MAE——Masked Autoencoders Are Scalable Vision Learners/图像分类和去雨雾重建/
论文:《Masked Autoencoders Are Scalable Vision Learners》
地址:[2111.06377] Masked Autoencoders Are Scalable Vision Learners
一、论文精华
掩码自编码器(MAE)是一种简单的自编码方法,它能够根据信号的局部观测来重建原始信号。采用了一种非对称设计:编码器仅对部分、被观测到的信号(不含掩码标记)进行操作,而解码器则是一个轻量级结构,它结合潜在表示和掩码标记来重建完整信号。
在预训练阶段,会随机遮蔽掉图像块(例如75%)中的大部分(即一个大比例的随机子集)。编码器仅作用于可见的小部分图像块。在编码器之后引入掩码标记(mask tokens),随后将所有已编码的图像块与这些掩码标记一起输入一个较小的解码器,该解码器负责将这些信息重建为原始像素级的图像。预训练完成后,解码器会被丢弃,而编码器则直接应用于未受损的完整图像(即全部图像块)以执行识别任务。
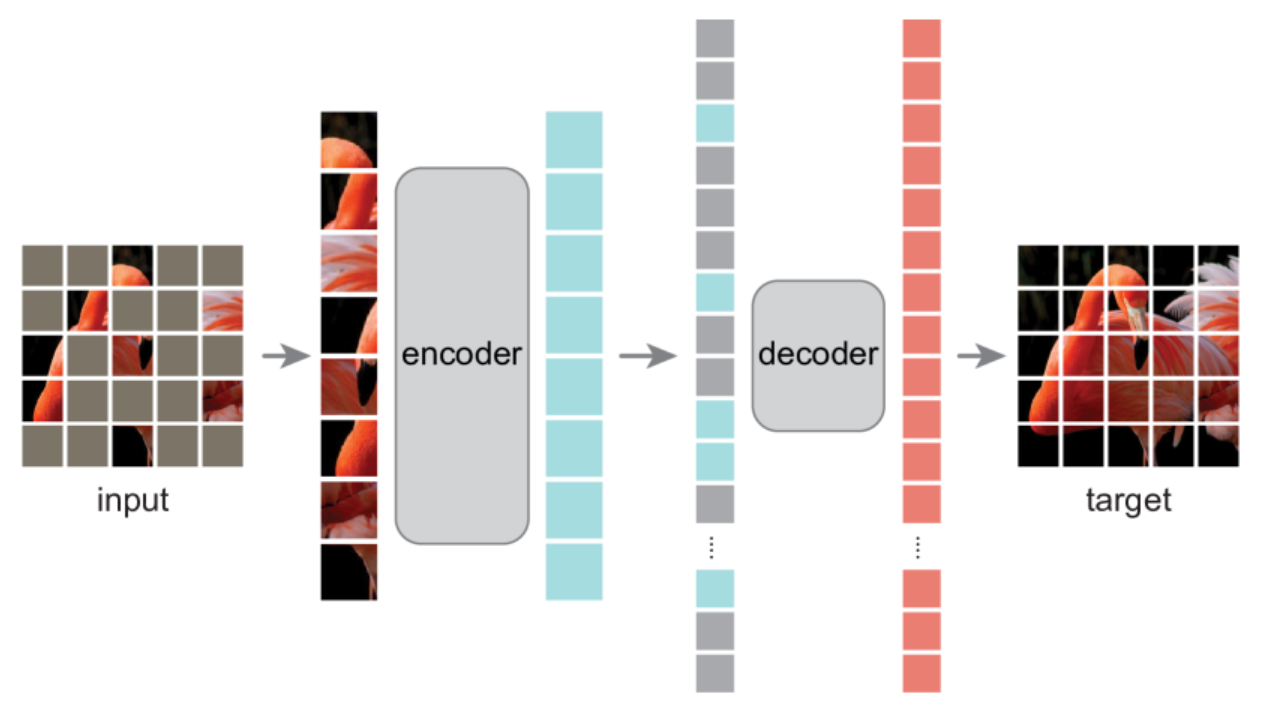
MAE通过预测每个被遮蔽图像块的像素值来重建输入图像。解码器输出的每一个元素都是一个表示某个图像块的像素值向量。解码器的最后一层是一个线性投影层,其输出通道数等于一个图像块中像素值的数量。随后,将解码器的输出重新reshape,以形成重建后的图像。
损失函数计算重建图像与原始图像在像素空间上的均方误差(MSE)。与BERT类似,我们仅在那些被遮蔽的图像块上计算损失。
论文的关键点是:Mask Token只在解码器输入时被引入,而不参与编码器的计算。Mask Token是一个可学习的向量,代表被遮盖的区域。这避免了编码器去适应这些没有任何图像信息的占位符,保证了编码器学到的特征纯粹来自于真实的图像 patches。
MAE的输出头是一个简单的线性层,将解码器输出的每个token映射回一个补丁的所有像素值(patch_size * patch_size * 3)。损失函数只计算被掩码区域的重建误差。这让模型专注于学习如何填补空白,而不是记住已经看到的内容。
二、模型复现
class MAE(nn.Module):def __init__(self, encoder_name="vit_tiny_patch16_224", img_size=224, mask_ratio=0.75):super().__init__()self.encoder = timm.create_model(encoder_name, pretrained=False, num_classes=0)self.embed_dim = self.encoder.embed_dimself.patch_size = self.encoder.patch_embed.patch_size[0]self.num_patches = self.encoder.patch_embed.num_patchesself.mask_ratio = mask_ratio# mask tokenself.mask_token = nn.Parameter(torch.zeros(1, 1, self.embed_dim))nn.init.normal_(self.mask_token, std=0.02) # 正确初始化mask token# 增强的decoderself.decoder_embed = nn.Linear(self.embed_dim, self.embed_dim, bias=True)self.decoder_pos_embed = nn.Parameter(torch.zeros(1, self.num_patches, self.embed_dim))# 使用更深的transformer作为decoderself.decoder_blocks = nn.ModuleList([nn.TransformerEncoderLayer(d_model=self.embed_dim,nhead=8,dim_feedforward=self.embed_dim * 4,dropout=0.1,activation='gelu',batch_first=True) for _ in range(4) # 4层decoder])self.decoder_norm = nn.LayerNorm(self.embed_dim)self.decoder_pred = nn.Linear(self.embed_dim, self.patch_size * self.patch_size * 3, bias=True)# 初始化nn.init.trunc_normal_(self.decoder_pos_embed, std=0.02)self.apply(self._init_weights) # 应用权重初始化def _init_weights(self, m):if isinstance(m, nn.Linear):nn.init.xavier_uniform_(m.weight)if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.LayerNorm):nn.init.constant_(m.bias, 0)nn.init.constant_(m.weight, 1.0)def forward(self, x):# 拆 patchx = self.encoder.patch_embed(x) # [B, N, C]B, N, C = x.shape# 添加位置编码x = x + self.encoder.pos_embed[:, 1:(N + 1)] # 跳过cls token# 生成 masklen_keep = int(N * (1 - self.mask_ratio))noise = torch.rand(B, N, device=x.device)ids_shuffle = torch.argsort(noise, dim=1)ids_restore = torch.argsort(ids_shuffle, dim=1)ids_keep = ids_shuffle[:, :len_keep]x_masked = torch.gather(x, 1, ids_keep.unsqueeze(-1).expand(-1, -1, C))# 应用encoder blocksfor blk in self.encoder.blocks:x_masked = blk(x_masked)x_encoded = self.encoder.norm(x_masked)# 拼回完整序列(含 mask token)mask_tokens = self.mask_token.repeat(B, N - len_keep, 1)x_ = torch.cat([x_encoded, mask_tokens], dim=1) # [B, N, C]x_full = torch.gather(x_, 1, ids_restore.unsqueeze(-1).expand(-1, -1, C))# decoderx_decoder = self.decoder_embed(x_full)x_decoder = x_decoder + self.decoder_pos_embedfor blk in self.decoder_blocks:x_decoder = blk(x_decoder)x_decoder = self.decoder_norm(x_decoder)pred = self.decoder_pred(x_decoder)return pred, ids_restoreMAE的流程是这样的:对图像进行分块和嵌入,添加位置编码(ViT操作),生成随机噪声(掩码75%),只将可见的patch送到编码器。使用ViT处理可见patch,将编码的可见patches和mask tokens拼接,将整个序列恢复位置顺序。将序列送进解码器,最后使用一个线性投影层将输出的token映射到像素空间,重建patches,随后针对被掩码的区域计算损失。
由于输入编码器是一个标准ViT,我这里可以使用timm库里的tiny模型,如果追求模型质量可以更换为base模型。
三、实现图像分类
import argparse
import os
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from tqdm import tqdm
import timm
import numpy as np
import matplotlib.pyplot as plt
import math
from PIL import Image
import warningswarnings.filterwarnings('ignore')
# -------------------
# MAE 定义
# -------------------
class MAE(nn.Module):def __init__(self, encoder_name="vit_tiny_patch16_224", img_size=224, mask_ratio=0.75):super().__init__()self.encoder = timm.create_model(encoder_name, pretrained=False, num_classes=0)self.embed_dim = self.encoder.embed_dimself.patch_size = self.encoder.patch_embed.patch_size[0]self.num_patches = self.encoder.patch_embed.num_patchesself.mask_ratio = mask_ratio# mask tokenself.mask_token = nn.Parameter(torch.zeros(1, 1, self.embed_dim))nn.init.normal_(self.mask_token, std=0.02) # 正确初始化mask token# 增强的decoderself.decoder_embed = nn.Linear(self.embed_dim, self.embed_dim, bias=True)self.decoder_pos_embed = nn.Parameter(torch.zeros(1, self.num_patches, self.embed_dim))# 使用更深的transformer作为decoderself.decoder_blocks = nn.ModuleList([nn.TransformerEncoderLayer(d_model=self.embed_dim,nhead=8,dim_feedforward=self.embed_dim * 4,dropout=0.1,activation='gelu',batch_first=True) for _ in range(4) # 4层decoder])self.decoder_norm = nn.LayerNorm(self.embed_dim)self.decoder_pred = nn.Linear(self.embed_dim, self.patch_size * self.patch_size * 3, bias=True)# 初始化nn.init.trunc_normal_(self.decoder_pos_embed, std=0.02)self.apply(self._init_weights) # 应用权重初始化def _init_weights(self, m):if