redis----hash类型详解
hash类型的key通常用field表示
一、常用命令
1. 基础操作命令
| 命令格式 | 功能说明 | 示例 | 返回值 |
|---|---|---|---|
HSET key field value [field value ...] | 为哈希表设置一个或多个字段值 | HSET user:1 name "张三" age 25 | 成功设置的字段数量 |
HGET key field | 获取哈希表中指定字段的值 | HGET user:1 name | 字段值(不存在返回nil) |
HMSET key field value [field value ...] | 批量设置哈希表字段值(Redis 4.0.0 后推荐用HSET替代) | HMSET user:2 name "李四" gender "男" | 成功返回OK |
HMGET key field [field ...] | 批量获取哈希表多个字段的值 | HMGET user:1 name age | 字段值列表(按输入顺序) |
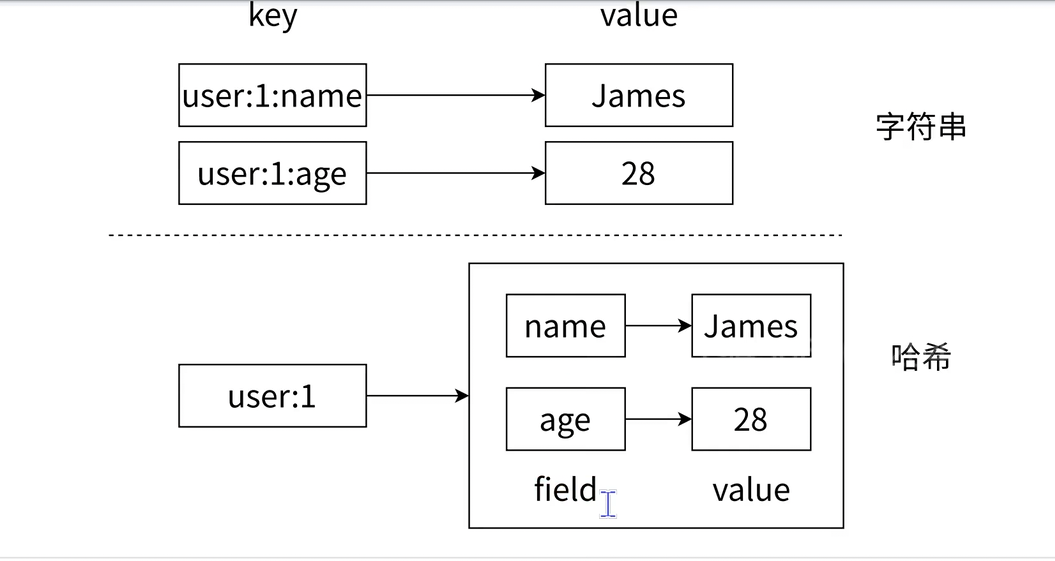
HGETALL key | 获取哈希表中所有字段和值 | HGETALL user:1 | 字段和值交替出现的列表 |
hset:

hget:

hmget:

hgetall:
2. 字段检查与删除
| 命令格式 | 功能说明 | 示例 | 返回值 |
|---|---|---|---|
HEXISTS key field | 判断哈希表中是否存在指定字段 | HEXISTS user:1 age | 存在返回1,不存在返回0 |
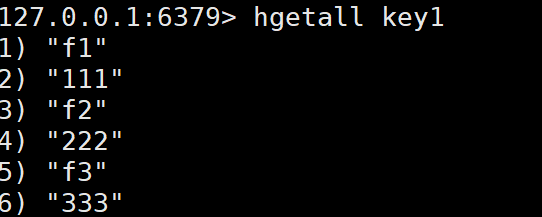
HDEL key field [field ...] | 删除哈希表中一个或多个字段 | HDEL user:1 age | 成功删除的字段数量 |
HLEN key | 获取哈希表中字段的数量 | HLEN user:1 | 字段总数 |
hexists:

hdel:

hlen:

