DAY 51 复习日+退款开始
作业:day43的时候我们安排大家对自己找的数据集用简单cnn训练,现在可以尝试下借助这几天的知识来实现精度的进一步提高
话不多说,先复习一下day43的内容
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import os
import warnings
warnings.filterwarnings("ignore")# 设置随机种子确保结果可复现
torch.manual_seed(42)
np.random.seed(42)# 数据集路径 - 根据实际情况修改
data_dir =r"D:\课程\新建文件夹" # 包含train, test, val子目录的主文件夹from torchvision.transforms import RandomResizedCrop, RandomRotation, ColorJitter # 导入ColorJitter# 训练集数据增强变换
train_transform = transforms.Compose([RandomResizedCrop(224, scale=(0.8, 1.0)),RandomRotation(15),ColorJitter(brightness=0.2), # 调整亮度,范围是 [-0.2, 0.2] 相对于原亮度变化transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])val_test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])train_dataset = torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'train'),transform=train_transform # 训练集用增强
)
test_dataset = torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'test'),transform=val_test_transform # 测试集不用增强
)
val_dataset = torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'val'),transform=val_test_transform # 验证集不用增强
)# 获取类别名称(53种扑克牌)
classes = train_dataset.classes
print(f"类别数量: {len(classes)}")
print(f"前5个类别: {classes[:5]}")# 定义适合224x224图像的CNN模型
class CardCNN(nn.Module):def __init__(self, num_classes=53):super(CardCNN, self).__init__()# 第一个卷积块self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)self.bn1 = nn.BatchNorm2d(32)# 第二个卷积块self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)self.bn2 = nn.BatchNorm2d(64)# 第三个卷积块self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)self.bn3 = nn.BatchNorm2d(128)# 第四个卷积块 - 用于Grad-CAM可视化self.conv4 = nn.Conv2d(128, 256, kernel_size=3, padding=1)self.bn4 = nn.BatchNorm2d(256)# 新增注意力机制self.attention = nn.Sequential(nn.AdaptiveAvgPool2d(1), nn.Conv2d(256, 256, 1), nn.Sigmoid() )# 池化层self.pool = nn.MaxPool2d(2, 2)# 全连接层# 经过4次池化后,224x224图像变为14x14 (224 -> 112 -> 56 -> 28 -> 14)self.fc1 = nn.Linear(256 * 14 * 14, 1024)self.dropout = nn.Dropout(0.5)self.fc2 = nn.Linear(1024, num_classes)def forward(self, x):# 卷积块1: 卷积 -> 批归一化 -> ReLU -> 池化x = self.pool(F.relu(self.bn1(self.conv1(x)))) # 224->112# 卷积块2x = self.pool(F.relu(self.bn2(self.conv2(x)))) # 112->56# 卷积块3x = self.pool(F.relu(self.bn3(self.conv3(x)))) # 56->28# 卷积块4x = self.pool(F.relu(self.bn4(self.conv4(x)))) # 28->14# 注意力加权att = self.attention(x) x = x * att # 特征图与注意力相乘# 展平特征图x = x.view(-1, 256 * 14 * 14)# 全连接层x = F.relu(self.fc1(x))x = self.dropout(x)x = self.fc2(x)return x# 初始化模型
model = CardCNN(num_classes=len(classes))
print("模型已创建")# 设备配置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
print(f"使用设备: {device}")# 训练模型
def train_model(model, epochs=20):# 创建数据加载器trainloader = torch.utils.data.DataLoader(train_dataset, batch_size=32,shuffle=True, num_workers=2)valloader = torch.utils.data.DataLoader(val_dataset, batch_size=32,shuffle=False, num_workers=2)# 定义损失函数和优化器criterion = nn.CrossEntropyLoss()optimizer = torch.optim.AdamW(model.parameters(), lr=0.001, weight_decay=0.001)scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=2, factor=0.5)best_val_acc = 0.0for epoch in range(epochs):# 训练阶段model.train()running_loss = 0.0correct = 0total = 0for i, data in enumerate(trainloader, 0):inputs, labels = datainputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()# 计算训练准确率_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()if i % 50 == 49: # 每50个批次打印一次信息print(f'[{epoch + 1}, {i + 1}] 损失: {running_loss / 50:.3f}, 准确率: {100 * correct / total:.2f}%')running_loss = 0.0# 验证阶段model.eval()val_loss = 0.0val_correct = 0val_total = 0with torch.no_grad():for data in valloader:images, labels = dataimages, labels = images.to(device), labels.to(device)outputs = model(images)loss = criterion(outputs, labels)val_loss += loss.item()_, predicted = torch.max(outputs.data, 1)val_total += labels.size(0)val_correct += (predicted == labels).sum().item()val_acc = 100 * val_correct / val_totalval_avg_loss = val_loss / len(valloader)print(f'Epoch {epoch+1} 验证集: 损失: {val_avg_loss:.3f}, 准确率: {val_acc:.2f}%')# 学习率调整scheduler.step(val_avg_loss)# 保存最佳模型if val_acc > best_val_acc:print(f'验证准确率提升 ({best_val_acc:.2f}% -> {val_acc:.2f}%), 保存模型...')best_val_acc = val_acctorch.save(model.state_dict(), 'card_cnn_best.pth')print("训练完成")# 尝试加载预训练模型,如果没有则训练新模型
