_state=0, max_iter=1000)# 在训练数据上训练模型
log_reg.fit(X_train, y_train)# 在测试数据上评估模型准确率
log_reg_score = log_reg.score(X_test, y_test)# 打印逻辑回归模型的准确率
print("逻辑回归模型的准确率为 {:.2f}%".format(log_reg_score * 100))
#打印结果
#逻辑回归模型的准确率为 84.00%
from sklearn.metrics import precision_score, recall_score, f1_score, roc_auc_score# 预测测试集的标签
y_pred = log_reg.predict(X_test)# 预测测试集的概率(用于计算ROC AUC)
y_prob = log_reg.predict_proba(X_test)[:, 1]# 计算各项指标
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
roc_auc = roc_auc_score(y_test, y_prob)print(f"Precision: {precision:.2f}")
print(f"Recall: {recall:.2f}")
print(f"F1 Score: {f1:.2f}")
print(f"ROC AUC: {roc_auc:.2f}")
# -------------------------------
# Precision: 0.85
# Recall: 0.85
# F1 Score: 0.85
# ROC AUC: 0.92
支持向量分类器(SVC)
支持向量分类器有多种核函数可选。将测试其中几种,看看哪种核函数的准确率最高。
svc_scores = [] # 创建空列表,用来存储不同核函数对应的准确率
kernels = ['linear', 'poly', 'rbf', 'sigmoid'] # 定义要测试的核函数列表for i in range(len(kernels)): # 遍历所有核函数svc_classifier = SVC(kernel=kernels[i]) # 创建支持向量机分类器,指定当前核函数svc_classifier.fit(X_train, y_train) # 用训练集训练模型svc_scores.append(svc_classifier.score(X_test, y_test)) # 计算测试集准确率并存入列表现在将绘制每个核函数对应的准确率柱状图,看看哪种核函数表现最好。
colors = rainbow(np.linspace(0, 1, len(kernels)))
# 使用rainbow颜色映射生成与核函数数量相等的颜色列表,保证每个柱状图颜色不同plt.bar(kernels, svc_scores, color=colors)
# 绘制柱状图,x轴为核函数名称,y轴为对应的准确率,柱子颜色由colors指定
for i in range(len(kernels)):plt.text(i, svc_scores[i], svc_scores[i]) # 在每个柱子上方显示对应的准确率数值,方便查看
plt.xlabel('Kernels')
# 设置x轴标签为“核函数”
plt.ylabel('Scores')
# 设置y轴标签为“准确率”
plt.title('Support Vector Classifier scores for different kernels')
# 设置图表标题为“不同核函数下支持向量分类器的准确率”
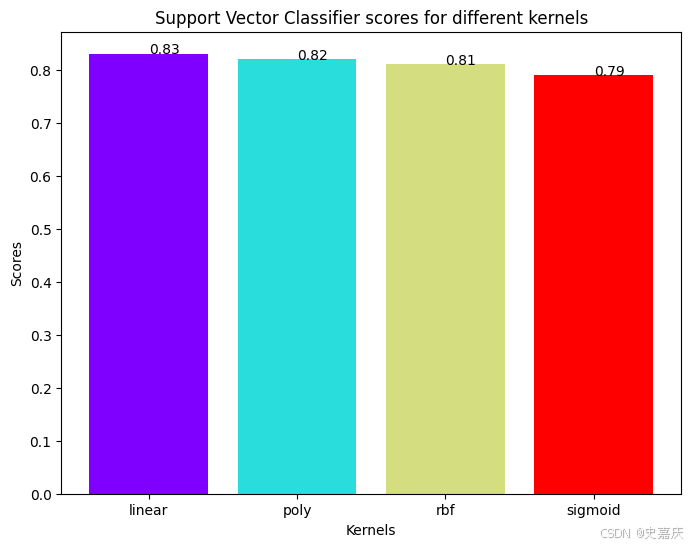
linear(线性)核表现最好,略优于 rbf 核。
决策树分类器
这里将使用决策树分类器来建模这个问题。调整一组 max_features 参数,看看哪个参数能得到最高的准确率。
dt_scores = [] # 创建空列表,用于保存不同 max_features 参数下的模型准确率for i in range(1, len(X.columns) + 1): # 遍历 max_features 从1到特征总数的所有可能值dt_classifier = DecisionTreeClassifier(max_features=i, random_state=0) # 初始化决策树分类器,设置当前 max_features 和随机种子dt_classifier.fit(X_train, y_train) # 使用训练集训练模型dt_scores.append(dt_classifier.score(X_test, y_test)) # 计算测试集上的准确率并保存
