【datawhale组队学习】RAG技术 - TASK04 向量及多模态嵌入(第三章1、2节)
教程地址:https://github.com/datawhalechina/all-in-rag
文章目录
- 向量嵌入
- 一、向量嵌入基础
- 什么是Embedding
- 向量空间的语义表示
- Embedding 在 RAG 中的作用
- 二、Embedding 技术发展
- 静态词嵌入:上下文无关的表示
- 动态上下文嵌入
- RAG 对嵌入技术的新要求
- 三、嵌入模型训练原理
- 核心架构:BERT
- 核心训练任务
- 效果增强策略
- 四、嵌入模型选型指南
- 关键评估维度
- 迭代测试与优化
- 多模态嵌入
- 一、为什么需要多模态嵌入?
- 二、CLIP 模型浅析
- 三、常用多模态嵌入模型(以bge-visualized-m3为例)
- 四、代码示例
向量嵌入
一、向量嵌入基础
什么是Embedding
向量嵌入(Embedding)是一种将真实世界中复杂、高维的数据对象(如文本、图像、音频、视频等)转换为数学上易于处理的、低维、稠密的连续数值向量的技术。
想象一下,我们将每一个词、每一段话、每一张图片都放在一个巨大的多维空间里,并给它一个独一无二的坐标。这个坐标就是一个向量,它“嵌入”了原始数据的所有关键信息。这个过程,就是 Embedding。
- 数据对象:任何信息,如文本“你好世界”,或一张猫的图片。
- Embedding 模型:一个深度学习模型,负责接收数据对象并进行转换。
- 输出向量:一个固定长度的一维数组,例如
[0.16, 0.29, -0.88, ...]。这个向量的维度(长度)通常在几百到几千之间。

向量空间的语义表示
Embedding 的真正威力在于,它产生的向量不是随机数值的堆砌,而是对数据语义的数学编码。
- 核心原则:在 Embedding 构建的向量空间中,语义上相似的对象,其对应的向量在空间中的距离会更近;而语义上不相关的对象,它们的向量距离会更远。
- 关键度量:我们通常使用以下数学方法来衡量向量间的“距离”或“相似度”:
- 余弦相似度 (Cosine Similarity):计算两个向量夹角的余弦值。值越接近 1,代表方向越一致,语义越相似。这是最常用的度量方式。
- 点积 (Dot Product):计算两个向量的乘积和。在向量归一化后,点积等价于余弦相似度。
- 欧氏距离 (Euclidean Distance):计算两个向量在空间中的直线距离。距离越小,语义越相似。
Embedding 在 RAG 中的作用
语义检索的基础
RAG 的“检索”环节通常以基于 Embedding 的语义搜索为核心。通用流程如下:
- 离线索引构建:将知识库内文档切分后,使用 Embedding 模型将每个文档块(Chunk)转换为向量,存入专门的向量数据库中。
- 在线查询检索:当用户提出问题时,使用同一个 Embedding 模型将用户的问题也转换为一个向量。
- 相似度计算:在向量数据库中,计算“问题向量”与所有“文档块向量”的相似度。
- 召回上下文:选取相似度最高的 Top-K 个文档块,作为补充的上下文信息,与原始问题一同送给大语言模型(LLM)生成最终答案。
决定检索质量的关键
Embedding 的质量直接决定了 RAG 检索召回内容的准确性与相关性。