try:model.load_state_dict(torch.load('card_cnn_best.pth', map_location=device))print("已加载预训练模型")
except:print("无法加载预训练模型,开始训练新模型")train_model(model, epochs=20) # 可根据需要调整训练轮次# 设置模型为评估模式
model.eval()# Grad-CAM实现
class GradCAM:def __init__(self, model, target_layer):self.model = modelself.target_layer = target_layerself.gradients = Noneself.activations = None# 注册钩子self.register_hooks()def register_hooks(self):def forward_hook(module, input, output):self.activations = output.detach()def backward_hook(module, grad_input, grad_output):self.gradients = grad_output[0].detach()self.target_layer.register_forward_hook(forward_hook)self.target_layer.register_backward_hook(backward_hook)def generate_cam(self, input_image, target_class=None):model_output = self.model(input_image)if target_class is None:target_class = torch.argmax(model_output, dim=1).item()self.model.zero_grad()one_hot = torch.zeros_like(model_output)one_hot[0, target_class] = 1model_output.backward(gradient=one_hot, retain_graph=True)gradients = self.gradientsactivations = self.activations# 计算权重 (全局平均池化)weights = torch.mean(gradients, dim=(2, 3), keepdim=True)# 加权组合特征图cam = torch.sum(weights * activations, dim=1, keepdim=True)# ReLU激活cam = F.relu(cam)# 调整大小并归一化cam = F.interpolate(cam, size=(224, 224), mode='bilinear', align_corners=False)cam = cam - cam.min()if cam.max() > 0:cam = cam / cam.max()return cam.cpu().squeeze().numpy(), target_class# 设置中文字体支持
plt.rcParams["font.family"] = ["Microsoft YaHei"]
plt.rcParams['axes.unicode_minus'] = False
# 图像转换函数
def tensor_to_np(tensor):img = tensor.cpu().numpy().transpose(1, 2, 0)mean = np.array([0.485, 0.456, 0.406])std = np.array([0.229, 0.224, 0.225])img = std * img + meanimg = np.clip(img, 0, 1)return img# 可视化多个样本
def visualize_samples(num_samples=5):# 创建测试集数据加载器testloader = torch.utils.data.DataLoader(test_dataset, batch_size=1,shuffle=True)# 初始化Grad-CAM(使用最后一个卷积层)grad_cam = GradCAM(model, model.conv4)# 创建图像并显示fig, axes = plt.subplots(num_samples, 3, figsize=(15, 5*num_samples))for i, data in enumerate(testloader):if i >= num_samples:breakimage, label = datatrue_class = classes[label.item()]# 准备输入input_tensor = image.to(device)# 生成Grad-CAM热力图heatmap, pred_class_idx = grad_cam.generate_cam(input_tensor)pred_class = classes[pred_class_idx]# 转换图像以便显示img_np = tensor_to_np(image.squeeze())# 绘制原始图像axes[i, 0].imshow(img_np)axes[i, 0].set_title(f"原始图像: {true_class}")axes[i, 0].axis('off')# 绘制热力图axes[i, 1].imshow(heatmap, cmap='jet')axes[i, 1].set_title(f"Grad-CAM热力图: {pred_class}")axes[i, 1].axis('off')# 绘制叠加图像heatmap_colored = plt.cm.jet(heatmap)[:, :, :3]superimposed_img = heatmap_colored * 0.4 + img_np * 0.6axes[i, 2].imshow(superimposed_img)axes[i, 2].set_title(f"叠加效果: {'正确' if true_class == pred_class else '错误'}")axes[i, 2].axis('off')plt.tight_layout()plt.savefig('card_grad_cam_results.png', dpi=300, bbox_inches='tight')plt.show()# 执行可视化
visualize_samples(num_samples=5)类别数量: 53
前5个类别: ['ace of clubs', 'ace of diamonds', 'ace of hearts', 'ace of spades', 'eight of clubs']
模型已创建
使用设备: cuda:0
无法加载预训练模型,开始训练新模型
[1, 50] 损失: 6.465, 准确率: 3.75%
[1, 100] 损失: 3.764, 准确率: 4.44%
[1, 150] 损失: 3.425, 准确率: 5.92%
[1, 200] 损失: 3.117, 准确率: 7.95%
Epoch 1 验证集: 损失: 2.937, 准确率: 21.89%
验证准确率提升 (0.00% -> 21.89%), 保存模型...