isinstance(m, nn.Linear):nn.init.xavier_uniform_(m.weight)if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.LayerNorm):nn.init.constant_(m.bias, 0)nn.init.constant_(m.weight, 1.0)def forward(self, x):# 拆 patchx = self.encoder.patch_embed(x) # [B, N, C]B, N, C = x.shape# 添加位置编码x = x + self.encoder.pos_embed[:, 1:(N + 1)] # 跳过cls token# 生成 masklen_keep = int(N * (1 - self.mask_ratio))noise = torch.rand(B, N, device=x.device)ids_shuffle = torch.argsort(noise, dim=1)ids_restore = torch.argsort(ids_shuffle, dim=1)ids_keep = ids_shuffle[:, :len_keep]x_masked = torch.gather(x, 1, ids_keep.unsqueeze(-1).expand(-1, -1, C))# 应用encoder blocksfor blk in self.encoder.blocks:x_masked = blk(x_masked)x_encoded = self.encoder.norm(x_masked)# 拼回完整序列(含 mask token)mask_tokens = self.mask_token.repeat(B, N - len_keep, 1)x_ = torch.cat([x_encoded, mask_tokens], dim=1) # [B, N, C]x_full = torch.gather(x_, 1, ids_restore.unsqueeze(-1).expand(-1, -1, C))# decoderx_decoder = self.decoder_embed(x_full)x_decoder = x_decoder + self.decoder_pos_embedfor blk in self.decoder_blocks:x_decoder = blk(x_decoder)x_decoder = self.decoder_norm(x_decoder)pred = self.decoder_pred(x_decoder)return pred, ids_restore# -------------------
# Pretrain 阶段
# -------------------
def train_one_epoch_pretrain(model, dataloader, optimizer, device):model.train()total_loss = 0.0pbar = tqdm(dataloader, desc="Pretraining", leave=False)for images, _ in pbar:images = images.to(device)optimizer.zero_grad()pred, ids_restore = model(images)patch_size = model.patch_size# 将原图切分成 patchB, C, H, W = images.shapetarget_patches = images.unfold(2, patch_size, patch_size).unfold(3, patch_size, patch_size)target_patches = target_patches.permute(0, 2, 3, 1, 4, 5).reshape(B, -1, C, patch_size, patch_size)target_patches = target_patches.reshape(B, -1, patch_size * patch_size * C)# 关键修改:对目标patch进行归一化(按patch的均值和方差)target_patches_mean = target_patches.mean(dim=-1, keepdim=True)target_patches_var = target_patches.var(dim=-1, keepdim=True)target_patches_normalized = (target_patches - target_patches_mean) / (target_patches_var + 1e-6).sqrt()# 同样对预测进行归一化pred_mean = pred.mean(dim=-1, keepdim=True)pred_var = pred.var(dim=-1, keepdim=True)pred_normalized = (pred - pred_mean) / (pred_var + 1e-6).sqrt()# loss: 只计算 mask 部分mask = torch.ones([B, model.num_patches], device=device)len_keep = int(model.num_patches * (1 - model.mask_ratio))mask[:, :len_keep] = 0mask = torch.gather(mask, 1, ids_restore) # [B, N]mask = mask.unsqueeze(-1) # [B, N, 1]# 计算MSE loss,只对mask部分loss = F.mse_loss(pred_normalized * mask, target_patches_normalized * mask, reduction='sum') / mask.sum()loss.backward()optimizer.step()total_loss += loss.item() * images.size(0)pbar.set_postfix({'Loss': f'{loss.item():.4f}'})return total_loss / len(dataloader.dataset)# -------------------
# 可视化函数
# -------------------
def visualize_reconstruction(model, dataloader, device, num_images=4):model.eval()images, _ = next(iter(dataloader))images = images.to(device)with torch.no_grad():pred, ids_restore = model(images)patch_size = model.patch_sizeB, C, H, W = images.shapenum_patches_per_row = H // patch_size# 反标准化用于可视化mean = torch.tensor([0.4914, 0.4822, 0.4465]).view(1, 3, 1, 1).to(device)std = torch.tensor([0.2023, 0.1994, 0.2010]).view(1, 3, 1, 1).to(device)imgs = (images * std + mean).clamp(0, 1)[:num_images].cpu()recon_imgs, masked_imgs = [], []for i in range(num_images):# 重建图像pred_patches = pred[i].cpu().numpy().reshape(-1, patch_size, patch_size, 3)pred_patches = np.clip(pred_patches, 0, 1) # 限制在[0,1]范围内rec_img = np.zeros((H, W, 3))patch_idx = 0for y in range(num_patches_per_row):for x in range(num_patches_per_row):rec_img[y * patch_size:(y + 1) * patch_size, x * patch_size:(x + 1) * patch_size, :] = pred_patches[patch_idx]patch_idx += 1recon_imgs.append(rec_img)# mask 后的图像mask = torch.ones(model.num_patches, device=device)len_keep = int(model.num_patches * (1 - model.mask_ratio))mask[:len_keep] = 0mask = torch.gather(mask, 0, ids_restore[i])mask = mask.cpu().reshape(num_patches_per_row, num_patches_per_row)masked_img = imgs[i].permute(1, 2, 0).numpy().copy()for y in range(num_patches_per_row):for x in range(num_patches_per_row):if mask[y, x] == 1:masked_img[y * patch_size:(y + 1) * patch_size, x * patch_size:(x + 1) * patch_size, :] = 0.5masked_imgs.append(masked_img)# 画图fig, axes = plt.subplots(num_images, 3, figsize=(9, num_images * 3))for i in range(num_images):axes[i, 0].imshow(imgs[i].permute(1, 2, 0))axes[i, 0].set_title("Original")axes[i, 1].imshow(masked_imgs[i])axes[i, 1].set_title("Masked")axes[i, 2].imshow(recon_imgs[i])axes[i, 2].set_title("Reconstructed")for ax in axes[i]:ax.axis("off")plt.tight_layout()plt.show()def run_pretrain(args, train_loader):model = MAE(encoder_name="vit_tiny_patch16_224").to(args.device)# 使用AdamW优化器optimizer = optim.AdamW(model.parameters(),lr=args.lr,weight_decay=0.05,betas=(0.9, 0.95))# 添加warmupfrom torch.optim.lr_scheduler import LambdaLRwarmup_epochs = 5def lr_lambda(epoch):if epoch < warmup_epochs:return (epoch + 1) / warmup_epochselse:return 0.5 * (1 + math.cos(math.pi * (epoch - warmup_epochs) / (args.epochs - warmup_epochs)))scheduler = LambdaLR(optimizer, lr_lambda)for epoch in range(args.epochs):loss = train_one_epoch_pretrain(model, train_loader, optimizer, args.device)scheduler.step()print(f"Epoch [{epoch + 1}/{args.epochs}] Loss: {loss:.4f}, LR: {scheduler.get_last_lr()[0]:.6f}")if args.visualize and ((epoch + 1) % 5 == 0 or epoch == args.epochs - 1):visualize_reconstruction(model, train_loader, args.device)torch.save({"model": model.state_dict()}, args.save_path)print(f"=> MAE Pretrain finished. Model weights saved to {args.save_path}")# -------------------
