JUC之volatile关键字
文章目录
- 一、volatile解决了什么问题?
- 二、JVM是如何实现volatile的
- 2.1 可见性实现:基于 MESI 协议与总线嗅探
- 2.2 有序性实现:内存屏障(Memory Barrier)
- 2.3 源码分析
- 2.3.1 UnSafe.java
- 2.3.2 JVM实现
- 2.4 orderAccess.hpp 分析
- 2.4.1 术语说明
- 2.4.2 定义的四种基本内存屏障操作
- 1. LoadLoad
- 2. StoreStore
- 3. LoadStore
- 4. StoreLoad
- 2.4.3 “释放”(release)和“获取”(acquire)操作
- 1. 释放(release)
- 2. 获取(acquire)
- 2.4.4 定义一个“围栏”(fence)操作
- 2.4.5 release和 acquire的独立实现
- 2.4.6 使用 release_store 和 load_acquire 实现有序操作序列
- 2.4.7 常规用法建议
- 2.4.8 C++ 中的 volatile
- 2.4.9 关于 os::is_MP() 的冗余性
- 2.4.10 内存排序与缓存一致性的重要说明
- 2.4.11 关于 MutexLocker 及其相关类
- 2.4.12 总结【重点内容: 装逼的地方到了】
- 2.5 orderAccess_linux_x86.inline.hpp 分析
- 三、代码示例: 深入理解语义
- 3.1 可见性演示【无限循环问题】
- 3.2 有序性演示
- 3.2.1 指令重排序导致的问题
- 3.2.2 DCL 单例模式
- 四、volatile局限性: 不能保证原子性
- 4.1 示例: 自增操作(i ++)
- 五、总结
- 5.1 volatile vs synchronized
- 5.2 何时使用 `volatile`?
一、volatile解决了什么问题?
在多线程并发编程中,通常会遇到三大问题:原子性、可见性、有序性。
synchronized 关键字可以同时保证这三者,但它是一个重量级的锁,会带来线程阻塞和上下文切换的开销。
volatile 的两大核心语义
- 保证变量的可见性:当一个线程修改了一个
volatile变量的值,新值会立即被刷新回主内存。其他线程在使用这个变量前,会强制从主内存重新读取最新的值,而不是使用自己工作内存中的旧值拷贝。 - 禁止指令重排序:通过插入内存屏障(Memory Barrier),确保编译器和使用乱序执行技术的 CPU 不会对
volatile变量读写操作的指令进行重排序,从而防止由此带来的并发问题。
二、JVM是如何实现volatile的
2.1 可见性实现:基于 MESI 协议与总线嗅探
现代 CPU 为了缓解内存读写速度与 CPU 执行速度之间的巨大差距,引入了多级缓存(L1, L2, L3)。每个线程可能会在各自 CPU 核心的缓存中操作数据,这就导致了数据不一致的问题。
JVM 通过 volatile 关键字,底层会借助硬件的缓存一致性协议(如 Intel 的 MESI 协议)来实现可见性。
- MESI 协议:将缓存行(Cache Line)的状态标记为以下四种之一:
- M (Modified): 缓存行是脏的,与主内存值不同。
- E (Exclusive): 缓存行只被当前核心缓存,且与主内存一致。
- S (Shared): 缓存行被多个核心缓存,且与主内存一致。
- I (Invalid): 缓存行数据无效。
