使用Lora微调大模型介绍篇
使用Lora微调大模型介绍篇
前言:LoRA使用低秩微调大模型达到甚至优于全量微调
介绍
Lora为PEFT 基于重参数化(Reparametrization-based)训练方法。全称low-rank adaptation of large language models。
为了使微调更加高效,LoRA的方法是通过低秩分解将权重更新表示为两个较小的矩阵(称为更新矩阵)。这些新矩阵可以在适应新数据的同时保持整体变化数量较少进行训练。
原始权重矩阵保持冻结状态,并且不再接受任何进一步的调整。最终结果是通过将原始权重和适应后的权重进行组合得到。
“低秩”(Low-Rank)是一个线性代数中的概念。简单来说,低秩意味着一个矩阵内部存在大量的冗余和重复性,它包含的信息可以用远少于它本身尺寸的少量“核心元素”来概括和表示。
一个生活中的完美比喻:做菜
想象一下你有100道菜的完整菜谱(一个100x100的大矩阵)。每一行是一道菜,每一列是一种食材的用量。
| 菜谱 | 鸡蛋 | 面粉 | 糖 | 牛奶 | 番茄 | …(100种食材) |
|---|---|---|---|---|---|---|
| 蛋糕1 | 2 | 200 | 100 | 100 | 0 | … |
| 蛋糕2 | 3 | 250 | 120 | 120 | 0 | … |
| 蛋糕3 | 2 | 210 | 110 | 110 | 0 | … |
| … | … | … | … | … | … | … |
| 番茄炒蛋1 | 3 | 0 | 0 | 0 | 2 | … |
| 番茄炒蛋2 | 4 | 0 | 0 | 0 | 3 | … |
| … | … | … | … | … | … | … |
你发现,这100道菜其实主要就是两大类:蛋糕和番茄炒蛋。
- 所有蛋糕的菜谱:都是鸡蛋、面粉、糖、牛奶的不同组合,根本用不到番茄。
- 所有番茄炒蛋的菜谱:都是鸡蛋和番茄的不同组合,根本用不到面粉、糖、牛奶。
那么,我们何必要维护一个巨大的100x100的表格呢?我们可以这样做:
第1步:定义“基础菜系”(低维核心)
我们只需要两个“基础菜系向量”就能概括所有信息:
