数据库原理及应用_数据库基础_第2章关系数据库标准语言SQL_索引和视图
前言
"<数据库原理及应用>(MySQL版)".以下称为"本书"中2.5节
引入
索引和视图是两个独立的知识点,视图和前面的联系紧密一点,先说视图再说索引
2.5.2视图
视图和查询语句区别不大,可以把视图理解成"成为文件的查询语句".
概念
本书P65原话:视图(View)是由SELECT查询语句定义的一个逻辑表,只有定义没有数据,是一个"虚表".
---由概念的信息看出视图是SELECT查询得到的一个表.
下面两段讲了可以通过视图操作数据库中的数据,但除了SELECT之外,在INSERT等方面受限
---数据库的数据维护可以用视图操作完成,但不建议用(也就是别这样用),可以省去一些学习
为什么建立视图
本书P66讲了三点原因
1.提供各种数据表现形式,隐藏数据的逻辑复杂性并简化查询语句
如果自己有数据库操作的界面,这点没有什么意义,见下图Navicat Premium Lite的导航界面
可以看到"视图"和"查询"和"表"处于同一层.如果是自己使用,那么编写的"视图"语句和查询语句是一样的.而查询语句是可以单独保存的,现在又来个单独保存的视图语句,做法重复.
输入本书建立视图的语句--"新建查询"中输入
CREATE VIEW ave_sal
AS
SELECT dname 部门名称,AVG(sal) 平均工资,MAX(sal) 最高工资,
MIN(sal) 最低工资,COUNT(*) 员工人数
FROM emp e,dept d
WHERE e.deptno=d.deptno
GROUP BY dname;再输入查询语句,因为在建立视图时用了别名,所以排序用了dname的别名-部门名称;
SELECT * FROM ave_sal
ORDER BY `部门名称`;运行结果
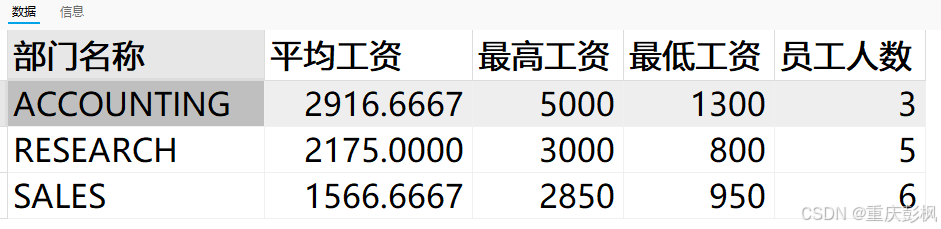
虽然意义不大,但视图的作用体现在:作成视图将查询语句文件化.
再用简单的查询语句:SELECT * FROM ave_sal,即可得到搜索结果
2.提供某些安全性保证,简化用户权限的管理
基于安全的需要,数据库通常要划分查询等级,有的表A能看B不能看,因此用户需要查看的权限.
用到视图之后,可以简化用户权限,这点很有意义
3.对重构数据库提供一定的逻辑独立性
因目前不知道重构数据库的概念和操作,所以暂时不做解读.
创建视图,修改视图和删除视图
创建视图格式:
CREATE VIEW 视图名[别名]
AS
SELECT 语句
修改视图格式:
CREATE OR REPLACE VIEW 视图名[别名]
AS
SELECT 语句
---修改视图自动覆盖创建的视图
删除视图格式:
DROP VIEW 视图名
其他
如果视图只提供查询功能,其他内容可以不看.也就是不考虑用视图去修改表数据
2.5.1索引
索引总览
索引和编程语言,框架一样,是"被实现的工具".应用程序员只管操作,不必关系底层实现.
先了解索引的操作---创建索引,查看索引和删除索引,再分析索引的思路和实现.
索引的创建、查看和删除
创建索引
格式:
CREATE INDEX 索引名 ON 表名(列名1,列名2...)
---可一次创建含多列的索引.
本书P64例2-50--单列索引
//为emp_c表创建ename索引
//emp_c表需要先创建
CREATE INDEX emp_ename_idx
ON emp_c(ename);本书P64例2-51--双列索引
//为emp_c表创建工作和工资索引CREATE INDEX emp_job_sal_idx
ON emp_c(job,sal);命名约定:索引名的命名一般采用 表名_列名_idx方式,将来维护方便.
查看索引
格式:
SHOW INDEX FROM 表名;
删除索引
格式:
DROP INDEX 索引名 ON 表名;
索引的原理和实现
本书P64第3段讲述了索引的原理:加快查询速度那么如何实现的呢?简单分析如下:
---以下小节内容为笔者视角,不保证准确.
假设有一个表table1(建表过程略),格式如下:
table1
| id序号(int) | ename名称(char(13) | sal薪水(int) |
| 1 | 张三 | 5000 |
| 2 | 李四 | 4500 |
| … | … | … |
| n | 王五 | 6000 |
建立查询:搜索比张三薪水高或者相等的人,查询语句如下:
SELECT id,ename FROM table1
WHERE sal>=(SELECT sal FROM table1 WHERE ename='张三');执行后内层SELECT语句查找到一个数值5000,再执行sal>=5000.此时需要搜索sal.
如果不用索引,用C语言描述这个过程
/*伪代码*/
//声明指向数据文件的指针
File *p=Open("数据库文件路径");
//如果指针未指向文件末尾
while(p!=Null){
//指针偏移17个字节,id4个字节,ename13个字节
p=p+17;
//指针转换
int *ps=(int *)p;
//如果薪水符合要求,大于等于张三
if(sal>=*ps)放到新表中;
}如果给薪水设定索引,给个数字17就可以.int sal_index=17,写出的代码可能稍有改变,
/*伪代码*/
//声明指向数据文件的指针
File *p=Open("数据库文件路径");
//指针转换
int *ps=(int *)p;
//如果指针未指向文件末尾
while(ps!=Null){
//指针偏移17个字节,id4个字节,ename13个字节
ps=ps+17;
//如果薪水符合要求,大于等于张三
if(sal>=*ps)放到新表中;
}但即使是一点小的改变(只少一行代码),在庞大的数字搜索和网络中大量请求的时候,可能提高的效率也显著.或许细心的人已经发现,这两处代码是一致的,完全相同.是的,并没有看出索引的效果.但索引的用途可能在多个文件中有所体现.
使用索引的条件
本书P65页写了很多,归根结底就两条:查询频繁,没有修改.
这里的没有修改并不是完全不能改,而是表的结构几乎不改(DDL语句基本不用,列的数据类型不改,没有增加和删除列),在DML语句中INSERT和DELETE基本也不用,但UPDATE不会改变索引.综合说来,会改变索引值的语句,也可以用函数来解决.
小结
索引和视图的一点浅析