当一个 volatile 变量被写入时,JVM 会向处理器发送一条 LOCK 前缀的指令(实际可能是在底层汇编指令前加 lock)。这个指令会做两件事
- 立即将当前处理器缓存行的数据写回主内存。
- 这个写回操作会使其他 CPU 核心中缓存了该内存地址的缓存行无效化(I 状态)。
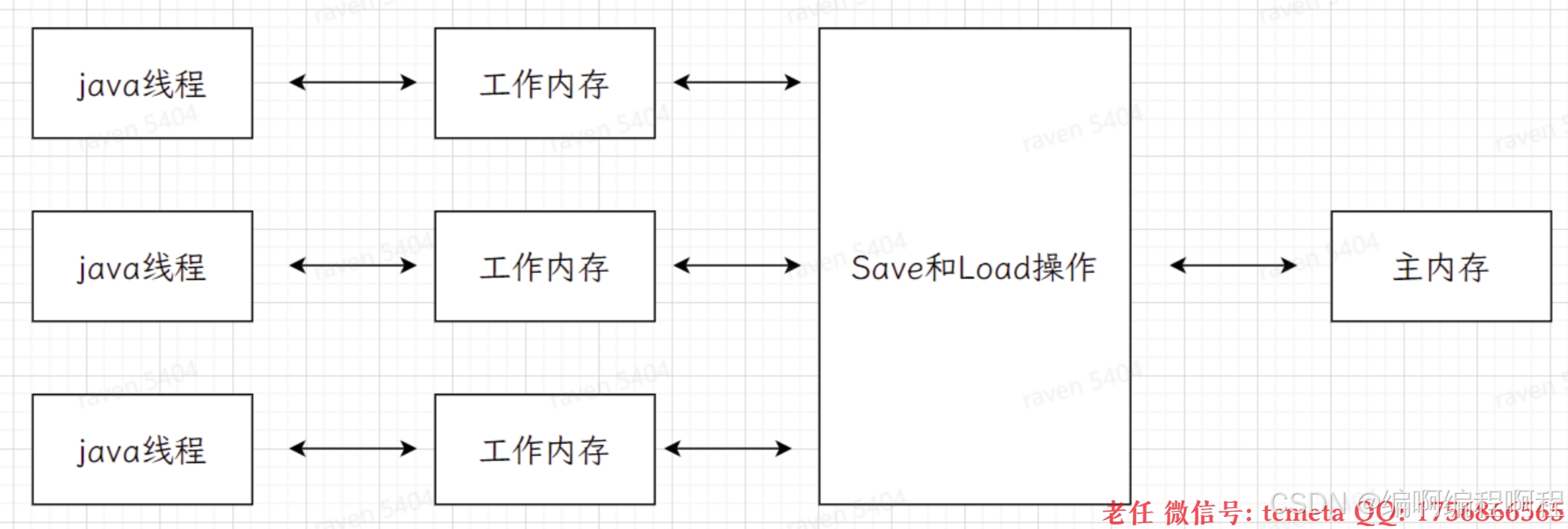
流程图:volatile 写操作引起的缓存同步
2.2 有序性实现:内存屏障(Memory Barrier)
编译器和处理器为了优化性能,会对指令进行重排序(Instruction Reorder)。但在多线程环境下,这种重排序可能会破坏程序的语义。
内存屏障「内存栅栏,屏障指令等」是一种同步屏障指令.是cpu编译在对从内存的随机访问的操作中一个同步点.这个同步点,使得: 在此点之前所有读写操作都执行后才可以开始执行此点之后的操作. 避免代码重排序.
**内存屏障其实是一种jvm指令,Java内存模型的重排规则会「要求java编译器在生成jvm指令时插入特定的内存屏障指令」,**通过这些内存屏障指令,volatile实现了Java内存模型中的可见性有序性「禁重排」, 但是volatile无法保证原子性.
[!NOTE]
- 内存屏障之前的所有「写操作」都要回到主内存.
- 内存屏障之后的所有「读操作」都能获取内存屏障之前的所有写操作的最新结果「实现了可见性」
- 写屏障「Store Memory Barrier」: 告诉处理器在写屏障之前将所有存储在缓存「store bufferes」中的数据同步刷新到主内存.
- 也就是说当看到
store屏障指令,就必须把该指令「store」之前的所有写入指令执行完毕才能继续向下执行.
- 也就是说当看到
- 读屏障「Load Memory Barrier」: 处理器在读屏障之后的读操作, 都在读屏障之后执行.也就是说, 在
Load屏障指令之后就能够保证后边的读数据指令一定能够读取到最新的数据.
volatile 通过内存屏障来禁止特定类型的重排序。内存屏障是一类 CPU 指令,用于控制指令之间的顺序关系。JMM(Java Memory Model)针对编译器和的 volatile 重排序规则如下:
| 是否能重排序 | 普通读/写 | volatile 读 | volatile 写 |
|---|---|---|---|
| 普通读/写 | NO | ||
| volatile 读 | NO | NO | NO |
| volatile 写 | NO |
为了实现上述规则,JVM 在编译后会插入以下类型的内存屏障:
StoreStore屏障: 禁止上面的普通写和下面的volatile写重排序。StoreLoad屏障: 禁止上面的volatile写和下面可能的volatile读/写重排序。(这是一个全能型屏障,开销最大)LoadLoad屏障: 禁止上面的volatile读和下面的普通读重排序。LoadStore屏障: 禁止上面的volatile读和下面的普通写重排序
volatile写操作:写指令之后插入写屏障, 强制把缓冲区的数据刷回到主内存中
-
在写操作之前插入
StoreStore屏障,确保所有之前的普通写操作都已经刷新到主内存,并对其他线程可见。 -
在写操作之后插入
StoreLoad屏障,确保 volatile 写操作的结果对其他线程立即可见,并防止与后续可能的 volatile 操作重排序。
volatile 读操作:在读指令之前插入读屏障, 让工作内存或者cpu高速缓存当中的缓存数据失效,重新回到主内存当中获取最新数据.