- 蛋糕向量:
[鸡蛋, 面粉, 糖, 牛奶](例如[1, 100, 50, 50]) - 番茄炒蛋向量:
[鸡蛋, 番茄](例如[1, 1])
第2步:记录每道菜是如何由“基础菜系”组合而成的
- 蛋糕1 = 2.0 * 蛋糕向量 + 0 * 番茄炒蛋向量
- 番茄炒蛋1 = 0 * 蛋糕向量 + 3.0 * 番茄炒蛋向量
你看,我们原本需要一个100x100的巨大矩阵,但现在我们只用:
- 2个基础向量(共
2*100=200个数) - 100道菜的组合系数(共
100*2=200个数)
总共400个数就几乎完美地还原了原本需要10,000个数的矩阵信息!
这个“2”就是“秩”(Rank)。我们用一个秩为2的表示法,高效地近似了原始的大矩阵。这就是低秩近似的核心思想。
原理分析
在LoRA方法中,实际上是在原始预训练语言模型(PLM)旁增加一个附加的网络通路,这可以视作一种“外挂”结构。这个外挂结构的目的是通过两个矩阵A和B的相乘来模拟本征秩(intrinsic rank)。如下图描绘了LoRA方法在微调大模型(如PLM:预训练语言模型)某一层时的具体实现细节:
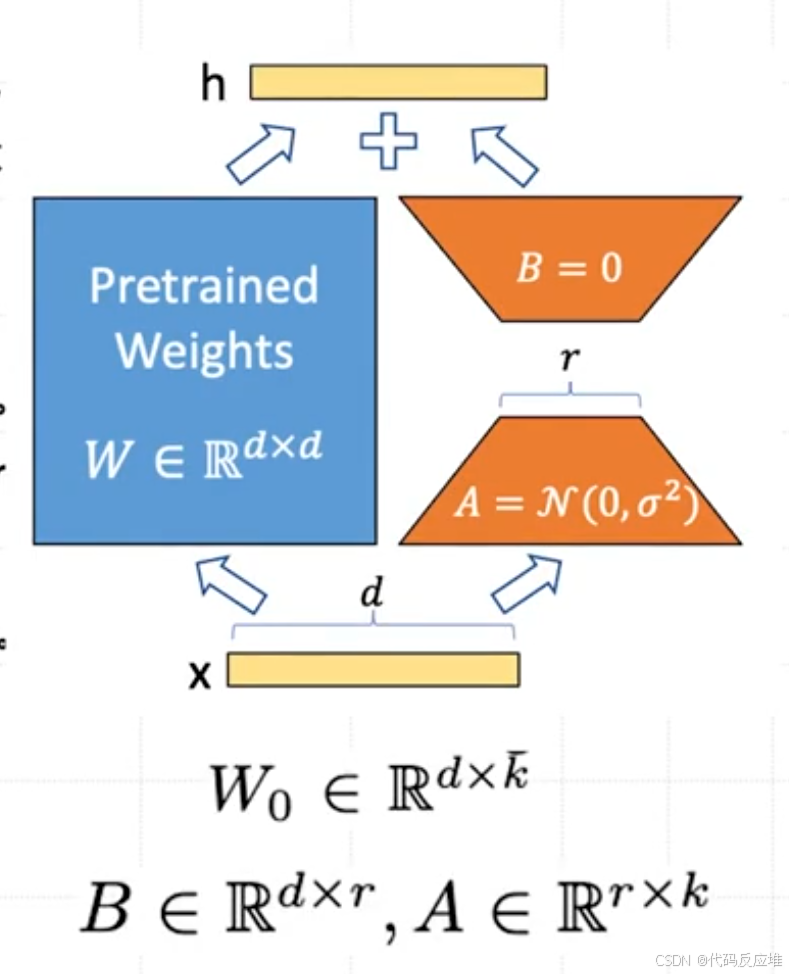
整体设计:(两个小模型)输入和输出的维度均为d,这与预训练模型层的维度相同。
低秩分解:A矩阵会将输入的d维数据降至r维(增量矩阵的本征秩),r远小于d(𝑟<<𝑑r<<d)。矩阵计算从d×d变为d×r+r×d,减少了模型的参数量和计算量。
回映射:B矩阵将这些r维数据再映射回d维,以便与预训练模型的其他部分保持兼容。
通过这样的低秩适配,LoRA能够有效地在保持预训练模型的复杂性和表达能力的同时,减少所需的计算资源,并提高微调的效率。这种结构使得只有一小部分参数(A和B矩阵)需要在特定任务上进行训练,而不是整个模型,从而提高了微调的效率和实用性。
图片内容详细解释如下
- 左侧部分为冻结的预训练模型,Pretrained Weights表示原始权重矩阵,维度是dxk(
