《C++哈希表:高效数据存储与检索的核心技术》


前引:在计算机科学中,高效的数据管理是系统性能的关键。哈希表(Hash Table)作为一种经典的数据结构,以其惊人的查找、插入和删除效率而闻名,平均时间复杂度可达$O(1)$。它通过巧妙的哈希函数将键(key)映射到存储位置,实现近乎即时的访问,广泛应用于数据库索引、缓存系统和编程语言实现中。然而,哈希表也面临冲突处理、负载因子控制等挑战。本文将带您从基础原理出发,逐步解析哈希表的设计、实现和优化策略,并通过实例代码帮助您掌握这一强大工具。无论您是初学者还是经验开发者,本指南都将助您提升数据处理能力!
声明:本文涉及到哈希切割、位图、布隆过滤器会在后面的算法中详解
目录
【一】哈希表源由
【二】线性哈希表
【三】线性哈希讲解
【一】结构详解
(1)枚举
(2)节点
(3)哈希结构
【二】插入详解
完整代码
【三】查找详解
完整代码
【四】删除详解
完整代码
【四】哈希桶
【五】哈希桶讲解
【一】结构详解
(1)节点结构
(2)哈希结构
【二】插入详解
完整代码
【三】查找详解
完整代码
【四】删除详解
完整代码
【一】哈希表源由
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素 时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即 O($log_2 N$),搜索的效率取决于搜索过程中元素的比较次数。 理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。 如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立 一一映射的关系,那么在查找时通过该函数可以很快找到该元素!(总结:对映射关系的改进)
插入元素:根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放
搜索元素:对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置 取元素比较,若关键码相等,则搜索成功
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称 为哈希表(Hash Table)(或者称散列表)
哈希表有两种高效的存储方式:线性+哈希桶
【二】线性哈希表
例如存在几个数据Key:20,26,34,29,10,35。假设存储元素的总大小capacity为:10
注意:vector是根据下标size访问元素的,后面我们要用resize将size变为capacity大小
存储公式为:Key % capacity = 存储下标
例如:
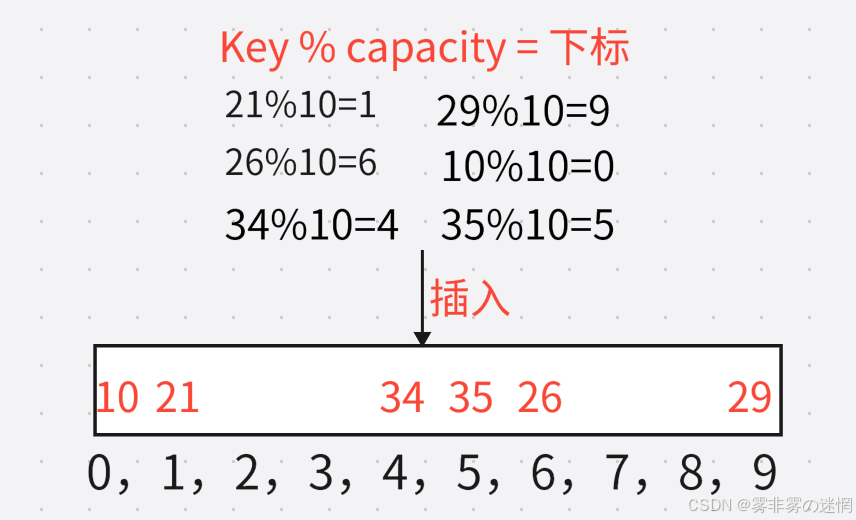
例如:

但是这样的话我们发现有特殊情况:
如果两个Key经过转化得到相同的存储位置?例如:54和34 % 10 =4
此时我们需要根据存储位置判断是否可以存:如果这个位置为空,就存;否则就考虑扩容,例如:

但是通过查找删除这个位置的值之后呢?删除的位置不能为空,但它可以存储数据,这样就很冲突,于是我们根据三种状态去判断:存在、空、删除
【三】线性哈希讲解
【一】结构详解
(1)枚举
枚举结构主要用来存储变量的三种状态:存在、空、删除
enum State
{//空vacuum,//删除eliminate,//存在existence
};(2)节点
哈希的存储是顺序存储,所有我们不需要用链表的形式去连接,直接用容器:vector
//节点结构
template<class T,class V>
struct Node
{//数据pair<T, V> dict;//状态enum State state = vacuum;
};(3)哈希结构
//Ha_Sh结构
template<class T,class V>
class Ha_Sh
{
public:Ha_Sh(){_table.resize(10);}private://哈希存储vector<Node<T, V>> _table;//数据有效个数int size = 0;
};【二】插入详解
(1)按照逻辑顺序,我们需要计算插入的下标:key % _table.size()
//计算插入下标
int val = date.first % _table.size();(2)开始插入:如果遇到状态为“存在”就继续向前走
int sum = date.first;
//循环找位置
while (_table[val].state == existence)
{//更新下标val = (++sum) % _table.max_size();
}
//插入
_table[val].dict = date;
_table[val].state = existence;
size++;(3)哈希强调的是效率,如果空间利用率达到100%,那么越往后元素冲突率越大,所有我们需要来控制空间利用率(一般负载因子控制 < 0.75)。当大于0.75,说明需要扩容了。扩容之后肯定要转移元素,而这个判断应该发生在插入之前
//计算负载因子(0.75)
double factor = (double)size / _table.size();
//准备扩容
if (factor > 0.75)
{vector<Node<T, V>> table(2 * _table.size());//转移元素for (int i = 0; i < _table.size(); i++){if (_table[i].state == existence){table[i] = _table[i];}}_table.swap(table);