-
在读操作之后插入
LoadLoad屏障,防止后续的普通读操作被重排序到 volatile 读之前。 -
在读操作之后插入
LoadStore屏障,防止后续的普通写操作被重排序到 volatile 读之前。
2.3 源码分析
2.3.1 UnSafe.java
版本: Java24
@IntrinsicCandidate
public native void fullFence();@IntrinsicCandidate
public final void storeFence() {// If storeFence intrinsic is not available, fall back to full fence.fullFence();
}@IntrinsicCandidate
public final void loadFence() {// If loadFence intrinsic is not available, fall back to full fence.fullFence();
}
2.3.2 JVM实现
代码路径: hotspot-8aac6d08b58e\src\share\vm\prims\unsafe.cpp
// hotspot-8aac6d08b58e\src\share\vm\prims\unsafe.cpp
UNSAFE_ENTRY(void, Unsafe_LoadFence(JNIEnv *env, jobject unsafe))UnsafeWrapper("Unsafe_LoadFence");OrderAccess::acquire();
UNSAFE_ENDUNSAFE_ENTRY(void, Unsafe_StoreFence(JNIEnv *env, jobject unsafe))UnsafeWrapper("Unsafe_StoreFence");OrderAccess::release();
UNSAFE_ENDUNSAFE_ENTRY(void, Unsafe_FullFence(JNIEnv *env, jobject unsafe))UnsafeWrapper("Unsafe_FullFence");Orde该文本中定义了相关的操作,其中包含了原始的大量注释,根据文中注释内容,核心内容展示如下.```c++
#ifndef SHARE_VM_RUNTIME_ORDERACCESS_HPP
#define SHARE_VM_RUNTIME_ORDERACCESS_HPP#include "memory/allocation.hpp"class OrderAccess : AllStatic
{
public:static void loadload();static void storestore();static void loadstore();static void storeload();static void acquire();static void release();static void fence();static jbyte load_acquire(volatile jbyte *p);static jshort load_acquire(volatile jshort *p);static jint load_acquire(volatile jint *p);static jlong load_acquire(volatile jlong *p);static jubyte load_acquire(volatile jubyte *p);static jushort load_acquire(volatile jushort *p);static juint load_acquire(volatile juint *p);static julong load_acquire(volatile julong *p);static jfloat load_acquire(volatile jfloat *p);static jdouble load_acquire(volatile jdouble *p);static intptr_t load_ptr_acquire(volatile intptr_t *p);static void *load_ptr_acquire(volatile void *p);static void *load_ptr_acquire(const volatile void *p);static void release_store(volatile jbyte *p, jbyte v);static void release_store(volatile jshort *p, jshort v);static void release_store(volatile jint *p, jint v);static void release_store(volatile jlong *p, jlong v);static void release_store(volatile jubyte *p, jubyte v);static void release_store(volatile jushort *p, jushort v);static void release_store(volatile juint *p, juint v);static void release_store(volatile julong *p, julong v);static void release_store(volatile jfloat *p, jfloat v);static void release_store(volatile jdouble *p, jdouble v);static void release_store_ptr(volatile intptr_t *p, intptr_t v);static void release_store_ptr(volatile void *p, void *v);static void store_fence(jbyte *p, jbyte v);static void store_fence(jshort *p, jshort v);static void store_fence(jint *p, jint v);static void store_fence(jlong *p, jlong v);static void store_fence(jubyte *p, jubyte v);static void store_fence(jushort *p, jushort v);static void store_fence(juint *p, juint v);static void store_fence(julong *p, julong v);static void store_fence(jfloat *p, jfloat v);static void store_fence(jdouble *p, jdouble