选择了从1到30个特征作为最大分裂特征数,现在来看一下每种情况下的准确率。
# 绘制最大特征数与准确率的折线
plt.plot([i for i in range(1, len(X.columns) + 1)], dt_scores, color='green') 图,颜色为绿色for i in range(1, len(X.columns) + 1):plt.text(i, dt_scores[i-1], (i, dt_scores[i-1])) # 在每个点上显示对应的 (最大特征数, 准确率) 值plt.xticks([i for i in range(1, len(X.columns) + 1)]) # 设置x轴刻度为从1到特征总数
plt.xlabel('Max features') # x轴标签:最大特征数
plt.ylabel('Scores') # y轴标签:准确率得分
# 图表标题:不同最大特征数下的决策树分类器得分
plt.title('Decision Tree Classifier scores for different number of maximum features')
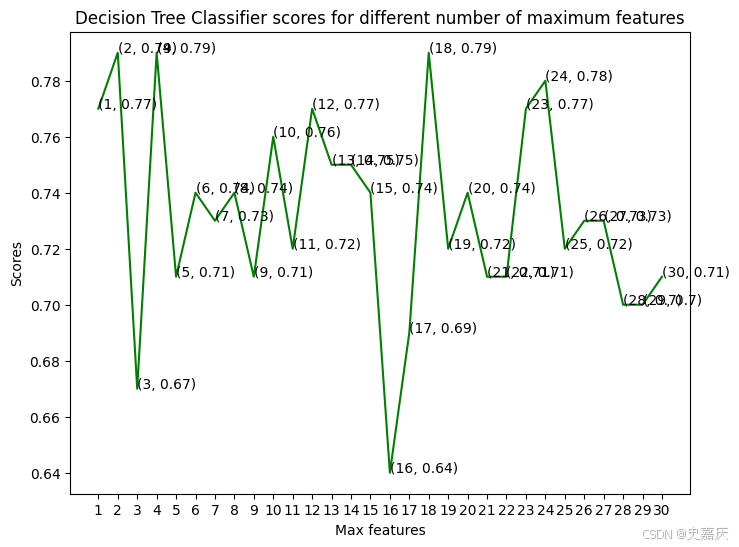
模型在最大特征数为 2、4 和 18 时,达到了最佳的准确率。
随机森林分类器
现在,将使用集成方法——随机森林分类器来创建模型,并改变估计器的数量以观察其影响。
rf_scores = [] # 创建一个空列表,用于存储不同估计器数量下模型的得分
estimators = [10, 100, 200, 500, 1000]# 定义不同的估计器数量列表,代表随机森林中决策树的数量。
for i in estimators: # 遍历每个估计器数量# 初始化随机森林分类器,设置估计器数量和随机种子rf_classifier = RandomForestClassifier(n_estimators=i, random_state=0) rf_classifier.fit(X_train, y_train # 在训练集上训练模型rf_scores.append(rf_classifier.score(X_test, y_test)) # 计算模型在测试集上的准确率,并添加到得分列表中
模型已经训练完毕,得分也记录下来了,接下来绘制一个柱状图来比较各个得分。
colors = rainbow(np.linspace(0, 1, len(estimators))) # 生成颜色序列,数量与estimators列表长度相同,颜色从彩虹渐变取色
plt.bar([i for i in range(len(estimators))], rf_scores, color=colors, width=0.8) # 绘制柱状图,x轴为估计器数量的索引,y轴为对应的得分,柱宽设为0.8
for i in range(len(estimators)):plt.text(i, rf_scores[i], rf_scores[i]) # 在每个柱子顶部添加对应的得分文本标签,方便查看具体数值
plt.xticks(ticks=[i for i in range(len(estimators))], labels=[str(estimator) for estimator in estimators]) # 设置x轴刻度标签为estimators中的数字
plt.xlabel('Number of estimators') # 设置x轴标签:估计器数量
plt.ylabel('Scores') # 设置y轴标签:得分
plt.title('Random Forest Classifier scores for different number of estimators') # 设置图表标题
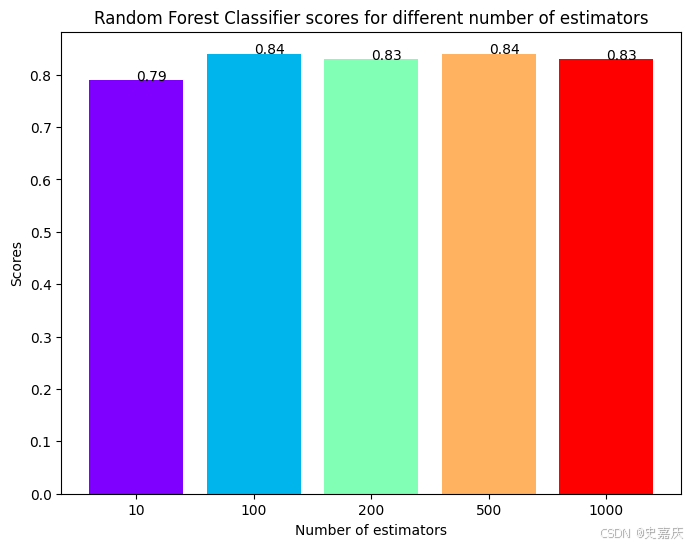
最大得分出现在估计器(决策树)数量为100或500时。这里也能反映到决策树数量要适中,因为太少会导致模型欠拟合和预测不稳定,太多则会造成计算资源浪费且准确率提升有限,存在收益递减效应,需要在性能与效率之间找到最佳平衡点。
结论
在本项目中,使用机器学习来预测一个人是否患有心脏病。导入数据后,通过绘图对数据进行了分析。然后,为类别特征生成了哑变量,并对其他特征进行了标准化处理。
接着,应用了四种机器学习算法:K近邻分类器、逻辑回归分类器、支持向量分类器、决策树分类器和随机森林分类器。在每个模型中调整参数,以提高模型的准确率。
最终,K近邻分类器在使用8个邻居时,取得了最高的准确率87%。