【数据结构】栈和队列——队列
目录
- 队列
- 队列的基本概念
- 顺序队列
- 顺序队列的定义与初始化
- 顺序队列的入队/出队
- 顺序队列的判空/判满
- 获取队头元素
- 循环队列
- 循环队列的概念
- 循环队列的状态判断
- 循环队列的定义
- 循环队列的初始化
- 循环队列的判空操作
- 循环队列的判满操作
- 循环队列的入队操作
- 循环队列的出队操作
- 获取队头元素
- 链式队列
- 链式队列的概念
- 链式队列的定义
- 链式队列的初始化
- 链式队列的判空操作
- 链式队列的入队操作
- 链式队列的出队操作
队列
队列的基本概念
队列的定义:
- 队列(Queue)是一种受限制的线性表。
- 特点是:先进先出(FIFO, First In First Out)。
- 元素只能在 队尾(rear) 插入。
- 元素只能在 队头(front) 删除。
可以想象一下:就像你排队买票,先到的人先买,后到的人只能排在后面,不能插队。
队列的基本操作:
- 初始化队列:创建一个空队列。
- 入队(EnQueue):新元素加入到队尾。
- 出队(DeQueue):删除队头的元素,并返回它。
- 取队头元素(GetFront):只读取队头的元素,但不删除。
- 判空(IsEmpty):判断队列里是否还有元素。
- 判满(IsFull)(针对顺序存储的队列):判断队列是否已满。
队列的分类:
- 顺序队列:用数组实现,队头队尾用下标表示。
- 缺点:出队时会产生“假溢出”现象(队头不断右移,空间浪费)。
- 链式队列:用链表实现,动态分配内存,不存在“溢出”,更灵活。
- 循环队列:对顺序队列的改进,把数组头尾“连成环”,解决假溢出问题。
- 公式:
(rear + 1) % MaxSize == front表示队满。
- 公式:
**图示理解:**假设队列最多能存放 5 个元素:
初始:front=0, rear=0, 队列空
[ ] [ ] [ ] [ ] [ ] 入队 A:rear=1
[A] [ ] [ ] [ ] [ ] 入队 B:rear=2
[A] [B] [ ] [ ] [ ] 出队(删除 A):front=1
[ ] [B] [ ] [ ] [ ] 入队 C:rear=3
[ ] [B] [C] [ ] [ ] 依次进行……
为什么顺序存储一定会“溢出”?
顺序存储结构(顺序表、顺序队列、顺序栈…)的特点是:
👉 用一块 连续的内存空间 来保存数据。定义时必然有一个
MaxSize(不管是静态数组还是动态malloc出来的数组)。插入/入队/入栈超过
MaxSize时,就会发生 溢出。即使用
realloc扩容,本质上还是“再申请更大的一块连续空间 → 搬数据”,最终也受系统内存限制。为什么链式存储不会“假溢出”?
链式存储结构(链表、链式队列、链式栈…)的特点是:
👉 每个结点通过 指针域 连接到下一个结点。不需要一块连续的内存,理论上只要能
malloc出一个新结点,就能继续插入。所以它没有固定的
MaxSize,也不会产生“假溢出”问题。系统层面的最终约束
不管是 顺序存储 还是 链式存储:
如果内存耗尽(比如系统没有空闲空间再给你
malloc结点 / 数组),都会失败。区别在于:
顺序存储:即使内存够,但你的
MaxSize限死了容量 → 提前溢出。链式存储:只要内存够,就能继续扩展,没有人为的
MaxSize。总结一句话 ✅
顺序存储类(顺序表/队列/栈):因为有
MaxSize,会溢出;链式存储类(链表/链式队列/链式栈):没有固定上限,只要内存够就能继续;
但 最终大家都受系统内存限制,内存不足时都会“溢出”。
顺序队列
顺序队列是用 数组 来实现的队列。
特点:
- 使用数组连续存储元素
- 有两个指标:
front:队头位置rear:队尾下一个空位位置
注意:这里 rear 指向的是 下一个可插入元素的位置,不是队尾元素的位置。
- 判断队空和队满:
- 队空:
front == rear - 队满(顺序队列固定大小):
rear == maxsize
- 队空:
- 固定大小顺序队列可能会出现“假溢出”:数组还有空位,但由于前面有元素出队,rear到达数组末尾也会认为队满。
