【系统架构设计师】数据库设计(一):数据库技术的发展、数据模型、数据库管理系统、数据库三级模式
数据库技术是研究数据库的结构、存储、设计、管理和应用的一门软件学科。
数据库系统本质上是一个用计算机存储信息的系统。
数据库管理系统是位于用户与操作系统之间的一层数据管理软件,其基本目标是提供一个可以方便、有效地存取数据库信息的环境。
数据库就是信息的集合,它是收集计算机数据的仓库或容器,系统用户可以对这些数据执行一系列操作。
设计数据库系统的目的是为了管理大量信息,给用户提供数据的抽象视图,即系统隐藏有关数据存储和维护的某些细节。
对数据的管理涉及信息存储结构的定义、信息操作机制的提供、安全性保证,以及多用户对数据的共享问题。
一、数据库技术的发展
数据处理是对各种数据进行收集、存储、加工和传播的一系列活动。数据管理是对数据进行分类、组织、编码、存储、检索和维护的活动。
数据管理技术的发展经历了3个阶段:人工管理、文件系统和数据库系统阶段。
(一)人工管理阶段
早期的数据处理都是通过手工进行的,因为当时的计算机主要用于科学计算。计算机上没有专门管理数据的软件,也没有诸如磁盘之类的设备来存储数据。
在人工管理阶段,数据处理具有以下几个特点。
1.人工管理阶段数据处理的特点
(1)数据量较少且“绑定”程序
数据和程序一一对应,即一组数据对应一个程序,数据面向应用,独立性很差。
数据和程序几乎是一一对应的“捆绑销售”。一组特定的数据只为解决一个特定的计算任务(应用)而生。这就好比每本菜谱(程序)都必须自带独一无二的食材清单(数据),想换个菜谱?对不起,清单也得重写。 数据完全服务于单一应用,毫无独立性可言。
(2)数据不保存
该阶段计算机主要用于科学计算(比如弹道计算、物理模拟),一般不需要将数据长期保存,只在计算一个题目时,将数据输入计算机,计算完成得到计算结果即可。
计算任务像“快餐”——数据是临时买来的食材,计算过程是烹饪,得到结果(菜肴)后,食材(数据)就被丢弃了。 一般没有长期保存数据的需要和意识。
(3)没有软件系统对数据进行管理
程序员需要“身兼数职”,没有专门的软件来管理数据这个“仓库”。
程序员不仅要设计数据的逻辑结构(数据代表什么),还得在程序里操心数据的物理存储细节(存在哪、怎么存、怎么取、怎么输入输出)。
这相当于建筑师不仅要设计房屋蓝图,还得亲自烧砖砌墙、铺设水电管道。
2.手工处理数据的缺点
(1)紧耦合的噩梦: 应用程序与数据深度绑定。
想修改一下数据结构(比如在员工信息里加个“电话号码”字段)?抱歉,所有用到这份数据的程序都得跟着大改,牵一发而动全身。 程序和数据完全无法独立演化。
(2)冗余的“信息孤岛”
不同部门或不同程序处理的数据常常重复。
销售部门有自己的客户地址卡片,财务部门也建了一套客户地址卡片用于开发票。
这不仅浪费存储空间(虽然当时存储空间极其珍贵),更可怕的是,一旦客户搬家,更新任何一处都可能遗漏其他地方,导致数据不一致,引发混乱。
3.人工管理的存储方式:物理世界的局限
数据主要栖身于物理介质。
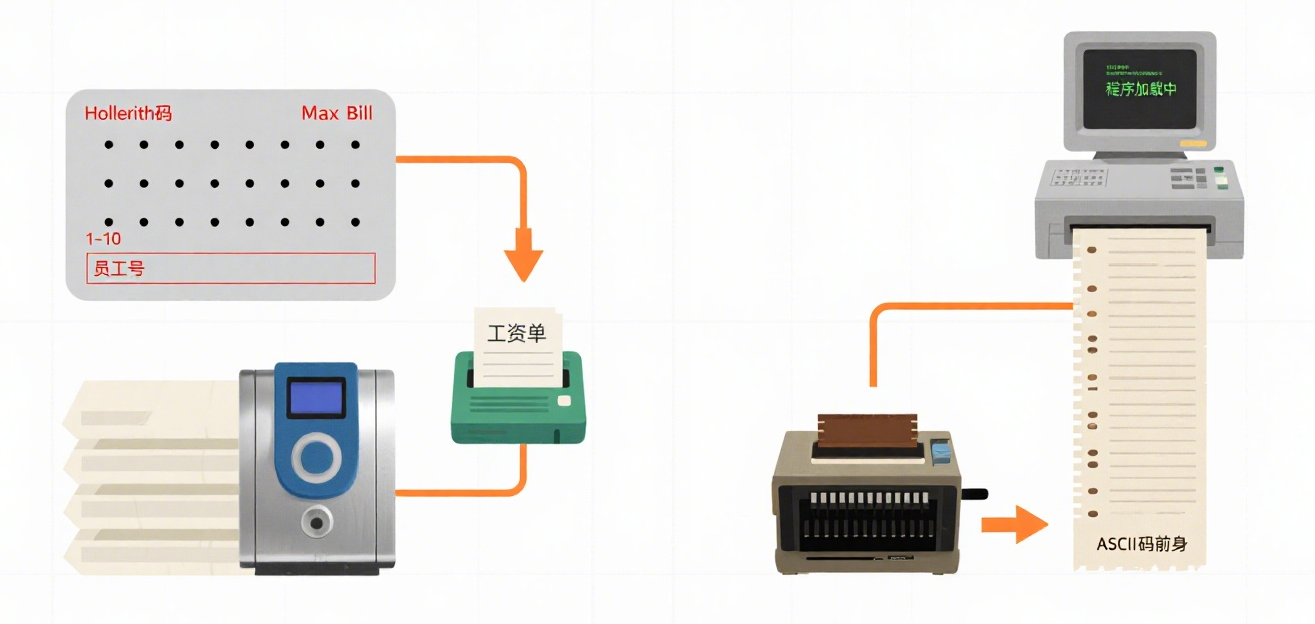
(1)打孔卡片:
在特制的硬纸卡片上,按照特定的编码规则(如Hollerith码,用孔的位置代表数字、字母或符号)打孔来表示数据和程序指令。
使用打卡机将数据和程序指令制作成卡片叠。每张卡片通常代表一条记录或一条指令。 计算机通过读卡器逐张读取卡片上的孔洞信息,将其转换成电信号输入内存进行计算。计算结果可通过打卡机输出到新的卡片上,或通过打印机输出到纸上。
例如,一家工厂的工资系统:每张卡片代表一个员工,记录其员工号、工作时长、工资率等。程序卡片叠规定了如何计算工资。处理时,读卡器依次读入员工卡片和程序卡片进行计算,结果输出到新的工资卡片或打印出来。
程序员在编写程序时,必须精确指定:数据在卡片上的哪几列(Column)代表什么字段(如1-10列是员工号)。
(2)纸带:
在长条纸带上打孔(通常一排孔代表一个字符,如ASCII码的前身)来表示数据和程序。
使用纸带穿孔机制作纸带。 计算机通过纸带阅读机连续读取纸带上的孔信息。 可通过纸带穿孔机输出结果纸带。
常用于在计算机之间或从终端向主机传输程序和数据。例如,一个分时系统的用户终端可能通过纸带阅读机将程序加载到主机运行。
(3)总结
打孔卡片是绝对主流,纸带次之,纸质文档是外围辅助。