v);static void store_ptr_fence(intptr_t *p, intptr_t v);static void store_ptr_fence(void **p, void *v);static void release_store_fence(volatile jbyte *p, jbyte v);static void release_store_fence(volatile jshort *p, jshort v);static void release_store_fence(volatile jint *p, jint v);static void release_store_fence(volatile jlong *p, jlong v);static void release_store_fence(volatile jubyte *p, jubyte v);static void release_store_fence(volatile jushort *p, jushort v);static void release_store_fence(volatile juint *p, juint v);static void release_store_fence(volatile julong *p, julong v);static void release_store_fence(volatile jfloat *p, jfloat v);static void release_store_fence(volatile jdouble *p, jdouble v);static void release_store_ptr_fence(volatile intptr_t *p, intptr_t v);static void release_store_ptr_fence(volatile void *p, void *v);private:// This is a helper that invokes the StubRoutines::fence_entry()// routine if it exists, It should only be used by platforms that// don't another way to do the inline eassembly.static void StubRoutines_fence();
};#endif // SHARE_VM_RUNTIME_ORDERACCESS_HPP2.4 orderAccess.hpp 分析
内存访问排序模型(Memory Access Ordering Model)
文件当中注释内容内容涉及 Java 和 JVM 中内存访问排序模型、volatile 关键字的底层实现、内存屏障(Memory Barriers)、获取/释放语义(acquire/release)以及在不同硬件架构(如 SPARC、IA64、x86)上的实现差异。
2.4.1 术语说明
在下文中:
- “之前”(previous)、“之后”(subsequent)、“前”(before)、“后”(after)、“先于”(preceding)、“后于”(succeeding)等术语均指程序顺序(program order)。
- “向下”(down)和“下方”(below)表示相对于程序顺序,加载或存储操作向前移动;
- “向上”(up)和“上方”(above)表示向后移动。
2.4.2 定义的四种基本内存屏障操作
1. LoadLoad
Load1(s); LoadLoad; Load2
确保 Load1 完成(即从内存中获取其值)早于 Load2 及其后的所有加载操作。
在 Load1 之前的加载操作不能移动到 Load2 或其后加载操作的下方。
2. StoreStore
Store1(s); StoreStore; Store2
确保 Store1 完成(即 Store1 对内存的影响对其他处理器可见)早于 Store2 及其后的所有存储操作。
在 Store1 之前的存储操作不能移动到 Store2 或其后存储操作的下方。
3. LoadStore
Load1(s); LoadStore; Store2
确保 Load1 完成早于 Store2 及其后的所有存储操作。
在 Load1 之前的加载操作不能移动到 Store2 或其后存储操作的下方。
4. StoreLoad
Store1(s); StoreLoad; Load2
确保 Store1 完成早于 Load2 及其后的所有加载操作。
在 Store1 之前的存储操作不能移动到 Load2 或其后加载操作的下方。
[!tip]
注意:
StoreLoad是最昂贵的屏障,因为它通常需要处理器刷新写缓冲区(write buffer),并强制等待所有先前的写操作对其他处理器可见。
2.4.3 “释放”(release)和“获取”(acquire)操作
我们进一步定义两个操作:“释放”(release)和“获取”(acquire)。它们互为镜像。
1. 释放(release)
当一个处理器执行 release 操作时,它会确保该处理器在 release 之前发出的所有内存访问操作的效果,在 release 完成之前,对所有其他处理器可见。
但 release 之后发出的内存访问操作,其效果可能在 release 完成之前就对其他处理器可见。
也就是说:后续操作可以“上浮”到 release 之上,但之前的操作不能“下沉”到 release 之下。
2. 获取(acquire)
当一个处理器执行 acquire 操作时,它会确保该处理器在 acquire 之后发出的所有内存访问操作的效果,在 acquire 完成之后才对其他处理器可见。
但 acquire 之前发出的内存访问操作,其效果可能在 acquire 完成之后才被看到.
也就是说:之前的操作可以“下沉”到 acquire 之下,但之后的操作不能“上浮”到 acquire 之上。
2.4.4 定义一个“围栏”(fence)操作
fence 在概念上是 release 和 acquire 的组合。
在实际硬件中,这些操作可能需要一条或多条机器指令,这些指令可能浮动在 release 或 acquire 的上下方,因此我们通常不能简单地将 release 和 acquire 紧挨着执行。
所有已知的现代处理器都实现了某种形式的内存围栏(memory fence)指令。
2.4.5 release和 acquire的独立实现
独立实现的 release 和 acquire 需要一个关联的“虚拟” volatile 存储或加载操作(dummy volatile store/load),以确保编译器和硬件不会重排序。
为了避免冗余操作,我们可以定义一些复合操作:
release_storestore_fenceload_acquire
以下是不同平台(SPARC RMO、IA64、x86)上各操作对应的机器指令汇总
| 操作 | SPARC RMO | IA64 | x86 |