一个优秀的 Embedding 模型能够精准捕捉问题和文档之间的深层语义联系,即使用户的提问和原文的表述不完全一致。
反之,一个劣质的 Embedding 模型可能会因为无法理解语义而召回不相关或错误的信息,从而“污染”提供给 LLM 的上下文,导致最终生成的答案质量低下。
二、Embedding 技术发展
Embedding 技术的发展与自然语言处理(NLP)的进步紧密相连,尤其是在 RAG 框架出现后,对嵌入技术提出了新的要求。
Embedding演进路径大致可分为以下几个关键阶段。
静态词嵌入:上下文无关的表示
代表模型:Word2Vec (2013), GloVe (2014)
主要原理:为词汇表中的每个单词生成一个固定的、与上下文无关的向量。例如,Word2Vec 通过 Skip-gram 和 CBOW 架构,利用局部上下文窗口学习词向量,并验证了向量运算的语义能力(如 国王 - 男人 + 女人 ≈ 王后)。GloVe 则融合了全局词-词共现矩阵的统计信息。
局限性:无法处理一词多义问题。在“苹果公司发布了新手机”和“我吃了一个苹果”中,“苹果”的词向量是完全相同的,这限制了其在复杂语境下的语义表达能力。
动态上下文嵌入
2017年,Transformer 架构的诞生带来了自注意力机制(Self-Attention),它允许模型在生成一个词的向量时,动态地考虑句子中所有其他词的影响。基于此,2018年 BERT 模型利用 Transformer 的编码器,通过掩码语言模型(MLM)等自监督任务进行预训练,生成了深度上下文相关的嵌入。同一个词在不同语境中会生成不同的向量,这有效解决了静态嵌入的一词多义难题。
RAG 对嵌入技术的新要求
2020年,RAG 框架的提出,旨在解决大型语言模型知识固化(其内部知识难以更新)和幻觉(生成的内容可能不符合事实且无法溯源)的问题。RAG 通过“检索-生成”范式,动态地为 LLM 注入外部知识。这一过程的核心是语义检索,它完全依赖于高质量的向量嵌入。
RAG 的兴起对嵌入技术提出了更高、更具体的要求:
- 领域自适应能力:通用的嵌入模型在专业领域(如法律、医疗)可能表现不佳。因此,能够通过微调或使用指令(如 INSTRUCTOR 模型)来适应特定领域术语和语义的嵌入模型变得至关重要。
- 多粒度与多模态支持:RAG 系统需要处理的不仅仅是短句,还可能包括长文档、代码,甚至是图像和表格。这就要求嵌入模型能够处理不同长度和类型的输入数据。
- 检索效率与混合检索:嵌入向量的维度和模型大小直接影响存储成本和检索速度。同时,为了结合语义相似性(密集检索)和关键词匹配(稀疏检索)的优点,支持混合检索的嵌入模型(如 BGE-M3)应运而生,在某些任务中成为提升召回率的关键。
三、嵌入模型训练原理
核心架构:BERT
现代嵌入模型的核心通常是 Transformer 的编码器(Encoder)部分,BERT 就是其中的典型代表。它通过堆叠多个 Transformer Encoder 层来构建一个深度的双向表示学习网络。
核心训练任务
BERT 的成功很大程度上归功于其巧妙的自监督学习策略,它允许模型从海量的、无标注的文本数据中学习知识。
任务一:掩码语言模型 (Masked Language Model, MLM)