人工管理阶段的核心矛盾: 日益增长的数据处理需求 与 原始、低效、脆弱、紧耦合的物理介质存储及管理方式 之间的矛盾。正是这个矛盾的激化,加上大容量磁盘的出现,才催生了文件系统这一革命性的解决方案。
(二)文件系统阶段
随着企业规模扩大、业务复杂度增加,以及——最关键的是——大容量磁盘等辅助存储设备的出现,数据的“洪流”开始涌现,人工管理和物理卡片系统彻底不堪重负。
数据量激增、需要长期保存和反复使用的需求日益迫切(比如工资计算每月都要用到员工数据)。
那种“用完即弃”和“翻箱倒柜”的方式走到了尽头。
技术终于迎来了突破点:专门用于管理辅助存储设备(主要是磁盘)上数据的软件——文件系统诞生了! 这就像是为数据修建了第一条“高速公路”。
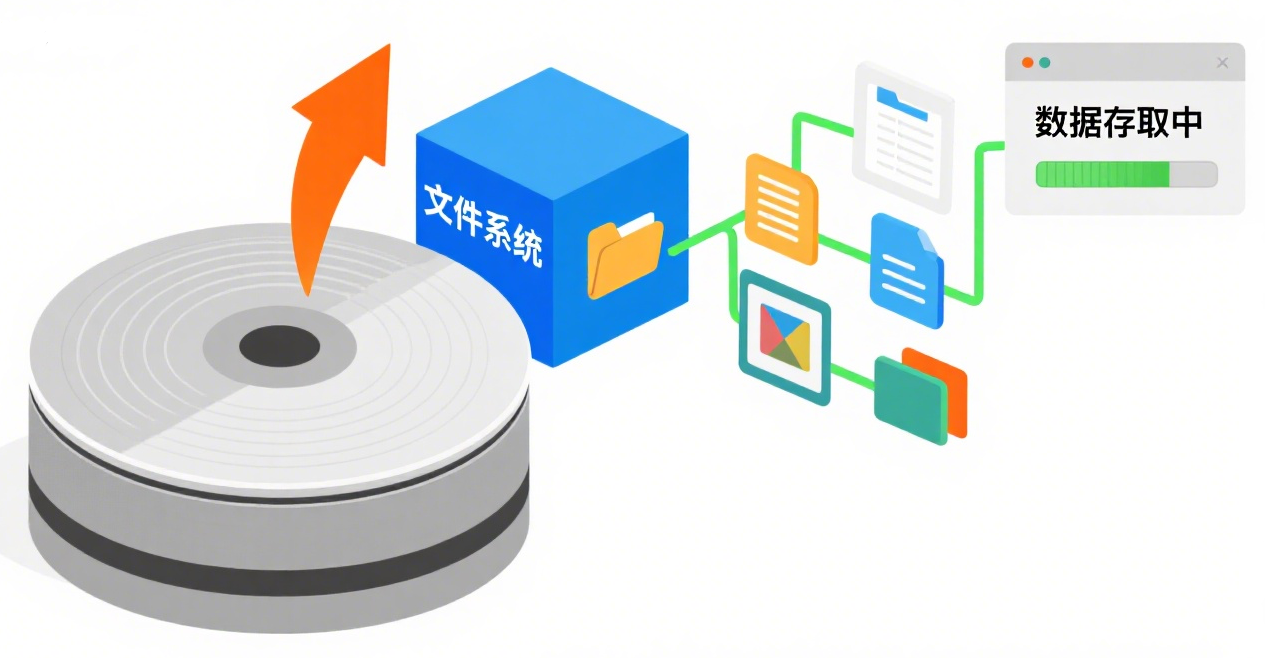
文件系统带来的核心变革是: 数据可以按一定的逻辑规则(比如按记录结构)组织成一个文件(如 employees.dat, books.txt)。
应用程序不再需要直接操作物理存储设备上的复杂细节(扇区、磁道等),而是**通过文件系统提供的统一接口(如打开、读取、写入、关闭文件)来访问和操作文件中的数据。**程序员终于可以从繁琐的物理存储管理中解放出来一部分精力。
1.在文件系统阶段中数据管理的特点
(1)数据可以长期保留
数据可以长期保存在磁盘上,不再是临时工。文件系统抽象了磁盘的复杂物理结构(磁道、扇区),程序只需要知道文件名和存取方法(读、写),就能找到并操作数据,不用管它具体藏在仓库的哪个角落(物理位置)。
(2)数据不属于某个特定的应用
数据不再死死绑定一个程序。同一个数据文件(如员工信息.txt)可以被工资计算程序、考勤统计程序甚至部门通讯录程序重复使用。数据有了一定的独立性。
(3)文件组织形式的多样化
文件系统提供了多种组织文件内部数据的方式:索引文件(像带目录的书,快速定位章节)、顺序文件/链接文件(像串珠,一个接一个找)、Hash文件(像分门别类的抽屉,按关键字直接定位)。
但是! 这些文件之间是完全独立、没有联系的。员工信息.txt 和 部门预算.xls 之间没有任何关联。想知道某个部门的员工总工资?得写个程序分别读两个文件,自己手动匹配部门ID。
2.文件系统的缺点
(1)数据冗余 (Data Redundancy)
因为文件是围绕应用建立的,不同应用需要相似数据时,往往各自建一个文件。比如销售系统有自己的客户地址.csv,财务系统也有自己的客户开票地址.txt。相同的数据(客户地址)被重复存储多次。
(2)数据不一致性 (Data Inconsistency)
正是由于冗余,当数据发生变化时(如客户地址更新),如果只修改了部分文件(如只改了销售部的文件),而其他文件(如财务部的)没改,就导致了同一个事实在系统中有多个版本,数据不一致。
(3)数据孤立 (Data Isolation)
数据分散在无数格式各异、互不关联的文件中。文件系统没有提供机制来描述和建立文件之间、数据之间的联系(如“员工属于部门”、“订单关联客户”)。要获得全局视图或复杂信息,需要编写极其复杂的程序去“拼图”。
3.文件系统的存储方式
文件:所有数据都被塞进一个个命名好的“档案袋”(文件)里,扔进仓库(磁盘)。人事档案袋(hr.dat),财务账本袋(finance.xls),各自为政。
索引:为了更快找到袋里某张特定纸(如“员工ID=10086”的记录),可以单独建一个“目录小册子”(索引文件)。小册子按ID排序,记录着每个ID对应的纸在档案袋里的位置(偏移量)。想找10086?先查小册子,再直奔档案袋指定位置!效率大大提升
4.总结
文件系统是数据管理史上的一次巨大飞跃。它让数据持久化、初步共享,并提供了基础的组织工具(文件、目录、索引)。它就像给混乱的数据世界建立了无数个有序的小档案室。
然而,它的本质局限在于:它只管理“档案袋”(文件),却不理解也不管理“档案袋里的内容”(数据本身)以及“档案袋之间的关系”(数据语义和联系)。
它解决了“存哪里、怎么找袋”的问题,但没解决“袋里装的是什么?袋子之间有什么关系?”的问题。
它实现了程序与数据的初步解耦(通过文件名),但数据与数据的耦合(联系)依然要靠程序硬编码,脆弱且低效。
这就引出了一个核心问题:我们能否建立一个系统,不仅能管理‘档案袋’(存储),更能理解‘档案袋里的内容’(数据含义)和它们之间的‘血缘关系’(数据联系),并提供统一、高效、安全的方式来操作和利用这些知识?
这个强烈的需求,正是数据库技术诞生的原动力!