|---|---|---|---|
| fence | `membar #LoadStore | #StoreStore | #LoadLoad |
| release | `membar #LoadStore | #StoreStore<br>st %g0,[]` | st.rel [sp]=r0 |
| acquire | ld [%sp],%g0`membar #LoadLoad | #LoadStore` | ld.acq <r>=[sp] |
| release_store | `membar #LoadStore | #StoreStore<br>st` | st.rel |
| store_fence | stfence | stmf | lock xchg |
| load_acquire | ld`membar #LoadLoad | #LoadStore` | ld.acq |
2.4.6 使用 release_store 和 load_acquire 实现有序操作序列
仅使用 release_store 和 load_acquire,我们可以实现以下有序操作序列:
-
加载,加载(load, load)
等价于:load_acquire,load- 或
load_acquire,load_acquire
-
加载,存储(load, store)
等价于:load,release_store- 或
load_acquire,store - 或
load_acquire,release_store
-
存储,存储(store, store)
等价于:store,release_store- 或
release_store,release_store - 注意: 在 SPARC-TSO 和 IA64 上,这些组合不需要额外的
membar指令,因此非常高效。
-
存储,加载(store, load)
- 必须使用
store_fence,即在存储和加载之间插入membar #StoreLoad(在 SPARC-TSO 上),或在 IA64 上使用mf,在 x86 上使用lock xchg。 - 注意: 使用
store_fence可确保“关键区域”内的所有存储操作在后续的加载和存储操作之前对其他处理器可见
- 必须使用
2.4.7 常规用法建议
- 使用
load_acquire实现有序加载。 - 使用
release_store实现有序存储,当你只关心之前的存储操作在release_store之前可见,但不关心release_store关联的存储何时可见。 - 使用
store_fence(或release_store_fence)来更新线程状态等关键变量,确保当前线程不会继续执行,直到所有之前的内存访问(包括新线程状态)对其他线程可见。
2.4.8 C++ 中的 volatile
C++ 标准(第 1.9 节 “程序执行”)规定,在称为“序列点”(sequence points)的操作处保证顺序性。序列点包括 volatile 访问和调用标准库 I/O 函数。
在序列点之前的所有“副作用”(包括 volatile 访问、I/O 调用和对象修改)必须在该点对程序可见。
这意味着:所有屏障操作(包括独立的 loadload、storestore、loadstore、storeload、acquire、release)都必须包含一个序列点,通常是通过 volatile 内存访问实现。
其他方式包括间接调用、或使用 __asm__ volatile(如 Linux 中)
注意:自 JDK 6973570 以来,已将原先的静态“虚拟”字段替换为对栈上变量的
volatile存储。目前使用的编译器(SunStudio、gcc、VC++)都尊重此处volatile的语义。
如果你使用其他编译器构建 HotSpot,需验证编译器不会在volatile访问所代表的序列点处进行重排序。
2.4.9 关于 os::is_MP() 的冗余性
调用此接口的代码无需在执行操作前手动检查 os::is_MP()(是否为多处理器系统)。
该检查已由接口实现内部处理(具体是否执行取决于 JVM 版本和平台)。
2.4.10 内存排序与缓存一致性的重要说明
缓存一致性(Cache Coherency)与内存排序(Memory Ordering)是两个正交的概念,但它们相互影响。
- 所有现有的 Itanium 机器都是缓存一致的,但硬件可以自由地重排加载相对于其他加载的操作,除非遇到
load-acquire指令。 - 所有现有的 SPARC 机器也是缓存一致的,但与 Itanium 不同,TSO(Total Store Order)模型保证硬件会自动对加载与加载、加载与存储、存储与存储进行排序。
考虑 loadload 的实现:
- 如果平台不支持缓存一致性,那么
loadload不仅要防止硬件加载指令的重排序,还必须确保后续对可能被其他处理器写入的地址的加载操作,能真正访问到这些处理器共享的第一级内存(如 E$ 或主存)。
例如,若某处理器有私有 D(数据缓存),不感知其他处理器的写操作,但共享E(数据缓存),不感知其他处理器的写操作,但共享E(二级缓存)可以感知,那么 loadload 必须确保:
- 使该处理器 D中可能被其他处理器修改的缓存行失效,从而后续加载会访问E中可能被其他处理器修改的缓存行失效,从而后续加载会访问E;或所有对共享数据的访问都绕过 D,直接从E,直接从E 满足。
- 若
loadload不具备这些特性,则“存储-释放”发布共享数据结构的模式将失效:一个处理器可能从自己的私有缓存中读取旧数据,而非从其他处理器刚刚写入的共享内存中读取。- 目前所有主流处理器都具备缓存一致性,因此上述问题在实践中很少出现。
2.4.11 关于 MutexLocker 及其相关类
参见 mutexLocker.hpp。
我们假设在整个 JVM 中,MutexLocker 及其相关类的构造函数按以下顺序执行:
fence → lock → acquire
而其析构函数按以下顺序执行:
release → unlock
如果这些类的实现发生变化,打破了上述顺序假设,将导致大量代码出错。
2.4.12 总结【重点内容: 装逼的地方到了】
其它可以不看,但是结论得记住.
- 通过插入内存屏障(LoadLoad、StoreStore、LoadStore、StoreLoad)。
- 利用
acquire/release/fence语义控制内存操作顺序。 - 在不同 CPU 架构上使用特定指令(如
membar、mf、lock xchg)实现。 - 依赖
volatile访问作为“序列点”防止编译器优化。 - 与缓存一致性机制协同工作,确保跨线程的数据可见性。
这正是 Java volatile 能在多线程环境下提供可靠语义的底层基石。
2.5 orderAccess_linux_x86.inline.hpp 分析
src\os_cpu\linux_x86\vm\orderAccess_linux_x86.inline.hpp

// Implementation of class OrderAccess. 实现定义的函数.
