深度学习周报(8.18~8.24)
目录
摘要
Abstract
1 CNN代码实现
2 CNN经典网络架构演变
2.1 LeNet-5 (1998)
2.2 AlexNet (2012)
2.3 VGGNet (2014)
2.4 GoogLeNet (2014)
2.5 ResNet (2015)
3 总结
摘要
本周首先通过代码加深了对CNN的基本网络结构(卷积+激活+池化+全连接)的理解,其次学习了CNN经典网络架构(包括LeNet-5、AlexNet、ResNet等)的结构特点及其演变过程,并动手实现了部分基础模块,有效巩固了对CNN整体架构与设计思想的认识。
Abstract
This week, I first deepened my understanding of the fundamental CNN network structure (convolution + activation + pooling + fully connected) through coding. Then, I studied the structural characteristics and evolutionary process of classic CNN architectures, including LeNet-5, AlexNet, ResNet and so on. By implementing some basic modules hands-on, I effectively reinforced my comprehension of the overall CNN architecture and its design principles.
1 CNN基本结构代码构建
由于是初次构建CNN网络模型,自己设计稍显困难,所以依据网上的模型结构进行代码构建,结构图大致如下: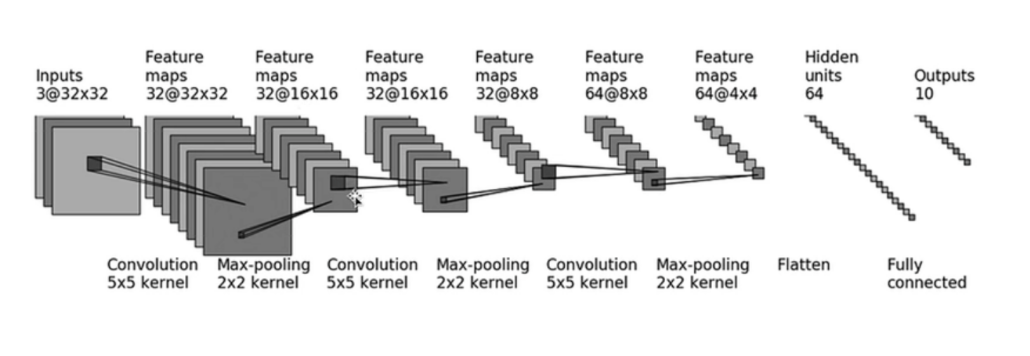
由于上述过程中,卷积核大小固定为5*5,且经过卷积层后,图像大小均保持不变,可得填充尺寸为2。于是可定义模型如下:
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, ReLUclass CF(nn.Module): #定义一个继承自nn.Module的类def __init__(self):super(CF, self).__init__() # 3为输入通道数,32为输出通道数(卷积核数量),5为卷积核尺寸,padding为填充(以下类似)# 3*32*32 -> 32*32*32self.conv1 = Conv2d(3, 32, 5, padding=2)# 添加激活函数层self.relu1 = ReLU()# 2为池化核尺寸 32*32*32 -> 32*16*16self.maxpool1 = MaxPool2d(2)# 32*16*16 -> 32*16*16self.conv2 = Conv2d(32, 32, 5, padding=2)self.relu2 = ReLU()# 32*16*16 -> 32*8*8self.maxpool2 = MaxPool2d(2)# 32*8*8 -> 64*8*8self.conv3 = Conv2d(32, 64, 5, padding=2)self.relu3 = ReLU()# 64*8*8 -> 64*4*4=1024self.maxpool3 = MaxPool2d(2)self.flatten = Flatten()# 1024 -> 364self.linear1 = Linear(1024, 64)self.relu4 = ReLU()# 64 -> 10self.linear2 = Linear(64, 10)def forward(self, x):x = self.conv1(x)x = self.relu1(x)x = self.maxpool1(x)x = self.conv2(x)x = self.relu2(x)x = self.maxpool2(x)x = self.conv3(x)x = self.relu3(x)x = self.maxpool3(x)x = self.flatten(x)x = self.linear1(x)x = self.relu4(x)x = self.linear2(x)return x以上代码可以利用Sequetial这个容器类进行简化,如下所示:
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential, ReLUclass CF(nn.Module):def __init__(self):super(CF, self).__init__() self.model = Sequential(Conv2d(3, 32, 5, padding=2),ReLU(),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),ReLU(),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),ReLU(),MaxPool2d(2),Flatten(),Linear(1024, 64),ReLU(),Linear(64, 10))def forward(self, x):x = self.model(x)return x2 CNN经典网络架构演变