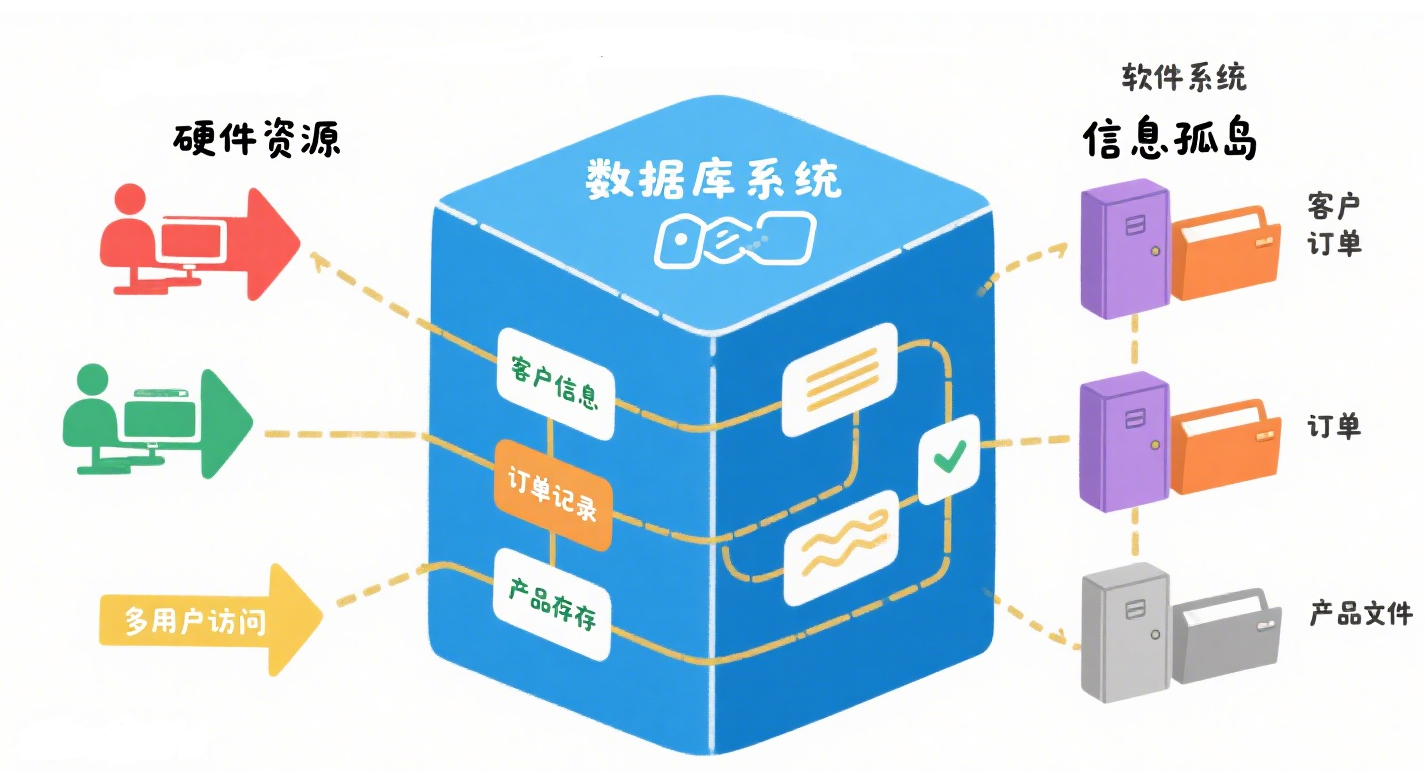
(三)数据库系统阶段
数据库系统是由计算机软件、硬件资源组成的系统,它有组织地、动态地存储大量关联数据,方便多用户访问,它与文件系统重要的区别是数据的充分共享、交叉访问、与应用程序的高度独立性。
1.数据库系统阶段数据管理的特点
(1)从“孤岛”到“大陆”:数据模型与共享
数据模型不仅描述数据本身的特点,还描述数据之间的联系。数据不再面向某个应用,而是面向整个应用系统。数据冗余明显减少,实现了数据共享。
想象一下,以前每个部门(应用)都有自己的小仓库(文件),里面堆满了重复的货物(数据冗余),比如财务有员工名单,人事也有员工名单,但格式还不同!数据库系统就像建造了一个超级智能的中央大仓库(大陆)。
它用一张精密的“关系地图”(关系模型)或“对象蓝图”(对象模型)来组织所有货物(数据),清晰地标出货物之间的联系(如“员工”属于“部门”)。
现在,所有部门都来这个同一个大仓库取货,仓库管理员(DBMS)保证大家看到的是唯一、最新、正确的货物信息。冗余大大减少,协作效率飙升!
(2)程序与数据的“离婚协议”:数据独立性
数据库也是以文件方式存储数据的,但是它是数据的一种更高级的组织形式,在应用程序和数据库之间由DBMS 负责数据的存取。 DBMS 对数据的处理方式和文件系统不同,它把所有应用程序中使用的数据以及数据间的联系汇集在一起,以便于应用程序查询和使用。
数据库系统与文件系统的区别是:数据库对数据的存储是按照同一种数据结构进行的,不同的应用程序都可以直接操作这些数据(即对应用程序的高度独立性)。
文件系统时代,程序和数据就像一对“连体婴”,程序严重依赖数据的存放格式和位置。换个硬盘位置或者改个文件结构?程序就得动大手术!
数据库系统引入了专业的“中介”——DBMS。它制定了一份完美的“离婚协议”(数据独立性):程序只需要告诉中介“我要什么”(如:查询所有销售部的员工),完全不用管数据具体存在哪个硬盘角落、是用表格还是对象存的(物理独立性),甚至仓库内部调整了货架结构(逻辑结构微调,如增加字段),只要程序要的信息不变,程序本身也完全不用改(逻辑独立性)。
(3)从“混乱集市”到“法治城市”:数据管理与控制
数据库系统对数据的完整性、一致性和安全性都提供了一套有效的管理手段(即数据的充分共享性)。数据库系统还提供管理和控制数据的各种简单操作命令,容易掌握,使用户编写程序简单(即操作方便性)。
文件系统下的数据共享,就像一个混乱的集市:谁都可以随意改价签(数据),没有统一规则,假币(错误数据)可能流通,小偷(未授权访问)容易得手。数据库系统则像建立了一个高度法治化的现代城市:
-
统一法典(数据结构): 所有市民(数据)都必须按统一的身份规则(Schema)登记注册。
-
警察与法官(DBMS): 严格执行法律:确保钱货一致(数据完整性,如年龄不能负数)、全城物价同步(数据一致性,如转账时A账户扣款和B账户加款必须同时成功或失败)、检查身份证(安全性,权限控制)。
-
便捷公共服务(SQL): 市民(用户/程序)只需用简单通用的语言(SQL)向市政厅(DBMS)提出需求(查询/更新),就能高效地获得服务,不用自己满城跑(操作文件)。
2. 数据库系统的存储方式
(1)关系数据库 (如MySQL, PostgreSQL, Oracle)
想象一个大型电商。Customers表存客户信息,Orders表存订单,Products表存商品。它们像精密的齿轮通过ID(主键/外键)相互咬合。
一个简单的SQL查询就能回答:“上海的金牌会员最近一个月买了哪些单价超过500元的电子产品?”——这需要瞬间关联多个表,精准筛选。体现了结构化数据的强大关联查询能力。
(2)NoSQL数据库 (如MongoDB-文档, Cassandra-列族, Redis-键值):
-
文档存储 (MongoDB): 你的整个个人主页(包含个人信息、发的所有动态、动态下的评论、点赞列表)可以作为一个复杂的JSON文档直接存储和读取。非常适合快速展示个人主页这种“一次性获取大量关联但不太结构化数据”的场景。
-
键值存储 (Redis): 用来存储用户的在线状态(Key: user:12345, Value: online)或者热门动态的点赞数(Key: post:67890:likes, Value: 1024)。读写快到飞起,支撑实时更新。
-
列族存储 (Cassandra): 存储海量用户的行为日志(如浏览记录)。可以按用户ID快速查询其所有行为,或者按时间范围查询所有用户的行为(用于大数据分析)。体现了灵活性与处理海量非结构化/半结构化数据、高并发读写的优势。
(3)对象数据库 (如db4o, ObjectDB - 不如关系/NoSQL主流,但有特定场景):
开发一个复杂的CAD软件或游戏引擎。一个“3D场景”对象可能包含复杂的几何网格对象、材质对象、光源对象,它们之间有复杂的继承和引用关系。
对象数据库允许程序员直接把内存中的对象“扔”进数据库持久化,保留其复杂的结构和关系,避免了在关系数据库中将对象“拆解”成多个表和繁琐的ORM映射带来的开销和复杂性。
体现了与面向对象编程思维的无缝衔接。
(4)索引
就像书本后面的“索引目录”。没有目录,你要找“数据库”相关内容,得翻遍整本书(全表扫描)。有了目录(索引),直接翻到第35、89、201页,瞬间找到!代价是目录本身要占空间,且增删书页时要更新目录。
(5)视图
就像一个“定制化的观察窗”。财务总监需要看公司总营收和各部门成本(一个视图),HR总监需要看员工薪资分布和绩效(另一个视图)。
他们看到的都是基于底层核心数据(员工表、销售表、成本表)实时计算组合出来的“虚拟表”,既简化了他们的操作,又隐藏了不必要的数据细节,保障了核心数据的安全。
二、数据模型
想象一下,你要设计一个图书馆来存放和管理海量的书籍。你需要一个清晰的蓝图来定义:书架如何排列(结构)、读者如何借阅归还(操作)、以及借阅规则(约束)。
数据库管理数据同样如此,它的核心蓝图就是数据模型——一组用于描述数据如何组织、操作和约束的概念和定义。
数据模型的三要素如同图书馆设计的三个关键方面:
(1) 数据结构
数据结构是对象类型的集合,是对系统静态特性的描述。
这就像图书馆的书架、图书分类标签、读者信息卡的设计。它定义了有哪些“东西”(如“读者”、“图书”、“借阅记录”)以及它们本身的结构(如“读者”包含姓名、ID、联系方式)。它关注的是系统在某个时刻的“样子”或“骨架”。
在关系模型中,数据结构就是“表”的定义(表名、列名、列的数据类型)。
(2) 数据操作
对数据库中各种对象(型)的实例(值)允许执行的操作集合,包括操作及操作规则。
如操作有检索、插入、删除和修改,操作规则有优先级等。数据操作是对系统动态特性的描述。
这规定了读者能做什么(借书、还书、查询)、管理员能做什么(上架新书、下架旧书、修改信息)以及这些操作的规则(比如必须先办卡才能借书)。它关注的是系统如何“动”起来,数据如何被“使用”和“改变”。
SQL语言中的 SELECT (检索), INSERT (插入), UPDATE (修改), DELETE (删除) 就是最核心的数据操作。
(3) 数据的约束条件