d是输入维度,k是输出维度,为简化常假设d = k,所以图中写为d x d)。在微调过程中这个矩阵被“冻结”(freeze),意味着它的权重值Wo始终保持不变,不参与梯度更新。输入x从上一层传来的数据,是一个维度为d的向量。 - 右侧为LoRA适配器 (The LoRA Adapter),这就是所谓的“外挂”结构。它由两个小矩阵 A 和 B 组成。矩阵
A(降维矩阵):维度:r x k。这里的r是“秩”(rank),是一个我们设定的非常小的数,它将输入x(维度d)投影到一个低维空间(维度r),捕捉任务最核心的变化信息。**A = N(0, σ²)表示训练开始时,矩阵A的权重从一个均值为0的高斯分布中随机初始化。矩阵B(升维矩阵)**升维。它将低维空间(维度r)的数据再投影回原始的高维空间(维度d)以便能与原始模型的输出相加,B = 0: 在训练开始时,矩阵B的权重初始化为0。这是一个非常巧妙的设计,意味着在训练刚开始时,整个LoRA适配器的输出是0,不会干扰原始模型的性能。模型从“完全原始状态”开始稳步学习。整个适配器做的计算就是B(A(x)),其效果BA就是一个模拟的权重更新矩阵ΔW(维度d x k)。因为r很小,所以BA是一个低秩矩阵。 - 最终输出:合并结果,最终这一层的输出
h是两条通路结果的和:h = W₀(x) + BA(x),原始输出加上一个低秩适配器学习到的“增量”,从而在不改变原模型的基础上,实现了对特定任务的适配。
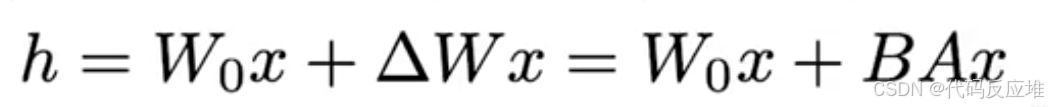
优势
1、相比于Adapter
推理性能高效:
- 与Adapter方法相比,LoRA在推理阶段直接利用训练好的A、B低秩矩阵替换原预训练模型的对应参数。这种替换避免了增加网络深度所带来的额外计算量和推理延时。
- LoRA方法使得推理过程与全参数微调(Full-finetuning)相似,但并不增加额外的计算负担。保持了高效的推理性能,同时实现了对模型的有效调整。
模拟全参数微调的效果:
- LoRA通过对模型关键部分的低秩调整,实际上模拟了全参数微调的过程。
- 这种方法几乎不会导致训练效果的损失。
2、相比于Soft Prompts
更深层次的模型修改:
- LoRA通过修改模型的权重矩阵,直接影响模型中的内部表示和处理机制,而不仅仅是输入层级。