[2, 50] 损失: 2.813, 准确率: 21.00%
[2, 100] 损失: 2.706, 准确率: 22.72%
[2, 150] 损失: 2.551, 准确率: 24.17%
[2, 200] 损失: 2.452, 准确率: 25.11%
Epoch 2 验证集: 损失: 2.031, 准确率: 37.36%
验证准确率提升 (21.89% -> 37.36%), 保存模型...
[3, 50] 损失: 2.345, 准确率: 29.38%
[3, 100] 损失: 2.329, 准确率: 29.34%
[3, 150] 损失: 2.330, 准确率: 29.92%
[3, 200] 损失: 2.383, 准确率: 30.17%
Epoch 3 验证集: 损失: 1.702, 准确率: 41.51%
验证准确率提升 (37.36% -> 41.51%), 保存模型...
[4, 50] 损失: 2.224, 准确率: 35.69%
[4, 100] 损失: 2.228, 准确率: 34.38%...[20, 150] 损失: 0.938, 准确率: 71.31%
[20, 200] 损失: 1.013, 准确率: 71.20%
Epoch 20 验证集: 损失: 0.684, 准确率: 79.25%
训练完成
现在尝试使用Resnet18+CBAM来实现精度的进一步提高
1.数据预处理
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import os
import warnings
warnings.filterwarnings("ignore")# 设置中文字体支持
plt.rcParams["font.family"] = ["Microsoft YaHei"]
plt.rcParams['axes.unicode_minus'] = False# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 设置随机种子确保结果可复现
torch.manual_seed(42)
np.random.seed(42)# 数据集路径 - 根据实际情况修改
data_dir =r"D:\课程\新建文件夹" # 包含train, test, val子目录的主文件夹from torchvision.transforms import RandomResizedCrop, RandomRotation, ColorJitter # 导入ColorJitter# 训练集数据增强变换
train_transform = transforms.Compose([RandomResizedCrop(224, scale=(0.8, 1.0)),RandomRotation(15),ColorJitter(brightness=0.2), # 调整亮度,范围是 [-0.2, 0.2] 相对于原亮度变化transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])val_test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])train_dataset = torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'train'),transform=train_transform # 训练集用增强
)
test_dataset = torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'test'),transform=val_test_transform # 测试集不用增强
)
val_dataset = torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'val'),transform=val_test_transform # 验证集不用增强
)# 获取类别名称(53种扑克牌)
classes = train_dataset.classes
print(f"类别数量: {len(classes)}")
print(f"前5个类别: {classes[:5]}")使用设备: cuda
类别数量: 53
前5个类别: ['ace of clubs', 'ace of diamonds', 'ace of hearts', 'ace of spades', 'eight of clubs']2.定义CBAM模块
import torch
import torch.nn as nn# 定义通道注意力
class ChannelAttention(nn.Module):def __init__(self, in_channels, ratio=16):"""通道注意力机制初始化参数:in_channels: 输入特征图的通道数ratio: 降维比例,用于减少参数量,默认为16"""super().__init__()# 全局平均池化,将每个通道的特征图压缩为1x1,保留通道间的平均值信息self.avg_pool = nn.AdaptiveAvgPool2d(1)#计算每个通道特征图中所有像素的平均值# 全局最大池化,将每个通道的特征图压缩为1x1,保留通道间的最显著特征self.max_pool = nn.AdaptiveMaxPool2d(1)#取每个通道特征图中所有像素的最大值# 共享全连接层,用于学习通道间的关系# 先降维(除以ratio),再通过ReLU激活,最后升维回原始通道数self.fc = nn.Sequential(nn.Linear(in_channels, in_channels // ratio, bias=False), # 降维层nn.ReLU(), # 非线性激活函数nn.Linear(in_channels // ratio, in_channels, bias=False) # 升维层)# Sigmoid函数将输出映射到0-1之间,作为各通道的权重self.sigmoid = nn.Sigmoid()def forward(self, x):"""前向传播函数参数:x: 输入特征图,形状为 [batch_size, channels, height, width]返回:调整后的特征图,通道权重已应用"""# 获取输入特征图的维度信息,这是一种元组的解包写法b, c, h, w = x.shape# 对平均池化结果进行处理:展平后通过全连接网络avg_out = self.fc(self.avg_pool(x).view(b, c))# 对最大池化结果 进行处理:展平后通过全连接网络max_out = self.fc(self.max_pool(x).view(b, c))# 将平均池化和最大池化的结果相加并通过sigmoid函数得到通道权重attention = self.sigmoid(avg_out + max_out).view(b, c, 1, 1)# 将注意力权重与原始特征相乘,增强重要通道,抑制不重要通道return x * attention #这个运算是pytorch的广播机制