数据的约束条件是一组完整性规则的集合。也就是说,对于具体的应用数据必须遵循特定的语义约束条件,以保证数据的正确、有效和相容。
这就像图书馆的规则:一本书不能同时被两个人借走(唯一性约束)、借书证必须有效才能借书(参照完整性)、还书日期不能早于借书日期(业务规则约束)。这些规则确保了图书馆运作的有序和数据的真实可靠。
在数据库中,约束可以是“员工年龄不能小于18岁”(域约束)、“订单必须关联一个存在的客户”(外键约束)、“员工的工号必须唯一”(主键约束)。
理解数据模型的演变: 随着信息需求越来越复杂,图书馆的管理方式也在进化(从简单卡片柜到电脑系统)。数据库的发展历程也类似,按照不同的数据模型,可以分为3个主要阶段:
(一)层次和网状数据库系统:早期的“树形”与“蛛网”组织法
最早的数据库需要高效地管理具有明确父子或复杂关联的数据,比如组织结构图(公司-部门-员工)或复杂的设备零件清单。它们像早期的图书馆分类法,要么像一棵树(层次),要么像一张网(网状)。
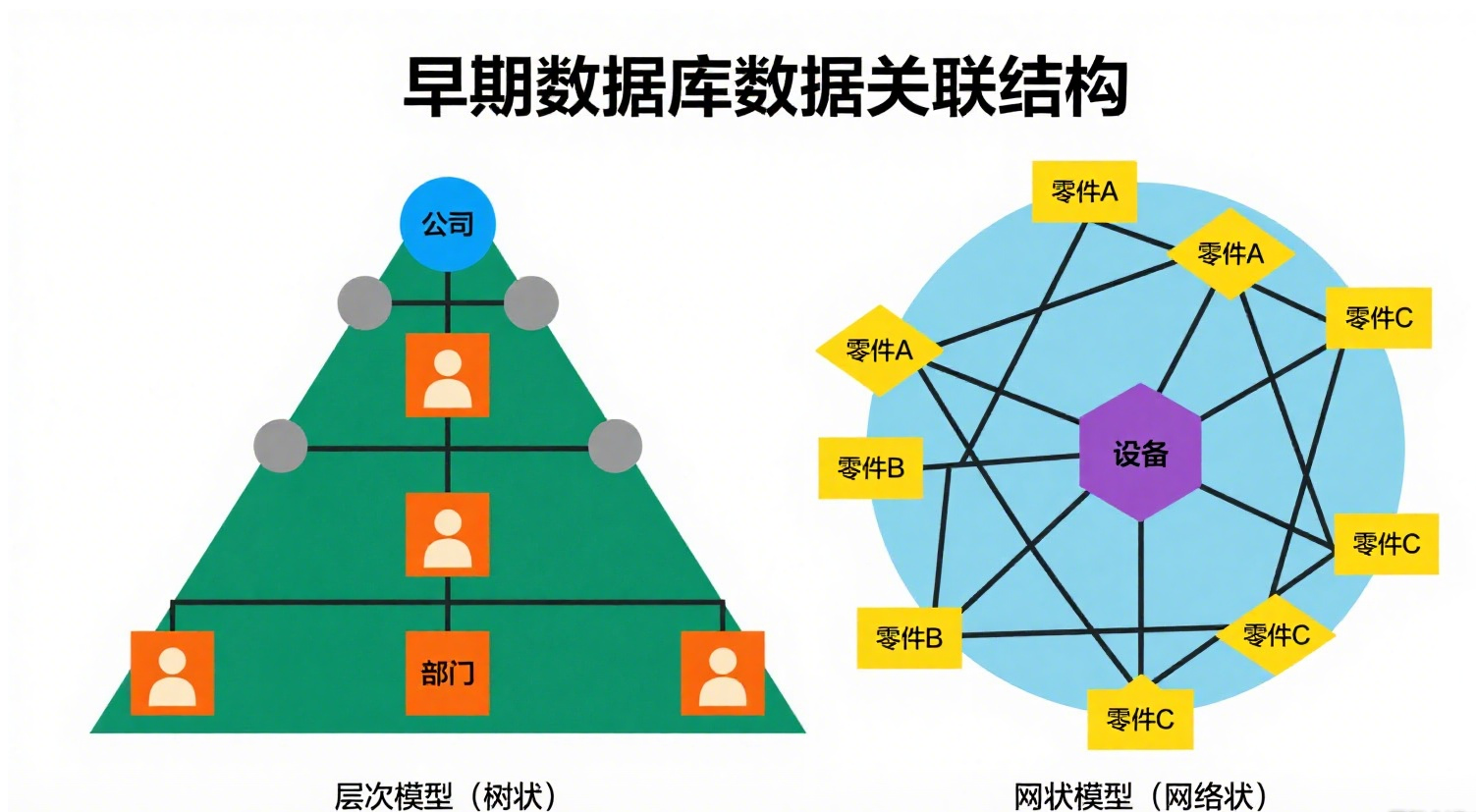
1.层次模型: 采用树形结构表示数据与数据间的联系。
每个结点(除根结点)有且仅有一个双亲结点。联系是严格的 1:n (包括 1:1)。
想象一个严格的公司架构图:一个部门(子节点)只能属于一个公司(父节点),但一个公司可以有多个部门。查询数据就像沿着这棵树的固定分支(存取路径)走。
IBM Information Management System (IMS) - 广泛应用于早期大型企业(金融、电信),处理如银行账户(账户是根,交易记录是子节点)这类结构清晰的数据。
2.网状模型: 采用网络结构表示数据间联系。
允许一个以上结点无双亲,或一个结点有多个双亲。能更直接描述现实世界(如“复合联系”)。
不能直接表示多对多(m:n)联系,需要引入额外的“联结记录”(如“选课”表连接“学生”和“课程”)。
想象一个城市交通图:一个交叉路口(节点)可以连接多条道路(父节点)。查询数据需要“导航”这张网,路径可能有多条,但也更复杂。
示例:
CODASYL DBTG Model - 定义了网状数据库的标准。
IDMS - 经典网状系统,用于大型主机环境,如管理复杂的制造业物料清单(一个零件可能被用在多个产品中,一个产品由多个零件组成)。
3.共同特点与局限
都支持三级模式、用存取路径显式表示联系、有独立的数据定义语言。
导航式数据操纵语言 - 程序员必须像地图导航一样,明确指定从一条记录到另一条记录的存取路径(“先找到A,再通过链接找到B”)。这增加了编程的复杂性。
想象在层次或网状图书馆里找一本书,你需要知道它具体在哪个房间的哪个书架的第几层(依赖物理路径),而不是像现代图书馆那样通过书名或作者名(逻辑查询)直接查找。
| 特性 | 层次数据库 | 网状数据库 |
|---|---|---|
| 数据模型 | 树形结构 | 网络结构 |
| 父节点 | 每个子节点有且仅有一个父节点 | 子节点可以有多个父节点 |
| 关系类型 | 1:N (或 1:1) | 支持更复杂关系 (但仍需联结记录处理 M:N) |
| 灵活性 | 较低 | 较高 |
| 复杂性 | 较低 | 较高 |
| 查询路径 | 固定路径 | 多路径 |
| 代表系统 | IBM IMS | IDMS (基于 CODASYL DBTG) |
(二)关系数据库系统
有没有一种更简单、更直观的方法来组织数据,摆脱复杂的指针和导航?就像用统一的Excel表格来管理图书馆信息,读者一张表、图书一张表、借阅记录一张表,表之间通过ID关联。
关系模型 (Relation Model) 是目前最常用的数据模型之一。关系数据库系统采用关系模型作为数据的组织方式,在关系模型中用表格结构表达实体集以及实体集之间的联系,其最大特色是描述的一致性。
关系模型是由若干个关系模式组成的集合。一个关系模式相当于一个记录型,对应于程序设计语言中类型定义的概念。
关系是一个实例,也是一张表,对应于程序设计语言中变量的概念。变量的值随时间可能会发生变化,类似地,当关系被更新时,关系实例的内容也发生了变化。
由于关系模型比网状、层次模型更为简单灵活,因此,数据处理领域中,关系数据库的使用已相当普遍。
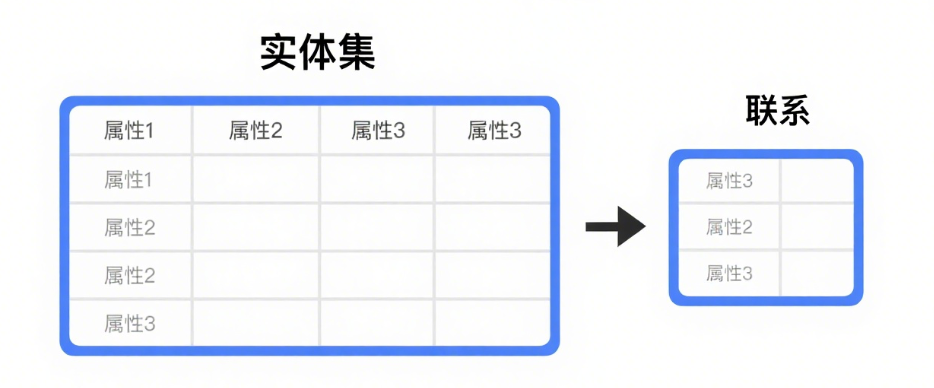
1.关系模型
关系模型用表格结构(关系) 表达实体集及实体集间的联系,最大特色是描述的一致性(都用表)。
-
关系模式 (Relation Schema): 相当于记录型的“类型定义”(表头:列名+数据类型)。定义结构。
-
关系 (Relation): 是关系模式的一个具体实例,是一张有数据的表。内容是动态的(可增删改)。
为何成功? 关系模型比网状、层次模型更为简单灵活。它隐藏了复杂的物理存储细节和存取路径,用户只需关心数据本身及其逻辑关系(通过表连接)。
核心语言:SQL (Structured Query Language) - 强大的声明式语言,用户只需说“要什么”(What),而不需指定“怎么取”(How)。
例如,查询“借了《数据库导论》这本书的所有读者姓名”,在关系数据库中,你只需用SQL描述这个逻辑需求(关联读者表、借阅表、图书表),DBMS会自动找到最优的存取路径执行。这大大降低了使用和开发的难度。
2.关系数据库特点:
- 数据独立性高(逻辑与物理分离)。
- 支持复杂的查询和强大的事务处理 (ACID)。
- 易于理解和使用(二维表直观)。
- 提供标准化的SQL语言。
- 能有效处理各种关系(1:1, 1:n, m:n 通过关联表)。
3.数据库示例 (验证其普及性):
Oracle Database - 企业级旗舰,功能全面强大。
MySQL - 开源、轻量、高性能,Web应用最爱。
Microsoft SQL Server - 深度集成Windows生态的企业级方案。
PostgreSQL - 开源、高度可靠、扩展性强,支持高级特性。
4.关系模型的优势
| 优势 | 说明 |
|---|---|
| 结构简单 | 使用直观的二维表格表示数据 |
| 数据独立性 | 物理数据存储与逻辑结构分离 |
| 强大的查询能力 | 通过SQL实现复杂查询 |
| 标准化 | SQL成为行业标准查询语言 |
| 完整性约束 | 提供丰富的数据完整性保障机制 |
| 事务支持 | 支持ACID事务,保证数据一致性 |
(三)第三代数据库系统
互联网、物联网、社交媒体的爆炸式增长带来了新挑战:数据量巨大(Volume)、类型繁多(Variety - 文本、图片、视频、日志)、产生速度极快(Velocity)、价值密度低(Value)——即大数据。
传统的关系数据库,为处理规整的事务型数据设计,在面对这些新型应用(如海量用户动态、实时传感器流、复杂对象关系图)时,开始显得力不从心。
从20世纪80年代开始,出现了许多新型应用,数据管理出现了许多新的数据模型,如面向对象模型、语义数据模型、 XML 数据模型、半结构化数据模型等。数据模型的发展,需要数据库系统支持日益复杂的数据类型。其中最典型的是No SQL(Not Only of SQL)运动。
1.NoSQL运动的兴起:
名称演变: 最初(1998)指“无SQL”的关系库 -> 后来(2009)主要指非关系型、分布式、不严格遵循ACID的设计模式。普遍解释为 “Not Only SQL” 或 “非关联型”。
