基于RFM模型的客户群体大数据分析及用户聚类系统的设计与实现
文章目录
- ==有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主==
- 项目介绍
- 一、项目背景
- 二、系统总体设计
- 三、核心功能模块
- 1. 数据采集与预处理
- 2. RFM 模型构建
- 3. 聚类算法应用
- 4. 数据可视化分析
- 5. 用户与管理员模块
- 四、系统实现亮点
- 五、应用价值
- 六、总结
- 每文一语
有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主
项目介绍
一、项目背景
在数字化经济快速发展的时代,电子商务行业的规模与影响力持续扩大。随着消费者行为的全面线上化,企业积累了庞大的交易数据,这些数据不仅包含时间、金额、渠道等基本信息,还隐含了客户行为模式、消费习惯以及潜在价值。然而,数据的价值能否真正转化为企业的竞争优势,取决于企业是否具备有效的数据分析与客户价值管理能力。
传统的客户分析方法往往依赖单一指标,例如消费金额或购买频率。这种片面化的评估方式无法全面刻画客户价值,容易导致营销策略失准。为了实现客户的科学分群与精准营销,企业需要借助更加系统化和智能化的分析方法。
RFM 模型作为一种经典的客户价值评估工具,能够通过 最近一次购买时间(Recency)、购买频率(Frequency)、购买金额(Monetary) 三个维度综合衡量客户价值,为客户细分提供直观依据。然而,传统 RFM 模型通常依赖人工设定分值区间,划分结果具有一定主观性,难以反映客户真实差异。随着大数据和机器学习的发展,将 RFM 模型与聚类算法结合,成为客户价值分析的前沿方向。
在这一背景下,本项目基于 RFM 模型与无监督学习聚类算法,设计并实现了一个 客户群大数据分析系统。该系统不仅能够完成数据采集、清洗、存储和可视化,还集成了 K-means 聚类与 MiniBatchK-means 算法,在避免主观划分偏差的同时,实现更加精准的客户群体细分。系统前端采用 Layui 框架,后端基于 Flask 开发,数据库使用 MySQL,并通过 Pyecharts 实现数据的可视化分析。最终形成一个面向企业用户与管理员的综合平台,既支持客户群体分析,也提供了数据管理与权限控制功能。