顺序队列的定义与初始化
顺序队列的定义:
#define MAXSIZE 100typedef struct {int data[MAXSIZE]; // 存储元素int front; // 队头int rear; // 队尾下一个位置
} SqQueue;
这部分定义了一个结构体SqQueue(通常表示 “顺序队列”,Sequential Queue),用于描述队列的存储结构,包含 3 个成员:
int data[MAXSIZE]:一个 int 类型的数组,用于实际存储队列中的元素,数组大小由MAXSIZE指定(即最多可存储 100 个 int 元素)。int front:表示 “队头指针”,记录队列中第一个元素的位置(索引)。通过front可以快速获取队头元素。int rear:表示 “队尾指针的下一个位置”,记录队列中最后一个元素的下一个空闲位置(索引)。当有新元素入队时,会将元素存放在rear指向的位置,再更新rear。
顺序队列的初始化:
void InitQueue(SqQueue *Q) {Q->front = 0;Q->rear = 0;
}
Q->front = 0;:将队列的队头指针front初始化为 0(指向数组的起始索引)。Q->rear = 0;:将队列的队尾指针rear也初始化为 0(同样指向数组的起始索引)。
顺序队列的入队/出队
入队操作:
int EnQueue(SqQueue *Q, int e) {if(Q->rear == MAXSIZE) // 队满return 0;Q->data[Q->rear] = e;Q->rear++;return 1;
}
- 函数定义:
int EnQueue(SqQueue *Q, int e)- 返回值类型为
int:通常用1表示入队成功,0表示入队失败(队列已满)。 - 参数
SqQueue *Q:指向队列结构体的指针,用于操作目标队列(通过指针修改队列的实际数据)。 - 参数
int e:要插入队列的元素(int 类型)。
- 返回值类型为
- 核心逻辑:
- 第一步(判断队列是否已满):
if(Q->rear == MAXSIZE) return 0;
检查队尾指针rear是否等于最大容量MAXSIZE。由于rear表示 “队尾元素的下一个位置”,当rear达到MAXSIZE时,说明数组data已被填满(没有空闲位置),此时队列已满,无法插入新元素,返回0表示失败。 - 第二步(插入元素):
Q->data[Q->rear] = e;
若队列未满,将元素e存入data数组中rear指向的位置(即当前队尾的下一个空闲位置)。 - 第三步(更新队尾指针):
Q->rear++;
插入元素后,将rear指针向后移动一位(指向新的队尾下一个位置),为下一次入队做准备。 - 第四步(返回成功标识):
return 1;
入队操作完成,返回1表示成功。
- 第一步(判断队列是否已满):
出队操作:
int DeQueue(SqQueue *Q, int *e) {if(Q->front == Q->rear) // 队空return 0;*e = Q->data[Q->front];Q->front++;return 1;
}
- 函数定义:
int DeQueue(SqQueue *Q, int *e)- 返回值类型为
int:用1表示出队成功,0表示出队失败(队列已空)。 - 参数
SqQueue *Q:指向队列结构体的指针,用于操作目标队列。 - 参数
int *e:一个 int 类型的指针,用于 “传出” 被删除的队头元素(通过指针可以将函数内部的值传递到函数外部)。
- 返回值类型为
- 核心逻辑:
- 第一步(判断队列是否为空):
if(Q->front == Q->rear) return 0;
检查队头指针front是否等于队尾指针rear。根据队列约定,当两者相等时表示队列为空(没有元素可删除),此时返回0表示出队失败。 - 第二步(获取并传出队头元素):
*e = Q->data[Q->front];
若队列非空,将front指向的队头元素(data[front])赋值给指针e指向的变量(即通过e将队头元素 “带出去” 给函数调用者)。 - 第三步(更新队头指针):