# Finetune 阶段
# -------------------
def build_finetune_model(num_classes, weight_path=None, device="cuda"):model = timm.create_model("vit_tiny_patch16_224", pretrained=False, num_classes=num_classes)if weight_path and os.path.exists(weight_path):checkpoint = torch.load(weight_path, map_location="cpu")if "model" in checkpoint:print("=> Loading MAE pretrain encoder")state_dict = checkpoint["model"]new_state_dict = {}for k, v in state_dict.items():if k.startswith('encoder.'):new_k = k.replace('encoder.', '')new_state_dict[new_k] = velse:new_state_dict[k] = vmsg = model.load_state_dict(new_state_dict, strict=False)print("Missing keys:", len(msg.missing_keys) if msg.missing_keys else "None")print("Unexpected keys:", len(msg.unexpected_keys) if msg.unexpected_keys else "None")else:print("=> Loading fine-tuned weights")model.load_state_dict(checkpoint, strict=True)else:print("=> Training from scratch (no pretrained weights)")return model.to(device)def train_one_epoch_finetune(model, dataloader, criterion, optimizer, device):model.train()total_loss, correct, total = 0.0, 0, 0pbar = tqdm(dataloader, desc="Finetuning", leave=False)for images, labels in pbar:images, labels = images.to(device), labels.to(device)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()total_loss += loss.item() * images.size(0)_, preds = outputs.max(1)correct += preds.eq(labels).sum().item()total += labels.size(0)pbar.set_postfix({'Loss': f'{loss.item():.4f}', 'Acc': f'{correct / total:.4f}'})return total_loss / total, correct / totaldef evaluate(model, dataloader, criterion, device):model.eval()total_loss, correct, total = 0.0, 0, 0with torch.no_grad():for images, labels in dataloader:images, labels = images.to(device), labels.to(device)outputs = model(images)loss = criterion(outputs, labels)total_loss += loss.item() * images.size(0)_, preds = outputs.max(1)correct += preds.eq(labels).sum().item()total += labels.size(0)return total_loss / total, correct / totaldef run_finetune(args, train_loader, val_loader):model = build_finetune_model(args.num_classes, args.weights, args.device)criterion = nn.CrossEntropyLoss()optimizer = optim.AdamW(model.parameters(), lr=args.lr, weight_decay=0.05)best_acc = 0.0for epoch in range(args.epochs):print(f"\nEpoch {epoch + 1}/{args.epochs}")train_loss, train_acc = train_one_epoch_finetune(model, train_loader, criterion, optimizer, args.device)val_loss, val_acc = evaluate(model, val_loader, criterion, args.device)print(f"[{epoch + 1}/{args.epochs}] Train Loss={train_loss:.4f} Acc={train_acc:.4f} | "f"Val Loss={val_loss:.4f} Acc={val_acc:.4f}")if val_acc > best_acc:best_acc = val_acctorch.save(model.state_dict(), args.save_path)print(f"=> Saved best model to {args.save_path}")# -------------------
# 预测函数
# -------------------
def predict_image(model, image_path, class_names, device="cpu", in_channels=3):if in_channels == 1:transform = transforms.Compose([transforms.Resize((224, 224)),transforms.Grayscale(num_output_channels=1),transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,)),])img = Image.open(image_path).convert("L")else:transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),])img = Image.open(image_path).convert("RGB")img = transform(img).unsqueeze(0).to(device)model.eval()with torch.no_grad():outputs = model(img)probs = torch.softmax(outputs, dim=1)conf, pred = torch.max(probs, dim=1)return class_names[pred.item()], conf.item()def run_predict(args):# 确定输入通道数if args.dataset in ['mnist', 'fashionmnist']:in_channels = 1else:in_channels = 3# 构建模型model = build_finetune_model(args.num_classes, args.weights, args.device)# 加载微调后的权重if os.path.exists(args.save_path):model.load_state_dict(torch.load(args.save_path, map_location=args.device))print(f"=> Loaded fine-tuned weights from {args.save_path}")else:print(f"=> Warning: Fine-tuned weights not found at {args.save_path}, using pretrained backbone only")model.eval()# 获取类别名称if args.dataset == 'cifar10':class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer','dog', 'frog', 'horse', 'ship', 'truck']elif args.dataset == 'cifar100':class_names = [str(i) for i in range(100)]elif args.dataset == 'mnist':class_names = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']elif args.dataset == 'fashionmnist':class_names = ['T-shirt', 'Trouser', 'Pullover', 'Dress', 'Coat','Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']else:class_names = [str(i) for i in range(args.num_classes)]# 预测单张图片if os.path.isfile(args.image_path):label, conf = predict_image(model, args.image_path, class_names,device=args.device, in_channels=in_channels)print(f"预测结果: {label}, 置信度: {conf:.4f}")# 预测文件夹中的所有图片elif os.path.isdir(args.image_path):image_extensions = ['.jpg', '.jpeg', '.png', '.bmp']image_files = [f for f in os.listdir(args.image_path)if os.path.splitext(f)[1].lower() in image_extensions]for image_file in image_files:image_full_path = os.path.join(args.image_path, image_file)label, conf = predict_image(model, image_full_path, class_names,device=args.device, in_channels=in_channels)print(f"{image_file}: {label} (置信度: {conf:.4f})")else:print(f"错误: {args.image_path} 不是有效的文件或目录")# -------------------
