Aligning Effective Tokens with Video Anomaly in Large Language Models

Abstract
理解视频中的异常事件是一项至关重要且颇具挑战性的任务,在众多应用领域中受到了广泛关注。尽管当前用于视频理解的多模态大语言模型(Multi-modal Large Language Models, MLLMs)能够对普通视频进行分析,但由于异常事件存在空间稀疏性与时间稀疏性的特点,这些模型在处理异常事件时往往力不从心——冗余信息常会导致模型输出不理想的结果。为应对这些挑战,我们充分利用视觉语言模型(Vision Language Models, VLMs)和大语言模型(Large Language Models, LLMs)的表征能力与泛化能力,提出了一种名为VA-GPT的新型多模态大语言模型。该模型专为总结和定位各类视频中的异常事件而设计。我们的方法通过两个核心模块,高效实现了视觉编码器与大语言模型之间有效令牌(tokens)的对齐,这两个模块分别是:空间有效令牌选择模块(Spatial Effective Token Selection, SETS)和时间有效令牌生成模块(Temporal Effective Token Generation, TETG)。这些模块使我们的模型能够有效捕捉并分析与异常事件相关的空间和时间信息,从而实现更精准的响应与交互。此外,我们还构建了一个专门用于微调“视频异常感知多模态大语言模型”的指令遵循数据集(instruction-following dataset),并基于XD-Violence数据集引入了一个跨域评估基准。在各类基准测试中,我们提出的方法性能均优于现有的最先进方法。
1. Introduction
检测并总结视频中的异常事件是一项关键且具有挑战性的任务,该任务已在多个研究领域及实际应用场景中获得了广泛关注,例如安防监控、视频分析和犯罪检测等。
尽管已有众多传统方法 [4, 16, 37, 43, 47, 73, 86] 被广泛应用于视频异常检测领域,但它们在有效性方面仍存在显著局限 [22, 51, 60, 66, 71, 84]。这些局限主要体现在两个方面:1)传统视频异常检测方法 [6, 13, 57, 63, 64, 86] 本质上是将该任务视为一个闭集检测与分类问题,这一特性使其从根本上难以全面理解和解读异常事件;2)这些方法 [2, 19, 23, 65, 68, 78] 受到词汇量有限的制约,导致其难以有效处理未见过的或新型的异常场景。
视觉语言模型(Vision Language Models, VLMs)和大语言模型(Large Language Models, LLMs)领域的最新进展 [1, 28, 34, 36, 45, 58],已展现出卓越的场景理解与综合分析能力。多模态大语言模型(Multimodal Large Language Models, MLLMs),尤其是专为视频理解设计的模型 [27, 29, 31, 39, 42, 74],在通用视频分析任务中取得了显著进展。然而,尽管这些模型在通用视频理解方面表现出较强性能,却在精准检测和解读异常事件方面存在不足。
为应对上述挑战,部分研究工作[12, 55, 67, 75, 79]提出了具有异常感知能力的视频多模态大语言模型(anomaly-aware video MLLMs),以更好地理解视频中的异常事件。尽管这些模型在检测打架、火灾等明显异常事件时表现良好,但在两个方面仍存在不足:一是难以实现异常区域与相关描述文本的有效对齐(这需要解决空间冗余问题);二是难以通过减少时间冗余来精准识别异常时间区间。究其原因,在于这些方法在空间和时间维度上对所有潜在令牌(latent tokens)均给予同等优先级。这种处理方式会因与异常无关的冗余令牌导致模型性能下降。然而,在大多数情况下,仅少数帧中的小区域包含识别异常所需的关键信息(如图1所示)。因此,我们提出如下研究问题:多模态架构应如何构建选择性令牌生成与处理机制,以在保留全面场景理解能力的同时,动态优先处理异常显著信息?