- 这意味着LoRA能够在模型的更深层次上产生影响,可能导致更有效的学习和适应性。
无需牺牲输入空间:
- Soft prompts通常需要占用模型的输入空间,这在有限的序列长度下可能限制了其他实际输入内容的长度。
- LoRA不依赖于Prompt调整方法,避免了相关的限制,因此不会影响模型能处理的输入长度。
直接作用于模型结构:
- LoRA通过在模型的特定层(如Transformer层)内引入低秩矩阵来调整模型的行为,这种修改是直接作用于模型结构的。
- 相比之下,soft prompts更多是通过操纵输入数据来影响模型的输出。
更高的灵活性和适应性:
- LoRA提供了更大的灵活性,在不同的层和模型部件中引入低秩矩阵,可以根据具体任务进行调整。
- 这种灵活性使得LoRA可以更精细地调整模型以适应特定的任务。
模拟全参数微调的效果:
- LoRA的设计思路是模拟全参数微调的过程,这种方法通常能够带来更接近全面微调的效果,尤其是在复杂任务中。
总的来说,LoRA的优势在于其能够更深入地、不占用额外输入空间地修改模型,从而提供更高的灵活性和适应性,适用于需要深层次模型调整的场景。
Lora实验数据
数据1
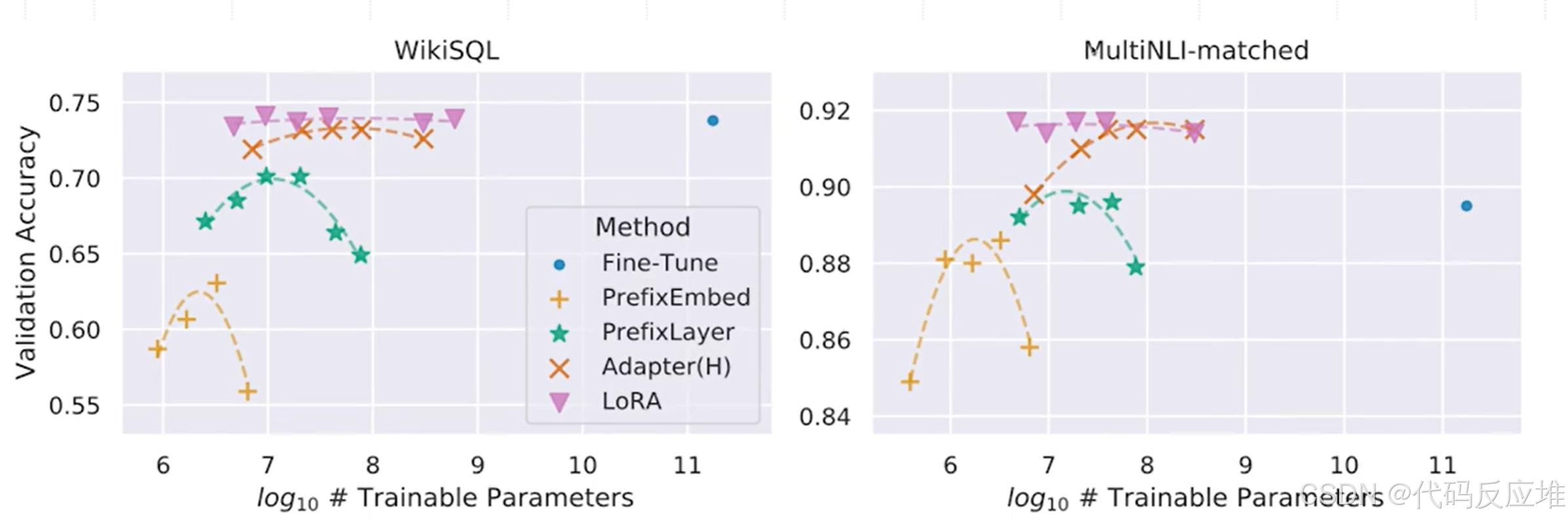
图表在两个截然不同的任务(WikiSQL(结构化数据查询)和MultiNLI-matched(自然语言推理))上都进行了测试。LoRA在不同类型的任务上都能保持稳定且优异的性能。
横轴是 log10(# Trainable Parameters)(可训练参数数量的对数),纵轴是验证准确率。
- 在WikiSQL任务上,LoRA的性能显著优于其他参数高效方法(PrefixEmbed, PrefixLayer, Adapter),并且匹配甚至超过了全参数微调(Fine-Tune)的性能。并且是以极小的参数量开销(通常只占原模型参数的0.01%~1%),实现与全参数微调相媲美的效果,极大地降低了计算和存储成本。
- 在MultiNLI任务上,LoRA明显超过了全参数微调(Fine-Tune, ~0.9),而PrefixEmbed是除LoRA之外表现最好的方法。LoRA不仅参数效率高,而且泛化能力很强,在各种NLP任务上都能达到一流的性能,可靠性高。