# 主程序入口
# -------------------
def main():parser = argparse.ArgumentParser(description="MAE Pretrain & Finetune")parser.add_argument("--mode", type=str, choices=["pretrain", "finetune", "predict"],default="predict", help="运行模式: pretrain (预训练), finetune (微调) 或 predict (预测)")parser.add_argument("--dataset", type=str, default="cifar10",help="数据集名称: cifar10, cifar100, mnist, fashionmnist 或自定义数据集路径")parser.add_argument("--data_dir", type=str, default="./data",help="数据存储目录")parser.add_argument("--weights", type=str, default='mae_tiny_finetune.pth',help="预训练权重路径")parser.add_argument("--epochs", type=int, default=4,help="训练轮数")parser.add_argument("--batch_size", type=int, default=32,help="批次大小")parser.add_argument("--lr", type=float, default=1.5e-4,help="学习率")parser.add_argument("--device", type=str, default="cuda",help="设备: cuda/cpu")parser.add_argument("--save_path", type=str, default="mae_tiny_finetune.pth",help="模型保存路径")parser.add_argument("--num_classes", type=int, default=10,help="类别数量")parser.add_argument("--visualize", action="store_true", default=False,help="是否在预训练过程中进行可视化重建")parser.add_argument("--image_path", type=str, default="R-C.jpg",help="预测图片路径(可以是单张图片或包含图片的文件夹)")args = parser.parse_args()# 设备检测if args.device == "cuda" and not torch.cuda.is_available():print("CUDA不可用,使用CPU")args.device = "cpu"# transforms - 简化预处理,适合CIFARtransform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010])])if args.mode == "predict":if not args.image_path:print("错误: 预测模式需要指定 --image_path 参数")returnrun_predict(args)returnif args.dataset == "cifar10":train_set = datasets.CIFAR10(root=args.data_dir, train=True, download=True, transform=transform)val_set = datasets.CIFAR10(root=args.data_dir, train=False, download=True, transform=transform)args.num_classes = 10elif args.dataset == "cifar100":train_set = datasets.CIFAR100(root=args.data_dir, train=True, download=True, transform=transform)val_set = datasets.CIFAR100(root=args.data_dir, train=False, download=True, transform=transform)args.num_classes = 100elif args.dataset == "mnist":train_set = datasets.MNIST(root=args.data_dir, train=True, download=True, transform=transform)val_set = datasets.MNIST(root=args.data_dir, train=False, download=True, transform=transform)args.num_classes = 10elif args.dataset == "fashionmnist":train_set = datasets.FashionMNIST(root=args.data_dir, train=True, download=True, transform=transform)val_set = datasets.FashionMNIST(root=args.data_dir, train=False, download=True, transform=transform)args.num_classes = 10else:train_set = datasets.ImageFolder(root=os.path.join(args.data_dir, "train"), transform=transform)val_set = datasets.ImageFolder(root=os.path.join(args.data_dir, "val"), transform=transform)train_loader = DataLoader(train_set, batch_size=args.batch_size, shuffle=True, num_workers=2)val_loader = DataLoader(val_set, batch_size=args.batch_size, shuffle=False, num_workers=2)print(f"运行模式: {args.mode}")print(f"数据集: {args.dataset}, 类别数: {args.num_classes}")print(f"模型架构: vit_tiny_patch16_224")if args.mode == "pretrain":run_pretrain(args, train_loader)elif args.mode == "finetune":run_finetune(args, train_loader, val_loader)if __name__ == "__main__":main()这里使用了cifar10作为数据集,大家可以使用torchvision或者自己的数据集(ImageFolder格式)进行更换。训练方式分为预训练(从头训练)和微调,目前MAE提供了预训练的模型权重
这里我使用tiny版本进行预训练,如果不想预训练可以使用base进行微调。训练之后可以预测。
-
Pretrain (预训练) - 使用 MAE 方法在无标签数据上训练模型,预训练模式使用:python script.py --mode pretrain --dataset cifar10 --epochs 50 --batch_size 64 --visualize 在 CIFAR-10 上预训练 MAE 模型,每 5 个 epoch 可视化一次重建效果,模型保存为默认路径
-
Finetune (微调) - 在预训练模型基础上进行有监督分类训练 - python script.py --mode finetune --dataset cifar10 --weights mae_pretrain.pth --epochs 20 --lr 1e-4 加载预训练权重进行微调,
-
Predict (预测) - 使用训练好的模型进行图像分类预测 python script.py --mode predict --weights mae_tiny_finetune.pth --image_path test_image.jpg 使用训练好的模型进行预测,支持单张图片或文件夹批量预测
四、图像去雨/去噪
我以Rain100L数据集为例,它分为rain和norain两个子文件夹,设计了数据集加载方式:
# =============================
# Rain100L 数据集(配对)
# =============================
class RainPairDataset(Dataset):"""root/rain/norain/文件名一一对应(子目录结构保持一致或同名即可)"""def __init__(self, root: str, img_size: int = 224, split: str = "train",random_crop: bool = True, center_crop_val: bool = True, aug_hflip: bool = True):super().