3. 字段值运算与自增
| 命令格式 | 功能说明 | 示例 | 返回值 |
|---|---|---|---|
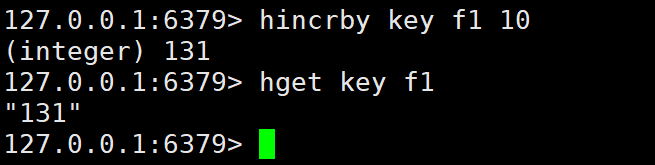
HINCRBY key field increment | 为哈希表字段的整数值增加指定增量(支持负数) | HINCRBY user:1 age 1 | 增量后的值 |
HINCRBYFLOAT key field increment | 为哈希表字段的浮点数值增加指定增量 | HINCRBYFLOAT product:1 price 0.5 | 增量后的值(字符串形式) |
hincrby:
hincrbyfloat:

4. 字段 / 值的批量获取
| 命令格式 | 功能说明 | 示例 | 返回值 |
|---|---|---|---|
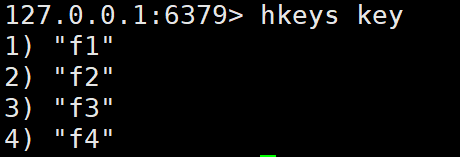
HKEYS key | 获取哈希表中所有字段名 | HKEYS user:1 | 字段名列表 |
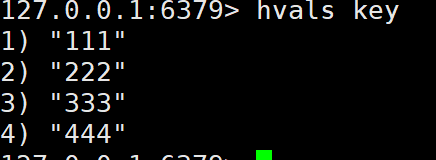
HVALS key | 获取哈希表中所有字段值 | HVALS user:1 | 字段值列表 |
如果hash的值较多,可能会使redis服务被阻塞掉
heys:
hvals:
5. 其他实用命令
| 命令格式 | 功能说明 | 示例 | 返回值 |
|---|---|---|---|
HSTRLEN key field | 获取哈希表中指定字段值的字符串长度 | HSTRLEN user:1 name | 字符串长度(不存在返回0) |
HSCAN key cursor [MATCH pattern] [COUNT count] | 迭代哈希表中的字段和值(用于大数据量遍历) | HSCAN user:1 0 MATCH "a*" COUNT 10 | 下一个游标和字段值列表 |
| HSETNX key field value | 设置哈希表中的值,存在设置错误,不存在设置成功 | hsetnx key f1 222 | 成功返回1,错误返回0 |
典型应用场景
- 存储用户信息(如
user:1001的name、age、email等字段) - 记录商品属性(如
product:500的price、stock、category) - 统计数据(如
stats:daily的pv、uv、click等计数)
二、内部编码
Redis 的 Hash 类型(哈希表)在底层有两种不同的内部编码方式,Redis 会根据哈希表的实际数据情况自动选择合适的编码,以在内存占用和操作效率之间取得平衡。这两种编码方式分别是:
1. ziplist(压缩列表)
适用场景:当哈希表满足以下两个条件时,Redis 会使用 ziplist 编码:
- 哈希表中所有键值对的键(field)和值(value)的字符串长度都小于 64 字节(可通过配置
hash-max-ziplist-value调整); - 哈希表中键值对数量小于 512 个(可通过配置
hash-max-ziplist-entries调整)。
编码特点:
- ziplist 是一种紧凑的连续内存结构,将所有键值对按顺序存储在一块连续内存中,减少了内存碎片和指针开销,内存利用率极高。
- 键值对按「键 1、值 1、键 2、值 2...」的顺序紧凑排列,无需额外的元数据(如哈希表节点的指针)。
- 缺点是修改操作(如插入、删除)效率较低,因为需要移动内存中的数据。
2. hashtable(哈希表)
适用场景:当哈希表不满足 ziplist 的条件时(如键值对数量超过 512 个,或某个键 / 值的长度超过 64 字节),Redis 会自动将编码转换为 hashtable。
编码特点:
- 基于数组 + 链表的经典哈希表结构(与 Java 的 HashMap 类似),通过哈希函数将键映射到数组索引,解决哈希冲突。
- 支持快速的插入、删除、查找操作(平均时间复杂度为 O (1)),适合键值对数量多或键 / 值较大的场景。
- 缺点是内存占用较高,因为需要存储哈希表节点、指针等额外元数据。
编码转换规则
- 当哈希表使用 ziplist 编码时,若后续操作导致键值对数量超过
hash-max-ziplist-entries,或某个键 / 值长度超过hash-max-ziplist-value,Redis 会自动将编码转换为 hashtable。 - 转换是单向的:一旦从 ziplist 转为 hashtable,即使后续键值对数量减少或长度变短,也不会再转回 ziplist。