数据2
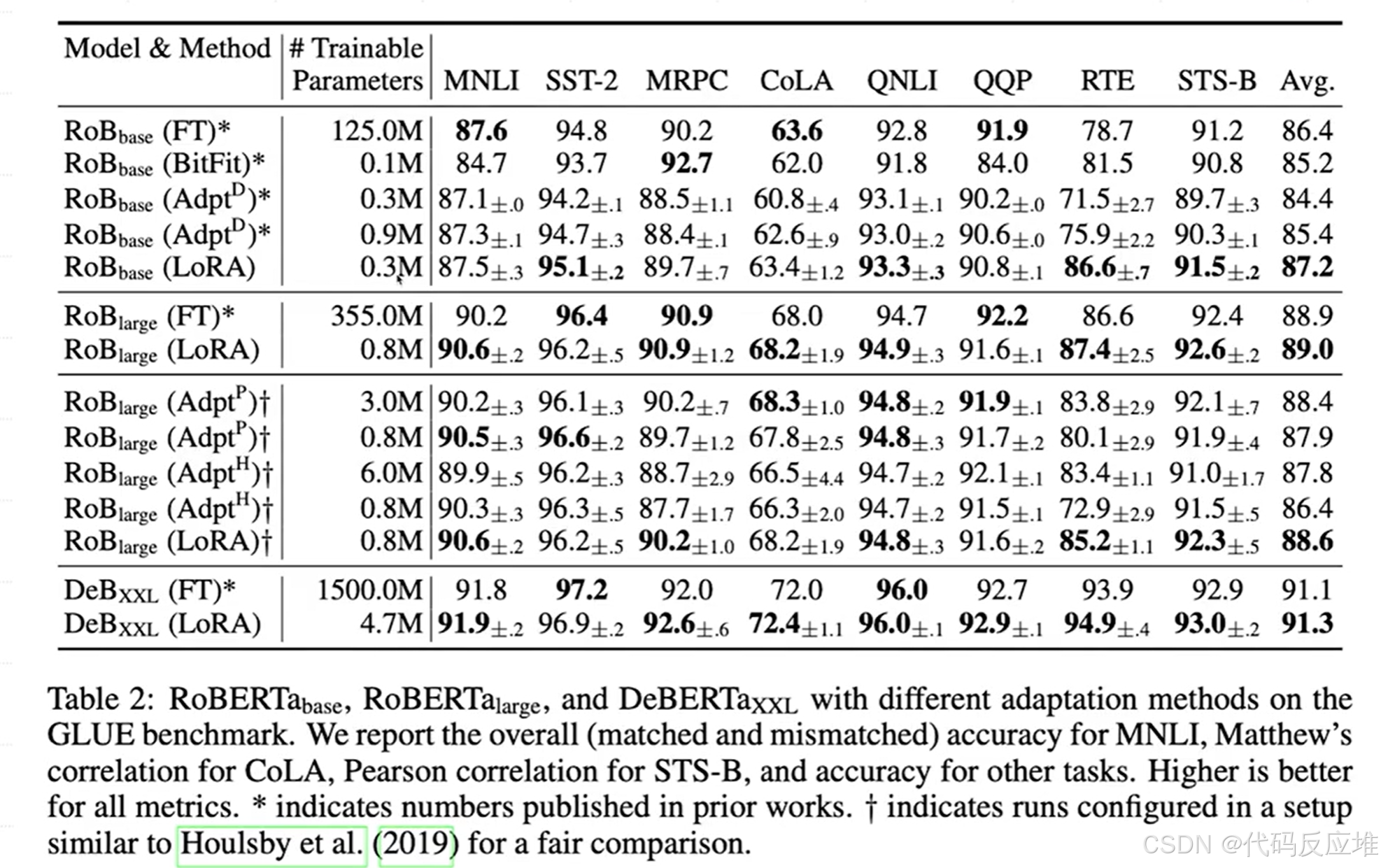
LoRA使用极少的可训练参数(通常不到原模型的1%),在绝大多数任务上达到了与全参数微调(Fine-Tune)相当甚至更优的性能,并且显著优于其他参数高效微调方法(如Adapter、BitFit)。
- 在 RoBERTa-base 上:全参数微调 (FT):需要训练 1.25亿 个参数,平均得分 86.4。LoRA:仅训练 30万 个参数(是FT的 0.24%),平均得分 87.2。LoRA用 *1/400* 的参数量,实现了比全量微调更高的平均性能。这堪称“四两拨千斤”。
- 在 RoBERTa-large 上:FT:3.55亿 参数,平均分 88.9。LoRA:80万 参数(FT的 0.23%),平均分 89.0。参数量节省幅度巨大,但性能丝毫不损,甚至略有超越。
- 在巨大的 DeBERTa-xxL 上:FT:15亿 参数,平均分 91.1。LoRA:470万 参数(FT的 0.31%),平均分 91.3。对于超大规模模型,LoRA的优势更加明显。微调15亿参数的模型通常需要极高的硬件成本,而LoRA将其降低到只需微调一个470万参数的小模型,效果反而更好。
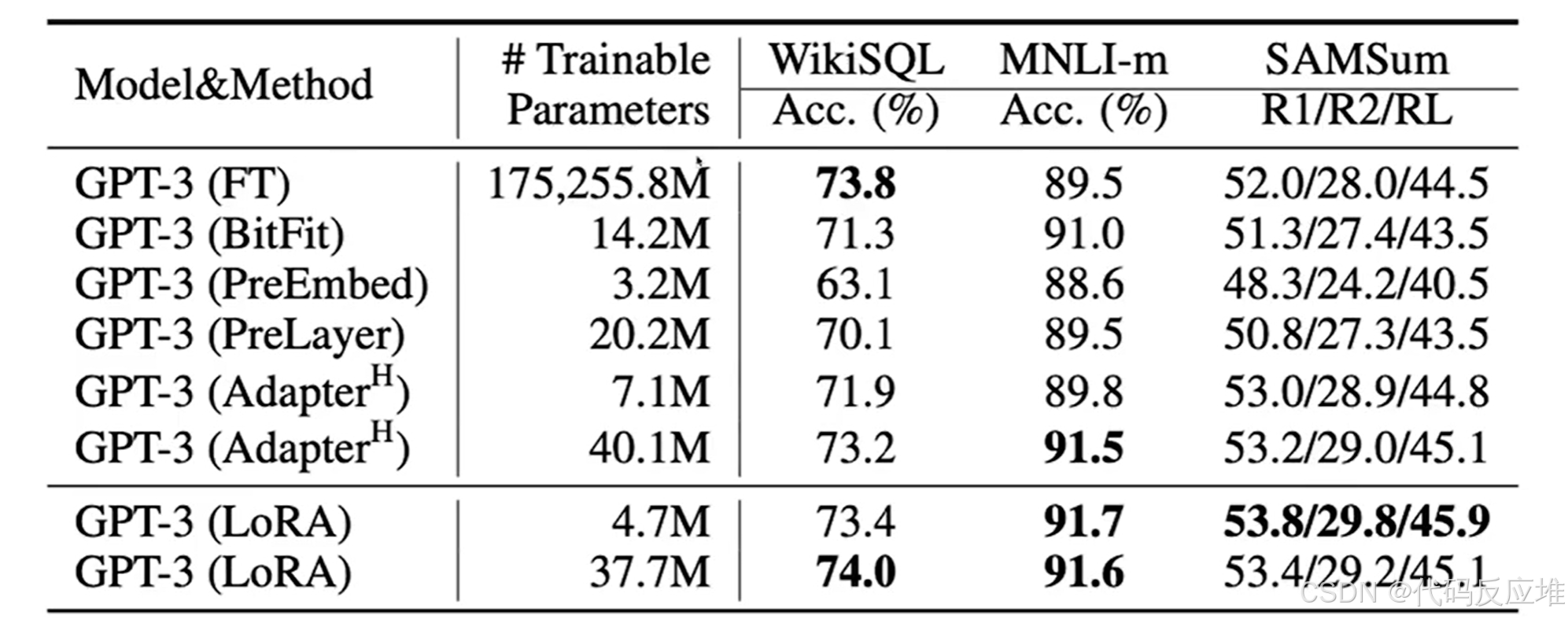
- 在GPT3上: FT需要1752.55亿练参数,这在实践中需要极高的硬件成本,几乎难以实现。LoRA:仅需训练 470万 (4.7M) 或 3770万 (37.7M) 个参数。即使是其他高效方法(BitFit, Prefix, Adapter),其参数量(3.2M - 40.1M)也普遍高于最低配置的LoRA (4.7M)。LoRA实现了“用最少的参数,办最多的事”。
- 任务一:WikiSQL (文本转SQL查询):全参数微调 (FT) 的准确率为 73.8%。LoRA (37.7M) 取得了所有方法中的最高分 74.0%,超越了全参数微调。最低配的LoRA (4.7M) 也达到了 73.4%,与FT几乎持平,且远优于Prefix等方法的 ~70%。