为解决上述问题,我们提出了一种名为VA-GPT的新型模型,该模型通过在空间和时间两个维度上对齐与大语言模型(LLMs)相关的有效且准确的令牌,实现对各类视频中异常事件的分析。VA-GPT集成了两个关键组件,用于识别用于对齐的有效视觉令牌,同时剔除可能阻碍异常分析、干扰模型提取有用信息的冗余令牌:1)我们设计了空间有效令牌选择(Spatial Effective Token Selection, SETS)模块,该模块可识别那些在与大语言模型对齐过程中存在难度的区域所对应的令牌,同时过滤掉与微小动态相关的令牌以去除冗余。这是因为我们发现,异常事件通常会导致局部区域出现不同的视觉变化与差异(见图1);2)我们提出了时间有效令牌生成(Temporal Effective Token Generation, TETG)模块,该模块采用轻量级预训练分类器,为每帧图像分配一个置信度分数,以表示该帧包含异常事件的可能性。随后,TETG利用异常事件时间信息的先验知识,在语言空间中直接生成高效令牌,并将其作为额外输入提供给大语言模型,从而有效提升模型对异常事件的时间推理与理解能力。
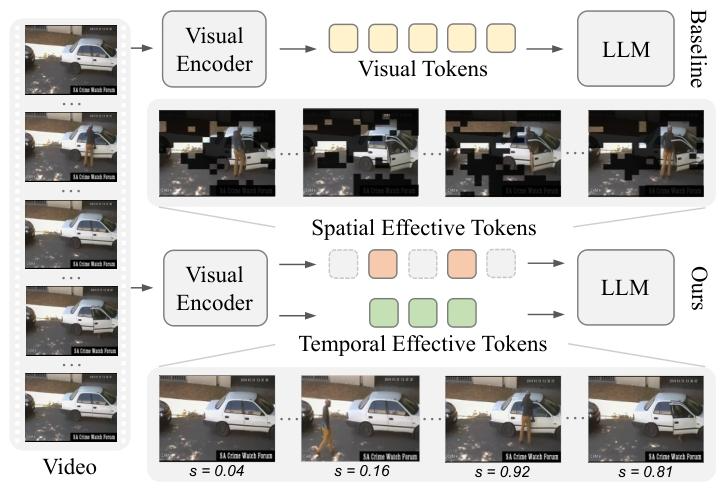
图1. 基准视频理解多模态大语言模型(MLLM)会将所有视觉令牌(黄色方块)同等地向前传递,以参与微调与推理过程(上行)。与之不同,我们的方法聚焦于每一帧中的有效区域(视频中帧的无遮挡区域),并为大语言模型(LLM)筛选出空间有效令牌(橙色方块)(详见3.2节)(被过滤的令牌以灰色方块表示)。同时,我们基于预训练分类器为每一帧分配的异常分数(记为s),生成具有异常感知能力的时间有效令牌(绿色方块)(详见3.3节),从而实现更精准的异常时间定位。
此外,除了传统基准(域内基准)之外,我们还建立了一套新的跨域评估协议,用于系统性地评估模型在域偏移情况下的鲁棒性。基于XD-Violence这一新型视频数据集[64],我们设计了涵盖异常事件的全面问答对(QAs),这些问答对包含与我们训练数据不同的视觉内容,并将其整合为一个新的跨域基准。同时,我们在域内和跨域基准上均设计了面向时间信息的问答对,以评估模型的时间定位能力。大量实验证明了VA-GPT的优越性,该模型在域内异常定位和跨域泛化场景中均取得了最先进的性能。
主要贡献总结如下:
• 我们提出了VA-GPT模型,这是一种具有视频异常感知能力的多模态大语言模型(MLLM),可用于检测和总结各类视频中的异常事件,该模型将多模态大语言模型引入了视频异常理解这一特定领域。
• 我们设计了空间有效令牌选择(SETS)模块和时间有效令牌生成(TETG)模块,这两个模块使我们的多模态大语言模型能够有效捕捉视频序列中的空间和时间信息,从而实现对异常事件的准确理解与定位。同时,我们还构建了一个用于视频异常分析的新型指令遵循数据集,以及一个全面的跨域评估基准,以更好地评估多模态大语言模型在视频异常任务上的泛化能力。
• 大量实验表明,我们的方法在各类基准测试中性能均优于现有的最先进方法,这充分证明了该方法的有效性,以及其在视频异常理解实际应用中的潜力。
2. Related Work
2.1. Large Language Models (LLMs)