二、系统总体设计
本系统采用 前后端分离架构,整体设计分为四个层次:
- 数据层:负责存储和管理客户交易数据,采用 MySQL 关系型数据库,保证数据的高效存取与一致性。
- 模型层:实现 RFM 指标计算、规则打分及聚类建模,支持 RFM + K-means 的混合分析模式。
- 业务逻辑层:以 Flask 框架为核心,负责用户认证、数据处理、接口调用等功能,实现对管理员和普通用户的不同角色支持。
- 表现层:前端采用 Layui 和 Ajax,实现交互式界面与数据调用;可视化部分使用 Pyecharts 输出 HTML 图表并嵌入系统前端,实现直观的数据展示。
这种架构设计既保证了系统的扩展性,又提高了响应效率。RFM 模型与聚类算法的结合,使得系统能够提供从简单规则划分到智能聚类的多层次分析结果,既适合中小企业快速应用,也满足大规模数据场景下的性能需求。
三、核心功能模块
1. 数据采集与预处理
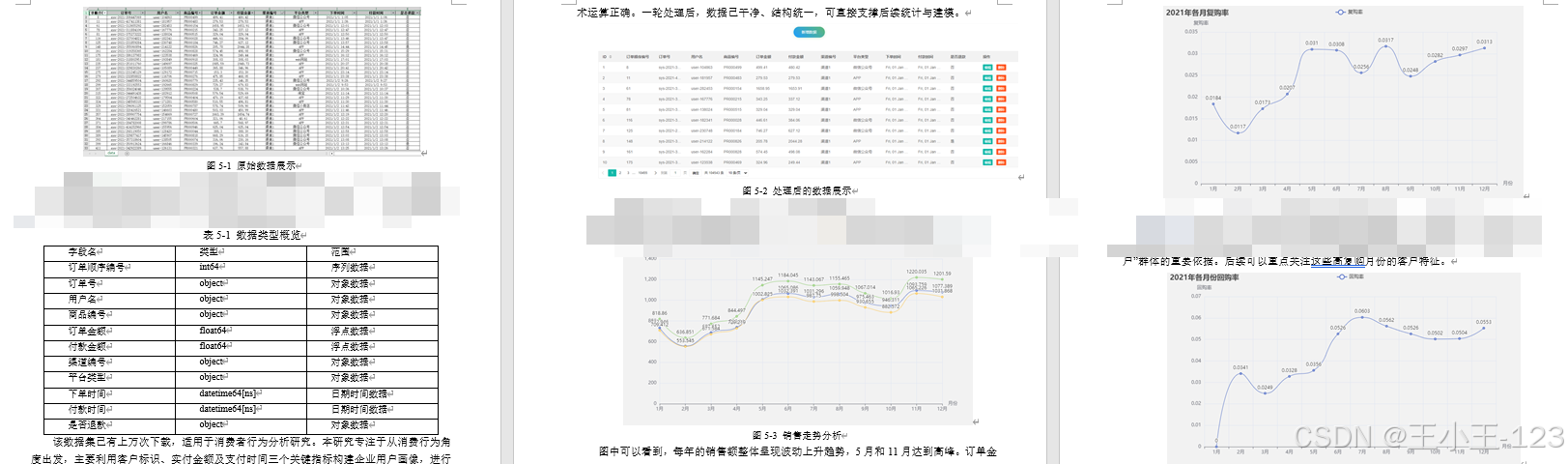
系统通过开源电商交易数据集(如和鲸数据平台)获取客户订单记录,包括订单编号、用户 ID、商品编号、订单金额、付款金额、渠道、平台类型、时间戳及退款状态等字段。数据导入后,利用 Pandas 进行预处理,具体包括:
- 重复值处理:删除完全重复的订单记录;
- 缺失值处理:剔除缺失字段较多的行,确保数据完整性;
- 异常值处理:过滤付款金额为负值或极端不合理值;
- 数据类型转换:将金额转为浮点型,时间转为 datetime 类型,保证运算与可视化准确性。
最终,清洗后的数据存储在 MySQL 数据库中,既利于后续模型调用,也便于系统的统一管理。
2. RFM 模型构建
在数据预处理完成后,系统基于订单数据计算 RFM 三个核心指标:
- Recency(R):用户最近一次交易距今的天数;
- Frequency(F):用户在统计周期内的交易次数;
