Redis实战-缓存的解决方案(一)
1.什么是缓存
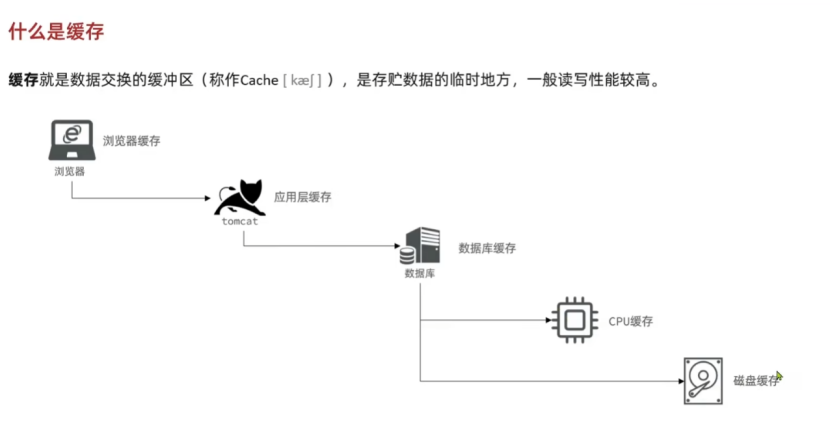
缓存就是数据交换的缓存区,是存储数据的临时区域,读写性能高。
浏览器会有缓存,tomcat服务器也会有缓存,数据库也会有缓存,CPU也会有缓存,磁盘也会有缓存,所以说缓存是无处不在的并且起到了相当大的作用。
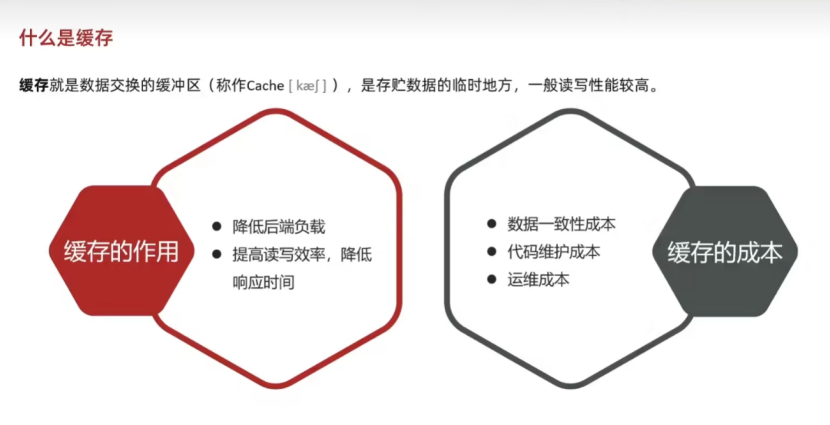
缓存的作用 => 降低后端负载,提高读写效率,降低响应时间。
缓存成本 => 数据一致性成本,代码维护的成本,运维的成本。
2.添加Redis缓存
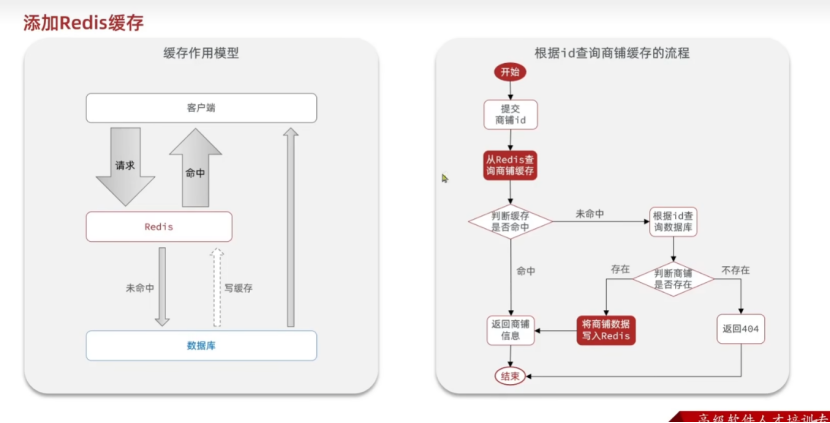
2.1Redis缓存存储对象(string)
其key的设计是cache:shop:店铺ID,感觉不太好,没有遵循业务:类型:标识。
如果按照那样的话,key应该设计为shop:cache:店铺ID。
不过其实也行,把缓存都统一设计在一个地方,不过感觉还是一般。
如果使用string存储对象的话,肯定得使用对象转换为JsonStr,才能存储进去,取出的时候也需要进行反序列化,这个过程肯定是要消耗一定时间的。
/*** 查询店铺详情** @param id* @return*/
@Override
public Result queryById(Long id) {// 1. 查询缓存是否有数据String key = CACHE_SHOP_KEY + id;String shopDetailCache = stringRedisTemplate.opsForValue().get(key);// 2. 缓存存在if (StrUtil.isNotBlank(shopDetailCache)) {log.debug("店铺详情缓存: {}", shopDetailCache);Shop shop = JSONUtil.toBean(shopDetailCache, Shop.class);return Result.ok(shop);}// 3. 缓存不存在Shop shop = getById(id);// 4. 店铺为空if (shop == null) {return Result.fail("店铺为空!");}// 5. 将缓存存储到缓存中stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop));// 6. 设置缓存时间stringRedisTemplate.expire(key, CACHE_SHOP_TTL, TimeUnit.MINUTES);// 7. 返回return Result.ok(shop);
}2.2Redis缓存存储对象(Hash)
/*** 查询店铺详情** @param id* @return*/
@Override
public Result queryById(Long id) {// 1. 查询缓存是否有数据String key = CACHE_SHOP_KEY + id;Map<Object, Object> shopDetailCache = stringRedisTemplate.opsForHash().entries(key);// 2. 处理缓存存在的情况if (!shopDetailCache.isEmpty()) {return Result.ok(BeanUtil.mapToBean(shopDetailCache, Shop.class, true));}// 3. 缓存不存在 -> 查询数据库Shop shop = getById(id);// 4. 处理数据库中无数据的情况if (shop == null) {return Result.fail("无相关店铺数据");}// 5. 将数据存入缓存Map<String, Object> map = BeanUtil.beanToMap(shop, new HashMap<>(),CopyOptions.create().setIgnoreNullValue(true).setFieldValueEditor((fieldName, fieldValue) -> {if (fieldValue != null) {return fieldValue.toString();}return null;}));stringRedisTemplate.opsForHash().putAll(key, map);// 6. 设置缓存时间stringRedisTemplate.expire(key, CACHE_SHOP_TTL, TimeUnit.MINUTES);// 7. 返回数据return Result.ok(shop);
}2.2.1获取Hash数据
获取Hash数据使用的是opsForHash().entries(key)这个API,进行获取出来的Hash会被映射为Java中的Map数据。
需要注意的是,里面的数据全是字符串,SpringMVC也不会帮我们处理这种情况的,所以我们必须进行自己将Map转回Bean,这样才能将匹配类型的数据返回前端(比如数字字符串)。
Map<Object, Object> shopDetailCache = stringRedisTemplate.opsForHash().entries(key);// 2. 处理缓存存在的情况
if (!shopDetailCache.isEmpty()) {return Result.ok(BeanUtil.mapToBean(shopDetailCache, Shop.class, true));
}2.2.2存入缓存数据
Bean需要转换为Map才能存到缓存中,但是要注意的是,Bean中的null问题。
Bean中可能会有null数据,setIgnoreNullValue是在Bean转换为Map的时候取出里面为null的数据,它的优先级是比setFieldValueEditor要低的,所以很有可能在setFieldValueEditor中出现NullPointerException异常,建议要进行判断。
3.练习:给店铺类型添加缓存
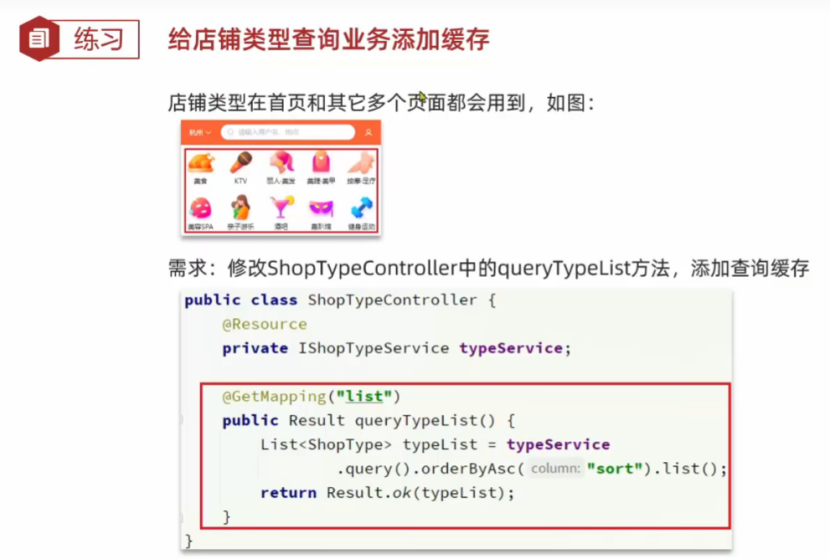
3.1使用string实现
@Override
public Result queryTypeList() {// 1. 查询缓存中是否有数据String shopTypeCache = stringRedisTemplate.opsForValue().get(SHOP_TYPE_CACHE_KEY);// 2. 缓存存在if (StrUtil.isNotEmpty(shopTypeCache)) {return Result.ok(JSONUtil.toList(shopTypeCache, ShopType.class));}// 3. 缓存不存在 -> 去数据库中查询数据List<ShopType> typeList = query().orderByAsc("sort").list();// 4. 将数据存储到缓存中stringRedisTemplate.opsForValue().set(SHOP_TYPE_CACHE_KEY, JSONUtil.toJsonStr(typeList));// 5. 设置缓存时间stringRedisTemplate.expire(SHOP_TYPE_CACHE_KEY, SHOP_TYPE_CACHE_TTL, TimeUnit.MINUTES);// 6. 返回return Result.ok(typeList);
}3.2使用List实现
4.缓存更新策略
4.1三大策略
主要从一致性方向去分析选择即可。

4.2主动更新策略
4.2.1主动更新策略的三大策略
1.更新数据库时同时更新缓存 => 代码量多一些。
2.将缓存和数据库整合为一个服务,由服务来维护一致性,调用者直接调用服务即可,无需关注一致性。=> 无好用的第三方组件,要引入其它组件,增加了系统的复杂度。
3.只操作缓存,由其它线程进行将缓存持久化到数据库,保证最终一致性。 => 无好用的第三方组件,并且多线程将系统变得更加复杂了。
所以建议自己进行控制,使用自己编码的方式进行更新。

4.2.2调用者进行主动更新缓存的特点

1.删除缓存还是更新缓存?
不建议更新缓存,因为如果在多次更新缓存后,没有人来访问,会增加很多的无效缓存,所以建议直接删除缓存,等下次有人来访问的时候再进行写入缓存。
2.如何保证缓存和数据库同时成功或者失败?