过程:
- 随机地将输入句子中 15% 的词元(Token)替换为一个特殊的 [MASK] 标记。
- 让模型去预测这些被遮盖住的原始词元是什么。
**目标:**通过这个任务,模型被迫学习每个词元与其上下文之间的关系,从而掌握深层次的语境语义。
任务二:下一句预测 (Next Sentence Prediction, NSP)
过程:
- 构造训练样本,每个样本包含两个句子 A 和 B。
- 其中 50% 的样本,B 是 A 的真实下一句(IsNext);另外 50% 的样本,B 是从语料库中随机抽取的句子(NotNext)。
- 让模型判断 B 是否是 A 的下一句。
目标:这个任务让模型学习句子与句子之间的逻辑关系、连贯性和主题相关性。
重要说明:后续的研究(如 RoBERTa)发现2,NSP 任务可能过于简单,甚至会损害模型性能。因此,许多现代的预训练模型(如 RoBERTa、SBERT)已经放弃了 NSP 任务。
效果增强策略
虽然 MLM 和 NSP 赋予了模型强大的基础语义理解能力,但为了在检索任务中表现更佳,现代嵌入模型通常会引入更具针对性的训练策略。
- 度量学习 (Metric Learning):
- 思想:直接以**“相似度”**作为优化目标。
- 重点优化距离函数的 “判别性”,确保对任务有用的相似性被放大,无用的被抑制。
- 目标是学习一个 “任务专用” 的距离度量函数,直接服务于特定下游任务(如分类、检索、推荐)。
- 方法:收集大量相关的文本对(例如,(问题,答案)、(新闻标题,正文))。训练的目标是优化向量空间中的相对距离:让“正例对”的向量表示在空间中被“拉近”,而“负例对”的向量表示被“推远”。关键在于优化排序关系,而非追求绝对的相似度值(如 1 或 0),因为过度追求极端值可能导致模型过拟合。
- 对比学习 (Contrastive Learning):
- 思想:在向量空间中,将相似的样本“拉近”,将不相似的样本“推远”。
- 目标是学习 “通用的特征表示”,不直接针对某个下游任务,而是让模型学到数据本身的内在结构(如语义相似性、视觉一致性)。
- 重点优化特征分布的 “一致性”,让相似样本的特征在向量空间中聚集,不同样本的特征均匀分散。
- 方法:构建一个三元组(Anchor, Positive, Negative)。其中,Anchor 和 Positive 是相关的(例如,同一个问题的两种不同问法),Anchor 和 Negative 是不相关的。训练的目标是让 distance(Anchor, Positive) 尽可能小,同时让 distance(Anchor, Negative) 尽可能大。
四、嵌入模型选型指南
https://huggingface.co/spaces/mteb/leaderboard
是一个由 Hugging Face 维护的、全面的文本嵌入模型评测基准。它涵盖了分类、聚类、检索、排序等多种任务,并提供了公开的排行榜,为评估和选择嵌入模型提供了重要的参考依据。
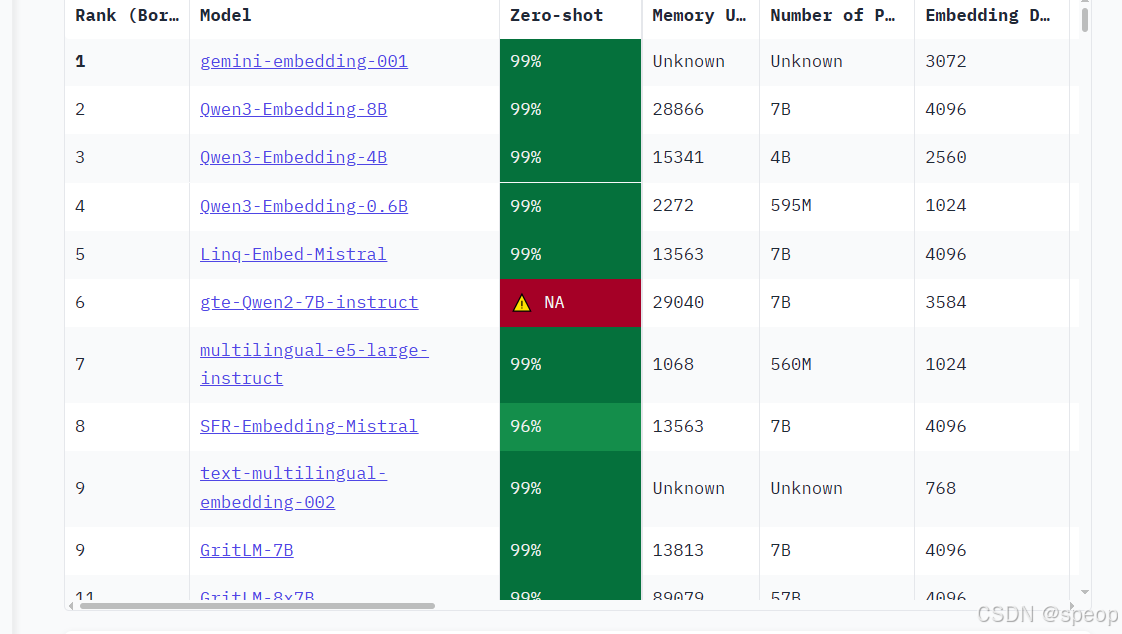
下面这张图是网站中的模型评估图像,非常直观地展示了在选择开源嵌入模型时需要权衡的四个核心维度:
横轴 - 模型参数量 (Number of Parameters):代表了模型的大小。通常,参数量越大的模型(越靠右),其潜在能力越强,但对计算资源的要求也越高。
纵轴 - 平均任务得分 (Mean Task Score):代表了模型的综合性能。这个分数是模型在分类、聚类、检索等一系列标准 NLP 任务上的平均表现。分数越高(越靠上),说明模型的通用语义理解能力越强。
气泡大小 - 嵌入维度 (Embedding Size):代表了模型输出向量的维度。气泡越大,维度越高,理论上能编码更丰富的语义细节,但同时也会占用更多的存储和计算资源。
气泡颜色 - 最大处理长度 (Max Tokens):代表了模型能处理的文本长度上限。颜色越深,表示模型能处理的 Token 数量越多,对长文本的适应性越好。
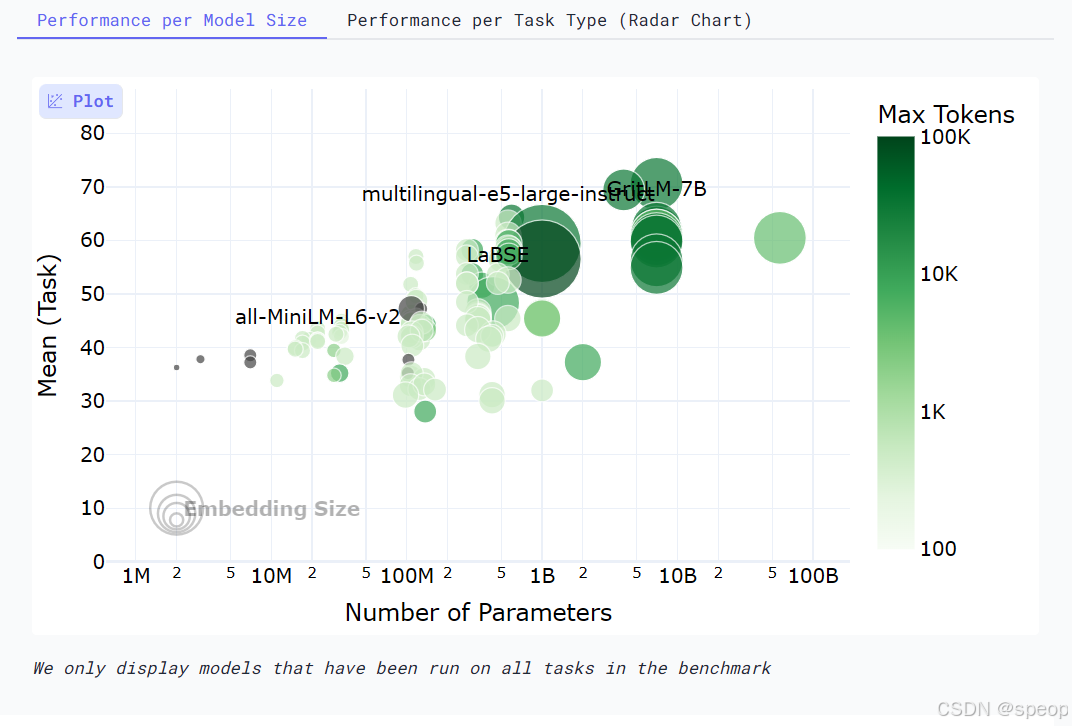
MTEB 榜单可以帮助我们快速筛选掉大量不合适的模型。但需要注意,榜单上的得分是在通用数据集上评测的,可能无法完全反映模型在你特定业务场景下的表现。
关键评估维度
在查看榜单时,除了分数,你还需要关注以下几个关键维度:
- 任务 (Task):对于 RAG 应用,需要重点关注模型在
Retrieval(检索) 任务下的排名。 - 语言 (Language):模型是否支持你的业务数据所使用的语言?对于中文 RAG,应选择明确支持中文或多语言的模型。
- 模型大小 (Size):模型越大,通常性能越好,但对硬件(显存)的要求也越高,推理速度也越慢。需要根据你的部署环境和性能要求来权衡。
- 维度 (Dimensions):向量维度越高,能编码的信息越丰富,但也会占用更多的存储空间和计算资源。
- 最大 Token 数 (Max Tokens):这决定了模型能处理的文本长度上限。这个参数是你设计文本分块(Chunking)策略时必须考虑的重要依据,块大小不应超过此限制。
- 得分与机构 (Score & Publisher):结合模型的得分排名和其发布机构的声誉进行初步筛选。知名机构发布的模型通常质量更有保障。
- 成本 (Cost):如果是使用 API 服务的模型,需要考虑其调用成本;如果是自部署开源模型,则需要评估其对硬件资源的消耗(如显存、内存)以及带来的运维成本。
迭代测试与优化
不要只依赖公开榜单做最终决定。
- 确定基线 (Baseline):根据上述维度,选择几个符合要求的模型作为你的初始基准模型。
- 构建私有评测集:根据真实业务数据,手动创建一批高质量的评测样本,每个样本包含一个典型用户问题和它对应的标准答案(或最相关的文档块)。
- 迭代优化:
- 使用基线模型在你的私有评测集上运行,评估其召回的准确率和相关性。
- 如果效果不理想,可以尝试更换模型,或者调整 RAG 流程的其他环节(如文本分块策略)。
- 通过几轮的对比测试和迭代优化,最终选出在你的特定场景下表现最佳的那个“心仪”模型。
多模态嵌入
现代 AI 的一项重要突破,是将简单的词向量发展成了能统一理解图文、音视频的复杂系统。这一发展建立在注意力机制、Transformer 架构和对比学习等关键技术之上,它们解决了在共享向量空间中对齐不同数据模态的核心挑战。其发展环环相扣:Word2Vec 为 BERT 的上下文理解铺路,而 BERT 又为 CLIP 等模型的跨模态能力奠定了基础。
一、为什么需要多模态嵌入?