Q->front++;
删除队头元素后,将front指针向后移动一位(指向新的队头元素),完成出队操作。 - 第四步(返回成功标识):
return 1;
出队操作完成,返回1表示成功。
- 第一步(判断队列是否为空):
顺序队列的判空/判满
判空操作:
// 判断队空
int QueueEmpty(SqQueue *Q) {return Q->front == Q->rear;
}
- 函数定义:
int QueueEmpty(SqQueue *Q)- 返回值类型为
int:在 C 语言中,通常用1表示 “真”(队列为空),0表示 “假”(队列非空)。 - 参数
SqQueue *Q:指向队列结构体的指针,用于访问队列的front和rear指针。
- 返回值类型为
- 核心逻辑:
函数体只有一行:return Q->front == Q->rear;- 表达式
Q->front == Q->rear用于判断 “队头指针” 和 “队尾指针” 是否指向同一个位置。 - 根据队列的约定(结合之前的初始化、入队、出队逻辑):当
front和rear相等时,队列中没有任何元素(为空);当两者不相等时,队列中至少有一个元素(非空)。 - 该表达式的结果是一个 “布尔值”:若相等则为
1(真),表示队空;若不相等则为0(假),表示队列非空。
- 表达式
判满操作:
// 判断队满
int QueueFull(SqQueue *Q) {return Q->rear == MAXSIZE;
}
- 函数定义:
int QueueFull(SqQueue *Q)- 返回值类型为
int:在 C 语言中,通常用1表示 “真”(队列已满),0表示 “假”(队列未满)。 - 参数
SqQueue *Q:指向队列结构体的指针,用于访问队列的rear指针和最大容量MAXSIZE。
- 返回值类型为
- 核心逻辑:
函数体只有一行:return Q->rear == MAXSIZE;- 表达式
Q->rear == MAXSIZE用于判断 “队尾指针的下一个位置” 是否已达到队列的最大容量(MAXSIZE)。 - 根据之前的入队逻辑(
EnQueue函数),rear始终指向队尾元素的下一个空闲位置,且每次入队后rear会递增(rear++)。因此,当rear等于MAXSIZE时,意味着数组data的所有位置(0到MAXSIZE-1)都已被元素占用,没有空闲空间可供新元素插入 —— 即队列已满。 - 该表达式的结果为 “布尔值”:若相等则返回
1(真,表示队满);若不相等则返回0(假,表示队列未满)。
- 表达式
获取队头元素
获取队头操作:
// 获取队头元素
int GetHead(SqQueue *Q, int *e) {if (QueueEmpty(Q)) return 0;*e = Q->data[Q->front];return 1;
}
- 函数定义:
int GetHead(SqQueue *Q, int *e)- 返回值类型为
int:用1表示获取成功(队列非空),0表示获取失败(队列为空)。 - 参数
SqQueue *Q:指向队列结构体的指针,用于访问队列的元素和指针。 - 参数
int *e:int 类型的指针,用于 “传出” 获取到的队头元素(通过指针将队头元素的值传递给函数外部)。
- 返回值类型为
- 核心逻辑:
- 第一步(判断队列是否为空):
if (QueueEmpty(Q)) return 0;
调用之前定义的QueueEmpty函数判断队列是否为空。若队空(front == rear),则没有队头元素可获取,返回0表示失败。 - 第二步(获取队头元素并传出):
*e = Q->data[Q->front];
若队列非空,直接读取front指针指向的元素(data[front],即队头元素),并通过指针e将其值传递给外部变量。 - 第三步(返回成功标识):
return 1;
成功获取队头元素后,返回1表示操作成功。
- 第一步(判断队列是否为空):
队列状态:
- 队空:
front == rear - 队满(固定大小顺序队列):
rear == MAXSIZE