驱动力: Web 2.0/社交网络(SNS)的超大规模、高并发、动态、半/非结构化数据需求。关系数据库的扩展性(尤其是水平扩展)、写入性能、灵活模式成为瓶颈。
核心理念: “select fun, profit from real_world where relational=false;” - 在关系模型不适用或低效的现实场景中选择合适的工具。
目标: 解决大规模数据集合和多重数据种类带来的挑战,特别是大数据应用难题。通常优先考虑可扩展性、性能和灵活性,在一致性上可能妥协(最终一致性)。
第三代数据库主要类型:
2.对象数据库
数据模型:对象数据库将数据存储为对象,类似于面向对象编程中的对象。每个对象包含数据和方法。
特点:
- 支持复杂的数据类型和面向对象的特性。
- 与面向对象编程语言集成度高,便于开发。
- 适合需要复杂数据结构和行为的应用。
示例:
ObjectDB:开源的对象数据库管理系统,支持Java持久化API (JPA) 和 Java Data Objects (JDO)。
db4o (database for objects):开源的对象数据库,支持多种编程语言,如Java和.NET。
3.NoSQL数据库 (多种模型):
数据模型:NoSQL数据库不使用传统的表格形式,而是采用更加灵活的数据模型,如键值对、文档、列族或图形。
特点:
- 高可扩展性,适合大规模分布式环境。
- 灵活的数据模型,支持非结构化和半结构化数据。
- 通常不支持完整的ACID事务,但提供最终一致性。
示例:
MongoDB:文档型NoSQL数据库,使用BSON格式存储数据,支持动态模式和丰富的查询功能。
Cassandra:列族存储的NoSQL数据库,设计用于处理大规模数据集,具有高可用性和水平扩展性。
Redis:内存数据存储,可以用作数据库、缓存和消息中间件,支持多种数据结构如字符串、哈希、列表等。
Neo4j:图形数据库,专门用于处理复杂的图形数据和关系,适用于社交网络、推荐系统等领域。
4.为什么NOSQL数据库比关系型数据库更适合大型分布式系统?
| 特性 | NoSQL数据库 | 关系型数据库 (RDBMS) | 为什么NoSQL更优 (在特定场景下) |
|---|---|---|---|
| 数据模型 | 灵活 (键值、文档、列、图) | 固定/严格 (表格,需预定义Schema) | 适应快速变化、非/半结构化数据,无需昂贵Schema变更。 |
| 扩展方式 | 水平扩展 (添加节点) 为主,天然分布式设计 | 垂直扩展 (升级单机) 为主,水平扩展 (分库分表) 复杂 | 轻松应对海量数据和高流量,成本更低廉。 |
| 一致性模型 | 通常最终一致性 (优先保证可用性和分区容忍性) | 强一致性 (ACID事务) | 在分布式环境下,强一致性会严重限制性能和可用性。 |
| 读写性能 | 极高 (尤其特定模式,如Key访问、批量写) | 高 (但复杂Join、事务会成瓶颈) | 满足高并发、低延迟需求,尤其写入密集型场景。 |
| 管理与运维 | 更简单 (自动化分片、复制、恢复) | 更复杂 (尤其大规模集群的分片、复制、备份) | 降低大规模分布式系统的运维成本和复杂性。 |
(1)数据模型的灵活性
NoSQL数据库通常支持灵活的数据模型,如键值对、文档、列族或图形。关系型数据库使用固定的数据模型(表格形式),并且需要预先定义好表结构(模式)。这种严格的模式要求在扩展时可能会变得复杂。
(2)水平扩展能力
NoSQL数据库通常设计为可以轻松进行水平扩展,即通过增加更多的服务器节点来提高系统的处理能力和存储容量。传统的关系型数据库通常是垂直扩展的,即通过增加单个服务器的硬件资源(如CPU、内存、磁盘)来提高性能。
(3)一致性和容错性
NoSQL数据库通常采用最终一致性模型,这意味着在某些情况下,系统可以在一段时间内容忍不一致的状态,以换取更高的可用性和性能。关系型数据库通常遵循ACID(原子性、一致性、隔离性、持久性)事务原则,保证了强一致性。强一致性要求在分布式环境中实现起来更加复杂,特别是在跨多个节点的情况下。
(4)写入和读取性能。
NoSQL数据库通常优化了写入和读取性能,尤其是在高并发环境下。例如,Redis作为一个内存数据库,提供了极高的读写速度。关系型数据库在处理大量并发写入和读取时可能会遇到瓶颈,尤其是在需要执行复杂的联接操作时。虽然关系型数据库也有优化措施(如索引、缓存等),但在大规模分布式环境中,这些优化可能不足以满足高性能需求。
(5)管理和运维
NoSQL数据库通常设计为易于管理和运维,自动化的数据分布和故障恢复机制减少了手动干预的需求。关系型数据库在大规模分布式环境中可能需要更多的手动配置和管理,特别是在数据复制、备份、恢复等方面。
(四)核心术语解析
理解了数据模型和数据库类型,让我们明确几个最基础但至关重要的术语,它们是理解整个数据库领域的基石。
1.数据 (Data):
描述事物的符号记录。形式多样:文字、数字、图形、图像、声音等。
案例: “25℃", “张三”, “https://example.com/photo.jpg” 都是数据。
2.信息 (Information)
信息是数据经过处理后得到的、对接收者具有特定意义和价值的结果。它是现实世界事物存在方式或状态的反映。
今天气温25℃” 是数据,结合“人体舒适温度是22-26℃”这个知识,你就得到了“今天天气舒适”这个信息。信息能减少不确定性、辅助决策。
数据是信息的载体和表现形式,信息是数据的含义和价值体现。
3.数据库 (DB, DataBase)
长期储存在计算机内、有组织的、可共享的、统一管理的相关数据的集合。
数据间联系密切、冗余度小、独立性较高、易扩展、可共享。
存储数据的物理介质(硬盘、SSD)及其上按模型组织的数据本身。
4.数据库管理系统 (DBMS, DataBase Management System)
位于用户和操作系统之间的一层数据管理软件。它是数据库系统的核心。
科学组织存储数据、高效获取维护数据。核心功能包括:
- 数据定义 (DDL): 定义数据库结构 (创建/修改表等)。
- 数据操纵 (DML): 查询、插入、删除、修改数据 (SQL的核心)。
- 数据库运行管理: 并发控制、安全性检查、完整性检查、故障恢复等。
- 数据库维护: 备份、恢复、性能监控、重组等。
5.数据库系统 (DBS, DataBase System):
采用数据库技术存储和管理数据的计算机系统。广义上,它包括:
- 数据库 (DB)
- 数据库管理系统 (DBMS)
- 应用系统
- 数据库管理员 (DBA)
- 用户
简单理解: DBS = DB + DBMS + 相关的软硬件和人。
关键关系比喻:
-
DB 是图书馆的藏书库(书+书架)。
-
DBMS 是图书馆的管理系统(借还书流程、管理员、编目规则)。
-
DBS 是整个图书馆实体(书库+管理系统+管理员+读者+借阅规则)。
三、数据库管理系统
想象一下,如果一个公司没有统一的仓库,每个部门都用自己的Excel表存放数据:销售部存一份客户信息,财务部存另一份,两边的数据还经常对不上。这简直就是一场数据灾难!