前面的章节介绍了如何为文本创建向量嵌入。然而,仅有文本的世界是不完整的。现实世界的信息是多模态的,包含图像、音频、视频等。传统的文本嵌入无法理解“那张有红色汽车的图片”这样的查询,因为文本向量和图像向量处于相互隔离的空间,存在一堵“模态墙”。
多模态嵌入 (Multimodal Embedding) 的目标正是为了打破这堵墙。其目的是将不同类型的数据(如图像和文本)映射到同一个共享的向量空间。在这个统一的空间里,一段描述“一只奔跑的狗”的文字,其向量会非常接近一张真实小狗奔跑的图片向量。
实现这一目标的关键,在于解决 跨模态对齐 (Cross-modal Alignment) 的挑战。以对比学习、视觉 Transformer (ViT) 等技术为代表的突破,让模型能够学习到不同模态数据之间的语义关联,最终催生了像 CLIP 这样的模型。
二、CLIP 模型浅析
在图文多模态领域,OpenAI 的 CLIP (Contrastive Language-Image Pre-training) 是一个很有影响力的模型,它为多模态嵌入定义了一个有效的范式。
CLIP 的架构清晰简洁。它采用双编码器架构 (Dual-Encoder Architecture),包含一个图像编码器和一个文本编码器,分别将图像和文本映射到同一个共享的向量空间中。
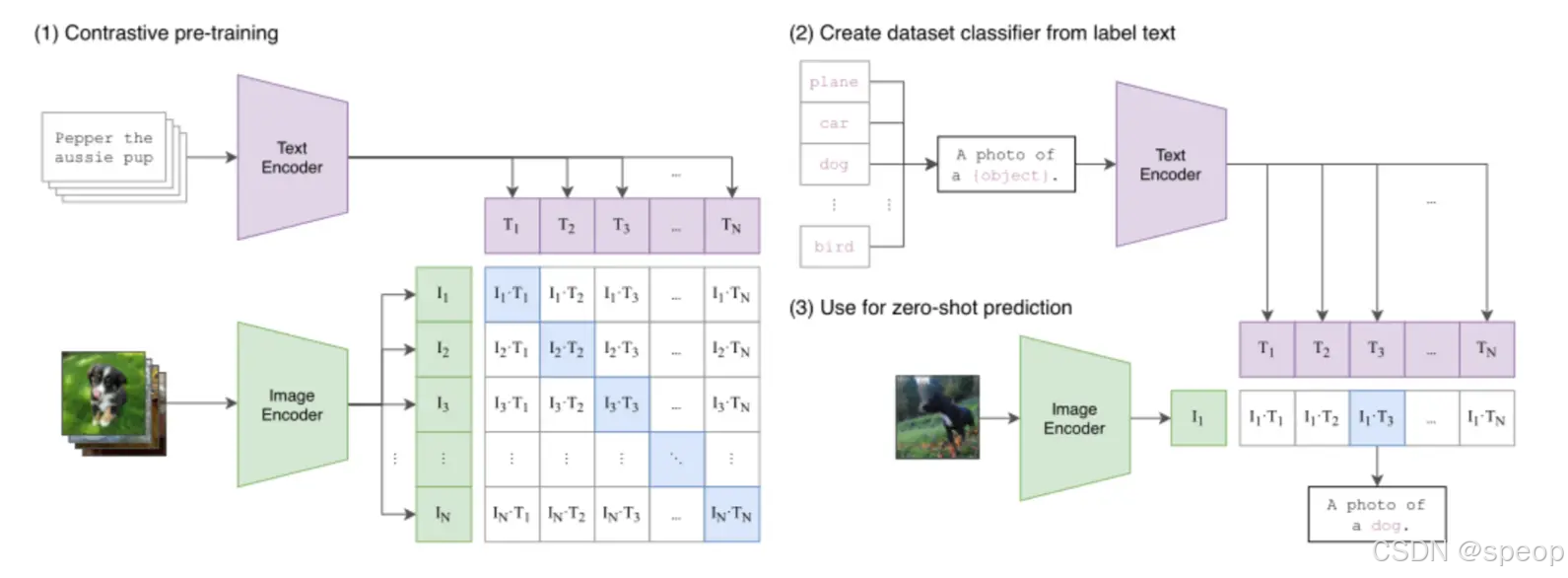
图:CLIP 的工作流程。(1) 通过对比学习训练双编码器,对齐图文向量空间。(2)和(3) 展示了如何利用该空间,通过图文相似度匹配实现零样本预测。
为了让这两个编码器学会**“对齐”不同模态的语义,CLIP 在训练时采用了对比学习 (Contrastive Learning)** 策略。在处理一批图文数据时,模型的目标是:最大化正确图文对的向量相似度,同时最小化所有错误配对的相似度。通过这种“拉近正例,推远负例”的方式,模型从海量数据中学会了将语义相关的图像和文本在向量空间中拉近。
这种大规模的对比学习赋予了 CLIP 有效的零样本(Zero-shot)识别能力。它能将一个传统的分类任务,转化为一个**“图文检索**”问题——例如,要判断一张图片是不是猫,只需计算图片向量与“a photo of a cat”文本向量的相似度即可。这使得 CLIP 无需针对特定任务进行微调,就能实现对视觉概念的泛化理解。
三、常用多模态嵌入模型(以bge-visualized-m3为例)
虽然 CLIP 为图文预训练提供了重要基础,但多模态领域的研究迅速发展,涌现了许多针对不同目标和场景进行优化的模型。例如,BLIP 系列专注于提升细粒度的图文理解与生成能力,而 ALIGN 则证明了利用海量噪声数据进行大规模训练的有效性。
在众多优秀的模型中,由北京智源人工智能研究院(BAAI)开发的 BGE-M3 是一个很有代表性的现代多模态嵌入模型。它在多语言、多功能和多粒度处理上都表现出色,体现了当前技术向“更统一、更全面”发展的趋势。
BGE-M3 的核心特性可以概括为“M3”:
- 多语言性 (Multi-Linguality):原生支持超过 100 种语言的文本与图像处理,能够轻松实现跨语言的图文检索。
- 多功能性 (Multi-Functionality):在单一模型内同时支持密集检索(Dense Retrieval)、多向量检索(Multi-Vector Retrieval)和稀疏检索(Sparse Retrieval),为不同应用场景提供了灵活的检索策略。