- Monetary(M):用户在统计周期内的消费总额。
通过 Pandas 聚合函数完成指标计算,并生成客户-指标表。随后,基于规则打分法,将每个指标划分为高低分区间,组合生成 8 类客户群体,如“重要价值客户”“潜力客户”“一般保持客户”等。这一方法直观易懂,但带有一定的主观性。
3. 聚类算法应用
为了克服主观划分的不足,系统进一步引入了 K-means 聚类与其高效变体 MiniBatchK-means。
- 数据标准化:使用 StandardScaler 将 R、F、M 转换为均值为 0、方差为 1 的标准分布,避免量纲差异影响聚类效果。
- 聚类数确定:通过 肘部法则与轮廓系数综合判断,确定最佳聚类数。
- 聚类实现:利用 scikit-learn 的 KMeans 与 MiniBatchKMeans 库进行建模,并为每位客户打上聚类标签。
聚类结果通过箱型图、直方图等方式可视化解释,每个聚类群体都具备明确的消费行为特征。例如:
- “核心价值型”:近期活跃、频繁消费、高额贡献;
- “潜力培养型”:新近购买,但消费频次与金额较低;
- “重要唤回型”:曾高消费但近期沉默,需召回激励。
这种方法实现了客户群体的客观划分,提高了细分的科学性。
4. 数据可视化分析
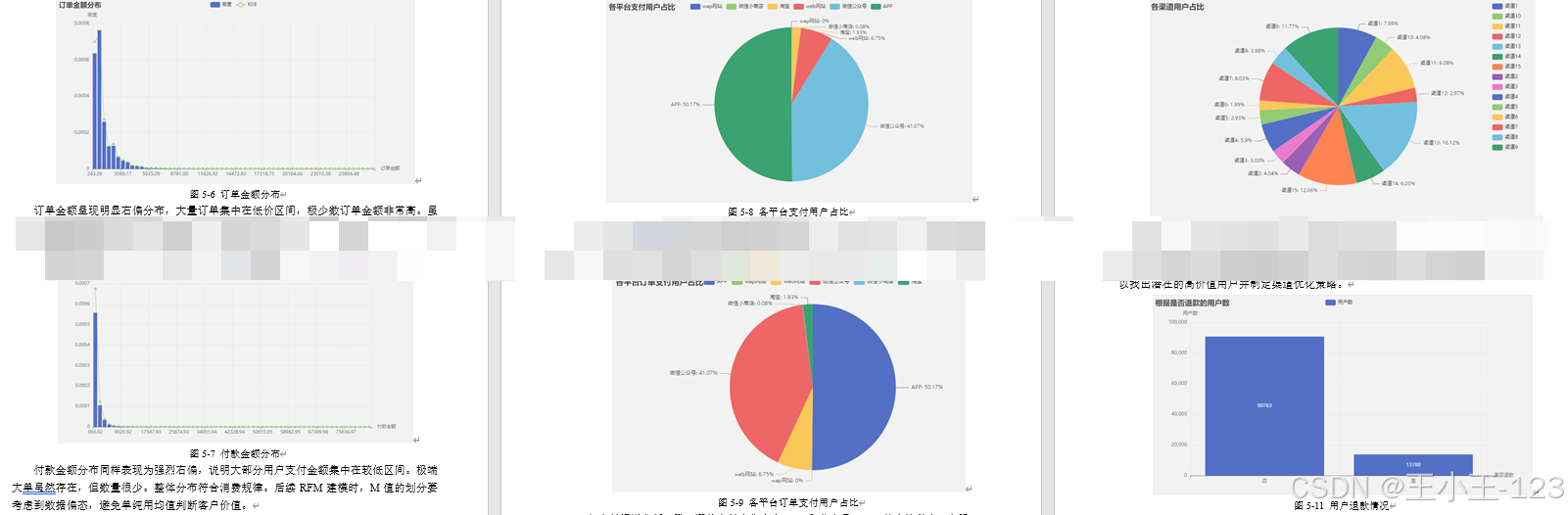
系统通过 Pyecharts 将分析结果转化为交互式图表,主要展示内容包括:
- 销售趋势图:展示不同月份的交易额变化;
- 复购率与回购率分析:反映客户黏性与忠诚度;
- 订单金额与付款金额分布:揭示消费层次差异;
- 支付渠道与平台占比:反映客户使用习惯;
- 聚类结果展示:通过散点图与箱型图解释不同客户群体特征。
所有图表以 HTML 形式导出并嵌入前端界面,支持缩放、提示框交互,用户能够直观理解数据规律。
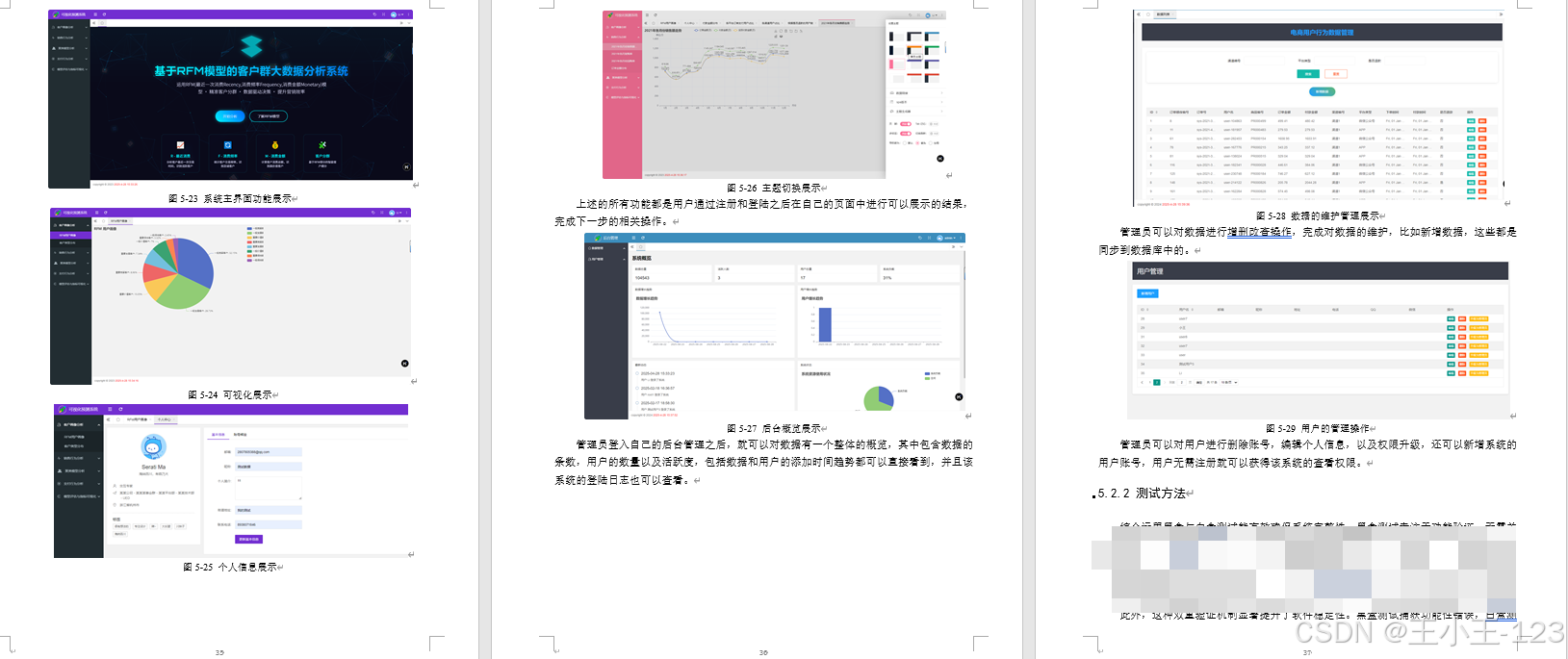
5. 用户与管理员模块
- 用户模块:支持注册、登录、修改个人信息与密码。用户可查看基于 RFM 与聚类的客户群体划分结果,以及相应的可视化图表。