- 任务二:MNLI-matched (自然语言推理): 全参数微调 (FT) 的准确率为 89.5%。LoRA (4.7M和37.7M) 分别取得了 91.7% 和 91.6% 的惊人成绩,大幅超越FT(近2个点)和其他所有方法。
- 任务三:SAMSum (对话摘要):全参数微调 (FT) 的三个分数为:52.0 / 28.0 / 44.5。LoRA (4.7M) 取得了所有方法中的最高分:53.8 / 29.8 / 45.9,在所有指标上均全面超越了FT和其他方法。即使增加参数量,LoRA (37.7M) 的性能也几乎没有提升甚至略有下降,这反而证明了低秩假设的有效性——对于此任务,4.7M的参数已经足够捕捉所需的变化,更多参数可能是冗余的。
如何使用Lora微调大模型
1、根据具体任务准确率选择权重和低秩匹配
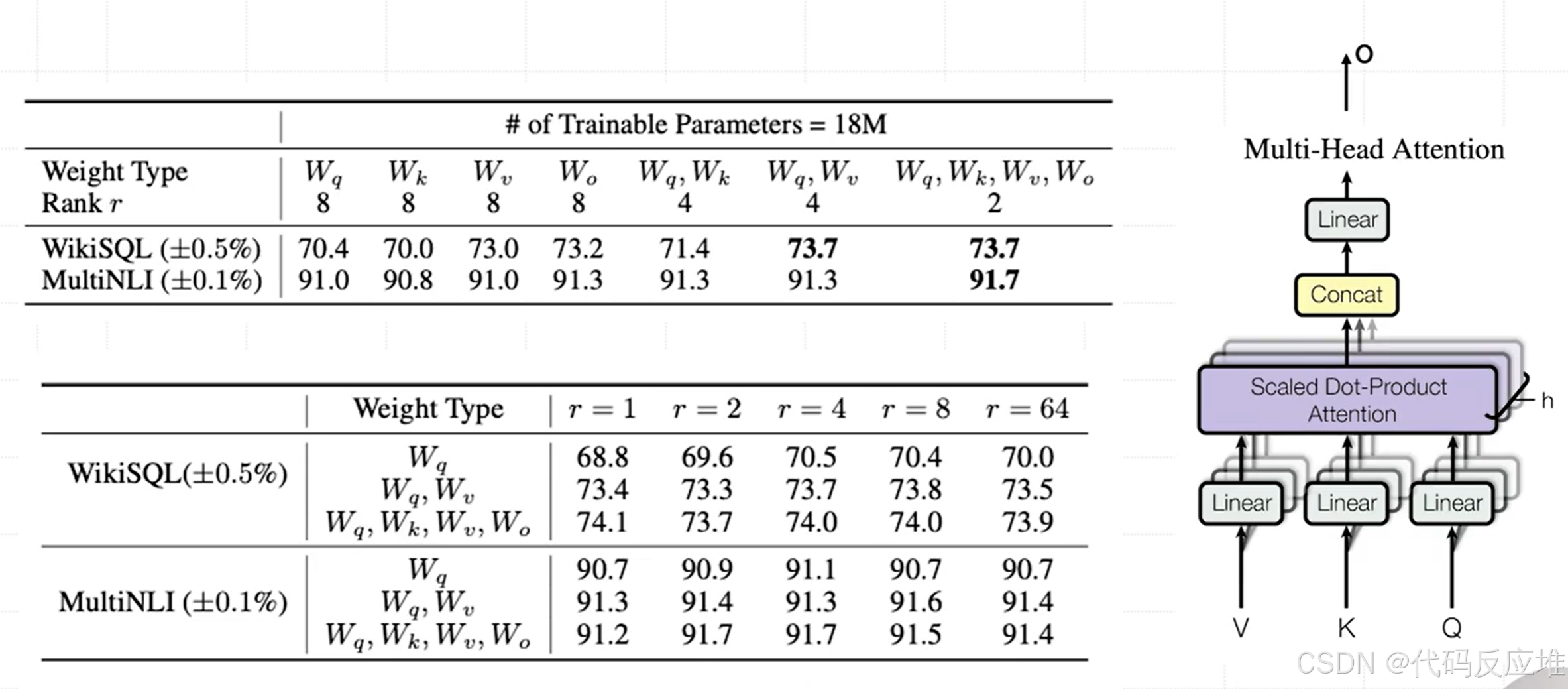
第一部分:对于18M的参数,微调参数该怎么设置,通过调整秩 r 的大小来尝试不同的矩阵组合。
- Weight Type :指微调类型,即应该对Transformer模型里的哪些权重矩阵应用LoRA,如Wq对应图中的Q,微调
Wv(Value) 和Wo(输出投影) 矩阵通常比微调W_q(Query) 和W_k(Key) 矩阵更有效。最稳妥和高效的策略是对所有四个矩阵(W_q, W_k, W_v, W_o)都应用LoRA,并采用一个较小的秩(如2、4、8)。 - Rank r:就是指低秩的比例,即LoRA的秩(Rank
r)应该设置多大,在大多数情况下,一个很小的秩(r=4, 8)就足够了,增大秩(例如到64)带来的性能提升非常有限,甚至可能下降,这会导致参数利用效率降低。
第二部分:固定目标矩阵,选择不同的秩 ®
- 秩存在一个“甜蜜点”(Sweet Spot),通常很小,在
r=4或r=8左右。超过这个点后(例如r=64),性能不再增长甚至可能下降。这是因为过大的秩可能使低秩矩阵BA过度拟合训练数据,损害其泛化能力,同时也违背了LoRA的“低秩内在假设”。 - 更大的秩 ≠ 更好的性能。选择一个适中的秩是最划算的。
总结:
- 选择目标矩阵:最通用的配置是对Attention模块中的所有四个权重矩阵(