inline void OrderAccess::loadload() { acquire(); }
inline void OrderAccess::storestore() { release(); }
inline void OrderAccess::loadstore() { acquire(); }
inline void OrderAccess::storeload() { fence(); }// HotSpot JVM 中封装的“获取”内存屏障操作,表示一个 acquire fence
// 在内存模型中,“acquire” 操作确保:该操作之后的所有内存访问(load/store)不能重排到它之前。
// 它常用于锁的获取(lock)或 volatile 变量的读取,以保证能看到之前释放(release)写入的最新数据。
inline void OrderAccess::acquire() // 具体实现
{// local_dummy:一个“虚拟”变量(dummy variable),仅用于触发一个 volatile 内存访问// volatile:防止编译器优化掉这个变量的读写操作。// intptr_t:一个能容纳指针大小的整数类型(32位为 int,64位为 long),确保跨平台兼容// 这里添加volatile目的: volatile 访问是一个“序列点”(sequence point),编译器不能跨越它进行指令重排序。这是实现内存屏障语义的关键手段。volatile intptr_t local_dummy;
#ifdef AMD64 __asm__ volatile("movq 0(%%rsp), %0" : "=r"(local_dummy) : : "memory");
#else__asm__ volatile("movl 0(%%esp),%0" : "=r"(local_dummy) : : "memory");
#endif // AMD64
}对于 64 位系统(AMD64):
__asm__ volatile("movq 0(%%rsp), %0" : "=r"(local_dummy) : : "memory");
对于 32 位系统(i386):
__asm__ volatile("movl 0(%%esp),%0" : "=r"(local_dummy) : : "memory");
拆解这行内联汇编:
-
"movq 0(%%rsp), %0"(64位)-
movq:64 位的移动指令。 -
0(%%rsp):从栈顶(rsp寄存器指向的位置)读取一个 8 字节值。 -
%0:代表输出操作数local_dummy,即把读到的值存入local_dummy。
-
-
movl 0(%%esp),%0(32位)-
movl:32 位移动指令。 -
0(%%esp):从esp(栈指针)指向的地址读一个 4 字节值。
-
注意:
rsp是 64 位的栈指针,esp是 32 位的栈指针。
"=r"(local_dummy)
- `=` 表示输出。- `r` 表示使用任意通用寄存器。- 编译器会从栈顶读一个值,放入某个寄存器,再赋给 `local_dummy`。
-
: memory`, 重点内容
-
它告诉 GCC:这段汇编代码可能修改了任意内存位置,因此:
-
编译器不能缓存任何变量到寄存器;
-
不能对这条指令前后的内存访问进行重排序;
-
必须刷新所有内存状态。
-
-
这相当于一个 编译器屏障(compiler barrier),防止指令重排。
-
为什么读栈顶?为什么不读别的地址?
0(%%rsp)或0(%%esp)是当前栈顶地址,总是可读的,不会导致段错误。- 读取这个地址没有实际语义——我们不关心读到什么值,只关心“发生了一次
volatile内存读取”这个动作。- 使用栈顶是为了避免引入额外的全局变量或内存分配,保证高效且线程安全。
- 💡 本质上:我们通过一次“无害的、可预测的
volatile内存读取”,触发编译器的内存屏障行为。这个函数实现了什么语义?
- 确保在此调用之后的所有内存读写操作,不会被重排到此调用之前。
- 这实现了 acquire semantics,典型用途包括:
- 获取锁(mutex lock)时,确保临界区内的读写不会重排到锁获取之前;
- 读取
volatile变量后,确保能看见之前volatile写入的全部副作用;- 实现
volatile读的“获取”语义。
举例说明: 在 HotSpot 中,volatile 变量的读取可能被编译为:
int value = volatile_field;
OrderAccess::acquire(); // 确保后续操作不会重排到读之前
而 OrderAccess::acquire() 就是上面这段内联汇编。
这段代码主要的目的总结:
| 目的 | 实现方式 |
|---|---|
| 实现 acquire 内存屏障 | 提供“获取”语义,防止后续内存访问重排到前面 |
| 防止编译器重排序 | 使用 volatile + "memory" clobber |
| 避免硬件开销(x86) | 不使用 mfence 等昂贵指令,利用 x86-TSO 特性 |
| 线程安全且高效 | 读取栈顶,无需全局变量或系统调用 |
结论: OrderAccess::acquire() 通过一次对栈顶的 volatile 读操作 + "memory" 内存屏障,阻止编译器将后续的内存访问重排序到该点之前,从而实现 acquire 语义,是 volatile 读和锁获取的底层基石。
三、代码示例: 深入理解语义
3.1 可见性演示【无限循环问题】
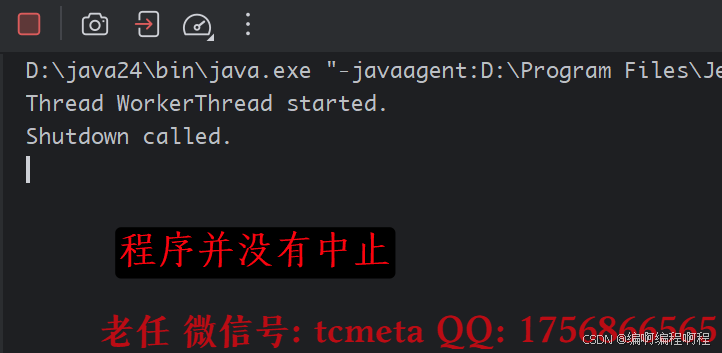
- 不添加
volatile关键字
package cn.tcmeta.usevolatile;public class VisibilityDemo {// 尝试分别加上和去掉 volatile 关键字来运行程序,观察结果private boolean flag = true;public void execute() {System.out.println("Thread " + Thread.currentThread().getName() + " started.");while (flag) {// 循环体不能是空的,否则JVM可能会进行优化,即使没有volatile也可能退出循环。// 但加入一些代码(如输出)会影响JVM优化策略,导致实验现象不稳定。// 所以这里用一个空的循环体来模拟最极端的情况}System.out.println("Thread " + Thread.currentThread().getName() + " stopped.");}public void shutdown() {flag = false;System.out.println("Shutdown called.");}public static void main(String[] args) throws InterruptedException {VisibilityDemo demo = new VisibilityDemo();// 启动一个线程执行循环Thread workerThread = new Thread(demo::execute, "WorkerThread");workerThread.start();// 主线程休眠1秒,确保工作线程已启动并进入循环Thread.sleep(1000);// 在主线程中修改标志位demo.shutdown();// 等待工作线程结束(如果它能结束的话)workerThread.join();System.out.println("Main thread exits.");}