自然语言处理(Natural Language Processing, NLP)领域已取得显著进展,尤其是随着大语言模型(Large Language Models, LLMs)的出现,这一进展更为突出。Transformer架构[3, 18, 59]的提出是该领域的关键转折点,此后,一系列具有影响力的语言模型[3, 10, 25, 80]相继出现,展现出卓越的性能。生成式预训练Transformer(Generative Pre-trained Transformers, GPT)[49]通过采用自回归预测方法,在自然语言处理领域掀起了一场变革,成为一种强大的语言建模方法。近年来,ChatGPT[45]、GPT-4[1]、LaMDA[56]和LLaMA[58]等突破性成果的出现,进一步拓展了该领域的发展边界。这些模型经过海量文本数据的训练,在复杂的语言任务中表现出非凡的性能。
2.2. Vision Language Models (VLMs)
计算机视觉与自然语言处理领域的发展推动了视觉语言模型(vision-language models, VLMs)[14, 21, 33, 34, 50, 61, 69]的诞生。这类模型融合视觉系统与语言系统,助力跨模态理解与推理。典型案例包括:将BERT[10]与ViT[11]相结合的CLIP[50];将视觉Transformer(Vision Transformer)特征融入Flan-T5[8]的BLIP-2[28];实现BLIP-2与Vicuna[28, 48]连接的MiniGPT4[85];以及搭建ImageBind[15]与Vicuna桥梁的PandaGPT[53]。这些模型在图像分类、图像描述生成、目标检测等任务中表现出色[24, 53, 83]。视觉语言模型的最新发展已延伸至视频处理领域,涌现出Video-Chat[29]、Video-ChatGPT[42]、Otter[26]、Valley[39]、mPLUG[27]、Video-LLaMA[74]和LLaMAVID[31]等模型。这些系统支持交互式视频查询,通过音视频-文本对齐提升理解能力,并可实现全面的视频分析。在本文中,我们借助视觉语言模型(VLMs)与大语言模型(LLMs),提出了一种用于视频异常理解的新型方法。
2.3. Video Anomaly Understanding (VAU)
为监控视频帧添加标注需要耗费大量人力,这促使研究人员探索替代方案:单类学习[72]、无需标注的无监督异常检测[4, 5, 16, 20, 37, 38, 47],或是仅使用视频级标注的弱监督方法[6, 13, 30, 57, 60, 62, 63, 71, 76]。在单类学习领域,Luo等人开发了一种用于正常片段学习的ConvLSTM网络[40];部分研究人员采用自动编码器(Auto-Encoder)网络重构正常帧特征[5, 20, 81],另有研究人员则通过记忆机制[4, 16, 37, 47]或元学习[38]来提升模型的泛化能力。在弱监督学习方面,Tian[57]采用多实例学习(multiple-instance learning)对异常片段进行定位;Zhong等人则运用图卷积网络,但该方法的泛化能力有限[82]。