W_q,W_k,W_v,W_o)都应用LoRA。这是效果最好、最稳定的选择。 - 选择秩 ®:从一个较小的秩开始尝试,例如
r=8或r=16。这通常能提供非常好的性能。只有在你的任务非常复杂时,才考虑尝试增大到r=32或r=64,但不要期望有巨大提升。 - 优先尝试
W_v和W_o:如果你的计算资源非常紧张,可以尝试只对W_v和W_o应用LoRA,并设置一个稍大的秩(如r=16),这可能会在性能和成本间取得一个好平衡。
2、根据测试集上性能指标表现选择低秩配置
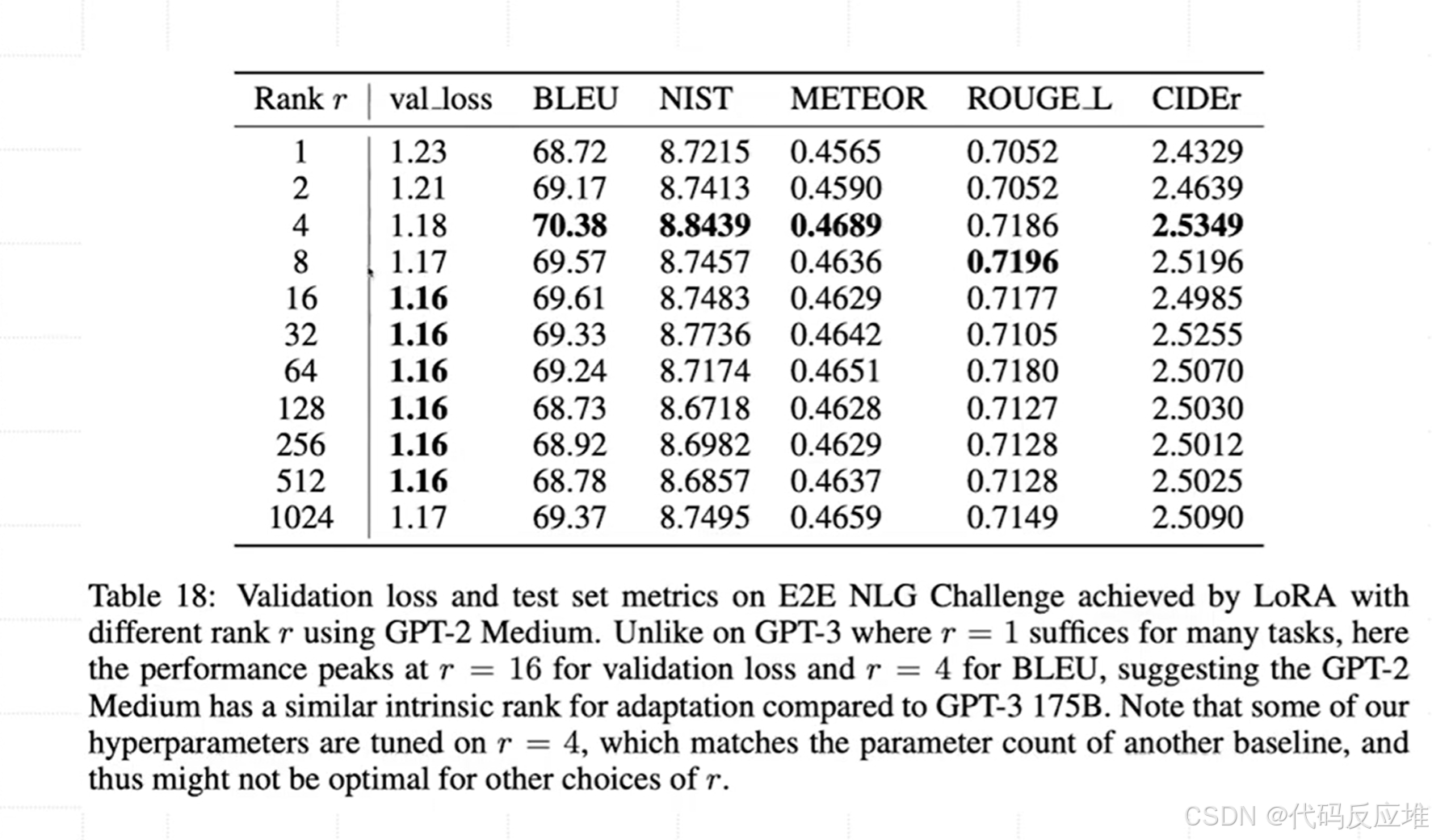
指标解释及表数据分析:
-
val_loss (Validation Loss) - 验证损失:损失函数是模型在训练过程中用于优化参数的核心指标。它直观地衡量了模型预测的概率分布与真实的目标分布之间的“差异”或“错误程度”。值越低越好。下降的损失表明模型正在学习,其预测结果与正确答案越来越接近。它是在验证集上计算的,用于监控训练过程是否正常,以及模型是否开始过拟合(记住训练数据而非学会泛化)。表中当
r增加到 16 时,val_loss降至最低点 (1.16) 并保持稳定。这表明从“减小预测错误”的角度来看,r >= 16的模型复杂度已经足够 -
质量评估指标 (Automatic Evaluation Metrics):这些指标是在模型训练完成后,在测试集上评估其最终生成文本质量的指标。它们通过比较模型生成的文本和人类编写的参考文本(标准答案)来计算得分。
- BLEU (Bilingual Evaluation Understudy):最经典和广泛使用的机器翻译评估指标。它通过计算机器生成文本中的n-grams(连续n个词) 在参考文本中出现的精确度。值越高越好,范围在0到100之间(有时表示为0到1)。侧重于生成的准确性和流畅度。高BLEU分意味着生成的文本包含了许多与参考答案相同的词和短语。更关注“精确”而非“语义”,可能会惩罚那些使用不同但正确的同义词的表达。