## 空间注意力模块
class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super().__init__()self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):# 通道维度池化avg_out = torch.mean(x, dim=1, keepdim=True) # 平均池化:(B,1,H,W)max_out, _ = torch.max(x, dim=1, keepdim=True) # 最大池化:(B,1,H,W)pool_out = torch.cat([avg_out, max_out], dim=1) # 拼接:(B,2,H,W)attention = self.conv(pool_out) # 卷积提取空间特征return x * self.sigmoid(attention) # 特征与空间权重相乘
## CBAM模块
class CBAM(nn.Module):def __init__(self,in_channels,ratio=16,kernel_size=7):super().__init__()self.channel_attn=ChannelAttention(in_channels,ratio)self.spatial_attn=SpatialAttention(kernel_size)def forward(self,x):x=self.channel_attn(x)x=self.spatial_attn(x)return x3.定义带CBAM的ResNet18模型并实例化
注意:这里需要恢复原始首层卷积以适应输入数据尺寸
import torch
import torch.nn as nn
from torchvision import models# 自定义ResNet18模型,插入CBAM模块
class ResNet18_CBAM(nn.Module):def __init__(self, num_classes=53, pretrained=True, cbam_ratio=16, cbam_kernel=7):super().__init__()# 加载预训练ResNet18self.backbone = models.resnet18(pretrained=pretrained) # 恢复原始首层卷积以适应224x224输入self.backbone.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3, bias=False)# 恢复原始MaxPool层self.backbone.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)# 在每个残差块组后添加CBAM模块self.cbam_layer1 = CBAM(in_channels=64, ratio=cbam_ratio, kernel_size=cbam_kernel)self.cbam_layer2 = CBAM(in_channels=128, ratio=cbam_ratio, kernel_size=cbam_kernel)self.cbam_layer3 = CBAM(in_channels=256, ratio=cbam_ratio, kernel_size=cbam_kernel)self.cbam_layer4 = CBAM(in_channels=512, ratio=cbam_ratio, kernel_size=cbam_kernel)# 修改分类头以适应53个类别self.backbone.fc = nn.Linear(in_features=512, out_features=num_classes)def forward(self, x):# 主干特征提取x = self.backbone.conv1(x)x = self.backbone.bn1(x)x = self.backbone.relu(x)x = self.backbone.maxpool(x) # 恢复MaxPool层的使用# 第一层残差块 + CBAMx = self.backbone.layer1(x)x = self.cbam_layer1(x)# 第二层残差块 + CBAMx = self.backbone.layer2(x)x = self.cbam_layer2(x)# 第三层残差块 + CBAMx = self.backbone.layer3(x)x = self.cbam_layer3(x)# 第四层残差块 + CBAMx = self.backbone.layer4(x)x = self.cbam_layer4(x)# 全局平均池化 + 分类x = self.backbone.avgpool(x)x = torch.flatten(x, 1)x = self.backbone.fc(x)return x
# 初始化模型并移至设备
model = ResNet18_CBAM().to(device)4.定义GradCAM
# Grad-CAM实现
class GradCAM:def __init__(self, model, target_layer):self.model = modelself.target_layer = target_layerself.gradients = Noneself.activations = None# 注册钩子self.register_hooks()def register_hooks(self):def forward_hook(module, input, output):self.activations = output.detach()def backward_hook(module, grad_input, grad_output):self.gradients = grad_output[0].detach()self.target_layer.register_forward_hook(forward_hook)self.target_layer.register_backward_hook(backward_hook)def generate_cam(self, input_image, target_class=None):model_output = self.model(input_image)if target_class is None:target_class = torch.argmax(model_output, dim=1).item()self.model.zero_grad()one_hot = torch.zeros_like(model_output)one_hot[0, target_class] = 1model_output.backward(gradient=one_hot, retain_graph=True)gradients = self.gradientsactivations = self.activations# 计算权重 (全局平均池化)weights = torch.mean(gradients, dim=(2, 3), keepdim=True)# 加权组合特征图cam = torch.sum(weights * activations, dim=1, keepdim=True)# ReLU激活cam = F.relu(cam)# 调整大小并归一化cam = F.interpolate(cam, size=(224, 224), mode='bilinear', align_corners=False)cam = cam - cam.min()if cam.max() > 0:cam = cam / cam.max()return cam.cpu().squeeze().numpy(), target_class# 图像转换函数