为解决这一问题,Ramachandra等人开发了一种用于正常特征学习的孪生网络(Siamese network);Wan等人与Zaheer等人[60, 71]提出了基于聚类的异常识别框架。近期研究还为时空特征集成学习引入了新的架构[6, 13, 30, 57, 62, 63, 76]。然而,这些方法在推理过程中仅能提供异常分数,仍需在测试集上凭经验设定阈值以区分异常事件。近年来,已有研究开始探索借助多模态大语言模型(MLLMs)来提升模型识别和描述异常事件的能力[12, 55, 67, 75, 79]。
3. Method
3.1. Overview
任务说明
视频异常理解多模态大语言模型(MLLMs)旨在判断输入视频是否包含异常事件,同时对检测到的异常事件(若存在)的时间定位信息及完整过程进行描述,并支持相关交互。我们使用基于异常视频构建的指令遵循数据集[54]对该模型进行训练,以便模型能更好地实现视觉编码器与大语言模型(LLMs)之间的令牌(tokens)对齐,从而更有效地呈现和泛化异常事件相关信息。
流程说明
参考图2所示的视频理解多模态大语言模型(MLLM)框架,该流程以一段包含T帧的视频作为输入,通过一个冻结的、基于视觉Transformer(ViT)[11]的视觉编码器(CLIP[52]),从每一帧视频帧VtV^{t}Vt(t=1,…,Tt=1,\dots,Tt=1,…,T)中提取视觉令牌xtx^{t}xt。对于当前帧的视觉令牌集合Xt={xit}i=1,…,NX^{t}=\{x_{i}^{t}\}_{i=1,\dots,N}Xt={xit}i=1,…,N,其中包含N个视觉令牌,每个令牌对应数量相等的图像补丁(image patches)。
模态对齐会将经过处理的视觉令牌xtx^{t}xt转换到大语言模型(LLMs)的语义空间中;与此同时,文本提示(text prompts)会被处理并编码为文本令牌,同样映射到该语义空间,进而作为大语言模型输入的一部分。
我们在模型上的核心设计包括:(1)为每一帧从视觉令牌xtx^{t}xt中筛选出空间有效令牌X∗tX^{*t}X∗t(SET),用其替代xtx^{t}xt参与微调与推理过程(详见3.2节);(2)生成时间有效令牌S∗tS^{*t}S∗t(TET),将其作为具有异常感知能力的时间先验信息,参与推理过程以帮助大语言模型实现对异常事件的时间定位(详见3.3节)。此外,我们还构建了高质量的异常视频指令遵循数据集,并为此设计了训练策略,以最大限度发挥所提方法的有效性(详见3.4节)。
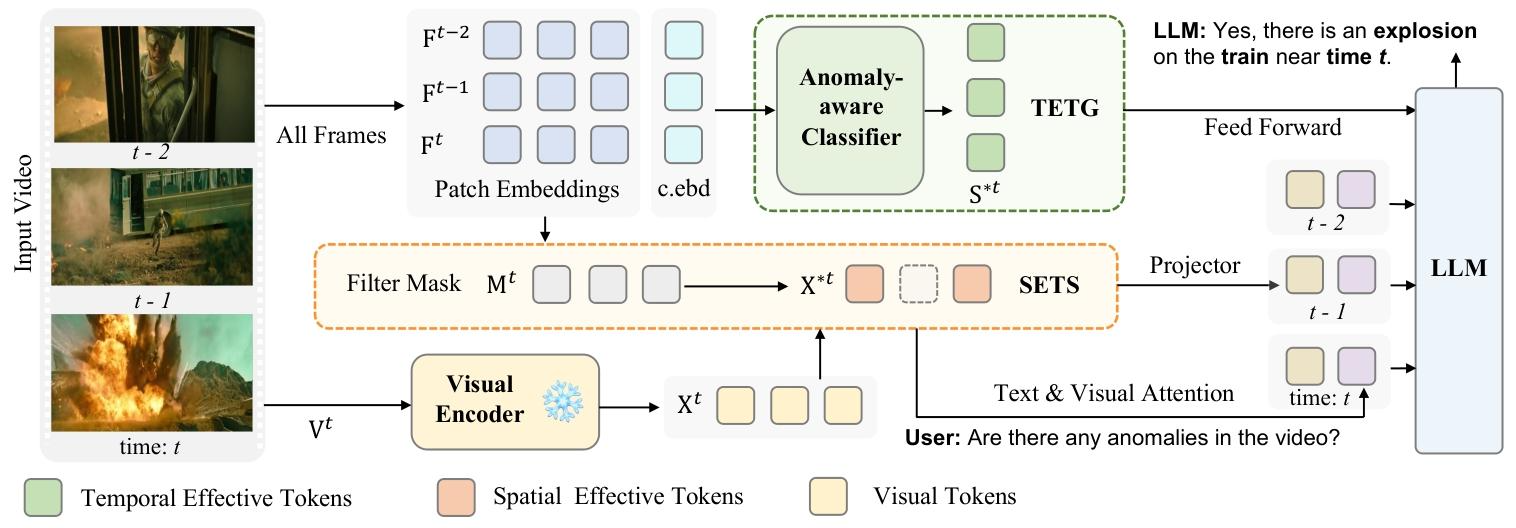
图2. 所提模型的详细示意图。当视频输入模型后,会从所有帧中提取补丁嵌入(patch embeddings)和类嵌入(class embeddings,记为c.ebd)。