}
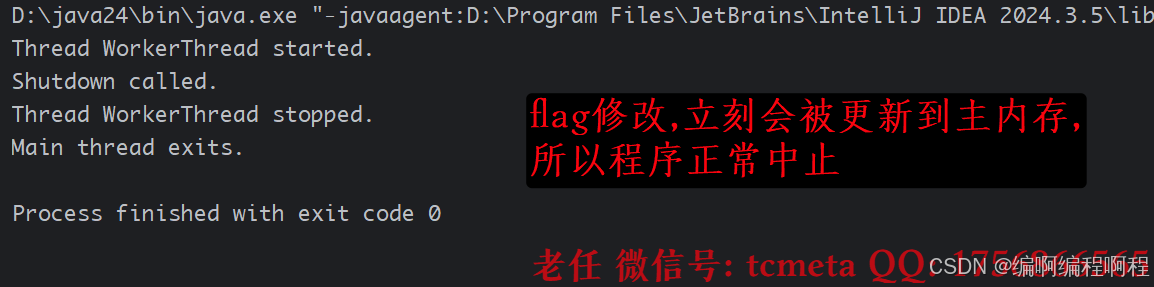
添加上volatile关键字
package cn.tcmeta.usevolatile;public class VisibilityDemo {// 尝试分别加上和去掉 volatile 关键字来运行程序,观察结果private volatile boolean flag = true;public void execute() {System.out.println("Thread " + Thread.currentThread().getName() + " started.");while (flag) {// 循环体不能是空的,否则JVM可能会进行优化,即使没有volatile也可能退出循环。// 但加入一些代码(如输出)会影响JVM优化策略,导致实验现象不稳定。// 所以这里用一个空的循环体来模拟最极端的情况}System.out.println("Thread " + Thread.currentThread().getName() + " stopped.");}public void shutdown() {flag = false;System.out.println("Shutdown called.");}public static void main(String[] args) throws InterruptedException {VisibilityDemo demo = new VisibilityDemo();// 启动一个线程执行循环Thread workerThread = new Thread(demo::execute, "WorkerThread");workerThread.start();// 主线程休眠1秒,确保工作线程已启动并进入循环Thread.sleep(1000);// 在主线程中修改标志位demo.shutdown();// 等待工作线程结束(如果它能结束的话)workerThread.join();System.out.println("Main thread exits.");}
}
- 不加
volatile: 极大概率WorkerThread永远不会看到main线程修改后的flag值(false),因此会陷入死循环,无法退出。因为WorkerThread一直在读取自己工作内存中的flag副本(始终为true)。 - 加上
volatile:main线程对flag的修改会立即被刷新到主内存,并使得WorkerThread的缓存行失效。WorkerThread在下次判断while(flag)时,会强制从主内存重新读取,读到false后循环终止。
3.2 有序性演示
3.2.1 指令重排序导致的问题
package cn.tcmeta.usevolatile;public class ReorderDemo {private static int a = 0, b = 0;private static int x = 0, y = 0;public static void main(String[] args) throws InterruptedException {int i = 0;while (true) {i++;a = 0; b = 0;x = 0; y = 0;// 线程 1:执行 a=1; x=b;Thread t1 = new Thread(() -> {a = 1;x = b;});// 线程 2:执行 b=1; y=a;Thread t2 = new Thread(() -> {b = 1;y = a;});t1.start();t2.start();t1.join();t2.join();// 正常情况下,x 和 y 不可能同时为 0if (x == 0 && y == 0) {System.out.println("第 " + i + " 次执行:x=" + x + ", y=" + y);break;}}}
}
现象:程序可能会输出 x=0, y=0。
原因:线程 t1 中的 a=1 和 x=b 可能被重排序为 x=b; a=1,同时线程 t2 中的 b=1 和 y=a 被重排序为 y=a; b=1,导致 x 和 y 都读取到 0。
3.2.2 DCL 单例模式
著名的双重检查锁定(Double-Checked Locking, DCL) 单例模式是 volatile 禁止重排序的经典案例。
public class Singleton {// 必须使用 volatile!禁止 instance = new Singleton(); 这句代码内部的指令重排序。private static volatile Singleton instance;private Singleton() {System.out.println("Singleton instance is created.");}public static Singleton getInstance() {if (instance == null) { // First check (no locking)synchronized (Singleton.class) {if (instance == null) { // Second check (with locking)// 这行代码不是原子的,它分为三步:// 1. 分配内存空间// 2. 初始化对象(调用构造方法)// 3. 将 instance 引用指向这块内存(此时 instance != null)// 如果没有 volatile,步骤 2 和 3 可能被重排序!instance = new Singleton();}}}return instance;}public static void main(String[] args) {for (int i = 0; i < 10; i++) {new Thread(() -> Singleton.getInstance(), "Thread-" + i).start();}}
}

这里为什么必须要添加volatile?