__init__()self.root = rootself.rain_dir = os.path.join(root, "rain")self.clean_dir = os.path.join(root, "norain")assert os.path.isdir(self.rain_dir) and os.path.isdir(self.clean_dir), "目录需包含 rain/ 与 norain/"rain_files = list_images(self.rain_dir)clean_files = list_images(self.clean_dir)rain_basenames = {os.path.basename(f) for f in rain_files}clean_basenames = {os.path.basename(f) for f in clean_files}common = sorted(list(rain_basenames & clean_basenames))assert len(common) > 0, "未找到可配对的文件(文件名需一致)"self.pairs = [(os.path.join(self.rain_dir, n), os.path.join(self.clean_dir, n)) for n in common]# 切分(简单 9:1)n = len(self.pairs)split_idx = int(n * 0.9)if split == "train":self.pairs = self.pairs[:split_idx]else:self.pairs = self.pairs[split_idx:]# 变换base = [transforms.Resize((img_size, img_size))]self.to_tensor = transforms.ToTensor()self.random_crop = random_cropself.center_crop_val = center_crop_valself.aug_hflip = aug_hflipself.img_size = img_sizedef _paired_random_crop(self, img1: Image.Image, img2: Image.Image, size: int) -> Tuple[Image.Image, Image.Image]:w, h = img1.sizeif w == size and h == size:return img1, img2if w < size or h < size:img1 = img1.resize((max(w, size), max(h, size)), Image.BICUBIC)img2 = img2.resize((max(w, size), max(h, size)), Image.BICUBIC)w, h = img1.sizex = random.randint(0, w - size)y = random.randint(0, h - size)return img1.crop((x, y, x + size, y + size)), img2.crop((x, y, x + size, y + size))def __len__(self):return len(self.pairs)def __getitem__(self, idx):rain_path, clean_path = self.pairs[idx]rain = Image.open(rain_path).convert("RGB")clean = Image.open(clean_path).convert("RGB")# 同步增广if self.random_crop:rain, clean = self._paired_random_crop(rain, clean, self.img_size)else:rain = rain.resize((self.img_size, self.img_size), Image.BICUBIC)clean = clean.resize((self.img_size, self.img_size), Image.BICUBIC)if self.aug_hflip and random.random() < 0.5:rain = rain.transpose(Image.FLIP_LEFT_RIGHT)clean = clean.transpose(Image.FLIP_LEFT_RIGHT)rain = self.to_tensor(rain) # [3,H,W] 0~1clean = self.to_tensor(clean)return rain, clean, os.path.basename(rain_path)# =============================
# 也用于 Pretrain 的 Clean-only 数据集
# =============================
class CleanOnlyDataset(Dataset):def __init__(self, root: str, img_size: int = 224, split: str = "train"):self.ds = RainPairDataset(root, img_size, split)def __len__(self): return len(self.ds)def __getitem__(self, i):_, clean, _ = self.ds[i]return clean, os.path.basename(self.ds.pairs[i][1])在图像修复中可以使用SSIM对图像块进行颜色、亮度等对比,特别适合需要保持边缘和纹理的图像恢复任务
def ssim_simple(x, y, C1=0.01**2, C2=0.03**2, win_size=11):# x,y: [B,3,H,W], 值域 0~1pad = win_size // 2mu_x = F.avg_pool2d(x, win_size, 1, pad)mu_y = F.avg_pool2d(y, win_size, 1, pad)sigma_x = F.avg_pool2d(x * x, win_size, 1, pad) - mu_x ** 2sigma_y = F.avg_pool2d(y * y, win_size, 1, pad) - mu_y ** 2sigma_xy = F.avg_pool2d(x * y, win_size, 1, pad) - mu_x * mu_yssim_map = ((2 * mu_x * mu_y + C1) * (2 * sigma_xy + C2)) / ((mu_x ** 2 + mu_y ** 2 + C1) * (sigma_x + sigma_y + C2))return ssim_map.mean()训练代码:
import argparse
import os
import glob
import math
import random
from typing import List, Tupleimport torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import timm
import numpy as np
import matplotlib.pyplot as plt# =============================
# 工具:可复现 & 路径
# =============================
def set_seed(seed: int = 42):random.seed(seed); np.random.seed(seed); torch.manual_seed(seed); torch.cuda.manual_seed_all(seed)def list_images(p: str) -> List[str]:exts = ["*.png", "*.jpg", "*.jpeg", "*.bmp", "*.tif", "*.tiff"]files = []for e in exts:files.extend(glob.glob(os.path.join(p, e)))return sorted(files)# =============================
# Rain100L 数据集(配对)
# =============================
class RainPairDataset(Dataset):"""root/rain/norain/文件名一一对应(子目录结构保持一致或同名即可)"""def __init__(self, root: str, img_size: int = 224, split: str = "train",random_crop: bool = True, center_crop_val: bool = True, aug_hflip: bool = True):super().__init__()self.root = rootself.rain_dir = os.path.join(root, "rain")self.clean_dir = os.path.join(root, "norain")assert os.path.isdir(self.rain_dir) and os.path.isdir(self.clean_dir), "目录需包含 rain/ 与 norain/"rain_files = list_images(self.rain_dir)clean_files = list_images(self.clean_dir)rain_basenames = {os.path.basename(f) for f in rain_files}clean_basenames = {os.path.basename(f) for f in clean_files}common = sorted(list(rain_basenames & clean_basenames))assert len(common) > 0, "未找到可配对的文件(文件名需一致)"self.pairs = [(os.path.join(self.rain_dir, n), os.path.join(self.clean_dir, n)) for n in common]# 切分(简单 9:1)n = len(self.pairs)split_idx = int(n * 0.9)if split == "train":self.pairs = self.pairs[:split_idx]else:self.pairs = self.pairs[split_idx:]# 变换base = [transforms.Resize((img_size, img_size))]self.to_tensor = transforms.ToTensor()self.random_crop = random_cropself.center_crop_val = center_crop_valself.aug_hflip = aug_hflipself.img_size = img_sizedef _paired_random_crop(self, img1: Image.Image, img2: Image.Image, size: int) -> Tuple[Image.Image, Image.Image]:w, h = img1.sizeif w == size and h == size:return img1, img2if w < size or h < size:img1 = img1.resize((max(w, size), max(h, size)), Image.BICUBIC)img2 = img2.resize((max(w, size), max(h, size)), Image.BICUBIC)w, h = img1.sizex = random.randint(0, w - size)y = random.randint(0, h - size)return img1.crop((x, y, x + size, y + size)), img2.crop((x, y, x + size, y + size))def __len__(self):return len(self.pairs)def __getitem__(self, idx):rain_path, clean_path = self.pairs[idx]rain = Image.open(rain_path).convert("RGB")clean = Image.open(clean_path).convert("RGB")# 同步增广if self.random_crop:rain, clean = self._paired_random_crop(rain, clean, self.img_size)else:rain = rain.resize((self.img_size, self.img_size), Image.BICUBIC)clean = clean.resize((self.img_size, self.img_size), Image.BICUBIC)if self.aug_hflip and random.random() < 0.5:rain = rain.transpose(Image.FLIP_LEFT_RIGHT)clean = clean.transpose(Image.FLIP_LEFT_RIGHT)rain = self.to_tensor(rain) # [3,H,W] 0~1clean = self.to_tensor(clean)return rain, clean, os.path.basename(rain_path)# =============================