- 管理员模块:除基本登录外,还可执行对用户的增删改查、权限升级,以及对数据的新增、修改、删除和查询。同时,后台首页提供整体概览,包括用户数、数据量、近期趋势和登录日志等。
四、系统实现亮点
- 方法融合:结合传统 RFM 规则打分与 K-means 聚类算法,实现从主观划分到数据驱动的智能细分。
- 高效处理:通过 MiniBatchK-means 提升大数据场景下的聚类效率,兼顾速度与精度。
- 前后端分离:Flask 提供 RESTful 接口,前端 Layui 与 Ajax 渲染页面,保证系统结构清晰、扩展性强。
- 可视化直观:所有分析结果均以图表方式呈现,支持用户快速理解客户群体特征。
- 易用与维护:MySQL 数据库结构直观,管理员可通过 Web 界面完成数据与用户管理,降低维护成本。
五、应用价值
- 对企业的价值
- 精准识别高价值客户,制定差异化营销策略;
- 提供科学的客户分群依据,优化资源配置;
- 通过可视化结果支持产品开发、促销活动与库存管理决策。
- 对客户的价值
- 提供个性化的服务与产品推荐,提升客户满意度;
- 通过客户群体划分改善用户体验,增加客户黏性。
- 对行业的意义
本项目为 RFM 模型与聚类算法在电商领域的融合应用提供了实践案例,展示了大数据与机器学习在客户关系管理中的落地方式。该方法论同样适用于零售、金融、电信等行业,具备较强的推广价值。
六、总结
本项目围绕 RFM 模型与无监督学习聚类算法,设计并实现了一个 客户群大数据分析系统。系统从数据采集、清洗到 RFM 建模,再到聚类细分与可视化展示,形成了完整的分析流程。通过 Flask 与 MySQL 的后端实现,结合前端 Layui 与 Pyecharts 的可视化展示,项目实现了用户与管理员双角色支持,满足了客户群体分析的实际需求。
与传统单一的 RFM 模型相比,本项目通过机器学习算法提升了客户群体划分的客观性与精确性;与现有商业平台相比,本系统成本低、可扩展、适用性强,特别适合中小企业应用。未来,随着实时数据流处理与更多算法的引入,该系统将进一步拓展功能,向智能化客户关系管理平台迈进。

每文一语
既然花了时间 就要过一次眼和脑 不管是否可以记忆