instance = new Singleton(); 这行代码(字节码层面)并非原子操作,它大致分为三步:
memory = allocate(); // 1. 为对象分配堆内存空间
ctorInstance(memory); // 2. 初始化对象(调用构造方法)
instance = memory; // 3. 将 instance 引用指向分配好的内存地址
如果没有 volatile,JIT 编译器或 CPU 可能会进行指令重排序,将步骤 3 和步骤 2 调换顺序:
memory = allocate(); // 1. 分配内存
instance = memory; // 3. 引用指向内存(此时 instance != null,但对象还未初始化!)
ctorInstance(memory); // 2. 初始化对象
假设线程 A 执行 getInstance(),发生了重排序,刚执行完步骤 2(instance 已不为 null,但对象还未初始化)。
此时线程 B 执行第一个 if (instance == null),发现 instance 不是 null,便会直接返回这个尚未初始化完成的残缺对象,从而导致程序错误。
结论: volatile 的作用: 通过插入内存屏障,禁止了步骤 2(写普通变量,即对象的初始化操作)和步骤 3(写 volatile 变量)之间的重排序,从而保证了其他线程在看到 instance 引用不为 null 时,其指向的对象一定是已经初始化完成的。
四、volatile局限性: 不能保证原子性
这是一个非常重要的点。volatile 保证了单个读/写操作的原子性(即使是 64 位的 long 和 double),但它不保证复合操作的原子性。
4.1 示例: 自增操作(i ++)
package cn.tcmeta.usevolatile;public class AtomicityDemo {private volatile int count = 0;public void increment() {count++; // 这不是一个原子操作,它分为三步:1.读取count 2.count + 1 3.写入count}public static void main(String[] args) throws InterruptedException {AtomicityDemo demo = new AtomicityDemo();Thread t1 = new Thread(() -> {for (int i = 0; i < 10000; i++) {demo.increment();}});Thread t2 = new Thread(() -> {for (int i = 0; i < 10000; i++) {demo.increment();}});t1.start();t2.start();t1.join();t2.join();// 结果几乎永远不会是 20000System.out.println("Final count is : " + demo.count);}
}
结果分析: 即使 count 是 volatile 的,最终结果也几乎不可能是 20000。因为 count++ 是 read-modify-write 三步操作,volatile 只能保证每次读到的都是最新值,但无法保证当两个线程同时读到同一个最新值后,依次执行 +1 和写回操作时不会相互覆盖。
解决方案: 对于这种复合操作,需要使用 synchronized 或 java.util.concurrent.atomic.* 包下的原子类(如 AtomicInteger,它们通过 CAS 循环指令实现无锁原子操作)。
五、总结
5.1 volatile vs synchronized
| 特性 | synchronized | volatile |
|---|---|---|
| 原子性 | 可以保证(互斥执行代码块) | 不能保证(仅保证单次读/写的原子性) |
| 可见性 | 可以保证(解锁前将变量刷回主内存) | 可以保证(写操作立即刷新,读操作重新加载) |
| 有序性 | 可以保证(一个变量在同一时刻只允许一条线程对其加锁) | 可以保证(通过内存屏障禁止重排序) |
| 性能 | 重量级,开销大(线程阻塞、上下文切换) | 轻量级,开销小(通常只在CPU指令级别) |
| 使用场景 | 复杂的复合操作,需要互斥执行的代码段 | 简单的状态标志位、DCL单例模式等特定场景 |
5.2 何时使用 volatile?
- 运算结果不依赖变量的当前值,或者能确保只有单一的线程修改变量的值。
- 变量不需要与其他状态变量共同参与不变约束。
- 访问变量时,没有其他的原因需要加锁。