单体架构:使用事务,将缓存和数据库放在同一个事务中。
分布式系系统:使用TCC等分布式事务。
3.先操作缓存还是先操作数据库?
4.2.3先操作缓存还是先操作数据库
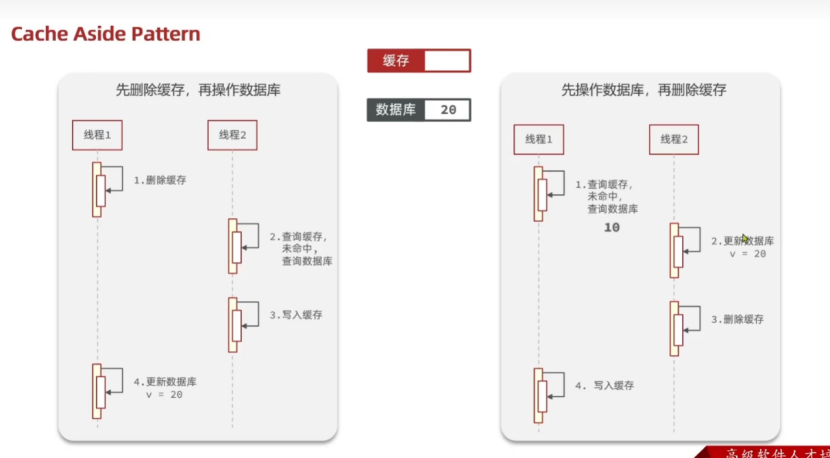
1.先删除缓存,再操作数据库
极端情况:当缓存刚删除完的时候,又来个线程去查询缓存,没有命中,去查询数据库,写入缓存,第一个线程在第二个线程操作完之后才更新数据到数据库,则会导致数据不一致的问题。
2.先操作数据库,再删除缓存
极端情况:不知道h为什么,缓存过期了/Redis崩掉了,没有查询到缓存,故去查询数据库,但是第二个线程又进行更新数据库了在线程1还没有写入缓存之前,这就导致了,线程1查出来的数据是不一致的,写入缓存的数据也是不一致的。
其实根据分析,由于数据库查询数据慢于redis,而且像第二种的情况出现的也少,其实第一种是更加好的,即使出现了第二种情况,也可以进行使用缓存时间淘汰策略进行兜底,所以应该采用,先删除缓存,再操作数据库。
4.3缓存更新策略的最佳实践方案

4.4使用主动更新策略进行缓存一致性操作
先更改数据库,再更新缓存。
可以加一个Spring的事务@Transactional注解,这样就可以保证redis操作和mysql操作同时成功/失败。
/*** 更新店铺数据** @param shop* @return*/
@Override
@Transactional
public Result updateShopById(Shop shop) {Long id = shop.getId();if (id == null) {return Result.fail("店铺ID参数错误!");}// 1. 更新数据库数据boolean isSuccess = updateById(shop);// 2. 处理更新失败if (!isSuccess) {return Result.fail("系统错误!!!");}// 3. 删除缓存stringRedisTemplate.delete(CACHE_SHOP_KEY + id);return Result.ok();
}5.缓存穿透
5.1什么是缓存穿透
客户端请求在缓存的时候,假设请求的数据在缓存和数据库中都不存在,是不是缓存永远都不会生效,这样就会直接打在数据库上,造成数据库被打穿。
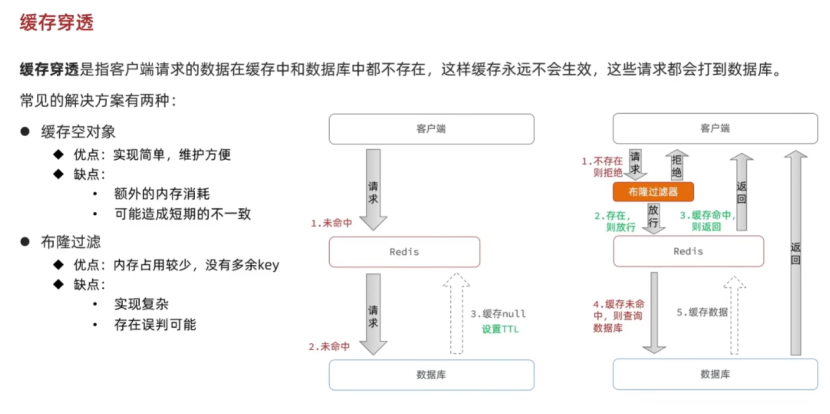
5.2解决缓存穿透的方案
5.2.1缓存空对象
数据库查询不到的数据就缓存一个空对象,这样实现简单,维护简单,也能保证数据库不会被打穿。
但是会有额外的内存消耗,也可能会导致短期数据不一致,因为后台新增数据的时候,也需要去删除空对象,在这个期间可能出现短期的数据不一致问题。
5.2.2布隆过滤器
布隆过滤器其实就是在缓存和客户端又加了一层,将数据库中的数据以一种hash计算算法转换为二进制数据放在布隆过滤器中,请求来的时候,使用布隆过滤器去查询数据是否存在,这样做的好处就是redis中的内存占用少,不会有空value的存在。
但是布隆过滤器实现很复杂,而且可能出现误判的可能,布隆过滤器中计算出来的数据可能出现误判的可能性,可能两个数据计算出来是一样的结果,但是有一个数据在数据库中并不存在,就会导致误判的情况,依然会打到数据库,但是这种情况虽然存在,但是少一些,主要是实现复杂,还要引入多余的中间件。
5.2.3增加限流器+降级操作
5.3使用缓存空对象解决缓存穿透
5.3.1业务流程
业务流程就是如果缓存不存在仍然会打到数据库,但是数据库查不到数据库的时候,仍然会做一个多余的操作,就是将一个空对象进行缓存到redis缓存中。
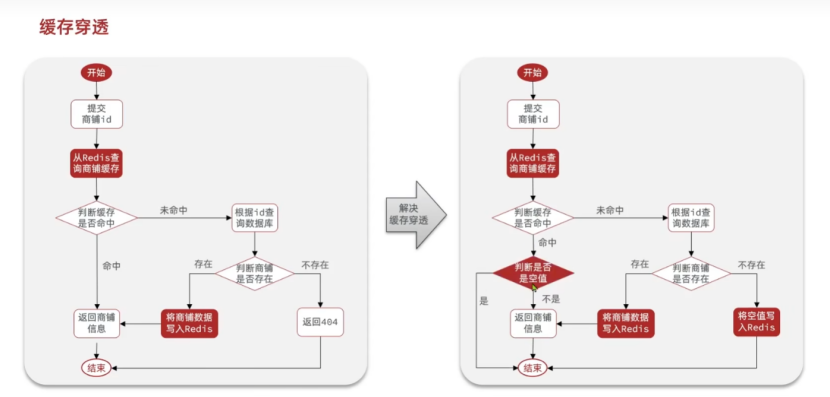
5.3.2代码实现
/*** 查询店铺详情** @param id* @return*/
@Override
public Result queryById(Long id) {// 1. 查询缓存是否有数据String key = CACHE_SHOP_KEY + id;Map<Object, Object> shopDetailCache = stringRedisTemplate.opsForHash().entries(key);// 2.1 处理缓存对象为空的情况if (shopDetailCache.containsKey("isEmpty")) {return Result.fail("无相关店铺数据");}// 2.2 处理缓存存在的情况if (!shopDetailCache.isEmpty()) {return Result.ok(BeanUtil.mapToBean(shopDetailCache, Shop.class, true));}// 3. 缓存不存在 -> 查询数据库Shop shop = getById(id);// 4. 处理数据库中无数据的情况if (shop == null) {// 4.1 将空数据存入缓存stringRedisTemplate.opsForHash().put(key, "isEmpty", "");// 4.2 设置缓存时间stringRedisTemplate.expire(key, CACHE_SHOP_TTL, TimeUnit.MINUTES);return Result.fail("无相关店铺数据");}// 5. 将数据存入缓存Map<String, Object> map = BeanUtil.beanToMap(shop, new HashMap<>(),CopyOptions.create().setIgnoreNullValue(true).setFieldValueEditor((fieldName, fieldValue) -> {if (fieldValue != null) {return fieldValue.toString();}return null;}));stringRedisTemplate.opsForHash().putAll(key, map);// 6. 设置缓存时间stringRedisTemplate.expire(key, CACHE_SHOP_TTL, TimeUnit.MINUTES);// 7. 返回数据return Result.ok(shop);
}5.4玩个压测 => 测一下限流效果
5.4.1不限流redis接口单机tomcat能抗多久(测试环境16H64G)
测试环境:16H64GB,未做任何JVM和tomcat优化。
5.4.1.1一秒并发500次
首先来一个一秒并发500次。

可以看到500次的并发,该接口仍然抗住了这次流量突刺,吞吐量497.7/s,异常率0%。
5.4.1.2一秒并发1000次
再来一个一秒并发一千次。
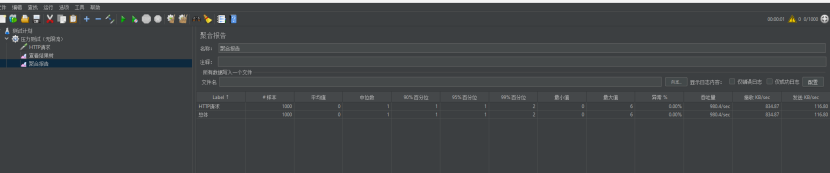
可以看到1000次并发,接口依然抗住了这次流量突刺,吞吐量980.7/s,异常率0%。
5.4.1.3一秒并发3500次
上强度,一秒并发3500次!

抗住了!!!这次流量突刺并没有干掉服务,吞吐量3893.2/s,异常率0.77%。
5.4.1.4一秒并发4000次
上强度,一秒并发4000次!
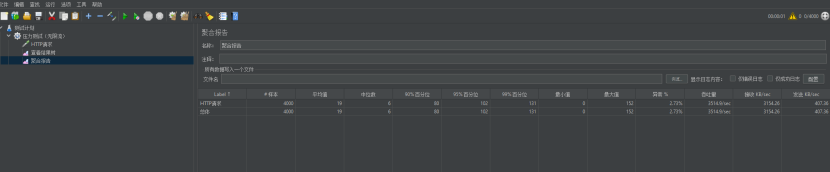
这次似乎顶不住了,出现了少量的异常现象,吞吐量3514.9/s,异常率2.73%。
5.4.1.5一秒并发5000次
上强度,一秒并发5000次!!!
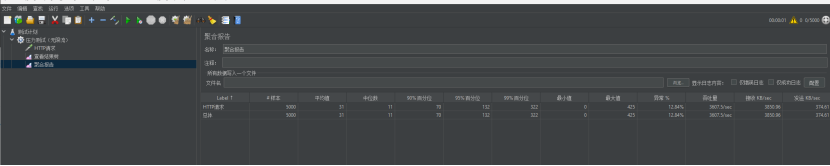
这次更不行了,出现了十分之一以上的异常请求,吞吐量3607.5/s,异常率12.84%。
5.4.1.6一秒并发10000次
再试试,看看单机tomcat多久会撑不住!!!