⚠️ 注意:顺序队列在多次入队出队后,前面出队留下的空间不会自动利用,所以容易“假溢出”。
动态顺序队列:
如果用 malloc 动态分配数组,就可以避免固定大小队列的溢出问题:
- 当队尾到达数组末尾但队头有空位时,可以 搬移元素 或 扩容数组
- 使用循环队列(Circular Queue)可以更高效利用空间
循环队列
顺序队列有个大问题就是会出现 “假溢出” ——明明数组前面有空位置,但 rear 到了末尾就不能再入队了。
👉 为了解决这个问题,就出现了 循环队列(Circular Queue)。
循环队列的概念
循环队列就是把顺序队列的存储空间 看成一个环形,利用取模运算 (mod) 让 front 和 rear 在数组末尾能“绕回”开头,循环使用存储空间。
指针变化:
- 队头指针
front:指向队头元素 - 队尾指针
rear:指向 下一个要插入的位置
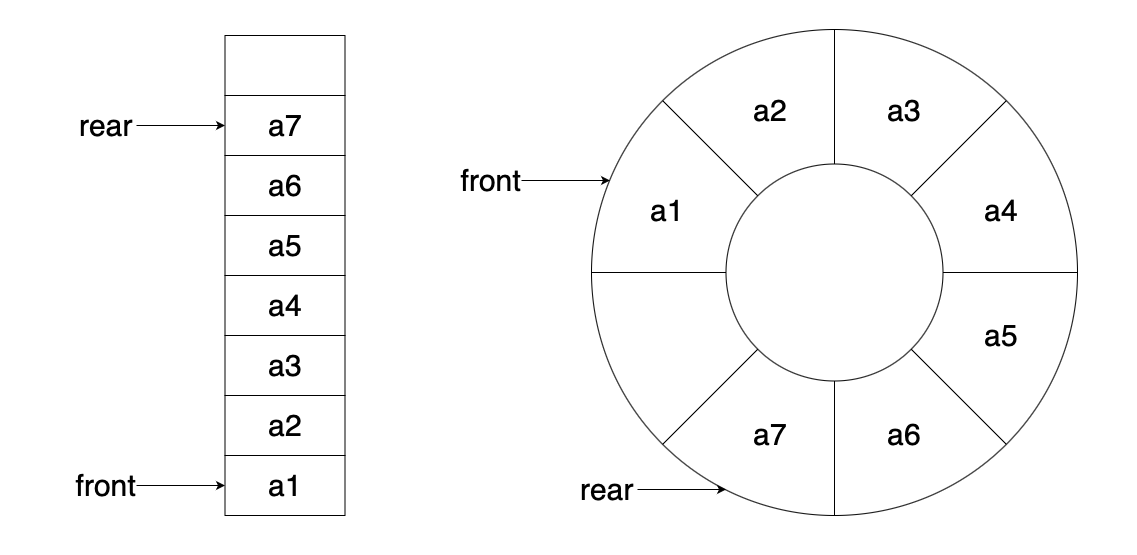
虽然循环队列可以看成环形,但实际上仍然是一个顺序结构
循环队列的状态判断
为了避免 front == rear 同时表示队满和队空的问题,通常采用两种方法之一:
- 少用一个存储单元(最常用)
- 队空:
front == rear - 队满:
(rear + 1) % MaxSize == front
这样最多只能存MaxSize - 1个元素。
- 队空:
- 增加一个计数器
- 用一个变量记录队列中元素的数量
- 队空:
size == 0 - 队满:
size == MaxSize
循环队列的定义
#define MAXQSIZE 100 // 最大队列长度typedef int QElemType; // 这里可以根据需要定义成int/char/struct等typedef struct {QElemType *base; // 存储空间的基址(动态分配)int front; // 队头指针,指向队头元素int rear; // 队尾指针,指向队尾元素的下一个位置
} SqQueue;
QElemType *base:
一个指向QElemType类型的指针,用于指向队列元素的存储空间(通常是动态分配的数组)。“基址” 表示这个指针指向整个存储空间的起始位置。int front:
队头指针(此处用整数表示数组索引),指向队列中第一个元素的位置。int rear:
队尾指针(同样用整数表示数组索引),指向队列中最后一个元素的下一个位置(即下一个入队元素将要存放的位置)。
循环队列的初始化
// 初始化队列
int InitQueue(SqQueue *Q) {Q->base = (QElemType *)malloc(MAXQSIZE * sizeof(QElemType));if (!Q->base) exit(0); // 分配失败Q->front = Q->rear = 0;return 1;
}
函数定义:int InitQueue(SqQueue *Q)
- 函数名
InitQueue:表示 “初始化队列”(Initialize Queue)。 - 参数
SqQueue *Q:传入队列结构体的指针,用于操作具体的队列实例(通过指针修改原队列的成员)。 - 返回值
int:通常用1表示初始化成功,0表示失败(此处成功返回1,失败直接退出程序)。
函数内部逻辑:
- 分配存储空间
Q->base = (QElemType *)malloc(MAXQSIZE * sizeof(QElemType));malloc函数动态分配一块内存,大小为MAXQSIZE * sizeof(QElemType):MAXQSIZE是队列最大长度(之前定义的 100);sizeof(QElemType)是单个元素的字节大小(由QElemType类型决定,如int占 4 字节)。
- 分配的内存用于存储队列元素,将其首地址强制转换为
QElemType*类型后,赋值给队列的base成员(即指向存储空间的基址)。
- 检查内存分配是否成功
if (!Q->base) exit(0); // 分配失败- 如果
malloc分配内存失败,会返回NULL,此时Q->base为NULL(!Q->base为真)。 - 遇到这种情况,调用