而数据库管理系统(DBMS)就是这个混乱世界的救星。
DBMS 实现了对共享数据有效地组织、管理和存取,因此DBMS应具有如下几个方面的功能及特征。
(一)DBMS功能
DBMS功能主要包括数据定义、数据库操作、数据库运行管理、数据组织、存储和管理、数据库的建立和维护。
1.数据定义(DDL)
DBMS提供数据定义语言 (Data Definition Language,DDL), 可以对数据库的结构进行描述,包括外模式、模式和内模式的定义;数据库的完整性定义;安全保密定义,如口令、级别和存取权限等。
DDL不是操作数据本身,而是定义数据的“形状”和“规则”。
-- 1.创建表 (定义结构)
-- 请你准备一个表格,规定好:
-- 必须有三列:ID(数字,主键)、名字(字符串,非空)、邮箱(字符串,唯一)
-- 这就是规矩,以后所有数据都得按这个来”
CREATE TABLE users (id INT PRIMARY KEY,name VARCHAR(100) NOT NULL,email VARCHAR(100) UNIQUE
);
-- 2. 修改表结构
-- “还得记录用户的手机号,在表格里加一列”
ALTER TABLE users ADD COLUMN phone VARCHAR(20);-- 3. 删除表
-- “整个`users`表我不要了,连规矩带数据全扔掉”
DROP TABLE users;
这些定义存储在数据字典中,是 DBMS 运行的基本依据。
DDL就是你用来设计和建造仓库货架(数据库结构)的工具,而不是往货架上放货物(数据)。
2.数据库操作(DML)
DBMS 向用户提供数据操纵语言 (Data Manipulation Language,DML), 实现对数据库中数据的基本操作,如检索、插入、修改和删除。
-- 1. 检索 (Retrieve) - SELECT
SELECT * FROM users WHERE name = '小王';-- 2. 插入 (Insert) - INSERT
INSERT INTO users (name, email) VALUES ('小李', 'lw@example.com');-- 3. 修改 (Update) - UPDATE
UPDATE users SET email = 'wang.new@example.com' WHERE name = '小王';-- 4. 删除 (Delete) - DELETE
DELETE FROM users WHERE name = '小李';
3.数据库运行管理。
数据库在运行期间,多用户环境下的并发控制、安全性检查和存取控制、完整性检查和执行、运行日志的组织管理、事务管理和自动恢复等都是DBMS 的重要组成部分。这些功能可以保证数据库系统的正常运行。
防止“超卖”的经典案例:假设有两个用户同时试图购买最后一件商品。
-- 事务 (Transaction) 开始
BEGIN TRANSACTION;-- 1. 用户A的会话执行:查询库存,结果是1
SELECT stock FROM products WHERE id = 123; -- stock = 1-- 2. 几乎同时,用户B的会话也执行了同样的查询,看到的stock也是1
SELECT stock FROM products WHERE id = 123; -- stock = 1-- 3. 用户A下单,库存减1
UPDATE products SET stock = stock - 1 WHERE id = 123;
COMMIT; -- 提交事务,库存变为0-- 4. 用户B也下单,试图库存减1
UPDATE products SET stock = stock - 1 WHERE id = 123; -- 此时库存已经是0了!
COMMIT;
-- 如果没有并发控制,库存就会变成-1,这就是“超卖”
4.数据组织、存储和管理。
DBMS 分类组织、存储和管理各种数据,包括数据字典、用户数据和存取路径等。
要确定以何种文件结构和存取方式在存储级别上组织这些数据,以提高存取效率。
实现数据间的联系、数据组织和存储的基本目标是提高存储空间的利用率。
例如,baidu要索引整个互联网的数据。它不可能每次搜索都去扫描几十亿个网页。DBMS(或类似系统)会以极其高效的方式(如倒排索引)组织和存储数据,让你在毫秒级内得到结果。
5.数据库的建立和维护。
数据库的建立和维护,包括数据库的初始建立、数据的转换、数据库的转储和恢复、数据
库的重组和重构、性能监测和分析等。
6.其他功能。
如DBMS 与网络中其他软件系统的通信功能,一个DBMS 与另一个 DBMS或文件系统的数据转换功能等。
(二) DBMS 的特点
通过 DBMS来管理数据具有如下特点:
1.数据结构化且统一管理。
数据库中的数据由DBMS统一管理。由于数据库系统采用数据模型表示数据结构,数据模型不仅描述数据本身的特点,还描述数据之间的联系。
数据不再面向某个应用,而是面向整个企业内的所有应用。数据易维护、易扩展,数据冗余明显减少,真正实现了数据的共享。
(1)无DBMS(文件系统)的问题:
假设一个公司,销售部用 sales.txt 文件管理客户,客服部用 support.csv 文件管理客户。
- 数据冗余:两个文件都存了客户的姓名、电话,造成重复。
- 数据不一致:销售部更新了客户的电话,但客服部的文件还是旧号码。
- 孤立数据:销售部的文件里有客户的购买记录,客服部无法直接获取和使用这个信息。
- 程序依赖数据存储方式:如果
sales.txt的格式从逗号分隔改成制表符分隔,所有读取这个文件的程序都需要重写。
(2)有DBMS的解决方案:
DBMS让我们可以建立结构化的、互相关联的表。
-- 1. 数据定义:建立结构化的、有关联的表
-- “客户”表,存储所有客户的核心信息
CREATE TABLE customers (customer_id INT PRIMARY KEY, -- 主键,唯一标识一个客户name VARCHAR(100) NOT NULL,phone VARCHAR(20) NOT NULL
);-- “订单”表,存储客户的购买记录
CREATE TABLE orders (order_id INT PRIMARY KEY,order_date DATE NOT NULL,amount DECIMAL(10, 2) NOT NULL,customer_id INT NOT NULL, -- 外键,指向 customers 表的 customer_idFOREIGN KEY (customer_id) REFERENCES customers(customer_id) -- 建立外键关系
);-- “服务工单”表,存储客户的支持请求
CREATE TABLE support_tickets (ticket_id INT PRIMARY KEY,issue_description TEXT,status VARCHAR(20),customer_id INT NOT NULL, -- 外键,同样指向 customers 表FOREIGN KEY (customer_id) REFERENCES customers(customer_id) -- 建立外键关系
);
-
统一管理,共享数据:销售部和客服部都通过DBMS操作唯一的 customers 表。客户的电话在这里只存一份,任何部门修改,其他部门看到的就是最新数据。
-
数据关联:我们可以轻松地查询出“所有下过订单但从未提交过服务工单的优质客户”:
-
易维护和扩展:如果需要给客户增加一个“会员等级”属性,只需一条SQL,所有程序都能立即使用这个新字段,而无需改变程序读取数据的方式。
2.有较高的数据独立性。
数据的独立性是指数据与程序独立,将数据的定义从程序中分离出去,由 DBMS负责数据的存储,应用程序关心的只是数据的逻辑结构,无须了解数据在磁盘上的存储形式,从而简化应用程序,大大减少应用程序编制的工作量。