1)基于当前帧与其相邻帧在补丁嵌入上的差异,可得到一个过滤掩码(filter mask),用于从当前帧的视觉令牌中筛选掉不重要的视觉令牌(以虚线方块表示),进而筛选出空间有效令牌(Spatial Effective Tokens);这些空间有效令牌通过带有池化操作的投影器(projector)压缩为每帧的对齐内容令牌(aligned content token),同时与用户的文本输入进行注意力交互,得到每帧的对齐上下文令牌(aligned context token);2)基于所有帧的类嵌入(c.ebd),利用预训练的异常感知分类器(Anomaly-aware Classifier)定位异常事件的时间区间,从而生成时间有效令牌(Temporal Effective Tokens),并将其前馈输入到大语言模型(LLM)中。最终,所有得到的对齐令牌均被输入到大语言模型,用于整个模型的推理与推断过程。
3.2. Spatial Effective Token Selection (SETS)
在传统的视频分类任务中,上下文信息及关联关系至关重要。然而,在我们的多模态大语言模型(MLLM)框架下,除了利用上下文信息外,最核心的问题是实现视觉模态与语言模态的对齐。因此,我们设计的关键在于提取有用信息,以实现视觉令牌与大语言模型(LLM)的有效对齐。由于文本描述主要用于刻画异常事件,而异常事件在整个视频中仅占极小部分,若将所有视觉模式与文本令牌进行对齐,不仅不合情理,还会带来沉重的计算负担。为此,我们首次提出了一种新颖的令牌选择方法——空间有效令牌选择(SETS),以实现高效且有效的对齐。
帧间差异
对于一段视频,我们认为相邻帧中变化较大的区域更值得关注。如图2所示,针对视频的每一帧VtV_tVt,我们可将其前一帧Vt−1V_{t-1}Vt−1作为参考帧,以考察当前时刻与前一时刻帧之间的差异。采用DINOv2[46]作为特征提取器(记为FE),可提取补丁嵌入(patch embeddings):
Ft,Ft−1=FE(Vt),FE(Vt−1)(1)F_t, F_{t-1} = FE(V_t), FE(V_{t-1}) (1)Ft,Ft−1=FE(Vt),FE(Vt−1)(1)
其中,Ft,Ft−1∈RN×CF_t, F_{t-1} \in \mathbb{R}^{N \times C}Ft,Ft−1∈RN×C表示提取到的嵌入(N 为图像补丁数量,C 为通道数)。借助提取特征的区分性与稳定性,我们计算补丁级(patch-wise)距离,作为当前帧的帧间差异图:
Dt=dis(Ft,Ft−1)(2)D_t = dis(F_t, F_{t-1}) (2)Dt=dis(Ft,Ft−1)(2)
其中,dis(⋅)dis(\cdot)dis(⋅) 表示曼哈顿距离[17],Dt∈RND_t \in \mathbb{R}^NDt∈RN 表示相邻帧中对应补丁对之间的距离。
筛选空间有效令牌
根据帧间差异图DtD^{t}Dt,我们可构建向量Mt=[m1t,m2t,...,mNt]M^{t}=[m_{1}^{t}, m_{2}^{t}, ..., m_{N}^{t}]Mt=[m1t,m2t,...,mNt]来记录每个补丁的差异情况:其中距离值最大的前K比例元素被赋值为1,其余元素赋值为0。由此得到用于过滤和更新视觉令牌的掩码,公式如下:
X∗t={xit∣mit=1,mit∈Mt},(3)X^{* t}=\left\{x_{i}^{t} | m_{i}^{t}=1, m_{i}^{t} \in M^{t}\right\}, (3)X∗t={xit∣mit=1,mit∈Mt},(3)