- NIST (National Institute of Standards and Technology):BLEU的改良版。它不仅计算n-gram的出现次数,还为信息量更大的n-grams赋予更高的权重(例如,出现频率较低的词或短语更重要)。值越高越好。相比BLEU,它通常被认为与人类判断的相关性更高。
- METEOR (Metric for Evaluation of Translation with Explicit ORdering):另一个针对BLEU缺点的改进指标。它基于单义词(unigrams) 的精确率和召回率的调和平均(F-score)。值越高越好,范围在0到1之间。它引入了同义词匹配和词干匹配(例如,“running”和“run”可以算作匹配)。因此,它比BLEU更能捕捉语义相似性。它也考虑了句子结构的流畅度。
- ROUGE-L (Recall-Oriented Understudy for Gisting Evaluation - Longest Common Subsequence):最初为文本摘要任务设计,但也广泛应用于其他生成任务。它计算机器生成文本和参考文本之间的最长公共子序列的比率。值越高越好,范围在0到1之间。侧重于衡量生成文本的连贯性和覆盖度(即是否包含了参考答案中的关键信息点)。ROUGE-L的“R”代表召回率,意味着它更关心参考答案中有多少信息被覆盖了。
- CIDEr (Consensus-based Image Description Evaluation):最初为图像描述生成任务设计。它通过计算TF-IDF权重来衡量n-grams的重要性。值越高越好。TF-IDF意味着它会给那些频繁出现在参考文本中,但又不常见的词(即任务相关的关键词)更高的权重。因此,它能很好地判断生成内容是否包含了该领域的关键术语和共识性内容。
-
最佳性能点:虽然
val_loss在r=16时就已最低,但任务质量指标(尤其是BLEU, NIST, METEOR, CIDEr)在r=4达到峰值。
一个在损失函数上表现“完美”的模型,不一定能生成质量最高的文本。 对于文本生成任务,BLEU 等指标比损失函数更能反映模型的真实性能。
模型不同,最优秩不同:注释明确指出,这与在GPT-3上的发现(r=1 就足够)不同。说明不同模型和不同任务有其独特的“内在秩”,需要通过实验来确定。