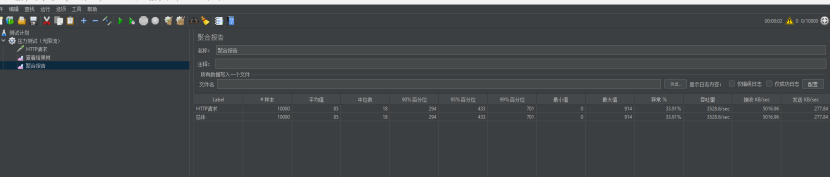
好家伙这次直接绷不住了,异常量逆天了,吞吐量的3528.6/s,异常率33.91%。
5.4.1.7一秒并发20000次
再上点强度试试。

好家伙这次直接完蛋了,吞吐量2284.7/s,异常率69.03%,直接完蛋了哈哈哈。
电脑也要死掉了。
5.4.1.8二十秒并发500次

持续并发进攻,看看效果怎么样。
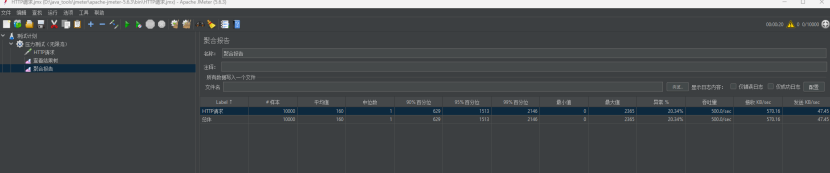
持续进攻的时候,吞吐量确实是顶住了,但是持续并发还是撑不住啊,吞吐量:500/s,异常20.34%。所以说这个并发持久了之后,就绷不住了。
5.4.2限流redis接口单机tomcat能抗多久(测试环境16H64G)
多因素,再考虑吧。
5.5总结缓存穿透的方案

5.5.1增加ID复杂度
为什么增加ID复杂度可以防止缓存穿透?
因为缓存穿透的产生的原因是,恶意用户一直访问没有的数据,也就是通过ID进行访问数据库和redis中都没有的数据,这样就会出现缓存穿透的问题。所以我们可以增加ID的复杂度,让恶意攻击者短时间内猜不出来,这样攻击者就无法进行进攻啦。
5.5.2做好数据的基础格式校验
进行校验基础数据,不能让随机提交参数的人进攻到服务器。
5.5.3加强用户权限校验
当用户发起多次恶意请求的时候,可以对用户进行限流,防止单个用户多次请求,恶意用户直接封号等,加强用户的校验。
5.5.4做好热点参数的限流
对于一些热点参数进行限流,防止当用户大量访问热点key,且不存在的数据的时候,将数据库直接打垮。
6.缓存雪崩
缓存雪崩就是同一时间大量缓存key同时失效或者Redis服务宕机,导致大量请求打击到数据库,带来巨大压力。
现在可以进行做到的就是给不同的key设置随机的TTL来进行防止key同时过期。
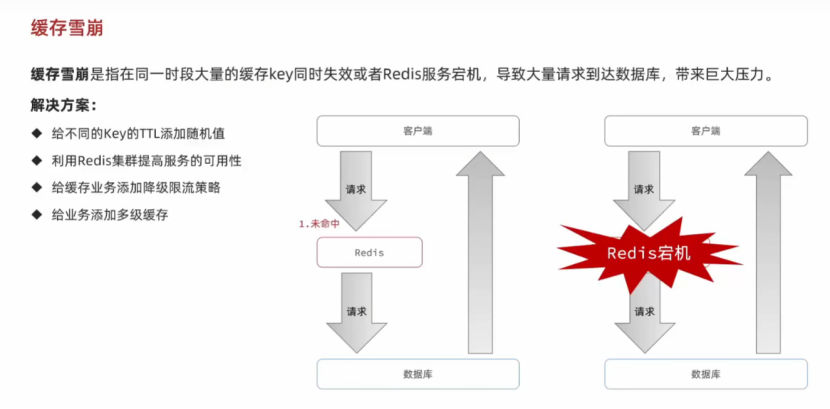
6.1使用随机TTL解决缓存雪崩
// 随机生成缓存过期时间 15 - 45秒
int cacheTime = (int) ((Math.random() * 30) + 15);7.缓存击穿
缓存击穿就是一个被高并发访问并且缓存重建业务比较复杂的key突然失效了,无数的请求就会瞬间给数据库带来毁灭性打击。
在redis中的key重建之前,所有的线程来访问的时候,都会进行进入重建key的过程,这样在这期间,数据库很有可能被打崩掉。
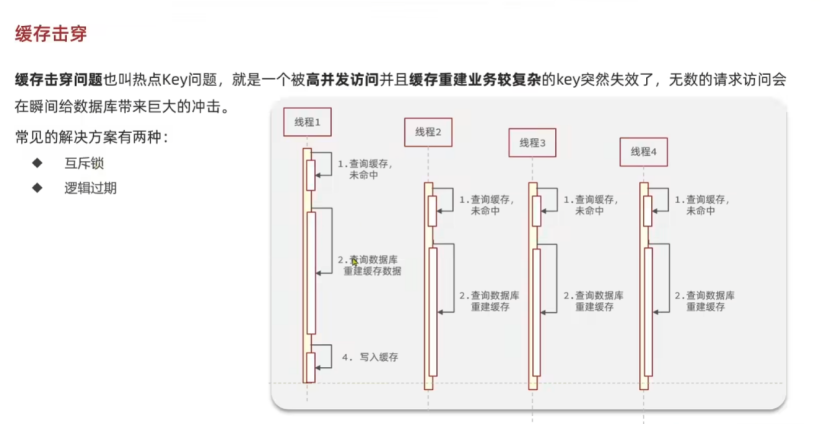
7.1缓存击穿的解决方案
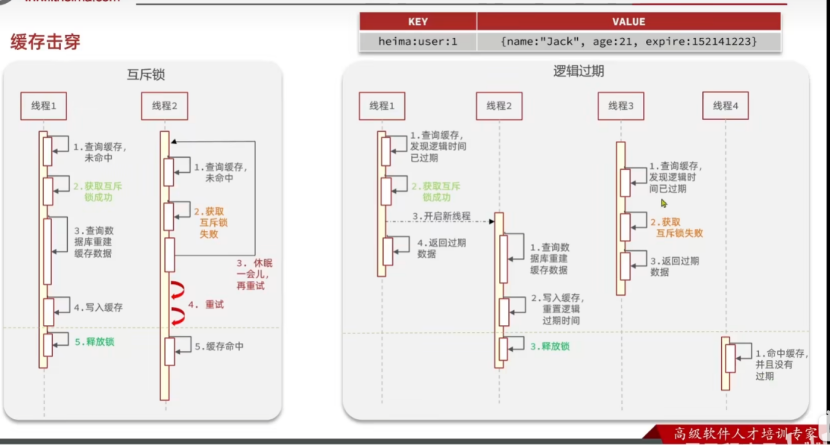
7.1.1使用互斥锁进行解决
在未命中缓存之后,进行查询数据库过程前,使用一个互斥锁进行锁住,保证只有一个线程进行执行查询数据库重建缓存的过程,如果有多个线程去抢锁,其它线程会抢锁失败,进入休眠状态,当重建缓存的线程释放了锁之后,回到查询缓存的步骤,进行重试,这样就可以完美解决缓存击穿的问题。
但是也是有缺点的,在进入锁之后,在缓存重建的这个过程中,其它线程是无法访问的,无疑会降低系统并发量,并且使用互斥锁可能会出现死锁的情况,但是这种做法具有高度一致性。
并且使用互斥锁没有额外的内存消耗,无需使用逻辑删除。
使用互斥锁实现也很简单。
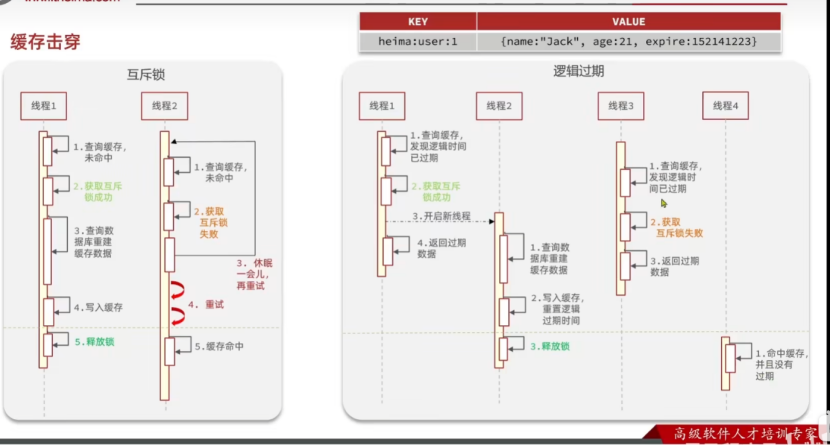
7.1.2使用逻辑过期解决缓存击穿问题
逻辑过期,就是定义一个expire过期时间,如果使用逻辑过期的话,就不会出现不是热点key的数据,如果不是热点key的数据根本不会出现在这个缓存中,热点key配合逻辑过期一般是要进行数据预热的,将热点key的数据提前预热到系统中,而不是让整个访问的代码去根据访问数据的不同去重建key,重建的key一定不会是热点key,所以逻辑过期+预加载才是一个真正的热点key模拟出的缓存击穿的场景。
但是逻辑过期有一致性风险,因为逻辑时间过期后,缓存重建的过程是数据不一致的,因为过期的数据仍然可以被访问到。
逻辑过期的性能好,但是性能好的前提是依靠不一致性和额外的内存消耗带来的,只能说有利也有弊吧。
7.1.3两种方法的优缺点

7.2使用互斥锁解决缓存击穿问题
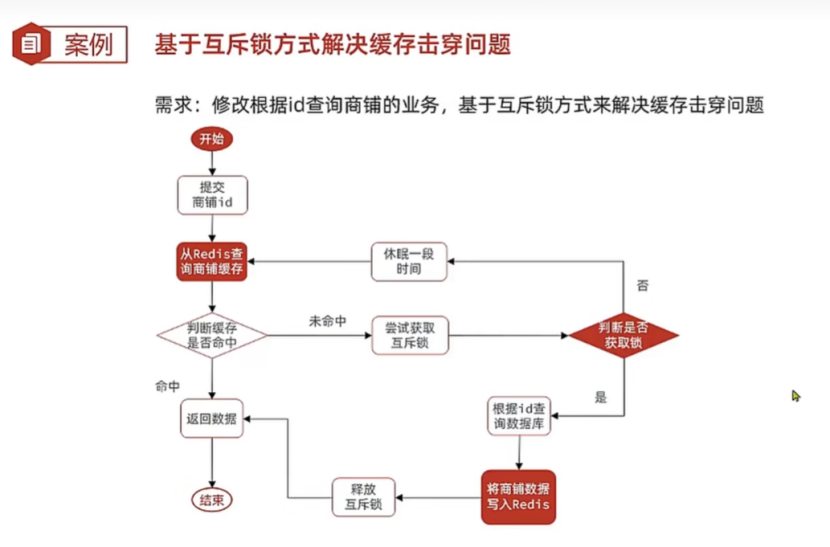
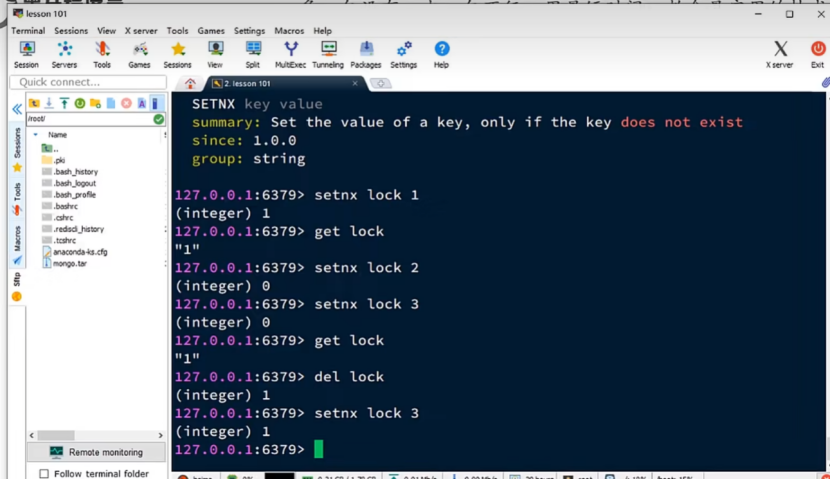
7.2.1锁的选型
这次使用setnx进行充当锁,setnx lock 1,lock不存在就将lock设置为1,并返回1表示设置成功,但是如果lock存在,再进行使用setnx进行设置的时候,就会设置失败,返回0。
其实还是又更专业实现redis锁的方式,但是现在先暂时使用这个方式进行实现。
7.2.2实现锁
封装了一个尝试获得锁的函数和一个释放锁的函数。
使用setIfAbsent,就是进行使用setnx进行上锁,返回一个boolean值。