# 也用于 Pretrain 的 Clean-only 数据集
# =============================
class CleanOnlyDataset(Dataset):def __init__(self, root: str, img_size: int = 224, split: str = "train"):self.ds = RainPairDataset(root, img_size, split)def __len__(self): return len(self.ds)def __getitem__(self, i):_, clean, _ = self.ds[i]return clean, os.path.basename(self.ds.pairs[i][1])# =============================
# SSIM(简洁实现)
# =============================
# 参考经典实现,窗口大小固定 11,高斯权重略简化为均值窗口(轻量)
def ssim_simple(x, y, C1=0.01**2, C2=0.03**2, win_size=11):# x,y: [B,3,H,W], 值域 0~1pad = win_size // 2mu_x = F.avg_pool2d(x, win_size, 1, pad)mu_y = F.avg_pool2d(y, win_size, 1, pad)sigma_x = F.avg_pool2d(x * x, win_size, 1, pad) - mu_x ** 2sigma_y = F.avg_pool2d(y * y, win_size, 1, pad) - mu_y ** 2sigma_xy = F.avg_pool2d(x * y, win_size, 1, pad) - mu_x * mu_yssim_map = ((2 * mu_x * mu_y + C1) * (2 * sigma_xy + C2)) / ((mu_x ** 2 + mu_y ** 2 + C1) * (sigma_x + sigma_y + C2))return ssim_map.mean()# =============================
# MAE 模型
# =============================
class MAE(nn.Module):"""- 预训练:mask 输入的 clean 图像,重建被遮蔽 patch(MAE)- 微调:输入 rainy,目标 clean,可选是否仍旧 mask(默认不 mask)"""def __init__(self, encoder_name="vit_small_patch8_224", img_size=224, mask_ratio=0.75):super().__init__()self.encoder = timm.create_model(encoder_name, pretrained=False, num_classes=0)self.embed_dim = self.encoder.embed_dimself.patch_size = self.encoder.patch_embed.patch_size[0]self.num_patches = self.encoder.patch_embed.num_patchesself.mask_ratio = mask_ratioself.mask_token = nn.Parameter(torch.zeros(1, 1, self.embed_dim))nn.init.normal_(self.mask_token, std=0.02)self.decoder_embed = nn.Linear(self.embed_dim, self.embed_dim, bias=True)self.decoder_pos_embed = nn.Parameter(torch.zeros(1, self.num_patches, self.embed_dim))nn.init.trunc_normal_(self.decoder_pos_embed, std=0.02)self.decoder_blocks = nn.ModuleList([nn.TransformerEncoderLayer(d_model=self.embed_dim,nhead=8,dim_feedforward=self.embed_dim * 4,dropout=0.1,activation='gelu',batch_first=True) for _ in range(4)])self.decoder_norm = nn.LayerNorm(self.embed_dim)self.decoder_pred = nn.Linear(self.embed_dim, self.patch_size * self.patch_size * 3, bias=True)def patchify(self, imgs):# imgs: [B,3,H,W] 0~1p = self.patch_sizeB, C, H, W = imgs.shapeassert H % p == 0 and W % p == 0h = H // p; w = W // px = imgs.reshape(B, C, h, p, w, p).permute(0, 2, 4, 1, 3, 5)x = x.reshape(B, h * w, C * p * p) # [B, N, 3*p*p]return xdef unpatchify(self, x, H, W):# x: [B,N,3*p*p]p = self.patch_sizeB, N, PP = x.shapeC = 3h = H // p; w = W // px = x.reshape(B, h, w, C, p, p).permute(0, 3, 1, 4, 2, 5).reshape(B, C, H, W)return xdef _mask(self, x):# x: [B,N,C]B, N, C = x.shapelen_keep = int(N * (1 - self.mask_ratio))noise = torch.rand(B, N, device=x.device)ids_shuffle = torch.argsort(noise, dim=1)ids_restore = torch.argsort(ids_shuffle, dim=1)ids_keep = ids_shuffle[:, :len_keep]x_masked = torch.gather(x, 1, ids_keep.unsqueeze(-1).expand(-1, -1, C))return x_masked, ids_restore, len_keepdef forward_tokens(self, x_tokens, ids_restore=None, len_keep=None, use_mask=True):# x_tokens: [B,N,C] -> encoder blocksif use_mask:x_masked, ids_restore, len_keep = self._mask(x_tokens)else:# 不使用 mask:完整序列B, N, C = x_tokens.shapeids_restore = torch.arange(N, device=x_tokens.device).unsqueeze(0).repeat(B, 1)x_masked = x_tokensfor blk in self.encoder.blocks:x_masked = blk(x_masked)x_encoded = self.encoder.norm(x_masked)# 还原序列(如果有 mask)B = x_tokens.size(0); N = x_tokens.size(1); C = x_tokens.size(2)if use_mask:mask_tokens = self.mask_token.repeat(B, N - len_keep, 1)x_ = torch.cat([x_encoded, mask_tokens], dim=1) # [B,N,C] 未复原顺序x_full = torch.gather(x_, 1, ids_restore.unsqueeze(-1).expand(-1, -1, C))else:x_full = x_encoded# decoderx_dec = self.decoder_embed(x_full) + self.decoder_pos_embedfor blk in self.decoder_blocks:x_dec = blk(x_dec)x_dec = self.decoder_norm(x_dec)pred = self.decoder_pred(x_dec) # [B,N,3*p*p]return pred, ids_restoredef forward(self, imgs, use_mask=True):# imgs: [B,3,H,W] 0~1tokens = self.encoder.patch_embed(imgs) # [B,N,C]tokens = tokens + self.encoder.pos_embed[:, 1:(tokens.size(1) + 1)]pred, ids_restore = self.forward_tokens(tokens, use_mask=use_mask)return pred, ids_restore# =============================