def tensor_to_np(tensor):img = tensor.cpu().numpy().transpose(1, 2, 0)mean = np.array([0.485, 0.456, 0.406])std = np.array([0.229, 0.224, 0.225])img = std * img + meanimg = np.clip(img, 0, 1)return img# 可视化多个样本
def visualize_samples(num_samples=5):# 创建测试集数据加载器testloader = torch.utils.data.DataLoader(test_dataset, batch_size=1,shuffle=True)# 初始化Grad-CAM(使用最后一个卷积层)grad_cam = GradCAM(model, model.backbone.layer4[-1].conv2)# 创建图像并显示fig, axes = plt.subplots(num_samples, 3, figsize=(15, 5*num_samples))for i, data in enumerate(testloader):if i >= num_samples:breakimage, label = datatrue_class = classes[label.item()]# 准备输入input_tensor = image.to(device)# 生成Grad-CAM热力图heatmap, pred_class_idx = grad_cam.generate_cam(input_tensor)pred_class = classes[pred_class_idx]# 转换图像以便显示img_np = tensor_to_np(image.squeeze())# 绘制原始图像axes[i, 0].imshow(img_np)axes[i, 0].set_title(f"原始图像: {true_class}")axes[i, 0].axis('off')# 绘制热力图axes[i, 1].imshow(heatmap, cmap='jet')axes[i, 1].set_title(f"Grad-CAM热力图: {pred_class}")axes[i, 1].axis('off')# 绘制叠加图像heatmap_colored = plt.cm.jet(heatmap)[:, :, :3]superimposed_img = heatmap_colored * 0.4 + img_np * 0.6axes[i, 2].imshow(superimposed_img)axes[i, 2].set_title(f"叠加效果: {'正确' if true_class == pred_class else '错误'}")axes[i, 2].axis('off')plt.tight_layout()plt.savefig('card_grad_cam_results.png', dpi=300, bbox_inches='tight')plt.show()5.训练模型与可视化
# 分阶段微调相关函数
def set_trainable_layers(model, trainable_parts):"""设置可训练的层,冻结其他层"""print(f"\n---> 解冻以下部分并设为可训练: {trainable_parts}")for name, param in model.named_parameters():param.requires_grad = Falsefor part in trainable_parts:if part in name:param.requires_grad = Truebreakdef train_model(model, train_dataset, val_dataset, epochs=20):# 创建数据加载器trainloader = DataLoader(train_dataset, batch_size=32,shuffle=True, num_workers=2)valloader = DataLoader(val_dataset, batch_size=32,shuffle=False, num_workers=2)# 定义损失函数criterion = nn.CrossEntropyLoss()device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model.to(device)best_val_acc = 0.0optimizer = None# 初始化历史记录all_iter_losses, iter_indices = [], []train_acc_history, val_acc_history = [], []train_loss_history, val_loss_history = [], []for epoch in range(epochs):epoch_start_time = time.time()# 分阶段调整可训练层和优化器if epoch == 0: # 第一阶段:只训练CBAM和分类头set_trainable_layers(model, ["cbam", "backbone.fc"])optimizer = optim.AdamW(filter(lambda p: p.requires_grad, model.parameters()),lr=0.001, weight_decay=0.001)scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=2, factor=0.5)print("\n" + "="*50 + "\n🚀 阶段 1:训练注意力模块和分类头 \n" + "="*50)elif epoch == 5: # 