Mistral AI音频大模型Voxtral解读
1. 引言
传统的语音处理系统(如OpenAI的Whisper)在ASR任务上取得了巨大成功,能将语音高精度地转换为文本。但这只是第一步。真正的“语音理解”意味着:
- 内容推理:不仅知道说了什么,还能理解话语背后的含义、情感和意图。
- 长篇摘要:能够听完一段长达数十分钟的播客或会议,并总结其核心要点。
- 问答交互 (Audio QA):能回答关于音频内容细节的具体问题。
- 多语言能力:不仅能转录和翻译,还能理解不同语言的音频内容。
Voxtral正是为了实现这一从“转录”到“理解”的飞跃而设计的。它是一个端到端的音频对话模型,能够直接接收语音或文本输入,并生成文本回答,其32K的上下文窗口使其能处理长达40分钟的音频文件。
2. Voxtral架构设计:Whisper与Mistral的“强强联合”
Voxtral的架构清晰而优雅,由三个核心组件构成,巧妙地将SOTA的音频编码能力和语言建模能力结合在一起。
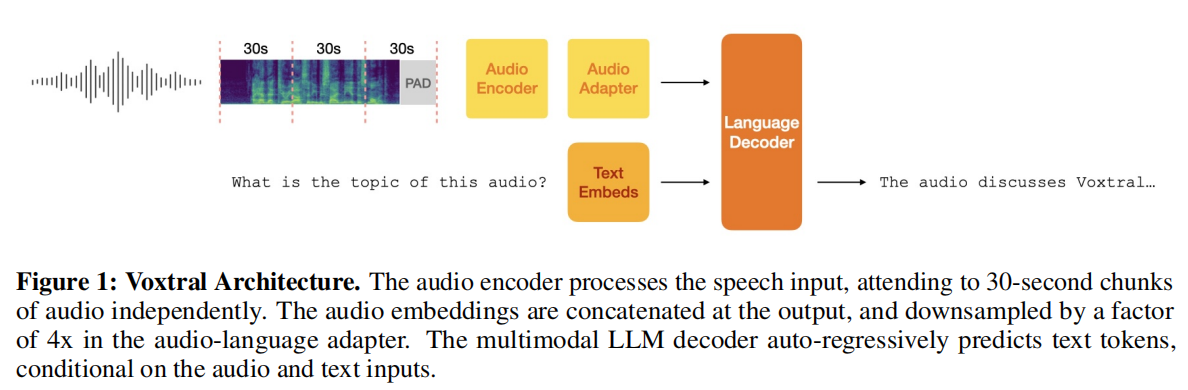
(Voxtral的整体架构:语音输入被Whisper编码器分块处理,输出的音频嵌入序列经过Adap