RAGFlow (二)小试牛刀:登陆页重构
基于目前强大的AI能力,我们让其对RAGFlow项目做总结,方便我们快速的理解代码结构,找到二开的入手点。
如下为AI阅读了仓库后,生成的部分项目开发指引:
🎯 1. 项目概述
1.1 项目简介
RAGFlow 是一个基于深度文档理解的开源 RAG(检索增强生成)引擎,为各种规模的企业提供简化的 RAG 工作流。
核心特点:
- 🧠 基于深度文档理解的知识提取
- 🔄 模板化文本切片
- 📄 支持多源异构数据格式
- 🎯 可视化的文本切片与人工干预
- 🔍 多路召回与融合重排序
- 📚 可追溯的引用和答案
1.2 技术架构
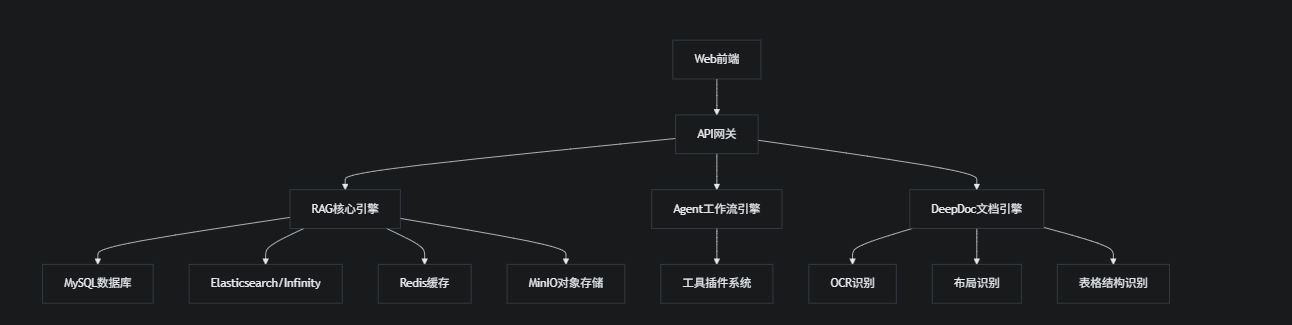
🏗️ 2. 项目结构分析