exit(0)直接终止程序(实际开发中可能更优雅地返回错误码,此处简化处理)。
- 如果
- 初始化队头和队尾指针
Q->front = Q->rear = 0;- 初始化时队列是空的,因此将
front(队头指针)和rear(队尾指针)都设置为0(指向数组的起始位置)。 - 在顺序队列中,
front == rear是 “队列空” 的判断条件。
- 初始化时队列是空的,因此将
- 返回成功标志
return 1;- 所有初始化操作完成后,返回
1表示队列初始化成功。
- 所有初始化操作完成后,返回
循环队列的判空操作
// 队空
int QueueEmpty(SqQueue Q) {return Q.front == Q.rear;
}
函数定义:int QueueEmpty(SqQueue Q)
- 函数名
QueueEmpty:表示 “队列是否为空”(Queue Empty)。 - 参数
SqQueue Q:传入队列结构体的值(而非指针),因为判断队列是否为空只需要读取队列的状态,不需要修改队列,所以传值即可。 - 返回值
int:在 C 语言中,通常用1(非 0 值)表示 “真”(队列空),0表示 “假”(队列非空)。
函数逻辑:return Q.front == Q.rear;
这行代码的核心是比较队头指针front和队尾指针rear是否相等:
- 当
Q.front == Q.rear时,表达式结果为1(真),函数返回1,表示队列是空的; - 当
Q.front != Q.rear时,表达式结果为0(假),函数返回0,表示队列中存在元素(非空)。
为什么
front == rear能判断队空?这与队列的设计逻辑一致:
- 初始化队列时(
InitQueue函数),front和rear被同时设置为0(Q->front = Q->rear = 0),此时队列为空;- 当队列中的元素全部出队后,
front会逐渐移动到与rear相同的位置,此时队列再次为空。因此,
front与rear相等是 “队列空” 的标志性条件。
循环队列的判满操作
// 队满
int QueueFull(SqQueue Q) {return (Q.rear + 1) % MAXQSIZE == Q.front;
}
函数定义:int QueueFull(SqQueue Q)
- 函数名
QueueFull:表示 “队列是否已满”(Queue Full)。 - 参数
SqQueue Q:传入队列结构体的值(无需修改队列,仅读取状态)。 - 返回值
int:用1表示 “队列已满”(真),0表示 “队列未满”(假)。
核心判断逻辑:return (Q.rear + 1) % MAXQSIZE == Q.front;
这行代码的设计是为了避免普通顺序队列的 “假溢出” 问题,我们需要结合 “循环队列” 的思想理解:
- 为什么不能用
Q.rear == MAXQSIZE判断队满?
普通顺序队列中,如果简单用 “队尾指针rear达到最大长度MAXQSIZE” 判断队满,会出现假溢出:- 例如:队列初始为空(
front=0, rear=0),依次入队元素后rear逐渐增大到MAXQSIZE(此时看似满了),但如果此时有元素出队,front会向后移动(比如front=2),队列前面会出现空位(索引 0、1),但rear已达最大值,无法再入队,导致空间浪费。
- 例如:队列初始为空(
- 循环队列的解决方案:
将队列的存储空间视为一个环形结构(通过取模运算实现 “绕回”),此时队满的判断条件设计为:(rear + 1) % MAXQSIZE == front
含义是:当队尾指针rear的下一个位置(加 1 后),通过取模MAXQSIZE绕回环形空间后,与队头指针front重合时,说明队列已满。 - 取模运算的作用:
% MAXQSIZE确保指针在达到数组边界(MAXQSIZE-1)后,能 “绕回” 到起始位置(0),形成环形。例如:- 若
MAXQSIZE=100,当rear=99(最后一个索引)时,rear+1=100,100 % 100 = 0,此时若front=0,则满足队满条件。
- 若
- 为什么要留一个空位?