- 多粒度性 (Multi-Granularity):能够有效处理从短句到长达 8192 个 token 的长文档,覆盖了更广泛的应用需求。
在技术架构上,BGE-M3 采用了基于XLM-RoBERTa 优化的联合编码器,并对视觉处理机制进行了创新。它不同于 CLIP 对整张图进行编码的方式,而是采用网格嵌入 (Grid-Based Embeddings),将图像分割为多个网格单元并独立编码。这种设计显著提升了模型对图像局部细节的捕捉能力,在处理多物体重叠等复杂场景时更具优势。
四、代码示例
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
#通过设置HF_ENDPOINT为国内镜像,解决 HuggingFace 资源访问慢的问题。
import torch
from visual_bge.visual_bge.visual_bge.modeling import Visualized_BGE
#Visualized_BGE是一个支持图文跨模态理解的模型,基于 BGE(BAAI General Embedding)扩展而来。model = Visualized_BGE(model_name_bge="BAAI/bge-base-en-v1.5",# 基础文本编码器(BGE文本模型)model_weight="../../models/bge/Visualized_base_en_v1.5.pth"# # 预训练的图文融合权重文件)
model.eval() # 切换到评估模式(关闭dropout等训练特有的层
#eval()确保模型在推理时使用固定的参数,避免随机波动。#特征编码(向量提取)
with torch.no_grad():# 关闭梯度计算,节省内存并加速推理# 纯文本编码:将文本"datawhale开源组织的logo"转换为向量text_emb = model.encode(text="datawhale开源组织的logo")
#model.encode()是核心方法,支持三种输入模式:
#仅文本(text参数):输出文本特征向量。
#仅图像(image参数):输出图像特征向量。
#图文混合(同时传text和image):输出融合了文本和图像信息的特征向量。
#torch.no_grad()用于推理阶段,减少内存占用并加速计算。# 纯图像编码:分别对两张DataWhale logo图片编码img_emb_1 = model.encode(image="../../data/C3/imgs/datawhale01.png")multi_emb_1 = model.encode(image="../../data/C3/imgs/datawhale01.png", text="datawhale开源组织的logo")# 图文混合编码:将图片与文本结合编码(同一文本+不同图片)img_emb_2 = model.encode(image="../../data/C3/imgs/datawhale02.png")multi_emb_2 = model.encode(image="../../data/C3/imgs/datawhale02.png", text="datawhale开源组织的logo")# 计算相似度
# 向量点积计算相似度(在特征向量已归一化的情况下,点积等价于余弦相似度)
sim_1 = img_emb_1 @ img_emb_2.T # 两张图片的相似度
sim_2 = img_emb_1 @ multi_emb_1.T# 第一张图 与 第一张图+文本的相似度