# 训练 / 评估
# =============================
def mae_loss(pred, target_patches, ids_restore, mask_ratio, reduction='mean', only_masked=True):# pred: [B,N,D], target_patches: [B,N,D]B, N, D = pred.shapeif only_masked:mask = torch.ones(B, N, device=pred.device)len_keep = int(N * (1 - mask_ratio))mask[:, :len_keep] = 0mask = torch.gather(mask, 1, ids_restore) # [B,N]mask = mask.unsqueeze(-1) # [B,N,1]loss = (pred - target_patches) ** 2loss = (loss * mask).sum() / (mask.sum() * D + 1e-8)else:loss = F.mse_loss(pred, target_patches, reduction='mean')return lossdef build_optimizer(model, lr, wd):return optim.AdamW(model.parameters(), lr=lr, weight_decay=wd, betas=(0.9, 0.95))def build_scheduler(optimizer, epochs, warmup_epochs):def lr_lambda(epoch):if epoch < warmup_epochs:return (epoch + 1) / warmup_epochsreturn 0.5 * (1 + math.cos(math.pi * (epoch - warmup_epochs) / max(1, (epochs - warmup_epochs))))return optim.lr_scheduler.LambdaLR(optimizer, lr_lambda)def save_checkpoint(path, model):os.makedirs(os.path.dirname(path) or ".", exist_ok=True)torch.save({"model": model.state_dict()}, path)def load_any_state_dict(model, weight_path, strict=False, map_encoder=False):if weight_path and os.path.exists(weight_path):ckpt = torch.load(weight_path, map_location="cpu")sd = ckpt.get("model", ckpt)if map_encoder:# 将 'encoder.' 前缀去掉以加载到分类/重建 backbonenew_sd = {}for k, v in sd.items():if k.startswith("encoder."):new_sd[k.replace("encoder.", "")] = vnew_sd[k] = vsd = new_sdmsg = model.load_state_dict(sd, strict=strict)print("=> Loaded weights from", weight_path)if hasattr(msg, "missing_keys") and msg.missing_keys:print("Missing:", len(msg.missing_keys))if hasattr(msg, "unexpected_keys") and msg.unexpected_keys:print("Unexpected:", len(msg.unexpected_keys))else:print("=> No weights loaded (path not found):", weight_path)# ---- 预训练(一类图:norain) ----
def run_pretrain(args):device = args.device if (args.device == "cpu" or torch.cuda.is_available()) else "cpu"set_seed(args.seed)ds = CleanOnlyDataset(args.dataset_root, img_size=args.img_size, split="train")dl = DataLoader(ds, batch_size=args.batch_size, shuffle=True, num_workers=args.workers, pin_memory=True, drop_last=True)model = MAE(img_size=args.img_size, mask_ratio=args.mask_ratio).to(device)# 可选:加载外部预训练(如 ImageNet 上的 MAE)if args.init_weights:load_any_state_dict(model, args.init_weights, strict=False)optimizer = build_optimizer(model, args.lr, args.weight_decay)scheduler = build_scheduler(optimizer, args.epochs, args.warmup_epochs)scaler = torch.cuda.amp.GradScaler(enabled=args.amp and device.startswith("cuda"))model.train()for epoch in range(args.epochs):running = 0.0for clean, _ in dl:clean = clean.to(device) # 0~1target_patches = model.patchify(clean)optimizer.zero_grad(set_to_none=True)with torch.cuda.amp.autocast(enabled=args.amp and device.startswith("cuda")):pred, ids_restore = model(clean, use_mask=True)loss = mae_loss(pred, target_patches, ids_restore, mask_ratio=args.mask_ratio,only_masked=True)scaler.scale(loss).backward()scaler.step(optimizer)scaler.update()running += loss.item() * clean.size(0)scheduler.step()epoch_loss = running / len(ds)print(f"[Pretrain] Epoch {epoch+1}/{args.epochs} Loss={epoch_loss:.4f} LR={scheduler.get_last_lr()[0]:.6e}")save_checkpoint(args.save_path, model)print(f"=> Pretrain finished. Saved to {args.save_path}")# ---- 微调(配对:rain -> norain) ----
def run_finetune(args):device = args.device if (args.device == "cpu" or torch.cuda.is_available()) else "cpu"set_seed(args.seed)train_set = RainPairDataset(args.dataset_root, img_size=args.img_size, split="train",random_crop=True, aug_hflip=True)val_set = RainPairDataset(args.dataset_root, img_size=args.img_size, split="val",random_crop=False, aug_hflip=False)train_loader = DataLoader(train_set, batch_size=args.batch_size, shuffle=True, num_workers=args.workers, pin_memory=True, drop_last=True)val_loader = DataLoader(val_set, batch_size=args.batch_size, shuffle=False, num_workers=args.workers, pin_memory=True)model = MAE(img_size=args.img_size, mask_ratio=args.mask_ratio).to(device)# 加载 MAE 预训练if args.init_weights:load_any_state_dict(model, args.init_weights, strict=False)optimizer = build_optimizer(model, args.lr, args.weight_decay)scheduler = build_scheduler(optimizer, args.epochs, args.warmup_epochs)scaler = torch.cuda.amp.GradScaler(enabled=args.amp and device.startswith("cuda"))def step(rain, clean, train=True):# 输入 0~1target_patches = model.patchify(clean)use_mask = args.use_mask_in_finetunepred, ids_restore = model(rain, use_mask=use_mask)if use_mask:recon_loss = mae_loss(pred, target_patches, ids_restore, mask_ratio=args.mask_ratio, only_masked=False)else:recon_loss = F.l1_loss(pred, target_patches) # patch 空间 L1# 转回图像做 SSIM(可选)with torch.no_grad():B, C, H, W = clean.shaperec_img = model.unpatchify(pred, H, W)rec_img = rec_img.clamp(0, 1)loss = recon_lossif args.use_ssim:ssim_val = ssim_simple(rec_img, clean)loss = loss + args.ssim_lambda * (1 - ssim_val)return loss, rec_imgbest_psnr = -1for epoch in range(args.epochs):# ---- train ----model.train()total_loss = 0.0for rain, clean, _ in train_loader:rain, clean = rain.to(device), clean.to(device)optimizer.zero_grad(set_to_none=True)with torch.cuda.amp.autocast(enabled=args.amp and device.startswith("cuda")):loss, _ = step(rain, clean, train=True)scaler.scale(loss).backward()scaler.step(optimizer)scaler.update()total_loss += loss.item() * rain.size(0)scheduler.step()train_loss = total_loss / len(train_set)# ---- val ----model.eval()val_loss = 0.0mse_sum, n_pix = 0.0, 0with torch.no_grad():for rain, clean, _ in val_loader:rain, clean = rain.to(device), clean.to(device)loss, rec = step(rain, clean, train=False)val_loss += loss.item() * rain.size(0)mse_sum += F.mse_loss(rec, clean, reduction='sum').item()n_pix += clean.numel()val_loss /= len(val_set)psnr = 10 * math.log10((1.0 ** 2) / (mse_sum / n_pix + 1e-12))print(f"[Finetune] Epoch {epoch+1}/{args.epochs} TrainLoss={train_loss:.4f} ValLoss={val_loss:.4f} PSNR={psnr:.2f}dB LR={scheduler.get_last_lr()[0]:.6e}")# 保存最好if psnr > best_psnr:best_psnr = psnrsave_checkpoint(args.save_path, model)print(f"=> Saved best to {args.save_path} (PSNR {best_psnr:.2f}dB)")# ---- 推理单图 ----