第二阶段:解冻高层卷积set_trainable_layers(model, ["cbam", "backbone.fc", "backbone.layer3", "backbone.layer4"])optimizer = optim.AdamW(filter(lambda p: p.requires_grad, model.parameters()),lr=0.0001, # 学习率降低一个数量级weight_decay=0.001)scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=2, factor=0.5)print("\n" + "="*50 + "\n✈️ 阶段 2:解冻高层卷积层 (layer3, layer4) \n" + "="*50)elif epoch == 14: # 第三阶段:全局微调for param in model.parameters():param.requires_grad = Trueoptimizer = optim.AdamW(model.parameters(),lr=0.00001, # 学习率进一步降低weight_decay=0.001)scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=2, factor=0.5)print("\n" + "="*50 + "\n🛰️ 阶段 3:解冻所有层,进行全局微调 \n" + "="*50)# 训练阶段model.train()running_loss = 0.0correct = 0total = 0for i, data in enumerate(trainloader, 0):inputs, labels = datainputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()# 计算训练准确率_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()# 记录每50个批次的损失if i % 50 == 49:print(f'[{epoch + 1}, {i + 1}] 损失: {running_loss / 50:.3f}, 准确率: {100 * correct / total:.2f}%')all_iter_losses.append(running_loss / 50)iter_indices.append(epoch * len(trainloader) + i)running_loss = 0.0# 计算训练集整体指标train_acc = 100 * correct / totaltrain_acc_history.append(train_acc)train_loss_history.append(running_loss / len(trainloader))# 验证阶段model.eval()val_loss = 0.0val_correct = 0val_total = 0with torch.no_grad():for data in valloader:images, labels = dataimages, labels = images.to(device), labels.to(device)outputs = model(images)loss = criterion(outputs, labels)val_loss += loss.item()_, predicted = torch.max(outputs.data, 1)val_total += labels.size(0)val_correct += (predicted == labels).sum().item()val_acc = 100 * val_correct / val_totalval_avg_loss = val_loss / len(valloader)val_acc_history.append(val_acc)val_loss_history.append(val_avg_loss)print(f'Epoch {epoch+1} 验证集: 损失: {val_avg_loss:.3f}, 准确率: {val_acc:.2f}%')print(f'Epoch 耗时: {time.time() - epoch_start_time:.2f}秒')# 学习率调整scheduler.step(val_avg_loss)# 保存最佳模型if val_acc > best_val_acc:print(f'验证准确率提升 ({best_val_acc:.2f}% -> {val_acc:.2f}%), 保存模型...')best_val_acc = val_acctorch.save(model.state_dict(), 'card_resnet18_CBAM_best.pth')print("训练完成")return {'train_acc': train_acc_history,'val_acc': val_acc_history,}
try:model.load_state_dict(torch.load('card_resnet18_CBAM_best.pth', map_location=device))print("已加载预训练模型")
except:print("无法加载预训练模型,开始训练新模型")history = train_model(model, train_dataset, val_dataset, epochs=20)
# 执行可视化
visualize_samples(num_samples=5)无法加载预训练模型,开始训练新模型---> 解冻以下部分并设为可训练: ['cbam', 'backbone.fc']==================================================
🚀 阶段 1:训练注意力模块和分类头
==================================================
[1, 50] 损失: 3.921, 准确率: 3.56%
[1, 100] 损失: 3.480, 准确率: 7.28%
[1, 150] 损失: 3.100, 准确率: 10.40%
[1, 200] 损失: 2.849, 准确率: 13.45%
Epoch 1 验证集: 损失: 2.455, 准确率: 29.06%
Epoch 耗时: 27.81秒
验证准确率提升 (0.00% -> 29.06%), 保存模型...
[2, 50] 损失: 2.579, 准确率: 29.88%
[2, 100] 损失: 2.511, 准确率: 30.81%
[2, 150] 损失: 2.398, 准确率: 31.60%
[2, 200] 损失: 2.461, 准确率: 32.22%
Epoch 2 验证集: 损失: 2.063, 准确率: 40.38%
Epoch 耗时: 27.56秒
验证准确率提升 (29.06% -> 40.38%), 保存模型...