式中,X∗tX^{* t}X∗t包含筛选出的空间有效令牌(Spatial Effective Tokens, SET),如图2所示,这些令牌将替代原视觉令牌xtx^{t}xt输入后续处理流程。空间有效令牌能够高效筛选出与异常事件高度相关的区域,参与模型的微调与推理过程。
3.3. Temporal Effective Token Generation (TETG)
异常感知分类器
我们设计了一个结构简单但性能有效的多层感知机(MLP)FAF_{A}FA,用于判断每一帧是否与异常事件相关。对于从特征编码器中提取的类嵌入(记为z),我们可根据训练视频的描述文本将其划分为正常嵌入和异常嵌入,分别记为znz^{n}zn和zaz^{a}za。基于此,我们采用二分类损失函数对FAF_{A}FA进行优化,公式如下:
L=Ez∼zn[−log11+exp−FA(z)]+Ez∼za[−logexp−FA(z)1+exp−FA(z)].(4)\begin{array} {r}{\mathcal {L}=\mathbb {E}_{z\sim z^{n}}\left[ -log \frac {1}{1+exp ^{-\mathcal {F}_{A}(z)}}\right] +\mathbb {E}_{z\sim z^{a}}\left[ -log \frac {exp ^{-\mathcal {F}_{A}(z)}}{1+exp ^{-\mathcal {F}_{A}(z)}}\right] . (4)}\end{array}L=Ez∼zn[−log1+exp−FA(z)1]+Ez∼za[−log1+exp−FA(z)exp−FA(z)].(4)
异常感知分类器可预测视频中每一帧是否与异常事件相关,该分类器能以极低的成本为大语言模型(LLMs)提供额外的重要先验知识,从而辅助其推理过程。
生成时间有效令牌
由于从异常感知分类器中获取的信息具有明确性,我们可通过自然语言轻松将其映射到大语言模型(LLMs)的文本令牌空间。基于异常感知分类器的预测结果,我们筛选出包含异常事件置信度较高的起始帧与结束帧时间戳,分别记为<a−start><a-start><a−start>和<a−end><a-end><a−end>。随后,我们使用如下模板对这些时间戳进行令牌化处理:“已知常见犯罪类型包括:‘枪击’、‘纵火’、‘逮捕’……在<a−start><a-start><a−start>至<a−end><a-end><a−end>时间段内发生了上述犯罪类型中的某一种”,最终在大语言模型的文本令牌空间中生成时间有效令牌(Temporal Effective Tokens, TET)。
在推理阶段,借助训练良好的轻量级异常感知分类器,时间有效令牌会作为额外输入参与大语言模型的前向传播过程,为模型提供与异常事件相关的时间维度先验知识(如图2所示)。
3.4. Training Strategy
在模态对齐与指令微调方面,我们参考基准模型[31]的方法,确保视觉特征能与语言空间实现良好对齐。本研究中,训练策略可分为两个阶段:1)第一阶段:利用异常视频数据进行微调;2)第二阶段:将空间有效令牌(Spatial Effective Tokens)与大语言模型(LLMs)进行对齐。