def run_predict(args):device = args.device if (args.device == "cpu" or torch.cuda.is_available()) else "cpu"model = MAE(img_size=args.img_size, mask_ratio=args.mask_ratio).to(device)load_any_state_dict(model, args.weights, strict=False) # 加载微调后的权重model.eval()to_tensor = transforms.Compose([transforms.Resize((args.img_size, args.img_size)),transforms.ToTensor()])img = Image.open(args.noisy_img).convert("RGB")inp = to_tensor(img).unsqueeze(0).to(device) # 0~1with torch.no_grad():pred, _ = model(inp, use_mask=False)rec = model.unpatchify(pred, args.img_size, args.img_size).clamp(0, 1)[0].permute(1, 2, 0).cpu().numpy()# 可视化fig, axes = plt.subplots(1, 2, figsize=(8, 4))axes[0].imshow(img.resize((args.img_size, args.img_size))); axes[0].set_title("Input (Rain/Noise/Blur)")axes[1].imshow(rec); axes[1].set_title("Clean (Reconstructed)")for ax in axes: ax.axis("off")os.makedirs(os.path.dirname(args.save_path) or ".", exist_ok=True)plt.tight_layout(); plt.savefig(args.save_path)print(f"=> Saved result to {args.save_path}")# =============================
# 主程序(argparse)
# =============================
def main():parser = argparse.ArgumentParser(description="MAE for Rain Removal / Denoising (Pretrain + Finetune + Predict)")# 通用parser.add_argument("--mode", type=str, choices=["pretrain", "finetune", "predict"],help="运行模式:pretrain(仅norain自监督)、finetune(配对监督)、predict(单图推理)",default="predict")parser.add_argument("--dataset_root", type=str, default="./Rain100L",help="数据集根目录,需包含 rain/ 与 norain/")parser.add_argument("--img_size", type=int, default=224, help="输入尺寸,应为patch倍数")parser.add_argument("--batch_size", type=int, default=16)parser.add_argument("--epochs", type=int, default=150)parser.add_argument("--lr", type=float, default=1.5e-4)parser.add_argument("--weight_decay", type=float, default=0.05)parser.add_argument("--warmup_epochs", type=int, default=3)parser.add_argument("--mask_ratio", type=float, default=0.8, help="MAE 掩码比例(预训练使用)")parser.add_argument("--seed", type=int, default=42)parser.add_argument("--workers", type=int, default=4)parser.add_argument("--amp", action="store_true", help="启用混合精度", default=True)parser.add_argument("--device", type=str, default="cuda", help="cuda 或 cpu")# 权重parser.add_argument("--init_weights", type=str, default="./checkpoints/mae_derain_best.pth", help="初始化权重路径(可加载外部MAE预训练)")parser.add_argument("--save_path", type=str, default="./checkpoints/mae_derain_best.pth", help="权重保存路径")parser.add_argument("--weights", type=str, default="./checkpoints/mae_derain_best.pth", help="predict 时加载的微调权重")# 微调损失parser.add_argument("--use_mask_in_finetune", action="store_true", help="微调阶段仍使用 MAE 掩码", default=False)parser.add_argument("--use_ssim", action="store_true", help="在微调损失中加入 SSIM", default=True)parser.add_argument("--ssim_lambda", type=float, default=0.1, help="SSIM 权重(loss += λ*(1-SSIM))")# predictparser.add_argument("--noisy_img", type=str, default="./test.png", help="predict 输入图像(雨/噪声/模糊)路径")parser.add_argument("--save_pred_vis", type=str, default="./vis/pred.png", help="predict 可视化保存路径")args = parser.parse_args()# 运行if args.mode == "pretrain":assert os.path.isdir(args.dataset_root), "请提供正确的 Rain100L 路径(包含 norain/)"run_pretrain(args)elif args.mode == "finetune":assert os.path.isdir(args.dataset_root), "请提供正确的 Rain100L 路径(包含 rain/ 与 norain/)"run_finetune(args)else:assert args.weights and os.path.exists(args.weights), "predict 需要提供训练好的权重 --weights"assert args.noisy_img and os.path.exists(args.noisy_img), "请提供待处理图片路径 --noisy_img"args.save_path = args.save_pred_vis # 复用变量名run_predict(args)if __name__ == "__main__":main()也是分为三个模式:
Pretrain (预训练) - 使用无标签的干净图像进行自监督学习Finetune (微调) - 使用配对数据(有雨图+干净图)进行监督学习Predict (预测) - 使用训练好的模型进行单张图像去雨处理预训练模式需要加载norain数据,微调模式加载全部数据(注意rain和norain文件夹的图片名需要一一配对),需要加载预训练权重进行初始化。预测模加载训练好的模型,处理单张雨雾图像,最后输出去雨结果和可视化对比。
需要使用代码对数据集进行配对的可以使用代码:此代码分别对rain和norain的图片名去掉标签。
import osdef rename_rain_files(folder_path):"""重命名rain文件夹中的文件,移除'rain-'前缀Args:folder_path (str): rain文件夹的路径"""# 获取文件夹中的所有文件files = os.listdir(folder_path)# 计数器,用于显示进度count = 0for filename in files:# 检查文件名是否以'rain-'开头且以'.png'结尾if filename.startswith('norain-') and filename.endswith('.png'):# 构建新文件名(移除'rain-'前缀)new_filename = filename.replace('norain-', '', 1)# 构建完整的文件路径old_filepath = os.path.join(folder_path, filename)new_filepath = os.path.join(folder_path, new_filename)# 重命名文件os.rename(old_filepath, new_filepath)count += 1print(f'重命名: {filename} -> {new_filename}')print(f'\n完成!共重命名了 {count} 个文件')# 使用方法
if __name__ == "__main__":# 替换为你的rain文件夹实际路径folder_path = r"Rain100L\norain" # Windows路径示例rename_rain_files(folder_path)最后,给大家看看重建效果:

我这里是使用vit_small_patch8_224版本的模型进行finetune200epoch。
MAE更多的功能等待大家去挖掘,以上为本文全部内容!