数据的独立性包括数据的物理独立性和数据的逻辑独立性。
(1)物理独立性:改变存储结构,不影响应用程序
指数据的物理存储结构(如硬盘上的文件格式、索引类型、存储路径)的改变,不需要修改应用程序。
假设我们一开始的数据没有索引,查询很慢。
-- 应用程序的查询语句
SELECT * FROM orders WHERE customer_id = 123;
-- DBA 在后台执行的优化操作,应用程序完全无感知
CREATE INDEX idx_orders_customer_id ON orders (customer_id);
之后同样的 SELECT 查询语句,速度得到了巨大提升,但应用程序的代码一行都不用改。DBMS自动选择了更高效的存取路径(使用新索引)来执行这条查询。
反之亦然,DBA甚至可以决定把 orders 表从一个硬盘迁移到另一个更快的SSD硬盘上,应用程序也完全感觉不到变化。
(2)逻辑独立性:改变逻辑结构,尽可能不影响应用程序
指数据库的逻辑结构(如表结构、视图)发生改变,理论上可能影响应用程序,但DBMS提供了机制(如视图)来尽量减少这种影响。
假设我们最初的 customers 表有很多字段,但某个应用程序只需要 name 和 phone。
-- 应用程序的查询语句
SELECT name, phone FROM customers;
后来,业务需求变化,我们需要将 customers 表拆分成 customer_details 和 customer_contacts 两个表。
-- 数据库结构变更
CREATE TABLE customer_details (customer_id INT PRIMARY KEY,name VARCHAR(100)-- ... 其他字段
);
CREATE TABLE customer_contacts (customer_id INT PRIMARY KEY,phone VARCHAR(20)-- ... 其他字段
);
如果我们直接删除旧的 customers 表,那么之前那个应用程序的查询就会报错,因为它依赖的表不存在了。这就是逻辑依赖。
DBMS如何提供逻辑独立性?—— 使用视图(View)。
我们可以创建一个名为 customers 的视图,它模拟出原来表的结构。
CREATE VIEW customers AS
SELECT d.customer_id, d.name, c.phone
FROM customer_details d
JOIN customer_contacts c ON d.customer_id = c.customer_id;
之后,应用程序依然执行 SELECT name, phone FROM customers;,它甚至不知道自己查询的不再是一张真实的表,而是一个视图。DBMS会自动将查询转换成对底层 customer_details 和 customer_contacts 表的连接操作。
这样,虽然数据库的逻辑结构发生了巨大变化(表被拆分),但通过视图这个抽象层,保护了上层的应用程序免受影响,这就是逻辑独立性。
3.数据控制功能。
DBMS提供了数据控制功能,以适应共享数据的环境。数据控制功能包括对数据库中数据的安全性、完整性、并发和恢复的控制。
(1)安全性
数据库的安全性 (Security) 是指保护数据库以防止不合法的使用所造成的数据泄露、更改或破坏。这样,用户只能按规定对数据进行处理,例如,划分了不同的权限,有的用户只有读数据的权限,有的用户有修改数据的权限,用户只能在规定的权限范围内操纵数据库。
-- 1. 管理员给不同用户授权
-- “管家,让实习生`intern01`只有读`users`表的权限”
GRANT SELECT ON users TO intern01;-- “管家,让经理`manager01`可以读、可以改`users`表”
GRANT SELECT, INSERT, UPDATE ON users TO manager01;-- 2. 实习生`intern01`试图删表,会直接被管家拒绝
DELETE FROM users; -- 执行错误: Access denied (权限不足)
(2)完整性 (Integrality)
数据的完整性是指数据库正确性和相容性,是防止合法用户使用数据库时向数据库加入不符合语义的数据。保证数据库中数据是正确的,避免非法的更新。
-- 1. 非空约束 (NOT NULL)
-- 试图插入一个没有名字的用户,管家会拒绝
INSERT INTO users (id, email) VALUES (1, 'test@example.com'); -- 错误!-- 2. 唯一约束 (UNIQUE)
-- 试图插入一个重复的邮箱,管家会拒绝
INSERT INTO users (id, name, email) VALUES (2, '小张', 'wang.new@example.com'); -- 错误!邮箱和‘小王’的一样了
(3)并发控制 (concurrency control)
并发控制是指在多用户共享的系统中,许多用户可能同时对同一数据进行操作。 DBMS的并发控制子系统负责协调并发事务的执行,保证数据库的完整性不受破坏,避免用户得到不正确的数据。
DBMS管家会使用锁(Locking) 或多版本并发控制(MVCC) 等机制。比如,在用户A开始修改库存时,DBMS会自动给这条数据加上锁,用户B的更新操作必须等待,直到用户A的锁释放(事务提交)后才会继续。此时用户B看到库存已是0,更新就会失败,从而保证了数据的一致性。
(4)故障恢复 (recovery from failure)
数据库中的常见故障是事务内部故障、系统故障、介质故障及计算机病毒等。故障恢复主要是指恢复数据库本身,即在故障导致数据库状态不一致时,将数据库恢复到某个正确状态或一致状态。
-- 一个银行转账事务:从A账户转100元到B账户
BEGIN TRANSACTION; -- 事务开始UPDATE accounts SET balance = balance - 100 WHERE name = 'A';
UPDATE accounts SET balance = balance + 100 WHERE name = 'B';-- 此时,系统突然断电!
- 没有DBMS的情况:A的钱扣了,B的钱没收到,100元不翼而飞。
- 有DBMS的情况:DBMS管家在做事务时,会先把要做的操作(“A-100”, “B+100”)记录到日志文件中。断电重启后,管家检查日志,发现这个事务没有完成(COMMIT记录)。它会自动利用日志回滚(ROLLBACK) 这个未完成的事务,将A的账户余额加回100元,就像这个转账从来没发生过一样。这就保证了交易的原子性——要么完全发生,要么完全不影响系统。
恢复的原理非常简单,就是要建立冗余 (redundancy) 数据。
换句话说,确定数据库是否可恢复的方法就是其包含的每一条信息是否都可以利用冗余的存储在别处的信息重构。
四、数据库三级模式
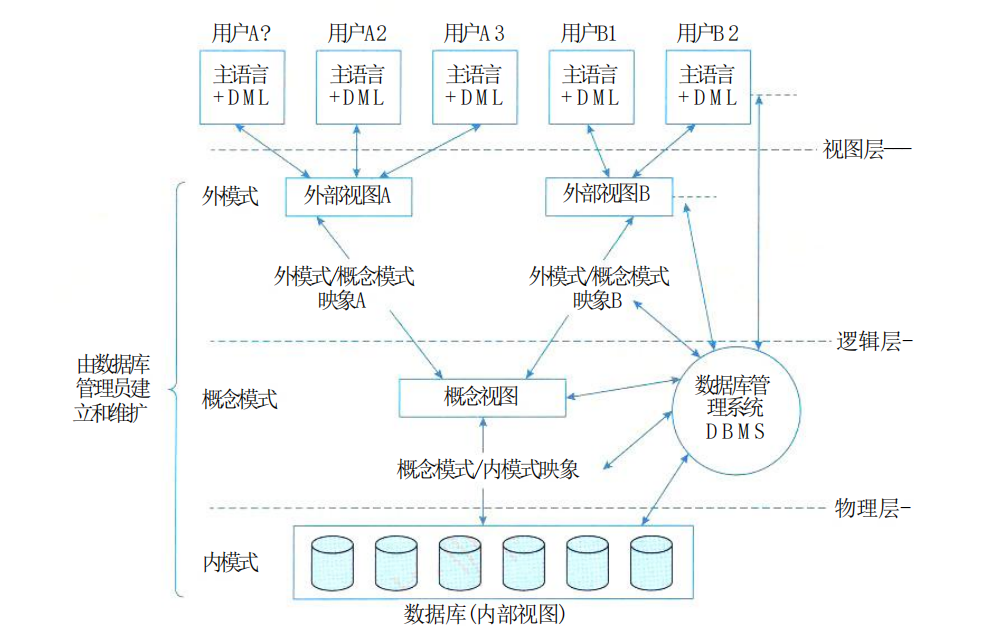
站在数据库管理系统的角度看,数据库系统一般采用三级模式结构,其体系结构如图所示。
事实上,一个可用的数据库系统必须能够高效地检索数据。这种高效性的需求促使数据库设计者使用复杂的数据结构来表示数据。
可以把一个数据库想象成一座繁华的城市。城市规划局需要管理这座城市的方方面面,但不同的人需要看到城市的不同视图:
-
游客:只关心景点、餐厅和酒店(外模式)。
-
市长/城市规划师:关心城市的整体布局、功能区划分和建筑规范(概念模式)。
-
市政工程师:关心地下管线、地基结构、建筑材料(内模式)。
数据库的三级模式结构正是为了高效、安全地管理这座“数据城市”而设计的蓝图。
(二)三级模式结构
数据库系统采用三级模式结构,这是数据库管理系统内部的系统结构。
数据库有“型”和“值”的概念,“型”是指对某一数据的结构和属性的说明,“值”是型的一个具体赋值。