2.1 顶层目录结构
ragflow/
├── web/ # 主前端应用(React + UmiJS + Ant Design)
├── api/ # Flask后端API服务
├── rag/ # RAG核心引擎
├── deepdoc/ # 深度文档理解模块
├── agent/ # Agent工作流引擎
├── graphrag/ # 图RAG模块
├── agentic_reasoning/ # 代理推理模块
├── plugin/ # 插件系统
├── mcp/ # MCP服务
├── sandbox/ # 沙箱环境
├── docker/ # Docker部署配置
├── conf/ # 配置文件
├── sdk/ # SDK工具包
└── test/ # 测试文件2.2 核心模块详解
🎨 前端应用模块
主前端应用 (web/)
- 技术栈: React 18 + UmiJS 4 + TypeScript + Ant Design 5
- 功能: 用户界面、文档管理、对话系统、知识库管理
- 关键目录:
web/src/ ├── components/ # 通用组件 ├── pages/ # 页面组件 ├── hooks/ # 自定义Hooks ├── services/ # API服务 ├── utils/ # 工具函数 ├── constants/ # 常量定义 └── locales/ # 国际化
........此处省略一万字
基于上述总结,我们知道RAGFlow的前端主要在web/目录下。前端框架及脚手架是React+ UmiJS 。由此,我们能找到我们准备修改的登陆页代码路径。