2.1 LeNet-5 (1998)
LeNet-5 由Yann LeCun等人提出,是最早的CNN之一,最初应用于手写数字识别(如MNIST),是现代深度学习发展的奠基性模型之一。它首次完整的提出前面学习的,即我们现在熟知的 CNN 架构:卷积 + 激活 + 池化 + 全连接,是LeNet系列中最成熟完整并被广泛引用和复现的版本。
LeNet-5主要包括三个卷积层(C1、C3、C5)、两个池化层(S2、S4)与两个全连接层(F6、Output),其中C5层使用 5*5 的卷积核作用在 5*5 的输入图像上,实际等价于一个全连接层。其输入尺寸在原始 LeNet-5 中是固定的 32*32 单通道图像,但在现代实现中可以调整。另外,由于当时最大池化还未普及,所以LeNet-5 的池化层使用的是平均池化方法。同样当时常用的激活函数是Tanh,而非如今的ReLU。
代码如下:
from torch import nn
from torch.nn import Conv2d, AvgPool2d, Flatten, Linear, Sequential, Tanhclass LeNet5(nn.Module):def __init__(self):super(LeNet5, self).__init__()#特征提取self.features = Sequential(# C1(输入通道数为1,输出通道数(卷积核数)为6,卷积核大小5*5,无填充,以下类似)# 1*32*32 -> 6*28*28Conv2d(1, 6, 5),Tanh(),# S2 6*28*28 -> 6*14*14AvgPool2d(2),# C3 6*14*14 -> 16*10*10Conv2d(6, 16, 5),Tanh(),# S4 16*10*10 -> 16*5*5AvgPool2d(2),)#分类self.classifier = Sequential(# C5 16*5*5 -> 120*1*1Conv2d(16, 120, 5), Tanh(),# 展平Flatten(),# F6 120 -> 84Linear(120, 84),Tanh(),# Output 84 -> 10Linear(84, 10))def forward(self, x):x = self.features(x)x = self.classifier(x)return x之所以不直接映射到10,是为了增加非线性表达能力,同时提供更好的容量控制灵活性,84 是一个“瓶颈维度”,既不过分压缩,也不过度膨胀,起到特征提炼的作用。
LeNet-5 的优点是结构简单、计算量小,比较适合基础学习与小规模任务,缺点是网络深度浅、难以处理复杂的图像分类任务,精度也有限。
2.2 AlexNet (2012)
AlexNet 由Alex Krizhevsky等人提出,在ImageNet大规模视觉识别挑战赛(ILSVRC)上取得了突破性胜利,它证明了深度 CNN 的有效性,开启了深度学习的新时代。
AlexNet 的输入图像尺寸通常为 3*227*227,网络由 8 个带权重的层(5 个卷积层 + 3 个全连接层)以及多个激活函数、池化、归一化和正则化层组成。在此基础上,它能取得突破性进展的主要原因还是引入了ReLU、重叠池化、局部响应归一化和Dropout等多项关键技术。
其中ReLU可以有效缓解梯度消失问题(主要应用在所有卷积层与前两个全连接层之后),Dropout可以随机忽略一部分神经元,从而有效防止过拟合(主要应用在前两个全连接层的输入),这两者在前面的学习都有提到;重叠池化是指池化区域有重叠的池化方法,具体表现为池化核尺寸大于池化步长,这也能降低过拟合,并提供较好的性能;局部响应归一化(LRN)的灵感来源于神经生物学中的侧抑制概念,通常作用于邻近的神经元输出,而这些输出可能是同一空间位置不同通道上的激活值(一般应用在前两个卷积层后)。
代码如下:
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential, ReLU, LocalResponseNormclass AlexNet(nn.Module):def __init__(self, num_classes=1000):super(AlexNet, self).__init__()# 特征提取self.features = Sequential(#输入通道数为3,输出通道数为96,卷积核大小11*11,步长为4,无填充,以下类似# 3*227*227 -> 96*55*55Conv2d(3, 96, 11, stride=4, padding=0),#inplace默认为False,True代表直接在输入张量的位置进行修改,不需要额外的内存空间ReLU(inplace=True), # 96*55*55 -> 96*27*27,池化核大小3*3MaxPool2d(3, stride=2),# LRNLocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2),# 96*27*27 -> 256*27*27Conv2d(96, 256, 5, stride=1, padding=2),ReLU(inplace=True),# 256*27*27 -> 256*13*13MaxPool2d(3, stride=2),# LRNLocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2),# 256*13*13 -> 384*13*13(增加网络的宽度和表达能力)Conv2d(256, 384, 3, stride=1, padding=1),ReLU(inplace=True),# 384*13*13 -> 384*13*13(进一步提炼和组合特征)Conv2d(384, 384, 3, stride=1, padding=1),ReLU(inplace=True),# 384*13*13 -> 256*13*13(降维并准备输入全连接层)Conv2d(384, 256, 3, stride=1, padding=1),ReLU(inplace=True),# 256*13*13 -> 256*6*6MaxPool2d(3, stride=2),)self.flatten = Flatten()# 分类器self.classifier = Sequential(# FC6nn.Dropout(p=0.5), # 6*6*256 = 9216 -> 4096Linear(6 * 6 * 256, 4096),ReLU(inplace=True),# FC7 全连接: 4096 -> 4096,维度看似没变,实际会学习到不同的、更复杂的特征表示nn.Dropout(p=0.5),Linear(4096, 4096),ReLU(inplace=True),# FC8 全连接: 4096 -> num_classesLinear(4096, num_classes))def forward(self, x):x = self.features(x)x = self.flatten(x)x = self.classifier(x)return x除此之外,AlexNet还引入了数据增强技术,这种技术通过人为地增加训练数据的多样性(例如对图像进行裁剪、旋转以及颜色扰动),可以显著提高模型的泛化能力,并有效防止过拟合。
AlexNet使用深度网络提高了分类精度,可以处理复杂的图像数据,但计算量较大,训练时间长。
2.3 VGGNet (2014)
VGGNet 由牛津大学Visual Geometry Group提出,典型的有VGG16 (包含 13 个卷积层和 3 个全连接层,总共 16 个带权重的层)与VGG19 (包含 16 个卷积层和 3 个全连接层,总共 19 个带权重的层)。它证明了增加网络深度(使用更小的卷积核堆叠)可以显著提升性能。
在卷积核的计算中,可以发现连续使用两个 3*3 卷积层可以拥有与一个 5*5 卷积层相同的感受野,第一个 3×3 卷积的每个输出点看到输入的 3×3 区域,第二个 3×3 卷积的输入是第一个卷积的输出,每个点对应原始输入的 3×3 区域,当前层一个点看前一层的 3×3 邻域,每个邻域点又看原始输入的 3×3 区域,这些区域合并后,中心点能覆盖原始输入的 5×5 区域。
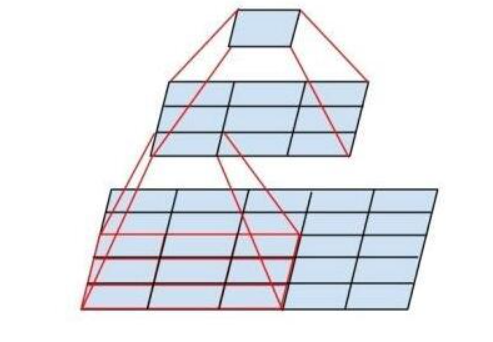
这样设计,在中间层(输入与输出通道数量接近的情况下)堆叠的小卷积核比大卷积核的优势更加明显,比如输入通道与输出通道均为256,如果使用一个5*5的卷积核,参数量应为5*5*256*256 =1638400;若使用两个3*3的卷积核,参数量应为2*3*3*256*256=1179648。显然后者参数更少,计算量更小,在实际应用中多个卷积层还可以引入更多的非线性以增强模型的表达能力。
当然,在前面AlexNet的代码中,后三个卷积层也连续使用了三个 3*3 的小卷积核,但那更多是为了在保持空间分辨率的同时进行深度特征提取和降维(为 FC 层准备),而不是像 VGG 这样系统性地进行替代。
VGGNet优点在于结构清晰、易于理解和实现,性能非常好。但它的参数量非常大(VGG16 的参数量超过 1.38 亿),计算资源消耗高、速度慢且容易过拟合。
2.4 GoogLeNet (2014)
GoogLeNet 由Google提出,引入了Inception模块,其设计思想是在网络的同一层级上并行地使用多种不同尺寸的卷积核和池化操作,以捕捉不同尺度的特征信息,然后将这些信息在通道维度上进行拼接(Concatenate)。一个典型的 Inception 模块通常包含以下并行分支:1*1卷积、3*3卷积、5*5卷积以及3*3最大池化。在3*3卷积、5*5之前和池化之后都有用到1*1卷积,它主要有两个作用,一是降维,减少输入特征图的通道数,二是增加非线性,因为每个卷积层后面通常会跟激活函数。
一个inception模块的代码大致如下:
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Sequential, ReLUclass Inception(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):# in_channels 输入特征图的通道数。# ch1x1 分支1的输出通道数。# ch3x3red 分支2中,3x3卷积前的 1x1 卷积的输出通道数。# ch3x3 分支2 (3x3 卷积) 的输出通道数。# ch5x5red 分支3中,5x5卷积前的 1x1 卷积的输出通道数。# ch5x5 分支3 (5x5 卷积) 的输出通道数。# pool_proj 分支4中,池化后 1x1 卷积的输出通道数。super(Inception, self).__init__()# 分支 1: 单独的 1x1 卷积self.branch1 = Sequential(Conv2d(in_channels, ch1x1, kernel_size=1),ReLU())# 分支 2: 1x1 卷积降维 + 3x3 卷积self.branch2 = Sequential(Conv2d(in_channels, ch3x3red, kernel_size=1),ReLU(),Conv2d(ch3x3red, ch3x3, kernel_size=3, padding=1))# 分支 3: 1x1 卷积降维 + 5x5 卷积self.branch3 = nn.Sequential(Conv2d(in_channels, ch5x5red, kernel_size=1),ReLU(),Conv2d(ch5x5red, ch5x5, kernel_size=5, padding=2))# 分支 4: 最大池化 + 1x1 卷积self.branch4 = nn.Sequential(MaxPool2d(kernel_size=3, stride=1, padding=1),Conv2d(in_channels, pool_proj, kernel_size=1),ReLU())def forward(self, x):# 计算每个分支的输出branch1_out = self.branch1(x)branch2_out = self.branch2(x)branch3_out = self.branch3(x)branch4_out = self.branch4(x)# 将四个分支的输出在通道维度 (dim=1) 上进行拼接outputs = [branch1_out, branch2_out, branch3_out, branch4_out]return torch.cat(outputs, dim=1) # 拼接后,通道数为 ch1x1 + ch3x3 + ch5x5 + pool_proj为了解决超深网络训练中可能出现的梯度消失问题,并提供额外的正则化,GoogLeNet 在网络的中间层(通常是第 3 和第 5 个 Inception 模块之后)引入了两个辅助分类器。这些辅助分类器由一个小的卷积网络和一个全连接层组成,直接输出一个分类结果。在训练时,它们的损失会以较小的权重(如 0.3)加到总损失中,为浅层提供梯度信号。在测试时,这些辅助分类器会被丢弃。
另外 GoogLeNet 摒弃了传统 CNN 末端使用的巨大全连接层。在最后一个 Inception 模块之后,它使用全局平均池化将每个特征图(例如 7*7*1024)压缩成一个标量(1*1*1024),这大幅减少了模型的参数量和计算量,减轻了过拟合,使模型对输入图像的平移变化更具鲁棒性。
在现在的实际运用中,通常会在其卷积层的后面添加批量归一化层(BN,15年才提出)对每个通道上的数据进行归一化,以稳定和加速网络的训练过程。
GoogLeNet计算效率高、参数量小且易于拓展,但它模型复杂,超参数多,辅助分类器的作用也有限。
2.5 ResNet (2015)
ResNet 由微软提出,主要引入了残差块和跳跃连接,解决了极深网络中的梯度消失/爆炸问题,使得训练数百层乃至上千层的网络成为可能。
在ResNet出现以前,普遍认为网络越深,性能越好。但实验发现,当网络深度超过一定层数后,训练误差和测试误差反而会增大,这种现象被称为退化。这种现象的根本原因是网络层数深导致的梯度消失或梯度爆炸问题。
跳跃连接是 ResNet 的核心创新。它是一种捷径,允许信息跨过一个或多个层,直接传递到后面。它的一个作用就是缓解梯度消失(在反向传播时,梯度可以直接通过跳跃连接回到浅层,形成一条短路径,大大缩短了梯度传递的路径,使得浅层也能接收到有效的梯度信号);另一个作用就是,即使中间的层学习效果很差,输入信息也能通过跳跃连接无损地传递到后面,保证了信息的流动性。
残差块就是实现跳跃连接的具体模块,它不直接学习目标映射 ,而是学习残差函数
。其基本公式为:
其中,x 和 y 分别为残差块的输入与最终输出, 是由模块内部的若干层(如两个 3x3 卷积层)构成的残差函数,+x 代表跳跃连接,不管输入是哪一层,都将输入 x 直接加到对应残差函数的输出上。
残差块包括两种类型,一种是基本残差块,另一种是瓶颈残差块。前者主要用于较浅的 ResNet,内部包含两个 3*3 卷积层,跳跃连接是恒等映射,即要求输入和残差函数输出的维度必须完全相同;后者则主要用于较深的ResNet,其结构通常是一个1*1卷积层、一个3*3卷积层、一个1*1卷积层, 前面的1*1 卷积层主要用于降维,降低3*3卷积层的计算量,后面的则用于恢复通道数,因此并不要求输入和残差函数输出的维度完全相同。
ResNet解决了梯度消失/爆炸问题,加快了收敛速度,提高了准确率,可拓展性也很强,但计算成本还是比较大,模型复杂性也有所增加,而且也不是在所有情况下都优于浅层网络。
3 总结
本周比较注重理论和代码的结合学习,内容比较多,感觉对卷积神经网络的经典架构都有了一个大致的认识,希望在后续可以通过实战加深对部分经典网络的理解。下周可能会进行RNN(循环神经网络)的学习。