上锁函数需要返回一个boolean值表示是否上锁成功/
释放锁的时候,直接使用delete删除锁即可。
/*** 上锁* @param key* @return*/
private boolean tryLock(String key) {Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);return BooleanUtil.isTrue(flag);
}/*** 释放锁* @param key*/
private void unlock(String key) {stringRedisTemplate.delete(key);
}7.2.3完整代码实现
主要是将互斥锁+缓存穿透和缓存雪崩封装成了一个函数,函数进行返回Shop数据。
如果返回的没有数据就直接抛出Resul.fail()即可,如果存在就直接将店铺数据返回出去。
@Override
public Result queryById(Long id) {// 互斥锁解决缓存击穿Shop shop = queryWithMutex(id);if (shop == null) {return Result.fail("店铺不存在!");}// 7. 返回数据return Result.ok(shop);
}public Shop queryWithMutex(Long id) {// 1. 启动redis限流器try {// 获取redis限流令牌redisSemaphore.acquire();} catch (InterruptedException e) {e.printStackTrace();}// 1. 查询缓存是否有数据String key = CACHE_SHOP_KEY + id;Map<Object, Object> shopDetailCache = stringRedisTemplate.opsForHash().entries(key);// 2.1 处理缓存对象为空的情况if (shopDetailCache.containsKey("isEmpty")) {redisSemaphore.release();return null;}// 2.2 处理缓存存在的情况if (!shopDetailCache.isEmpty()) {redisSemaphore.release();return BeanUtil.mapToBean(shopDetailCache, Shop.class, true);}// 3. 释放redis限流器redisSemaphore.release();// 4. 缓存不存在 -> 查询数据库Shop shop = getById(id);// 随机生成缓存过期时间 15 - 45秒int cacheTime = (int) ((Math.random() * 30) + 15);// 5. 实现缓存重建// 5.1 获取互斥锁String lockKey = "lock:shop:" + id;try {boolean isLock = tryLock(lockKey);// 5.2 判断是否获取成功if (!isLock) {// 5.3 失败,则休眠并重试Thread.sleep(50);return queryWithMutex(id);}// 6 处理数据库中无数据的情况if (shop == null) {// 6.1 将空数据存入缓存stringRedisTemplate.opsForHash().put(key, "isEmpty", "");// 6.2 设置缓存时间stringRedisTemplate.expire(key, cacheTime, TimeUnit.MINUTES);return null;}// 7. 将数据存入缓存Map<String, Object> map = BeanUtil.beanToMap(shop, new HashMap<>(),CopyOptions.create().setIgnoreNullValue(true).setFieldValueEditor((fieldName, fieldValue) -> {if (fieldValue != null) {return fieldValue.toString();}return null;}));stringRedisTemplate.opsForHash().putAll(key, map);// 8. 设置缓存时间stringRedisTemplate.expire(key, cacheTime, TimeUnit.MINUTES);} catch (InterruptedException e) {throw new RuntimeException(e);} finally {// 9. 释放互斥锁unlock(lockKey);}// 10. 返回数据return shop;