从数据库管理系统的角度,数据库也分为三级模式,分别是外模式、概念模式和内模式。
1.概念模式
概念模式也称模式,是数据库中全部数据的逻辑结构和特征的描述,它由若干个概念记录类型组成,只涉及“型”的描述,不涉及具体的值。
概念模式的一个具体值称为模式的一个实例,同一个模式可以有很多实例。
概念模式反映的是数据库的结构及其联系,所以是相对稳定的;而实例反映的是数据库某一时刻的状态,是相对变动的。
数据库管理员 (DBA) 使用 DDL 来定义概念模式。
-- 定义订单表的结构
CREATE TABLE Orders (OrderID INT PRIMARY KEY,OrderDate DATE NOT NULL,TotalAmount DECIMAL(10, 2),UserID INT NOT NULL, -- 这条“路”连接回Users区FOREIGN KEY (UserID) REFERENCES Users(UserID) -- 外键约束,定义“联系”
);
这个模式定义了数据的结构和规则。任何应用程序如果想在这个城市里“建房”或“修路”(操作数据),都必须遵守这些规划。它是系统中最稳定、最核心的一层。
需要说明的是,概念模式不仅要描述概念记录类型,还要描述记录间的联系、操作、数据的完整性和安全性等要求。
但是,概念模式不涉及存储结构、访问技术等细节。只有这样,概念模式才算做到了“物理数据独立性”。
2.外模式
外模式也称用户模式或子模式,是用户与数据库系统的接口,是用户需要使用的部分数据的描述。它由若干个外部记录类型组成。
用户使用数据操纵语言对数据库进行操作,实际上是对外模式的外部记录进行操作。
使用 VIEW 来创建外模式。
-- 为销售人员创建一个视图(外模式)
-- 他们只需要看到客户姓名和订单金额,不需要看到客户的邮箱等敏感信息
CREATE VIEW SalesView AS
SELECT u.UserName AS CustomerName,o.OrderDate,o.TotalAmount
FROM Users u
INNER JOIN Orders o ON u.UserID = o.UserID;-- 销售人员可以像查询普通表一样使用这个视图,完全不知道底层复杂的连接
SELECT * FROM SalesView WHERE TotalAmount > 1000;
每个视图都是从总体规划(概念模式)中派生出来的子集或转换,它屏蔽了不需要的细节,并保证了安全性。
通过外模式,你可以轻松地创建一个视图,其中自动过滤掉了所有未明确同意营销条款的用户数据。应用程序无需修改任何代码,只需查询这个视图,就能天然地遵守数据隐私法规。这就是逻辑数据独立性的威力——修改逻辑结构(增加隐私控制)而不影响应用程序。
3.内模式
内模式也称存储模式,是数据物理结构和存储方式的描述,是数据在数据库内部的表示方式。定义所有的内部记录类型、索引和文件的组织方式,以及数据控制方面的细节。
内模式通常由 DBA 通过特定的 SQL 扩展来定义和优化。
-- 在‘Users’表的‘UserName’列上创建一个索引,就像为城市制作一个姓名目录
-- 这样按名字查找用户的速度会极大提高
CREATE INDEX idx_users_username ON Users (UserName);-- 为‘Orders’表选择一种特定的存储引擎(MySQL示例)
-- 这决定了数据在磁盘上如何被组织、索引和缓存
ALTER TABLE Orders ENGINE = InnoDB;-- 配置数据库的物理文件布局(通常在生产环境初始化时设定)
-- 例如:将频繁访问的‘Orders’表的数据文件放在更快的SSD硬盘上,
-- 而将归档的日志表放在更大的机械硬盘上。
-- (这通常是数据库配置文件的设置,而非标准SQL)
应用程序和普通用户完全看不到也不需要关心内模式。无论工程师是把数据从HDD迁移到SSD,还是改变索引类型,只要概念模式不变,上层应用就毫无感知。这就是物理数据独立性。
总之,数据按外模式的描述提供给用户,按内模式的描述存储在磁盘上,而概念模式提供了连接这两极模式的相对稳定的中间观点,并使得两级的任意一级的改变都不受另一级的牵制。
(二)三层架构
由于大多数数据库系统用户并未受过计算机的专业训练,因此系统开发人员需要通过视图层、逻辑层和物理层三个层次上的抽象来对用户屏蔽系统的复杂性,简化用户与系统的交互。
1.视图层 (View Level)
视图层是最高层次的抽象,描述整个数据库的某个部分的数据。
因为数据库系统的很多用户并不关心数据库中的所有信息,而只关心所需要的那部分数据。可以通过构建视图层来实现用户的数据需求,这样做不仅使用户与系统交互简化,而且还可以保证数据的保密性和安全性。
例子:
- 普通顾客看到的商品列表(只包含商品名、图片、售价、评分)。
- 商家后台看到的则是另一个视图(包含成本、库存、月销量)。
- 物流人员看到的又是另一个视图(仅包含订单号、收货地址、配送状态)。
每个用户只能看到和理解他们需要的数据,界面简单友好,同时也保证了数据安全(顾客看不到商品的成本,物流看不到商品的价格)。
2.逻辑层 (Logical Level)
逻辑层是比物理层更高一层的抽象,描述数据库中存储的数据以及这些数据间存在的关系。
逻辑层通过相对简单的结构描述了整个数据库。尽管逻辑层简单结构的实现涉及了复杂的物理层结构,但逻辑层的用户不必知道这些复杂性。因为,逻辑层抽象是数据库管理员的职责,管理员确定数据库应保存哪些信息。
例如:数据库中的表结构(Schema)。
-- 这就是在定义逻辑层的结构
CREATE TABLE Users (user_id INT PRIMARY KEY,username VARCHAR(50),email VARCHAR(100)
);
CREATE TABLE Products (product_id INT PRIMARY KEY,product_name VARCHAR(100),price DECIMAL(10, 2)
);
CREATE TABLE Orders (order_id INT PRIMARY KEY,user_id INT,order_date DATE,FOREIGN KEY (user_id) REFERENCES Users(user_id) -- 定义了“关系”
);
数据库管理员(DBA)和应用程序开发者关心这一层。他们用SQL语句(如 SELECT * FROM Orders WHERE user_id = 123;)来操作数据,而无需关心数据是存在SSD硬盘还是机械硬盘上。
3.物理层 (Physical Level)
物理层是最低层次的抽象,描述数据在存储器中是如何存储的。物理层详细地描述复杂的底层结构。
例子:
- 数据是以堆文件形式存储,还是B+树索引形式组织?
- 数据文件在磁盘的哪个块(Block)上?
- 是否使用了数据压缩或加密技术?
数据库系统本身负责这一层,目标是实现最高效的存储和检索。用户和开发者完全感知不到它的存在。
比如,你执行一条查询语句,数据库引擎会自动决定是走全表扫描还是使用索引,这个过程对你是透明的。而像excel表或txt文件,比如改下从ASCII到Unicode的编码,程序就需要重新读取文件了。
实际上,数据库的产品很多,它们支持不同的数据模型,使用不同的数据库语言,建立在不同的操作系统上,而且数据的存储结构也各不相同,但基本上都支持三级模式。
| 三层架构 (为用户抽象) | 三级模式 (在DBMS内实现) | 比喻 | 主要操作者 |
|---|---|---|---|
| 视图层 | 外模式 (Views) | 房间的窗户 | 最终用户 |
| 逻辑层 | 概念模式 (Tables, Schema) | 建筑蓝图 | 开发者、DBA |
| 物理层 | 内模式 (Indexes, Storage) | 建材与地基 | DBMS自身、资深DBA |