于是,在一通操作后,

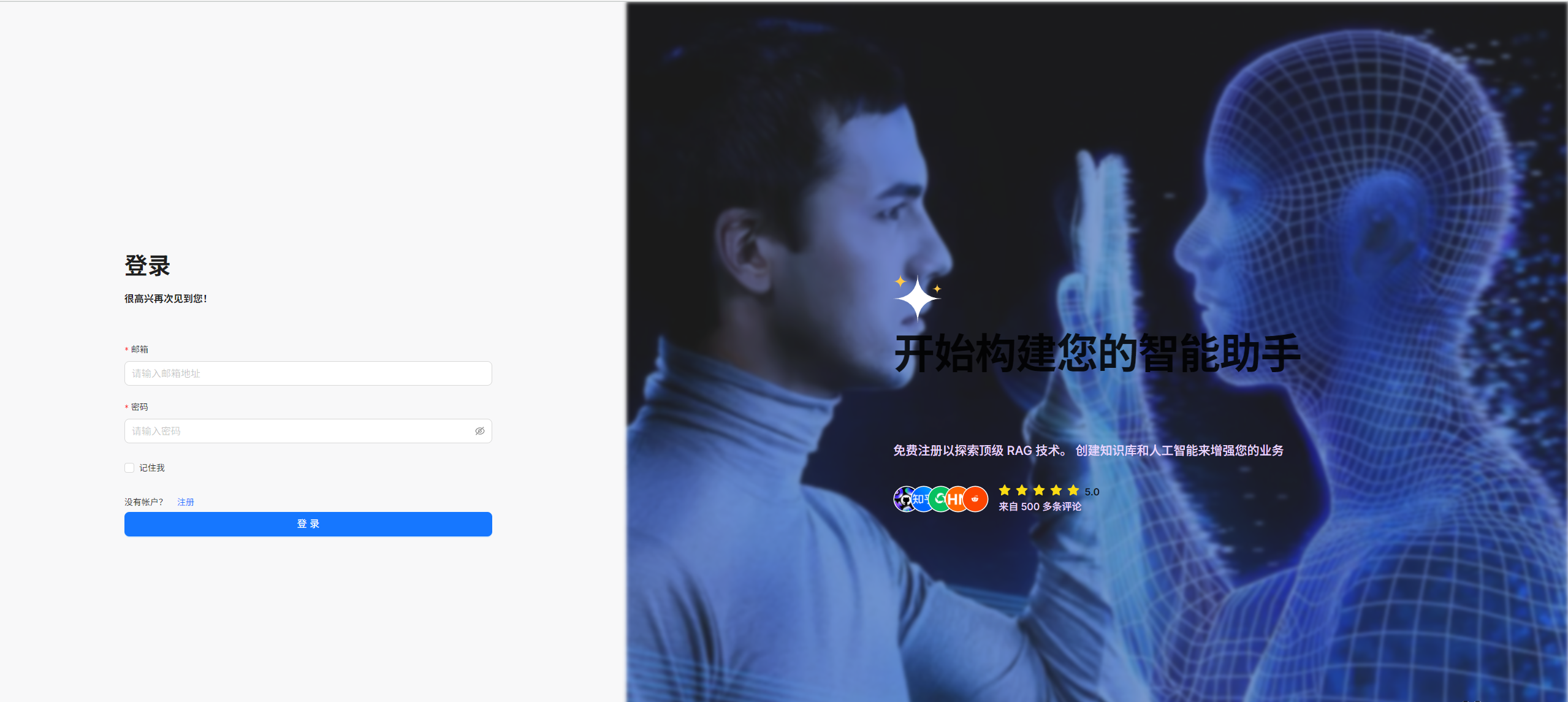
我们就能把原来的登录页从这样:
变成这样:

emmmm,个人看上去就顺眼多了。
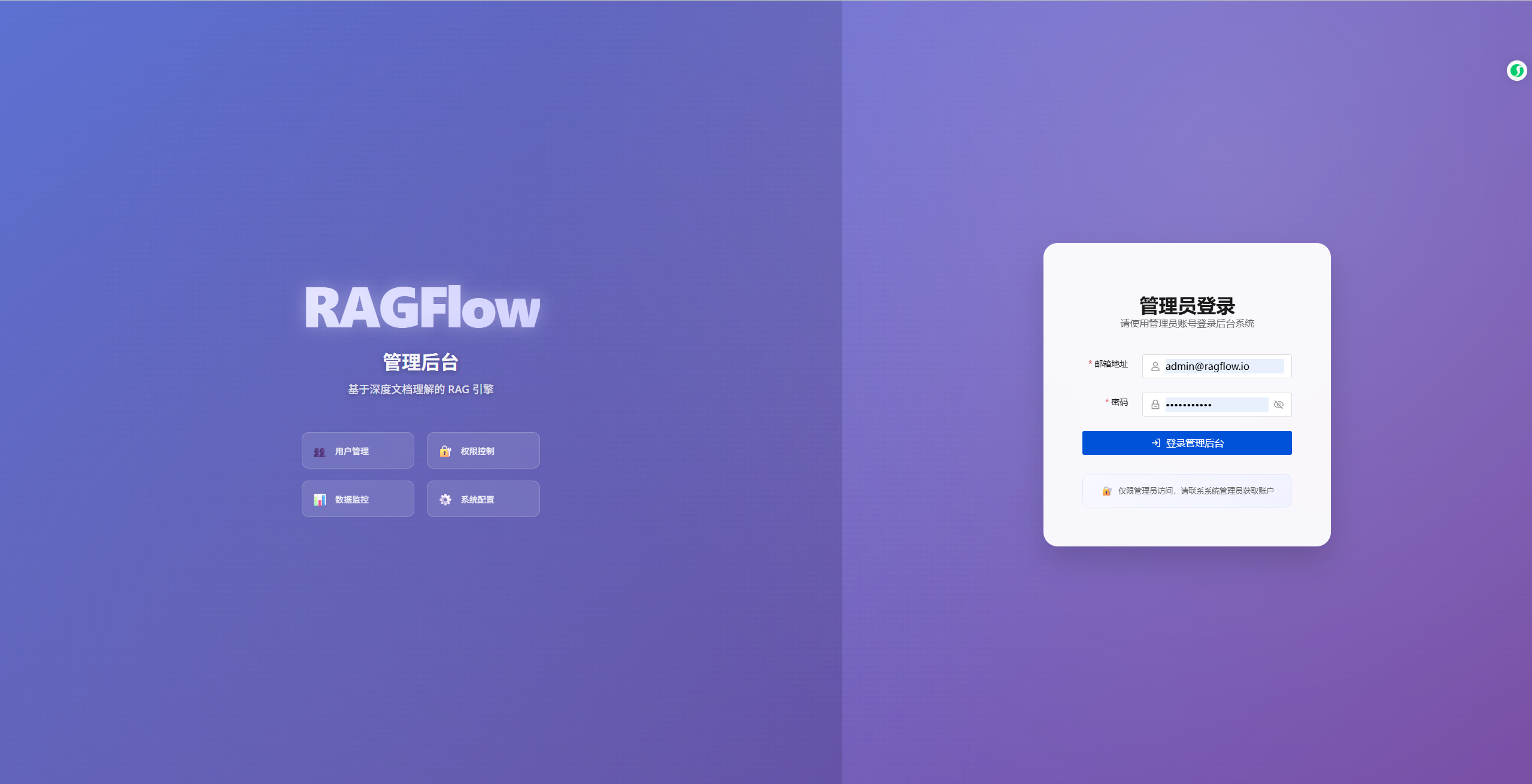
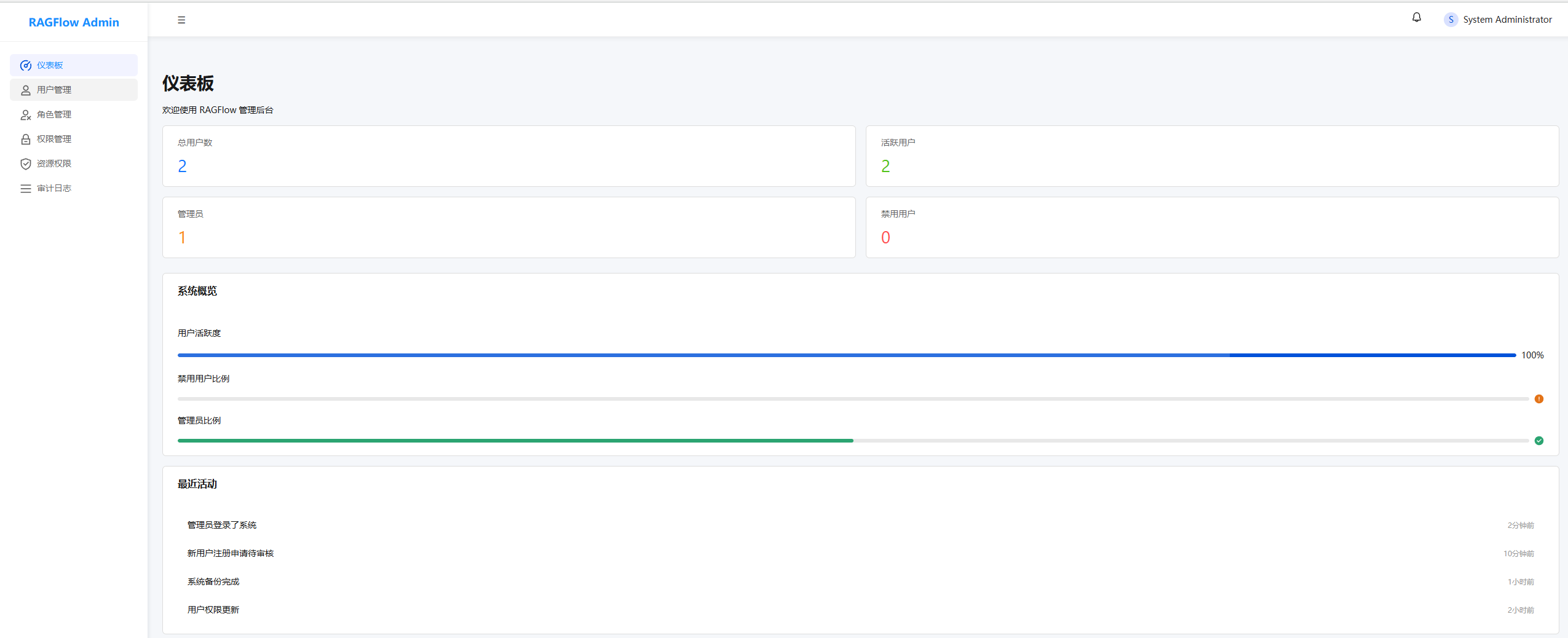
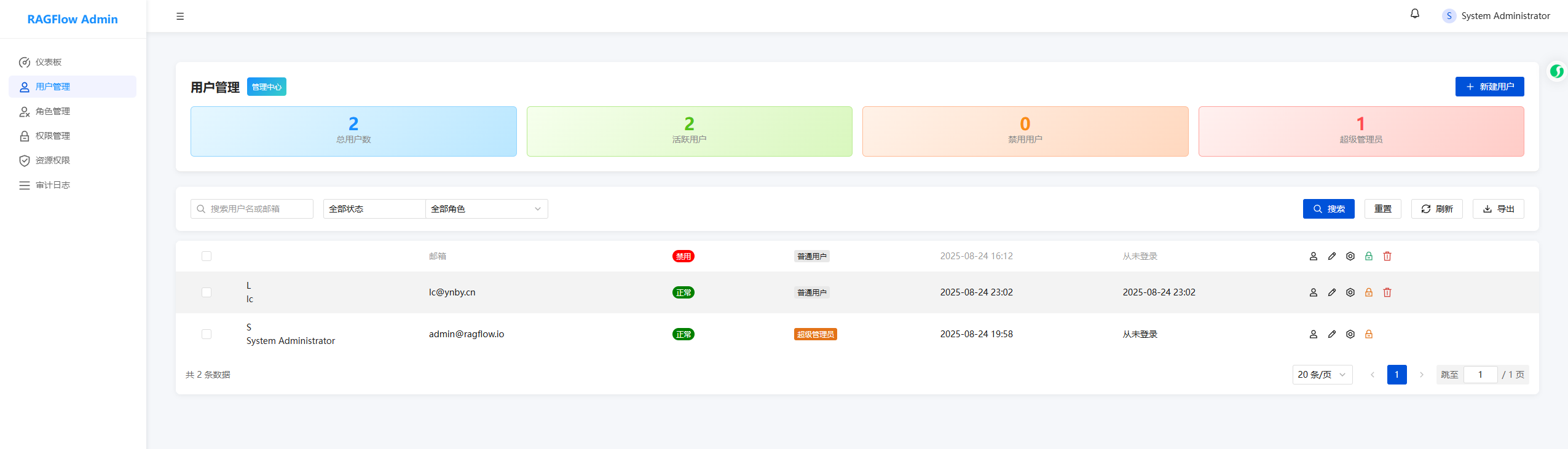
在修改中,按惯例,我们移除了首页的注册选项,
通过统一的后台用户管理页面进行管理
类似这种:
写到这里写不动了,RABC实现起来太掉头发了,后台管理相关的下篇再见👋