}7.2.4互斥锁的思路设计
锁key的设计是根据每个
主要是使用了tryLock去获得锁,如果锁获取失败,就会使用sleep去等待,等待了一会之后就会醒来去递归返回数据,因为使用了return,所有最后一定会是能返回出去数据的,不会说递归死。
但是递归其实不建议使用,我感觉很有可能在高并发的情况下,因为递归栈过多(递归使用的是系统栈)会导致JVM崩溃,系统栈中存储的递归数据过多就会崩溃,所以在工程中不建议进行使用递归实现的,在8中我们进行综合利用测试一下缓存击穿+缓存穿透+缓存雪崩。
// 5. 实现缓存重建
// 5.1 获取互斥锁
String lockKey = "lock:shop:" + id;
try {boolean isLock = tryLock(lockKey);// 5.2 判断是否获取成功if (!isLock) {// 5.3 失败,则休眠并重试Thread.sleep(50);return queryWithMutex(id);}// 6 处理数据库中无数据的情况if (shop == null) {// 6.1 将空数据存入缓存stringRedisTemplate.opsForHash().put(key, "isEmpty", "");// 6.2 设置缓存时间stringRedisTemplate.expire(key, cacheTime, TimeUnit.MINUTES);return null;}// 7. 将数据存入缓存Map<String, Object> map = BeanUtil.beanToMap(shop, new HashMap<>(),CopyOptions.create().setIgnoreNullValue(true).setFieldValueEditor((fieldName, fieldValue) -> {if (fieldValue != null) {return fieldValue.toString();}return null;}));stringRedisTemplate.opsForHash().putAll(key, map);// 8. 设置缓存时间stringRedisTemplate.expire(key, cacheTime, TimeUnit.MINUTES);
} catch (InterruptedException e) {throw new RuntimeException(e);
} finally {// 9. 释放互斥锁unlock(lockKey);
}7.3使用缓存过期策略
7.3.1业务分析
缓存击穿一般存在的场景都是一些高并发的场景,key一定是经常会被进行访问的,所以无key的直接返回空即可,说明者根本不是热点key,如果一个数据经常被访问,在一定访问量后肯定要进行升级为热点key,加载到redis中。
如果redis中没有该key => 直接返回null。
如果redis中有key,没有过期 => 直接返回。
如果redis中有key,过期了 => 开启新线程进行重建key,并立刻进行返回原来的旧数据。
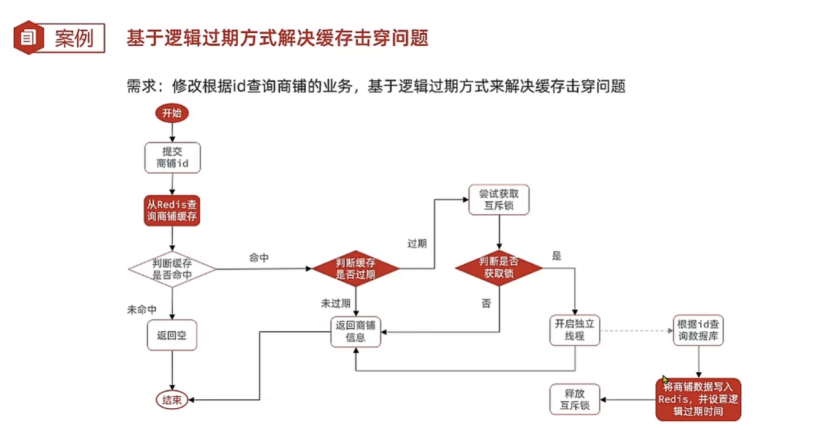
7.3.2封装一个RedisData
这个Data中有过期时间和Object类型的数据,将data封装为Object类型,可以更加通用,但是在Json转换上也带来了一些问题。
@Data
public class RedisData {private LocalDateTime expireTime;private Object data;
}7.3.3整体流程
整个流程其实没什么太多亮点,就照着以下几点进行分析吧:
1.JSON数据的转换操作
2.线程池的设定
3.重建缓存时的DoubleCheck
这几点可以详细研究一下。
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);/*** 缓存击穿 + 缓存雪崩(逻辑过期)** @param id* @return*/
public Shop queryWithLogicalExpire(Long id) {// 1. 查询缓存是否有数据String key = CACHE_SHOP_KEY + id;String shopJson = stringRedisTemplate.opsForValue().get(key);// 2. 处理缓存不存在的情况if (StrUtil.isBlank(shopJson)) {return null;}// 3. 命中, 需要先把json反序列化为对象RedisData redisData = JSONUtil.toBean(shopJson, RedisData.class);JSONObject data = (JSONObject) redisData.getData();Shop shop = JSONUtil.toBean(data, Shop.class);LocalDateTime expireTime = redisData.getExpireTime();// 4. 