这种判断方式会故意保留一个空闲位置(即rear指向的位置始终为空),目的是区分 “队满” 和 “队空”:- 队空条件:
front == rear(两者指向同一位置,且该位置无元素); - 队满条件:
(rear+1) % MAXQSIZE == front(rear的下一个位置是front,中间无空闲空间)。
- 队空条件:
如果不留空位,当队列满时也会出现 front == rear,就无法区分是 “空” 还是 “满” 了。
循环队列的入队操作
int EnQueue(SqQueue *Q, QElemType e) {if (QueueFull(*Q)) return 0; // 队满Q->base[Q->rear] = e;Q->rear = (Q->rear + 1) % MAXQSIZE;return 1;
}
函数定义:int EnQueue(SqQueue *Q, QElemType e)
- 函数名
EnQueue:表示 “入队”(Enqueue,即元素进入队列)。 - 参数
SqQueue *Q:队列结构体的指针,用于修改队列的状态(如队尾指针rear和存储元素)。 - 参数
QElemType e:要插入队列的元素(类型由QElemType定义,如int)。 - 返回值
int:1表示入队成功,0表示入队失败(队列已满时)。
函数内部逻辑:
- 判断队列是否已满
if (QueueFull(*Q)) return 0; // 队满- 调用之前定义的
QueueFull函数判断队列是否已满(传入*Q是因为QueueFull参数是结构体值)。 - 如果队列已满,无法插入新元素,直接返回
0表示入队失败。
- 调用之前定义的
- 将元素存入队尾
Q->base[Q->rear] = e;- 队列未满时,将元素
e存入base数组中rear指针指向的位置。 - 回忆之前的设计:
rear始终指向队尾元素的下一个空闲位置,因此这里直接赋值即可将e作为新的队尾元素。
- 队列未满时,将元素
- 更新队尾指针
Q->rear = (Q->rear + 1) % MAXQSIZE;- 插入元素后,队尾指针需要向后移动一位,指向新的空闲位置。
- 由于是循环队列,通过
% MAXQSIZE实现 “绕回” 效果:当rear达到最大索引(MAXQSIZE-1)时,加 1 后取模会回到0,继续使用前面的空闲空间,避免 “假溢出”。
- 返回成功标志
return 1;- 所有操作完成后,返回
1表示元素e成功入队。
- 所有操作完成后,返回
循环队列的出队操作
int DeQueue(SqQueue *Q, QElemType *e) {if (QueueEmpty(*Q)) return 0; // 队空*e = Q->base[Q->front];Q->front = (Q->front + 1) % MAXQSIZE;return 1;
}
函数定义:int DeQueue(SqQueue *Q, QElemType *e)
- 函数名
DeQueue:表示 “出队”(Dequeue,即元素离开队列)。 - 参数
SqQueue *Q:队列结构体的指针,用于修改队列的状态(如队头指针front)。 - 参数
QElemType *e:指向QElemType类型的指针,用于接收出队的元素值(将队头元素 “带出去”)。 - 返回值
int:1表示出队成功,0表示出队失败(队列空时)。
函数内部逻辑:
- 判断队列是否为空
if (QueueEmpty(*Q)) return 0; // 队空- 调用之前定义的
QueueEmpty函数判断队列是否为空(传入*Q,因为QueueEmpty需要结构体值)。 - 如果队列为空,没有元素可出队,直接返回
0表示操作失败。
- 调用之前定义的
- 取出队头元素并通过指针传出
*e = Q->base[Q->front];- 队列非空时,队头指针
front指向的位置就是队头元素(根据队列设计,front始终指向队头元素)。 - 将
base[front](队头元素)赋值给*e(通过指针e将元素值传出函数,供外部使用)。
- 队列非空时,队头指针
- 更新队头指针
Q->front = (Q->front + 1) % MAXQSIZE;- 移除队头元素后,队头指针需要向后移动一位,指向新的队头元素。
- 同样使用
% MAXQSIZE实现循环效果:当front达到最大索引(MAXQSIZE-1)时,加 1 后取模会绕回0,继续维护环形结构。
- 返回成功标志
return 1;- 所有操作完成后,返回
1表示队头元素成功出队。
- 所有操作完成后,返回
严格来说,出队(DeQueue)不会真的把数组里的元素“删除”掉。
出队其实只是“逻辑删除”,通过移动
front指针来忽略这个元素,而不是物理删除。
获取队头元素
int GetHead(SqQueue Q, QElemType *e) {if (QueueEmpty(Q)) return 0;*e = Q.base[Q.front];return 1;
}
函数定义:int GetHead(SqQueue Q, QElemType *e)
- 函数名
GetHead:表示 “获取队头”(Get Head),即读取队列的第一个元素。 - 参数
SqQueue Q:传入队列结构体的值(仅读取队列状态,无需修改队列,因此传值即可)。 - 参数
QElemType *e:指向QElemType类型的指针,用于接收队头元素的值(将读取到的队头元素 “带出去” 供外部使用)。 - 返回值