利用视频异常数据进行微调
为提升大语言模型(LLMs)对异常场景的理解能力,我们构建了基于UCF-crime数据集[70]的问答对(Question-Answer pairs),用于模型微调。同时,我们还融合了来自不同来源[32]的多种指令对,包括文本对话、单轮/多轮视觉问答对以及视频问答对。训练过程中,我们采用了针对文本、图像和视频输入的不同格式,并在用户输入的开头或结尾随机插入图像令牌。
本阶段会对除冻结的视觉编码器之外的所有模块进行优化。经过微调后,大语言模型将对异常事件形成优先感知,从而确保推理阶段时间有效令牌(详见3.3节)的有效性。关于数据集的更多细节将在4节中阐述。
将空间有效令牌与大语言模型对齐
在异常视频场景中,大部分区域无法与语言实现有效对齐。因此,我们额外增加了一个微调步骤。该步骤会利用从UCF-Crime数据集中各视频帧提取的空间有效令牌(详见3.2节);通过融入这些令牌,我们旨在让模型对异常事件的空间上下文形成更精细的理解。这一过程还能实现高效优化,且此处的对齐仅针对短期微调设计,可显著提升模型检测和理解异常事件的能力。
4. Experiments
数据集
我们基于 UCF-Crime 数据集 [54],构建了包含 4077 段视频和 7730 张图像、采用所提指令遵循格式 [34] 的训练数据集,并在该数据集上对模型进行微调。
模型评估则基于两个异常视频理解基准展开:一是用于域内评估的 UCF-Crime 数据集 [54],二是基于 XD-Violence 数据集 [64] 设计的全新基准(用于跨域评估)。更多细节详见补充材料。
基准与指标
为评估模型的视频审查及异常识别能力,我们采用来自Video-Bench[44]的视频异常理解评估方案来衡量模型的时间综合能力,该方案包含基于UCF-Crime数据集[54]构建的、以自然语言形式呈现的问答对。同时,为评估模型的跨域视频异常理解能力,我们基于XD-Violence数据集构建了问答对作为额外基准。这些问答对包含四个选项,每个选项均标注了异常类别及异常事件发生的对应时间区间。
针对每个基准,我们设计了两组不同的问题以开展两类评估:一类是对异常事件检测与理解能力的综合评估,另一类是聚焦时间定位能力的专项评估,两类评估均通过问答准确率进行衡量(分别记为综合准确率Total Acc.和时间准确率Temporal Acc.,数值越高越好)。
实现细节
在网络结构方面,我们采用预训练的CLIP[52]和DINOv2[46]作为视觉编码器,采用Qformer[9]作为文本解码器。在模态对齐阶段,我们参考文献[31]的方法冻结编码器;在指令微调阶段,则利用异常视频与指令数据对可训练参数进行优化。
训练过程中,我们的模型基于PyTorch框架,在4块NVIDIA A100 GPU上运行。优化器采用AdamW,批处理大小(batch size)设为64;学习策略采用余弦衰减(cosine decay),学习率(learning rate)为2e-5,总训练轮次(epoch)为1。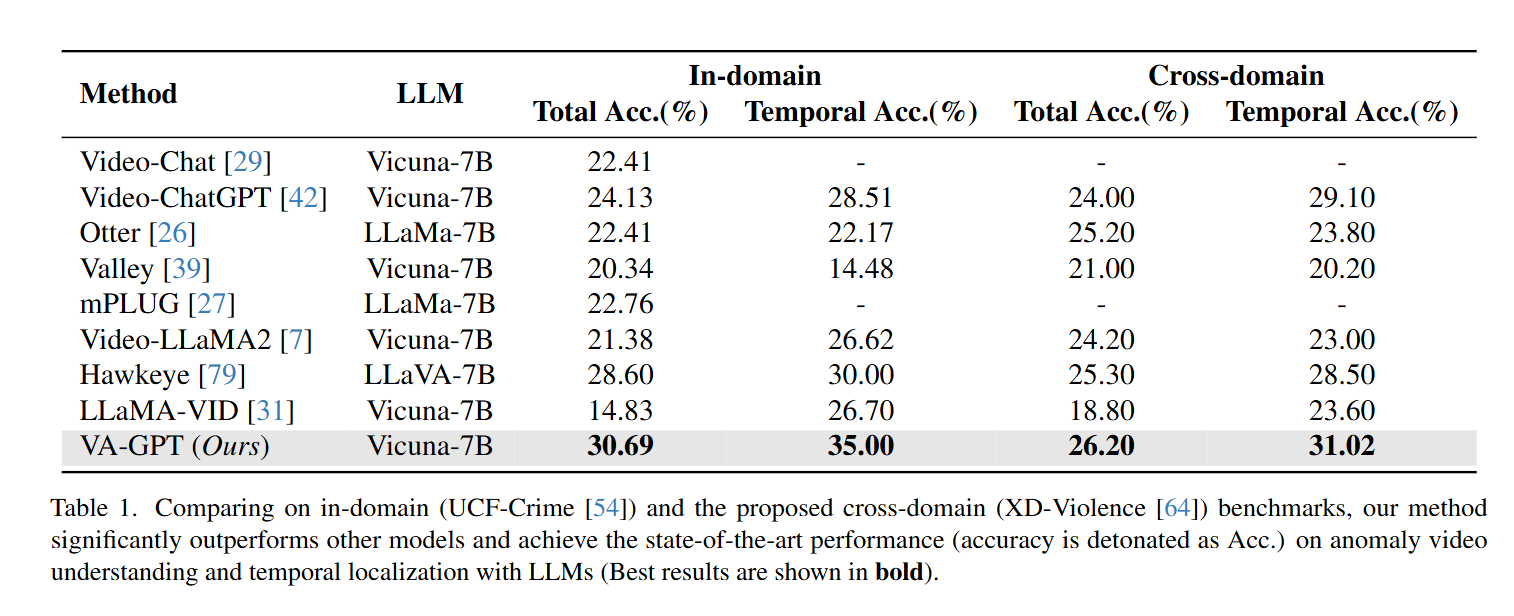