判断是否过期if (expireTime.isAfter(LocalDateTime.now())) {// 4.1 未过期,直接返回店铺信息return shop;}// 4.2 已过期,需要缓存重建// 5. 缓存重建// 5.1 获取互斥锁String lockKey = LOCK_SHOP_KEY + id;boolean isLock = tryLock(lockKey);// 5.2 判单是否获取锁成功if (isLock) {// 5.3 成功,开启独立线程,实现缓存重建CACHE_REBUILD_EXECUTOR.submit(() -> {// doubleCheck缓存是否存在String shopCheckJson = stringRedisTemplate.opsForValue().get(key);// 转换json数据RedisData redisCheckData = JSONUtil.toBean(shopCheckJson, RedisData.class);LocalDateTime expireCheckTime = redisCheckData.getExpireTime();if (expireCheckTime.isAfter(LocalDateTime.now())) {return;}try {// 重建缓存saveShop2Redis(id, 20L);} catch (Exception e) {throw new RuntimeException(e);} finally {// 释放锁unlock(lockKey);}});}// 5.4 返回过期的商铺信息return shop;
}8.综合优化 => 缓存穿透使用互斥锁解决
缓存击穿 + 缓存穿透 + 缓存雪崩一起进行测试。
8.1优化第一版本
8.1.1拆分出redis中数据是否存在
定义isExists函数,进行获取到redis中的指定key数据是否存在,由于redis中存储的是一个Hash数据,所以使用entries进行获取到Map数据之后,判断一下是否不为空,如果不为空,就返回shop数据。
定义getShopDataByRedis数据,接收一个shopDetailCache参数,若存在isEmpty就返回一个null,主要是进行防止缓存穿透的这一步是,进行缓存一个空对象。若缓存数据不为空,并且通过了第一个if,就代表其中key是对应真实的value数据的,进行返回Shop对象即可。
/*** 判断是否存在key在redis中** @param key* @return*/
public Map<Object, Object> isExists(String key) {Map<Object, Object> shopDetailCache = stringRedisTemplate.opsForHash().entries(key);if (!shopDetailCache.isEmpty()) {return shopDetailCache;}return null;
}/*** 根据Redis中返回的数据,返回特定的数据** @param shopDetailCache* @return*/
public Shop getShopDataByRedis(Map<Object, Object> shopDetailCache) {// 1. 处理缓存对象为空的情况if (shopDetailCache.containsKey("isEmpty")) {return null;}// 2 处理缓存存在的情况if (!shopDetailCache.isEmpty()) {return BeanUtil.mapToBean(shopDetailCache, Shop.class, true);}return null;
}8.1.2整体流程分析
@Override
public Result queryById(Long id) {// 互斥锁解决缓存击穿Shop shop = queryWithMutex(id);if (shop == null) {return Result.fail("店铺不存在!");}// 7. 返回数据return Result.ok(shop);
}/*** 缓存击穿 + 缓存穿透 + 缓存雪崩** @param id* @return*/