}(4)对于下标的计算我们需要修改一下,借助仿函数来完成:
如果这个数据不是整型我们需要修改为整型,比如string
如果是整型直接返回无符号的整型(否则有符号取模会出错),这里用到了一种算法去重
(各种字符串Hash函数 - clq - 博客园http://www.cnblogs.com/atlantis13579/archive/2010/02/06/1664792.htmlhttp://blog.csdn.net/icefireelf/article/details/5796529 字符串Hash函数对比 分类: 数据结构与算法 20
https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html)
//取整
template<class T>
struct HaShiFunc
{//如果是整型const size_t operator()(const T& date){return size_t(date);}
};
//字符型(特化)
template<>
struct HaShiFunc<string>
{const size_t operator()(const string& date){size_t _date = 0;for (auto e : date){//去重算法_date *= 131;_date += e;}return _date;}
};
完整代码
//插入
bool insert(const pair<T, V>& date)
{HashFunc Hash;//计算平衡因子(0.75)double factor = double(Hash(size)) / _table.size();//准备扩容if (factor > 0.75){vector<Node<T, V>> table(2 * _table.size());//转移元素for (int i = 0; i < _table.size(); i++){if (_table[i].state == existence){table[i] = _table[i];}}_table.swap(table);}//计算插入下标size_t val = Hash(date.first) % _table.size();int sum = date.first;//循环找位置while (_table[val].state == existence){//更新下标val = (++sum) % _table.max_size();}//插入_table[val].dict = date;_table[val].state = existence;size++;return true;
}【三】查找详解
查找我们暂时返回当前位置的哈希数据结构(值+状态)
注意:可以把 Key 值封装一下,防止修改
查找思路:根据映射下标去绕圈似的查找,如果找到空状态依旧没有找到就返回空指针
完整代码
Node<const T, V>* Find(const T& date)
{HashFunc Hash;size_t num = Hash(date) % _table.size();while (_table[num].state != eliminate){if (_table[num].state==existence && _table[num].dict.first == date){return (Node<const T,V>*) & _table[num];}num++;num%= _table.size();}return nullptr;
}【四】删除详解
思路:利用查找返回该位置的节点指针,直接修改状态值,以此避免直接删除节点导致映射混乱
完整代码
//删除
bool Erase(const T& date)
{Node<const T, V>* node = Find(date);//如果找到了,就修改状态if (node){node->state = eliminate;return true;}return false;
}【四】哈希桶
哈希桶与线性哈希结构有相似地方,不过是存储的结构体指针(类似链表),采用单链表存储
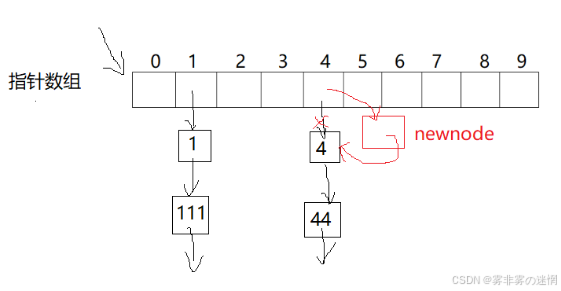
【五】哈希桶讲解
【一】结构详解
(1)节点结构
//节点结构
template<class T, class V>
struct Node
{Node(const pair<T, V>& date):dict(date){ }//数据pair<T, V> dict;//下一个节点Node<T, V>* _next = nullptr;
};(2)哈希结构
vector里面换成了指针,形成链表形式
//Ha_Sh结构
template<class T, class V, class HashFunc = HaShiFunc<T>>
class Ha_Sh
{
public:typedef Node<const T, V> Node;Ha_Sh(){_table.resize(5);}~Ha_Sh(){Node* cur = nullptr;Node* next = nullptr;for (int i = 0; i < _table.size(); i++){cur = _table[i];while (cur){next = cur->_next;//释放curdelete cur;cur = next;}_table[i] = nullptr;}size = 0;}private://哈希存储vector<Node*> _table;//数据有效个数size_t size = 0;
