分析 HashMap 源码
一、成员变量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;1、初始容量,左移4位相当于×2⁴,也就是16;
static final int MAXIMUM_CAPACITY = 1 << 30;2、最大容量必须小于等于 2³⁰;
static final float DEFAULT_LOAD_FACTOR = 0.75f;3、默认负载因子为 0.75;
static final int TREEIFY_THRESHOLD = 8;
static final int MIN_TREEIFY_CAPACITY = 64;4、两句都是树化条件之一,前者表示链表长度超过8就树化,而后者表示数组长度超过64就树化;
static final int UNTREEIFY_THRESHOLD = 6;5、解树化的条件;
transient Node<K,V>[] table;6、创建数组,但未分配内存空间。(transient 防止字段被序列化的关键字)
transient Set<Map.Entry<K,V>> entrySet;7、Map.Entry 是 Map 内部实现的用来存放 <key, value> 键值对映射关系的内部类,该内部类中主要提供了 <key, value> 的获取,value 的设置,以及 key 的比较方式;
transient int size;8、此映射中包含的键值映射数。
transient int modCount;9、此HashMap被结构修改的次数;
int threshold;10、扩容阈值(容量×负载因子);
final float loadFactor;11、哈希表的负载因子,默认为0.0f。
二、构造方法
public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);}public HashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);}public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}public HashMap(Map<? extends K, ? extends V> m) {this.loadFactor = DEFAULT_LOAD_FACTOR;putMapEntries(m, false);}当我们通过语句 HashMap<Integer> map = new HashMap<>(); 创建对象时,调用的是无参的构造方法,该构造方法只是将负载因子设置为默认值,并没有为哈希表分配内存。
那么如果我们放个10进去,是否由构造方法开辟内存?

由此可见,并非是直接由构造方法为哈希表开辟内存空间。实际上当调用无参构造方法时,是由 put 方法开辟内存,这避免了创建了 HashMap 却从未使用而造成的空间浪费。下面分析 put 方法:
三、put 方法
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);} put 方法调用的是 putVal 方法,传入 5 个参数。解读 HashMap 的 putVal 方法是理解整个 HashMap 工作原理的关键。这个方法非常核心,它完成了插入、更新、扩容、链表化、树化等所有重要操作。
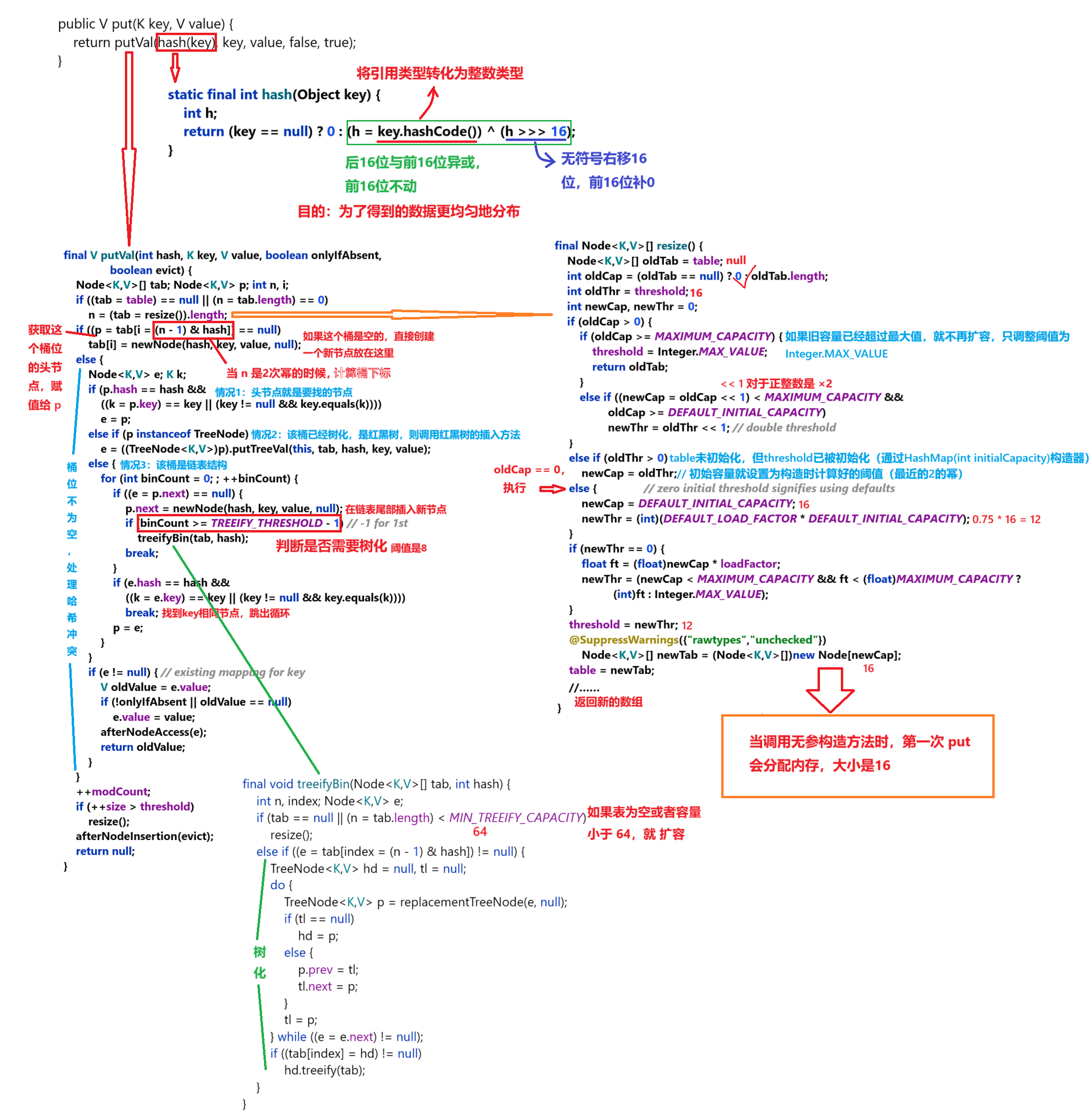
懒加载 (Lazy Initialization):HashMap 的底层数组
table并不是在构造函数中直接创建的,而是在第一次调用put方法时,通过resize()方法完成初始化的。这避免了创建了 HashMap 却从未使用而造成的空间浪费。
四、get 方法
public V get(Object key) {Node<K,V> e;return (e = getNode(hash(key), key)) == null ? null : e.value;}实际调用的是 getNode(int hash, Object key) 方法,如果找到节点就返回其 value 值,否则返回 null。
final Node<K,V> getNode(int hash, Object key) {Node<K,V>[] tab; Node<K,V> first, e; int n; K k;if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {if (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))return first;if ((e = first.next) != null) {if (first instanceof TreeNode)return ((TreeNode<K,V>)first).getTreeNode(hash, key);do {if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}return null;}
tips:
1、面试十有八九会问到的 HashMap 源码或者用法,要你介绍一下;还有可能考手搓 HashMap 中的 get 和 put 方法的编程题,即 HashMap 的具体实现。
2、如果一个对象为 key 时,hashCode 和 equals 方法的用法要注意什么?
put 和 get 方法中多次调用了 hashCode() 和 equals() 方法,hashCode() 决定了键值对的“寻址”(找哪个桶),而 equals() 决定了在同一个桶内的“匹配”(找哪个元素)。两者缺一不可,必须协同工作。因此在定义自定义类型作为 key 值的时候,必须同时重写这两个方法。
=> 思考:如果只重写了一个方法,会有什么问题,导致什么结果?