public Shop queryWithMutex(Long id) {// 1. 查询缓存是否有数据String key = CACHE_SHOP_KEY + id;Map<Object, Object> shopMapData = isExists(key);if (shopMapData != null) {return getShopDataByRedis(shopMapData);}// 2. 实现缓存重建String lockKey = "lock:shop:" + id;Shop shop = null;try {// 2.1 获取互斥锁boolean isLock = tryLock(lockKey);// 2.2 若没有获取到锁就进行自旋获取锁while (!isLock) {Thread.sleep(50);// 自旋去redis中查询数据shopMapData = isExists(key);if (shopMapData != null) {return getShopDataByRedis(shopMapData);}}// 3. 缓存不存在 -> 查询数据库shop = getById(id);// 随机生成缓存过期时间 15 - 45秒int cacheTime = (int) ((Math.random() * 30) + 15);// 4. 处理数据库中无数据的情况if (shop == null) {// 4.1 将空数据存入缓存stringRedisTemplate.opsForHash().put(key, "isEmpty", "");// 4.2 设置缓存时间stringRedisTemplate.expire(key, cacheTime, TimeUnit.MINUTES);return null;}// 5. 将数据存入缓存Map<String, Object> map = BeanUtil.beanToMap(shop, new HashMap<>(),CopyOptions.create().setIgnoreNullValue(true).setFieldValueEditor((fieldName, fieldValue) -> {if (fieldValue != null) {return fieldValue.toString();}return null;}));stringRedisTemplate.opsForHash().putAll(key, map);// 5. 设置缓存时间stringRedisTemplate.expire(key, cacheTime, TimeUnit.MINUTES);} catch (InterruptedException e) {throw new RuntimeException(e);} finally {// 6. 释放互斥锁unlock(lockKey);}// 7. 返回数据return shop;
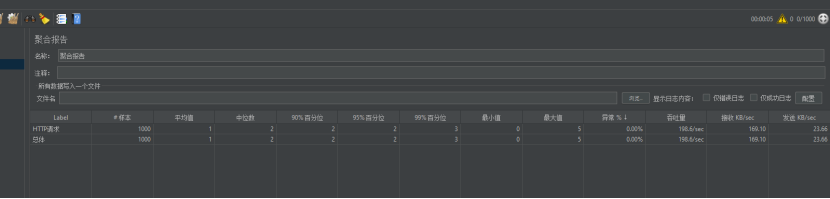
}8.1.3进行压力测试有缓存的状态的key的吞吐量
每秒吞吐量测试稳到200次/s,没有任何压力。
而且平均值还是能干到1ms左右的,最大值也不会超过5ms。
8.1.4进行压力测试有自旋重建锁的过程
8.1.4.1进行使用每秒200次并发
可以稳定到吞吐量198/s。
最大值仅7ms,平均值1ms,并且数据库访问仅仅有一次。
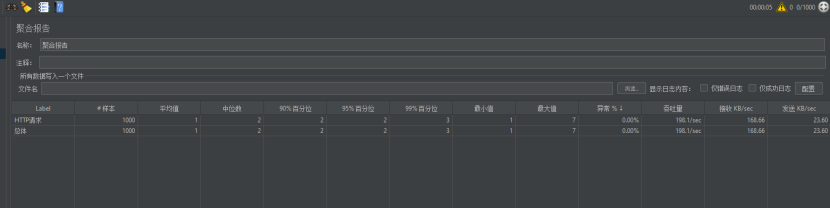
可以看到确实仅有一个线程去访问MySQL了。

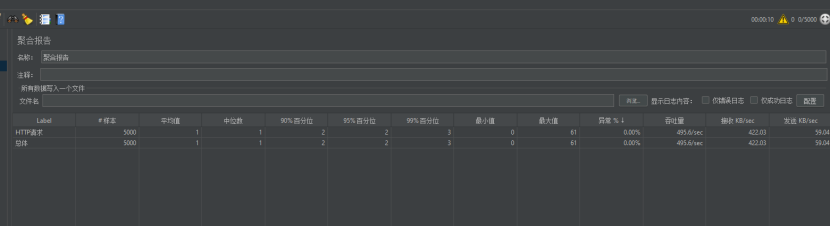
8.1.4.2进行使用每秒500次并发
还是可以做到495.6次/s的并发的,并且最大值61ms(估计是tomcat的线程调度原因,将最大值拉高了),但是平均值还是很低的,只有1ms,大部分数据99%中位数也就是3ms,表明目前系统还是很稳定的。
8.1.5思考:线程睡眠多久合适呢?
其实完全可以去测试一下重建一个缓存的速度是多,进行多次测试,取一个平均值,这样是比较好的。
经过测试,其实高并发量下,1000次对数据库的请求也就是三秒多而已,平均下来3ms一个,走postman测试的话其实也就是8ms左右一个,所以其实缓存重建的过程非常快的,为了防止CPU一直无效进行自旋,再加上CPU浪费时间等待,我们完全可以将Thread线程等待的时间缩小到10ms左右,多出来做个冗余嘛。
测试函数:
@Test
void testReCreateCache1() throws InterruptedException {for (int i = 0; i < 1000; i++) {STOP_WATCH.start();HttpUtil.get("http://127.0.0.1:8081/shop/1");STOP_WATCH.stop();stringRedisTemplate.delete("shop:detail:cache:1");}System.out.println(STOP_WATCH.getTotalTimeMillis());
}缓存重建一千次的速度:
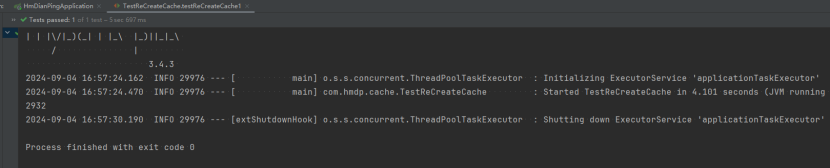
缓存重建一次的速度:
8.1.6睡眠时间调优后的压力测试
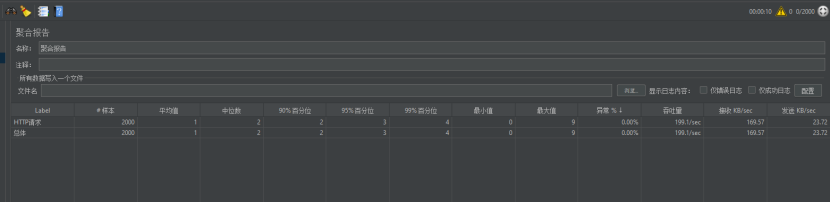
8.1.6.1进行使用每秒200次并发
效果还不错,最大值9ms,中位数2ms,99%中位数4ms,平均值1ms,吞吐量稳定199.1次/ms,估计最大值9ms是在进行缓存重建的过程。
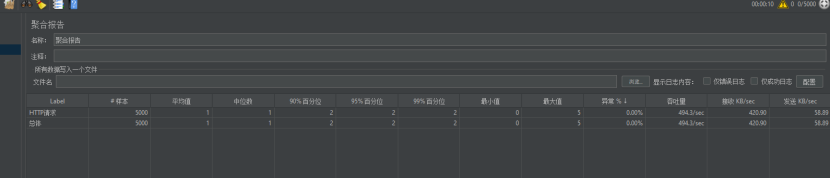
8.1.6.2进行使用每秒500次并发
效果还不错,最大值5ms,中位数1ms,99%中位数2ms,平均值1ms,吞吐量494.3次/ms,能力再次提升,这次优化起到了很大的作用。
8.1.6.3进行使用每秒1000次并发
没问题,没有出现任何异常,可抗每秒1000次的并发。
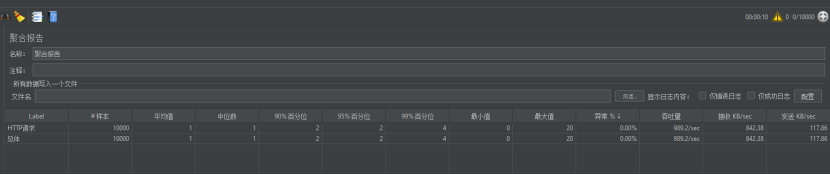
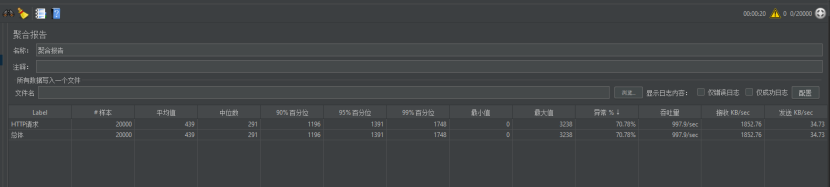
8.1.6.4进行使用每秒2000次并发
出问题啦,绷不住了,需要进行限流了,现在对整个系统的流量进行限制,不可否则的是整个系统有可能也收到了tomcat的限制。
8.2使用高级工具进一步高并发时系统发生了什么
这里我们以2000次/s,持久十秒钟为例。
8.2.1初始化状态
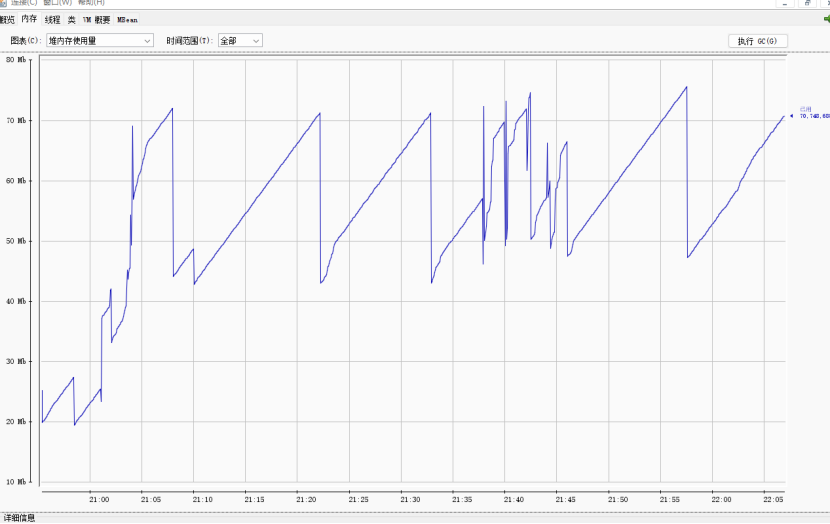
8.2.1.1使用JVM监控工具jconsole进行查看
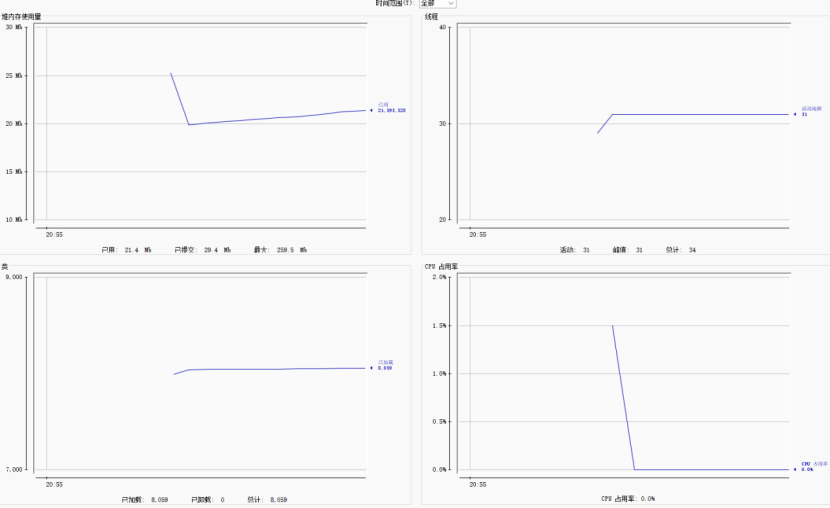
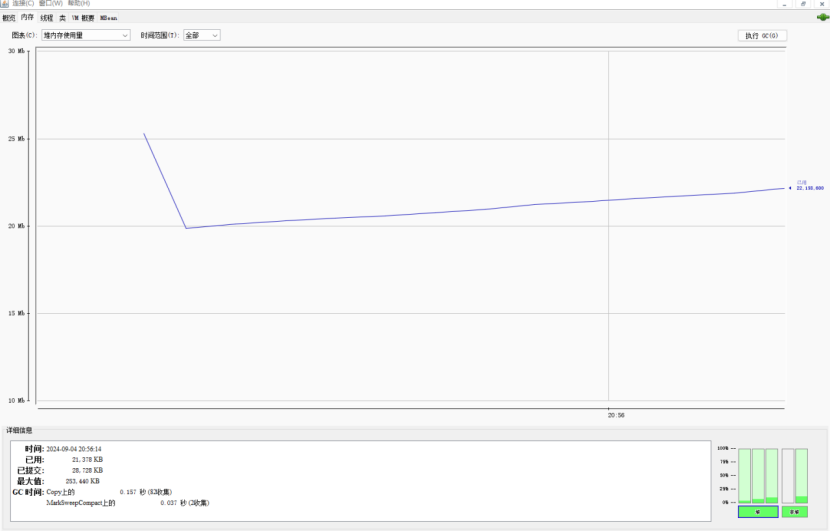
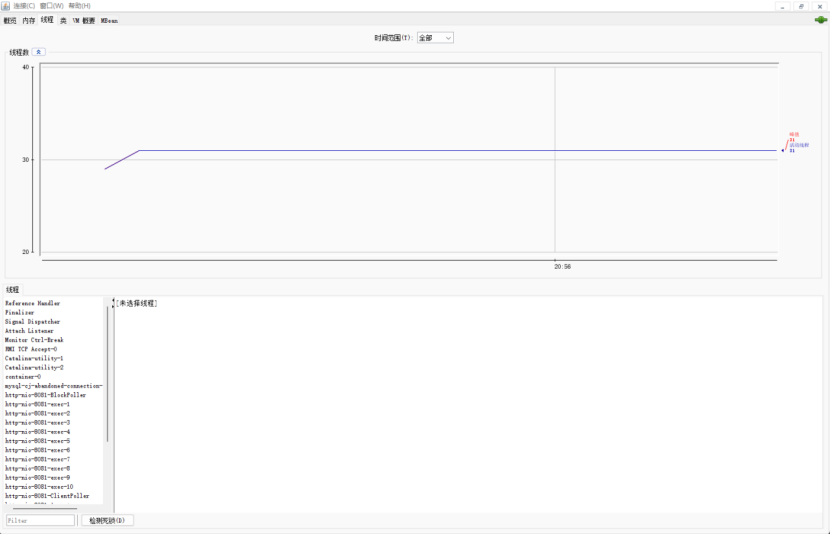
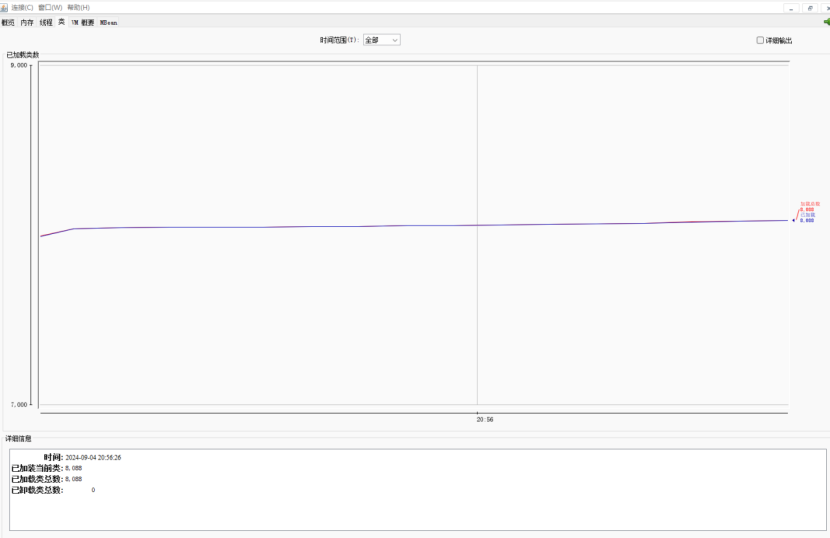
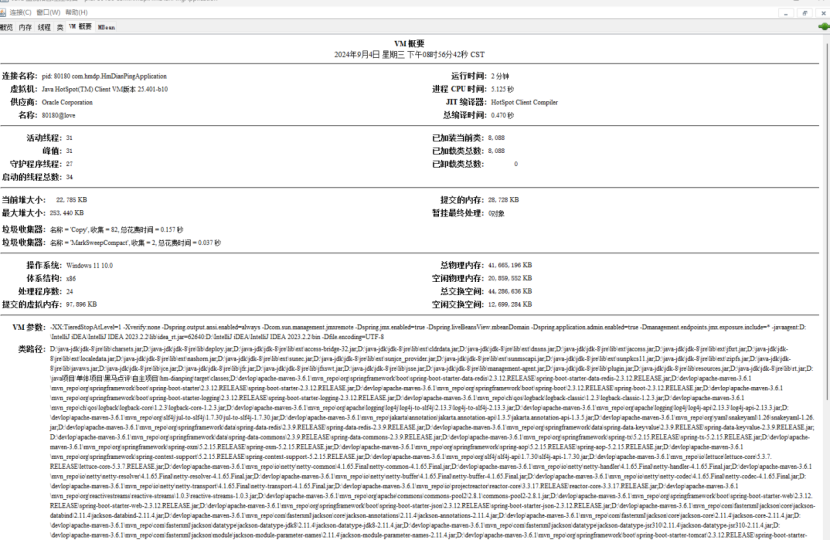
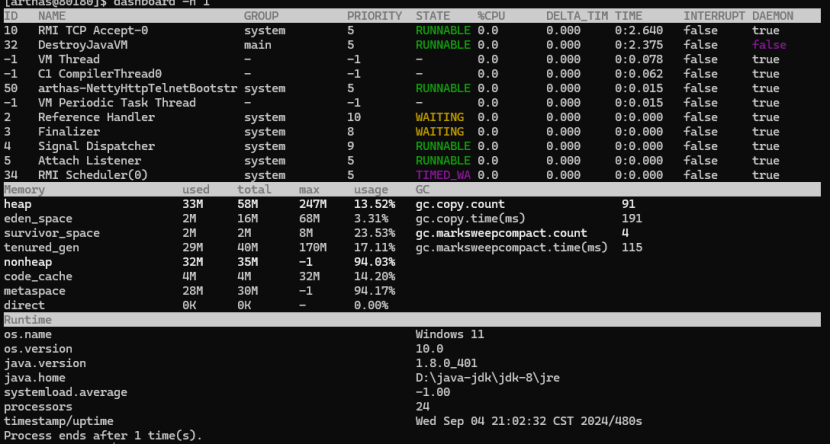
8.2.1.2使用JVM监控工具arthas进行查看
8.2.2高并发状态
8.2.2.1使用JVM监控工具jconsole进行查看
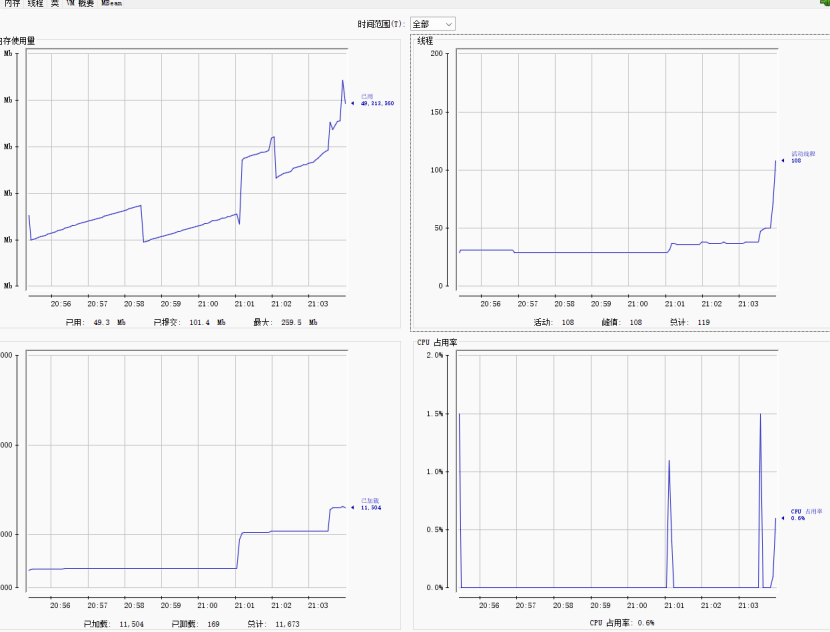
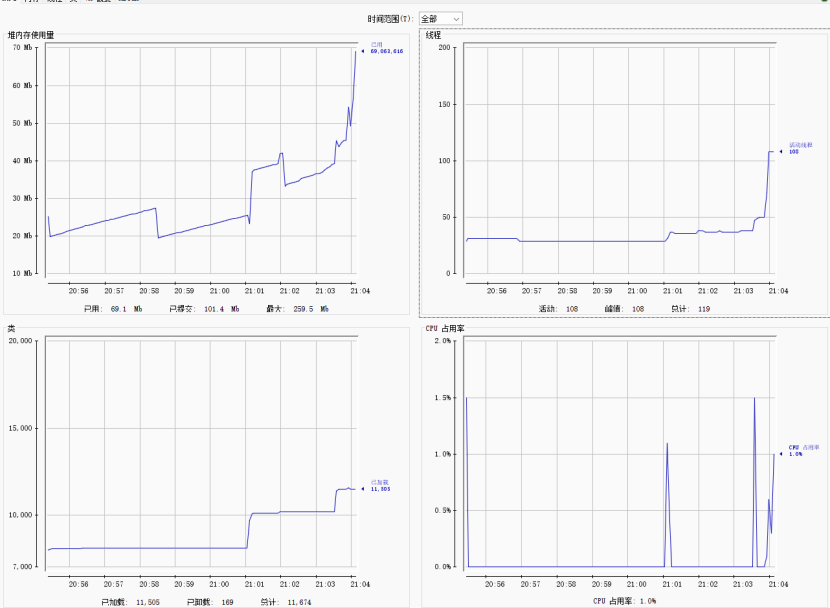
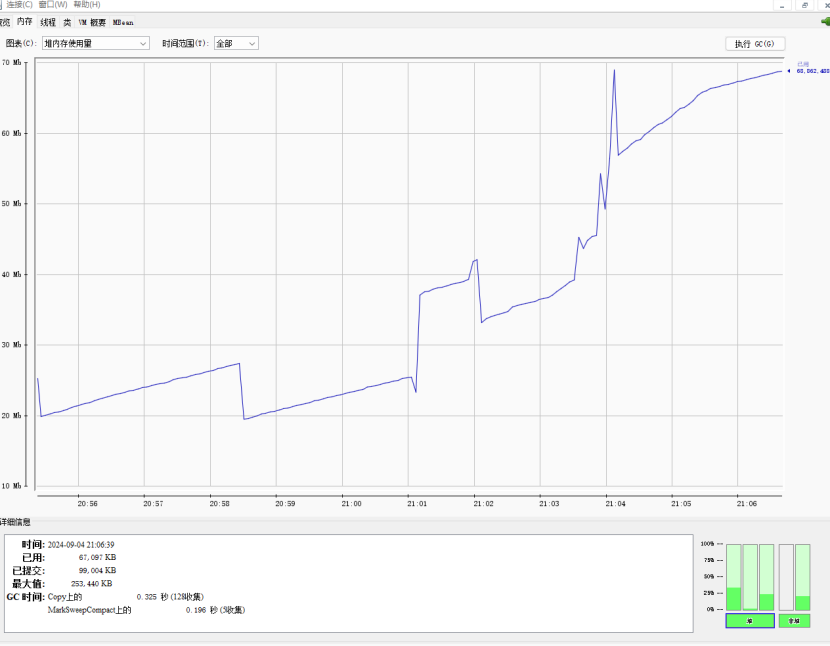
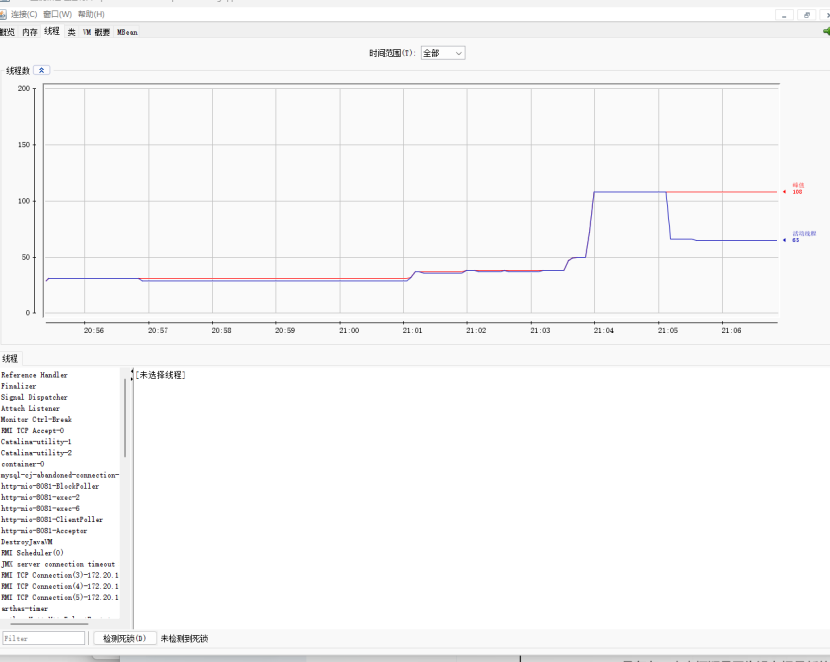

8.2.2.2使用JVM监控工具arthas进行查看
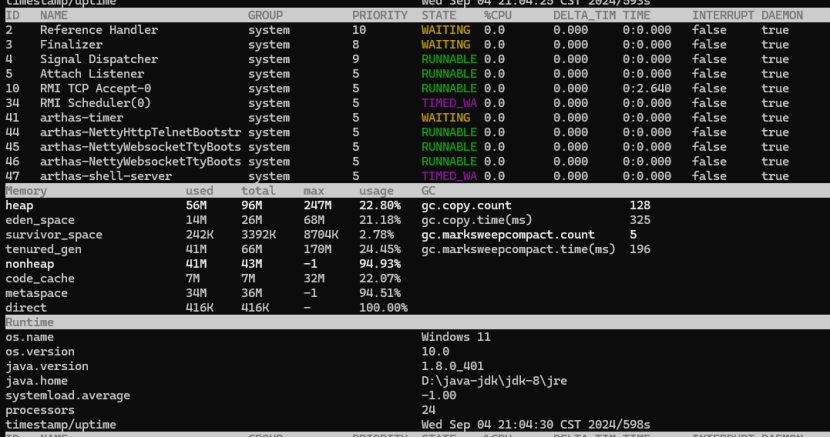
8.2.3终结状态
8.2.3.1使用JVM监控工具jconsole进行查看
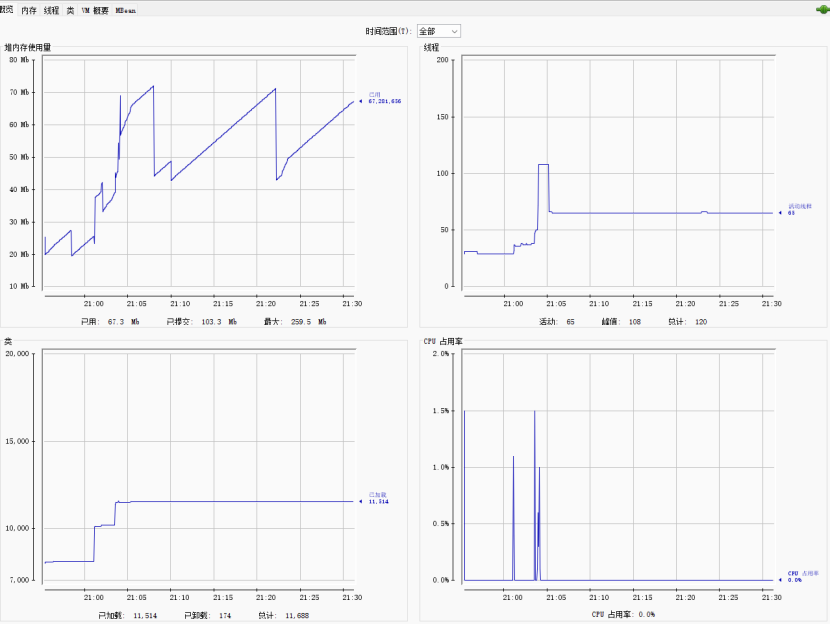
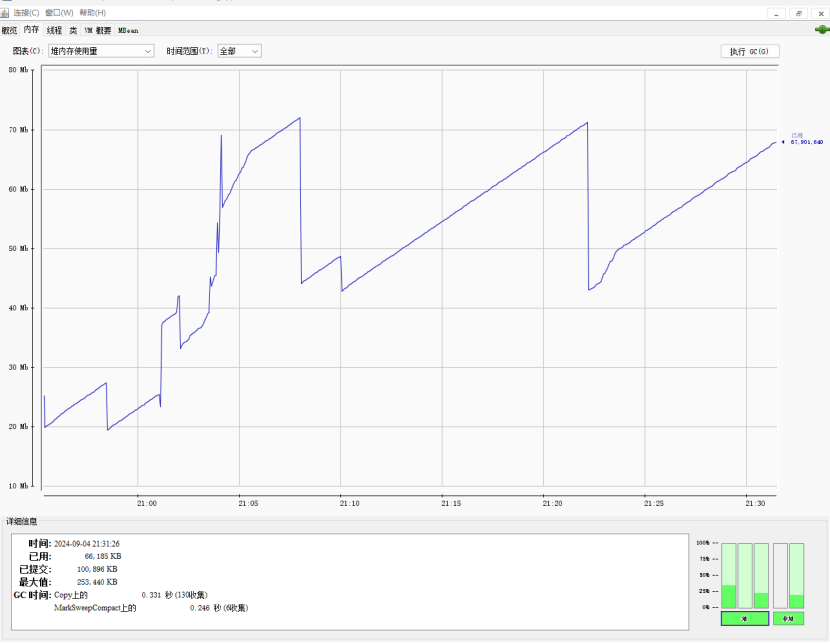
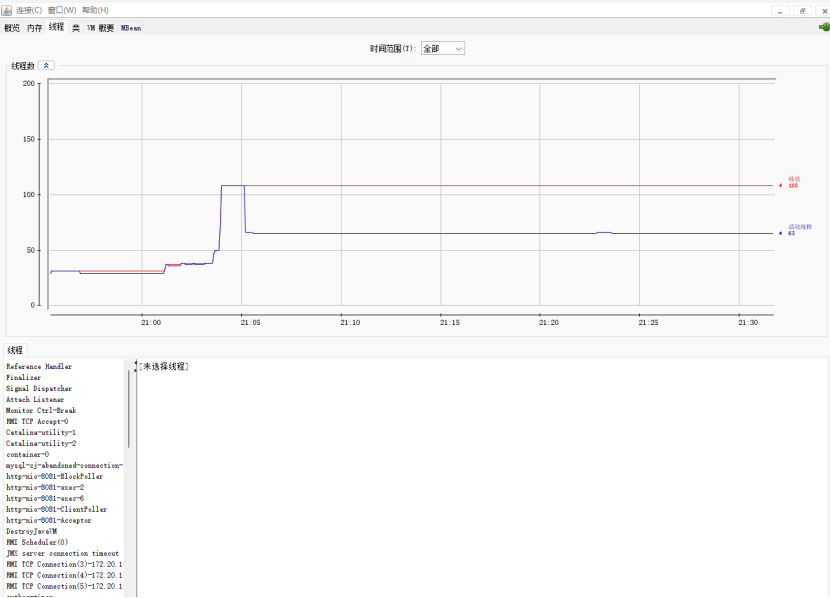
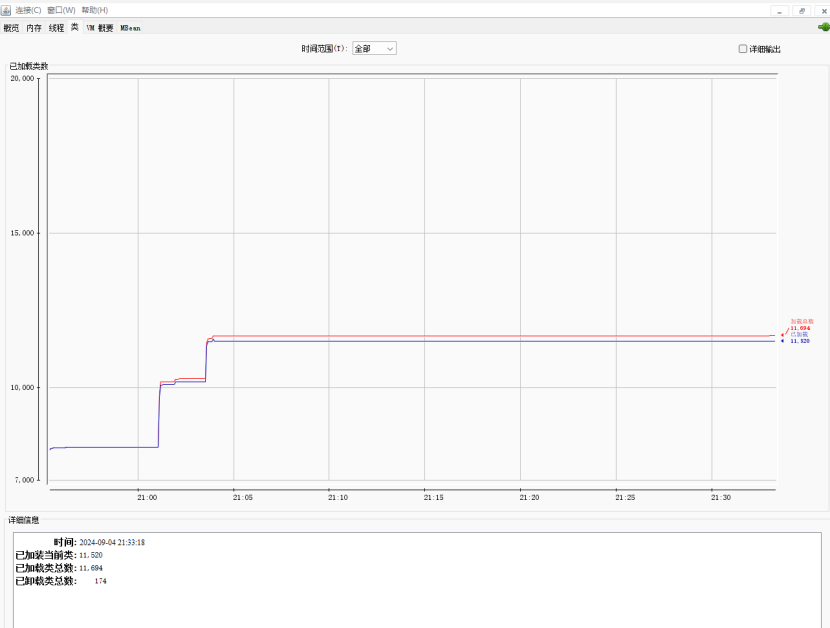

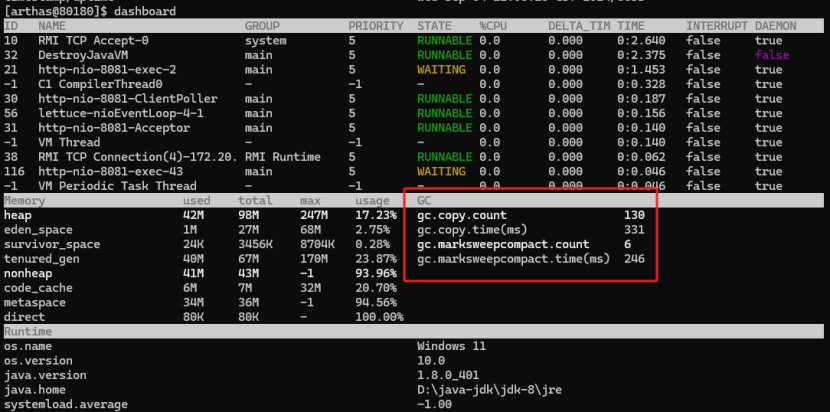
8.2.3.2使用JVM监控工具arthas进行查看
8.2.4见识你的倔强吧!JVM!
8.2.4.1狂轰滥炸
第二次进攻。
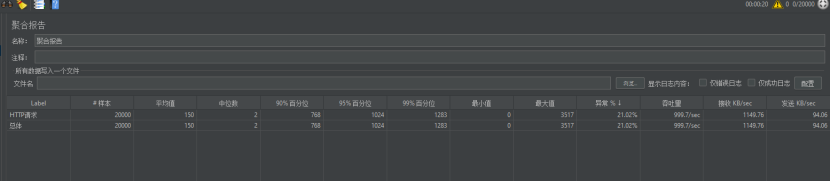
第三次进攻。
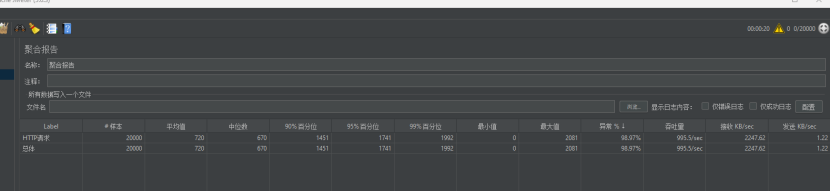
第四次进攻。
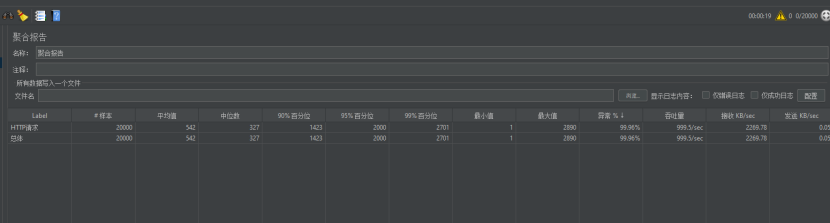
第五次进攻。
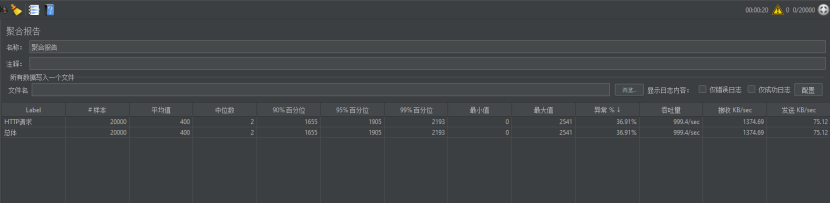
第六次进攻。
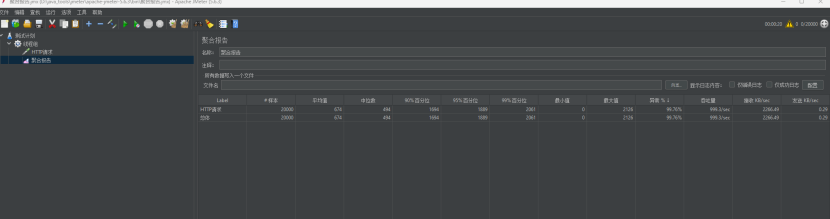
持久进攻2分钟,每秒并发2000次!
其实系统进入一种自卫的状态,你打不死我,我坚强的活着,你打一会我恢复一次,只要你停下来,我就能自愈。
虽然异常达到了不可用状态(86.56%)。
但是它崛起的撑住了。
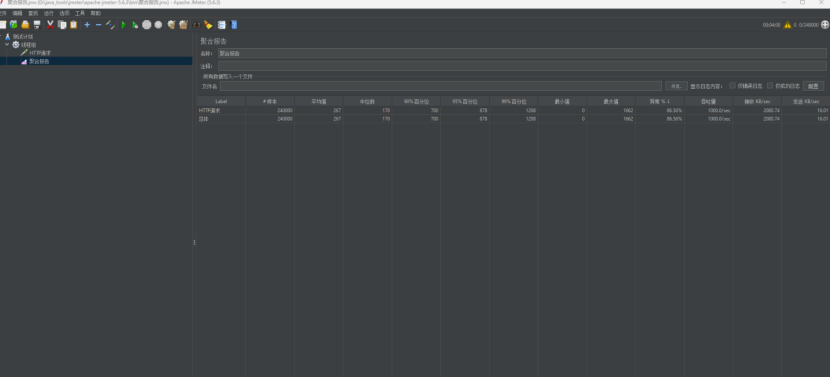
8.2.4.2狂轰滥炸
其实只要不是发生内存泄漏,整个垃圾回收处理器还是能去优雅地处理的。
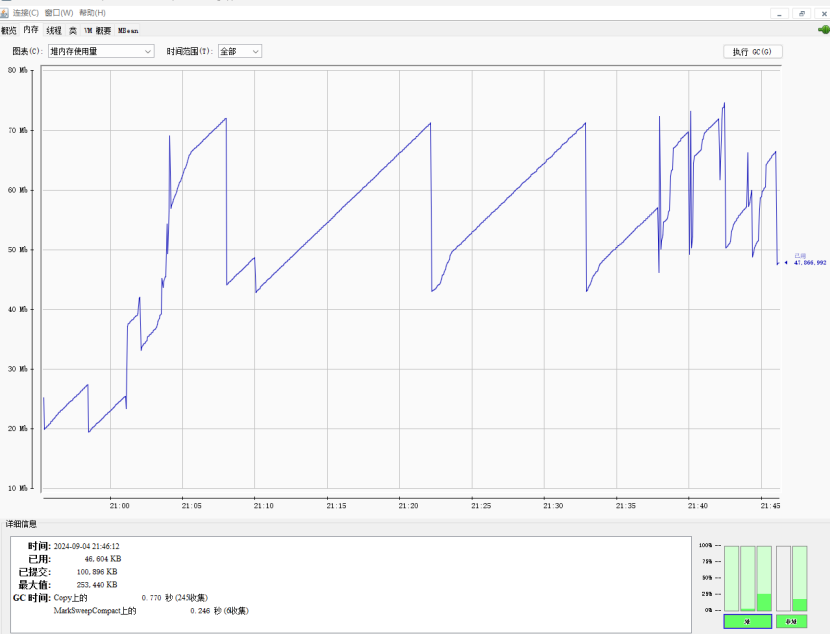
但是full GC频繁,还是需要进行去仔细研究一下堆内存的设置。
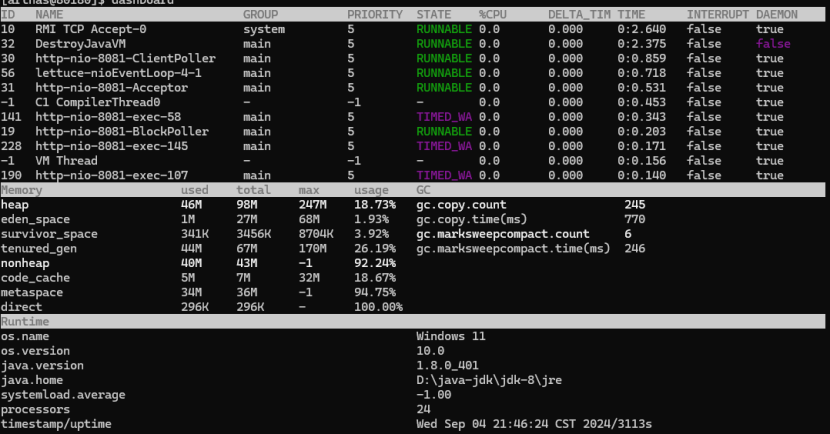
确实是这样的,整个系统似乎内存回收不掉了,回不到高压前的状态了,需要研究一下。