int:1表示获取成功(队列非空),0表示获取失败(队列空,无队头元素)。
函数内部逻辑:
- 判断队列是否为空
if (QueueEmpty(Q)) return 0;- 调用
QueueEmpty函数判断队列是否为空:若为空(front == rear),则没有队头元素可获取,返回0表示失败。
- 调用
- 读取队头元素并通过指针传出
*e = Q.base[Q.front];- 队列非空时,根据循环队列的设计,
front指针始终指向队头元素,因此直接通过Q.base[Q.front]即可访问队头元素。 - 将读取到的队头元素赋值给
*e(通过指针e传出,供函数外部使用)。
- 队列非空时,根据循环队列的设计,
- 返回成功标志
return 1;- 成功读取队头元素后,返回
1表示操作成功。
- 成功读取队头元素后,返回
核心特点:仅读取,不修改队列
与出队操作 DeQueue 的关键区别在于:
GetHead只读取队头元素,不会改变队列的结构(front指针位置不变,队列中的元素数量也不变);DeQueue会移除队头元素,并修改front指针位置(队列元素数量减少)。
链式队列
链式队列的概念
队列:先进先出(FIFO)。
顺序队列:用数组实现,空间固定。
链式队列:用链表实现,动态分配内存,理论上只要内存够就不会溢出。
链式队列一般用 单链表 来实现,通常带有 头指针(front) 和 尾指针(rear):
front:指向队头结点(一般是头结点,方便操作)。rear:指向队尾结点,方便在队尾插入。
链式队列的基本原理
链式队列通过链表的方式存储数据,遵循 “先进先出(FIFO)” 原则:
- 入队(添加元素):在队尾(
rear指向的结点后)插入新结点,更新rear指针。 - 出队(删除元素):移除队头(
front指向的头结点的下一个结点)元素,更新front指针的指向。
链式队列的定义
// 队列结点
typedef struct QNode {int data;struct QNode *next;
} QNode;// 队列(带头结点)
typedef struct {QNode *front; // 队头指针QNode *rear; // 队尾指针
} LinkQueue;
QNode是队列的基本组成单元(结点),用于存储队列中的单个元素。data:存储具体的数据(此处定义为int类型,实际可根据需求修改)。next:是一个指向QNode类型的指针,用于连接下一个结点,形成链表结构。LinkQueue是队列的管理结构,用于整体管理队列(通过队头和队尾指针操作队列)。front:指向队列的头结点(或队头元素,取决于实现细节,带头结点时通常指向头结点)。rear:指向队列的最后一个元素(队尾结点)。
链式队列的初始化
void InitQueue(LinkQueue *Q) {QNode *dummy = (QNode *)malloc(sizeof(QNode)); // 建立头结点dummy->next = NULL;Q->front = Q->rear = dummy; // front和rear都指向头结点
}
InitQueue(LinkQueue *Q) 的作用是对一个 LinkQueue 类型的队列进行初始化,使其成为一个空队列(但包含头结点),为后续的入队、出队等操作做好准备。
- 创建头结点
QNode *dummy = (QNode *)malloc(sizeof(QNode)); // 建立头结点- 通过
malloc动态分配一块QNode大小的内存,创建一个头结点(用dummy指针临时指向)。 - 头结点是一个不存储实际数据的结点,仅用于简化队列操作(例如统一空队列和非空队列的处理逻辑)。
- 通过
- 初始化头结点的指针
dummy->next = NULL;- 头结点的
next指针设为NULL,表示此时头结点后面没有任何元素(队列初始为空)。
- 头结点的
- 设置队头和队尾指针
Q->front = Q->rear = dummy; // front和rear都指向头结点- 让队列的
front(队头指针)和rear(队尾指针)都指向刚创建的头结点。 - 这是 “带头结点的空队列” 的标准状态:此时队列中没有有效数据元素,
front和rear重合且都指向头结点。
- 让队列的
初始化完成后,队列处于空队列状态:
- 存在一个头结点(不存储数据)。
front和rear指针均指向头结点。- 头结点的
next为NULL(表示没有后续元素)。
链式队列的判空操作
int QueueEmpty(LinkQueue Q) {return Q.front == Q.rear;
}
- 函数定义:
int QueueEmpty(LinkQueue Q)- 函数名
QueueEmpty直观表示 “队列是否为空”。 - 参数
LinkQueue Q表示要判断的链式队列(LinkQueue是链式队列的结构体类型,通常包含队头指针front和队尾指针rear)。 - 返回值类型
int:在 C 语言中常用1表示 “真”(空队列),0表示 “假”(非空队列)。
- 函数名
- 函数逻辑:
return Q.front == Q.rear;- 核心判断:比较队列的队头指针(front) 和队尾指针(rear) 是否指向同一个位置。
- 在链式队列的典型实现中,当队头指针和队尾指针相等时,意味着队列中没有元素(为空);反之则队列非空。
链式队列的“判满”:
- 顺序队列:因为数组长度固定,所以可以判断