4.1. Main Results
域内数据集上的结果
我们首先在域内数据集上对所提方法进行评估,该数据集的测试集与3.4节训练过程中使用的数据具有相同的风格和录制模式。如表1所示,与基准模型[31]相比,我们的方法在使用更少视觉嵌入令牌和时间有效令牌的情况下,使综合准确率(Total Acc.)提升了一倍以上,同时在时间定位能力上也实现了显著提升。
在我们提出的训练策略及所设计的有效令牌的驱动下,更多纯净且有效的异常事件视觉-语义信息得以与大语言模型(LLMs)高效对齐,从而使模型展现出强大的异常视频理解能力。与此同时,我们还与现有的视频理解模型[26, 27, 29, 39, 42, 74]进行了公平对比(见表1),并表现出具有竞争力的性能。值得注意的是,在所有对比方法中,我们的方法使用的令牌数量最少,却在综合准确率和时间准确率(Temporal Acc.)上均实现了当前最优(state-of-the-art)的结果。
跨域数据集上的结果
为评估模型的鲁棒性与泛化能力,我们额外设计了一个跨域基准。在该跨域基准上,我们将所提方法与基准模型[31]及现有域内方法进行了公平对比。表1中的结果显示,在跨域数据集上,我们的方法相较于现有方法实现了显著的性能提升,这凸显了我们方法出色的泛化能力与时间定位能力。这种明显的性能优势,有力地验证了我们的方法在不同领域间具有良好的鲁棒性与适应性。
与模型的交互
为更好地评估模型性能,我们与训练完成的模型进行了一系列交互。如图3所示,我们展示了模型在应对各类视频异常理解任务时的表现。为评估模型的有效性,我们选取了不同时长的视频:短时长(0至1分钟)、中时长(1至30分钟)和长时长(超过30分钟)。这种多样化的视频选择,使我们能够全面评估模型在不同异常理解场景下的处理能力。
在“道路事故”视频中(图3左侧),即使是在低分辨率画面下,我们的方法仍能成功识别出高速行驶的车辆,并检测到人员摔倒的异常事件。针对“爆炸”视频(图3中间),模型在这段描绘爆炸场景的中时长视频中,准确预测了场景内容及异常事件。在一段时长超过30分钟的正常视频中(图3右侧),我们通过让模型总结视频内容,验证了其同时关注全局信息与局部信息的能力。
其他基准上的对比
此外,我们还在另一个异常视频理解基准(MMEval[12])上,从不同维度将所提方法与基于大语言模型(LLMs)的其他方法进行了对比。我们对所提模型开展了公平评估,得到的定量结果如表2所示,该结果印证了我们方法的优越性。
6. Conclusions
本文提出了一种新颖的多模态大语言模型(MLLM),通过在时间和空间维度对齐有效令牌,实现基于大语言模型(LLMs)的视频异常理解。所提方法包含两部分核心设计:一是空间有效令牌选择(SETS),用于在大场景的局部小区域中识别异常事件;二是时间有效令牌生成(TETG),用于解决视频时间序列中异常事件稀疏性的问题。同时,我们构建了视频异常检测领域的指令遵循数据集,用于对模型进行微调。
此外,在视频异常理解基准及所提出的跨域基准上的评估结果,均验证了所提方法的有效性。本文进一步为基于多模态大语言模型的视频异常理解提供了一种具有前景的技术思路,并证明了有效令牌在提升视频理解任务性能方面的潜力。