[3, 50] 损失: 2.256, 准确率: 38.44%
[3, 100] 损失: 2.329, 准确率: 37.56%
[3, 150] 损失: 2.165, 准确率: 38.83%
[3, 200] 损失: 2.120, 准确率: 39.44% ... [20, 200] 损失: 0.136, 准确率: 97.33%
Epoch 20 验证集: 损失: 0.499, 准确率: 84.15%
Epoch 耗时: 35.19秒
训练完成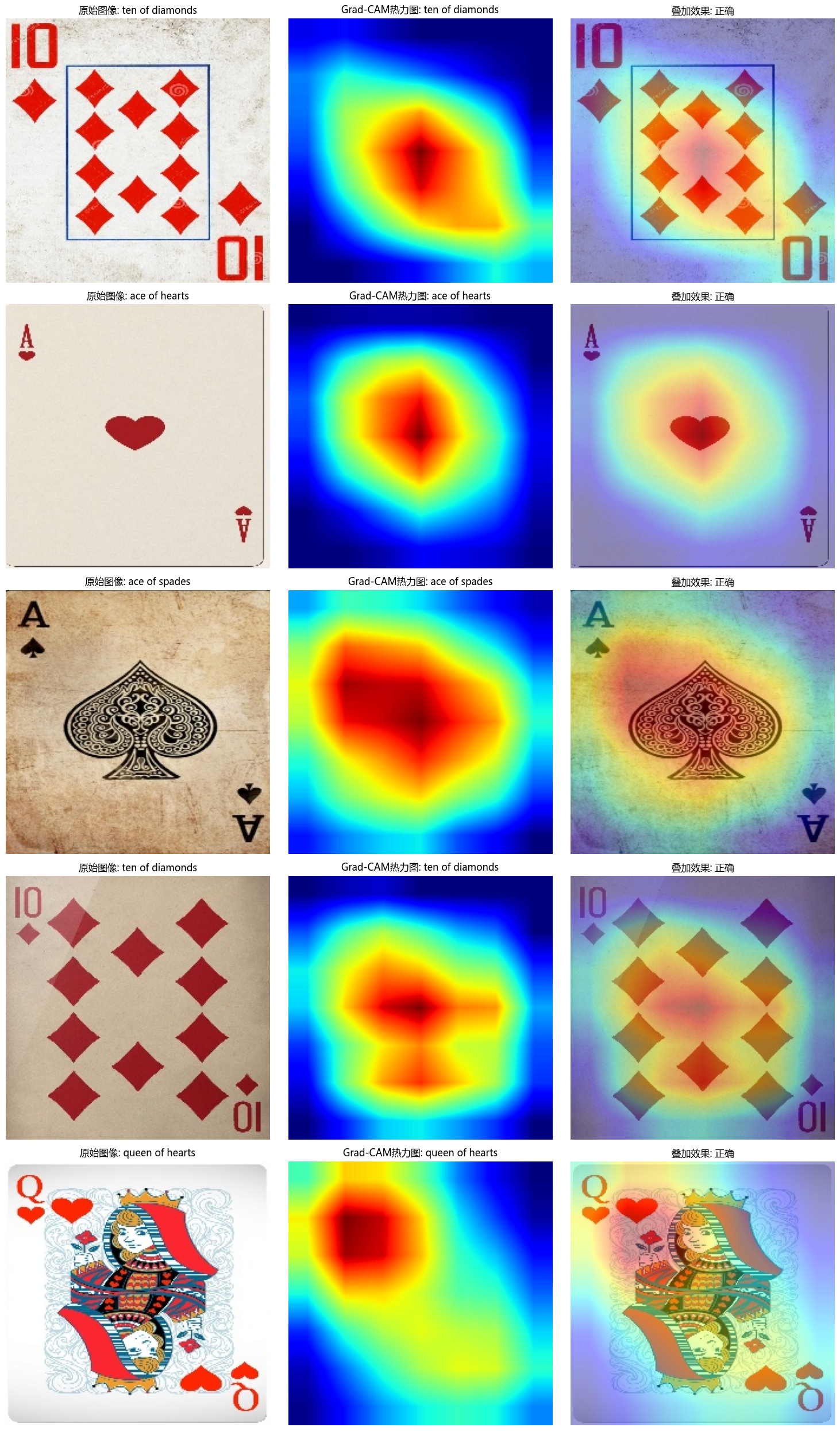
@浙大疏锦行