};【二】插入详解
仿函数还是不变用来除数取整:
//取整
template<class T>
struct HaShiFunc
{//如果是整型const size_t operator()(const T& date){return size_t(date);}
};
//字符型(特化)
template<>
struct HaShiFunc<string>
{const size_t operator()(const string& date){size_t _date = 0;for (auto e : date){_date *= 131;_date += e;}return _date;}
};通过链表头插的方法来完成新增节点:
//计算下标
size_t val = Hash(date.first) % _table.size();
Node* _date = new Node(date);
//头插
_date->_next = _table[val];
_table[val] = _date;
size++;哈希桶我们的负载因子设置为1就考虑扩容:
注意:扩容转移节点时需要重新插入每一个接地那
HashFunc Hash;
//负载因子是否为1
if (size == _table.size())
{vector<Node*> newtable(_table.size() * 2, nullptr);Node* cur = nullptr;Node* next = nullptr;//重新映射for (int i = 0; i < _table.size(); i++){cur = _table[i];while (cur){next = cur->_next;size_t val = Hash(cur->dict.first) % newtable.size();//头插cur->_next = newtable[val];newtable[val] = cur;//下一个节点cur = next;}_table[i] = nullptr;}_table.swap(newtable);
}完整代码
//插入
bool insert(const pair<T, V>& date)
{HashFunc Hash;//负载因子是否为1if (size == _table.size()){vector<Node*> newtable(_table.size() * 2, nullptr);Node* cur = nullptr;Node* next = nullptr;//重新映射for (int i = 0; i < _table.size(); i++){cur = _table[i];while (cur){next = cur->_next;size_t val = Hash(cur->dict.first) % newtable.size();//头插cur->_next = newtable[val];newtable[val] = cur;//下一个节点cur = next;}_table[i] = nullptr;}_table.swap(newtable);}//计算下标size_t val = Hash(date.first) % _table.size();Node* _date = new Node(date);//头插_date->_next = _table[val];_table[val] = _date;size++;return true;
}【三】查找详解
通过计算下标从头节点开始找,开始遍历单链表,如果没有说明不存在
完整代码
//查找
Node* Find(const T& date)
{if (size == 0){return nullptr;}//计算下标size_t val = Hash(date) % _table.size();//遍历链表Node* cur = _table[val];while (cur){if (cur->dict.first == date){return cur;}cur = cur->_next;}return nullptr;
}【四】删除详解
通过Find查找目标位置,设置一个前驱指针找到目标节点的前一个位置,开始连接
注意:可能是头删
完整代码
//删除
bool Erase(const T& date)
{Node* cur = Find(date);if (cur){HashFunc Hash;size_t val = Hash(date) % _table.size();Node* sum = _table[val];for (int i = 0; i < _table.size(); i++){//如果删的是头if (cur == sum){_table[i] = cur->_next;break;}//删中间节点while (sum->_next && sum->_next->dict.first != date){sum = sum->_next;}if (sum->_next && sum->_next->dict.first == date){sum->_next = cur->_next;break;}}delete cur;size--;return true;}return false;
}