sim_3 = text_emb @ multi_emb_1.T # 纯文本 与 第一张图+文本的相似度
sim_4 = multi_emb_1 @ multi_emb_2.T # 两个图文组合(同文本+不同图)的相似度print("=== 相似度计算结果 ===")
print(f"纯图像 vs 纯图像: {sim_1}")
print(f"图文结合1 vs 纯图像: {sim_2}")
print(f"图文结合1 vs 纯文本: {sim_3}")
print(f"图文结合1 vs 图文结合2: {sim_4}")# 向量信息分析
print("\n=== 嵌入向量信息 ===")
print(f"多模态向量维度: {multi_emb_1.shape}")
print(f"图像向量维度: {img_emb_1.shape}")
print(f"多模态向量示例 (前10个元素): {multi_emb_1[0][:10]}")
print(f"图像向量示例 (前10个元素): {img_emb_1[0][:10]}")

代码解读:
- 模型架构:
Visualized_BGE是通过将图像token嵌入集成到BGE文本嵌入框架中构建的通用多模态嵌入模型,具备处理超越纯文本的多模态数据的灵活性。 - 模型参数:
model_name_bge: 指定底层BGE文本嵌入模型,继承其强大的文本表示能力。model_weight: Visual BGE的预训练权重文件,包含视觉编码器参数。
- 多模态编码能力: Visual BGE提供了编码多模态数据的多样性,支持纯文本、纯图像或图文组合的格式:
- 纯文本编码: 保持原始BGE模型的强大文本嵌入能力。
- 纯图像编码: 使用基于EVA-CLIP的视觉编码器处理图像。
- 图文联合编码: 将图像和文本特征融合到统一的向量空间。
- 应用场景: 主要用于混合模态检索任务,包括多模态知识检索、组合图像检索、多模态查询的知识检索等。
- 相似度计算: 使用矩阵乘法计算余弦相似度,所有嵌入向量都被标准化到单位长度,确保相似度值在合理范围内。
运行结果:
=== 相似度计算结果 ===
纯图像 vs 纯图像: tensor([[0.8318]], device='cuda:0')
图文结合1 vs 纯图像: tensor([[0.8291]], device='cuda:0')
图文结合1 vs 纯文本: tensor([[0.7627]], device='cuda:0')
图文结合1 vs 图文结合2: tensor([[0.9058]], device='cuda:0')=== 嵌入向量信息 ===
多模态向量维度: torch.Size([1, 768])
图像向量维度: torch.Size([1, 768])
多模态向量示例 (前10个元素): tensor([ 0.0360, -0.0032, -0.0377, 0.0240, 0.0140, 0.0340, 0.0148, 0.0292,0.0060, -0.0145], device='cuda:0')
图像向量示例 (前10个元素): tensor([ 0.0407, -0.0606, -0.0037, 0.0073, 0.0305, 0.0318, 0.0132, 0.0442,-0.0380, -0.0270], device='cuda:0')
将datawhale开源组织的logo替换为蓝鲸看看结果有什么不同。