rear == MAXSIZE-1来判满。- 链式队列:用的是 动态内存分配,理论上只要系统有足够的内存就不会满。
所以链式队列通常 不需要判满。
链式队列的入队操作
void EnQueue(LinkQueue *Q, int x) {QNode *node = (QNode *)malloc(sizeof(QNode));node->data = x;node->next = NULL;Q->rear->next = node; // 原队尾指向新节点Q->rear = node; // 更新队尾指针
}
- 创建新结点
QNode *node = (QNode *)malloc(sizeof(QNode));- 用
malloc动态分配一块QNode大小的内存,创建一个新结点(node指针指向该结点),用于存储要入队的数据x。
- 用
- 初始化新结点
node->data = x; // 新结点的数据域存入 x node->next = NULL; // 新结点的 next 设为 NULL(因为它将成为队尾,后面暂无其他结点) - 将新结点链接到队尾
Q->rear->next = node; // 原队尾结点的 next 指向新结点- 队列当前的队尾是
Q->rear指向的结点,通过Q->rear->next = node,将新结点链接到原队尾结点的后面,使其成为队列的新尾部。
- 队列当前的队尾是
- 更新队尾指针
Q->rear = node; // 队尾指针 rear 移动到新结点(新结点成为新的队尾)
假设队列初始状态为空队列(front 和 rear 都指向头结点):
- 第一次入队(如
EnQueue(Q, 10)):- 创建存储
10的新结点node1。 - 头结点(
Q->rear此时指向头结点)的next指向node1。 Q->rear改为指向node1(现在node1是队尾)。
- 创建存储
- 第二次入队(如
EnQueue(Q, 20)):- 创建存储
20的新结点node2。 - 当前队尾
node1的next指向node2。 Q->rear改为指向node2(node2成为新队尾)。
- 创建存储
此时队列结构为:
头结点 -> node1(10) -> node2(20),front 仍指头结点,rear 指向 node2。
链式队列的出队操作
int DeQueue(LinkQueue *Q, int *x) {if (Q->front == Q->rear) return 0; // 空队列QNode *p = Q->front->next; // 第一个有效结点*x = p->data;Q->front->next = p->next; // 头结点指向下一个if (Q->rear == p) { // 若出队的是最后一个结点Q->rear = Q->front; // rear回到头结点}free(p);return 1;
}
- 判断队列是否为空
if (Q->front == Q->rear) return 0; // 空队列- 若队头指针
front和队尾指针rear指向同一位置(即空队列),无法出队,返回 0 表示失败。
- 若队头指针
- 定位队头有效元素
QNode *p = Q->front->next; // 第一个有效结点front指向头结点,头结点的next才是队列中第一个存储有效数据的结点(队头元素),用p指针临时指向该结点(即要删除的结点)。
- 获取出队元素的值
*x = p->data;- 将待删除结点
p中存储的数据存入x指向的内存(调用者通过x即可获取出队元素)。
- 将待删除结点
- 移除队头元素
Q->front->next = p->next; // 头结点指向下一个- 让头结点的
next跳过p结点,直接指向p的下一个结点(p->next),相当于将p从链表中 “摘除”,此时队列的新队头变为原第二个元素。
- 让头结点的
- 处理 “删除最后一个元素” 的边界情况
if (Q->rear == p) { // 若出队的是最后一个结点Q->rear = Q->front; // rear回到头结点 }- 当
p是队列中最后一个有效元素(即rear也指向p)时,删除p后队列变为空队列。 - 此时需将
rear重新指向头结点(与front保持一致),符合 “空队列时front == rear” 的规则。
- 当
- 释放内存并返回成功标志
free(p); // 释放被删除结点的内存,避免泄漏 return 1; // 出队成功
假设队列当前状态为:
头结点(front) -> node1(10) -> node2(20) -> node3(30)(rear)
- 第一次出队(删除 node1):
p指向 node1,*x被赋值为 10。- 头结点的
next改为指向 node2。 - 此时
rear仍指向 node3(非最后一个元素),无需调整rear。 - 释放 node1 内存,队列变为:
头结点 -> node2(20) -> node3(30)(rear)。
- 继续出队直到只剩最后一个元素(删除 node2、node3):
- 删除 node3 时,
p指向 node3,且rear == p(node3 是最后一个元素)。 - 头结点的
next改为NULL(因为 node3 的next是 NULL)。 - 执行
Q->rear = Q->front,rear回到头结点。 - 释放 node3 内存,队列变为空队列(
front == rear都指向头结点)。
- 删除 node3 时,